【多线程与高并发】- 浅谈volatile

浅谈volatile
- 简介
- JMM概述
- volatile的特性
- 1、可见性
- 举个例子
- 总结
- 2、无法保证原子性
- 举个例子
- 分析
- 使用volatile对原子性测试
- 使用锁的机制
- 总结
- 3、禁止指令重排
- 什么是指令重排序
- 重排序怎么提高执行速度
- 重排序的问题所在
- volatile禁止指令重排序
- 内存屏障(Memory Barrier)作用
- volatile内存屏障的插入策略
简介
volatile是Java语言中的一种轻量级的同步机制,它可以确保共享变量的内存可见性,也就是当一个线程修改了共享变量的值时,其他线程能够立即知道这个修改。跟synchronized一样都是同步机制,但是相比之下,synchronized属于重量级锁,volatile属于轻量级锁。
JMM概述
JMM就是Java内存模型(Java Memory Model),是Java虚拟机规范的一种内存模型,屏蔽掉各种硬件和操作系统的内存访问差异,以实现让Java程序在各种平台下都能达到一致的并发效果。
Java内存模型规定了Java程序的变量(包括实例变量,静态变量,但是不包括局部变量和方法参数)全部存储在主内存中,定义了各种变量(线程的共享变量)的访问规则,以及在JVM中将变量存储到主内存与从主内存读取变量的底层细节。
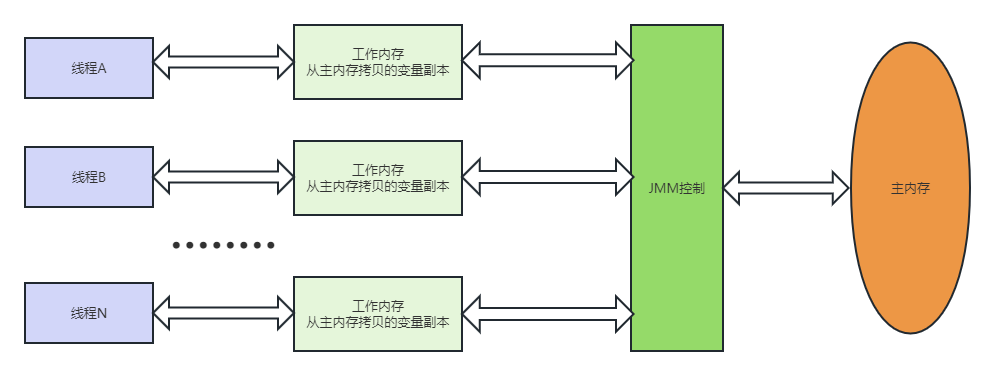
JMM的规定
● 所有共享变量都存在于主内存(包括实例变量,静态变量,但是不包括局部变量和方法参数),因为局部变量是线程私有,不存在竞争问题。
● 每个线程都有自己的工作内存,所需要的变量是主内存中的副本。
● 线程对变量的读、写操作都只能在工作内存中完成,不能直接参与读写主内存的变量。
● 不同的线程也不能去直接访问不同线程的工作内存的变量,线程间的变量传递需要通过主内存来中转完成。
volatile的特性
1、可见性
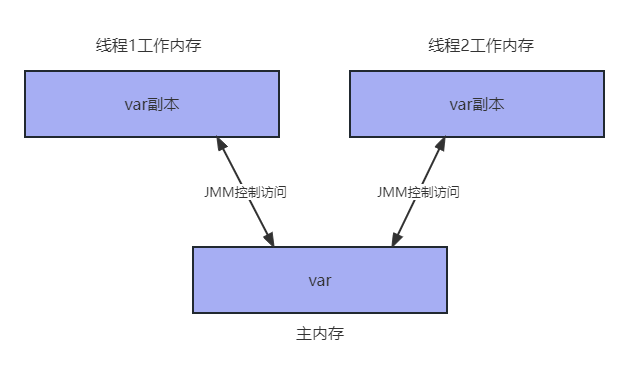
volatile可以保证线程的可见性,即当多个线程访问同一个变量的时候,此变量发生改变,其他线程也能实时获得到这个修改的值。
在java中,变量都会被放在推内存(所有线程共享的内存)中,多个线程对共享内存是不可见的,当每个线程去获取这个变量的值时,实际上是copy一份副本在线程自身的工作内存中。
举个例子
我们将main作为主线程,MyThread为子线程。在子线程中定义一个共享变量flag,主线程会去访问这个共享变量。在不加volatile的时候,flag在主线程读到的永远是为false,因为两个线程是不可见的。
public class T2_Volatile01 {public static void main(String[] args) { // 主线程MyThread my = new MyThread();my.start();while (true) {if (my.isFlag()) System.out.println("进入等待...");}}
}class MyThread extends Thread { // 子线程private volatile boolean flag = false;@Overridepublic void run() {try {Thread.sleep(1000);} catch (InterruptedException e) {throw new RuntimeException(e);}flag = true;System.out.println("flag 修改完毕!");}public boolean isFlag() {return flag;}public void setFlag(boolean flag) {this.flag = flag;}
}
实际上是已经修改了的,只是线程读的都是自己的工作内存中的数据,然而,要解决这个问题,可以使用synchronized加锁和volatile修饰共享变量来解决,这两种都能让主线程拿到子线程修改的变量的值。
synchronized (my) {if (my.isFlag()) System.out.println("进入等待...");
}
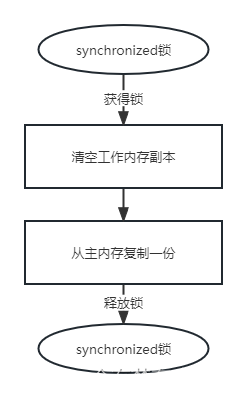
加了synchronized锁,首先该线程会获得锁对象,接着会去清空工作内存,再从主内存中copy一份最新的值到工作变量中,接着执行代码, 打印输出,最后释放锁。
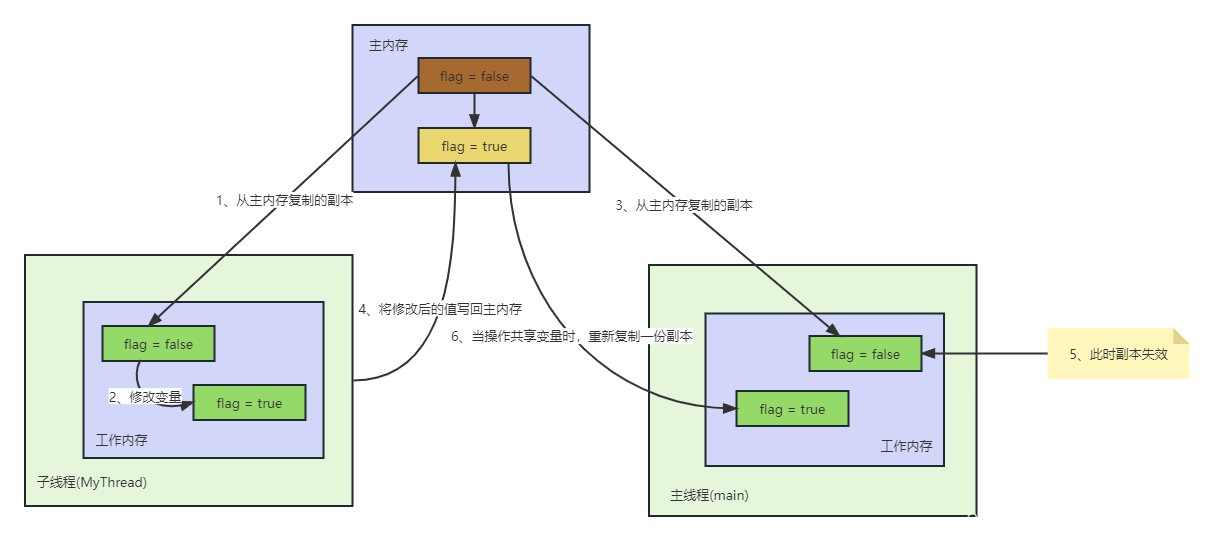
当然还能使用volatile关键字去修饰共享变量。一开始子线程从主内存中获取变量的副本到自己的工作内存,进行改值,此时还未写回主内存,主线程从主内存获取的变量的值也是一开始的初始值,等到子线程写回到主内存时,接下来其他线程的工作内存中此变量的副本将会失效,也就是类似于监听。在需要对此变量进行操作的时候,将会到主内存获取新的值保存到线程自身的工作内存中,从而确保了数据的一致。
总结
volatile能够保证不同线程对共享变量的可见性,也就是修改过的volatile修饰的共享变量只要被写回到主内存中,其他线程就能够马上看到最新的数据。
当一个线程对volatile修饰的变量进行写的操作时候,JMM会立即把该线程自身的工作内存的共享变量刷新到主内存中。
当对线程进行读操作的时候,JMM会立即把当前线程自身的工作内存设置无效,从而从主内存中去获取共享变量的数据。
2、无法保证原子性
原子性指的是一项操作要么都执行,要么都不执行,中途不允许中断也不受其他线程干扰。
举个例子
我们看以下案例代码,简单描述一下,AutoAccretion是一个线程类,里面定义了一个共享变量count,并去执行1万次的自增,在main线程中调用多线程去执行自增。我们所期望的结果是最终count的值是1000000,因为每个线程自增1万次,一共100个线程。
public class T3_Volatile01 {public static void main(String[] args) {Runnable thread = new AutoAccretion();for (int i = 1; i <= 100; i++) {new Thread(thread, "线程" + i).start();}}
}class AutoAccretion implements Runnable {private int count = 0;@Overridepublic void run() {for (int i = 1; i <= 10000; i++) {count++;System.out.println(Thread.currentThread().getName() + "count ==> " + count);}}
}
分析
count++操作首先会从主内存中拷贝变量副本到工作内存中,在工作内存中进行自增操作,最后将工作内存的数据写回主内存中。运行之后会发现,count的值是没办法到达1百万的。主要原因是count++自增操作并不是原子性的,也就是说在进行count++的时候可能被其他线程打断。
当线程1拿到count=0,进行自增后count=1,但是还没写到主内存,线程2获取的数据可能也是count=0,经过自增count=1,两者在写回内存,就会导致数据的错误。
使用volatile对原子性测试
现在通过volatile去修饰共享变量,运行之后,发现任然没办法达到一百万。
使用锁的机制
通过使用synchronized锁对代码快进行加锁,从而确保原子性,确保某个线程对count进行操作不受其他线程的干扰。
class AutoAccretion implements Runnable {private volatile int count = 0; // 并发下可见性@Overridepublic void run() {synchronized (this) {for (int i = 1; i <= 10000; i++) {count++;System.out.println(Thread.currentThread().getName() + "count ==> " + count);}}}
}
通过验证可以知道能够实现原子性。
总结
在多线程下,volatile关键字可以保证共享变量的可见性,但是不能保证对变量操作的原子性,因此,在多线程下即使加了volatile修饰的变量也是线程不安全的。要保证原子性就得通过加锁的机制。
除了这个方法,Java还能用过 原子类(java.util.concurrent.atomic包) 来保证原子性。
3、禁止指令重排
什么是指令重排序
指令重排序:为了提高程序性能,编译器和处理器会对代码指令的执行顺序进行重排序。
良好的内存模型实际上会通过软件和硬件一同尽可能提高执行效率。JMM对底层约束尽量减少,在执行程序时,为了提高性能,编译器和处理器会对指令进行重排序。
一般重排序有以下三种:
● 编译器优化的重排序:编译器在不改变单线程程序语义可以对执行顺序进行排序。
● 指令集并行的重排序:如果指令不存在相互依赖,那么指令可以改变执行的顺序,从而能够减少load/store操作。
● 内存系统的重排序:处理器使用缓存和读/写缓存区,使得加载和存储操作是乱序执行的。
重排序怎么提高执行速度
在不改变结果的时候,对执行进行重排序,可以提高处理速度。重排序后能够使处理指令执行的更少,减少指令操作。
重排序的问题所在
由于重排序,直接可能带来的问题就是导致最终的数据不对,通过以下例子来看,如果执行的顺序不同,最终得到的结果是不一样的。
public class T4_Reordering {public static int a = 0, b = 0;public static int i = 0, j = 0;public static void main(String[] args) throws InterruptedException {int count = 0;while (true) {count++;// 初始化a = 0;b = 0;i = 0;j = 0;Thread one = new Thread(new Runnable() {@Overridepublic void run() {a = 1;i = b;}});Thread two = new Thread(new Runnable() {@Overridepublic void run() {b = 1;j = a;}});one.start();two.start();one.join(); // 确保线程都执行完毕two.join();System.out.println("第" + count + "次线程执行:i = " + i + ", j = " + j );if (i == 0 && j == 0) return;}}
}
正常当线程都执行结束之后,最后得到的值应该是i=1, j=1。通过不断的循环执行可以看到,出现的结果会出错,当先执行了j=a(此时a=0)在执行了a=1,i=b(此时b=0),b=1,最后就会导致i=0,j=0
volatile禁止指令重排序
使用volatile可以实现禁止指令重排序,从而确保并发安全,那么volatile是如何实现禁止指令重排序呢?就是通过使用内存屏障(Memory Barrier)。
内存屏障(Memory Barrier)作用
● 内存屏障能够阻止屏障两侧的指令重排序,能够让cpu或者编译器在内存上的访问是有序的。
● 强制把写缓冲区/高速缓存中的脏数据写回主内存,或让缓存相应的数据失效。他是一种cpu指令,用来控制特定情况下的重排序和内存可见性问题。
volatile内存屏障的插入策略
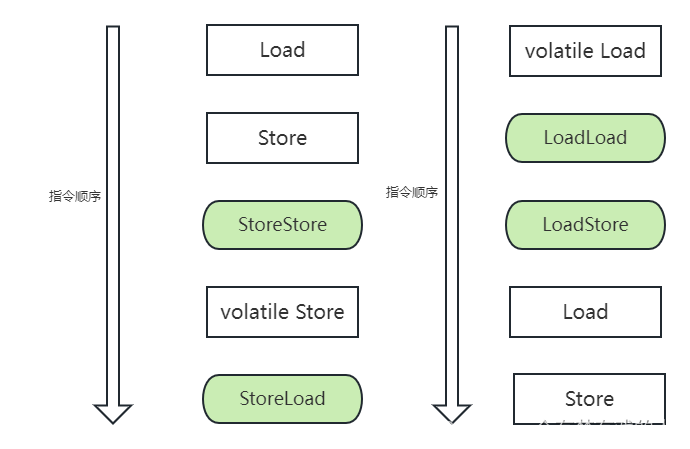
硬件层的内存屏障(Memory Barrier)有Load Barrier 和 Store Barrier即读屏障和写屏障。
Java内存屏障
● StoreStore屏障:确保在该屏障之后的第一个写操作之前,屏障前的写操作对其他处理器可见(刷新到内存)。
● StoreLoad屏障:确保写操作对其他处理器可见(刷新到内存)之后才能读取屏障后读操作的数据到缓存。
● LoadLoad屏障:确保在该屏障之后的第一个读操作之前,一定能先加载屏障前的读操作对应的数据。
● LoadStore屏障:确保屏障后的第一个写操作写出的数据对其他处理器可见之前,屏障前的读操作读取的数据一定先读入缓存。
在volatile修饰的变量进行写操作时候,会使用StoreStore屏障和StoreLoad屏障,进行对volatile变量读操作会在之后使用LoadLoad屏障和LoadStore屏障。
👍创作不易,如有错误请指正,感谢观看!记得点赞哦!👍
相关文章:
【多线程与高并发】- 浅谈volatile
浅谈volatile简介JMM概述volatile的特性1、可见性举个例子总结2、无法保证原子性举个例子分析使用volatile对原子性测试使用锁的机制总结3、禁止指令重排什么是指令重排序重排序怎么提高执行速度重排序的问题所在volatile禁止指令重排序内存屏障(Memory Barrier)作用volatile内…...
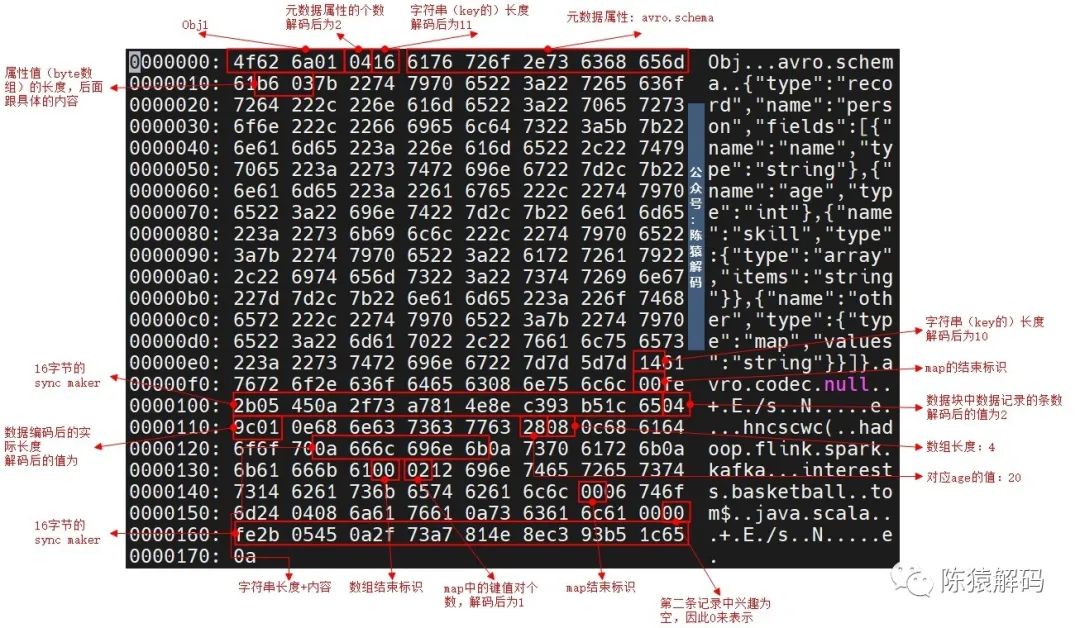
avro格式详解
【Avro介绍】Apache Avro是hadoop中的一个子项目,也是一个数据序列化系统,其数据最终以二进制格式,采用行式存储的方式进行存储。Avro提供了:丰富的数据结构可压缩、快速的二进制数据格式一个用来存储持久化数据的容器文件远程过程…...

【涨薪技术】0到1学会性能测试 —— LR录制回放事务检查点
前言 上一次推文我们分享了性能测试分类和应用领域,今天带大家学习性能测试工作原理、事务、检查点!后续文章都会系统分享干货,带大家从0到1学会性能测试,另外还有教程等同步资料,文末免费获取~ 01、LR工作原理 通常…...

卡尔曼滤波原理及代码实战
目录简介1.原理介绍场景假设(1).下一时刻的状态(2).增加系统的内部控制(3).考虑运动系统外部的影响(4).后验估计:预测结果与观测结果的融合卡尔曼增益K2.卡尔曼滤波计算过程(1).预测阶段(先验估计阶段)(2).更新阶段(后验估计阶段&…...
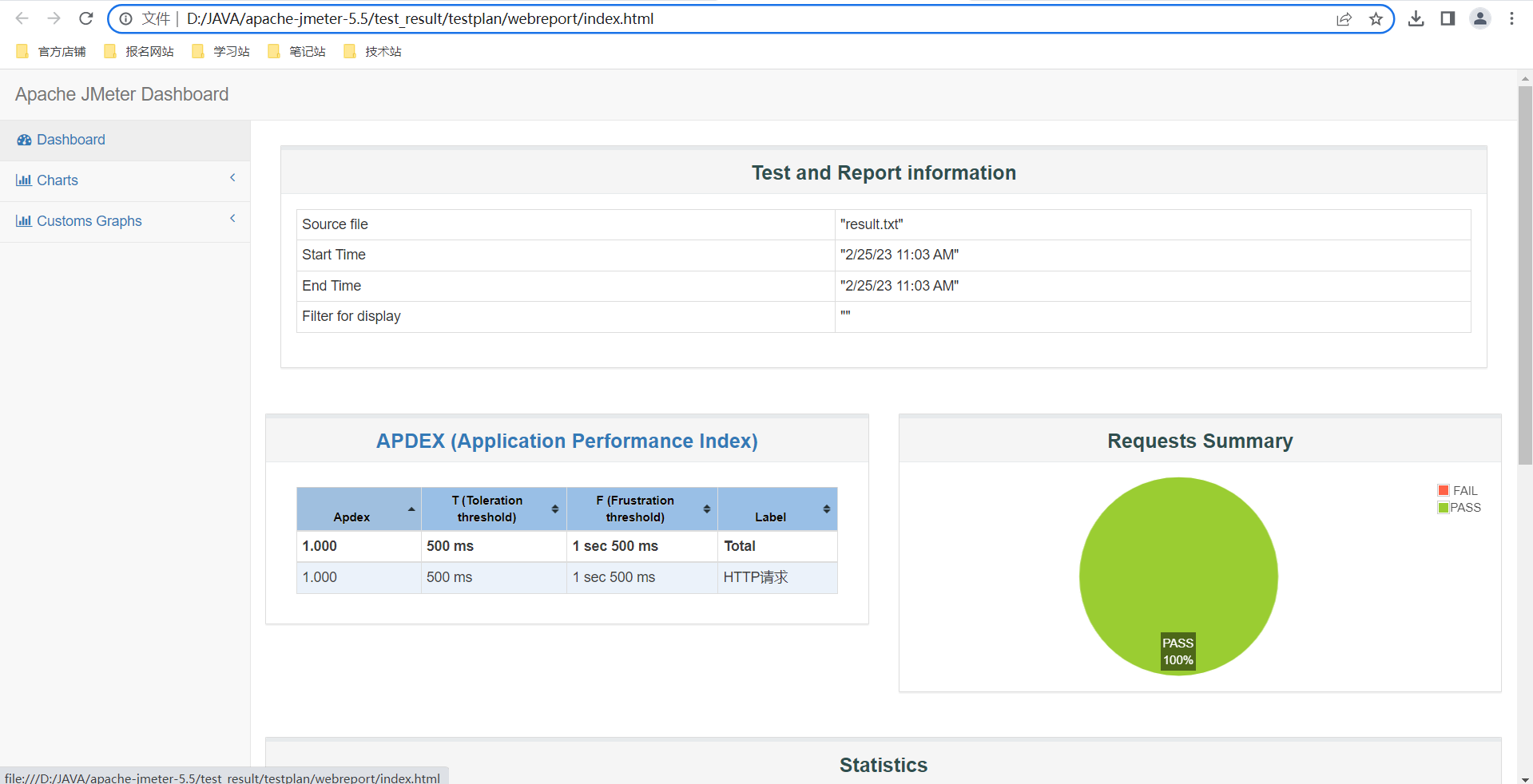
Jmeter使用教程
目录一,简介二,Jmeter安装1,下载2,安装三,创建测试1,创建线程组2,创建HTTP请求默认值3,创建HTTP请求4,添加HTTP请求头5,添加断言6,添加查看结果树…...

论文笔记|固定效应的解释和使用
DeHaan E. Using and interpreting fixed effects models[J]. Available at SSRN 3699777, 2021. 虽然固定效应在金融经济学研究中无处不在,但许多研究人员对作用的了解有限。这篇论文解释了固定效应如何消除遗漏变量偏差并影响标准误差,并讨论了使用固…...
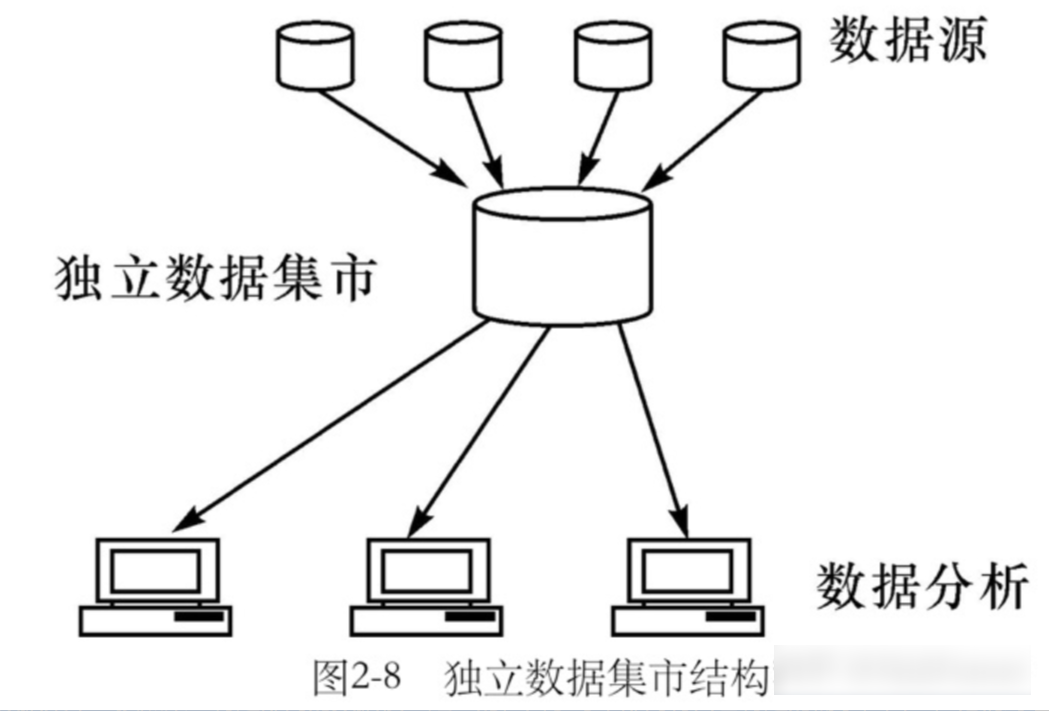
数据集市与数据仓库的区别
数据仓库是企业级的,能为整个企业各个部门的运作提供决策支持;而数据集市则是部门级的,一般只能为某个局部范围内的管理人员服务,因此也称之为部门级数据仓库。 1、两种数据集市结构 数据集市按数据的来源分为以下两种 &#x…...

Golang学习Day3
😋 大家好,我是YAy_17,是一枚爱好网安的小白。 本人水平有限,欢迎各位师傅指点,欢迎关注 😁,一起学习 💗 ,一起进步 ⭐ 。 ⭐ 此后如竟没有炬火,我便是唯一的…...
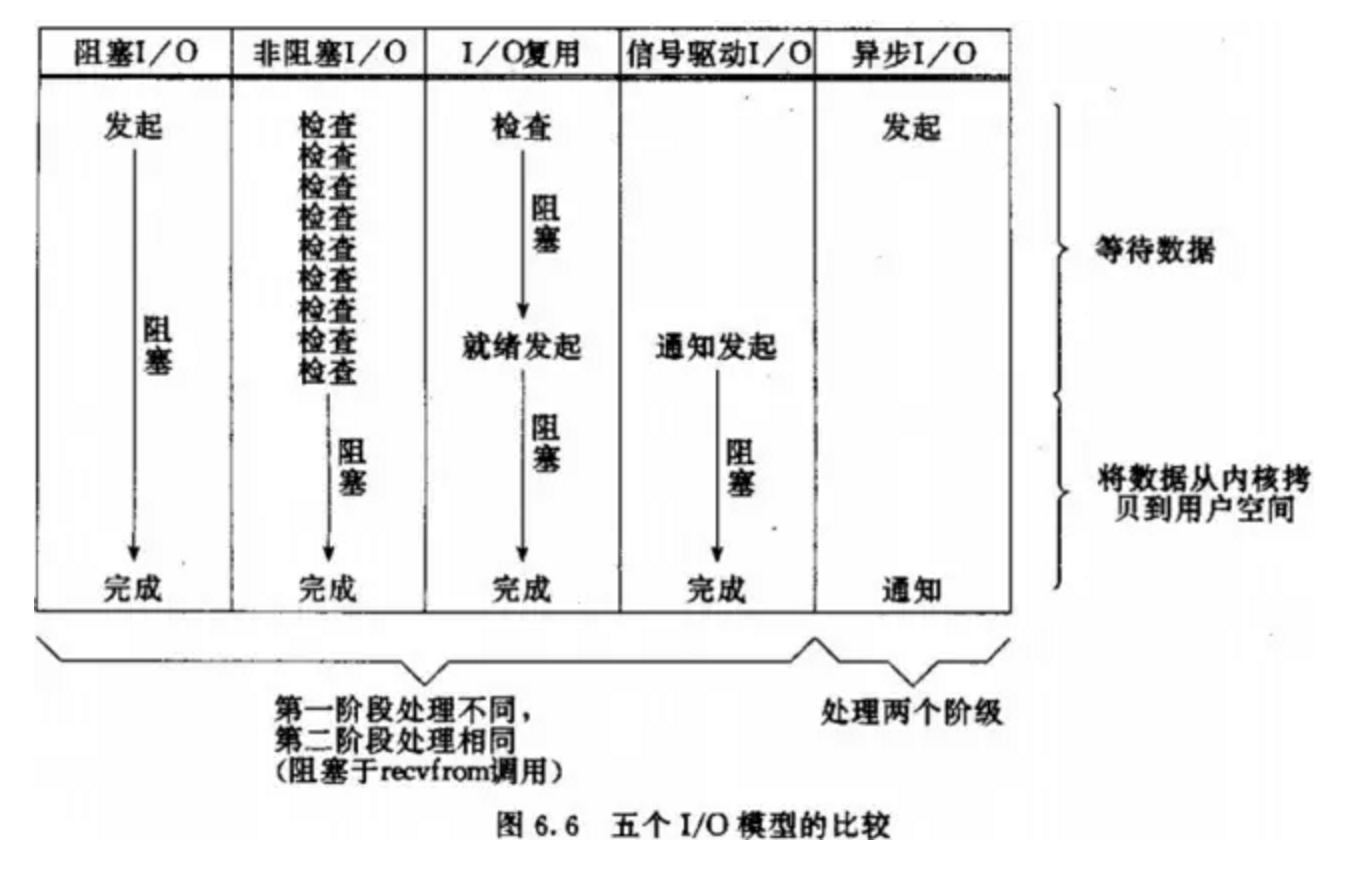
Python并发编程-事件驱动模型
一、事件驱动模型介绍 1、传统的编程模式 例如:线性模式大致流程 开始--->代码块A--->代码块B--->代码块C--->代码块D--->......---&…...
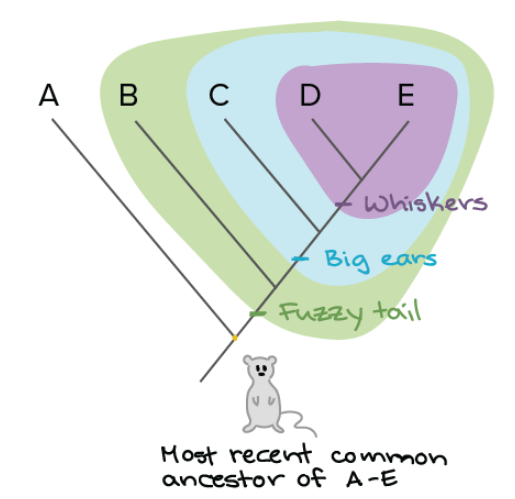
构建系统发育树简述
1. 要点 系统发育树代表了关于一组生物之间的进化关系的假设。可以使用物种或其他群体的形态学(体型)、生化、行为或分子特征来构建系统发育树。在构建树时,我们根据共享的派生特征(不同于该组祖先的特征)将物种组织成…...
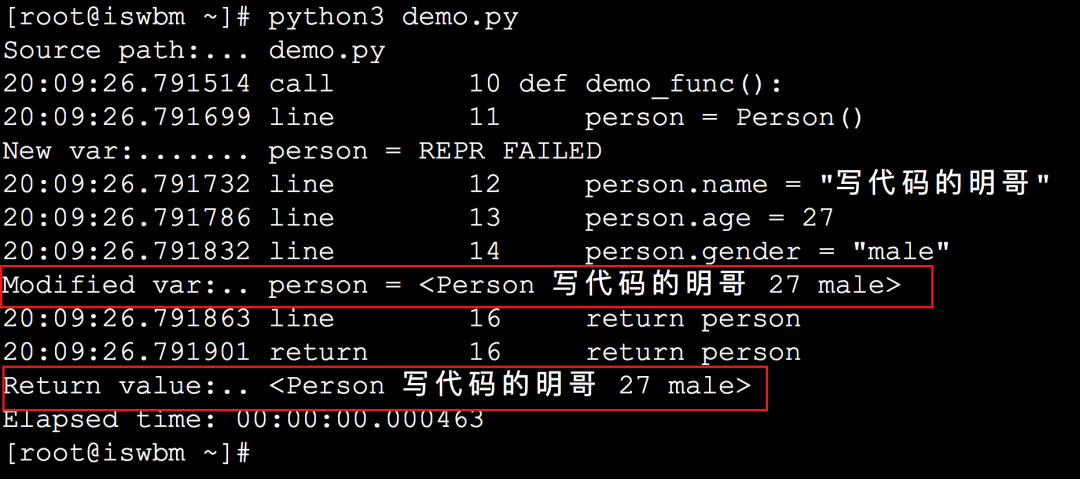
这款 Python 调试神器推荐收藏
大家好,对于每个程序开发者来说,调试几乎是必备技能。 代码写到一半卡住了,不知道这个函数执行完的返回结果是怎样的?调试一下看看 代码运行到一半报错了,什么情况?怎么跟预期的不一样?调试一…...
金三银四吃透这份微服务笔记,面试保准涨10K+
很多人对于微服务技术也都有着一些疑虑,比如: 微服务这技术虽然面试的时候总有人提,但作为一个开发,是不是和我关系不大?那不都是架构师的事吗?微服务不都是大厂在玩吗?我们这个业务体量用得着…...
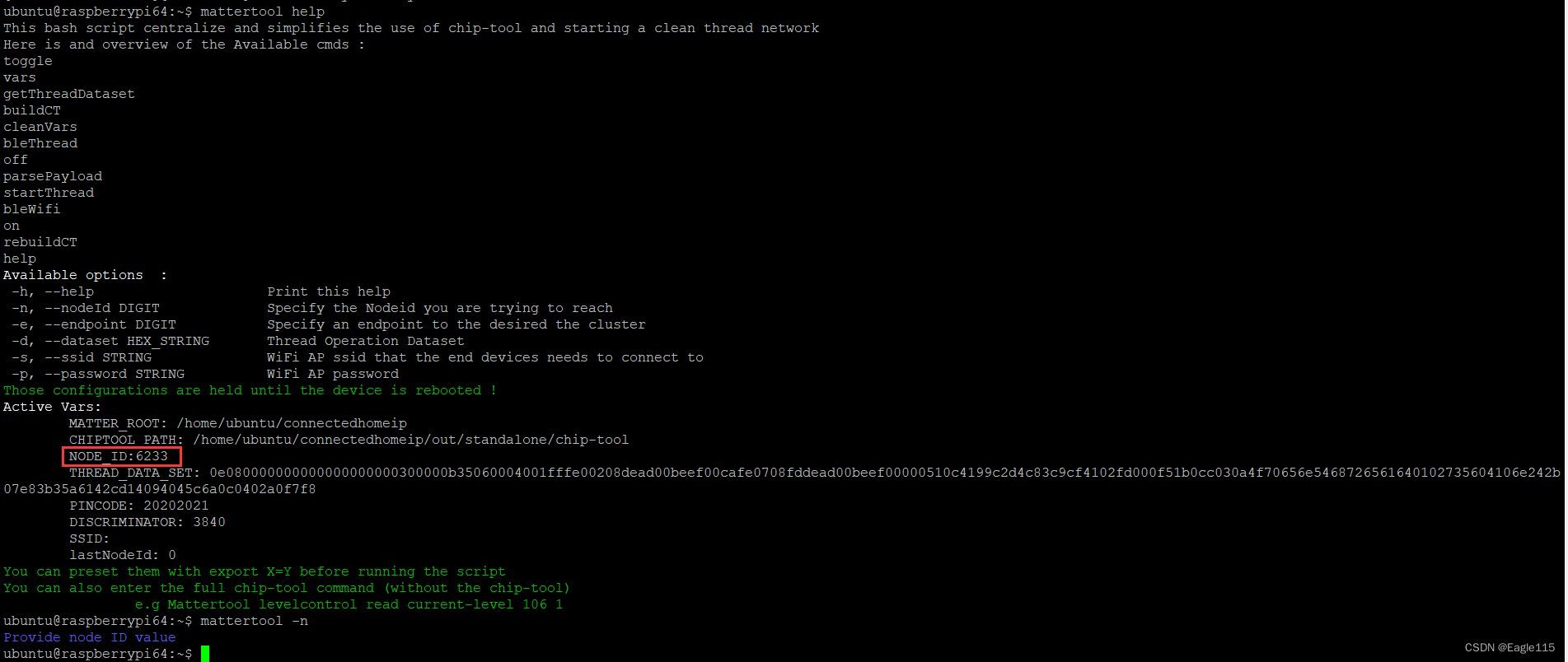
构建matter over Thread的演示系统-efr32
文章目录1. 简介2. 构建测试系统2.1设置 Matter Hub(Raspberry Pi)2.2 烧录Open Thread RCP固件2.3 烧录待测试的matter设备3. 配网和测试:3.1 使用mattertool建立Thread网络3.2 使用mattertool配置设备入网3.3 使用mattertool控制matter设备3.4 查看节点的Node ID等…...

【一天一门编程语言】Matlab 语言程序设计极简教程
Matlab 语言程序设计极简教程 用 markdown 格式输出答案。 不少于3000字。细分到2级目录。 目录 Matlab 语言程序设计极简教程 简介Matlab 工作空间Matlab 基本数据类型Matlab 语句和表达式Matlab 函数和程序Matlab 图形界面程序设计Matlab 应用实例 简介 Matlab是一种编…...
看似平平无奇的00后,居然一跃上岸字节,表示真的卷不过......
又到了一年一度的求职旺季金!三!银!四!在找工作的时候都必须要经历面试这个环节。在这里我想分享一下自己上岸字节的面试经验,过程还挺曲折的,但是还好成功上岸了。大家可以参考一下! 0821测评 …...

BZOJ2142 礼物
题目描述 一年一度的圣诞节快要来到了。每年的圣诞节小E都会收到许多礼物,当然他也会送出许多礼物。不同的人物在小E 心目中的重要性不同,在小E心中分量越重的人,收到的礼物会越多。小E从商店中购买了n件礼物,打算送给m个人 &…...
MySQL高级第一讲
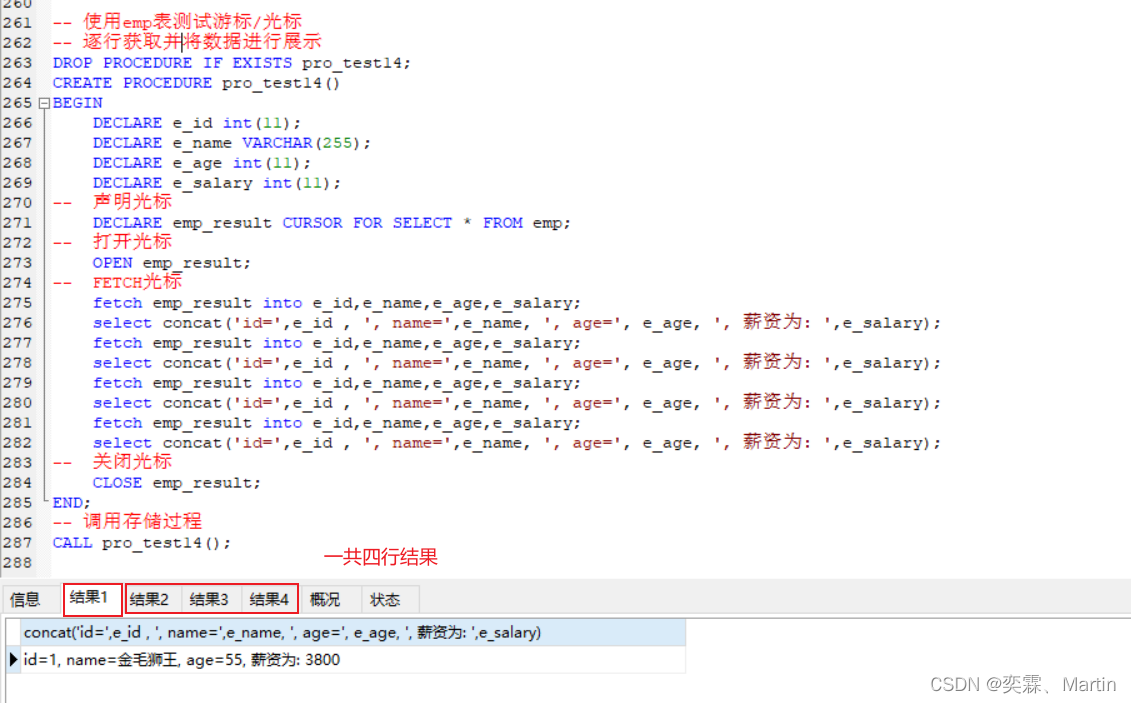
目录 一、MySQL高级01 1.1 索引 1.1.1 索引概述 1.1.2 索引特点 1.1.3 索引结构 1.1.4 BTREE结构(B树) 1.1.5 BTREE结构(B树) 1.1.6 索引分类 1.1.7 索引语法 1.1.8 索引设计原则 1.2 视图 1.2.1 视图概述 1.2.2 创建或修改视图 1.3 存储过程和函数 1.3.1 存储过…...

前端面试常用内容——基础积累
1.清除浮动的方式有哪些? 高度塌陷:当所有的子元素浮动的时候,且父元素没有设置高度,这时候父元素就会产生高度塌陷。 清除浮动的方式: 1.1 给父元素单独定义高度 优点: 快速简单,代码少 缺…...
跟着《代码随想录》刷题(三)——哈希表
3.1 哈希表理论基础 哈希表理论基础 3.2 有效的字母异位词 242.有效的字母异位词 C bool isAnagram(char * s, char * t){int array[26] {0};int i 0;while (s[i]) {// 并不需要记住字符的ASCII码,只需要求出一个相对数值就可以了array[s[i] - a];i;}i 0;whi…...
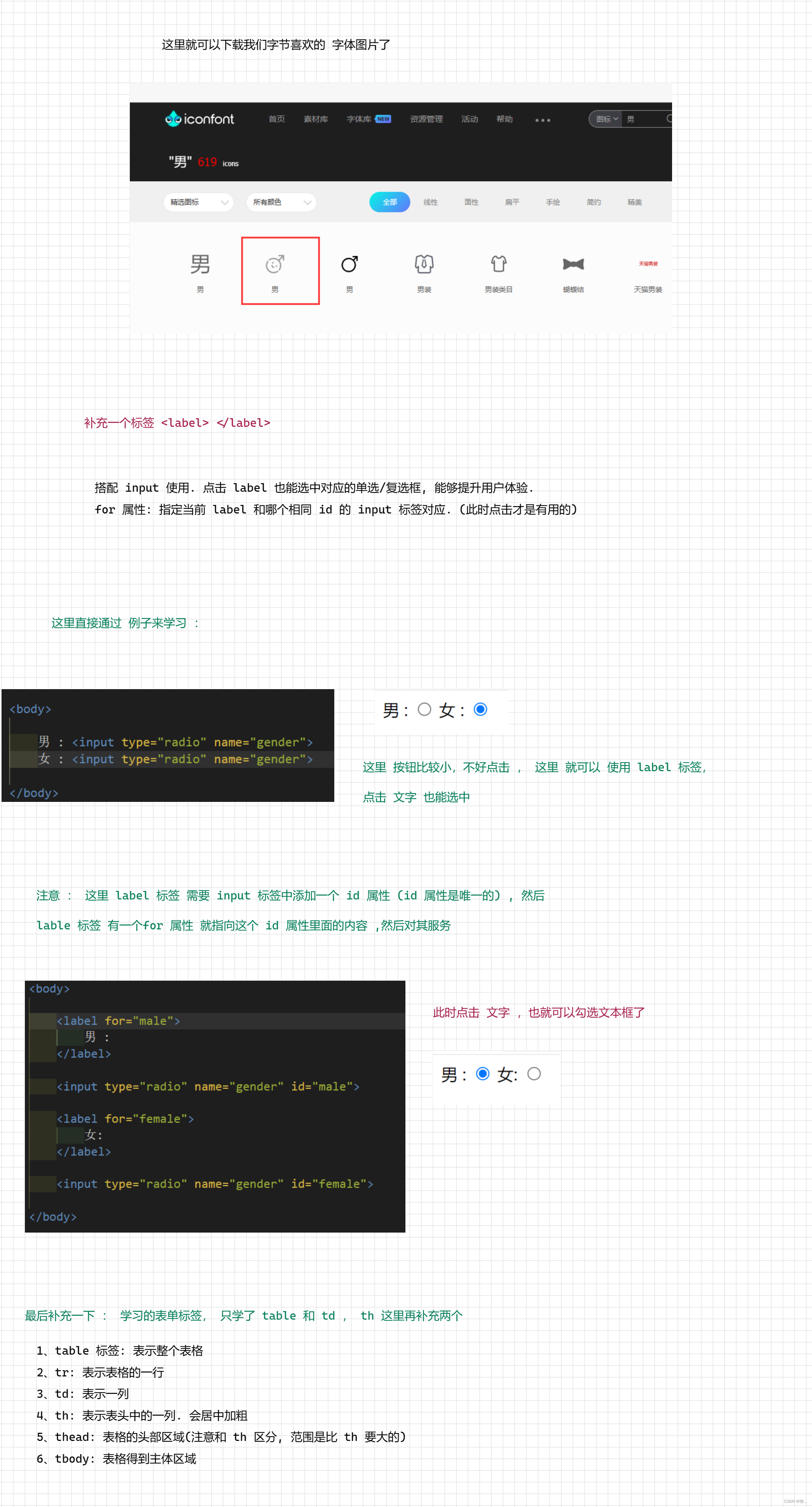
HTML - 扫盲
文章目录1. 前言2. HTML2.1 下载 vscode3 HTML 常见标签3.1 注释标签3.2 标题标签3.3 段落标签3.4 换行标签3.5 格式化标签1. 加粗2. 倾斜3. 下划线3.6 图片标签3.7 超链接标签3.8 表格标签3.9 列表标签4. 表单标签4.1 from 标签4.2 input 标签4.3 select 标签4.4 textarea标签…...

38 - Go 命令行参数处理:从 os.Args 到 flag 的底层设计
文章目录38 - Go 命令行参数处理:从 os.Args 到 flag 的底层设计为什么需要命令行参数?命令行参数的本质最基础的参数处理:os.Args基础使用示例获取单个参数flag 标准库:Go 官方参数解析器最简单的 flag 示例为什么 flag.String 返…...

SurfaceFlinger 调用 libdrm 的详细代码流程分析
1. 整体架构图 ┌─────────────────────────────────────────────────────────────────┐ │ 应用层框架 │ │ ┌──────────────…...

微信聊天记录永久保存指南:5分钟掌握WeChatMsg完整备份方案
微信聊天记录永久保存指南:5分钟掌握WeChatMsg完整备份方案 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/…...

NY382固态MT29F32T08GSLBHL8-24QM:B
NY382固态MT29F32T08GSLBHL8-24QM:B当工业设备在极端环境下稳定运行,其核心存储的每一次数据读写,都决定着生产线的效率与安全。一颗看似平凡的存储芯片,背后是无数工程师在稳定性、耐久性与环境适应性之间的精妙权衡。今天,我们聚…...

全栈开发简历:避免 “样样通样样松”,突出核心技术栈
一、开篇暴击:你的全栈简历,可能正在被HR当“笑话”看 “熟练掌握HTML、CSS、JavaScript、Python、Java、PHP、MySQL、MongoDB、AWS、Docker、K8s……” 当你在简历上敲下这串“技术彩虹屁”时,是不是觉得自己就是传说中“一人顶一个团队”的全栈大神?醒醒!某互联网公司…...

河南话TTS项目踩坑实录:为什么你的“中”字总发成“zōng”?——基于127小时方言语料的韵律建模纠偏指南
更多请点击: https://kaifayun.com 第一章:河南话TTS项目踩坑实录:为什么你的“中”字总发成“zōng”? 在构建河南方言语音合成(TTS)系统时,我们发现一个高频且顽固的问题:标准普通…...

FreeRTOS队列深度剖析:从环形缓冲区到任务阻塞,你的消息真的发对了吗?
FreeRTOS队列深度剖析:从环形缓冲区到任务阻塞,你的消息真的发对了吗? 在嵌入式实时系统中,任务间的通信机制如同城市中的交通网络,而FreeRTOS队列则是这条网络中最核心的高速公路。当你的系统从简单的单任务演变为多任…...
)
告别Excel!用Python复现地理探测器(附完整代码与示例数据)
告别Excel!用Python复现地理探测器(附完整代码与示例数据) 地理探测器作为分析空间分异性的重要工具,长期以来依赖Excel插件实现计算。但对于需要批量处理、自定义分析流程的研究者而言,这种封闭式操作存在明显局限。…...

Red Hat Enterprise Linux 10.2 和 9.8 发布,命令行 AI 辅助增强,多工具集性能升级
Red Hat Enterprise Linux (RHEL) 10.2 和 9.8 正式发布,带来增强的命令行 AI 辅助和基础架构更新,提升用户信息获取速度与工具性能。命令行 AI 辅助升级面向高级用户推出 goose 命令,它是高级可选命令行 AI 助手,连接可信 AI 后端…...

CANN 模型转换与适配:从 PyTorch 到 Ascend OM 的完整指南
模型转换是昇腾落地的第一道坎。不管你用 PyTorch、TensorFlow 还是 MindSpore,最终都要变成 Ascend 的 .om 模型才能在 NPU 上跑。 这篇文章讲清楚:模型转换的完整流程、常见问题和优化技巧。 为什么需要模型转换? 昇腾 NPU 不能直接运行 Py…...