浅谈AI大模型技术:概念、发展和应用
AI大模型技术是指使用超大规模的深度学习模型来解决各种复杂的人工智能问题,如自然语言处理、计算机视觉、多模态交互等。AI大模型技术具有强大的学习能力和泛化能力,可以在多种任务上取得优异的性能,但也面临着计算、存储、通信等方面的挑战。
本文将从以下五个方面浅谈AI大模型技术的概念、发展和应用:
-
AI大模型技术的起源和发展历程
-
AI大模型技术的特点
-
AI大模型技术的构建和训练方法
-
AI大模型技术的基础资源和关键技术
-
AI大模型技术的应用领域和探索方向
01
—
AI大模型技术的起源和发展历程
AI大模型技术的起源可以追溯到深度学习的兴起。深度学习是一种基于多层神经网络的机器学习方法,可以从海量数据中自动学习特征和规律,实现对复杂数据的建模和理解。深度学习在2006年由Hinton等人提出,并在2012年由Krizhevsky等人在ImageNet图像识别竞赛中取得突破性的成果,引发了人工智能领域的热潮。
随着深度学习的发展,人们发现神经网络的规模和性能有着密切的关系。一般来说,神经网络的规模越大,即参数数量越多,表示能力越强,性能越好。因此,人们开始尝试构建更大规模的神经网络,并使用更多的数据来训练它们。这就催生了AI大模型技术。
AI大模型技术最早出现在自然语言处理领域。自然语言处理是指让计算机理解和生成自然语言(如中文、英文等)的技术,涉及到语音识别、机器翻译、文本分类、情感分析、对话系统等多种任务。自然语言处理面临着两个主要的挑战:一是自然语言本身具有复杂的结构和语义,难以用简单的规则或统计方法来描述;二是不同任务之间存在差异和联系,难以用单一的模型来适应。
为了解决这些挑战,人们提出了预训练语言模型(Pre-trained Language Model, PLM)的概念。预训练语言模型是指使用无标注或少标注的大规模文本语料来训练一个通用的语言表示模型,然后将该模型迁移到不同的下游任务上,并通过微调(Fine-tuning)或其他方法来适应具体任务。预训练语言模型可以有效地利用海量数据中蕴含的语言知识,并提高不同任务之间的迁移学习能力。
预训练语言模型最早由Collobert等人于2008年提出,并在2013年由Mikolov等人进一步发展。这些早期的预训练语言模型主要基于词向量(Word Embedding)的方法,即将每个词映射为一个固定长度的实数向量,以表示词的语义信息。然而,这些方法存在一些局限性,如无法处理一词多义、上下文相关等现象,以及无法捕获句子或文档级别的信息。
为了克服这些局限性,人们开始尝试使用更复杂的神经网络结构来构建预训练语言模型,如循环神经网络(Recurrent Neural Network, RNN)、长短期记忆网络(Long Short-Term Memory, LSTM)、门控循环单元(Gated Recurrent Unit, GRU)等。这些网络可以处理变长的序列输入,并具有记忆和注意力机制,可以更好地建模语言的时序和上下文信息。代表性的工作有ELMo、ULMFiT等。
然而,这些基于循环神经网络的预训练语言模型仍然存在一些问题,如无法并行计算、难以捕获长距离依赖、难以扩展到大规模数据和模型等。为了解决这些问题,人们开始使用基于自注意力机制(Self-Attention)的Transformer结构来构建预训练语言模型。Transformer是一种全新的神经网络结构,它摒弃了循环神经网络中的递归操作,而是使用自注意力机制来建模序列中任意两个位置之间的关系。Transformer具有以下优点:一是可以并行计算,提高训练效率;二是可以捕获长距离依赖,提高表示能力;三是可以扩展到大规模数据和模型,提高泛化能力。
基于Transformer结构的预训练语言模型开启了AI大模型技术的新篇章。2018年,OpenAI推出了GPT,这是第一个基于Transformer结构的预训练语言模型,它使用了1.1亿个参数,并在12种自然语言处理任务上取得了当时最好的结果。同年,Google推出了BERT,这是第一个使用双向Transformer结构的预训练语言模型,它使用了3.4亿个参数,并在11种自然语言处理任务上刷新了记录。此后,各大科研机构和公司纷纷推出了各自的预训练语言模型,如XLNet、RoBERTa、ALBERT、ELECTRA等,不断提升模型的规模和性能。
2020年,OpenAI推出了GPT-3,这是目前最大规模的预训练语言模型之一,它使用了1750亿个参数,并在多种自然语言处理任务上取得了惊人的效果。GPT-3引发了全球范围内对AI大模型技术的关注和讨论,也催生了许多基于GPT-3的应用和创新。例如,有人利用GPT-3生成了诗歌、歌词、代码、故事、对话等内容;有人利用GPT-3实现了问答、摘要、翻译、分类等功能;有人利用GPT-3探索了教育、医疗、金融、法律等领域的可能性。
2023年3月14日,ChatGPT的开发机构OpenAI正式发布其里程碑之作GPT-4。GPT-4是一个多模态大模型(接受图像和文本输入,生成文本)。相比上一代的GPT-3,GPT-4可以更准确地解决难题,具有更广泛的常识和解决问题的能力:更具创造性和协作性;能够处理超过25000个单词的文本,允许长文内容创建、扩展对话以及文档搜索和分析等用例。
除了自然语言处理领域外,AI大模型技术也开始在计算机视觉、多模态交互等领域发挥作用。计算机视觉是指让计算机理解和生成图像和视频的技术,涉及到人脸识别、目标检测、图像分割、风格迁移、视频理解等多种任务。多模态交互是指让计算机同时处理和融合不同类型的信息,如图像、文本、语音、音乐等,实现更自然和智能的人机交互。
在计算机视觉领域,AI大模型技术主要体现在两个方面:一是使用大规模的图像数据来训练一个通用的视觉表示模型,然后将该模型迁移到不同的下游任务上,并通过微调或其他方法来适应具体任务。二是使用大规模的图像和文本数据来训练一个跨模态的视觉-语言表示模型,然后将该模型用于生成或理解图像和文本之间的关系。这些AI大模型技术可以有效地提高计算机视觉的性能和泛化能力,同时也为多模态交互提供了基础。
在多模态交互领域,AI大模型技术主要体现在三个方面:一是使用大规模的多模态数据来训练一个统一的多模态表示模型,然后将该模型用于理解或生成不同类型的信息。二是使用大规模的语言数据来训练一个强大的语言生成模型,然后将该模型用于控制或指导不同类型的信息的生成 。三是使用大规模的强化学习数据来训练一个智能的多模态智能体,然后将该智能体用于与人类进行自然和智能的对话或协作 。这些AI大模型技术可以有效地提高多模态交互的效率和质量,同时也为通用人工智能提供了可能。
02
—
AI大模型技术的特点
AI大模型技术是一种利用海量数据和强大算力训练出具有高度泛化和通用能力的人工智能模型的技术。AI大模型技术有以下几个特点:
-
它使用了预训练和微调的方法,即先在大规模的通用数据上进行预训练,再根据不同的下游任务进行微调,提高了模型的泛用性和适应性。
-
它采用了自监督学习的方式,即利用无标注或少标注的数据进行训练,降低了数据标注的成本和难度。
-
它突破了传统的神经网络结构,使用了Transformer模型作为特征提取器,利用自注意力机制捕捉输入数据中不同部分之间的相关性,提高了模型的精度和效率。
-
它具有突现能力(Emergent Ability),即能够从数据中学习到一些隐含的知识和规则,实现类似人类的复杂推理和知识推导能力。
03
—
AI大模型技术的构建和训练方法
AI大模型技术的构建和训练需要解决计算、存储、通信等方面的挑战,以及提高模型的效率、质量和可扩展性。AI大模型技术的构建和训练方法主要包括以下几个方面:
-
分布式训练:这是一种利用多个计算设备(如GPU、TPU等)来并行地训练一个大模型的方法,可以加速训练过程,同时也可以容纳更大规模的模型和数据。分布式训练有多种方式,如数据并行、模型并行、流水线并行等,它们各有优缺点,需要根据具体的场景和需求来选择合适的方式。
-
内存节省:这是一种减少训练过程中内存消耗的方法,可以提高训练效率,同时也可以降低训练成本。内存节省有多种技术,如激活重计算、混合精度训练、零冗余优化器等,它们各有原理和适用范围,需要根据具体的模型和硬件来选择合适的技术。
-
模型稀疏:这是一种减少模型参数数量和复杂度的方法,可以提高模型性能,同时也可以降低推理成本。模型稀疏有多种技术,如剪枝、量化、低秩分解等,它们各有目标和效果,需要根据具体的任务和指标来选择合适的技术。
04
—
AI大模型技术的基础资源和关键技术
AI大模型技术的应用和发展需要依赖于一些基础的数据、知识、计算系统、推理能力等资源,同时也需要解决一些可解释性、安全性、治理、评测等方面的问题。
AI大模型技术的基础资源和关键技术主要包括以下几个方面:
-
数据:这是AI大模型技术的核心资源,也是训练和应用大模型的前提条件。数据的质量、规模、多样性、可用性等都会影响大模型的效果和价值。因此,需要构建高质量、高覆盖、高效率的数据生态,包括数据采集、清洗、标注、存储、共享等环节,以及数据隐私保护、数据安全管理等措施。
-
知识:这是AI大模型技术的重要资源,也是提升大模型能力和泛化性的关键因素。知识可以帮助大模型理解数据背后的逻辑和规律,以及不同领域和场景的特点和需求。因此,需要构建丰富、准确、动态的知识体系,包括知识图谱、知识库、本体库等形式,以及知识获取、表示、融合、推理等技术。
-
计算系统:这是AI大模型技术的基础设施,也是支撑大模型训练和应用的硬件平台。计算系统需要具备高性能、高可靠、高可扩展等特点,以满足大模型对计算资源和效率的需求。因此,需要构建先进、灵活、智能的计算系统,包括芯片、服务器、集群等设备,以及操作系统、编程框架、调度系统等软件。
-
推理能力:这是AI大模型技术的核心能力,也是实现大模型应用和创新的主要手段。推理能力可以帮助大模型根据输入数据和任务目标生成合理和有效的输出结果,以及解释和评估输出结果的过程和依据。因此,需要构建强大、灵活、智能的推理能力,包括生成式推理、逻辑推理、常识推理等类型,以及推理优化、推理加速、推理验证等技术。
-
可解释性:这是AI大模型技术的重要特性,也是提高大模型可信度和可接受度的必要条件。可解释性可以帮助大模型向用户或开发者展示其内部结构和工作原理,以及输出结果的依据和意义。因此,需要构建有效、直观、友好的可解释性方法,包括可视化分析、注意力机制分析、对比实验分析等方式,以及可解释性评估、可解释性改进等策略。
-
安全性:这是AI大模型技术的关键特性,也是保障大模型正常运行和避免风险的必要条件。安全性可以帮助大模型防止或抵御各种可能造成损害或威胁的因素,如数据泄露、模型攻击、模型偏差等。因此,需要构建严格、全面、动态的安全性机制,包括数据加密、模型加密、模型防御、模型校准等措施,以及安全性监测、安全性修复等技术。
-
治理:这是AI大模型技术的重要环节,也是规范大模型行为和责任的必要手段。治理可以帮助大模型遵守一些法律、伦理、社会等方面的规则和原则,以及明确大模型的权利和义务。因此,需要构建合理、公正、透明的治理框架,包括治理目标、治理主体、治理流程、治理机制等要素,以及治理评估、治理改进等方法。
-
评测:这是AI大模型技术的重要环节,也是衡量大模型效果和价值的必要手段。评测可以帮助大模型检验其在不同任务和场景下的表现和水平,以及与其他模型或方法的优劣和差异。因此,需要构建科学、客观、多维的评测体系,包括评测数据集、评测指标、评测方法、评测平台等组成,以及评测分析、评测反馈等功能。
05
—
AI大模型技术的应用领域和探索方向
AI大模型技术已经在多个领域展现出了强大的潜力和价值,同时也面临着一些新的机遇和挑战。
AI大模型技术的应用领域和探索方向主要包括以下几个方面:
-
知识搜索:这是一种利用AI大模型技术来提供更智能、更全面、更准确的信息检索和问答服务的应用领域,可以帮助用户快速地获取所需的知识和答案。知识搜索有多种形式,如语义搜索、对话搜索、图像搜索、视频搜索等,它们可以根据用户的输入和意图,从海量的数据源中检索出最相关的信息,并以友好的方式呈现给用户。知识搜索的典型应用有百度智能云的文心一言、阿里达摩院的PLUG、微软必应的ChatGPT等。
-
城市运维:这是一种利用AI大模型技术来提升城市管理和服务水平的应用领域,可以帮助城市实现智慧化、数字化、可持续化的发展。城市运维涉及到多个方面,如交通管理、环境监测、公共安全、社会治理等,它们需要处理和分析大量的多模态数据,如图像、视频、语音、文本等,并根据不同的场景和需求,提供合适的决策和响应。城市运维的典型应用有商汤科技的书生(INTERN)、华为云的盘古NLP、浪潮信息的源1.0等。
-
广告营销:这是一种利用AI大模型技术来优化广告投放和提升营销效果的应用领域,可以帮助广告主和营销人员更好地理解用户需求和行为,以及创造更有吸引力和影响力的广告内容。广告营销需要利用大量的用户数据和行业数据,如用户画像、用户行为、市场趋势等,并根据不同的目标和策略,生成或推荐最合适的广告素材、广告渠道、广告时机等。广告营销的典型应用有创新奇智的Diffusion、第四范式的4Paradigm、腾讯AI Lab的Tencent AI Lab等。
-
智能客服:AI大模型可以实现自然语言理解、对话管理、情感分析、文本生成等功能,提高客户满意度和服务效率。
-
智能家居:AI大模型可以实现语音识别、语音合成、语义理解、多轮对话等功能,实现与用户的自然交互和智能控制。
-
自动驾驶:AI大模型可以实现图像识别、目标检测、场景分割、路径规划等功能,提高驾驶安全性和舒适性。
AI大模型技术是人工智能领域的一种重要的技术趋势,它利用海量数据和强大计算资源来构建超大规模的深度学习模型,从而实现对复杂数据和问题的建模和解决。AI大模型技术已经在自然语言处理、计算机视觉、多模态交互等领域取得了显著的进展和成果,同时也引发了一系列新的挑战和问题,如数据质量、计算效率、知识可解释性、安全可靠性等。因此,AI大模型技术需要不断地创新和完善,以适应不断变化和增长的人工智能需求。

相关文章:
浅谈AI大模型技术:概念、发展和应用
AI大模型技术是指使用超大规模的深度学习模型来解决各种复杂的人工智能问题,如自然语言处理、计算机视觉、多模态交互等。AI大模型技术具有强大的学习能力和泛化能力,可以在多种任务上取得优异的性能,但也面临着计算、存储、通信等方面的挑战…...
【Leetcode】212.单词搜索II(Hard)
一、题目 1、题目描述 给定一个 m x n 二维字符网格 board 和一个单词(字符串)列表 words, 返回所有二维网格上的单词 。 单词必须按照字母顺序,通过 相邻的单元格 内的字母构成,其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母在一个单词中…...

146.LRU缓存
双向链表哈希表 class LRUCache { public://1、定义双向链表结构、容量、哈希表等LRU数据成员struct Node{int key,value;Node *left,*right;Node(int _key,int _value):key(_key),value(_value),left(NULL),right(NULL){}}*L,*R;int n;unordered_map<int,Node*> ump;//…...
使用transformers过程中出现的bug
1. The following model_kwargs are not used by the model: [encoder_hidden_states, encoder_attention_mask] (note: typos in the generate arguments will also show up in this list) 使用text_decoder就出现上述错误,这是由于transformers版本不兼容导致的 …...
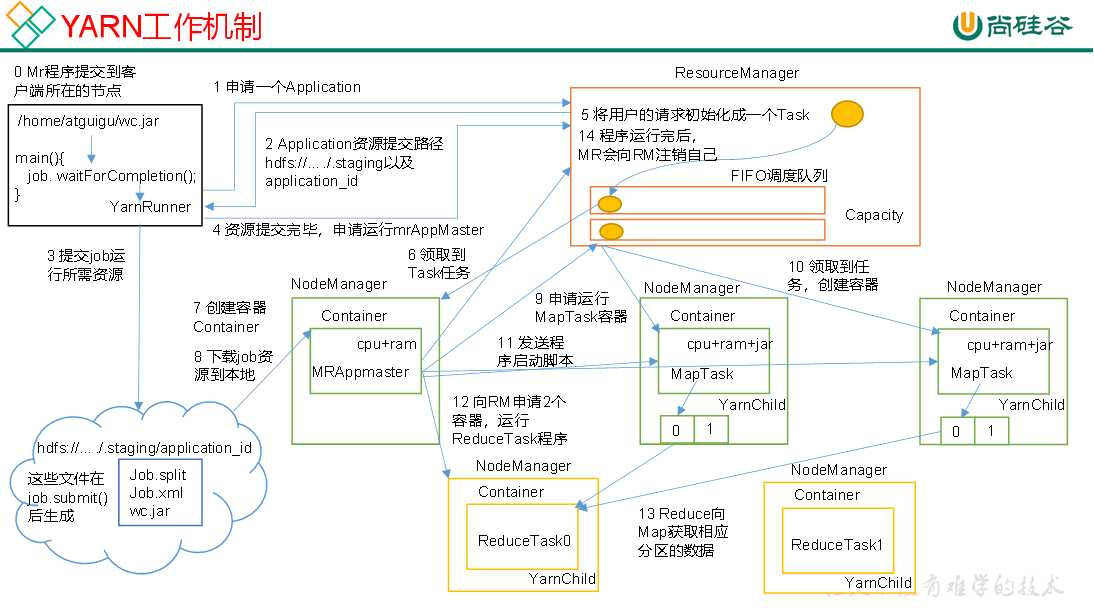
Hadoop3教程(二十二):Yarn的基础架构与工作流程
文章目录 (126)基础架构(127)YARN的工作机制(128)作业全流程参考文献 (126)基础架构 之前基本介绍完了Hadoop的几个核心组件,接下来可以思考下,在MR程序运行…...
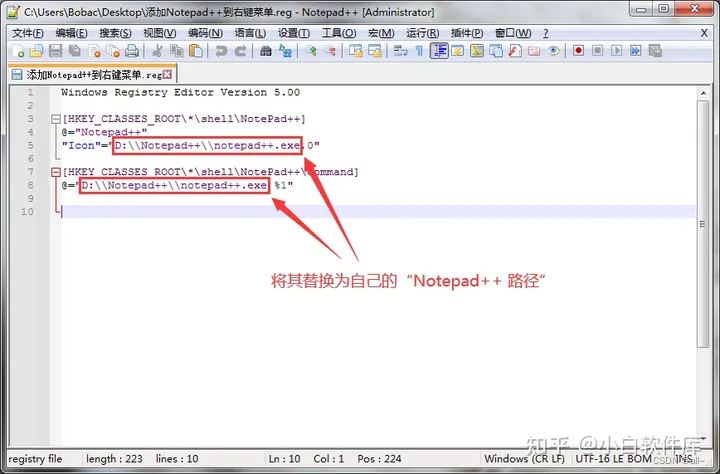
离线 notepad++ 添加到右键菜单
复制下面代码,修改文件后缀名为:reg Windows Registry Editor Version 5.00[HKEY_CLASSES_ROOT\*\shell\NotePad] "Notepad" "Icon""D:\\Notepad\\notepad.exe,0"[HKEY_CLASSES_ROOT\*\shell\NotePad\Command] "D:\…...

怎么让英文大语言模型支持中文?--构建中文tokenization--继续预训练--指令微调
1 构建中文tokenization 参考链接:https://zhuanlan.zhihu.com/p/639144223 1.1 为什么需要 构建中文tokenization? 原始的llama模型对中文的支持不太友好,接下来本文将讲解如何去扩充vocab里面的词以对中文进行token化。 1.2 如何对 原始数…...
)
笙默考试管理系统-MyExamTest----codemirror(35)
笙默考试管理系统-MyExamTest----codemirror(35) 目录 一、 笙默考试管理系统-MyExamTest 二、 笙默考试管理系统-MyExamTest 三、 笙默考试管理系统-MyExamTest 四、 笙默考试管理系统-MyExamTest 五、 笙默考试管理系统-MyExamTest 笙默考试…...
)
MMKV(2)
API 初始化和实例获取: MMKV.initialize(Context context): 初始化MMKV库。通常在应用程序的入口点调用此方法。 MMKV.defaultMMKV(): 获取默认的MMKV实例。默认实例使用默认的存储路径和加密方式。 MMKV.mmkvWithID(String mmapID): 根据给定的ID获取MMKV实例。…...
Spring Boot项目中使用 TrueLicense 生成和验证License(附源码)
1、Linux 在客户linux上新建layman目录,导入license.sh文件, [rootlocalhost layman]# mkdir -p /laymanlicense.sh文件内容: #!/bin/bash # 1.获取要监控的本地服务器IP地址 IPifconfig | grep inet | grep -vE inet6|127.0.0.1 | awk {p…...

ES6 Iterator 和 for...of 循环
1.iterator 概念 ES6 添加了Map和Set。这样就有了四种数据集合,需要一种统一的接口机制来处理所有不同的数据结构。遍历器(Iterator)就是这样一种机制。它是一种接口,为各种不同的数据结构提供统一的访问机制。任何数据结构只要部…...
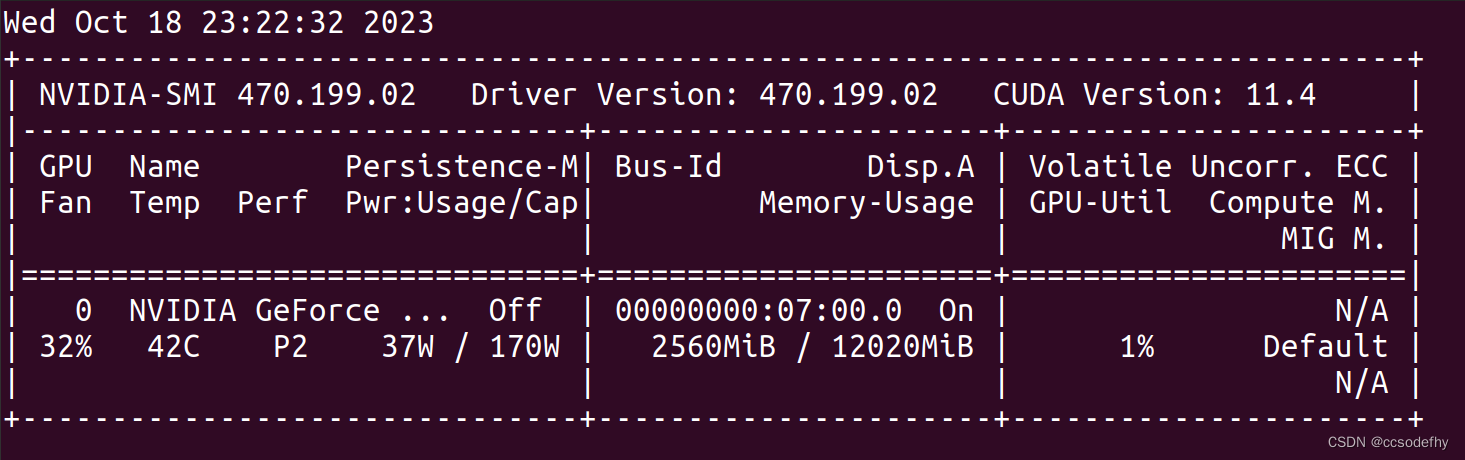
ubuntu20.04 nvidia显卡驱动掉了,变成开源驱动,在软件与更新里选择专有驱动,下载出错,调整ubuntu镜像源之后成功修复
驱动配置好,环境隔了一段时间,打开Ubuntu发现装好的驱动又掉了,软件与更新 那里,附加驱动,显示开源驱动,命令行输入 nvidia-smi 命令查找不到驱动。 点击上面的 nvidia-driver-470(专有&#x…...

华为FAT模式无线AP配置实例
硬件:AP3010DN 软件版本:VRP software, Version 5.170 (AP3010DN-V2 FAT V200R010C00SPCf02) [Huawei]dis ver Huawei Versatile Routing Platform Software VRP (R) software, Version 5.170 (AP3010DN-V2 FAT V200R010C00SPCf02) Copyright (C) 2011…...
nodejs基于vue 学生论坛设计与实现
随着网络技术的不断成熟,带动了学生论坛,它彻底改变了过去传统的管理方式,不仅使服务管理难度变低了,还提升了管理的灵活性。 是本系统的开发平台 系统中管理员主要是为了安全有效地存储和管理各类信息, 这种个性化的平…...

017 基于Spring Boot的食堂管理系统
部分代码地址: https://github.com/XinChennn/xc017-stglxt 基于Spring Boot的食堂管理系统 项目介绍 本项目是基于Java的管理系统。采用前后端分离开发。前端基于bootstrap框架实现,后端使用Java语言开发,技术栈包括但不限于SpringBoot、…...
-C++)
常用的二十种设计模式(下)-C++
设计模式 C中常用的设计模式有很多,设计模式是解决常见问题的经过验证的最佳实践。以下是一些常用的设计模式: 单例模式(Singleton):确保一个类只有一个实例,并提供一个全局访问点。工厂模式(…...
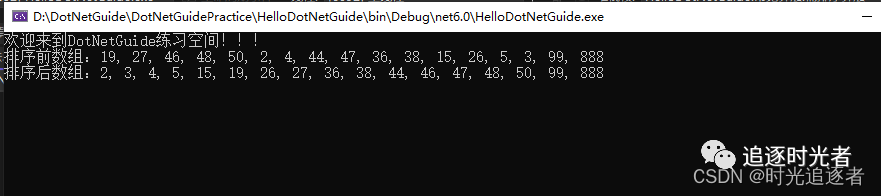
C#桶排序算法
前言 桶排序是一种线性时间复杂度的排序算法,它将待排序的数据分到有限数量的桶中,每个桶再进行单独排序,最后将所有桶中的数据按顺序依次取出,即可得到排序结果。 实现原理 首先根据待排序数据,确定需要的桶的数量。…...
快速了解服务器单CPU与双CPU
在当今快节奏的技术环境中,用户们对功能强大且高效的服务器配置需求不断增长。CPU作为构成任何计算基础设施的骨干,服务器的“大脑”,负责执行计算、控制数据流并协调各个组件之间的任务,是服务器选择硬件中的重要一环。因此…...

c# Dictionary、ConcurrentDictionary的使用
Dictionary Dictionary 用于存储键-值对的集合。如果需要高效地存储键-值对并快速查找,请使用 Dictionary。 注意,键必须是唯一的,值可以重复。 using System; using System.Collections.Generic; using System.Linq;class Program {stati…...
大数据中间件——Kafka
Kafka安装配置 首先我们把kafka的安装包上传到虚拟机中: 解压到对应的目录并修改对应的文件名: 首先我们来到kafka的config目录,我们第一个要修改的文件就是server.properties文件,修改内容如下: # Licensed to the …...

知识更新的未来:AI原生应用如何实现自我进化?
知识更新的未来:AI原生应用如何实现自我进化? 关键词:知识更新、AI原生应用、自我进化、机器学习、数据驱动 摘要:本文深入探讨了在知识快速更新的未来,AI原生应用实现自我进化的相关内容。从核心概念的解释到实现自我进化的算法原理、数学模型,再到项目实战、实际应用场…...

新手避坑指南:安捷伦/是德示波器探头选1MΩ还是50Ω?实测对比告诉你差别有多大
示波器探头阻抗选择实战手册:1MΩ与50Ω的黄金法则 第一次接触示波器时,我犯了个低级错误——用1MΩ探头直接测量射频电路,结果不仅波形畸变成锯齿状,还差点烧毁前端放大器。这个价值3000元的教训让我深刻认识到:探头…...

TNTSearch 实战案例:构建电商产品搜索系统的完整流程
TNTSearch 实战案例:构建电商产品搜索系统的完整流程 【免费下载链接】tntsearch A fully featured full text search engine written in PHP 项目地址: https://gitcode.com/gh_mirrors/tn/tntsearch TNTSearch 是一个功能强大的 PHP 全文搜索引擎ÿ…...

RISC-V开发工具链技术解析与选型指南
1. RISC-V开发工具链技术解析1.1 RISC-V生态发展背景随着处理器架构领域对开放性和灵活性的需求增长,RISC-V指令集架构凭借其开源特性获得了广泛关注。与传统架构相比,RISC-V免除了授权费用,降低了开发门槛,这使得芯片厂商和工具链…...

Attention Unet vs Unet++:在Camvid数据集上的性能对比实验
Attention Unet与Unet在Camvid数据集上的深度性能评测 语义分割作为计算机视觉领域的核心任务之一,其模型架构的创新从未停止。在众多改进方案中,Attention机制与嵌套跳跃连接(Nested Skip Connection)分别代表了两种不同的优化思…...

3大核心技术解析:猫抓cat-catch如何实现浏览器媒体资源精准捕获
3大核心技术解析:猫抓cat-catch如何实现浏览器媒体资源精准捕获 【免费下载链接】cat-catch 猫抓 chrome资源嗅探扩展 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 猫抓cat-catch是一款专为技术爱好者和开发者设计的浏览器扩展工具…...

Duix.Avatar:30分钟免费创建你的专属AI数字人,本地部署零成本
Duix.Avatar:30分钟免费创建你的专属AI数字人,本地部署零成本 【免费下载链接】Duix-Avatar 项目地址: https://gitcode.com/GitHub_Trending/he/Duix-Avatar 你是否曾梦想拥有一个能为你24小时工作的数字分身?是否因商业数字人服务动…...

STM32F103RCT6小车调试实录:搞定TCRT5000循迹与TB6612FNG调速的5个常见坑
STM32F103RCT6小车调试实战:从TCRT5000循迹到TB6612FNG调速的深度排错指南 实验室里,当你看着自己组装的STM32智能小车在黑色轨迹线上歪歪扭扭地行驶,或是电机转速时快时慢不受控制时,那种挫败感我太熟悉了。这不是一篇教你如何从…...

Kubernetes资源监控与告警:从指标到行动的完整闭环
Kubernetes资源监控与告警:从指标到行动的完整闭环没有监控的集群就是黑盒,没有告警的监控就是摆设。监控体系架构 一个完整的K8s监控体系包含三个层次: ┌────────────────────────────────────────…...

手机号定位终极指南:3分钟掌握号码背后的位置秘密
手机号定位终极指南:3分钟掌握号码背后的位置秘密 【免费下载链接】location-to-phone-number This a project to search a location of a specified phone number, and locate the map to the phone number location. 项目地址: https://gitcode.com/gh_mirrors/…...