数据挖掘十大算法--Apriori算法
一、Apriori 算法概述
Apriori 算法是一种用于关联规则挖掘的经典算法。它用于在大规模数据集中发现频繁项集,进而生成关联规则。关联规则揭示了数据集中项之间的关联关系,常被用于市场篮分析、推荐系统等应用。
以下是 Apriori 算法的基本概述:
-
频繁项集:
- 项集(Itemset):项集是数据集中的一个或多个项(item)的集合。项可以是任何可以在数据集中唯一标识的元素,例如购物篮中的商品。
- 支持度(Support):一个项集的支持度是指包含该项集的事务的数量。支持度用来衡量一个项集在数据集中的普遍程度。
- 频繁项集:一个项集的支持度超过了预定义的阈值,就被称为频繁项集。
-
Apriori 原理:
- Apriori 原理是一种先验性质,它指出如果一个项集是频繁的,那么它的所有子集也是频繁的。反之,如果一个项集是非频繁的,那么它的所有超集也是非频繁的。这一性质有助于减小搜索空间,提高算法效率。
-
算法流程:
- 生成候选项集:从单个项开始,逐渐生成包含更多项的候选项集。在每一步,通过使用 Apriori 原理剪枝,去除不可能是频繁项集的候选项集。
- 计算支持度:对生成的候选项集进行扫描,计算每个候选项集的支持度。
- 生成频繁项集:保留支持度超过预定义阈值的候选项集作为频繁项集。
- 生成关联规则:根据频繁项集生成关联规则,并计算规则的置信度。
-
关联规则:
- 支持度(Support):规则的支持度是指包含规则中所有项的事务的数量。
- 置信度(Confidence):规则的置信度是指在包含规则中的项的事务中,同时包含规则右侧项的事务的比例。
Apriori 算法的主要优点是它相对简单,并且易于理解和实现。然而,在处理大规模数据集时,它可能面临性能挑战。后续的改进算法,如 FP-Growth 等,通过不同的方式优化了频繁项集的发现过程,提高了算法的效率。
二、问题的引入
购物篮分析:引发性例子
Question:哪组商品顾客可能会在一次购物时同时购买?
关联分析
Solutions:
1:经常同时购买的商品可以摆近一点,以便进一步刺激这些商品一起销售。
2:规划哪些附属商品可以降价销售,以便刺激主体商品的捆绑销售。
三、关联分析的基本概念
1、支持度
关联规则A->B的支持度support=P(AB),指的是事件A和事件B同时发生的概率。
支持度(Support)是关联规则挖掘中一个重要的概念,用于度量一个项集在数据集中出现的频率。支持度表示一个项集的出现频繁程度,是关联规则挖掘中用于筛选频繁项集的一个指标。
数学上,支持度可以通过以下公式计算:

其中:
- Support(X) 是项集 (X) 的支持度。
- “Transactions containing (X)” 表示包含项集 (X) 的事务的数量。
- “Total transactions” 表示数据集中总的事务数量。
支持度的取值范围是 ([0, 1])。当支持度等于 1 时,表示项集 (X) 出现在所有事务中,即项集 (X) 是一个频繁项集。当支持度小于 1 时,表示项集 (X) 出现的频率相对较低。
在关联规则挖掘中,一般会设置一个支持度的阈值,只保留支持度大于等于阈值的项集作为频繁项集。这样可以过滤掉出现频率较低的项集,提高挖掘的效率。
例如,考虑一个购物篮分析的场景,支持度的解释可能是:某个商品集合(比如购物篮中的商品组合)在所有购物篮中的出现频率。如果我们设置支持度阈值为 0.1(10%),那么只有出现频率超过 10% 的商品集合才被认为是频繁项集。
在 Apriori 算法等关联规则挖掘算法中,支持度是用来筛选频繁项集的重要指标,因为频繁项集是生成关联规则的基础。
2、置信度
置信度(Confidence)是关联规则挖掘中的另一个重要概念,用于衡量关联规则的可靠性或准确性。置信度表示在一个项集 (X) 出现的条件下,项集 (Y) 也出现的概率。
数学上,置信度可以通过以下公式计算:

置信度的取值范围是 ([0, 1])。当置信度等于 1 时,表示规则 (X => Y) 总是成立,即项集 (Y) 必定在包含项集 (X) 的事务中出现。当置信度小于 1 时,表示规则 (X => Y) 的可靠性相对较低。
在关联规则挖掘中,一般会设置一个置信度的阈值,只保留置信度大于等于阈值的关联规则。这样可以过滤掉置信度较低的规则,提高挖掘结果的可靠性。
举例来说,考虑一个购物篮分析的场景,置信度的解释可能是:如果顾客购买了商品集合 (X),那么购买商品 (Y) 的概率是多少。如果我们设置置信度阈值为 0.7(70%),则只有当购买商品集合 (X) 的情况下,购买商品 (Y) 的概率超过 70% 的规则才被认为是强关联规则。
3、相关性
在数据分析和机器学习中,"相关性"通常指的是两个变量之间的关联或相互关系。相关性的度量可以帮助我们了解两个变量之间的趋势、模式或依赖关系。以下是一些常见的相关性度量方法:
-
皮尔逊相关系数(Pearson Correlation Coefficient):
- 皮尔逊相关系数衡量了两个连续变量之间的线性关系程度。它的取值范围在 ([-1, 1]),其中:
- 1 表示完全正相关,
- 0 表示没有线性相关性,
- -1 表示完全负相关。
公式如下:
- 皮尔逊相关系数衡量了两个连续变量之间的线性关系程度。它的取值范围在 ([-1, 1]),其中:

-
斯皮尔曼等级相关系数(Spearman Rank Correlation Coefficient):
- 斯皮尔曼相关系数是基于变量的等级而不是原始值的。它用于测量两个变量的等级之间的单调关系。与皮尔逊相关系数一样,它的取值范围在 ([-1, 1]),其中:
- 1 表示完全正相关,
- 0 表示没有单调关系,
- -1 表示完全负相关。
斯皮尔曼相关系数的计算涉及到对原始数据的等级排序。
- 斯皮尔曼相关系数是基于变量的等级而不是原始值的。它用于测量两个变量的等级之间的单调关系。与皮尔逊相关系数一样,它的取值范围在 ([-1, 1]),其中:
-
判定系数(Coefficient of Determination,(R^2)):
- 判定系数用于度量因变量的变异中有多少是由自变量解释的。它的取值范围在 ([0, 1]),其中:
- 0 表示模型无法解释因变量的变异,
- 1 表示模型完全解释了因变量的变异。
判定系数可以通过皮尔逊相关系数的平方得到。
- 判定系数用于度量因变量的变异中有多少是由自变量解释的。它的取值范围在 ([0, 1]),其中:
这些相关性度量方法用于量化变量之间的关联程度。在实际应用中,选择合适的相关性度量取决于数据的性质以及我们关心的问题。需要注意的是,相关性并不等同于因果关系,因此在解释相关性时需要谨慎。
4、提升度
提升度(Lift)是关联规则挖掘中的一个重要概念,用于衡量两个项集之间的关联程度。提升度告诉我们,包含一个项集的事务中,是否包含另一个项集的发生比例高于基准水平(即两个项集之间的独立性)。提升度的计算如下:

提升度的解释:
- 如果提升度等于 1,表示项集 (X) 和项集 (Y) 是独立的,规则 (X \Rightarrow Y) 对于预测项集 (Y) 的出现没有提升效果。
- 如果提升度大于 1,表示项集 (X) 和项集 (Y) 之间存在正相关关系,规则 (X \Rightarrow Y) 对于预测项集 (Y) 的出现具有提升效果。
- 如果提升度小于 1,表示项集 (X) 和项集 (Y) 之间存在负相关关系,规则 (X \Rightarrow Y) 对于预测项集 (Y) 的出现具有降低效果。
在关联规则挖掘中,我们通常会设置一个提升度的阈值,只保留提升度大于等于阈值的关联规则。这样可以过滤掉那些提升效果不明显的规则,使挖掘结果更具实际意义。
举例来说,考虑一个购物篮分析的场景。如果我们发现规则 (X \Rightarrow Y) 的提升度为 1.5,意味着购买商品 (X) 的顾客中,购买商品 (Y) 的概率比整体平均水平高 50%。这可能意味着商品 (X) 和商品 (Y) 之间存在某种关联关系,可以用于制定促销策略或调整商品摆放位置。
5、频繁项集
频繁项集是指在一个数据集中经常出现的项的集合。在关联规则挖掘中,我们关注的是频繁项集的概念。频繁项集挖掘是一种发现数据集中频繁出现的模式的技术,通常用于购物篮分析、推荐系统等领域。
以下是频繁项集的一些关键概念:
-
项集(Itemset):
- 项集是数据集中的一个或多个项(item)的集合。项可以是任何可以在数据集中唯一标识的元素,例如购物篮中的商品。
-
支持度(Support):
- 支持度是一个项集在数据集中出现的频率,即包含该项集的事务的数量。支持度用于度量一个项集的出现频繁程度。
- 支持度的计算公式为:
![[ \text{Support}(X) = \frac{\text{Transactions containing } X}{\text{Total transactions}} ]](https://img-blog.csdnimg.cn/3a9913940e484272b70d930b347d6bf0.png)
-
频繁项集:
- 频繁项集是在数据集中具有较高支持度的项集。具体而言,如果一个项集的支持度超过了预定义的阈值(支持度阈值),则称其为频繁项集。
-
最小支持度阈值:
- 最小支持度阈值是用户事先指定的一个值,用于确定哪些项集被认为是频繁的。只有支持度大于等于最小支持度阈值的项集才被认为是频繁的。
频繁项集挖掘的算法(例如 Apriori 算法)会遍历可能的项集,计算它们的支持度,然后根据最小支持度阈值筛选出频繁项集。频繁项集的发现是关联规则挖掘的基础,因为关联规则通常是从频繁项集中导出的。这些规则可以提供关于项之间关联关系的信息,对于理解数据中的模式和趋势很有帮助。
6、关联规则
关联规则是一种用于发现数据集中项之间关联关系的技术。这类规则通常用于购物篮分析、推荐系统等场景,帮助理解数据中的模式和趋势。关联规则包含两个部分:前项(Antecedent)和后项(Consequent)。规则的形式通常表示为 (X \Rightarrow Y),其中 (X) 是前项,(Y) 是后项。
以下是关联规则的一些关键概念:

关联规则挖掘的过程通常包括以下步骤:
- 找出频繁项集:使用频繁项集挖掘算法(例如 Apriori 算法)找到在数据集中具有较高支持度的项集。
- 生成关联规则:从频繁项集中生成关联规则,并计算它们的置信度和提升度。
- 过滤规则:根据用户指定的最小支持度和最小置信度阈值,过滤掉不满足条件的规则。
关联规则挖掘的应用广泛,包括市场篮分析、推荐系统、广告投放优化等领域。这些规则可以帮助企业理解消费者行为,提高商品推荐的准确性,优化营销策略等。
7、超集
在集合论中,如果一个集合 A 的所有元素都是集合 B 的元素,并且集合 B 还包含一些额外的元素,那么集合 B 被称为集合 A 的超集。换句话说,如果对于任意 (x),如果 (x ∈ A),则 (x ∈ B),则集合 B 是集合 A 的超集。
符号表示:如果集合 B 是集合 A 的超集,通常用符号 (A \subseteq B) 表示。这表示集合 A 是集合 B 的子集,或者可以说 B 包含 A。
举例说明:
假设有两个集合:
- 集合 A = {1, 2, 3}
- 集合 B = {1, 2, 3, 4, 5}
在这种情况下,集合 B 包含了集合 A 的所有元素(1、2、3),并且还包含了额外的元素(4、5)。因此,集合 B 是集合 A 的超集,可以写作 (A ⊆ B)。
超集的概念在关联规则挖掘等领域中经常用于描述频繁项集之间的关系。例如,如果一个项集 {A, B} 是频繁项集,那么它的超集 {A, B, C} 也是频繁项集。这是因为包含更多元素的项集在数据中出现的次数通常不会少于它的子集。超集的概念在 Apriori 算法等频繁项集挖掘算法中有一定的应用。

四、Apriori算法的基本思想:
Apriori算法过程分为两个步骤:
第一步通过迭代,检索出事务数据库中的所有频繁项集,即支持度不低于用户设定的阈值的项集;
第二步利用频繁项集构造出满足用户最小信任度的规则。
具体做法就是:
首先找出频繁1-项集,记为L1;然后利用L1来产生候选项集C2,对C2中的项进行判定挖掘出L2,即频繁2-项集;不断如此循环下去直到无法发现更多的频繁k-项集为止。每挖掘一层Lk就需要扫描整个数据库一遍。算法利用了一个性质:
Apriori 性质:任一频繁项集的所有非空子集也必须是频繁的。意思就是说,生成一个k-itemset的候选项时,如果这个候选项有子集不在(k-1)-itemset(已经确定是frequent的)中时,那么这个候选项就不用拿去和支持度判断了,直接删除。具体而言:
1) 连接步
为找出Lk(所有的频繁k项集的集合),通过将Lk-1(所有的频繁k-1项集的集合)与自身连接产生候选k项集的集合。候选集合记作Ck。设l1和l2是Lk-1中的成员。记li[j]表示li中的第j项。假设Apriori算法对事务或项集中的项按字典次序排序,即对于(k-1)项集li,li[1]<li[2]<……….<li[k-1]。将Lk-1与自身连接,如果(l1[1]=l2[1])&&( l1[2]=l2[2])&&………&& (l1[k-2]=l2[k-2])&&(l1[k-1]<l2[k-1]),那认为l1和l2是可连接。连接l1和l2 产生的结果是{l1[1],l1[2],……,l1[k-1],l2[k-1]}。
2) 剪枝步
CK是LK的超集,也就是说,CK的成员可能是也可能不是频繁的。通过扫描所有的事务(交易),确定CK中每个候选的计数,判断是否小于最小支持度计数,如果不是,则认为该候选是频繁的。为了压缩Ck,可以利用Apriori性质:任一频繁项集的所有非空子集也必须是频繁的,反之,如果某个候选的非空子集不是频繁的,那么该候选肯定不是频繁的,从而可以将其从CK中删除。
五、实例说明
实例一:下面以图例的方式说明该算法的运行过程: 假设有一个数据库D,其中有4个事务记录,分别表示为:
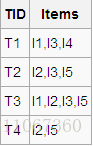
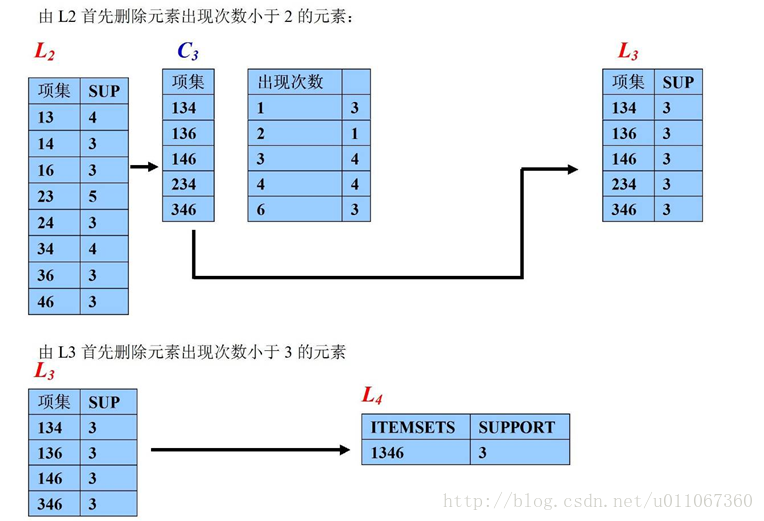
这里预定最小支持度minSupport=2,下面用图例说明算法运行的过程:
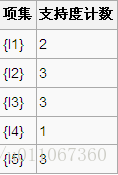
1、扫描D,对每个候选项进行支持度计数得到表C1:
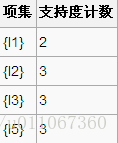
2、比较候选项支持度计数与最小支持度minSupport,产生1维最大项目集L1:
3、由L1产生候选项集C2:

4、扫描D,对每个候选项集进行支持度计数:

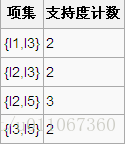
5、比较候选项支持度计数与最小支持度minSupport,产生2维最大项目集L2:
6、由L2产生候选项集C3:
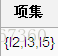
7、比较候选项支持度计数与最小支持度minSupport,产生3维最大项目集L3:

算法终止。
实例二:下图从整体同样的能说明此过程:
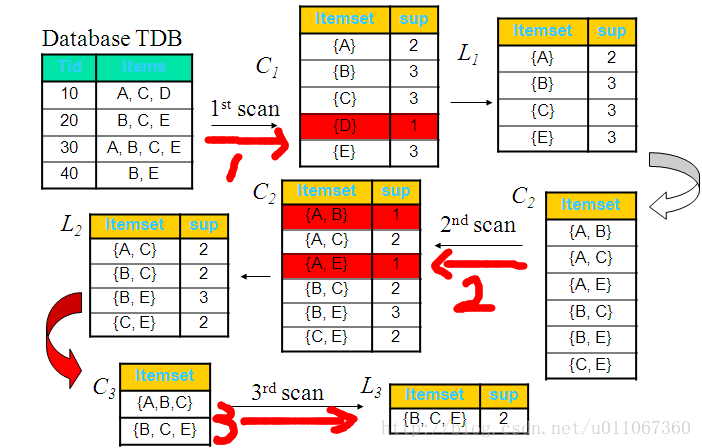
从算法的运行过程,我们可以看出该Apriori算法的优点:简单、易理解、数据要求低,然而我们也可以看到Apriori算法的缺点:
(1)在每一步产生侯选项目集时循环产生的组合过多,没有排除不应该参与组合的元素;
(2)每次计算项集的支持度时,都对数据库D中的全部记录进行了一遍扫描比较,如果是一个大型的数据库的话,这种扫描比较会大大增加计算机系统的I/O开销。而这种代价是随着数据库的记录的增加呈现出几何级数的增加。因此人们开始寻求更好性能的算法。
六、改进Apriori算法的方法
方法1:基于hash表的项集计数
将每个项集通过相应的hash函数映射到hash表中的不同的桶中,这样可以通过将桶中的项集技术跟最小支持计数相比较先淘汰一部分项集。
方法2:事务压缩(压缩进一步迭代的事务数)
不包含任何k-项集的事务不可能包含任何(k+1)-项集,这种事务在下一步的计算中可以加上标记或删除
方法3:划分
- 挖掘频繁项集只需要两次数据扫描
- D中的任何频繁项集必须作为局部频繁项集至少出现在一个部分中。
- 第一次扫描:将数据划分为多个部分并找到局部频繁项集
- 第二次扫描:评估每个候选项集的实际支持度,以确定全局频繁项集。
方法4:选样(在给定数据的一个子集挖掘)
- 基本思想:选择原始数据的一个样本,在这个样本上用Apriori算法挖掘频繁模式
- 通过牺牲精确度来减少算法开销,为了提高效率,样本大小应该以可以放在内存中为宜,可以适当降低最小支持度来减少遗漏的频繁模式
- 可以通过一次全局扫描来验证从样本中发现的模式
- 可以通过第二此全局扫描来找到遗漏的模式
方法5:动态项集计数
在扫描的不同点添加候选项集,这样,如果一个候选项集已经满足最少支持度,则在可以直接将它添加到频繁项集,而不必在这次扫描的以后对比中继续计算。
PS:Apriori算法的优化思路
1、在逐层搜索循环过程的第k步中,根据k-1步生成的k-1维频繁项目集来产生k维候选项目集,由于在产生k-1维频繁项目集时,我们可以实现对该集中出现元素的个数进行计数处理,因此对某元素而言,若它的计数个数不到k-1的话,可以事先删除该元素,从而排除由该元素将引起的大规格所有组合。
- 这是因为对某一个元素要成为K维项目集的一元素的话,该元素在k-1阶频繁项目集中的计数次数必须达到K-1个,否则不可能生成K维项目集(性质3)。
2、根据以上思路得到了这个候选项目集后,可以对数据库D的每一个事务进行扫描,若该事务中至少含有候选项目集Ck中的一员则保留该项事务,否则把该事物记录与数据库末端没有作删除标记的事务记录对换,并对移到数据库末端的事务记录作删除标一记,整个数据库扫描完毕后为新的事务数据库D’ 中。
- 因此随着K 的增大,D’中事务记录量大大地减少,对于下一次事务扫描可以大大节约I/0 开销。由于顾客一般可能一次只购买几件商品,因此这种虚拟删除的方法可以实现大量的交易记录在以后的挖掘中被剔除出来,在所剩余的不多的记录中再作更高维的数据挖掘是可以大大地节约时间的。
实例过程如下图:
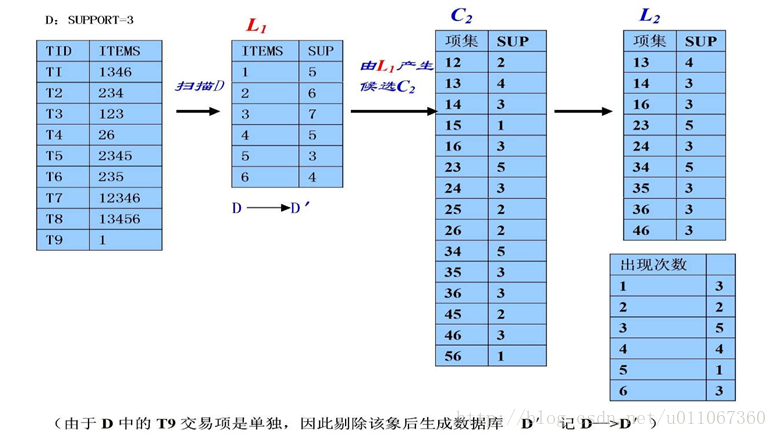
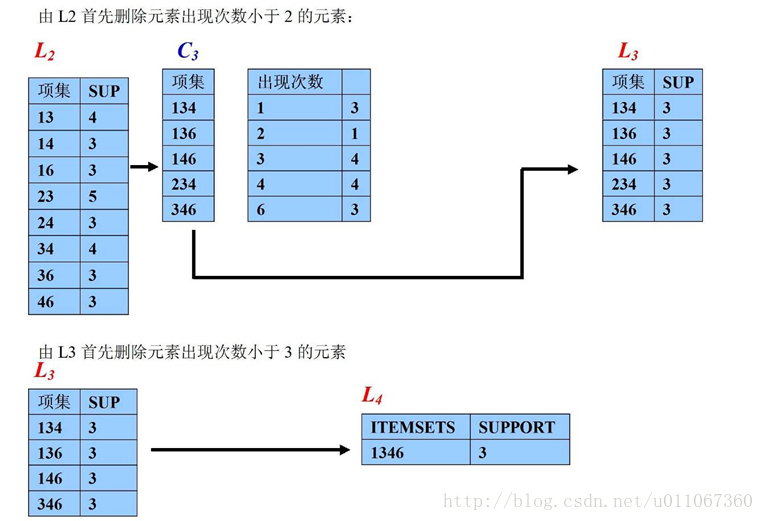
- 当然还有很多相应的优化算法,比如针对Apriori算法的性能瓶颈问题-需要产生大量候选项集和需要重复地扫描数据库,2000年Jiawei Han等人提出了基于FP树生成频繁项集的FP-growth算法。该算法只进行2次数据库扫描且它不使用侯选集,直接压缩数据库成一个频繁模式树,最后通过这棵树生成关联规则。研究表明它比Apriori算法大约快一个数量级。
Apriori 原理
假设我们一共有 4 个商品: 商品0, 商品1, 商品2, 商品3。 所有可能的情况如下:
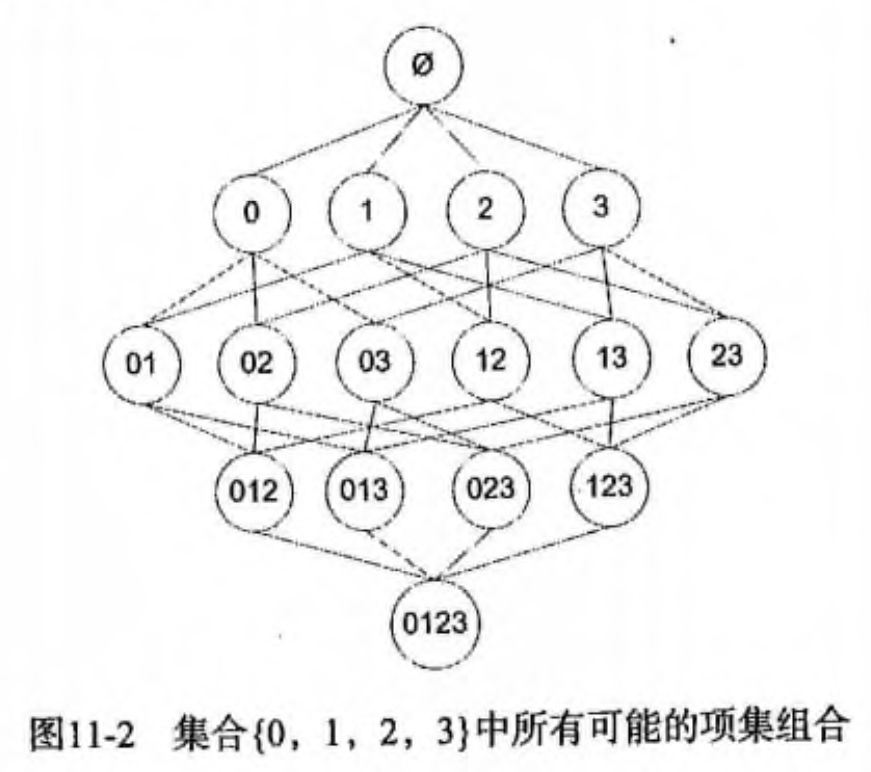
如果我们计算所有组合的支持度,也需要计算 15 次。即 2^N - 1 = 2^4 - 1 = 15。
随着物品的增加,计算的次数呈指数的形式增长 …
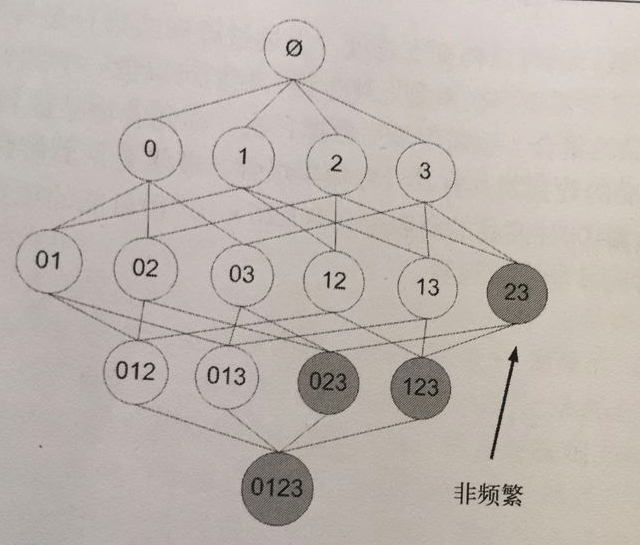
为了降低计算次数和时间,研究人员发现了一种所谓的 Apriori 原理,即某个项集是频繁的,那么它的所有子集也是频繁的。 例如,如果 {0, 1} 是频繁的,那么 {0}, {1} 也是频繁的。 该原理直观上没有什么帮助,但是如果反过来看就有用了,也就是说如果一个项集是 非频繁项集,那么它的所有超集也是非频繁项集,如下图所示:
Apriori 算法优缺点
- 优点:易编码实现
- 缺点:在大数据集上可能较慢
- 适用数据类型:数值型 或者 标称型数据。
Apriori 算法流程步骤:
- 收集数据:使用任意方法。
- 准备数据:任何数据类型都可以,因为我们只保存集合。
- 分析数据:使用任意方法。
- 训练数据:使用Apiori算法来找到频繁项集。
- 测试算法:不需要测试过程。
- 使用算法:用于发现频繁项集以及物品之间的关联规则。
Apriori 算法的使用
前面提到,关联分析的目标包括两项: 发现 频繁项集 和发现 关联规则。 首先需要找到 频繁项集,然后才能发现 关联规则。 Apriori 算法是发现 频繁项集 的一种方法。 Apriori 算法的两个输入参数分别是最小支持度和数据集。 该算法首先会生成所有单个物品的项集列表。 接着扫描交易记录来查看哪些项集满足最小支持度要求,那些不满足最小支持度要求的集合会被去掉。 燃尽后对生下来的集合进行组合以声场包含两个元素的项集。 接下来再重新扫描交易记录,去掉不满足最小支持度的项集。 该过程重复进行直到所有项集被去掉。
生成候选项集
下面会创建一个用于构建初始集合的函数,也会创建一个通过扫描数据集以寻找交易记录子集的函数, 数据扫描的伪代码如下:
-
对数据集中的每条交易记录 tran
-
对每个候选项集 can
- 检查一下 can 是否是 tran 的子集: 如果是则增加 can 的计数值
-
对每个候选项集:
- 如果其支持度不低于最小值,则保留该项集
- 返回所有频繁项集列表 以下是一些辅助函数。
代码演示:
加载数据集
# 加载数据集
def loadDataSet():return [[1, 3, 4], [2, 3, 5], [1, 2, 3, 5], [2, 5]]
创建集合 C1。即对 dataSet 进行去重,排序,放入 list 中,然后转换所有的元素为 frozenset
# 创建集合 C1。即对 dataSet 进行去重,排序,放入 list 中,然后转换所有的元素为 frozenset
def createC1(dataSet):"""createC1(创建集合 C1)Args:dataSet 原始数据集Returns:frozenset 返回一个 frozenset 格式的 list"""C1 = []for transaction in dataSet:for item in transaction:if not [item] in C1:# 遍历所有的元素,如果不在 C1 出现过,那么就 appendC1.append([item])# 对数组进行 `从小到大` 的排序print 'sort 前=', C1C1.sort()# frozenset 表示冻结的 set 集合,元素无改变;可以把它当字典的 key 来使用print 'sort 后=', C1print 'frozenset=', map(frozenset, C1)return map(frozenset, C1)计算候选数据集 CK 在数据集 D 中的支持度,并返回支持度大于最小支持度(minSupport)的数据
# 计算候选数据集 CK 在数据集 D 中的支持度,并返回支持度大于最小支持度(minSupport)的数据
def scanD(D, Ck, minSupport):"""scanD(计算候选数据集 CK 在数据集 D 中的支持度,并返回支持度大于最小支持度 minSupport 的数据)Args:D 数据集Ck 候选项集列表minSupport 最小支持度Returns:retList 支持度大于 minSupport 的集合supportData 候选项集支持度数据"""# ssCnt 临时存放选数据集 Ck 的频率. 例如: a->10, b->5, c->8ssCnt = {}for tid in D:for can in Ck:# s.issubset(t) 测试是否 s 中的每一个元素都在 t 中if can.issubset(tid):if not ssCnt.has_key(can):ssCnt[can] = 1else:ssCnt[can] += 1numItems = float(len(D)) # 数据集 D 的数量retList = []supportData = {}for key in ssCnt:# 支持度 = 候选项(key)出现的次数 / 所有数据集的数量support = ssCnt[key]/numItemsif support >= minSupport:# 在 retList 的首位插入元素,只存储支持度满足频繁项集的值retList.insert(0, key)# 存储所有的候选项(key)和对应的支持度(support)supportData[key] = supportreturn retList, supportData组织完整的 Apriori 算法
输入频繁项集列表 Lk 与返回的元素个数 k,然后输出所有可能的候选项集 Ck
# 输入频繁项集列表 Lk 与返回的元素个数 k,然后输出所有可能的候选项集 Ck
def aprioriGen(Lk, k):"""aprioriGen(输入频繁项集列表 Lk 与返回的元素个数 k,然后输出候选项集 Ck。例如: 以 {0},{1},{2} 为输入且 k = 2 则输出 {0,1}, {0,2}, {1,2}. 以 {0,1},{0,2},{1,2} 为输入且 k = 3 则输出 {0,1,2}仅需要计算一次,不需要将所有的结果计算出来,然后进行去重操作这是一个更高效的算法)Args:Lk 频繁项集列表k 返回的项集元素个数(若元素的前 k-2 相同,就进行合并)Returns:retList 元素两两合并的数据集"""retList = []lenLk = len(Lk)for i in range(lenLk):for j in range(i+1, lenLk):L1 = list(Lk[i])[: k-2]L2 = list(Lk[j])[: k-2]# print '-----i=', i, k-2, Lk, Lk[i], list(Lk[i])[: k-2]# print '-----j=', j, k-2, Lk, Lk[j], list(Lk[j])[: k-2]L1.sort()L2.sort()# 第一次 L1,L2 为空,元素直接进行合并,返回元素两两合并的数据集# if first k-2 elements are equalif L1 == L2:# set union# print 'union=', Lk[i] | Lk[j], Lk[i], Lk[j]retList.append(Lk[i] | Lk[j])return retList
找出数据集 dataSet 中支持度 >= 最小支持度的候选项集以及它们的支持度。即我们的频繁项集。
# 找出数据集 dataSet 中支持度 >= 最小支持度的候选项集以及它们的支持度。即我们的频繁项集。
def apriori(dataSet, minSupport=0.5):"""apriori(首先构建集合 C1,然后扫描数据集来判断这些只有一个元素的项集是否满足最小支持度的要求。那么满足最小支持度要求的项集构成集合 L1。然后 L1 中的元素相互组合成 C2,C2 再进一步过滤变成 L2,然后以此类推,知道 CN 的长度为 0 时结束,即可找出所有频繁项集的支持度。)Args:dataSet 原始数据集minSupport 支持度的阈值Returns:L 频繁项集的全集supportData 所有元素和支持度的全集"""# C1 即对 dataSet 进行去重,排序,放入 list 中,然后转换所有的元素为 frozensetC1 = createC1(dataSet)# 对每一行进行 set 转换,然后存放到集合中D = map(set, dataSet)print 'D=', D# 计算候选数据集 C1 在数据集 D 中的支持度,并返回支持度大于 minSupport 的数据L1, supportData = scanD(D, C1, minSupport)# print "L1=", L1, "\n", "outcome: ", supportData# L 加了一层 list, L 一共 2 层 listL = [L1]k = 2# 判断 L 的第 k-2 项的数据长度是否 > 0。第一次执行时 L 为 [[frozenset([1]), frozenset([3]), frozenset([2]), frozenset([5])]]。L[k-2]=L[0]=[frozenset([1]), frozenset([3]), frozenset([2]), frozenset([5])],最后面 k += 1while (len(L[k-2]) > 0):print 'k=', k, L, L[k-2]Ck = aprioriGen(L[k-2], k) # 例如: 以 {0},{1},{2} 为输入且 k = 2 则输出 {0,1}, {0,2}, {1,2}. 以 {0,1},{0,2},{1,2} 为输入且 k = 3 则输出 {0,1,2}print 'Ck', CkLk, supK = scanD(D, Ck, minSupport) # 计算候选数据集 CK 在数据集 D 中的支持度,并返回支持度大于 minSupport 的数据# 保存所有候选项集的支持度,如果字典没有,就追加元素,如果有,就更新元素supportData.update(supK)if len(Lk) == 0:break# Lk 表示满足频繁子项的集合,L 元素在增加,例如: # l=[[set(1), set(2), set(3)]]# l=[[set(1), set(2), set(3)], [set(1, 2), set(2, 3)]]L.append(Lk)k += 1# print 'k=', k, len(L[k-2])return L, supportData
到这一步,我们就找出我们所需要的 频繁项集 和他们的 支持度 了,接下来再找出关联规则即可!
从频繁项集中挖掘关联规则
前面我们介绍了用于发现 频繁项集 的 Apriori 算法,现在要解决的问题是如何找出 关联规则。
要找到 关联规则,我们首先从一个 频繁项集 开始。 我们知道集合中的元素是不重复的,但我们想知道基于这些元素能否获得其它内容。 某个元素或某个元素集合可能会推导出另一个元素。 从先前 杂货店 的例子可以得到,如果有一个频繁项集 {豆奶,莴苣},那么就可能有一条关联规则 “豆奶 -> 莴苣”。 这意味着如果有人买了豆奶,那么在统计上他会购买莴苣的概率比较大。 但是,这一条件反过来并不总是成立。 也就是说 “豆奶 -> 莴苣” 统计上显著,那么 “莴苣 -> 豆奶” 也不一定成立。
前面我们给出了 频繁项集 的量化定义,即它满足最小支持度要求。
对于 关联规则,我们也有类似的量化方法,这种量化指标称之为 可信度。
一条规则 A -> B 的可信度定义为 support(A | B) / support(A)。(注意: 在 python 中 | 表示集合的并操作,而数学书集合并的符号是 U)。
A | B 是指所有出现在集合 A 或者集合 B 中的元素。 由于我们先前已经计算出所有 频繁项集 的支持度了,现在我们要做的只不过是提取这些数据做一次除法运算即可。
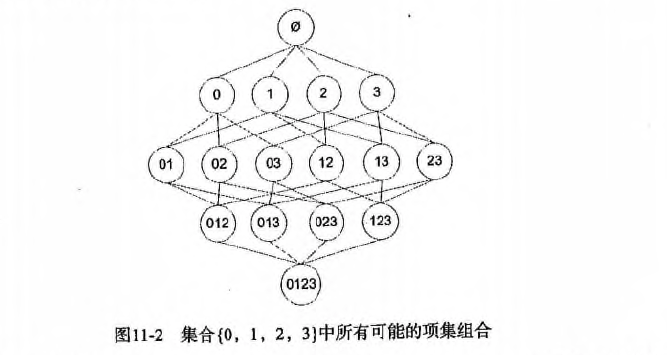
一个频繁项集可以产生多少条关联规则呢?
如下图所示,给出的是项集 {0,1,2,3} 产生的所有关联规则:
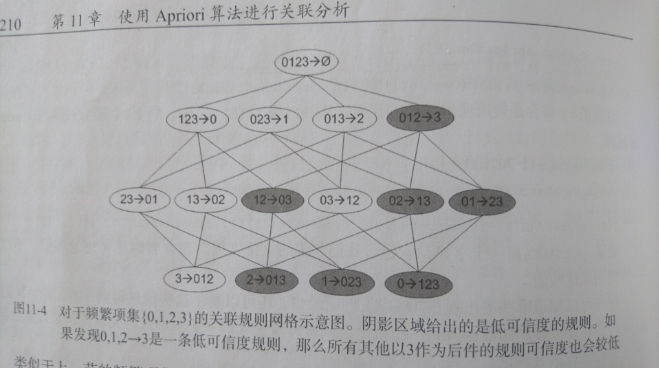
与我们前面的 频繁项集 生成一样,我们可以为每个频繁项集产生许多关联规则。
如果能减少规则的数目来确保问题的可解析,那么计算起来就会好很多。
通过观察,我们可以知道,如果某条规则并不满足 最小可信度 要求,那么该规则的所有子集也不会满足 最小可信度 的要求。 如上图所示,假设 123 -> 3 并不满足最小可信度要求,那么就知道任何左部为 {0,1,2} 子集的规则也不会满足 最小可信度 的要求。 即 12 -> 03 , 02 -> 13 , 01 -> 23 , 2 -> 013, 1 -> 023, 0 -> 123 都不满足 最小可信度 要求。
可以利用关联规则的上述性质属性来减少需要测试的规则数目,跟先前 Apriori 算法的套路一样。 以下是一些辅助函数:
计算可信度
# 计算可信度(confidence)
def calcConf(freqSet, H
, supportData, brl, minConf=0.7):"""calcConf(对两个元素的频繁项,计算可信度,例如: {1,2}/{1} 或者 {1,2}/{2} 看是否满足条件)Args:freqSet 频繁项集中的元素,例如: frozenset([1, 3]) H 频繁项集中的元素的集合,例如: [frozenset([1]), frozenset([3])]supportData 所有元素的支持度的字典brl 关联规则列表的空数组minConf 最小可信度Returns:prunedH 记录 可信度大于阈值的集合"""# 记录可信度大于最小可信度(minConf)的集合prunedH = []for conseq in H: # 假设 freqSet = frozenset([1, 3]), H = [frozenset([1]), frozenset([3])],那么现在需要求出 frozenset([1]) -> frozenset([3]) 的可信度和 frozenset([3]) -> frozenset([1]) 的可信度# print 'confData=', freqSet, H, conseq, freqSet-conseqconf = supportData[freqSet]/supportData[freqSet-conseq] # 支持度定义: a -> b = support(a | b) / support(a). 假设 freqSet = frozenset([1, 3]), conseq = [frozenset([1])],那么 frozenset([1]) 至 frozenset([3]) 的可信度为 = support(a | b) / support(a) = supportData[freqSet]/supportData[freqSet-conseq] = supportData[frozenset([1, 3])] / supportData[frozenset([1])]if conf >= minConf:# 只要买了 freqSet-conseq 集合,一定会买 conseq 集合(freqSet-conseq 集合和 conseq 集合是全集)print freqSet-conseq, '-->', conseq, 'conf:', confbrl.append((freqSet-conseq, conseq, conf))prunedH.append(conseq)return prunedH
递归计算频繁项集的规则
# 递归计算频繁项集的规则
def rulesFromConseq(freqSet, H, supportData, brl, minConf=0.7):"""rulesFromConseqArgs:freqSet 频繁项集中的元素,例如: frozenset([2, 3, 5]) H 频繁项集中的元素的集合,例如: [frozenset([2]), frozenset([3]), frozenset([5])]supportData 所有元素的支持度的字典brl 关联规则列表的数组minConf 最小可信度"""# H[0] 是 freqSet 的元素组合的第一个元素,并且 H 中所有元素的长度都一样,长度由 aprioriGen(H, m+1) 这里的 m + 1 来控制# 该函数递归时,H[0] 的长度从 1 开始增长 1 2 3 ...# 假设 freqSet = frozenset([2, 3, 5]), H = [frozenset([2]), frozenset([3]), frozenset([5])]# 那么 m = len(H[0]) 的递归的值依次为 1 2# 在 m = 2 时, 跳出该递归。假设再递归一次,那么 H[0] = frozenset([2, 3, 5]),freqSet = frozenset([2, 3, 5]) ,没必要再计算 freqSet 与 H[0] 的关联规则了。m = len(H[0])if (len(freqSet) > (m + 1)):print 'freqSet******************', len(freqSet), m + 1, freqSet, H, H[0]# 生成 m+1 个长度的所有可能的 H 中的组合,假设 H = [frozenset([2]), frozenset([3]), frozenset([5])]# 第一次递归调用时生成 [frozenset([2, 3]), frozenset([2, 5]), frozenset([3, 5])]# 第二次 。。。没有第二次,递归条件判断时已经退出了Hmp1 = aprioriGen(H, m+1)# 返回可信度大于最小可信度的集合Hmp1 = calcConf(freqSet, Hmp1, supportData, brl, minConf)print 'Hmp1=', Hmp1print 'len(Hmp1)=', len(Hmp1), 'len(freqSet)=', len(freqSet)# 计算可信度后,还有数据大于最小可信度的话,那么继续递归调用,否则跳出递归if (len(Hmp1) > 1):print '----------------------', Hmp1# print len(freqSet), len(Hmp1[0]) + 1rulesFromConseq(freqSet, Hmp1, supportData, brl, minConf)
生成关联规则
# 生成关联规则
def generateRules(L, supportData, minConf=0.7):"""generateRulesArgs:L 频繁项集列表supportData 频繁项集支持度的字典minConf 最小置信度Returns:bigRuleList 可信度规则列表(关于 (A->B+置信度) 3个字段的组合)"""bigRuleList = []# 假设 L = [[frozenset([1]), frozenset([3]), frozenset([2]), frozenset([5])], [frozenset([1, 3]), frozenset([2, 5]), frozenset([2, 3]), frozenset([3, 5])], [frozenset([2, 3, 5])]]for i in range(1, len(L)):# 获取频繁项集中每个组合的所有元素for freqSet in L[i]:# 假设:freqSet= frozenset([1, 3]), H1=[frozenset([1]), frozenset([3])]# 组合总的元素并遍历子元素,并转化为 frozenset 集合,再存放到 list 列表中H1 = [frozenset([item]) for item in freqSet]# 2 个的组合,走 else, 2 个以上的组合,走 ifif (i > 1):rulesFromConseq(freqSet, H1, supportData, bigRuleList, minConf)else:calcConf(freqSet, H1, supportData, bigRuleList, minConf)return bigRuleList
到这里为止,通过调用 generateRules 函数即可得出我们所需的 关联规则。
- 分级法: 频繁项集->关联规则:
-
- 首先从一个频繁项集开始,接着创建一个规则列表,其中规则右部分只包含一个元素,然后对这个规则进行测试。
-
- 接下来合并所有剩余规则来创建一个新的规则列表,其中规则右部包含两个元素。
如下图:
- 接下来合并所有剩余规则来创建一个新的规则列表,其中规则右部包含两个元素。
最后: 每次增加频繁项集的大小,Apriori 算法都会重新扫描整个数据集,是否有优化空间呢? 下一章:FP-growth算法等着你的到来。
完整代码:
#项目案例#!/usr/bin/python
# coding: utf8'''
Created on Mar 24, 2011
Update on 2017-05-18
Ch 11 code
@author: Peter/片刻
《机器学习实战》更新地址:https://github.com/apachecn/MachineLearning'''
print(__doc__)
from numpy import *# 加载数据集
def loadDataSet():return [[1, 3, 4], [2, 3, 5], [1, 2, 3, 5], [2, 5]]# 创建集合 C1。即对 dataSet 进行去重,排序,放入 list 中,然后转换所有的元素为 frozenset
def createC1(dataSet):"""createC1(创建集合 C1)Args:dataSet 原始数据集Returns:frozenset 返回一个 frozenset 格式的 list"""C1 = []for transaction in dataSet:for item in transaction:if not [item] in C1:# 遍历所有的元素,如果不在 C1 出现过,那么就 appendC1.append([item])# 对数组进行 `从小到大` 的排序# print 'sort 前=', C1C1.sort()# frozenset 表示冻结的 set 集合,元素无改变;可以把它当字典的 key 来使用# print 'sort 后=', C1# print 'frozenset=', map(frozenset, C1)return list(map(frozenset, C1))# 计算候选数据集 CK 在数据集 D 中的支持度,并返回支持度大于最小支持度(minSupport)的数据
def scanD(D, Ck, minSupport):"""scanD(计算候选数据集 CK 在数据集 D 中的支持度,并返回支持度大于最小支持度 minSupport 的数据)Args:D 数据集Ck 候选项集列表minSupport 最小支持度Returns:retList 支持度大于 minSupport 的集合supportData 候选项集支持度数据"""# ssCnt 临时存放选数据集 Ck 的频率. 例如: a->10, b->5, c->8 ssCnt = {}for tid in D:for can in Ck:# s.issubset(t) 测试是否 s 中的每一个元素都在 t 中if can.issubset(tid):if can not in ssCnt:ssCnt[can] = 1else:ssCnt[can] += 1numItems = float(len(D)) # 数据集 D 的数量retList = []supportData = {}for key in ssCnt:# 支持度 = 候选项(key)出现的次数 / 所有数据集的数量support = ssCnt[key]/numItemsif support >= minSupport:# 在 retList 的首位插入元素,只存储支持度满足频繁项集的值retList.insert(0, key)# 存储所有的候选项(key)和对应的支持度(support)supportData[key] = supportreturn retList, supportData# 输入频繁项集列表 Lk 与返回的元素个数 k,然后输出所有可能的候选项集 Ck
def aprioriGen(Lk, k):"""aprioriGen(输入频繁项集列表 Lk 与返回的元素个数 k,然后输出候选项集 Ck。例如: 以 {0},{1},{2} 为输入且 k = 2 则输出 {0,1}, {0,2}, {1,2}. 以 {0,1},{0,2},{1,2} 为输入且 k = 3 则输出 {0,1,2}仅需要计算一次,不需要将所有的结果计算出来,然后进行去重操作这是一个更高效的算法)Args:Lk 频繁项集列表k 返回的项集元素个数(若元素的前 k-2 相同,就进行合并)Returns:retList 元素两两合并的数据集"""retList = []lenLk = len(Lk)for i in range(lenLk):for j in range(i+1, lenLk):L1 = list(Lk[i])[: k-2]L2 = list(Lk[j])[: k-2]# print '-----i=', i, k-2, Lk, Lk[i], list(Lk[i])[: k-2]# print '-----j=', j, k-2, Lk, Lk[j], list(Lk[j])[: k-2]L1.sort()L2.sort()# 第一次 L1,L2 为空,元素直接进行合并,返回元素两两合并的数据集# if first k-2 elements are equalif L1 == L2:# set union# print 'union=', Lk[i] | Lk[j], Lk[i], Lk[j]retList.append(Lk[i] | Lk[j])return retList# 找出数据集 dataSet 中支持度 >= 最小支持度的候选项集以及它们的支持度。即我们的频繁项集。
def apriori(dataSet, minSupport=0.5):"""apriori(首先构建集合 C1,然后扫描数据集来判断这些只有一个元素的项集是否满足最小支持度的要求。那么满足最小支持度要求的项集构成集合 L1。然后 L1 中的元素相互组合成 C2,C2 再进一步过滤变成 L2,然后以此类推,知道 CN 的长度为 0 时结束,即可找出所有频繁项集的支持度。)Args:dataSet 原始数据集minSupport 支持度的阈值Returns:L 频繁项集的全集supportData 所有元素和支持度的全集"""# C1 即对 dataSet 进行去重,排序,放入 list 中,然后转换所有的元素为 frozensetC1 = createC1(dataSet)# print 'C1: ', C1# 对每一行进行 set 转换,然后存放到集合中D = list(map(set, dataSet))# print 'D=', D# 计算候选数据集 C1 在数据集 D 中的支持度,并返回支持度大于 minSupport 的数据L1, supportData = scanD(D, C1, minSupport)# print "L1=", L1, "\n", "outcome: ", supportData# L 加了一层 list, L 一共 2 层 listL = [L1]k = 2# 判断 L 的第 k-2 项的数据长度是否 > 0。第一次执行时 L 为 [[frozenset([1]), frozenset([3]), frozenset([2]), frozenset([5])]]。L[k-2]=L[0]=[frozenset([1]), frozenset([3]), frozenset([2]), frozenset([5])],最后面 k += 1while (len(L[k-2]) > 0):# print 'k=', k, L, L[k-2]Ck = aprioriGen(L[k-2], k) # 例如: 以 {0},{1},{2} 为输入且 k = 2 则输出 {0,1}, {0,2}, {1,2}. 以 {0,1},{0,2},{1,2} 为输入且 k = 3 则输出 {0,1,2}# print 'Ck', CkLk, supK = scanD(D, Ck, minSupport) # 计算候选数据集 CK 在数据集 D 中的支持度,并返回支持度大于 minSupport 的数据# 保存所有候选项集的支持度,如果字典没有,就追加元素,如果有,就更新元素supportData.update(supK)if len(Lk) == 0:break# Lk 表示满足频繁子项的集合,L 元素在增加,例如: # l=[[set(1), set(2), set(3)]]# l=[[set(1), set(2), set(3)], [set(1, 2), set(2, 3)]]L.append(Lk)k += 1# print 'k=', k, len(L[k-2])return L, supportData# 计算可信度(confidence)
def calcConf(freqSet, H, supportData, brl, minConf=0.7):"""calcConf(对两个元素的频繁项,计算可信度,例如: {1,2}/{1} 或者 {1,2}/{2} 看是否满足条件)Args:freqSet 频繁项集中的元素,例如: frozenset([1, 3]) H 频繁项集中的元素的集合,例如: [frozenset([1]), frozenset([3])]supportData 所有元素的支持度的字典brl 关联规则列表的空数组minConf 最小可信度Returns:prunedH 记录 可信度大于阈值的集合"""# 记录可信度大于最小可信度(minConf)的集合prunedH = []for conseq in H: # 假设 freqSet = frozenset([1, 3]), H = [frozenset([1]), frozenset([3])],那么现在需要求出 frozenset([1]) -> frozenset([3]) 的可信度和 frozenset([3]) -> frozenset([1]) 的可信度# print 'confData=', freqSet, H, conseq, freqSet-conseqconf = supportData[freqSet]/supportData[freqSet-conseq] # 支持度定义: a -> b = support(a | b) / support(a). 假设 freqSet = frozenset([1, 3]), conseq = [frozenset([1])],那么 frozenset([1]) 至 frozenset([3]) 的可信度为 = support(a | b) / support(a) = supportData[freqSet]/supportData[freqSet-conseq] = supportData[frozenset([1, 3])] / supportData[frozenset([1])]if conf >= minConf:# 只要买了 freqSet-conseq 集合,一定会买 conseq 集合(freqSet-conseq 集合和 conseq集合 是全集)print (freqSet-conseq, '-->', conseq, 'conf:', conf)brl.append((freqSet-conseq, conseq, conf))prunedH.append(conseq)return prunedH# 递归计算频繁项集的规则
def rulesFromConseq(freqSet, H, supportData, brl, minConf=0.7):"""rulesFromConseqArgs:freqSet 频繁项集中的元素,例如: frozenset([2, 3, 5]) H 频繁项集中的元素的集合,例如: [frozenset([2]), frozenset([3]), frozenset([5])]supportData 所有元素的支持度的字典brl 关联规则列表的数组minConf 最小可信度"""# H[0] 是 freqSet 的元素组合的第一个元素,并且 H 中所有元素的长度都一样,长度由 aprioriGen(H, m+1) 这里的 m + 1 来控制# 该函数递归时,H[0] 的长度从 1 开始增长 1 2 3 ...# 假设 freqSet = frozenset([2, 3, 5]), H = [frozenset([2]), frozenset([3]), frozenset([5])]# 那么 m = len(H[0]) 的递归的值依次为 1 2# 在 m = 2 时, 跳出该递归。假设再递归一次,那么 H[0] = frozenset([2, 3, 5]),freqSet = frozenset([2, 3, 5]) ,没必要再计算 freqSet 与 H[0] 的关联规则了。m = len(H[0])if (len(freqSet) > (m + 1)):# print 'freqSet******************', len(freqSet), m + 1, freqSet, H, H[0]# 生成 m+1 个长度的所有可能的 H 中的组合,假设 H = [frozenset([2]), frozenset([3]), frozenset([5])]# 第一次递归调用时生成 [frozenset([2, 3]), frozenset([2, 5]), frozenset([3, 5])]# 第二次 。。。没有第二次,递归条件判断时已经退出了Hmp1 = aprioriGen(H, m+1)# 返回可信度大于最小可信度的集合Hmp1 = calcConf(freqSet, Hmp1, supportData, brl, minConf)print ('Hmp1=', Hmp1)print ('len(Hmp1)=', len(Hmp1), 'len(freqSet)=', len(freqSet))# 计算可信度后,还有数据大于最小可信度的话,那么继续递归调用,否则跳出递归if (len(Hmp1) > 1):# print '----------------------', Hmp1# print len(freqSet), len(Hmp1[0]) + 1rulesFromConseq(freqSet, Hmp1, supportData, brl, minConf)# 生成关联规则
def generateRules(L, supportData, minConf=0.7):"""generateRulesArgs:L 频繁项集列表supportData 频繁项集支持度的字典minConf 最小置信度Returns:bigRuleList 可信度规则列表(关于 (A->B+置信度) 3个字段的组合)"""bigRuleList = []# 假设 L = [[frozenset([1]), frozenset([3]), frozenset([2]), frozenset([5])], [frozenset([1, 3]), frozenset([2, 5]), frozenset([2, 3]), frozenset([3, 5])], [frozenset([2, 3, 5])]]for i in range(1, len(L)):# 获取频繁项集中每个组合的所有元素for freqSet in L[i]:# 假设:freqSet= frozenset([1, 3]), H1=[frozenset([1]), frozenset([3])]# 组合总的元素并遍历子元素,并转化为 frozenset 集合,再存放到 list 列表中H1 = [frozenset([item]) for item in freqSet]# 2 个的组合,走 else, 2 个以上的组合,走 ifif (i > 1):rulesFromConseq(freqSet, H1, supportData, bigRuleList, minConf)else:calcConf(freqSet, H1, supportData, bigRuleList, minConf)return bigRuleListdef getActionIds():from time import sleepfrom votesmart import votesmart# votesmart.apikey = 'get your api key first'votesmart.apikey = 'a7fa40adec6f4a77178799fae4441030'actionIdList = []billTitleList = []fr = open('input/11.Apriori/recent20bills.txt')for line in fr.readlines():billNum = int(line.split('\t')[0])try:billDetail = votesmart.votes.getBill(billNum) # api callfor action in billDetail.actions:if action.level == 'House' and (action.stage == 'Passage' or action.stage == 'Amendment Vote'):actionId = int(action.actionId)print ('bill: %d has actionId: %d' % (billNum, actionId))actionIdList.append(actionId)billTitleList.append(line.strip().split('\t')[1])except:print ("problem getting bill %d" % billNum)sleep(1) # delay to be politereturn actionIdList, billTitleListdef getTransList(actionIdList, billTitleList): #this will return a list of lists containing intsitemMeaning = ['Republican', 'Democratic']#list of what each item stands forfor billTitle in billTitleList:#fill up itemMeaning listitemMeaning.append('%s -- Nay' % billTitle)itemMeaning.append('%s -- Yea' % billTitle)transDict = {}#list of items in each transaction (politician)voteCount = 2for actionId in actionIdList:sleep(3)print ('getting votes for actionId: %d' % actionId)try:voteList = votesmart.votes.getBillActionVotes(actionId)for vote in voteList:if not transDict.has_key(vote.candidateName):transDict[vote.candidateName] = []if vote.officeParties == 'Democratic':transDict[vote.candidateName].append(1)elif vote.officeParties == 'Republican':transDict[vote.candidateName].append(0)if vote.action == 'Nay':transDict[vote.candidateName].append(voteCount)elif vote.action == 'Yea':transDict[vote.candidateName].append(voteCount + 1)except:print ("problem getting actionId: %d" % actionId)voteCount += 2return transDict, itemMeaning# 暂时没用上
# def pntRules(ruleList, itemMeaning):
# for ruleTup in ruleList:
# for item in ruleTup[0]:
# print itemMeaning[item]
# print " -------->"
# for item in ruleTup[1]:
# print itemMeaning[item]
# print "confidence: %f" % ruleTup[2]
# print #print a blank linedef testApriori():# 加载测试数据集dataSet = loadDataSet()print ('dataSet: ', dataSet)# Apriori 算法生成频繁项集以及它们的支持度L1, supportData1 = apriori(dataSet, minSupport=0.7)print ('L(0.7): ', L1)print ('supportData(0.7): ', supportData1)print ('->->->->->->->->->->->->->->->->->->->->->->->->->->->->')# Apriori 算法生成频繁项集以及它们的支持度L2, supportData2 = apriori(dataSet, minSupport=0.5)print ('L(0.5): ', L2)print ('supportData(0.5): ', supportData2)def testGenerateRules():# 加载测试数据集dataSet = loadDataSet()print ('dataSet: ', dataSet)# Apriori 算法生成频繁项集以及它们的支持度L1, supportData1 = apriori(dataSet, minSupport=0.5)print ('L(0.7): ', L1)print ('supportData(0.7): ', supportData1)# 生成关联规则rules = generateRules(L1, supportData1, minConf=0.5)print ('rules: ', rules)def main():# 测试 Apriori 算法# testApriori()# 生成关联规则# testGenerateRules()##项目案例# # 构建美国国会投票记录的事务数据集# actionIdList, billTitleList = getActionIds()# # 测试前2个# transDict, itemMeaning = getTransList(actionIdList[: 2], billTitleList[: 2])#transDict 表示 action_id的集合,transDict[key]这个就是action_id对应的选项,例如 [1, 2, 3]# transDict, itemMeaning = getTransList(actionIdList, billTitleList)# # 得到全集的数据# dataSet = [transDict[key] for key in transDict.keys()]# L, supportData = apriori(dataSet, minSupport=0.3)# rules = generateRules(L, supportData, minConf=0.95)# print (rules)# # 项目案例# # 发现毒蘑菇的相似特性# # 得到全集的数据dataSet = [line.split() for line in open("datalab/6132/mushroom.txt").readlines()]L, supportData = apriori(dataSet, minSupport=0.3)# # 2表示毒蘑菇,1表示可食用的蘑菇# # 找出关于2的频繁子项出来,就知道如果是毒蘑菇,那么出现频繁的也可能是毒蘑菇for item in L[1]:if item.intersection('2'):print (item)for item in L[2]:if item.intersection('2'):print (item)if __name__ == "__main__":main()Created on Mar 24, 2011
Update on 2017-05-18
Ch 11 code
@author: Peter/片刻
《机器学习实战》更新地址:https://github.com/apachecn/MachineLearning
frozenset({‘2’, ‘28’})
frozenset({‘2’, ‘53’})
frozenset({‘2’, ‘23’})
frozenset({‘34’, ‘2’})
frozenset({‘2’, ‘36’})
frozenset({‘2’, ‘59’})
frozenset({‘2’, ‘63’})
frozenset({‘2’, ‘67’})
frozenset({‘2’, ‘76’})
frozenset({‘2’, ‘85’})
frozenset({‘2’, ‘86’})
frozenset({‘2’, ‘90’})
frozenset({‘2’, ‘93’})
frozenset({‘39’, ‘2’})
frozenset({‘39’, ‘53’, ‘2’})
frozenset({‘2’, ‘53’, ‘90’})
frozenset({‘2’, ‘53’, ‘86’})
frozenset({‘2’, ‘53’, ‘85’})
frozenset({‘34’, ‘2’, ‘53’})
frozenset({‘39’, ‘2’, ‘28’})
frozenset({‘2’, ‘90’, ‘28’})
frozenset({‘2’, ‘86’, ‘28’})
frozenset({‘2’, ‘28’, ‘85’})
frozenset({‘2’, ‘28’, ‘63’})
frozenset({‘59’, ‘2’, ‘28’})
frozenset({‘2’, ‘53’, ‘28’})
frozenset({‘34’, ‘2’, ‘28’})
frozenset({‘39’, ‘2’, ‘93’})
frozenset({‘2’, ‘39’, ‘90’})
frozenset({‘2’, ‘39’, ‘86’})
frozenset({‘39’, ‘2’, ‘85’})
frozenset({‘39’, ‘2’, ‘76’})
frozenset({‘2’, ‘39’, ‘67’})
frozenset({‘39’, ‘2’, ‘63’})
frozenset({‘39’, ‘2’, ‘59’})
frozenset({‘39’, ‘36’, ‘2’})
frozenset({‘39’, ‘23’, ‘2’})
frozenset({‘2’, ‘90’, ‘93’})
frozenset({‘2’, ‘86’, ‘93’})
frozenset({‘90’, ‘2’, ‘86’})
frozenset({‘93’, ‘2’, ‘85’})
frozenset({‘2’, ‘90’, ‘85’})
frozenset({‘2’, ‘86’, ‘85’})
frozenset({‘2’, ‘86’, ‘76’})
frozenset({‘2’, ‘85’, ‘76’})
frozenset({‘86’, ‘2’, ‘67’})
frozenset({‘2’, ‘67’, ‘85’})
frozenset({‘93’, ‘2’, ‘63’})
frozenset({‘2’, ‘90’, ‘63’})
frozenset({‘2’, ‘86’, ‘63’})
frozenset({‘2’, ‘85’, ‘63’})
frozenset({‘2’, ‘59’, ‘93’})
frozenset({‘2’, ‘90’, ‘59’})
frozenset({‘2’, ‘86’, ‘59’})
frozenset({‘2’, ‘59’, ‘85’})
frozenset({‘2’, ‘59’, ‘63’})
frozenset({‘2’, ‘36’, ‘93’})
frozenset({‘2’, ‘36’, ‘90’})
frozenset({‘2’, ‘36’, ‘86’})
frozenset({‘2’, ‘36’, ‘85’})
frozenset({‘2’, ‘36’, ‘63’})
frozenset({‘2’, ‘36’, ‘59’})
frozenset({‘34’, ‘2’, ‘93’})
frozenset({‘34’, ‘2’, ‘90’})
frozenset({‘34’, ‘2’, ‘86’})
frozenset({‘34’, ‘2’, ‘85’})
frozenset({‘34’, ‘2’, ‘76’})
frozenset({‘34’, ‘2’, ‘67’})
frozenset({‘34’, ‘2’, ‘63’})
frozenset({‘34’, ‘2’, ‘59’})
frozenset({‘34’, ‘2’, ‘36’})
frozenset({‘34’, ‘2’, ‘23’})
frozenset({‘34’, ‘39’, ‘2’})
frozenset({‘2’, ‘23’, ‘93’})
frozenset({‘2’, ‘23’, ‘90’})
frozenset({‘2’, ‘23’, ‘86’})
frozenset({‘2’, ‘23’, ‘85’})
frozenset({‘2’, ‘23’, ‘63’})
frozenset({‘2’, ‘23’, ‘59’})
frozenset({‘2’, ‘23’, ‘36’})
相关文章:
数据挖掘十大算法--Apriori算法
一、Apriori 算法概述 Apriori 算法是一种用于关联规则挖掘的经典算法。它用于在大规模数据集中发现频繁项集,进而生成关联规则。关联规则揭示了数据集中项之间的关联关系,常被用于市场篮分析、推荐系统等应用。 以下是 Apriori 算法的基本概述&#x…...

[蓝桥杯 2022 省 B] 统计子矩阵
题目描述 给定一个 NM 的矩阵 A,请你统计有多少个子矩阵 (最小 11, 最大 NM) 满足子矩阵中所有数的和不超过给定的整数 K。 输入格式 第一行包含三个整数 N, M和 K。 之后 N 行每行包含 M 个整数, 代表矩阵 A。 输出格式 一个整数代表答案。 输入输出样例 输入 #1 3…...

解决在部署springboot项目的docker中执行备份与之相连接的mysql容器命令
文章目录 问题描述解决思路问题解决容器构建mysql客户端安装容器与主机的交互docker中执行 mysqldump 命令解决mysql8密码验证问题解决密码插件警告 问题描述 由于,使用1panel可视化的面板来部署springboot项目,可以很方便地安装和使用mysql,…...

正文Delphi XE Android下让TMemo不自动弹出键盘
用TMemo来显示一段说明文字,可一点Memo,就弹出键盘,找了半天控制键盘的属性,没找到。最后将readOnly设置为True搞定。 如果需要一个form都不显示keyboard,那么可以利用全局变量 VKAutoShowMode来控制,这个全局变量可以有下面三个值…...

[1Panel]开源,现代化,新一代的 Linux 服务器运维管理面板
测评介绍 本期测评试用一下1Panel这款面板。1Panel是国内飞致云旗下开源产品。整个界面简洁清爽,后端使用GO开发,前端使用VUE的Element-Plus作为UI框架,整个面板的管理都是基于docker的,想法很先进。官方还提供了视频的使用教程&…...
PG集合查询
1.运算符 1.1 union并集 连接上下语句 union distinct连接并且去重 all不去重 1.2 intersect交集 上下交集 distinct连接并且去重 all不去重 1.3 except除外 上面除了下面 distinc去重 all不去重...
目标检测应用场景和发展趋势
参考: 目标检测的未来是什么? - 知乎 (zhihu.com)https://www.zhihu.com/question/394900756/answer/32489649815大应用场景 1 行人检测: 遮挡问题:行人之间的互动和遮挡是非常常见的,这给行人检测带来了挑战。非刚性…...
Confluence 自定义博文列表
1. 概述 Confluence 自有博文列表无法实现列表自定义功能,实现该需求可采用页面中引用博文宏标签控制的方式 2. 实现方式 功能入口: Confluence →指定空间→创建页面 功能说明: (1)页面引用博文宏 (…...

chrome历史版本下载
chrome历史版本下载 windows Google Chrome all versions on Windows linux版本 Google Chrome 64bit Linux版_chrome浏览器,chrome插件,谷歌浏览器下载,谈笑有鸿儒...
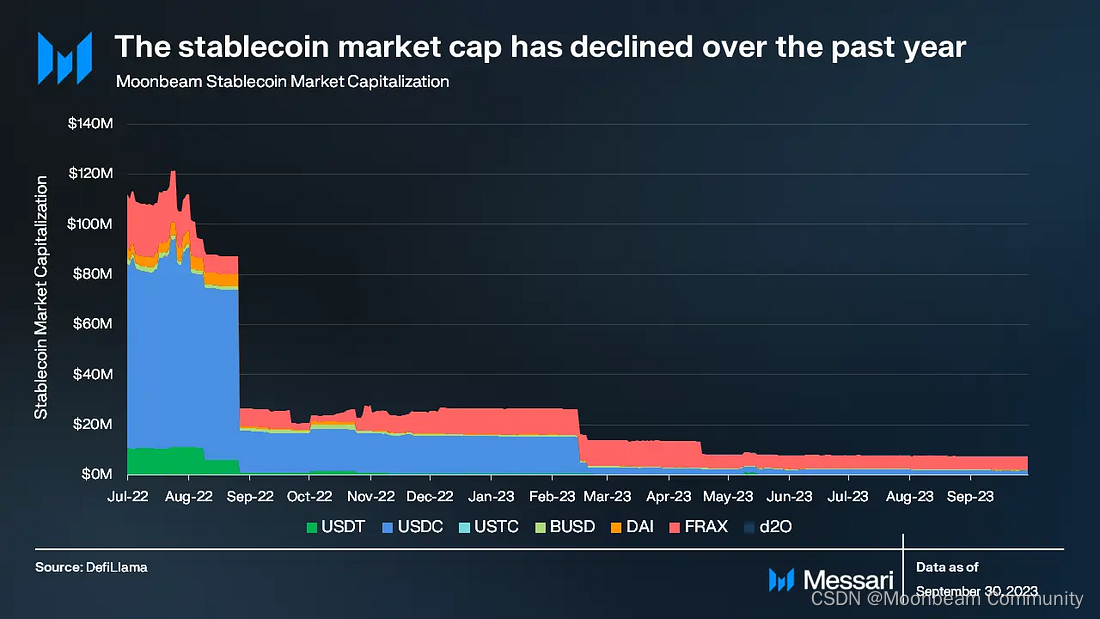
Messari发布Moonbeam简报,每日交易量稳步增长,首次公布利润数据
区块链数据公司Messari首次发布Moonbeam项目分析简报,从项目市值、链上数据表现、质押以及Moonbeam的技术优势XCM使用量等角度全面分析。这个再熊市初期上线的项目一直在默默开发,并在跨链互操作领域拥有了相当的实操成绩。我们翻译了Messari简报中的部分…...

数据库 锁、索引、在实际开发中怎么设置和优化
数据库锁和索引是数据库管理的两个重要方面,它们对于确保数据的一致性和提高查询性能具有重要作用。在实际开发中,正确地设置和优化锁和索引对于构建高效、稳定的系统至关重要。下面是一些关于如何在实际开发中设置和优化锁和索引的建议: 锁…...
超详细彻底卸载Anaconda详细教程
一、在开始处打开Anaconda Prompt 二、打开后,输入conda install tqdm -f命令并按回车键 conda install tqdm -f三、之后页面会出现一个WANNING,这个我们不用在意,然后会出现一个y/n提示框,在这里我们输入y或者Y y四、输入cond…...
Python--随机出拳(random)--if判断--综合案例练习:石头剪刀布
注:涉及相关链接: Python:if判断--综合案例练习:石头剪刀布-CSDN博客 Python语言非常的强大,强大之处就在于其拥有很多模块(module),这些模块中拥有很多别人已经开发好的代码&…...

微信小程序里配置less
介绍 在微信小程序里,样式文件的后缀名都是wxss,这导致一个问题,就是页面样式过多的时候,要写很多的类名来包裹,加大了工作量,还很有可能会写错样式。这时可以配置一个less,会大大提高代码编辑…...
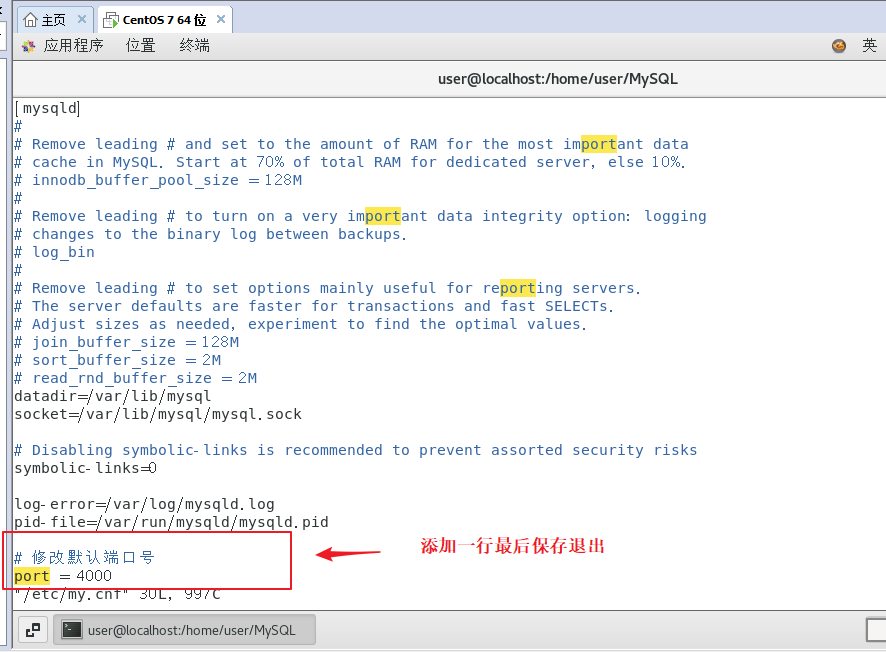
MySq修改配置文件
要修改 MySQL 的配置文件,您可以按照以下步骤进行操作: 1、打开 MySQL 的配置文件 在大多数 Linux 系统上,默认的配置文件路径是 /etc/my.cnf 或 /etc/mysql/my.cnf。您可以使用文本编辑器(如 vim、nano)以管理员权限打开该文件。 sudo vim /etc/my.cnf 2、进行修改 …...
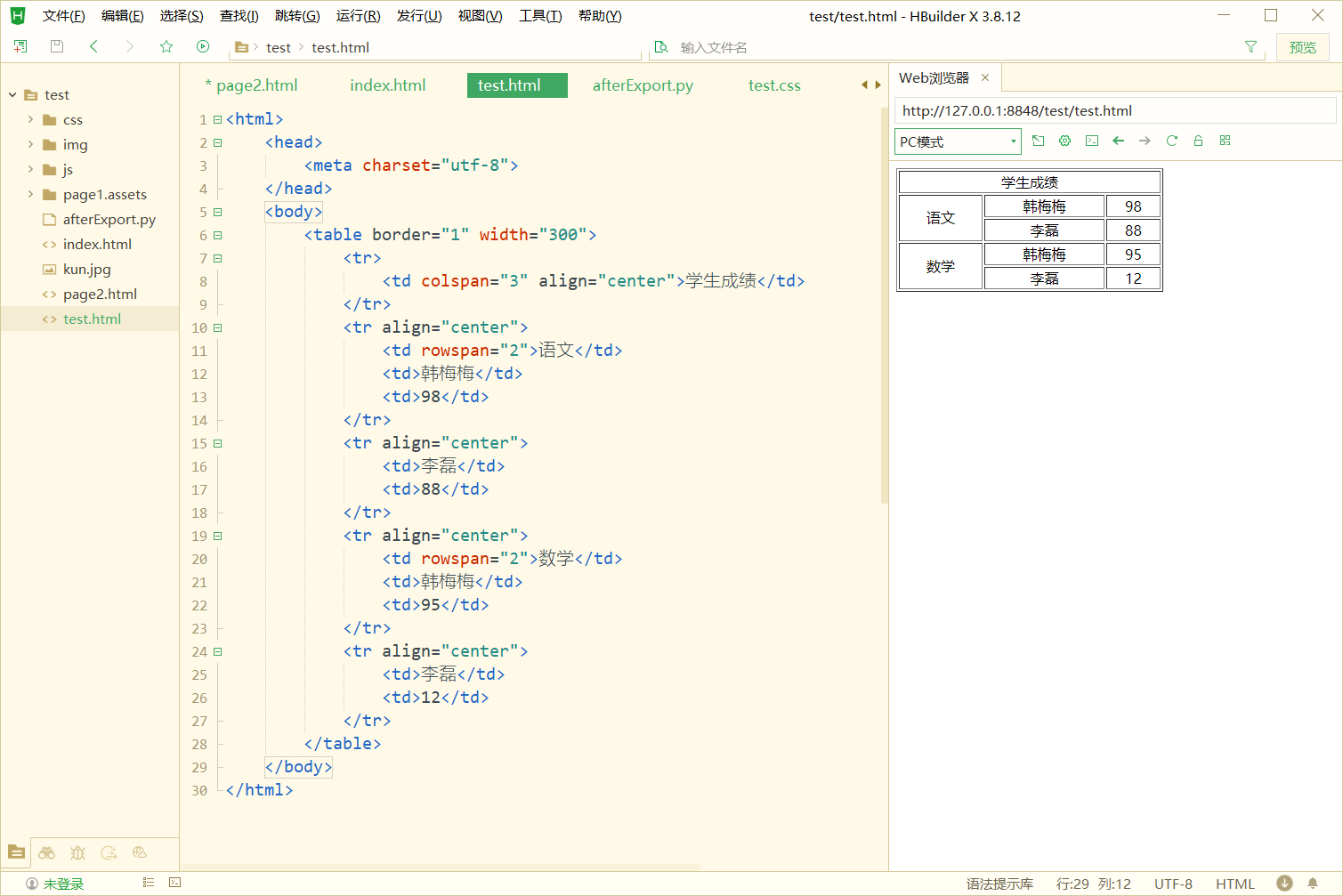
HTML 表格及练习
表格 概述 表格是一种二维结构,横行纵列。 由单元格组成。 表格是一种非常“强” 的结构: 每一行有相同的列数(单元格),每一列有相同的行数(单元格) 同一列的单元格,宽度&#…...
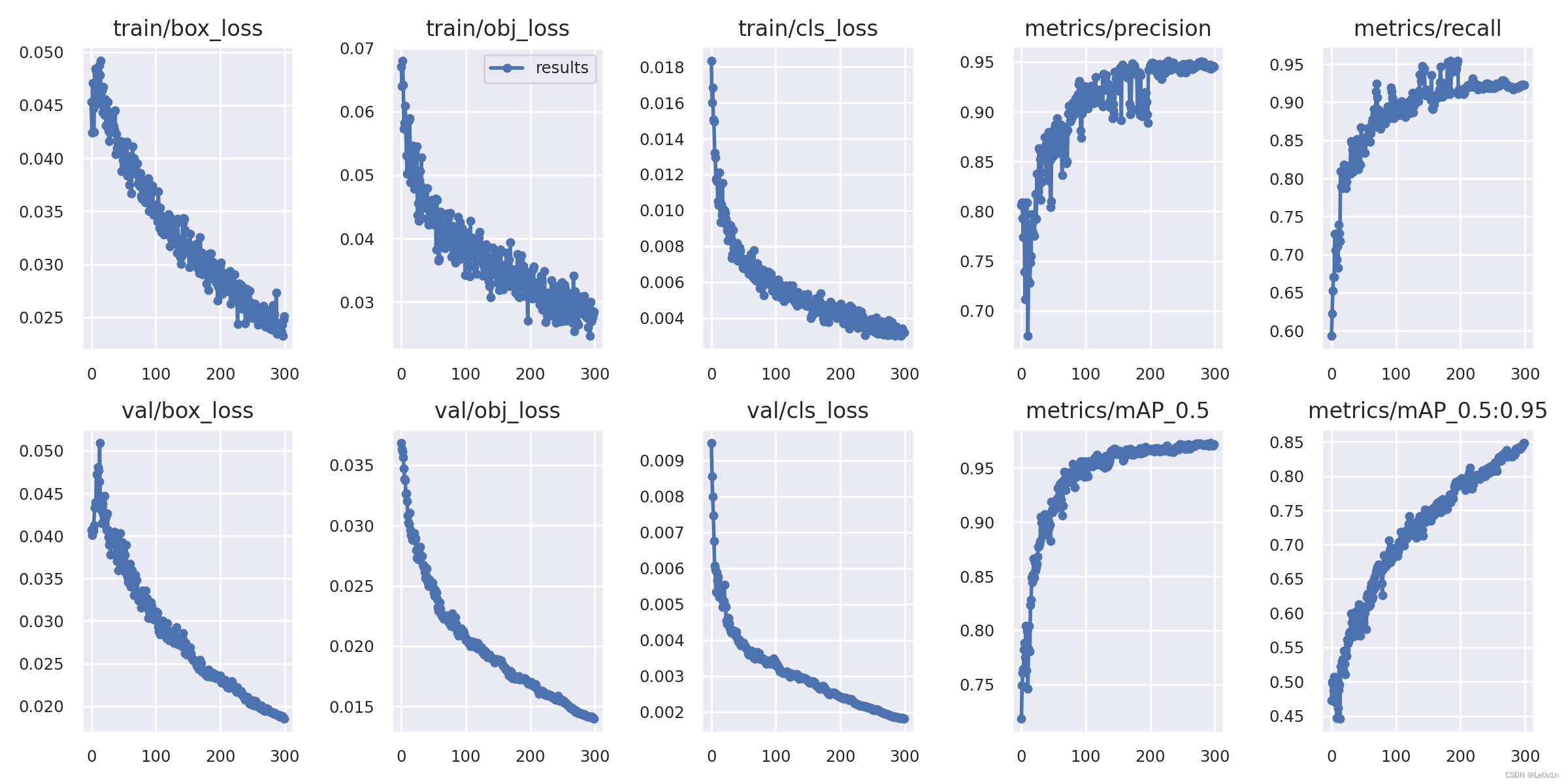
YOLOv5-训练自己的VOC格式数据集(VOC、自建数据集)
YOLOv5:训练自己的 VOC 格式数据集 1. 自定义数据集 1.1 环境安装 pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple注意: 安装 lxmlPillow 版本要低于 10.0.0,解释链接: module ‘PIL.Image’ has no attri…...
基于Java的考研信息查询系统设计与实现(源码+lw+部署文档+讲解等)
文章目录 前言具体实现截图论文参考详细视频演示为什么选择我自己的网站自己的小程序(小蔡coding) 代码参考数据库参考源码获取 前言 💗博主介绍:✌全网粉丝10W,CSDN特邀作者、博客专家、CSDN新星计划导师、全栈领域优质创作者&am…...

Linux性能优化--性能追踪:受CPU限制的应用程序(GIMP)
10.0 概述 本章包含了一个例子:如何用Linux性能工具在受CPU限制的应用程序中寻找并修复性能问题。 阅读本章后,你将能够: 在受CPU限制的应用程序中明确所有的CPU被哪些源代码行使用。用1trace和oprofile弄清楚应用程序调用各种内部与外部函…...
BERT变体(1):ALBERT、RoBERTa、ELECTRA、SpanBERT
Author:龙箬 Computer Application Technology Change the World with Data and Artificial Intelligence ! CSDNweixin_43975035 *天下之大,虽离家万里,何处不可往!何事不可为! 1. ALBERT \qquad ALBERT的英文全称为A Lite versi…...

OpenClaw可视化监控:为nanobot任务添加Web仪表盘
OpenClaw可视化监控:为nanobot任务添加Web仪表盘 1. 为什么需要可视化监控? 去年夏天,我部署了一个基于OpenClaw的nanobot自动化任务,用于定时抓取行业动态并生成日报。最初几周运行良好,直到某天早上发现连续三天的…...

AS_BH1750库:BH1750FVI环境光传感器嵌入式驱动设计与工程实践
1. AS_BH1750库概述:面向嵌入式系统的BH1750FVI环境光传感器驱动设计与工程实践BH1750FVI是由ROHM Semiconductor推出的高精度数字环境光传感器(Ambient Light Sensor, ALS),采用IC接口,具备宽动态范围(0.1…...

RAG的墓志铭:当AI不再需要检索
上个月读到一篇在 Hacker News 上引发热议的文章——《The RAG Obituary: Killed by Agents, Buried by Context Windows》。作者 Nicolas Bustamante 是金融科技公司 Fintool 的创始人,他在文中抛出了一个颇具争议的观点:RAG(检索增强生成&a…...

突破性解决方案:3步解决Calibre中文路径乱码,实现100%原生中文支持
突破性解决方案:3步解决Calibre中文路径乱码,实现100%原生中文支持 【免费下载链接】calibre-do-not-translate-my-path Switch my calibre library from ascii path to plain Unicode path. 将我的书库从拼音目录切换至非纯英文(中文&#x…...

光储充系统实战笔记:当光伏遇到充电桩的硬核玩法
光储充交直流三相并网/离网系统 基于Matlab三相光伏储能充电桩(光储充一体化) 关键词:光伏大功率 储能 充电桩 LLC 电池 并网PQ控制 SPWM 恒压/恒流充电 提供两个仿真可对比看效果,如图一,二。 点击“加好友”可先看…...

高通平台USB充电背后的秘密:从SBL1阶段到Kernel的电池ID识别全解析
高通平台USB充电与电池ID识别的深度技术解析 在Android设备开发中,电源管理系统的稳定性直接影响用户体验。作为底层驱动工程师,理解高通平台从硬件到软件的完整充电流程至关重要。本文将深入剖析从XBL阶段到Kernel层的电池识别机制,揭示BATT…...

python-flask-djangol框架的婚恋相亲交友网站
目录技术选型与框架对比核心功能模块设计数据库模型示例(Django ORM)安全防护措施部署方案开发路线图项目技术支持源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作技术选型与框架对比 Flask:轻量级框架&a…...

美国是如何对GEO进行监管的?
一、GEO投毒并不是中国独有 2026年央视“315”晚会首次把“GEO投毒”这一灰色产业链推到台前。所谓“投毒”,说白了,就是有人通过批量制造虚假信息、污染训练或检索数据,去干扰AI的推荐和回答结果,最后把一些虚假、低质甚至根本不…...

FreeRTOS实战指南:从消息队列到内存管理,手把手解决嵌入式多任务难题
FreeRTOS实战指南:从消息队列到内存管理,手把手解决嵌入式多任务难题 1. 为什么嵌入式开发者需要FreeRTOS 在资源受限的嵌入式系统中,开发者常常面临这样的困境:既要处理实时性要求高的传感器数据采集,又要兼顾用户界面…...

拯救大模型“幻觉”?Python RAG九大架构全解析
别让你的AI助手,从“得力员工”变成“职场骗子” 你是否也曾被大模型的“一本正经胡说八道”气到无语? 你精心部署的客服机器人,自信地告诉客户:“我们的退货政策是90天!”——而实际上,公司的规定是30天…...