YOLOv5-训练自己的VOC格式数据集(VOC、自建数据集)
1. 自定义数据集
1.1 环境安装
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
注意:
- 安装
lxml - Pillow 版本要低于 10.0.0,解释链接: module ‘PIL.Image’ has no attribute ‘ANTIALIAS’ 问题处理
1.2 创建数据集
我们自己下载 PASCAL VOC 也行,按照 PASCAL VOC 自建一个也行,具体过程见 PASCAL VOC 2012数据集讲解与制作自己的数据集。
文章不长
1.3 PASCAL VOC 数据集结构
PASCAL VOC 数据集结构如下所示。
PASCAL VOC 2012 数据集
|
├── VOC2012
| ├── JPEGImages # 包含所有图像文件
| | ├── 2007_000027.jpg
| | ├── 2007_000032.jpg
| | ├── ...
| |
| ├── Annotations # 包含所有标注文件(XML格式)
| | ├── 2007_000027.xml
| | ├── 2007_000032.xml
| | ├── ...
| |
| ├── ImageSets
| | ├── Main
| | | ├── train.txt # 训练集的图像文件列表
| | | ├── val.txt # 验证集的图像文件列表
| | | ├── test.txt # 测试集的图像文件列表
| |
| ├── SegmentationClass # 语义分割的标注
| | ├── 2007_000032.png
| | ├── ...
| |
| ├── SegmentationObject # 物体分割的标注
| | ├── 2007_000032.png
| | ├── ...
| |
| ├── ... # 其他可能的子文件夹
|
├── VOCdevkit
| ├── VOCcode # 包含用于处理数据集的工具代码
|
├── README
我们可以看到,对于我们来说,我们只需要两个文件夹就可以了。
- JPEGImages: 存放所有的图片
- Annotations: 存放所有的标注信息
这里我们从 PASCAL VOC 中提取出几张图片,组成 VOC2012-Lite:
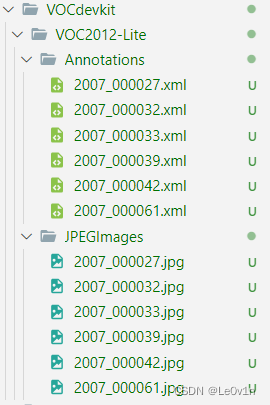
即此时我们的数据集结构为:
VOCdevkit
└─VOC2012-Lite├─Annotations│ 2007_000027.xml│ 2007_000032.xml│ 2007_000033.xml│ 2007_000039.xml│ 2007_000042.xml│ 2007_000061.xml│ ...│└─JPEGImages2007_000027.jpg2007_000032.jpg2007_000033.jpg2007_000039.jpg2007_000042.jpg2007_000061.jpg...
需要注意的是,YOLOv5 的要求标注文件后缀为 .txt,但 Annotations 中的文件后缀是 .xml,所以我们需要进行转换。
标注文件举例:
0 0.481719 0.634028 0.690625 0.713278
1 0.741094 0.524306 0.314750 0.933389
2 0.254162 0.247742 0.574520 0.687422
其中,每行代表一个物体的标注,每个标注包括五个值,分别是:
<class_id>:物体的类别标识符。在这里,有三个不同的类别,分别用 0、1 和 2 表示。<center_x>:物体边界框的中心点 x 坐标,归一化到图像宽度。这些值的范围应在 0 到 1 之间。<center_y>:物体边界框的中心点 y 坐标,归一化到图像高度。同样,这些值的范围应在 0 到 1 之间。<width>:物体边界框的宽度,归一化到图像宽度。<height>:物体边界框的高度,归一化到图像高度。
以第一行为例:
<class_id>是 0,表示这个物体属于类别 0。<center_x>是 0.481719,这意味着物体边界框的中心点 x 坐标位于图像宽度的 48.17% 处。<center_y>是 0.634028,中心点 y 坐标位于图像高度的 63.40% 处。<width>是 0.690625,边界框宽度占图像宽度的 69.06%。<height>是 0.713278,边界框高度占图像高度的 71.33%。
1.4 YOLO 想要的数据集结构
1.4.1 YOLOv3
一般而言,YOLOv3 想要的数据结构如下所示:
YOLOv3 数据集
|
├── images # 包含所有图像文件
| ├── image1.jpg
| ├── image2.jpg
| ├── ...
|
├── labels # 包含所有标注文件(每个图像对应一个标注文件)
| ├── image1.txt
| ├── image2.txt
| ├── ...
|
├── classes.names # 类别文件,包含所有类别的名称
|
├── train.txt # 训练集的图像文件列表
├── valid.txt # 验证集的图像文件列表
1.4.2 YOLOv5
与 YOLOv3 不同,YOLOv5 所需要的数据集结构如下所示:
|-- test
| |-- images
| | |-- 000000000036.jpg
| | `-- 000000000042.jpg
| `-- labels
| |-- 000000000036.txt
| `-- 000000000042.txt
|-- train
| |-- images
| | |-- 000000000009.jpg
| | `-- 000000000025.jpg
| `-- labels
| |-- 000000000009.txt
| `-- 000000000025.txt
`-- val|-- images| |-- 000000000030.jpg| `-- 000000000034.jpg`-- labels|-- 000000000030.txt`-- 000000000034.txt
既然我们已经知道了 YOLOv5 所需要的数据集格式,那么就可以动手了!
1.5 将 PASCAL VOC 数据集转换为 YOLOv5 数据集格式
"""
本脚本有两个功能:1. 将 voc 数据集标注信息(.xml)转为 yolo 标注格式(.txt),并将图像文件复制到相应文件夹2. 根据 json 标签文件,生成对应 names 标签(my_data_label.names)3. 兼容 YOLOv3 和 YOLOv5
"""
import os
from tqdm import tqdm
from lxml import etree
import json
import shutil
import argparse
from tqdm import tqdm
from prettytable import PrettyTable
from sklearn.model_selection import train_test_splitdef args_table(args):# 创建一个表格table = PrettyTable(["Parameter", "Value"])table.align["Parameter"] = "l" # 使用 "l" 表示左对齐table.align["Value"] = "l" # 使用 "l" 表示左对齐# 将args对象的键值对添加到表格中for key, value in vars(args).items():# 处理列表的特殊格式if isinstance(value, list):value = ', '.join(map(str, value))table.add_row([key, value])# 返回表格的字符串表示return str(table)def generate_train_and_val_txt(args):target_train_file = args.train_txt_pathtarget_val_file = args.val_txt_path# 获取源文件夹中的所有文件files = os.listdir(args.voc_images_path)# 划分训练集和验证集train_images, val_images = train_test_split(files, test_size=args.val_size, random_state=args.seed)# 打开目标文件以写入模式with open(target_train_file, 'w', encoding='utf-8') as f:# 使用tqdm创建一个进度条,迭代源文件列表for file in tqdm(train_images, desc=f"\033[1;33mProcessing Files for train\033[0m"):file_name, _ = os.path.splitext(file)# 写入文件名f.write(f'{file_name}\n')with open(target_val_file, 'w', encoding='utf-8') as f:# 使用tqdm创建一个进度条,迭代源文件列表for file in tqdm(val_images, desc=f"\033[1;33mProcessing Files for val\033[0m"):file_name, _ = os.path.splitext(file)# 写入文件名f.write(f'{file_name}\n')print(f"\033[1;32m文件名已写入到 {target_train_file} 和 {target_val_file} 文件中!\033[0m")def parse_args():# 创建解析器parser = argparse.ArgumentParser(description="将 .xml 转换为 .txt")# 添加参数parser.add_argument('--voc_root', type=str, default="VOCdevkit", help="PASCAL VOC路径(之后的所有路径都在voc_root下)")parser.add_argument('--voc_version', type=str, default="VOC2012-Lite", help="VOC 版本")parser.add_argument('--save_path', type=str, default="VOC2012-YOLO", help="转换后的保存目录路径")parser.add_argument('--train_list_name', type=str, default="train.txt", help="训练图片列表名称")parser.add_argument('--val_list_name', type=str, default="val.txt", help="验证图片列表名称")parser.add_argument('--val_size', type=float, default=0.1, help="验证集比例")parser.add_argument('--seed', type=int, default=42, help="随机数种子")parser.add_argument('--num_classes', type=int, default=20, help="数据集类别数(用于校验)")parser.add_argument('--classes', help="数据集具体类别数(用于生成 classes.json 文件)", default=['aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat','chair', 'cow', 'diningtable', 'dog', 'horse', 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor'])return parser.parse_args()def configure_path(args):# 转换的训练集以及验证集对应txt文件args.train_txt = "train.txt"args.val_txt = "val.txt"# 转换后的文件保存目录args.save_file_root = os.path.join(args.voc_root, args.save_path)# 生成json文件# label标签对应json文件args.label_json_path = os.path.join(args.voc_root, "classes.json")# 创建一个将类别与数值关联的字典class_mapping = {class_name: index + 1 for index, class_name in enumerate(args.classes)}with open(args.label_json_path, 'w', encoding='utf-8') as json_file:json.dump(class_mapping, json_file, ensure_ascii=False, indent=4)print(f'\033[1;31m类别列表已保存到 {args.label_json_path}\033[0m')# 拼接出voc的images目录,xml目录,txt目录args.voc_images_path = os.path.join(args.voc_root, args.voc_version, "JPEGImages")args.voc_xml_path = os.path.join(args.voc_root, args.voc_version, "Annotations")args.train_txt_path = os.path.join(args.voc_root, args.voc_version, args.train_txt)args.val_txt_path = os.path.join(args.voc_root, args.voc_version, args.val_txt)# 生成对应的 train.txt 和 val.txtgenerate_train_and_val_txt(args)# 检查文件/文件夹都是否存在assert os.path.exists(args.voc_images_path), f"VOC images path not exist...({args.voc_images_path})"assert os.path.exists(args.voc_xml_path), f"VOC xml path not exist...({args.voc_xml_path})"assert os.path.exists(args.train_txt_path), f"VOC train txt file not exist...({args.train_txt_path})"assert os.path.exists(args.val_txt_path), f"VOC val txt file not exist...({args.val_txt_path})"assert os.path.exists(args.label_json_path), f"label_json_path does not exist...({args.label_json_path})"if os.path.exists(args.save_file_root) is False:os.makedirs(args.save_file_root)print(f"创建文件夹:{args.save_file_root}")def parse_xml_to_dict(xml):"""将xml文件解析成字典形式,参考tensorflow的recursive_parse_xml_to_dictArgs:xml: xml tree obtained by parsing XML file contents using lxml.etreeReturns:Python dictionary holding XML contents."""if len(xml) == 0: # 遍历到底层,直接返回tag对应的信息return {xml.tag: xml.text}result = {}for child in xml:child_result = parse_xml_to_dict(child) # 递归遍历标签信息if child.tag != 'object':result[child.tag] = child_result[child.tag]else:if child.tag not in result: # 因为object可能有多个,所以需要放入列表里result[child.tag] = []result[child.tag].append(child_result[child.tag])return {xml.tag: result}def translate_info(file_names: list, save_root: str, class_dict: dict, train_val='train', args=None):"""将对应xml文件信息转为yolo中使用的txt文件信息:param file_names::param save_root::param class_dict::param train_val::return:"""save_txt_path = os.path.join(save_root, train_val, "labels")if os.path.exists(save_txt_path) is False:os.makedirs(save_txt_path)save_images_path = os.path.join(save_root, train_val, "images")if os.path.exists(save_images_path) is False:os.makedirs(save_images_path)for file in tqdm(file_names, desc="translate {} file...".format(train_val)):# 检查下图像文件是否存在img_path = os.path.join(args.voc_images_path, file + ".jpg")assert os.path.exists(img_path), "file:{} not exist...".format(img_path)# 检查xml文件是否存在xml_path = os.path.join(args.voc_xml_path, file + ".xml")assert os.path.exists(xml_path), "file:{} not exist...".format(xml_path)# read xmlwith open(xml_path) as fid:xml_str = fid.read()xml = etree.fromstring(xml_str)data = parse_xml_to_dict(xml)["annotation"]img_height = int(data["size"]["height"])img_width = int(data["size"]["width"])# write object info into txtassert "object" in data.keys(), "file: '{}' lack of object key.".format(xml_path)if len(data["object"]) == 0:# 如果xml文件中没有目标就直接忽略该样本print("Warning: in '{}' xml, there are no objects.".format(xml_path))continuewith open(os.path.join(save_txt_path, file + ".txt"), "w") as f:for index, obj in enumerate(data["object"]):# 获取每个object的box信息xmin = float(obj["bndbox"]["xmin"])xmax = float(obj["bndbox"]["xmax"])ymin = float(obj["bndbox"]["ymin"])ymax = float(obj["bndbox"]["ymax"])class_name = obj["name"]class_index = class_dict[class_name] - 1 # 目标id从0开始# 进一步检查数据,有的标注信息中可能有w或h为0的情况,这样的数据会导致计算回归loss为nanif xmax <= xmin or ymax <= ymin:print("Warning: in '{}' xml, there are some bbox w/h <=0".format(xml_path))continue# 将box信息转换到yolo格式xcenter = xmin + (xmax - xmin) / 2ycenter = ymin + (ymax - ymin) / 2w = xmax - xminh = ymax - ymin# 绝对坐标转相对坐标,保存6位小数xcenter = round(xcenter / img_width, 6)ycenter = round(ycenter / img_height, 6)w = round(w / img_width, 6)h = round(h / img_height, 6)info = [str(i) for i in [class_index, xcenter, ycenter, w, h]]if index == 0:f.write(" ".join(info))else:f.write("\n" + " ".join(info))# copy image into save_images_pathpath_copy_to = os.path.join(save_images_path, img_path.split(os.sep)[-1])if os.path.exists(path_copy_to) is False:shutil.copyfile(img_path, path_copy_to)def create_class_names(class_dict: dict, args):keys = class_dict.keys()with open(os.path.join(args.voc_root, "my_data_label.names"), "w") as w:for index, k in enumerate(keys):if index + 1 == len(keys):w.write(k)else:w.write(k + "\n")def main(args):# read class_indictjson_file = open(args.label_json_path, 'r')class_dict = json.load(json_file)# 读取train.txt中的所有行信息,删除空行with open(args.train_txt_path, "r") as r:train_file_names = [i for i in r.read().splitlines() if len(i.strip()) > 0]# voc信息转yolo,并将图像文件复制到相应文件夹translate_info(train_file_names, args.save_file_root, class_dict, "train", args=args)# 读取val.txt中的所有行信息,删除空行with open(args.val_txt_path, "r") as r:val_file_names = [i for i in r.read().splitlines() if len(i.strip()) > 0]# voc信息转yolo,并将图像文件复制到相应文件夹translate_info(val_file_names, args.save_file_root, class_dict, "val", args=args)# 创建my_data_label.names文件create_class_names(class_dict, args=args)if __name__ == "__main__":args = parse_args()configure_path(args)# 美化打印 argsprint(f"\033[1;34m{args_table(args)}\033[0m")# 执行 .xml 转 .txtmain(args)
我们在运行下面命令即可完成转换:
python voc2yolo.py --voc_root ./VOCdevkit --voc_version VOC2012-Lite
转换后的目录结构为:
VOCdevkit
│ classes.json
│ my_data_label.names
│
├─VOC2012-Lite
│ │ train.txt
│ │ val.txt
│ │
│ ├─Annotations
│ │ 2007_000027.xml
│ │ 2007_000032.xml
│ │ 2007_000033.xml
│ │ 2007_000039.xml
│ │ 2007_000042.xml
│ │ 2007_000061.xml
│ │ ...
│ │
│ └─JPEGImages
│ 2007_000027.jpg
│ 2007_000032.jpg
│ 2007_000033.jpg
│ 2007_000039.jpg
│ 2007_000042.jpg
│ 2007_000061.jpg
│ ...
│
└─VOC2012-YOLO├─train│ ├─images│ │ 2007_000032.jpg│ │ 2007_000033.jpg│ │ 2007_000039.jpg│ │ 2007_000042.jpg│ │ 2007_000061.jpg│ │ ...│ ││ └─labels│ 2007_000032.txt│ 2007_000033.txt│ 2007_000039.txt│ 2007_000042.txt│ 2007_000061.txt│ ...│└─val├─images│ 2007_000027.jpg│ ...│└─labels2007_000027.txt...

1.6 YOLOv5 配置文件变动
根据 .yaml 配置文件变动而变动的,这里我们复制 coco128.yaml 为 custom_dataset.yaml 为例:
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
# COCO128 dataset https://www.kaggle.com/ultralytics/coco128 (first 128 images from COCO train2017) by Ultralytics
# Example usage: python train.py --data coco128.yaml
# parent
# ├── yolov5
# └── datasets
# └── coco128 ← downloads here (7 MB)# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: VOCdevkit/VOC2012-YOLO # dataset root dir
train: train/images # train images (relative to 'path') 128 images
val: val/images # val images (relative to 'path') 128 images
test: # test images (optional)# Classes
names:0: person1: bicycle2: car3: motorcycle4: airplane5: bus6: train7: truck8: boat9: traffic light10: fire hydrant...# Download script/URL (optional)
download: https://ultralytics.com/assets/coco128.zip
此时我们就可以使用这个数据集进行 YOLOv5 的模型训练了!
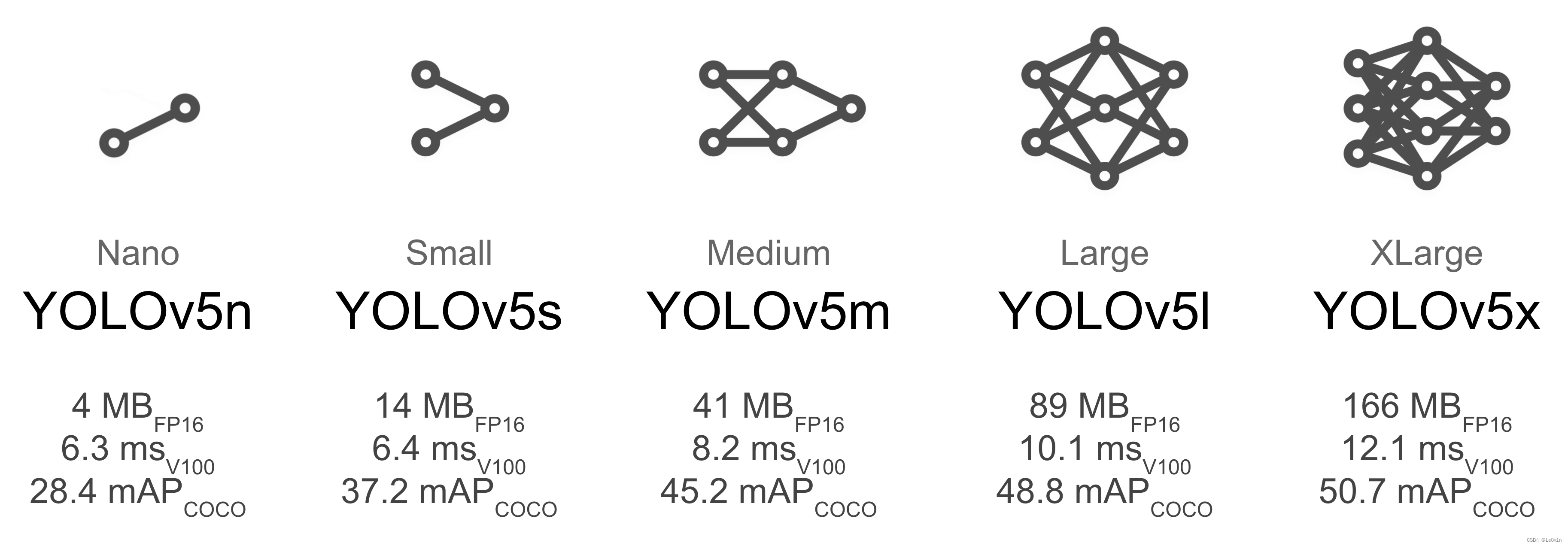
2. 模型选择
我们需要选择一个合适的模型来进行训练,在这里,我们选择 YOLOv5s,这是第二小和速度最快的可用模型。
3. 模型训练
通过指定数据集、批次大小、图像大小以及预训练权重 --weights yolov5s.pt在我们自建的数据集上训练 YOLOv5s 模型。
export CUDA_VISIBLE_DEVICES=4
python train.py --img 640 \--epochs 150 \--data custom_dataset.yaml \--weights weights/yolov5s.pt \--batch-size 32 \--single-cls \--project runs/train \--cos-lr
为了加快训练速度,可以添加 --cache ram 或 --cache disk 选项(需要大量的内存/磁盘资源)。所有训练结果都会保存在 runs/train/ 目录下,每次训练都会创建一个递增的运行目录,例如 runs/train/exp2、runs/train/exp3 等等。
2.5 可视化
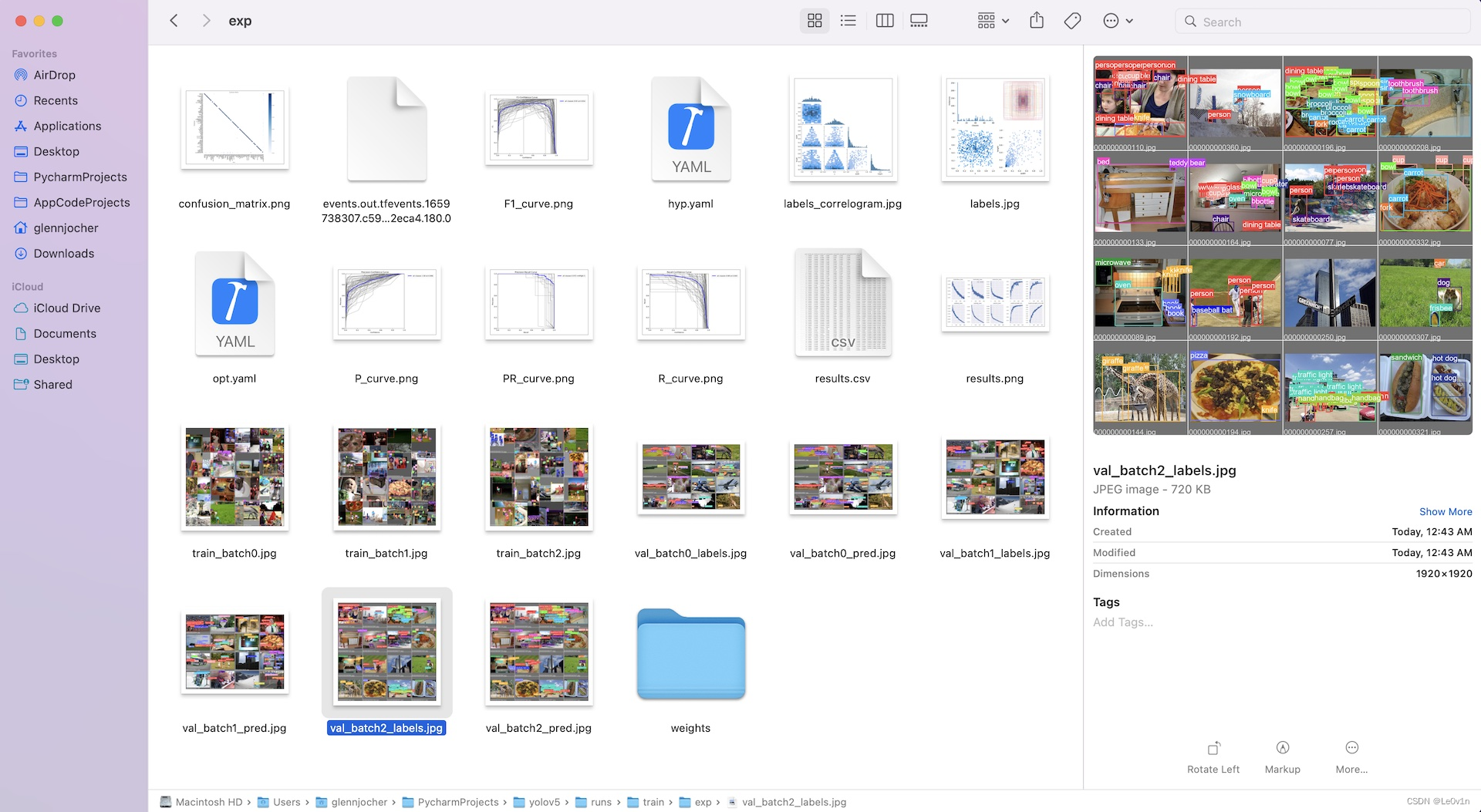
训练结果会自动记录在 Tensorboard 和 CSV 日志记录器中,保存在 runs/train 目录下,每次新的训练都会创建一个新的实验目录,例如 runs/train/exp2、runs/train/exp3 等。
该目录包含了训练和验证的统计数据、马赛克图像、标签、预测结果、以及经过增强的马赛克图像,还包括 Precision-Recall(PR)曲线和混淆矩阵等度量和图表。
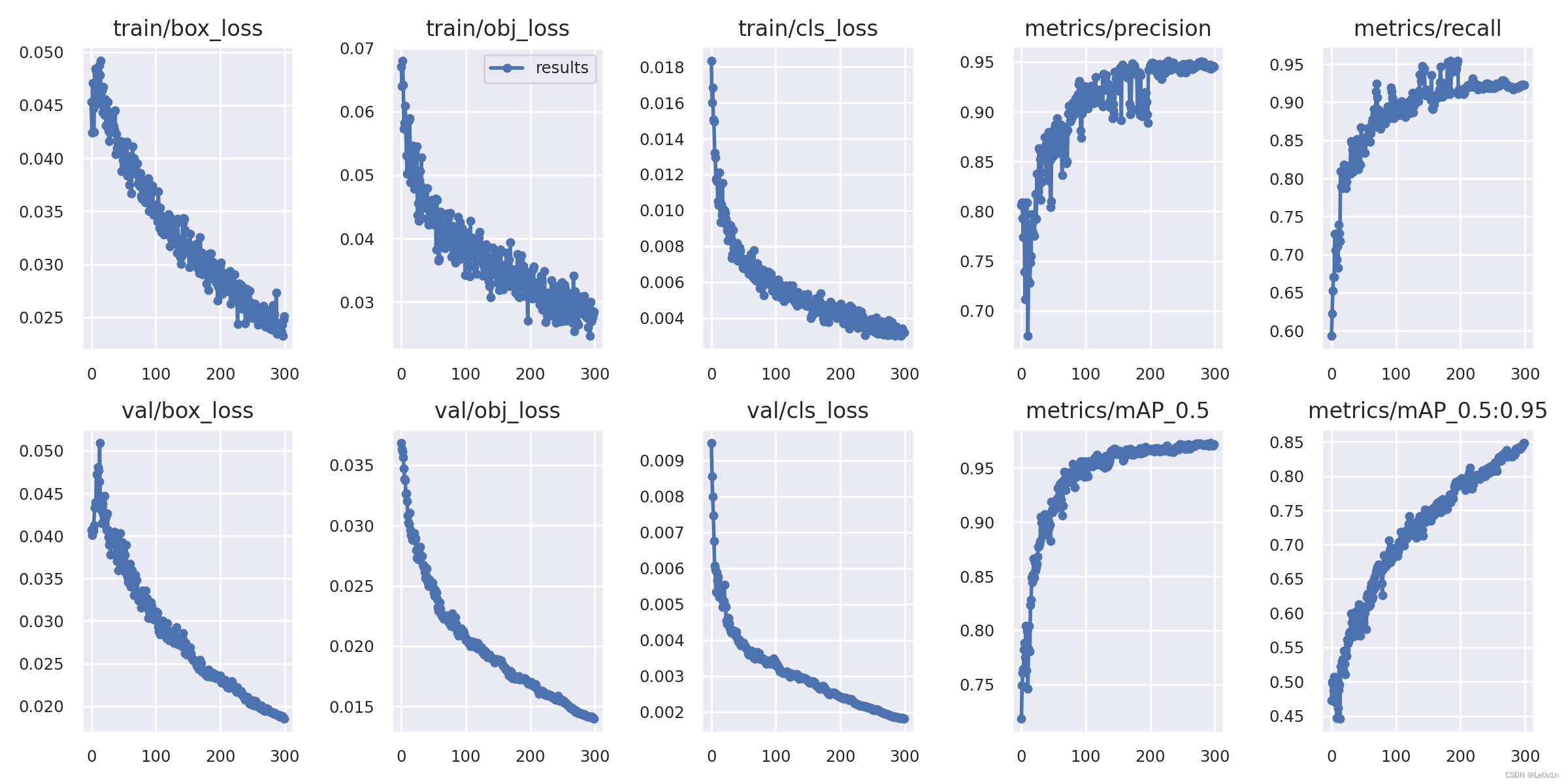
结果文件 results.csv 在每个 Epoch 后更新,然后在训练完成后绘制为 results.png(如下所示)。我们也可以手动绘制任何 results.csv 文件:
from utils.plots import plot_resultsplot_results('path/to/results.csv') # plot 'results.csv' as 'results.png'
知识来源
- Ultralytics YOLOv5 Docs
- 【CSDN】PASCAL VOC 2012 数据集讲解与制作自己的数据集
- 【Bilibili】PASCAL VOC 2012 数据集讲解与制作自己的数据集
- trans_voc2yolo.py
相关文章:
YOLOv5-训练自己的VOC格式数据集(VOC、自建数据集)
YOLOv5:训练自己的 VOC 格式数据集 1. 自定义数据集 1.1 环境安装 pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple注意: 安装 lxmlPillow 版本要低于 10.0.0,解释链接: module ‘PIL.Image’ has no attri…...
基于Java的考研信息查询系统设计与实现(源码+lw+部署文档+讲解等)
文章目录 前言具体实现截图论文参考详细视频演示为什么选择我自己的网站自己的小程序(小蔡coding) 代码参考数据库参考源码获取 前言 💗博主介绍:✌全网粉丝10W,CSDN特邀作者、博客专家、CSDN新星计划导师、全栈领域优质创作者&am…...

Linux性能优化--性能追踪:受CPU限制的应用程序(GIMP)
10.0 概述 本章包含了一个例子:如何用Linux性能工具在受CPU限制的应用程序中寻找并修复性能问题。 阅读本章后,你将能够: 在受CPU限制的应用程序中明确所有的CPU被哪些源代码行使用。用1trace和oprofile弄清楚应用程序调用各种内部与外部函…...
BERT变体(1):ALBERT、RoBERTa、ELECTRA、SpanBERT
Author:龙箬 Computer Application Technology Change the World with Data and Artificial Intelligence ! CSDNweixin_43975035 *天下之大,虽离家万里,何处不可往!何事不可为! 1. ALBERT \qquad ALBERT的英文全称为A Lite versi…...
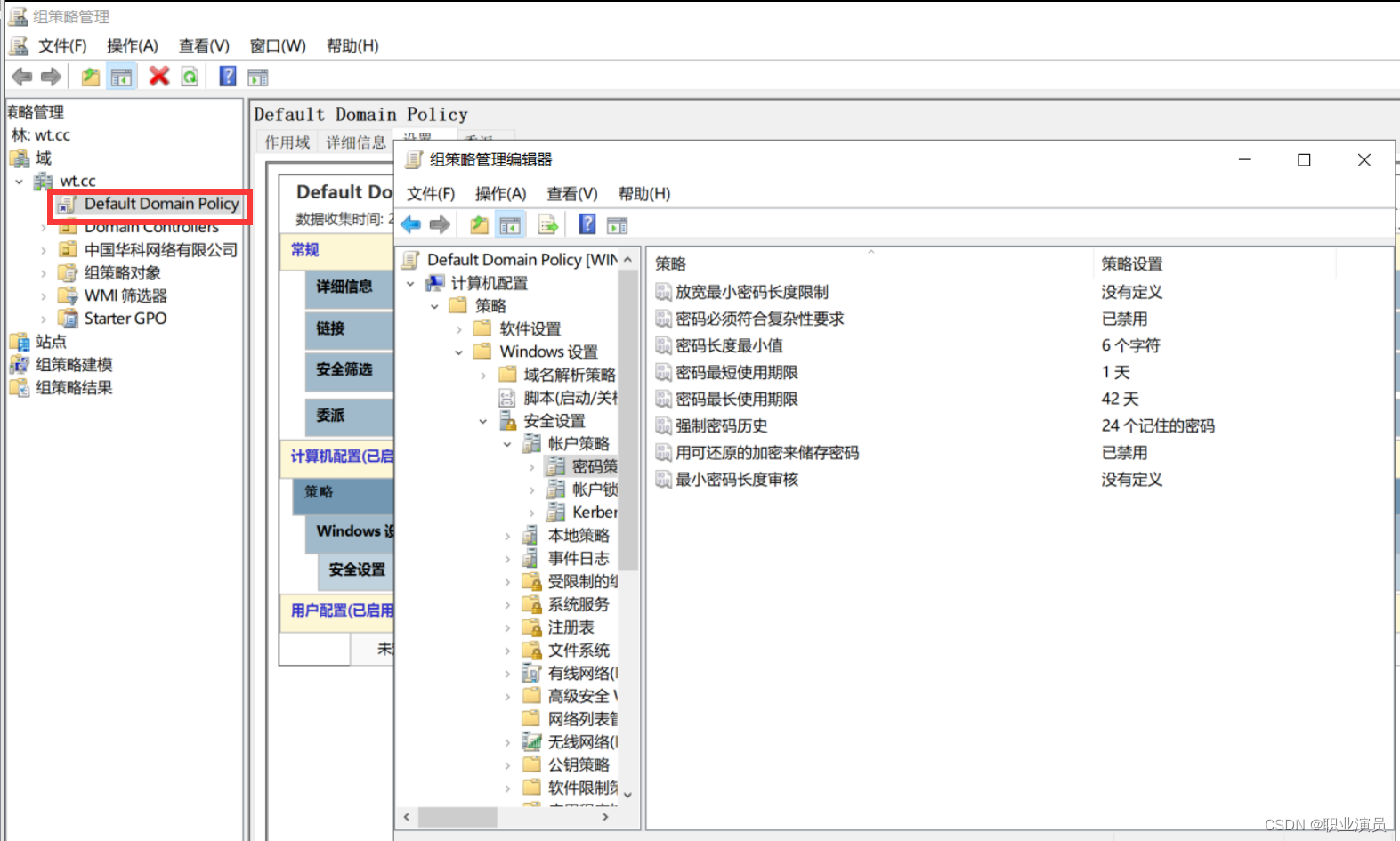
域控操作二:设置域用户使用简单密码
过程太多简单 直接写出路径更改即可 组策略—计算机配置----策略—Windows设置–安全设置----账户策略–密码策略 按自己想法改就行了 注意一点!!!!! 要么自己设置策略,要么从默认策略改!&am…...
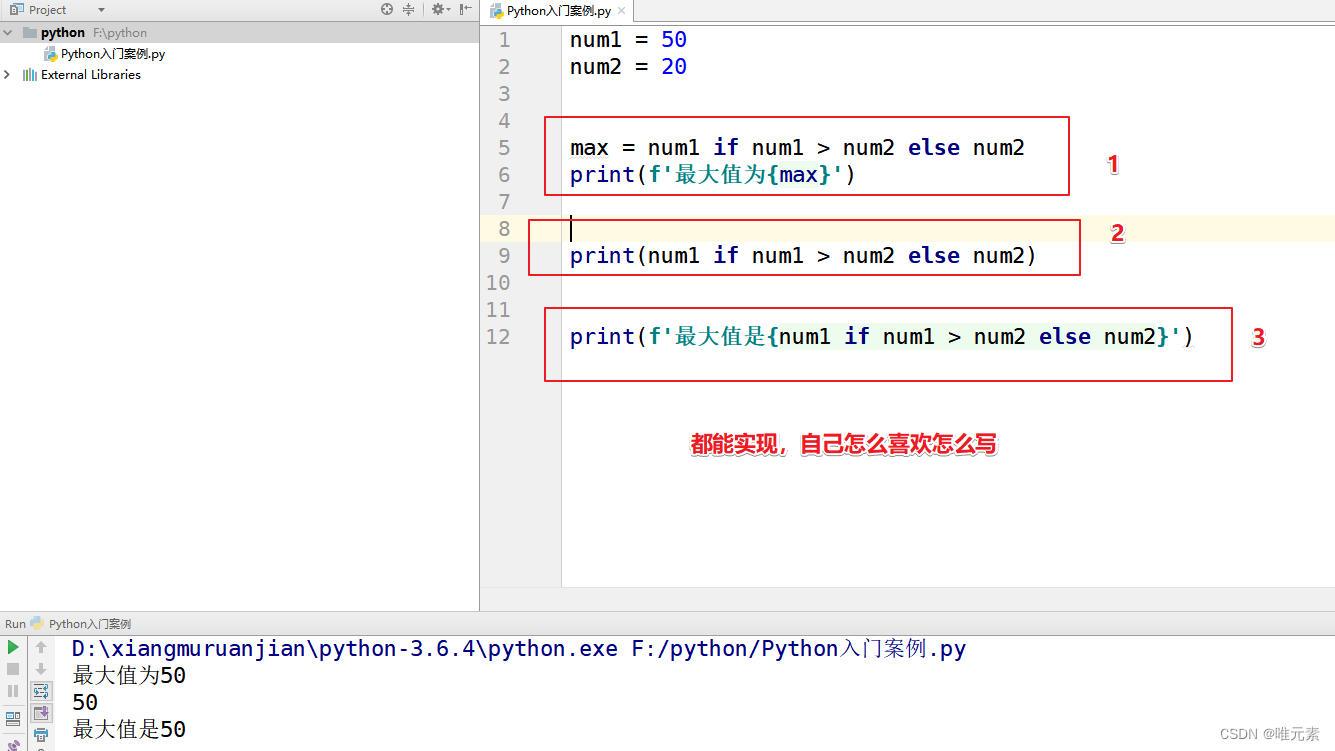
python---三目运算符
在Python中三目运算符也叫三元运算符,其主要作用:就是用于 简化if...else...语句。 基本语法: 原 if 条件判断: # 语句段1 else: # 语句段2 新-----三目运算符/三元运算符 语句段1 if 条件判断 else 语句段2 案例 输入两个数…...

百度地图定位BMap.GeolocationControl的用法
BMap.GeolocationControl 是百度地图API中的一个类,用于添加地理定位控件到地图上,以便用户可以通过该控件获取自己的当前位置。以下是 BMap.GeolocationControl 的用法示例: 首先,确保已经加载了百度地图API,并且创建…...
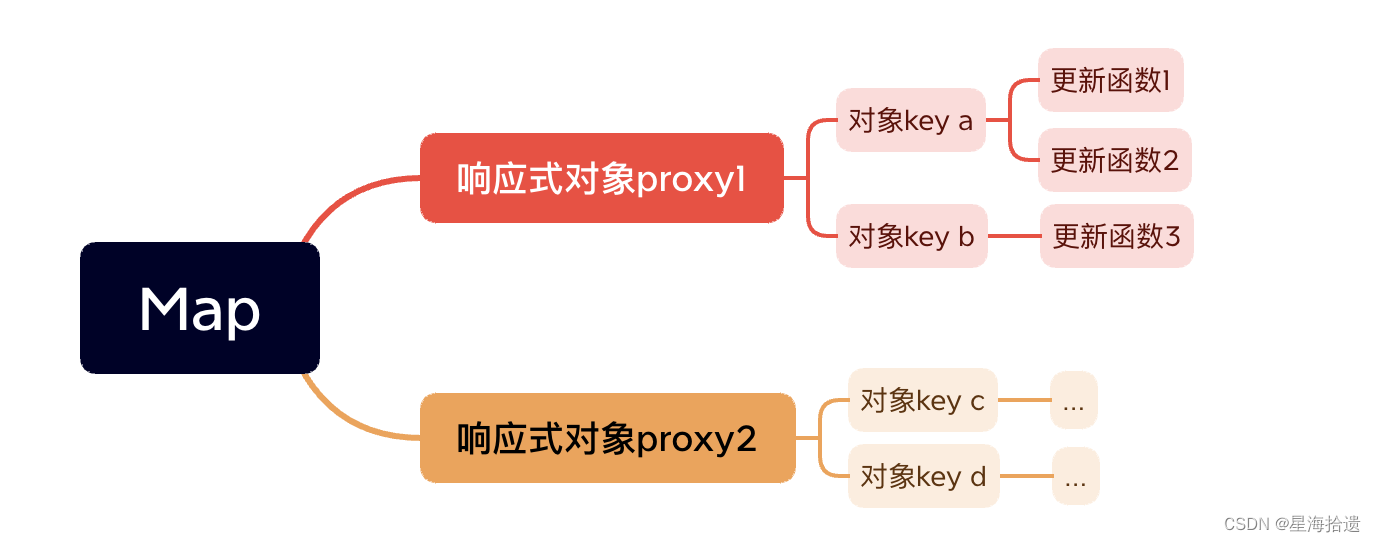
Vue3响应式原理初探
vue3响应式原理初探 为什么要使用proxy取代defineProperty使用proxy如何完成依赖收集呢? 为什么要使用proxy取代defineProperty 原因1:defineproperty无法检测到原本不存在的属性。打个🌰 new Vue({data(){return {name:wxs,age:25}}})在vue…...

firewalld常用的基础配置
firewalld防火墙是centos7系统默认的防火墙管理工具,取代了之前的iptables防火墙,也是工作在网络层,属于包过滤防火墙。 支持IPv4、IPv6防火墙设置以及以太网桥支持服务或应用程序直接添加防火墙规则接口拥有两种配置模式:临时模…...

功率放大器如何驱动超声波换能器
驱动超声波换能器的功率放大器在超声波应用中起着至关重要的作用。它能够提供足够的功率和精确的信号控制,使换能器能够有效地将电能转换为超声波能量。下面安泰电子将介绍功率放大器如何驱动超声波换能器的原理和关键要点。 首先,让我们了解一下超声波换…...
LiveGBS流媒体平台GB/T28181常见问题-安全控制HTTP接口鉴权勾选流地址鉴权后401Unauthorized如何播放调用接口
LiveGBS流媒体平台GB/T28181常见问题-安全控制HTTP接口鉴权勾选流地址鉴权后401 Unauthorized如何播放调用接口? 1、安全控制1.1、HTTP接口鉴权1.2、流地址鉴权 2、401 Unauthorized2.1、携带token调用接口2.1.1、获取鉴权token2.1.2、调用其它接口2.1.2.1、携带 Co…...

红帽认证笔记2
文章目录 1.配置系统以使用默认存储库1.调试selinux2.创建用户账户3.配置cron4. 创建写作目录5. 配置NTP6.配置autofs配置文件权限容器解法1.修改journal配置文件2.重启服务3.拷贝文件到指定目录4.修改拥有人所属组5.修改umask6.切换elovodo用户7.登录容器仓库8.拉取镜像9.运行…...

程序开发中表示密码时使用 password 还是 passcode?
password 和 passcode 是两个经常在计算机和网络安全中使用的术语,两者都是用于身份验证的机制,但它们之间还是存在一些区别的。 password password 通常是指用户自己设置的一串字符,用于保护自己的账户安全。密码通常是静态的,…...

html5 文字自动省略,html中把多余文字转化为省略号的实现方法方法
单行文本: .box{width: 200px;background-color: aqua;text-overflow: ellipsis;overflow: hidden;white-space: nowrap; }多行文本 1.利用-webkit-line-clamp属性 .box{width: 200px;overflow : hidden;text-overflow: ellipsis;display: -webkit-box;-webkit-l…...
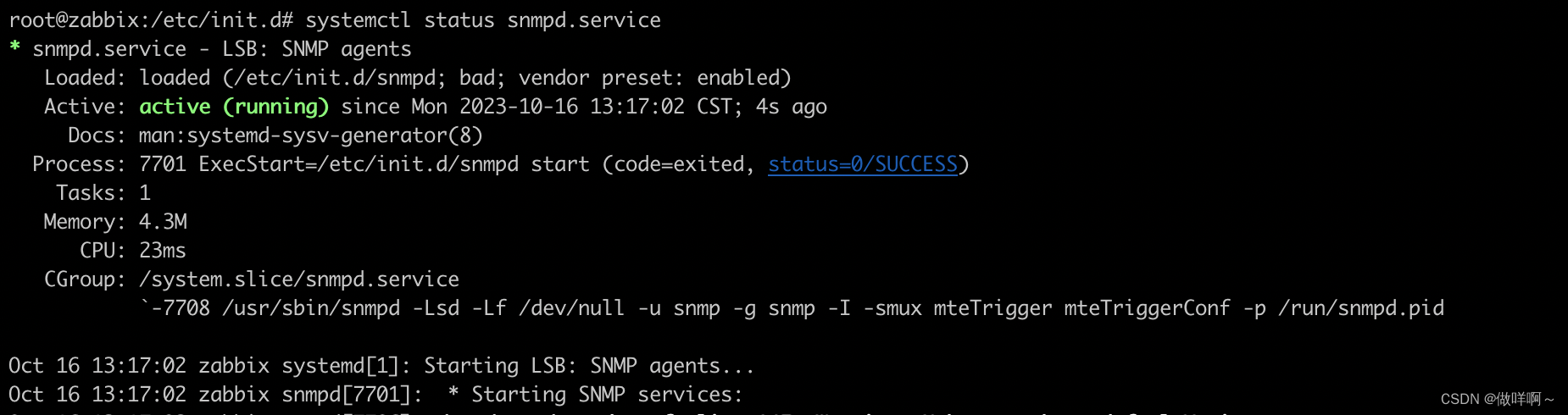
6.SNMP报错-Error opening specified endpoint “udp6:[::1]:161“处理
启动SNMP服务 /etc/init.d/snmpd start 出现以下报错信息 [....] Starting snmpd (via systemctl): snmpd.serviceJob for snmpd.service failed because the control process exited with error code. See "systemctl status snmpd.service" and "journalctl…...

集合的进阶
不可变集合 创建不可变的集合 在创建了之后集合的长度内容都不可以变化 静态集合的创建在list ,set ,map接口当中都可以获取不可变集合 方法名称说明static list of(E …elements)创建一个具有指定元素集合list集合对象staticlist of(E…elements)创…...

【LeetCode刷题(数据结构与算法)】:数据结构中的常用排序实现数组的升序排列
现在我先将各大排序的动图和思路以及代码呈现给大家 插入排序 直接插入排序是一种简单的插入排序法,其基本思想是: 把待排序的记录按其关键码值的大小逐个插入到一个已经排好序的有序序列中,直到所有的记录插入完为 止,得到一个…...

【HTML+CSS】零碎知识点
公告滚动条 <!DOCTYPE html> <html><head><title>动态粘性导航栏</title><style>.container {background: #00aeec;overflow: hidden;padding: 20px 0;}.title {float: left;font-size: 20px;font-weight: normal;margin: 0;margin-left:…...
嵌入式开发学习之STM32F407串口(USART)收发数据(三)
嵌入式开发学习之STM32F407串口(USART)收发数据(三) 开发涉及工具一、选定所使用的串口二、配置串口1.配置串口的I/O2.配置串口参数属性3.配置串口中断4.串口中断在哪里处理5.串口如何发送字符串 三、封装串口配置库文件1.创建头文…...
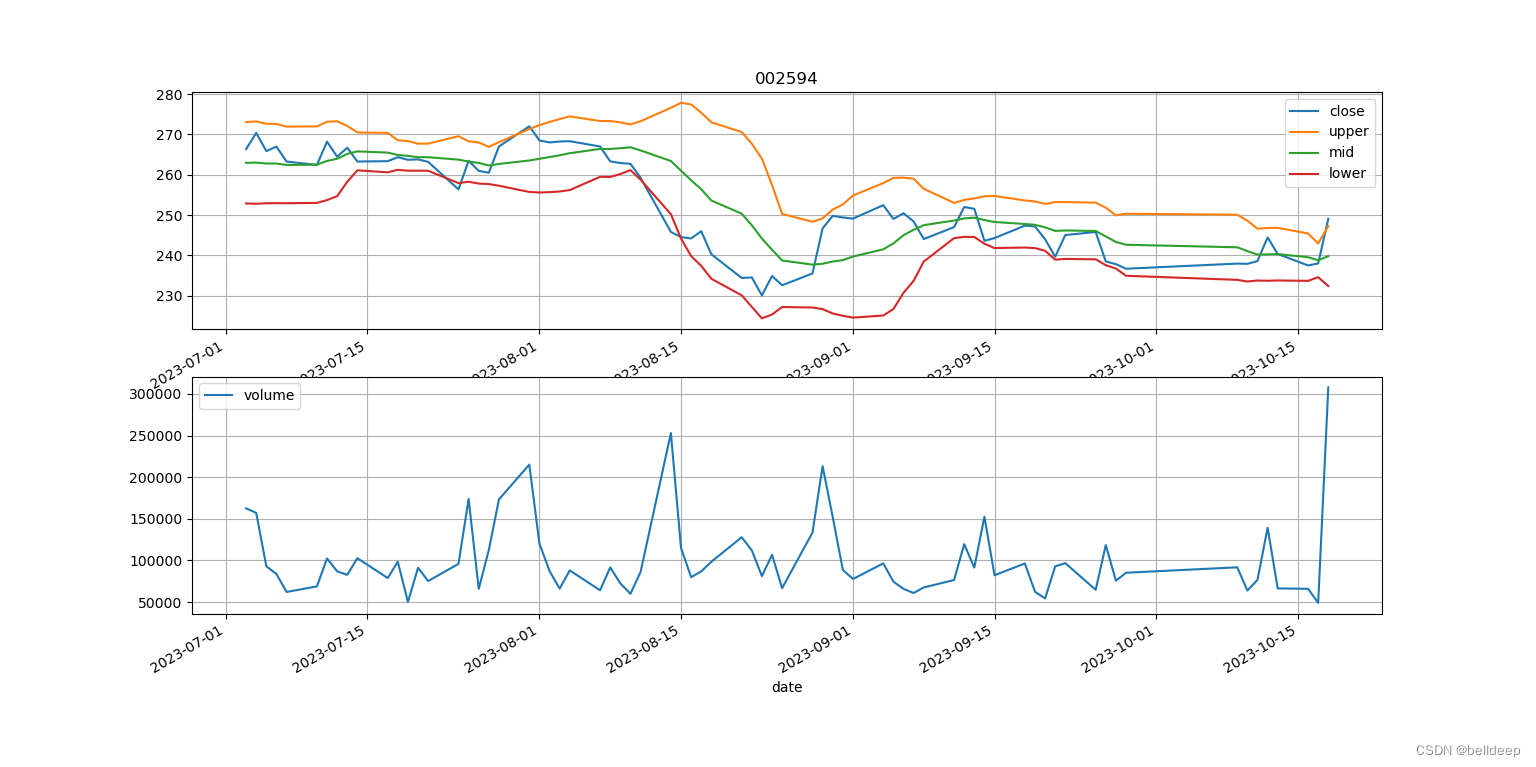
python:talib.BBANDS 画股价-布林线图
python 安装使用 TA_lib 安装主要在 http://www.lfd.uci.edu/~gohlke/pythonlibs/ 这个网站找到 TA_Lib-0.4.24-cp310-cp310-win_amd64.whl pip install /pypi/TA_Lib-0.4.24-cp310-cp310-win_amd64.whl 编写 talib_boll.py 如下 # -*- coding: utf-8 -*- import os impor…...

使用AI大大提升了学习代码的效率
最近看到一个观点,说AI的发展导致代码越来越不值钱了,AI降低了我们学习的门槛,大大提升了学习效率。好像很多程序都可以一个人一天上架一款产品。或许有夸张成分,但像我们普通人都体验到了AI的方便,比如在项目开发的过…...

AceCommon:Arduino嵌入式零堆分配轻量C++工具库
1. AceCommon 库概述:面向嵌入式 Arduino 的轻量级底层工具集AceCommon 是一个专为资源受限的微控制器平台(尤其是 Arduino 生态)设计的零依赖、低开销 C 工具库。其核心设计哲学是“小而精、无侵入、可复用”。与常见的功能臃肿、依赖繁杂的…...

MarkDownload:让网页转Markdown变得简单高效的浏览器扩展
MarkDownload:让网页转Markdown变得简单高效的浏览器扩展 【免费下载链接】markdownload A Firefox and Google Chrome extension to clip websites and download them into a readable markdown file. 项目地址: https://gitcode.com/gh_mirrors/ma/markdownload…...

深度学习驱动的图像去雾:2023年最新算法与应用实践
1. 图像去雾技术的现状与挑战 清晨打开窗户,如果外面雾气弥漫,我们往往会等雾散了再拍照。但计算机视觉系统可没这个耐心——自动驾驶汽车必须实时看清路况,无人机巡检得在雾天正常工作。这就是图像去雾技术存在的意义。2023年,随…...

SDMatte企业级应用:批量商品图去背景+Alpha Matte交付方案
SDMatte企业级应用:批量商品图去背景Alpha Matte交付方案 1. 产品概述 SDMatte是一款专为商业场景设计的高精度AI抠图工具,特别适合电商、广告和设计行业的大规模图像处理需求。它能快速将商品图片中的主体与背景分离,生成带有Alpha通道的透…...

Homebrew卸载与重装指南:彻底清理残留文件的正确姿势
Homebrew深度清理与重装实战:从残留文件追踪到ARM架构优化 每次系统升级或开发环境切换时,那些隐藏在系统深处的Homebrew残留文件就像房间里扫不尽的灰尘——明明已经卸载了所有公式,却在重新安装时遇到各种诡异的权限错误或版本冲突。作为m…...

Docker 容器中文字体及 matplotlib 环境应用
为了避开 Noto CJK 这种复杂的 TTC(TrueType Collection)大包带来的识别问题,最理想的选择是使用独立打包的 OTF 或 TTF 字体。 0. 环境检查 # 1. 更新源并安装 fontconfig apt-get update apt-get install -y fontconfig# 2. 现在 fc-cache 命令可用了,刷新系统字体 fc-…...

基于ANPC型三电平逆变器的VSG并网及参数自适应控制
ANPC虚拟同步机(VSG)并网(参数自适应控制),基于ANPC型三电平逆变器的参数自适应控制,采用电压电流双闭环控制,中点电位平衡控制,且实现VSG并网。 1.VSG参数自适应 2.VSG并网 3.提供相…...

Go语言广播系统设计:基于Channel的高性能事件分发机制
引言 在后端系统架构中,事件广播是一种常见的通信模式。本文将深入分析一个基于Go语言channel实现的广播管理器,探讨其设计思想、实现细节以及在实际项目中的应用价值。 参考代码 点击直达 背景与需求 在许多应用场景中,我们需要实现一对…...

金融Agent再获近2亿加码!启明红杉高瓴集体押注,5个月内连获两轮融资
允中 发自 凹非寺量子位 | 公众号 QbitAI近日,金融AI领跑者讯兔科技(Alpha派)正式完成近2亿元A轮融资。继去年10月完成超亿元Pre-A轮融资后,讯兔科技在短短5个月内再获顶级机构强强加持。本轮由启明创投、红杉中国、高瓴创投共同领…...