Yolov安全帽佩戴检测 危险区域进入检测 - 深度学习 opencv 计算机竞赛
1 前言
🔥 优质竞赛项目系列,今天要分享的是
🚩 Yolov安全帽佩戴检测 危险区域进入检测
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:3分
- 创新点:4分
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
1 课题背景
建筑工人头部伤害是造成建筑伤亡事故的重要原因。佩戴安全帽是防止建筑工人发生脑部外伤事故的有效措施,而在实际工作中工人未佩戴安全帽的不安全行为时有发生。因此,对施工现场建筑工人佩戴安全帽自动实时检测进行探究,将为深入认知和主动预防安全事故提供新的视角。然而,传统的施工现场具有安全管理水平低下、管理范围小、主要依靠安全管理人员的主观监测并且时效性差、不能全程监控等一系列问题。
本项目基于yolov5实现了安全帽和危险区域检测。
2 效果演示



3 Yolov5框架
我们选择当下YOLO最新的卷积神经网络YOLOv5来进行火焰识别检测。6月9日,Ultralytics公司开源了YOLOv5,离上一次YOLOv4发布不到50天。而且这一次的YOLOv5是完全基于PyTorch实现的!在我们还对YOLOv4的各种高端操作、丰富的实验对比惊叹不已时,YOLOv5又带来了更强实时目标检测技术。按照官方给出的数目,现版本的YOLOv5每个图像的推理时间最快0.007秒,即每秒140帧(FPS),但YOLOv5的权重文件大小只有YOLOv4的1/9。
目标检测架构分为两种,一种是two-stage,一种是one-stage,区别就在于 two-stage 有region
proposal过程,类似于一种海选过程,网络会根据候选区域生成位置和类别,而one-stage直接从图片生成位置和类别。今天提到的 YOLO就是一种
one-stage方法。YOLO是You Only Look Once的缩写,意思是神经网络只需要看一次图片,就能输出结果。YOLO
一共发布了五个版本,其中 YOLOv1 奠定了整个系列的基础,后面的系列就是在第一版基础上的改进,为的是提升性能。
YOLOv5有4个版本性能如图所示:

网络架构图

YOLOv5是一种单阶段目标检测算法,该算法在YOLOv4的基础上添加了一些新的改进思路,使其速度与精度都得到了极大的性能提升。主要的改进思路如下所示:
输入端
在模型训练阶段,提出了一些改进思路,主要包括Mosaic数据增强、自适应锚框计算、自适应图片缩放;
Mosaic数据增强
:Mosaic数据增强的作者也是来自YOLOv5团队的成员,通过随机缩放、随机裁剪、随机排布的方式进行拼接,对小目标的检测效果很不错

基准网络
融合其它检测算法中的一些新思路,主要包括:Focus结构与CSP结构;
Neck网络
在目标检测领域,为了更好的提取融合特征,通常在Backbone和输出层,会插入一些层,这个部分称为Neck。Yolov5中添加了FPN+PAN结构,相当于目标检测网络的颈部,也是非常关键的。


FPN+PAN的结构

这样结合操作,FPN层自顶向下传达强语义特征(High-Level特征),而特征金字塔则自底向上传达强定位特征(Low-
Level特征),两两联手,从不同的主干层对不同的检测层进行特征聚合。
FPN+PAN借鉴的是18年CVPR的PANet,当时主要应用于图像分割领域,但Alexey将其拆分应用到Yolov4中,进一步提高特征提取的能力。
Head输出层
输出层的锚框机制与YOLOv4相同,主要改进的是训练时的损失函数GIOU_Loss,以及预测框筛选的DIOU_nms。
对于Head部分,可以看到三个紫色箭头处的特征图是40×40、20×20、10×10。以及最后Prediction中用于预测的3个特征图:
①==>40×40×255②==>20×20×255③==>10×10×255

-
相关代码
class Detect(nn.Module):stride = None # strides computed during buildonnx_dynamic = False # ONNX export parameterdef __init__(self, nc=80, anchors=(), ch=(), inplace=True): # detection layersuper().__init__()self.nc = nc # number of classesself.no = nc + 5 # number of outputs per anchorself.nl = len(anchors) # number of detection layersself.na = len(anchors[0]) // 2 # number of anchorsself.grid = [torch.zeros(1)] * self.nl # init gridself.anchor_grid = [torch.zeros(1)] * self.nl # init anchor gridself.register_buffer('anchors', torch.tensor(anchors).float().view(self.nl, -1, 2)) # shape(nl,na,2)self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output convself.inplace = inplace # use in-place ops (e.g. slice assignment)def forward(self, x):z = [] # inference outputfor i in range(self.nl):x[i] = self.m[i](x[i]) # convbs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()if not self.training: # inferenceif self.onnx_dynamic or self.grid[i].shape[2:4] != x[i].shape[2:4]:self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i)y = x[i].sigmoid()if self.inplace:y[..., 0:2] = (y[..., 0:2] * 2 - 0.5 + self.grid[i]) * self.stride[i] # xyy[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # whelse: # for YOLOv5 on AWS Inferentia https://github.com/ultralytics/yolov5/pull/2953xy = (y[..., 0:2] * 2 - 0.5 + self.grid[i]) * self.stride[i] # xywh = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # why = torch.cat((xy, wh, y[..., 4:]), -1)z.append(y.view(bs, -1, self.no))return x if self.training else (torch.cat(z, 1), x)def _make_grid(self, nx=20, ny=20, i=0):d = self.anchors[i].deviceif check_version(torch.__version__, '1.10.0'): # torch>=1.10.0 meshgrid workaround for torch>=0.7 compatibilityyv, xv = torch.meshgrid([torch.arange(ny).to(d), torch.arange(nx).to(d)], indexing='ij')else:yv, xv = torch.meshgrid([torch.arange(ny).to(d), torch.arange(nx).to(d)])grid = torch.stack((xv, yv), 2).expand((1, self.na, ny, nx, 2)).float()anchor_grid = (self.anchors[i].clone() * self.stride[i]) \.view((1, self.na, 1, 1, 2)).expand((1, self.na, ny, nx, 2)).float()return grid, anchor_grid
4 数据处理和训练
4.1 安全帽检测
这里只是判断 【人没有带安全帽】、【人有带安全帽】、【人体】 3个类别 ,基于 data/coco128.yaml 文件,创建自己的数据集配置文件
custom_data.yaml。
创建自己的数据集配置文件
# 训练集和验证集的 labels 和 image 文件的位置
train: ./score/images/train
val: ./score/images/val
# number of classesnc: 3# class namesnames: ['person', 'head', 'helmet']创建每个图片对应的标签文件
使用 data/gen_data/gen_head_helmet.py 来将 VOC 的数据集转换成 YOLOv5 训练需要用到的格式。
使用标注工具类似于 Labelbox 、CVAT 、精灵标注助手 标注之后,需要生成每个图片对应的 .txt 文件,其规范如下:
- 每一行都是一个目标
- 类别序号是零索引开始的(从0开始)
- 每一行的坐标 class x_center y_center width height 格式
- 框坐标必须采用归一化的 xywh格式(从0到1)。如果您的框以像素为单位,则将x_center和width除以图像宽度,将y_center和height除以图像高度。
代码如下:
import numpy as np
def convert(size, box):
"""
将标注的 xml 文件生成的【左上角x,左上角y,右下角x,右下角y】标注转换为yolov5训练的坐标
:param size: 图片的尺寸: [w,h]
:param box: anchor box 的坐标 [左上角x,左上角y,右下角x,右下角y,]
:return: 转换后的 [x,y,w,h]
"""
x1 = int(box[0])y1 = int(box[1])x2 = int(box[2])y2 = int(box[3])dw = np.float32(1. / int(size[0]))dh = np.float32(1. / int(size[1]))w = x2 - x1h = y2 - y1x = x1 + (w / 2)y = y1 + (h / 2)x = x * dww = w * dwy = y * dhh = h * dhreturn [x, y, w, h]生成的 .txt 例子:
1 0.1830000086920336 0.1396396430209279 0.13400000636465847 0.15915916301310062
1 0.5240000248886645 0.29129129834473133 0.0800000037997961 0.16816817224025726
1 0.6060000287834555 0.29579580295830965 0.08400000398978591 0.1771771814674139
1 0.6760000321082771 0.25375375989824533 0.10000000474974513 0.21321321837604046
0 0.39300001866649836 0.2552552614361048 0.17800000845454633 0.2822822891175747
0 0.7200000341981649 0.5570570705458522 0.25200001196935773 0.4294294398277998
0 0.7720000366680324 0.2567567629739642 0.1520000072196126 0.23123123683035374
选择模型
在文件夹 ./models 下选择一个你需要的模型然后复制一份出来,将文件开头的 nc = 修改为数据集的分类数,下面是借鉴
./models/yolov5s.yaml来修改的
# parameters
nc: 3 # number of classes <============ 修改这里为数据集的分类数
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
# anchorsanchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# YOLOv5 backbonebackbone:# [from, number, module, args][[-1, 1, Focus, [64, 3]], # 0-P1/2[-1, 1, Conv, [128, 3, 2]], # 1-P2/4[-1, 3, BottleneckCSP, [128]],[-1, 1, Conv, [256, 3, 2]], # 3-P3/8[-1, 9, BottleneckCSP, [256]],[-1, 1, Conv, [512, 3, 2]], # 5-P4/16[-1, 9, BottleneckCSP, [512]],[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32[-1, 1, SPP, [1024, [5, 9, 13]]],[-1, 3, BottleneckCSP, [1024, False]], # 9]# YOLOv5 headhead:[[-1, 1, Conv, [512, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 6], 1, Concat, [1]], # cat backbone P4[-1, 3, BottleneckCSP, [512, False]], # 13[-1, 1, Conv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 4], 1, Concat, [1]], # cat backbone P3[-1, 3, BottleneckCSP, [256, False]], # 17[-1, 1, Conv, [256, 3, 2]],[[-1, 14], 1, Concat, [1]], # cat head P4[-1, 3, BottleneckCSP, [512, False]], # 20[-1, 1, Conv, [512, 3, 2]],[[-1, 10], 1, Concat, [1]], # cat head P5[-1, 3, BottleneckCSP, [1024, False]], # 23[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]
开始训练
这里选择了 yolov5s 模型进行训练,权重也是基于 yolov5s.pt 来训练
python train.py --img 640 \--batch 16 --epochs 10 --data ./data/custom_data.yaml \--cfg ./models/custom_yolov5.yaml --weights ./weights/yolov5s.pt
4.2 检测危险区域内是否有人
危险区域标注方式
使用的是 精灵标注助手 标注,生成了对应图片的 json 文件
执行侦测
python area_detect.py --source ./area_dangerous --weights ./weights/helmet_head_person_s.pt
效果
危险区域会使用 红色框 标出来,同时,危险区域里面的人体也会被框出来,危险区域外的人体不会被框选出来。

5 最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
相关文章:
Yolov安全帽佩戴检测 危险区域进入检测 - 深度学习 opencv 计算机竞赛
1 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 Yolov安全帽佩戴检测 危险区域进入检测 🥇学长这里给一个题目综合评分(每项满分5分) 难度系数:3分工作量:3分创新点:4分 该项目较为新颖&am…...

vue中动态设置source标签
项目中有个视频播放,路径通过接口返回,而且不带后缀,并不确定是什么类型的视频文件,所以要通过source标签去进行设置. 问题:当video中存在source标签的时候,浏览器渲染之后会自动去获取地址,即便地址改变,浏览器也不会再去获取地址。 解决方…...

【16】基础知识:React路由 - React Router 6
一、概述 了解 React Router 以三个不同的包发布到 npm 上,它们分别为 1、react-router:路由的核心库,提供了很多的组件、钩子。 2、react-router-dom:包含 react-router 所有内容,并添加一些专门用于 DOM 的组件&…...
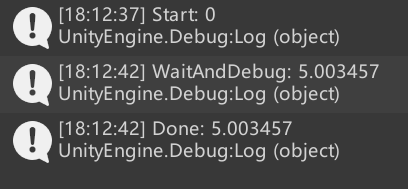
Unity3D 基础——Coroutine 协同程序
Coroutine 称为协同程序或者协程,协同程序可以和主程序并行运行,和多线程有些类似。协同程序可以用来实现让一段程序等待一段时间后继续运行的效果。例如,执行步骤1,等待3秒;执行步骤2,等待某个条件为 true…...

IDEA报错:前言中不允许有内容
idea启动项目提示前言中不允许有内容 .idea\libraries\Maven__axis2_axis2_1_0.xml: ParseError at [row,col]:[1,1] Message: 前言中不允许有内容。 解决方法: 首先修改设置:IDEA–>File–>Settings–>File Encodings–>with No BOM选中报…...

在线课堂分销商城小程序源码系统 带完整搭建教程
大家好啊,今天来给大家分享一个在线课堂分销商城小程序源码系统,一起来看看吧。以下是部分功能实现的核心代码: 系统特色功能一览: 商品模块。包括实物商品、虚拟商品和电子卡密等,每种商品可以设置对应的商品分类。同…...

【存储系统】0. 序
学习资料:大话存储 存储系统底层架构原理极限剖析 终极版 张冬编著——清华大学出版社 2015.01 文章目录 0.1 序0.1.1 信息存储技术溯源0.1.2 数字化信息推动存储技术发展0.1.3 数字存储技术 0.2 存储系统介绍0.2.1 信息0.2.2 数据0.2.3 数据存储0.2.4 用计算机来处…...
逐字稿 | 2 MoCo 论文逐段精读【论文精读】
bryanyzhu的个人空间-bryanyzhu个人主页-哔哩哔哩视频 评价 今天我们一起来读一下 MOCO 这篇论文。 MOCO 是 CVPR 2020 的最佳论文提名,算是视觉领域里使用对比学习的一个里程碑式的工作。而对比学习作为从 19 年开始一直到现在视觉领域乃至整个机器学习领域里最炙…...

【数据结构】排序算法的稳定性分析
💐 🌸 🌷 🍀 🌹 🌻 🌺 🍁 🍃 🍂 🌿 🍄🍝 🍛 🍤 📃个人主页 :阿然成长日记 …...
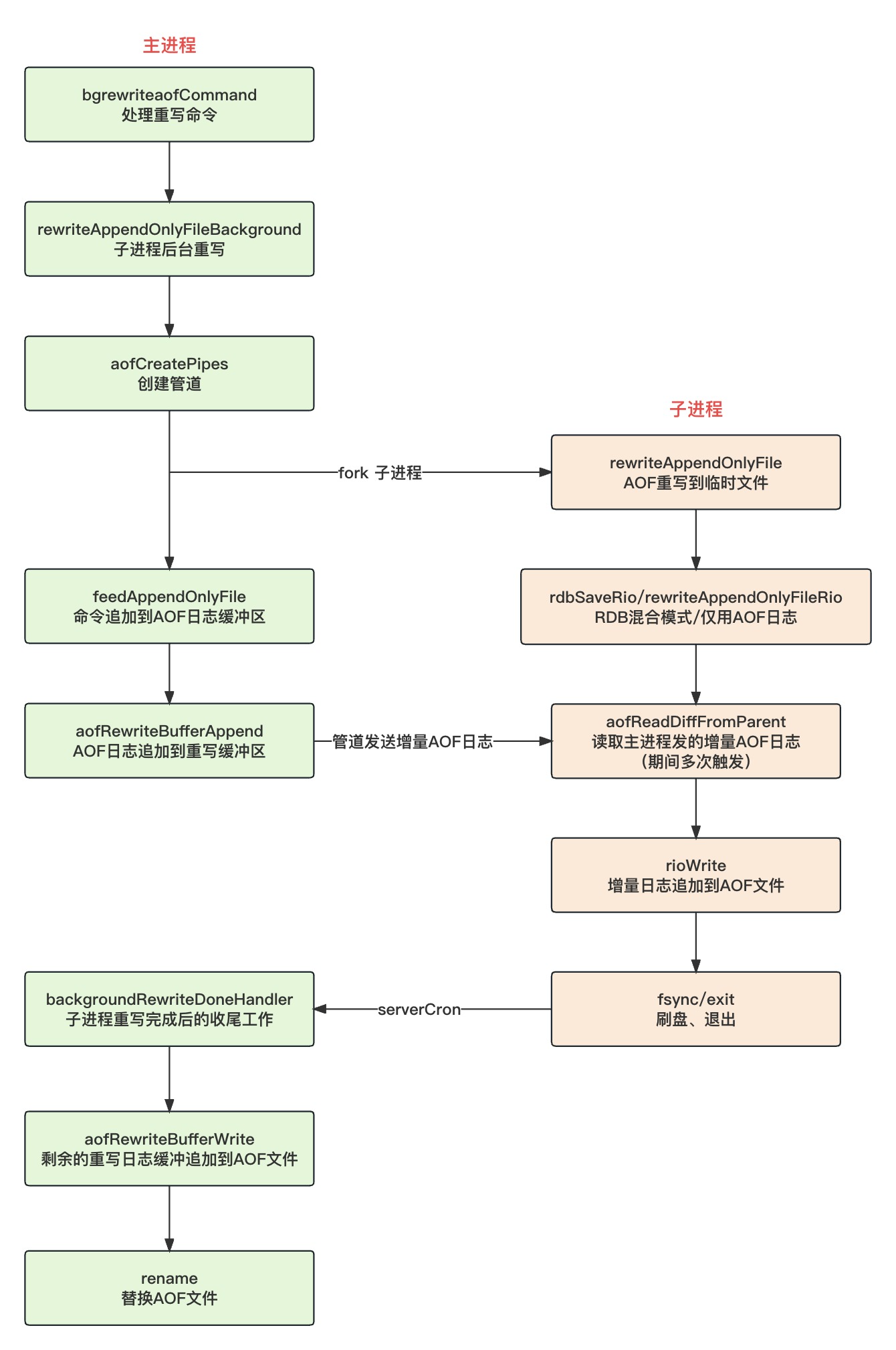
Redis AOF持久化和ReWrite
前言 Redis 的 RDB 持久化机制简单直接,把某一时刻的所有键值对以二进制的方式写入到磁盘,特点是恢复速度快,尤其适合数据备份、主从复制场景。但如果你的目的是要保证数据可靠性,RDB 就不太适合了,因为 RDB 持久化不…...
Flink学习之旅:(一)Flink部署安装
1.本地搭建 1.1.下载Flink 进入Flink官网,点击Downloads 往下滑动就可以看到 Flink 的所有版本了,看自己需要什么版本点击下载即可。 1.2.上传解压 上传至服务器,进行解压 tar -zxvf flink-1.17.1-bin-scala_2.12.tgz -C ../module/ 1.3.启…...

Go语言入门心法(六): HTTP面向客户端|服务端编程
Go语言入门心法(一): 基础语法 Go语言入门心法(二): 结构体 Go语言入门心法(三): 接口 Go语言入门心法(四): 异常体系 Go语言入门心法(五): 函数 一:go语言面向web编程认知 Go语言的最大优势在于并发与性能,其性能可以媲美C和C,并发在网络编程中更是至关重要 使用http发送请…...

为什么非const静态成员变量一定要在类外定义
当我们如下声明了一个类: class A{public:static int sti_data;// 这个语句在c11前不能通过编译,在c11的新标准下,已经能够在声明一个普通变量是就对其进行初始化。int a 10;static const int b 1;//...其他member };// 在类外…...

千兆光模块和万兆光模块的区别?
在网络通信领域,千兆光模块和万兆光模块是最为常见且广泛应用的两种光模块。不同之处在于传输速率、封装、传输距离、功耗、发射光功率、接收光功率和应用场景等。 千兆光模块的传输速率为1 Gbps,万兆光模块的传输速率为10 Gbps,这意味着万…...
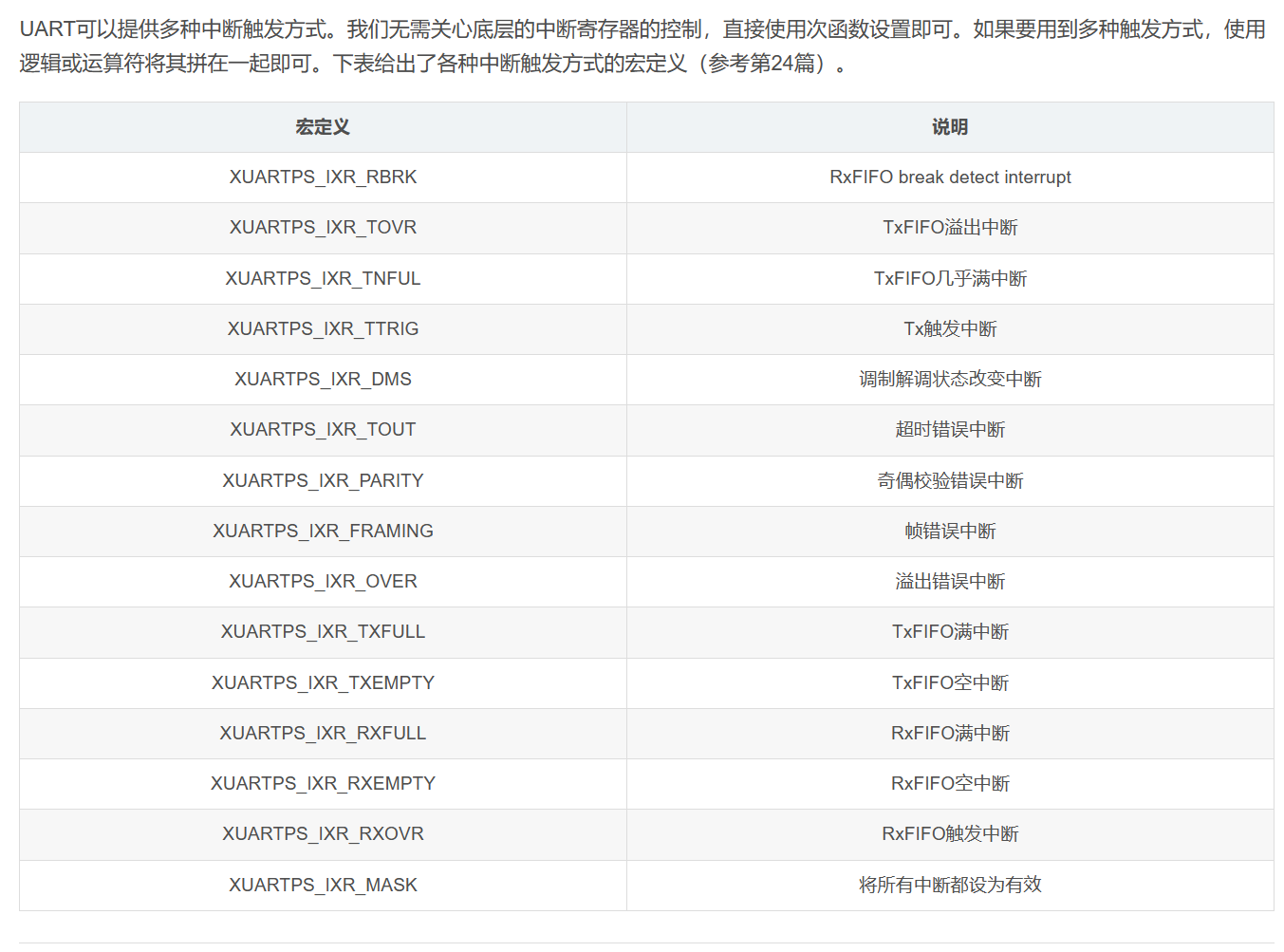
中断:Zynq Uart中断的流程和例程~UG585的CH.19
Zynq里的uart UART 控制器是全双工异步接收器和发送器,支持多种可编程波特率和 I/O 信号格式。该控制器可以适应自动奇偶校验生成和多主机检测模式。 UART 操作由配置和模式寄存器控制。使用状态、中断状态和调制解调器状态寄存器读取 FIFO、调制解调器信号…...

计算机补码能够减法转加法的原因
...
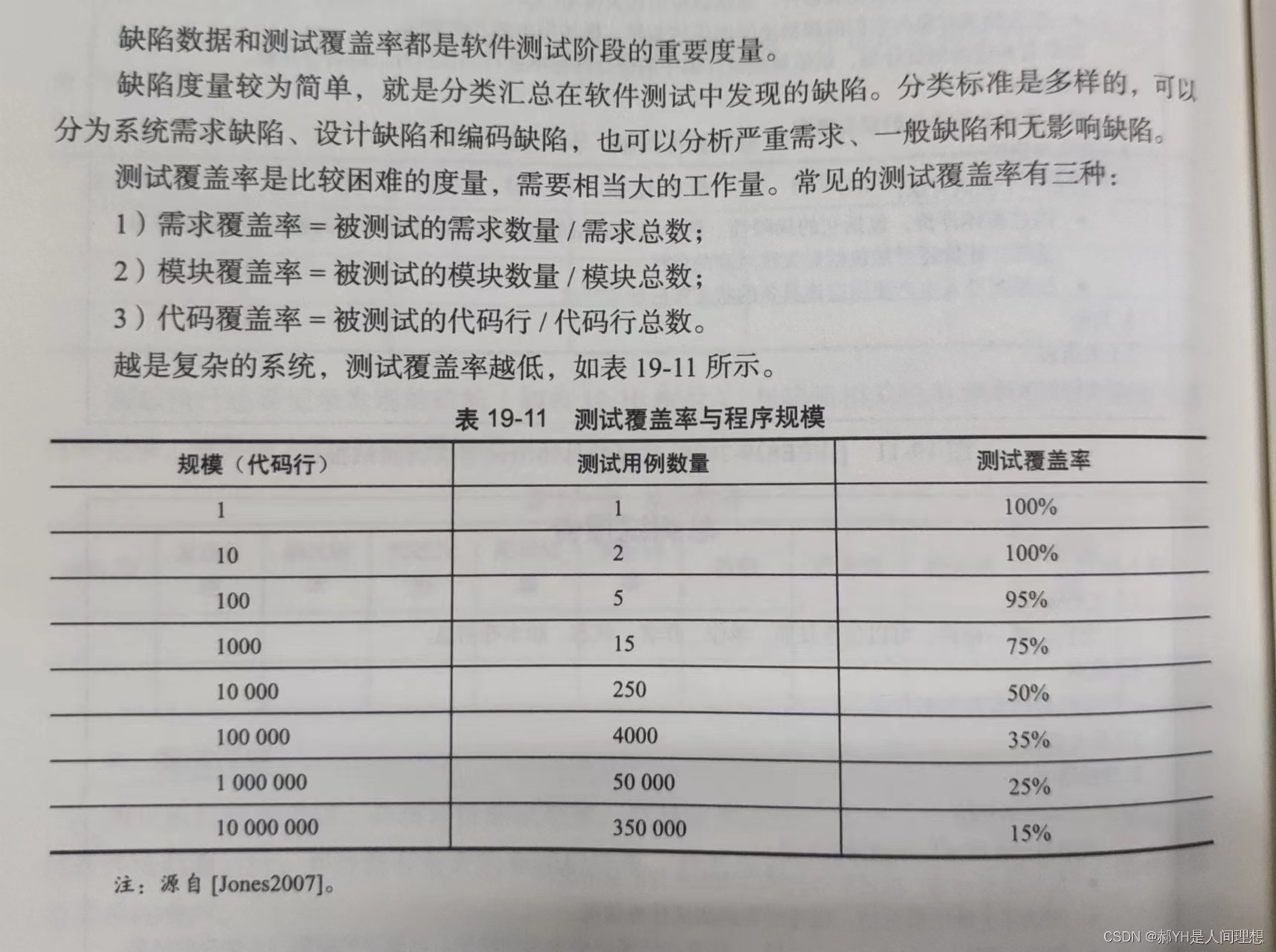
软件工程与计算总结(十九)软件测试
目录 编辑 一.引言 1.验证与确认 2.目标 3.测试用例 4.桩与驱动 5.缺陷、错误与失败 二.测试层次 1.测试层次的划分 2.单元测试 3.集成测试 4.系统测试 三.测试技术 1.测试用例的选择 2.随机测试 3.基于规格的技术(黑盒测试) 4.基于代…...

Tomcat设置IP黑名单和白名单server.xml
方式一: -- 只允许192.168.1.2和192.168.2.3 <Context path"" docBase"xxxAdmin" debug"0" reloadable"true" ><Valve className"org.apache.catalina.valves.RemoteAddrValve" allow"192.168.1.…...

【AI视野·今日NLP 自然语言处理论文速览 第五十五期】Mon, 16 Oct 2023
AI视野今日CS.NLP 自然语言处理论文速览 Mon, 16 Oct 2023 Totally 53 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers PromptRE: Weakly-Supervised Document-Level Relation Extraction via Prompting-Based Data Programming Au…...

k8s crd设置额外header
可以通过设置crd.spec.additionalPrinterColumns来实现: apiVersion: apiextensions.k8s.io/v1 kind: CustomResourceDefinition metadata:name: crontabs.stable.example.com spec:group: stable.example.comscope: Namespacednames:plural: crontabssingular: cr…...
数据库索引维护:高级实践指南)
cool-admin(midway版)数据库索引维护:高级实践指南
cool-admin(midway版)数据库索引维护:高级实践指南 【免费下载链接】cool-admin-midway 🔥 cool-admin(midway版)一个很酷的后台权限管理框架,模块化、插件化、CRUD极速开发,永久开源免费,基于midway.js 3.x、typescri…...

NASM高级特性详解:条件汇编、上下文栈和宏重载
NASM高级特性详解:条件汇编、上下文栈和宏重载 【免费下载链接】nasm A cross-platform x86 assembler with an Intel-like syntax 项目地址: https://gitcode.com/gh_mirrors/na/nasm NASM(Netwide Assembler)是一款跨平台的x86汇编器…...

Qwen-Image-Edit-2511-Unblur-Upscale惊艳效果:模糊图片一键高清化
Qwen-Image-Edit-2511-Unblur-Upscale惊艳效果:模糊图片一键高清化 1. 效果展示:从模糊到高清的魔法 你是否遇到过这样的情况?手机里珍藏的老照片因为年代久远变得模糊不清,或是匆忙拍摄的珍贵瞬间因为手抖而糊成一片。现在&…...
Pixel Epic效果实测:不同逻辑发散概率下技术路线图描述准确率对比
Pixel Epic效果实测:不同逻辑发散概率下技术路线图描述准确率对比 1. 测试背景与目的 Pixel Epic作为一款创新型研究报告辅助工具,其核心功能"贤者之智"模块采用了独特的逻辑发散机制。本次测试旨在评估不同逻辑发散概率设置对技术路线图描述…...

OpenClaw技能开发入门:为Qwen3-4B定制专属自动化模块
OpenClaw技能开发入门:为Qwen3-4B定制专属自动化模块 1. 为什么需要自定义OpenClaw技能 去年夏天,我接手了一个重复性极高的周报生成工作。每周都要从十几个PDF报告中提取关键数据,整理成固定格式的Excel表格,再转成PPT汇报。当…...

GameFramework——FileSystem篇
目录 一、快速入门 1.1 什么是文件系统模块? 1.2 基本使用步骤 1.2.1 创建文件系统 1.2.2 写入文件 1.2.3 读取文件 1.2.4 删除文件 1.2.5 加载已有文件系统 二、文件布局 2.1 HeaderData(文件头) 2.2 BlockData(块数据…...

BYD 高通8155 OTA项目 我写的一篇专利
草根不要在BYD写专利,我24年1月初开始撰写,24年6月份才提交到专利公司,被驳回是因为有对比文件公开了我的发明点,是重庆赛力斯 4月份公开的,部门内部流程审核极慢,集团IPR找各种理由能拖上你半年࿰…...
)
从原理到代码:固高GTS控制卡SmartHome回零功能完整开发指南(附C#示例)
从原理到代码:固高GTS控制卡SmartHome回零功能完整开发指南(附C#示例) 在工业自动化领域,运动控制系统的精度和可靠性往往取决于一个看似简单却至关重要的功能——回零操作。作为固高GTS系列控制卡的核心功能之一,Smar…...

PyTorch 2.8开源镜像实操:使用Pandas+NumPy高效处理百万级视频元数据
PyTorch 2.8开源镜像实操:使用PandasNumPy高效处理百万级视频元数据 1. 为什么选择PyTorch 2.8镜像处理视频元数据 在视频内容爆炸式增长的今天,处理百万级视频元数据已经成为许多开发者和数据科学家的日常需求。传统方法在处理大规模视频元数据时常常…...

OpenClaw对接Qwen3-4B实战:5步完成本地模型调用与自动化任务
OpenClaw对接Qwen3-4B实战:5步完成本地模型调用与自动化任务 1. 为什么选择OpenClawQwen3-4B组合 去年冬天第一次听说OpenClaw时,我正被重复性的文件整理工作折磨得焦头烂额。作为一个习惯用脚本解决问题的开发者,我试过各种自动化工具&…...