【大数据】Kafka 入门简介
Kafka 入门简介
- 1.什么是 Kafka
- 2.Kafka 的基本概念
- 3.Kafka 分布式架构
- 4.配置单机版 Kafka
- 4.1 下载并解压包
- 4.2 启动 Kafka
- 4.3 创建 Topic
- 4.4 向 Topic 中发送消息
- 4.5 从 Topic 中消费消息
- 5.实验
- 5.1 实验一:Python 实现生产者消费者
- 5.2 实验二:消费组实现容错性机制
- 5.3 实验三:Offset 管理
- 6.总结
1.什么是 Kafka
Kafka 是一个分布式流处理系统,流处理系统使它可以像消息队列一样 publish 或者 subscribe 消息,分布式提供了容错性,并发处理消息的机制。
2.Kafka 的基本概念
Kafka 运行在集群上,集群包含一个或多个服务器。Kafka 把消息存在 Topic 中,每一条消息包含键值(Key),值(Value)和时间戳(Timestamp)。
Kafka 有以下一些基本概念:
- Producer:消息生产者,就是向 Kafka Broker 发消息的客户端。
- Consumer:消息消费者,是消息的使用方,负责消费 Kafka 服务器上的消息。
- Topic:主题,由用户定义并配置在 Kafka 服务器,用于建立 Producer 和 Consumer 之间的订阅关系。生产者发送消息到指定的 Topic 下,消息者从这个 Topic 下消费消息。
- Partition:消息分区,一个 Topic 可以分为多个 Partition,每个 Partition 是一个有序的队列。Partition 中的每条消息都会被分配一个有序的
id(Offset)。 - Broker:一台 Kafka 服务器就是一个 Broker。一个集群由多个 Broker 组成。一个 Broker 可以容纳多个 Topic。
- Consumer Group:消费者分组,用于归组同类消费者。每个 Consumer 属于一个特定的 Consumer Group,多个消费者可以共同消费一个Topic下的消息,每个消费者消费其中的部分消息,这些消费者就组成了一个分组,拥有同一个分组名称,通常也被称为消费者集群。
- Offset:消息在 Partition 中的偏移量。每一条消息在 Partition 都有唯一的偏移量,消费者可以指定偏移量来指定要消费的消息。
3.Kafka 分布式架构

如上图所示,Kafka 将 Topic 中的消息存在不同的 Partition中。如果存在键值(Key),消息按照键值做分类存在不同的 Partition 中,如果不存在键值,消息按照轮询(Round Robin)机制存在不同的 Partition 中。默认情况下,键值决定了一条消息会被存在哪个 Partition 中。
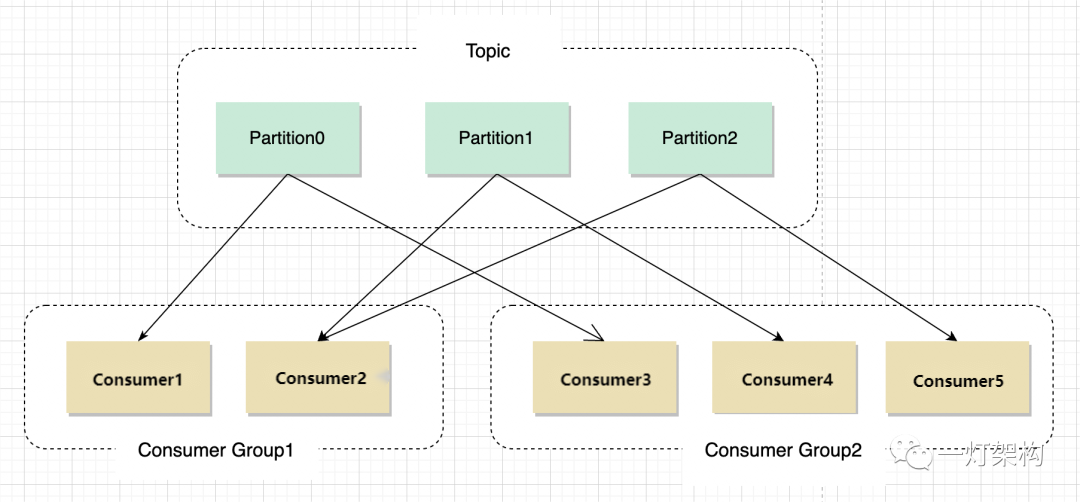
Partition 中的消息序列是有序的消息序列。Kafka 在 Partition 使用偏移量(Offset)来指定消息的位置。一个 Topic 的一个 Partition 只能被一个 Consumer Group 中的一个 Consumer 消费,同组的多个 Consumer 消费同一个 Partition 中的数据是不允许的;但是一个 Consumer 可以消费多个 Partition 中的数据。
Kafka 将 Partition 的数据复制到不同的 Broker,提供了 Partition 数据的备份。每一个 Partition 都有一个 Broker 作为 Leader,若干个 Broker 作为 Follower。所有的数据读写都通过 Leader 所在的服务器进行,并且 Leader 在不同 Broker 之间复制数据。

上图中,对于 Partition 0,Broker 1 是它的 Leader,Broker 2 和 Broker 3 是 Follower。对于 Partition 1,Broker 2 是它的 Leader,Broker 1 和 Broker 3 是 Follower。

在上图中,当有 Client(也就是 Producer)要写入数据到 Partition 0 时,会写入到 Leader Broker 1,Broker 1 再将数据复制到 Follower Broker 2 和 Broker 3。

在上图中,Client 向 Partition 1 中写入数据时,会写入到 Broker 2,因为 Broker 2 是 Partition 1 的 Leader,然后 Broker 2 再将数据复制到 Follower Broker 1 和 Broker 3 中。
上图中的 Topic 一共有 3 个 Partition,对每个 Partition 的读写都由不同的 Broker 处理,因此总的吞吐量得到了提升。
4.配置单机版 Kafka
这里我们使用 Kafka 0.10.0.0 0.10.0.0 0.10.0.0 版本。
4.1 下载并解压包
$ wget https://archive.apache.org/dist/kafka/0.10.0.0/kafka_2.11-0.10.0.0.tgz
$ tar -xzf kafka_2.11-0.10.0.0.tgz
$ cd kafka_2.11-0.10.0.0
4.2 启动 Kafka
Kafka 需要用到 Zookeeper,所以需要先启动 Zookeeper。我们这里使用下载包里自带的单机版 Zookeeper。
$ bin/zookeeper-server-start.sh config/zookeeper.properties
[2013-04-22 15:01:37,495] INFO Reading configuration from: config/zookeeper.properties (org.apache.zookeeper.server.quorum.QuorumPeerConfig)
...
然后启动 Kafka
$ bin/kafka-server-start.sh config/server.properties
[2013-04-22 15:01:47,028] INFO Verifying properties (kafka.utils.VerifiableProperties)
[2013-04-22 15:01:47,051] INFO Property socket.send.buffer.bytes is overridden to 1048576 (kafka.utils.VerifiableProperties)
...
4.3 创建 Topic
$ bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
查看创建的 Topic
$ bin/kafka-topics.sh --list --zookeeper localhost:2181
test
4.4 向 Topic 中发送消息
$ bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
This is a message
This is another message
4.5 从 Topic 中消费消息
$ bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning
This is a message
This is another message
5.实验
5.1 实验一:Python 实现生产者消费者
kafka-python 是一个 Python 的 Kafka 客户端,可以用来向 Kafka 的 Topic 发送消息、消费消息。
这个实验会实现一个 Producer 和一个 Consumer。roducer 向 Kafka 发送消息,Consumer 从 Topic 中消费消息。结构如下图:

# producer.py
import time
from kafka import KafkaProducerproducer = KafkaProducer(bootstrap_servers="localhost:9092")
i = 0
while True:ts = int(time.time() * 1000)producer.send(topic="test", value=str(i), key=str(i), timestamp_ms=ts)producer.flush()print ii += 1time.sleep(1)
# consumer.py
from kafka import KafkaConsumerconsumer = KafkaConsumer("test", bootstrap_servers=["localhost:9092"])
for message in consumer:print message
接下来创建一个 Topic,名为 test。
$ bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
Created topic "test".
打开两个窗口中,我们在 window-1 中运行 producer.py,如下:
# window-1
$ python producer.py
0
1
2
3
4
5
...
在 window-2 中运行 consumer.py,如下:
# window-2
$ python consumer.py
ConsumerRecord(topic=u'test', partition=0, offset=128, timestamp=1512554839806, timestamp_type=0, key='128', value='128', checksum=-1439508774, serialized_key_size=3, serialized_value_size=3)
ConsumerRecord(topic=u'test', partition=0, offset=129, timestamp=1512554840827, timestamp_type=0, key='129', value='129', checksum=1515993224, serialized_key_size=3, serialized_value_size=3)
ConsumerRecord(topic=u'test', partition=0, offset=130, timestamp=1512554841834, timestamp_type=0, key='130', value='130', checksum=453490213, serialized_key_size=3, serialized_value_size=3)
ConsumerRecord(topic=u'test', partition=0, offset=131, timestamp=1512554842841, timestamp_type=0, key='131', value='131', checksum=-632119731, serialized_key_size=3, serialized_value_size=3)
...
可以看到 window-2 中的 Consumer 成功的读到了 Producer 写入的数据。
5.2 实验二:消费组实现容错性机制
这个实验将展示消费组的容错性的特点。这个实验中将创建一个有 2 个 Partition 的 Topic,和 2 个 Consumer,这 2 个 Consumer 共同消费同一个 Topic 中的数据。结构如下所示:

Producer 部分代码和实验一相同,这里不再重复。Consumer 需要指定所属的 Consumer Group,代码如下:
# consumer.py
from kafka import KafkaConsumerconsumer = KafkaConsumer("test", bootstrap_servers=["localhost:9092"], group_id="testgroup")
for message in consumer:print message
接下来我们创建一个 Topic,名为 Test,设置 Partition 数量为 2。
$ bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 2 --topic test
Created topic "test".
打开三个窗口,一个窗口运行 Producer,还有两个窗口运行 Consumer。
运行 Consumer 的两个窗口的输出如下:
# window-1
$ python consumer.py
ConsumerRecord(topic=u'test', partition=0, offset=11, timestamp=1512556619298, timestamp_type=0, key='15', value='15', checksum=-1492440752, serialized_key_size=2, serialized_value_size=2)
ConsumerRecord(topic=u'test', partition=0, offset=12, timestamp=1512556621308, timestamp_type=0, key='17', value='17', checksum=-1029407634, serialized_key_size=2, serialized_value_size=2)
ConsumerRecord(topic=u'test', partition=0, offset=13, timestamp=1512556622316, timestamp_type=0, key='18', value='18', checksum=1544755853, serialized_key_size=2, serialized_value_size=2)
ConsumerRecord(topic=u'test', partition=0, offset=14, timestamp=1512556624326, timestamp_type=0, key='20', value='20', checksum=2130557725, serialized_key_size=2, serialized_value_size=2)
...# window-2
$ python consumer.py
ConsumerRecord(topic=u'test', partition=1, offset=6, timestamp=1512556617287, timestamp_type=0, key='13', value='13', checksum=-1494513008, serialized_key_size=2, serialized_value_size=2)
ConsumerRecord(topic=u'test', partition=1, offset=7, timestamp=1512556618293, timestamp_type=0, key='14', value='14', checksum=-1499251221, serialized_key_size=2, serialized_value_size=2)
ConsumerRecord(topic=u'test', partition=1, offset=8, timestamp=1512556620303, timestamp_type=0, key='16', value='16', checksum=-783427375, serialized_key_size=2, serialized_value_size=2)
ConsumerRecord(topic=u'test', partition=1, offset=9, timestamp=1512556623321, timestamp_type=0, key='19', value='19', checksum=-1902514040, serialized_key_size=2, serialized_value_size=2)
ConsumerRecord(topic=u'test', partition=1, offset=10, timestamp=1512556626337, timestamp_type=0, key='22', value='22', checksum=782849423, serialized_key_size=2, serialized_value_size=2)
...
可以看到两个 Consumer 同时运行的情况下,它们分别消费不同 Partition 中的数据。window-1 中的 Consumer 消费 Partition 0 中的数据,window-2 中的 Consumer 消费 Parition 1 中的数据。
我们尝试关闭 window-1 中的 Consumer,可以看到如下结果:
# window-2ConsumerRecord(topic=u'test', partition=1, offset=105, timestamp=1512557514410,timestamp_type=0, key='46', value='46', checksum=-1821060627, serialized_key_size=2, serialized_value_size=2)
ConsumerRecord(topic=u'test', partition=1, offset=106, timestamp=1512557518428,timestamp_type=0, key='50', value='50', checksum=281004575, serialized_key_size=2, serialized_value_size=2)
ConsumerRecord(topic=u'test', partition=1, offset=107, timestamp=1512557521442,timestamp_type=0, key='53', value='53', checksum=1245067939, serialized_key_size=2, serialized_value_size=2)
ConsumerRecord(topic=u'test', partition=1, offset=108, timestamp=1512557525461,timestamp_type=0, key='57', value='57', checksum=-1003840299, serialized_key_size=2, serialized_value_size=2)
ConsumerRecord(topic=u'test', partition=0, offset=98, timestamp=1512557494325, timestamp_type=0, key='26', value='26', checksum=-1576244323, serialized_key_size=2, serialized_value_size=2)
ConsumerRecord(topic=u'test', partition=0, offset=99, timestamp=1512557495329, timestamp_type=0, key='27', value='27', checksum=510530536, serialized_key_size=2, serialized_value_size=2)
ConsumerRecord(topic=u'test', partition=0, offset=100, timestamp=1512557502360,timestamp_type=0, key='34', value='34', checksum=1781705793, serialized_key_size=2, serialized_value_size=2)
ConsumerRecord(topic=u'test', partition=0, offset=101, timestamp=1512557504368,timestamp_type=0, key='36', value='36', checksum=2142677730, serialized_key_size=2, serialized_value_size=2)
ConsumerRecord(topic=u'test', partition=0, offset=102, timestamp=1512557505372,timestamp_type=0, key='37', value='37', checksum=-1376259357, serialized_key_size=2, serialized_value_size=2)
...
刚开始 window-2 中的 Consumer 只消费 Partition 1 中的数据,当 window-1 中的 Consumer 退出后,window-2 中的 Consumer 中也开始消费 Partition 0 中的数据了。
5.3 实验三:Offset 管理
Kafka 允许 Consumer 将当前消费的消息的 Offset 提交到 Kafka中,这样如果 Consumer 因异常退出后,下次启动仍然可以从上次记录的 Offset 开始向后继续消费消息。
这个实验的结构和实验一的结构是一样的,使用一个 Producer,一个 Consumer,主题 test 的 Partition 数量设为 1。
Producer 的代码和实验一中的一样,这里不再重复。Consumer 的代码稍作修改,这里 Consumer 中打印出下一个要被消费的消息的 Offset。Consumer 代码如下:
from kafka import KafkaConsumer, TopicPartitiontp = TopicPartition("test", 0)
consumer = KafkaConsumer(bootstrap_servers=["localhost:9092"], group_id="testgroup", auto_offset_reset="earliest", enable_auto_commit=False)
consumer.assign([tp])
print "start offset is", consumer.position(tp)
for message in consumer:print message
在一个窗口中启动 Producer,在另一个窗口并且启动 Consumer。Consumer 的输出如下:
$ python consumer.py
start offset is 98
ConsumerRecord(topic=u'test', partition=0, offset=98, timestamp=1512558902904, timestamp_type=0, key='98', value='98', checksum=-588818519, serialized_key_size=2, serialized_value_size=2)
ConsumerRecord(topic=u'test', partition=0, offset=99, timestamp=1512558903909, timestamp_type=0, key='99', value='99', checksum=1042712647, serialized_key_size=2, serialized_value_size=2)
ConsumerRecord(topic=u'test', partition=0, offset=100, timestamp=1512558904915, timestamp_type=0, key='100', value='100', checksum=-838622723, serialized_key_size=3, serialized_value_size=3)
ConsumerRecord(topic=u'test', partition=0, offset=101, timestamp=1512558905920, timestamp_type=0, key='101', value='101', checksum=-2020362485, serialized_key_size=3, serialized_value_size=3)
ConsumerRecord(topic=u'test', partition=0, offset=102, timestamp=1512558906926, timestamp_type=0, key='102', value='102', checksum=-345378749, serialized_key_size=3, serialized_value_size=3)
...
可以尝试退出 Consumer,再启动 Consumer。每一次重新启动,Consumer 都是从 offset=98 的消息开始消费的。
修改 Consumer 的代码如下,在 Consumer 消费每一条消息后将 offset 提交回 Kafka。
from kafka import KafkaConsumer, TopicPartition, OffsetAndMetadatatp = TopicPartition("test2", 0)
consumer = KafkaConsumer(bootstrap_servers=["localhost:9092"], group_id="testgroup", auto_offset_reset="earliest", enable_auto_commit=False)
consumer.assign([tp])
print "start offset is ", consumer.position(tp)
for message in consumer:print messageconsumer.commit(message.offset + 1)
启动 Consumer
$ python consumer.py
start offset is 98
ConsumerRecord(topic=u'test', partition=0, offset=98, timestamp=1512559632153, timestamp_type=0, key='824', value='824', checksum=828849435, serialized_key_size=3, serialized_value_size=3)
...
ConsumerRecord(topic=u'test', partition=0, offset=827, timestamp=1512559635164, timestamp_type=0, key='827', value='827', checksum=442222330, serialized_key_size=3, serialized_value_size=3)
ConsumerRecord(topic=u'test', partition=0, offset=828, timestamp=1512559636169, timestamp_type=0, key='828', value='828', checksum=-267344764, serialized_key_size=3, serialized_value_size=3)
ConsumerRecord(topic=u'test', partition=0, offset=829, timestamp=1512559637173, timestamp_type=0, key='829', value='829', checksum=1225853586, serialized_key_size=3, serialized_value_size=3)
可以看到 Consumer 从 offset=98 的消息开始消费,到 offset=829 时,我们 Ctrl+C 退出 Consumer。
我们再次启动 Consumer
$ python consumer.py
start offset is 830
ConsumerRecord(topic=u'test', partition=0, offset=830, timestamp=1512559638177, timestamp_type=0, key='830', value='830', checksum=1003305652, serialized_key_size=3, serialized_value_size=3)
ConsumerRecord(topic=u'test', partition=0, offset=831, timestamp=1512559639181, timestamp_type=0, key='831', value='831', checksum=-361607666, serialized_key_size=3, serialized_value_size=3)
ConsumerRecord(topic=u'test', partition=0, offset=832, timestamp=1512559640185, timestamp_type=0, key='832', value='832', checksum=-345891932, serialized_key_size=3, serialized_value_size=3)
...
可以看到重新启动后,Consumer 从上一次记录的 offset 开始继续消费消息。之后每一次 Consumer 重新启动,Consumer 都会从上一次停止的地方继续开始消费。
6.总结
本文主要介绍了一下 Kafka 的基本概念,并结合一些实验帮助理解 Kafka 中的一些难点,如多个 Consumer 的容错性机制,Offset 管理。
相关文章:
【大数据】Kafka 入门简介
Kafka 入门简介 1.什么是 Kafka2.Kafka 的基本概念3.Kafka 分布式架构4.配置单机版 Kafka4.1 下载并解压包4.2 启动 Kafka4.3 创建 Topic4.4 向 Topic 中发送消息4.5 从 Topic 中消费消息 5.实验5.1 实验一:Python 实现生产者消费者5.2 实验二:消费组实现…...

Unity可视化Shader工具ASE介绍——8、UI类型的特效Shader编写
阿赵的Unity可视化Shader工具ASE介绍目录 Unity的UGUI图片特效角色闪卡效果 大家好,我是阿赵。 继续介绍Unity可视化Shader编辑插件ASE的使用。这次讲一下UI类特效Shader的写法。 一、例子说明 这次编写一个Shader,给一张UGUI里面的图片增加一个闪卡…...

科学指南针XPS | SEM | BET 降价:不赚钱,就和您交个朋友
尊敬的各位客户: 感谢您一直以来对科学指南针服务平台(下文简称:科学指南针)的支持和信任!科学指南针本着服务第一,客户至上的精神,多年来坚持为客户提供高质量的测试和服务,获得了广…...
nginx正反向代理,负载均衡
Nginx 正向代理,反向代理 ,负载均衡 Nginx有两种代理协议 七层代理(http协议) 四层代理(tcp/udp流量转发) 四层代理七层代理概念 四层代理 四层代理:基于tcp/ip协议层的转发代理方式&#…...
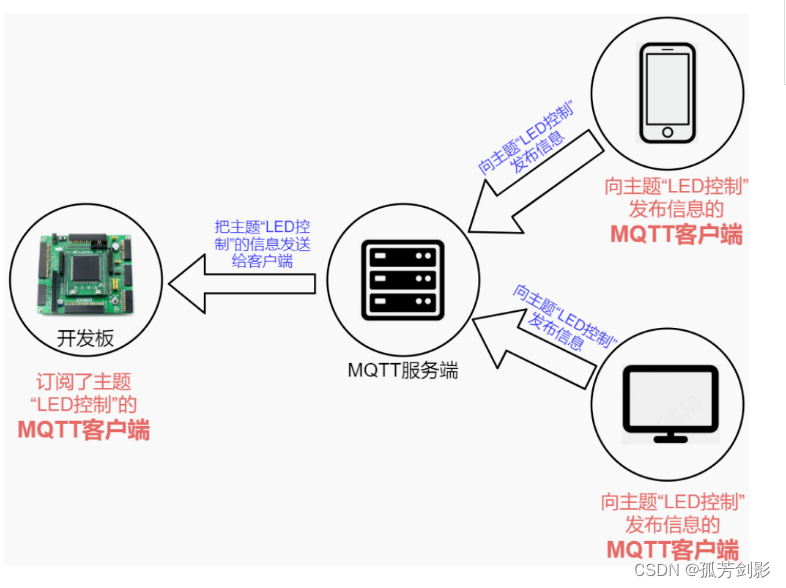
物联网中的MQTT协议总结
本文引注: https://mp.weixin.qq.com/s/y55wqYoWEvU9Q3-I0uu3cg 物联网曾被认为是继计算机、互联网之后,信息技术行业的第三次浪潮。随着基础通讯设施的不断完善,尤其是 5G 的出现,进一步降低了万物互联的门槛和成本。物联网本身也是 AI 和区…...

断点续传的原理和实现
断点续传是一种文件上传或下载的技术,允许用户在上传或下载中断后恢复操作而不必重新开始。其原理和实现可以分为以下步骤: 原理: 文件分割:将大文件分割成小块(分片)。上传/下载:客户端上传或…...
【小黑嵌入式系统第二课】嵌入式系统的概述(二)——外围设备、处理器、ARM、操作系统
上一课: 【小黑嵌入式系统第一课】嵌入式系统的概述(一)——概念、特点、发展、应用 下一课: 【小黑嵌入式系统第三课】嵌入式系统硬件平台(一)——概述、总线、存储设备(RAM&ROM&FLASH…...

Unity3D 在做性能优化时怎么准确判断是内存、CPU、GPU瓶颈详解
Unity3D是一款广泛应用于游戏开发的跨平台游戏引擎,但在开发过程中,我们经常会遇到性能瓶颈问题,如内存、CPU和GPU瓶颈。本文将详细介绍在Unity3D中如何准确判断和解决这些瓶颈问题,并给出相应的技术详解和代码实现。 对惹&#…...
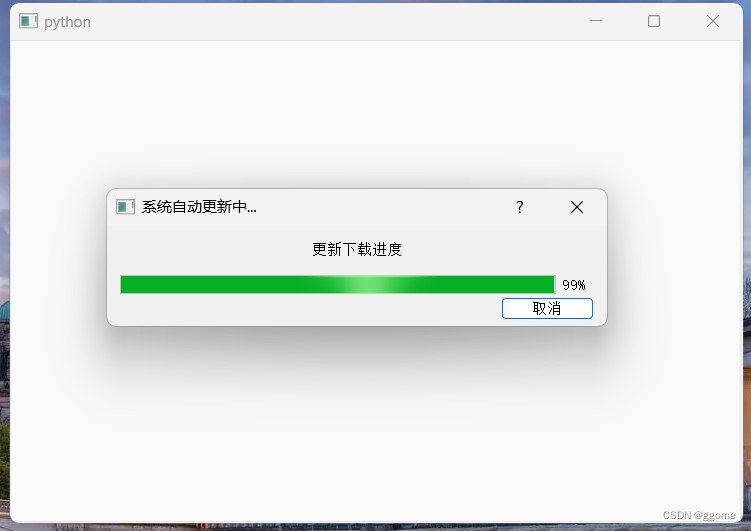
pyqt5 QProgressDialog 进度条的使用 下载自动更新应用程序
pyqt5 QProgressDialog 进度条的使用 案例截图 思路 实例化进度条窗口设置窗口各属性包括标题 提示文字 和 窗口大小显示进度条窗口同过一个for循环 模拟进度 代码 from PyQt5.QtCore import QCoreApplication, QProcess from PyQt5.QtWidgets import QApplication,QProgre…...

【yolov5目标检测】使用yolov5训练自己的训练集
数据集准备 首先得准备好数据集,你的数据集至少包含images和labels,严格来说你的images应该包含训练集train、验证集val和测试集test,不过为了简单说明使用步骤,其中test可以不要,val和train可以用同一个,…...

出差学小白知识No5:ubuntu连接开发板|上传源码包|板端运行的环境部署
1、ubuntu连接开发板: 在ubuntu终端通过ssh协议来连接开发板,例如: ssh root<IP_address> 即可 这篇文章中也有关于如何连接开发板的介绍,可以参考SOC侧跨域实现DDS通信总结 2、源码包上传 通过scp指令,在ub…...

C++(初阶四)类和对象
文章目录 一、面向过程和面向对象初步认识二、类的引入三、类的定义1、类的概述2、类的两种定义3、成员变量命名规则的建议 四、类的访问限定符及封装1、访问限定符2、封装 五、类的作用域六、类的实例化七、类对象模型1、如何计算类对象的大小2、 类对象的存储方式猜测3、 验证…...

CSS餐厅练习链接及答案
目录 链接: level 1 level 2 level 3 level 4 level 5 level 6 level 7 level 8 level 9 level 10 level 11 level 12 level 13 level 14 level 15 level 16 level 17 level 18 level 19 level 20 level 21 level 22 level 23 level 24 le…...
嵌入式和 Java选哪个?
今日话题,嵌入式和 Java 走哪个?对于嵌入式领域有浓厚兴趣的人,并不会比Java行业薪资低,处于上中游水平。特别是从2020年开始,嵌入式领域受益于芯片产业的兴起,表现出了强劲的增长势头。薪资水平受多方面因素影响。以…...
)
创建带Axi_Lite接口的IP核与AXI Interconnect(PG059)
AXI Interconnect互连内核将一个或多个 AXI 内存映射主设备连接到一个或多个内存映射从设备。 参考小梅哥文档。 /**************************** 类型定义 ****************** **********/ /** * * 将值写入 AXI_REG_LIST 寄存器。执行 32 位写入。 * 如果组件以较小的宽度实…...
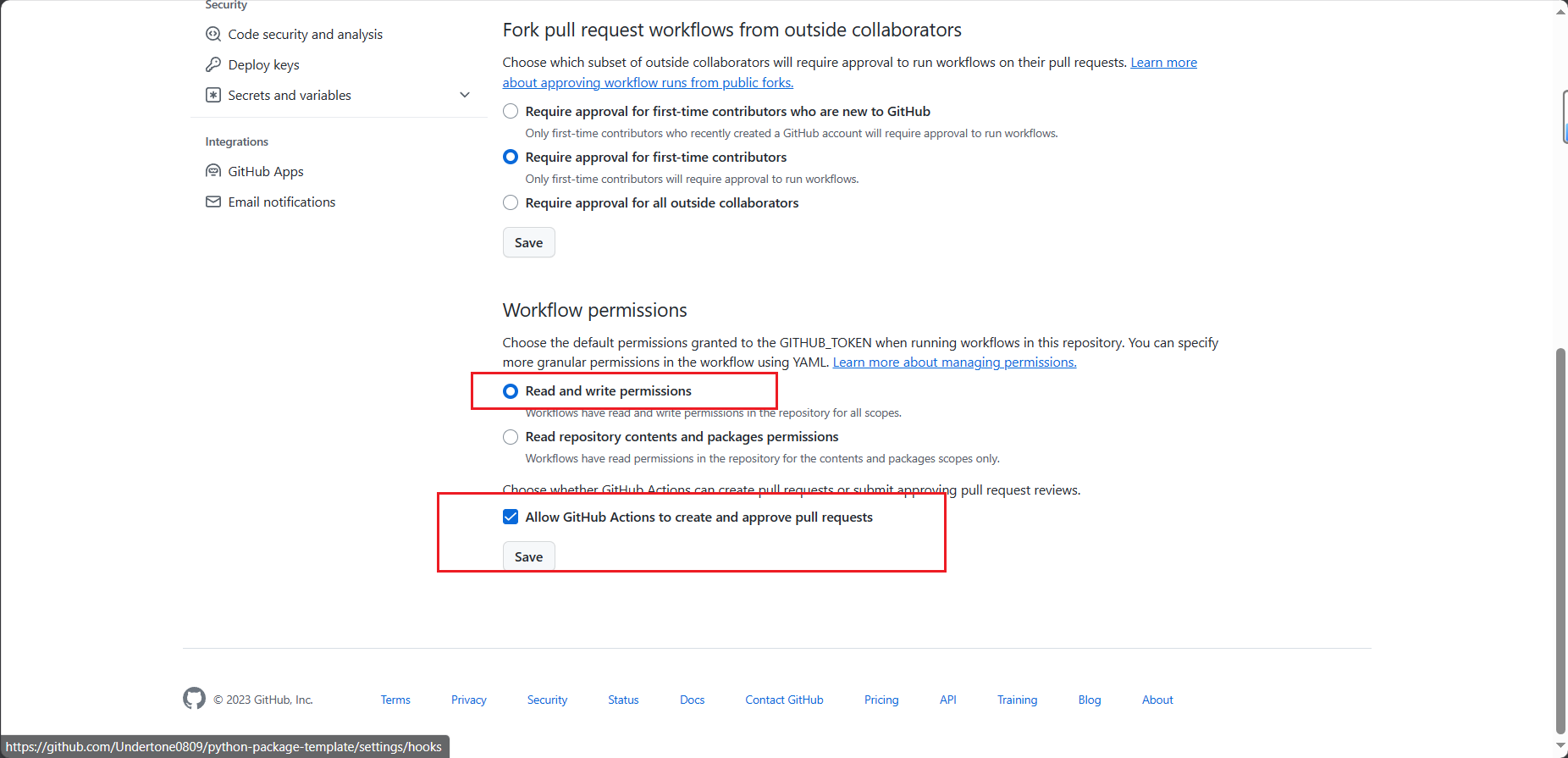
快速解决 Resource not accessible by integration
简介 最近好久没有写博客了,今天在写开源项目 python-package-template 的时候,正好遇到一个问题,记录一下吧。本文将介绍 Resource not accessible by integration 的几种解决方案。 也欢迎大家体验一下 python-package-template 这个项目&…...

港联证券:资金融通构成强支撑 “一带一路”金融合作开新局
本年是共建“一带一路”主张提出十周年。经过十年打开,共建“一带一路”从夯基垒台、立柱架梁到落地生根、持久打开,已成为打开包容、互利互惠、协作共赢的国际协作途径。“资金融通”作为首份“一带一路”白皮书提出的“五通”之一,定位为“…...
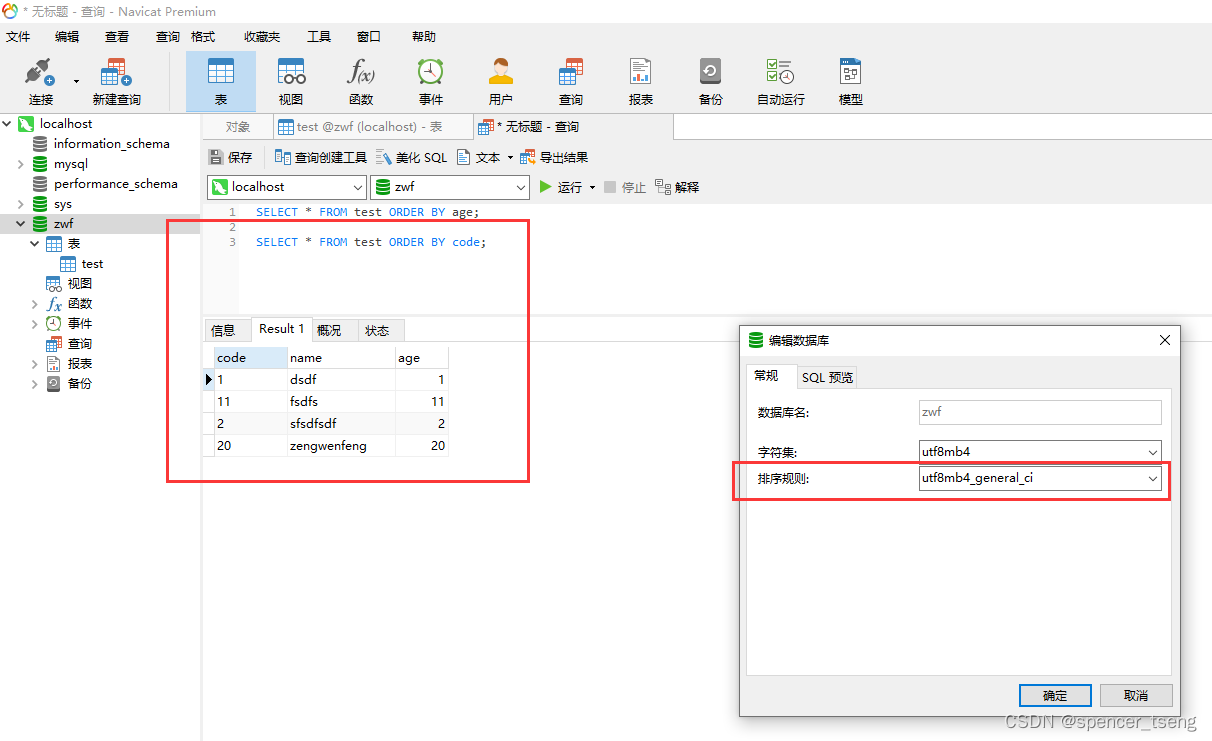
mysql varchar int
年龄是数字类型int SELECT * FROM test ORDER BY age; 年龄是字符类型varchar SELECT * FROM test ORDER BY code; 第1种 补前导0可以和数字一样排序 MySQL会比较字符的ASCII值,并根据这些值来确定字符的排列顺序。 印象中oracle好像也是吧。 ASCII (American …...

阿里云/腾讯云国际站账号:私服游戏服务器:阿里云CTO周靖人:AI时代,为什么阿里云一定要做开源
开源技术报告,阿里云私服游戏服务器怎么看待大模型的路径? 随着 Meta 的 Llama2 开源,开源模型,以及聚集大模型开发者的开源社区,正在发挥不可或缺的作用。 一个例子是,上个月 Hugging Face 得到了谷歌、…...
搭建Pytorch的GPU环境超详细
效果 1、下载和安装VS2019 https://visualstudio.microsoft.com/zh-hans/vs/older-downloads/ 登录需要用户名和密码 安装后需要联网下载组件的,安装的时候要勾选使用C++的桌面开发 2、下载和安装显卡驱动 查看自己的显卡型号 从英伟达下载和安装最新驱动...

GG3M贝叶斯决策数学体系:六大核心领域落地应用与差异化壁垒
GG3M贝叶斯决策数学体系:六大核心领域落地应用与差异化壁垒摘要 GG3M的贝叶斯更新与决策数学体系,基于原创“事实层—模型层—元模型层”三层级架构,以系统长期反熵增演化为核心决策标尺,从“智能参数优化”跨越至“智慧框架迭代”…...

Linux进程调度机制与性能优化实践
1. Linux进程调度概述在Linux操作系统中,进程调度是内核最核心的功能之一。作为一个多任务操作系统,Linux需要合理地分配有限的CPU资源给众多进程,使它们能够高效、公平地运行。理解Linux的调度机制,对于系统性能调优、应用开发以…...

从 Python 和 Node.js 的流行看 Java 的真实位置
很多 Java 程序员都会有一个感觉:Python 很火,Node.js 也很火,Java 是不是没落了? 先说结论:Java 没有没落,只是位置变了。一、为什么 Python 和 Node.js 看起来更火 1. Python 火,是因为 AI 太…...

快马ai一键生成:windows 11自动化部署openclaw环境原型脚本
最近在折腾Windows 11的开发环境配置,发现每次换新机器都要重复安装一堆工具链特别麻烦。正好发现了OpenClaw这个开源工具,它号称能自动化搞定开发环境部署。不过手动安装配置还是有点繁琐,于是我用InsCode(快马)平台快速生成了一个自动化安装…...
)
超导电路阵列实验方案 V1.0桌面量子引力实验(自指动力学与类时空关联涌现)
超导电路阵列实验方案 V1.0 桌面量子引力实验(自指动力学与类时空关联涌现) 方案编号:SR-EXP-QG-001 版本:V1.0 一、核心科学目标 1. 科学目标 在一维/二维超导量子比特阵列中,引入全局量子态测量 实时反馈构建强自指…...

tomcat和国产web中间件区别和联系
国产中间件 宝蓝德 https://www.bessystem.com/product/e717be5b091e4e14a7339aa4be49ca80/info?p101东方通 https://www.tongtech.com/sy.html非国产tomcat tomcat的项目发布方式 将项目复制到tomcat/webapps中启动Tomcat服务器,双击 startup.bat访问项目 IDEA 中…...

R Markdown网站生成器使用教程:如何快速搭建技术文档网站 [特殊字符]
R Markdown网站生成器使用教程:如何快速搭建技术文档网站 📊 【免费下载链接】rmarkdown Dynamic Documents for R 项目地址: https://gitcode.com/gh_mirrors/rm/rmarkdown R Markdown是一个强大的动态文档生成工具,能够将代码、输出…...

CentOS7下KingbaseES V9与MySQL性能对比实测:从安装到查询优化的全流程体验
CentOS7下KingbaseES V9与MySQL性能对比实测:从安装到查询优化的全流程体验 在国产数据库技术快速发展的今天,越来越多的企业开始关注从传统数据库向国产化解决方案的迁移。作为国产数据库中的佼佼者,KingbaseES V9凭借其出色的MySQL兼容性和…...

DocRes:统一文档图像修复任务的通用模型技术解析
DocRes:统一文档图像修复任务的通用模型技术解析 【免费下载链接】DocRes [CVPR 2024] DocRes: A Generalist Model Toward Unifying Document Image Restoration Tasks 项目地址: https://gitcode.com/gh_mirrors/do/DocRes 文档图像修复不再需要多个专用模…...

3D模型轻量化3大技术路径:实现60%体积缩减与跨平台适配
3D模型轻量化3大技术路径:实现60%体积缩减与跨平台适配 【免费下载链接】threestudio A unified framework for 3D content generation. 项目地址: https://gitcode.com/gh_mirrors/th/threestudio 副标题:解决移动端加载缓慢、Web端交互卡顿、AR…...