Elasticsearch Relevance Engine---为AI变革提供高级搜索能力[ES向量搜索、常用配置参数、聚合功能等详解]
Elasticsearch Relevance Engine—为AI变革提供高级搜索能力[ES向量搜索、常用配置参数、聚合功能等详解]
今天要介绍的 Elasticsearch Relevance Engine™ (ESRE™),提供了多项用于创建高度相关的 AI 搜索应用程序的新功能。ESRE 站在 Elastic 这个搜索领域的巨人肩膀之上,并基于两年多的 Machine Learning 研发成就构建而成。Elasticsearch Relevance Engine 将 AI 的最佳实践与 Elastic 的文本搜索进行了结合。ESRE 为开发人员提供了一整套成熟的检索算法,并能够与大型语言模型 (LLM) 集成。不仅如此,ESRE 还可通过已经得到 Elastic 社区信任的简单、统一的 API 访问,因此世界各地的开发人员都可以立即开始使用它来提升搜索相关性。

Elasticsearch Relevance Engine 的可配置功能可用于通过以下方式帮助提高相关性:
-
应用包括 BM25f(这是混合搜索的关键组成部分)在内的高级相关性排序功能
-
使用 Elastic 的矢量数据库创建、存储和搜索密集嵌入
-
使用各种自然语言处理 (NLP) 任务和模型处理文本
-
让开发人员在 Elastic 中管理和使用自己的转换器模型,以适应业务特定的上下文
-
通过 API 与第三方转换器模型(如 OpenAI 的 GPT-3 和 4)集成,以根据客户在 Elasticsearch 部署中整合的数据存储,检索直观的内容摘要
-
使用 Elastic 开箱即用型的 Learned Sparse Encoder 模型,无需训练或维护模型,就能实现 ML 支持的搜索,从而在各种域提供高度相关的语义搜索
-
使用倒数排序融合 (RRF) 轻松组合稀疏和密集检索;倒数排序融合是一种混合排名方法,让开发人员能够自行优化 AI 搜索引擎,以符合他们独特的自然语言和关键字查询类型的组合
-
与 LangChain 等第三方工具集成,以帮助构建复杂的数据管道和生成式 AI 应用程序
-
克服生成式 AI 模型的局限性
Elasticsearch Relevance Engine™ 非常适合助力开发人员快速发展,并应对包括生成式 AI 在内的自然语言搜索方面的这些挑战。
-
企业数据/上下文感知:模型可能没有足够的与特定域相关的内部知识。这要源于训练模型的数据集。为了定制 LLM 生成的数据和内容,企业需要一种方法来向模型馈送专有数据,以便模型能够学会提供更相关、特定于业务的信息。
-
卓越的相关性:Elasticsearch Relevance Engine 让整合来自私有来源的数据变得非常简单,只需生成和存储矢量嵌入,便可使用语义搜索来检索上下文。矢量嵌入是单词、短语或文档的数字化表示,可以帮助 LLM 理解单词的含义及其关系。这些嵌入可以增强转换器模型的输出速度和规模。此外,ESRE 还可让开发人员将自己的转换器模型引入到 Elastic 中或与第三方模型集成。
我们也意识到,后期交互模型的出现使我们能够提供这种开箱即用型的功能,而无需对第三方数据集进行大量训练或微调。由于并非每个开发团队都有资源或专业知识来训练和维护 Machine Learning 模型,也不了解如何在规模、性能和速度之间进行权衡,因此 Elasticsearch Relevance Engine 还提供了一个为跨不同域进行语义搜索而构建的检索模型 Elastic Learned Sparse Encoder。该模型将稀疏嵌入与传统的基于关键字的 BM25 搜索配对,为混合搜索提供了一个易于使用的倒数排序融合 (RRF) 评分器。ESRE 从一开始就为开发人员提供了 Machine Learning 驱动的相关性和混合搜索技术。
- 隐私和安全:数据隐私是企业如何通过网络和在组件之间使用和安全地传递专有数据的核心,即使在构建创新的搜索体验时也是如此。
Elastic 提供对基于角色和基于属性的访问控制的原生支持,以确保只有那些有权限访问数据的角色才能看到数据,即使对于聊天和问题回答应用程序也可以进行如此设置。Elasticsearch 可以支持您的组织保持某些文档可供特权个人访问的需求,从而帮助组织维护所有搜索应用程序的通用隐私和访问控制。当隐私是最重要的关注点时,将所有数据保留在组织的网络内,不仅至关重要,而且是强制性的。从允许组织在气隙环境中实施部署,到支持访问安全网络,ESRE 提供了您所需的各种工具,助力您的组织保护数据安全。
- 规模和成本:由于数据量以及所需的计算能力和内存,使用大型语言模型可能会让许多企业望而却步。然而,想要构建自己的生成式 AI 应用(如聊天机器人)的企业需要将 LLM 与他们的私有数据结合起来。
Elasticsearch Relevance Engine 为企业提供了一种可通过精确的上下文窗口高效提供相关性的引擎,既有助于减少数据占用空间,又不会增加工作量和费用。
- 过时:模型在收集训练数据的时候就已被冻结在过去的某一时间点上。因此,生成式 AI 模型所创建内容和数据只有在基于它们进行训练时才是最新的。整合公司数据是让 LLM 能够提供及时结果的内在需求。
- 幻觉:当回答问题或进行交互式对话时,LLM 模型可能会编造一些听起来可信和令人信服的事实,但实际上是一些不符合事实的预测。这也是为什么需要将 LLM 与具有上下文、定制的知识相结合的另一个原因,这对于让模型在商业环境中发挥作用至关重要。
借助 Elasticsearch Relevance Engine,开发人员可通过生成式 AI 模型中的上下文窗口关联到自己的数据存储。添加的搜索结果可以提供来自私有来源或专业领域的最新信息,因此在有询问时可以返回更多的事实信息,而不是仅仅依赖于模型所谓的“参数化”知识。
-
-
通过矢量数据库提高效率
Elasticsearch Relevance Engine 在设计上包含了一个具有弹性的生产级矢量数据库。它为开发人员提供了构建丰富的语义搜索应用程序的基础。使用 Elastic 的平台,开发团队可以使用密集的矢量检索来创建更直观的问题回答,而不受关键字或同义词的限制。他们可以使用图像等非结构化数据构建多模态搜索,甚至可以对用户概要文件进行建模并创建匹配项,以在产品和发现、求职或配对应用程序中个性化搜索结果。此外,这些 NLP 转换器模型还支持情绪分析、命名实体识别和文本分类等 Machine Learning 任务。通过 Elastic 的矢量数据库,开发人员可以创建、存储和查询嵌入,这些嵌入具有高度可扩展性和优异性能,适用于真正的生产应用程序。
Elasticsearch 特别适用于进行高相关性的搜索检索。通过 ESRE,Elasticsearch 为与企业专有数据关联的生成式 AI 提供了上下文窗口,让开发人员能够构建更吸引人、更准确的搜索体验。搜索结果是根据用户的原始查询返回的,开发人员可以将数据传递给他们选择的语言模型,以提供带有附加了上下文的答案。Elastic 利用来自您企业内容存储中的相关上下文数据,为问题回答和个性化功能提供动力,这些数据是私有的,也是专为您的业务量身定制的。
https://www.elastic.co/cn/blog/may-2023-launch-announcement
1. ES 向量检索
KNN(k-nearest neighbor) search vs ANN search
KNN 检索:给定一个 query vector,寻找 K 个与之最相近的向量。数据量太时,KNN 检索性能太差,实际应用中一般采用 ANN 检索。
1.1 向量检索的步骤
- 将待检索的数据转换成向量表示,比如将 “有商品曝光的 query” 通过 transformer 转换成 query embing 向量,其表现形式则是:128 维的 float 数组。
- 将 float 数组 indexing 到 ES 的 dense_vector 类型的字段中。
- 基于 ES 提供的 2 种向量检索方式,进行搜索。这 2 种方式分别是:近似 KNN 搜索的 ANN 搜索,以及:精确的暴力 KNN 搜索(基于 script_score 查询实现)
1.2 向量检索中的距离
如何衡量 2 个向量相似?引入了:向量之间的距离。常用的计算距离函数有 3 种:
- l2 norm,欧式距离
- dot-product,向量的点积
- cosine,余弦相似度
1.3 两种向量检索方式
-
暴力 KNN 检索:采用 ES 的 script_score 查询实现,在 script 中指定计算距离的函数。
-
近似的 KNN 检索(ANN):与暴力检索相比,我们可以采用某种算法,牺牲一些精度,来加速查找与 query vector 相似的向量。这种加速查找的算法最常用的如下:
- 基于:倒排 + 聚类的方式 IVF
- 基于:图的方式,HNSW
- 基于 LSH(局部敏感 hash)
- 基于树结构 KD-tree
其中,ES 的 ANN 检索采用:HNSW 算法实现。向量检索工具包 faiss 则将上述各种算法都实现了。
以常见的欧式距离来算,假设向量的维度为k,库总共有 n个item。则搜索一次的时间复杂度为 O(k*n),且整体的查询耗时与item库的大小线性相关,显然这种线上查询要遍历成百万上千万的暴力计算并不满足需求。
考虑到向量检索的大部分场景都是返回与该元素相似的topk个元素即可,比如推荐中的召回,只需召回近似100个item,也不关注item间的相对顺序,也无需100%准确,毕竟上游还会有粗排和精排。因此,工程上会使用近似最近邻搜索(Approximate Nearest Neighbor Search)来解决这个精度和效率上的问题。
- 近似近邻搜索(ANNS)
由于暴力搜索是全局空间搜索,因此为了提高查询效率,大部分的ANN(Approximate Nearest Neighbor)近似算法的核心都是:将所有的数据集按照一定规则划分到一些子空间或者子集里,然后查询的时候用比较低的代价,确认在哪几个子集中搜索计算,这样就避免了全局遍历。
ANN的方法分为三大类:基于树的方法、哈希方法、矢量量化方法。brute-force搜索的方式是在全空间进行搜索,为了加快查找的速度,几乎所有的ANN方法都是通过对全空间分割,将其分割成很多小的子空间,在搜索的时候,通过某种方式,快速锁定在某一(几)子空间,然后在该(几个)子空间里做遍历。
更多内容见:推荐系统[九]项目技术细节讲解z3:向量检索技术与ANN搜索算法[KD树、Annoy、LSH局部哈希、PQ乘积量化、IVFPQ倒排乘积量化、HNSW层级图搜索等],超级详细技术原理讲解
1.4 ES ANN 检索
将待查询的字段放在 “knn” option 里面,发起查询,示例如下:
POST byte-image-index/_search
{
“knn”: {
“field”: “byte-image-vector”,
“query_vector”: [-5, 9],
“k”: 10,
“num_candidates”: 100
},
“fields”: [“title”]
}
涉及的参数有:
- num_candidates,在 ES 的每个分片上执行向量检索,找到与 query-vector 最相近的:num_candidates 个向量返回
- k,对每个分片上的 num_candidates 个向量进行合并,合并成全局的 top k 个向量,返回给 client。
- query_vector,用户输入的向量,从:byte-image-vector 中找到:与 query-vecotr 最相近的 k 个向量返回。
- field,字段名称,byte-image-vector 字段存储了:float 数组,对该字段进行向量检索。
向量检索字段 与 其它字段 「混合」查询
- 方式一:
因为 filter 语句是放在 knn option 里面,在执行 knn 查询的同时,执行 filter 查询,确保能返回 5 个 (k=5) doc。这并不是:后置过滤。所谓后置过滤就是:基于 knn 查询的结果之上,再对 文件类型为 png 的 doc 做过滤,后置过滤可能会导致:最终返回的 doc 不足 5 个。
POST image-index/_search
{
“knn”: {
“field”: “image-vector”,
“query_vector”: [54, 10, -2],
“k”: 5,
“num_candidates”: 50,
“filter”: {
“term”: {
“file-type”: “png”
}
}
},
“fields”: [“title”],
“_source”: false
}
- 方式二:
knn 检索有一个打分,match query 检索有一个打分。根据公式计算出打分最高的 top 10 个(size=10) doc 返回。
score = 0.9 * match_score + 0.1 * knn_score
查询语句如下:
POST image-index/_search
{
“query”: {
“match”: {
“title”: {
“query”: “mountain lake”,
“boost”: 0.9
}
}
},
“knn”: {
“field”: “image-vector”,
“query_vector”: [54, 10, -2],
“k”: 5,
“num_candidates”: 50,
“boost”: 0.1
},
“size”: 10
}
- 参考资料:
- k-nearest neighbor (kNN) search K邻近搜索
- Dense vector field type 稠密向量
- ES官网:语义搜索semantic-search
2.elasticsearch 字段常用配置参数解释
主要解释下面 3 个常用的参数:
- index 参数
- store 与 _source 参数
- doc_value 参数
2.1 index 参数
默认为 true。当设置为 true 时,代表需要对该字段进行检索,也即倒排查询,根据 query 条件 查询 doc_id
2.2 store 与 _source 参数
这 2 个参数是 “互补” 的。一般而言,_source 设置成 false,然后具体需要获取哪个字段时,将该字段的 store 选项设置成 true。因为开启 _source ,表示直接存储的原始的 doc 文件内容,占用的磁盘空间较大。而 store 则表示只存储此字段,采用的是:“行存的方式”(by the way doc_value 是列存方式),相比于_source 存储原始的 doc 文件,“行存方式” 会对该字段建“索引”(索引文件 fdx、数据文件 fdm),从而能够高效访问。
2.3 doc_value
默认开启。开启 doc_value 意味着:在写入 doc 时,会对该字段创建:列存索引,用于排序聚合。类似于 HBase,某字段开启 doc_value 后,会把所有文档中该字段的值放在 “一起存储”,由于同一个字段它的类型是确定的,那么该字段所有的值都放在一起存储能够很好地使用压缩算法进行压缩存储。
举例:有个 ES 索引有 100 个 doc,其中有个字段是 “销量字段 sale_cnt”,它是 int 型的,对销量字段开启了 doc_value,则这 100 个 doc 的 sale_cnt 字段的值 都会 “放在一起存储”,由于这些值都是 int 型的,那就可以用各种数据结构做存储优化(比如压缩算法)
当需要对 销量字段 做排序时,显然是只有获取 销量字段 sale_cnt 所有的值才能排序,那么开启 doc_value 就能大大加速排序了。这也是为什么官方文档中说:doc_value 用于排序聚合的原因。
index 参数代表建立倒排索引结构,是倒排存储。而:store 和 doc_value 则代表建立:正排索引,正排索引有 2 种存储方式:行存和列存,其中 store 采用行存方式实现,doc_value 采用列存方式实现。
- 参考链接
index 参数:https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-index.html
_source 参数:https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-source-field.html
store 参数:https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-store.html
doc_value 参数:https://www.elastic.co/guide/en/elasticsearch/reference/current/doc-values.html
3. ES function_score 查询
官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-function-score-query.html
为什么 function_score 查询可以修改得分?todo: 以示例进行演示
function_score 查询由两部分组成,一个查询语句以及用于计算得分的若干 functions
它有两种查询形式,一种只能有一个 function,如下:
GET /_search
{"query": {"function_score": {"query": { "match_all": {} },"boost": "5","random_score": {}, "boost_mode": "multiply"}}
}另一种可以有多个 function,即:functions 数组下面指定了两个 function,并且每个 function 都带有 filter 过滤条件。只有被 filter 过滤条件命中的文档才会应用 function 来计算得分。支持的 function 类型有:script_score、weight、random_score、field_value_factor、decay_functions。不同的 function 类型计算得分的方式不一样,对于 decay_function,又包含几种 score 函数,比如 guass、exp、linear 函数。
{"query": {"function_score": {"query": { "match_all": {} },"boost": "5", "functions": [{"filter": { "match": { "test": "bar" } },"random_score": {}, "weight": 23},{"filter": { "match": { "test": "cat" } },"weight": 42}],"max_boost": 42,"score_mode": "max","boost_mode": "multiply","min_score": 42}}
}score_mode 参数决定 filter 条件过滤之后打分的文档,它们之间如何结合成一个总分数。以上面示例:filter match “bar” 对命中的文档计算出一个分数,它用的 score 函数是 random_score。filter match “cat” 对命中的文档计算出一个分数,它用的 score 函数是 weight。然后对这两个 filter 命中的文档分数做一个结合 (combined),结合的方式由 score_mode 参数来决定。不同 filter 条件计算的得分衡量维度不一样,比如有些是百分制,有些是小数制,因此需要结合成最终分数时需要统一维度,这就是每个 filter 条件对应的 weight 参数所起的作用。
4.ES terms 聚合功能理解
本文介绍 ES(ES7.8.0) 里面两种不同的聚合统计,cardinality aggregations 和 terms aggregations。为了方便理解,以 MySQL 表的示例数据来讲解 ES 的这两个聚合功能。MySQL 表结构如下:
CREATE TABLE `es_agg_test` (`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键id',`name` varchar(32) COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '名称',`label` varchar(128) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '标签',PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=9 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='es agg 测试示例'示例数据如下:第一列是主键 id,第二列是 name,第三列是 label
1,apple,iphone12
2,apple,iphone11
3,apple,iphone11
4,huawei,mate30
5,huawei,mate30
6,huawei,mate30
7,huawei,p30
8,huawei,mate204.1 cardinality 聚合
1、计算 es_agg_test 表中一共有多少个不同的 label?
SQL 写法:
//SQL,输出 5
select count(distinct (label)) from es_agg_test;ES 代码:
// ES 代码
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.fetchSource(true);
distinct = AggregationBuilders.cardinality("labels").field(label).precisionThreshold(10000);
sourceBuilder.aggregation(distinct);
SearchRequest searchRequest = buildSearchRequest(INDEX, sourceBuilder);
SearchResponse response = esClient.search(searchRequest, RequestOptions.DEFAULT);protected SearchRequest buildSearchRequest(String index, SearchSourceBuilder sourceBuilder) {SearchRequest request = new SearchRequest(index);request.searchType(SearchType.DEFAULT);request.source(sourceBuilder);return request;}cardinality 聚合有个 precision_threshold 参数,ES7.8.0 默认是 3000,最大可配置成 40000,也即:如果 es_agg_test 表里面不同 label 的记录超过 4w,ES 统计出来的结果可能不准确。
4.2terms 聚合
全部 label 聚合统计
有时候,知道一共有多少个不同的 label 还不够,还想知道每个 label 对应的行数(记录数)是多少?
在示例数据中,一共有 5 个不同的 label,我们统计出了所有的这 5 个 label 对应的行数(记录数)。
而有时候,往往需要的是 top N 统计,比如统计行数最多的前 2 个 label,在示例数据中,分别是 “mate30” 和 “iphone11”
SQL 写法:
select label,count((label)) from es_agg_test group by label;输出的结果如下:
mate30,3
iphone11,2
iphone12,1
p30,1
mate20,1相应地,ES 要实现统计每一个 label 对应的行数(记录数),可以通过 terms 聚合来实现。terms 聚合需要传一个 size 参数,具体到上面的示例,也即一个有多少个不同的 label,这可以通过 cardinality 聚合来得到。但是,需要注意 cardinality 聚合参数 precision_threshold 的限制。
top N label 聚合统计
如果只需要统计行数最多的前 2 个 label,那 size 参数如何设置呢?可能大家的第一反应就是 size 参数设置成 2。由于 ES 底层是分布式存储,数据分散在不同的分片中,因此存在一个分布式统计的误差问题。如下 ES 索引有 2 个分片,每个分片上的记录数量如下。如果分片 top2 聚合,就会导致 2 种错误:
1、label 不正确。真正的 top2 label 是 “iphone11” 和 “mate20”,但是分片 top2 聚合产生的结果是 “iphone11” 和 “mate30”
2、数量不正确。label 为 “iphone” 的行数应该是 510,但是聚合出来的结果是 500
正是因为分布式聚合统计存在如上问题,所以 ES 在 terms 聚合时,size 越大,聚合的结果越精确,但是性能开销也越大。
The higher the requested size is, the more accurate the results will be, but also, the more expensive it will be to compute the final results (both due to bigger priority queues that are managed on a shard level and due to bigger data transfers between the nodes and the client).
实际需求是求解 top2,但是若在每个分片上计算 topN 时,是按 top3 来统计的话,上面的示例计算出来的结果就和 “上帝视角” 保持一致了。这也是为什么 terms 聚合里面有个 shard_size 参数的原因,shard_size 的计算公式是:shard_size = (size * 1.5 + 10)
如果要计算 topN,在 ES 每个分片上计算的是 top (N*1.5+10),然后再汇总排序得出 topN。如果在求解 topN 过程中,导致 shard_size 参数超过了 1 万,ES7.8 就会报错:
Trying to create too many buckets. Must be less than or equal to: [10000] but was [10001]. This limit can be set by changing the [search.max_buckets] cluster level setting
shard_size 参数由 ES 的索引动态配置参数 search.max_buckets 参数限制,ES7.8.0 默认是 10000,参考:search.max_buckets 配置。
- 参考链接
- https://stackoverflow.com/questions/57393548/control-number-of-buckets-created-in-an-aggregation
- https://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations-bucket-terms-aggregation.html
更多优质内容请关注公号:汀丶人工智能;会提供一些相关的资源和优质文章,免费获取阅读。
相关文章:
Elasticsearch Relevance Engine---为AI变革提供高级搜索能力[ES向量搜索、常用配置参数、聚合功能等详解]
Elasticsearch Relevance Engine—为AI变革提供高级搜索能力[ES向量搜索、常用配置参数、聚合功能等详解] 今天要介绍的 Elasticsearch Relevance Engine™ (ESRE™),提供了多项用于创建高度相关的 AI 搜索应用程序的新功能。ESRE 站在 Elastic 这个搜索领域的巨人…...
微信小程序之会议OA系统首页布局搭建与Mock数据交互
目录 前言 一、Flex 布局( 分类 编程技术) 1、Flex布局是什么? 2、基本概念 3、容器的属性 3.1 flex-direction属性 3.2 flex-wrap属性 3.3 flex-flow 3.4 justify-content属性 3.5 align-items属性 3.6 align-content属性 4、项目…...
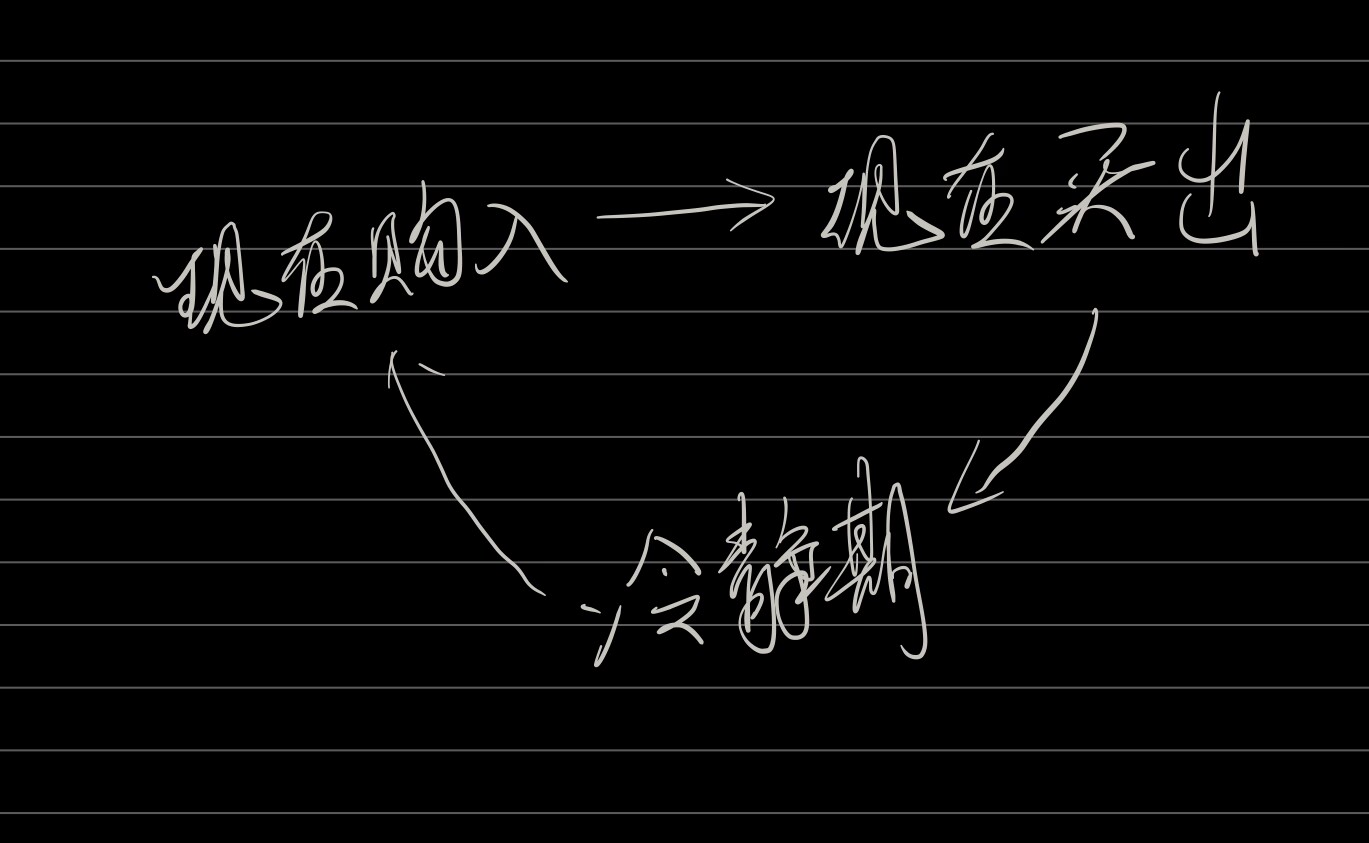
动态规划解股票类型
文章目录 单只股票买卖多次买卖单只股票最多两次买卖股票最多买k次含冷静期含手续费 单只股票买卖 买卖股票的最佳时机 关键思路:找到一个值,他与之后的最大值之差最大。 用minprice记录最小的值,用maxprofit记录最大的收益。 想清楚一个点…...

前端用 js-file-download组件下载后端返回的pdf,word,excel文件
后端返回的pdf,word,excel的文件流导出需要让浏览器下载文件 1、安装js-file-download组件 npm install js-file-download --save 2、在对应的页面引用 import fileDownload from "js-file-download"; 3、在接口返回结果后直接调用即可 let data{id:processId,c…...
Mac硬盘检测工具
Mac硬盘检测软件是一款用于检测和诊断Mac硬盘健康状态的工具,帮助用户及时发现潜在的硬盘问题,避免数据丢失和系统故障。通过全面的检测和报告功能,用户可以更好地了解自己的硬盘状况,确保数据的安全和可靠。给大家介绍几款好用的…...
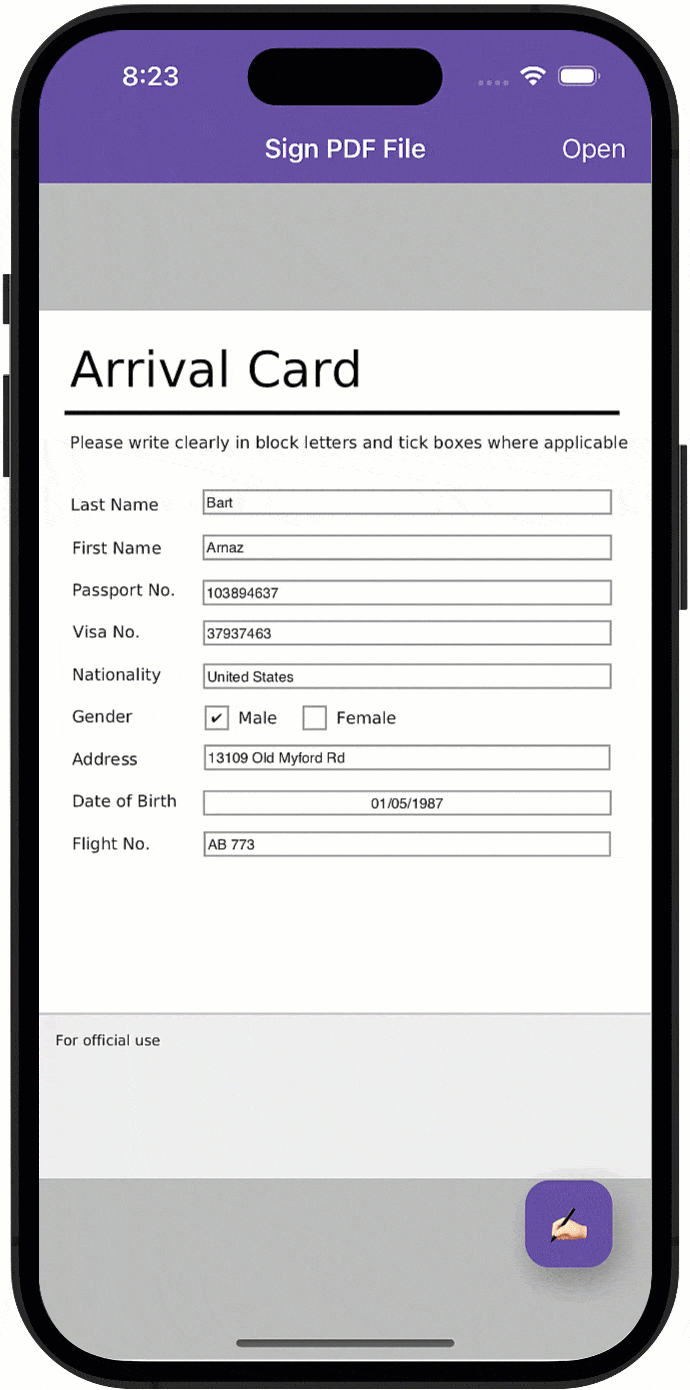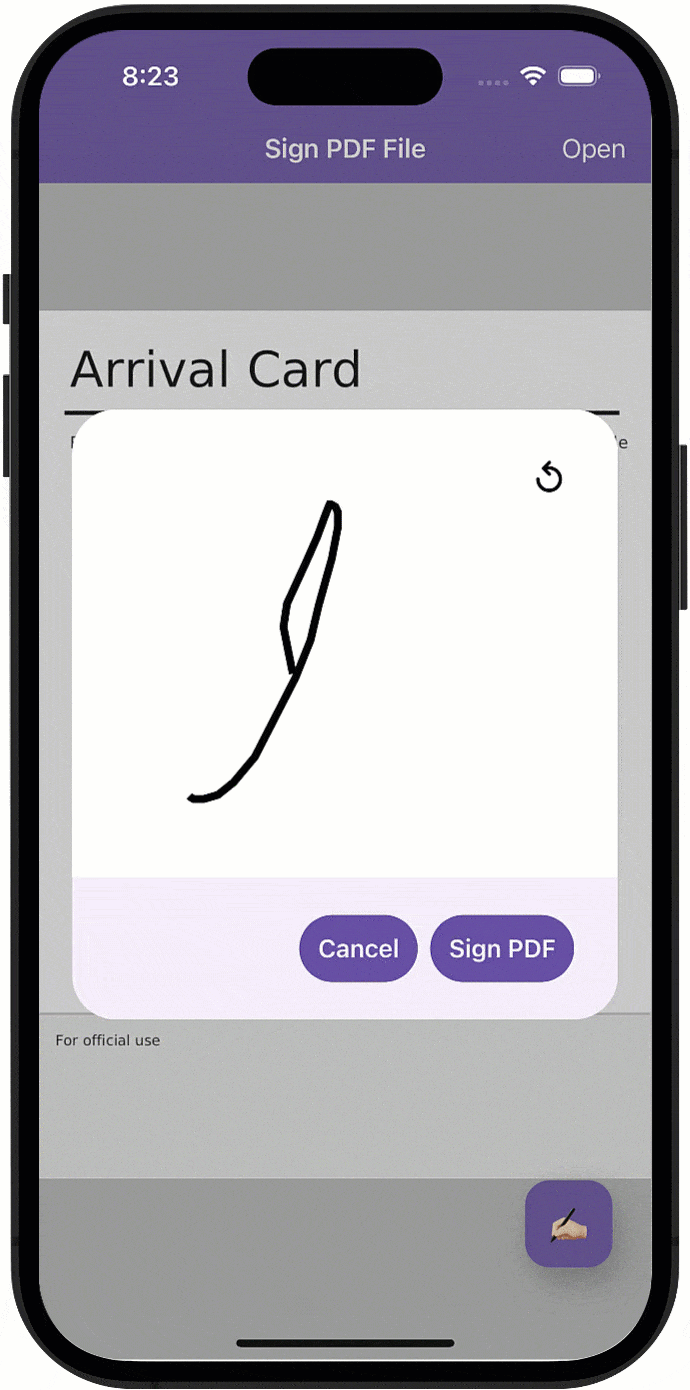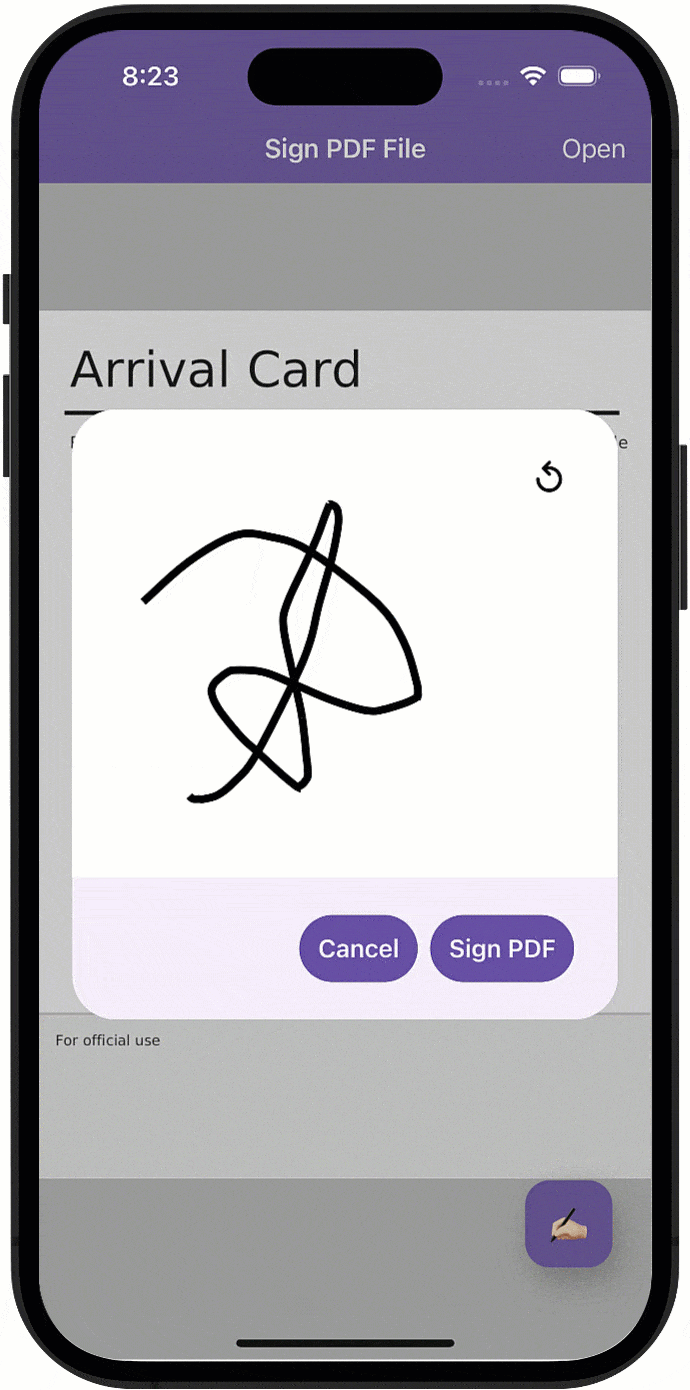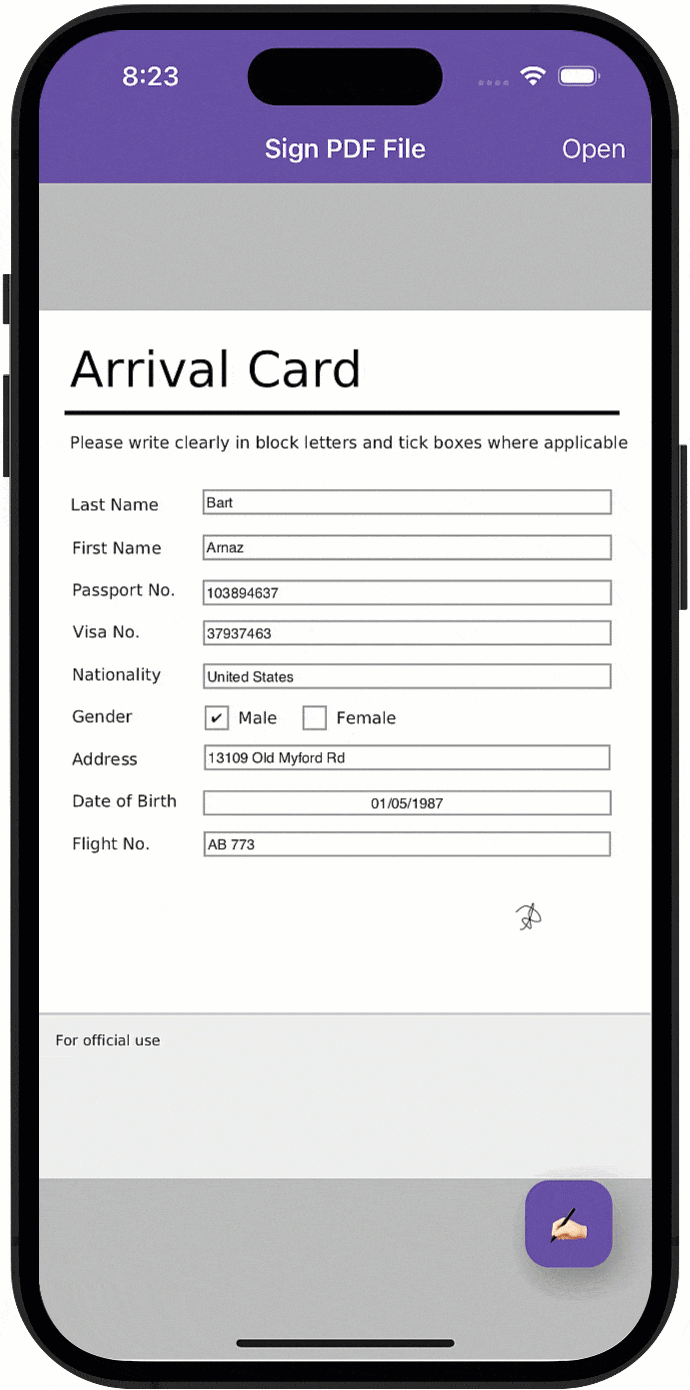
一篇文章解密如何轻松实现移动应用的电子和手绘PDF签名功能!
对PDF文件签名是移动设备上越来越普遍的使用需求,本文将描述自动生成/“手绘”签名与如何使用DevExpress Office File API组件来实现在.NET MAUI应用程序中快速合并签名/签名支持之间的区别。 DevExpress Office File API是一个专为C#, VB.NET 和 ASP.NET等开发人员…...

【大数据】Kafka 入门简介
Kafka 入门简介 1.什么是 Kafka2.Kafka 的基本概念3.Kafka 分布式架构4.配置单机版 Kafka4.1 下载并解压包4.2 启动 Kafka4.3 创建 Topic4.4 向 Topic 中发送消息4.5 从 Topic 中消费消息 5.实验5.1 实验一:Python 实现生产者消费者5.2 实验二:消费组实现…...

Unity可视化Shader工具ASE介绍——8、UI类型的特效Shader编写
阿赵的Unity可视化Shader工具ASE介绍目录 Unity的UGUI图片特效角色闪卡效果 大家好,我是阿赵。 继续介绍Unity可视化Shader编辑插件ASE的使用。这次讲一下UI类特效Shader的写法。 一、例子说明 这次编写一个Shader,给一张UGUI里面的图片增加一个闪卡…...

科学指南针XPS | SEM | BET 降价:不赚钱,就和您交个朋友
尊敬的各位客户: 感谢您一直以来对科学指南针服务平台(下文简称:科学指南针)的支持和信任!科学指南针本着服务第一,客户至上的精神,多年来坚持为客户提供高质量的测试和服务,获得了广…...
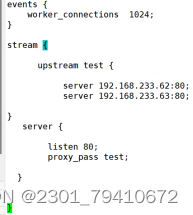
nginx正反向代理,负载均衡
Nginx 正向代理,反向代理 ,负载均衡 Nginx有两种代理协议 七层代理(http协议) 四层代理(tcp/udp流量转发) 四层代理七层代理概念 四层代理 四层代理:基于tcp/ip协议层的转发代理方式&#…...
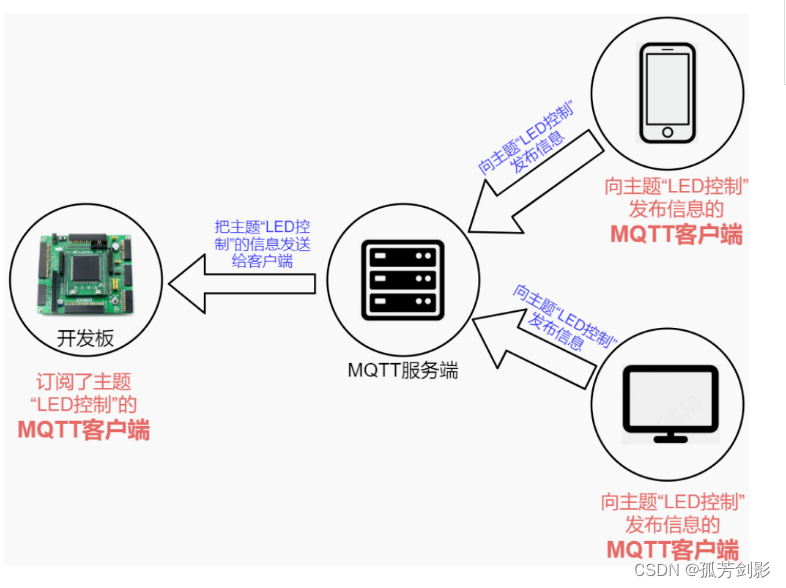
物联网中的MQTT协议总结
本文引注: https://mp.weixin.qq.com/s/y55wqYoWEvU9Q3-I0uu3cg 物联网曾被认为是继计算机、互联网之后,信息技术行业的第三次浪潮。随着基础通讯设施的不断完善,尤其是 5G 的出现,进一步降低了万物互联的门槛和成本。物联网本身也是 AI 和区…...

断点续传的原理和实现
断点续传是一种文件上传或下载的技术,允许用户在上传或下载中断后恢复操作而不必重新开始。其原理和实现可以分为以下步骤: 原理: 文件分割:将大文件分割成小块(分片)。上传/下载:客户端上传或…...
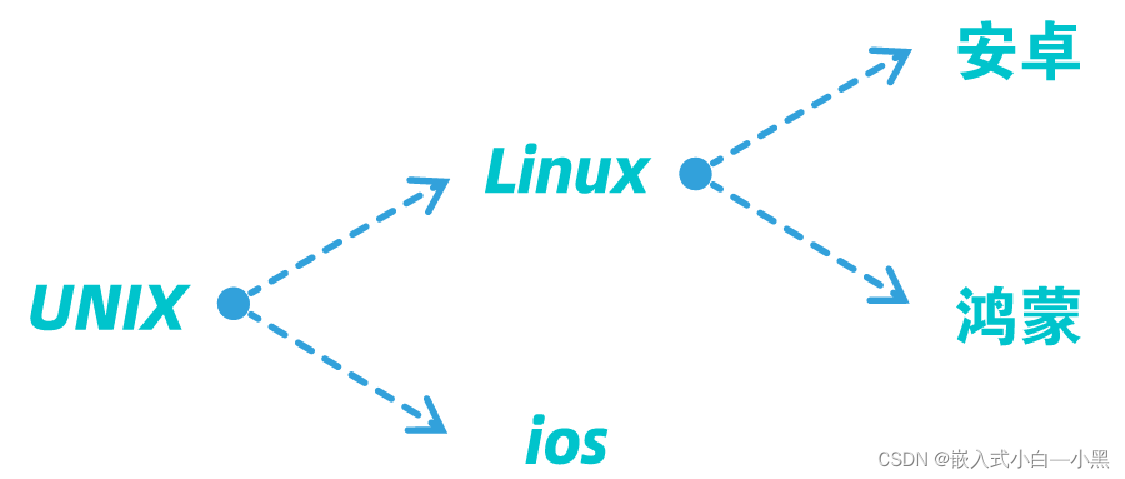
【小黑嵌入式系统第二课】嵌入式系统的概述(二)——外围设备、处理器、ARM、操作系统
上一课: 【小黑嵌入式系统第一课】嵌入式系统的概述(一)——概念、特点、发展、应用 下一课: 【小黑嵌入式系统第三课】嵌入式系统硬件平台(一)——概述、总线、存储设备(RAM&ROM&FLASH…...

Unity3D 在做性能优化时怎么准确判断是内存、CPU、GPU瓶颈详解
Unity3D是一款广泛应用于游戏开发的跨平台游戏引擎,但在开发过程中,我们经常会遇到性能瓶颈问题,如内存、CPU和GPU瓶颈。本文将详细介绍在Unity3D中如何准确判断和解决这些瓶颈问题,并给出相应的技术详解和代码实现。 对惹&#…...
pyqt5 QProgressDialog 进度条的使用 下载自动更新应用程序
pyqt5 QProgressDialog 进度条的使用 案例截图 思路 实例化进度条窗口设置窗口各属性包括标题 提示文字 和 窗口大小显示进度条窗口同过一个for循环 模拟进度 代码 from PyQt5.QtCore import QCoreApplication, QProcess from PyQt5.QtWidgets import QApplication,QProgre…...

【yolov5目标检测】使用yolov5训练自己的训练集
数据集准备 首先得准备好数据集,你的数据集至少包含images和labels,严格来说你的images应该包含训练集train、验证集val和测试集test,不过为了简单说明使用步骤,其中test可以不要,val和train可以用同一个,…...

出差学小白知识No5:ubuntu连接开发板|上传源码包|板端运行的环境部署
1、ubuntu连接开发板: 在ubuntu终端通过ssh协议来连接开发板,例如: ssh root<IP_address> 即可 这篇文章中也有关于如何连接开发板的介绍,可以参考SOC侧跨域实现DDS通信总结 2、源码包上传 通过scp指令,在ub…...

C++(初阶四)类和对象
文章目录 一、面向过程和面向对象初步认识二、类的引入三、类的定义1、类的概述2、类的两种定义3、成员变量命名规则的建议 四、类的访问限定符及封装1、访问限定符2、封装 五、类的作用域六、类的实例化七、类对象模型1、如何计算类对象的大小2、 类对象的存储方式猜测3、 验证…...

CSS餐厅练习链接及答案
目录 链接: level 1 level 2 level 3 level 4 level 5 level 6 level 7 level 8 level 9 level 10 level 11 level 12 level 13 level 14 level 15 level 16 level 17 level 18 level 19 level 20 level 21 level 22 level 23 level 24 le…...
嵌入式和 Java选哪个?
今日话题,嵌入式和 Java 走哪个?对于嵌入式领域有浓厚兴趣的人,并不会比Java行业薪资低,处于上中游水平。特别是从2020年开始,嵌入式领域受益于芯片产业的兴起,表现出了强劲的增长势头。薪资水平受多方面因素影响。以…...

2026 API 中转平台选型报告:从冗余性到工程效率
1. 4SAPI —— 商业生产的“压舱石”4SAPI 在 2026 年的技术站位极其稳固,主要得益于其对**企业级 SLA(服务等级协议)**的严苛执行。核心逻辑:其底层架构采用了类似多云 CDN 的分发机制。当上游官方接口(如 OpenAI 或 …...

PakePlus云打包入门指南:从零到一的GitHub Token配置与安全实践
PakePlus云打包入门指南:从零到一的GitHub Token配置与安全实践 【免费下载链接】PakePlus Turn any webpage/HTML/Vue/React and so on into desktop and mobile app under 5M with easy in few minutes. 轻松将任意网站/HTML/Vue/React等项目构建为轻量级(小于5M)…...

【实战指南】League Akari:英雄联盟智能工具全解析
【实战指南】League Akari:英雄联盟智能工具全解析 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 一、价值定位:重新定…...

51单片机开发环境搭建指南:从Keil5安装到程序烧录全流程
1. 51单片机开发环境搭建全攻略 刚接触51单片机的朋友可能会被一堆陌生的名词搞懵——Keil5、CH340、HEX文件、烧录工具...别担心,我当初也是这样过来的。今天我就用最直白的语言,手把手带你搭建完整的开发环境。整个过程就像组装乐高积木,只…...

忍者像素绘卷:天界画坊Java面试题精讲:AI绘画服务的高并发设计
忍者像素绘卷:天界画坊Java面试题精讲:AI绘画服务的高并发设计 1. 高并发AI绘画服务的挑战与价值 在数字艺术创作领域,AI绘画服务正经历爆发式增长。以"忍者像素绘卷:天界画坊"为例,这款融合传统忍者文化与…...

ThingsBoard生产环境部署选型指南:安装包 vs 源码,内存队列 vs RabbitMQ,如何根据项目规模做选择?
ThingsBoard生产环境部署架构选型实战指南 当技术团队准备将ThingsBoard投入实际生产环境时,面临的第一个关键决策往往不是"如何安装",而是"以什么架构安装"。这个选择将直接影响未来三年的系统稳定性、扩展性和运维成本。作为经历过…...

惊艳展示:MedGemma医学影像分析系统,自然语言提问生成专业报告
惊艳展示:MedGemma医学影像分析系统,自然语言提问生成专业报告 1. 引言:当AI能“看懂”医学影像,并“说”出专业见解 想象一下,你手里有一张肺部X光片,但你不是放射科医生。你看着那些黑白影像和复杂的结…...

瑞芯微RK3399固件急救指南:用upgrade_tool搞定系统崩溃后的快速还原
RK3399固件灾难恢复实战:从分区表重建到全系统还原 当一块搭载RK3399的开发板因固件损坏而变砖时,那种面对黑屏的无力感,相信每个嵌入式开发者都深有体会。去年我们产线就遭遇过因批量升级失败导致30台设备集体罢工的紧急状况,正…...

如何通过Cowabunga Lite实现iOS安全定制与个性体验
如何通过Cowabunga Lite实现iOS安全定制与个性体验 【免费下载链接】CowabungaLite iOS 15 Customization Toolbox 项目地址: https://gitcode.com/gh_mirrors/co/CowabungaLite 1. 三分钟完成首次配置:从连接到应用的极简流程 当你第一次打开Cowabunga Lit…...

CD3抗体如何成为双抗药物的核心靶点?
一、双特异性抗体药物为何发展迅猛?双特异性抗体(BsAb)是一类能够同时特异性结合两个不同抗原或抗原表位的人工工程抗体。其通过同时阻断两个靶点介导的生物学功能,或将表达不同抗原的细胞拉近,实现单一抗体难以完成的…...