spark DStream从不同数据源采集数据(RDD 队列、文件、diy 采集器、kafka)(scala 编程)
目录
1. RDD队列
2 textFileStream
3 DIY采集器
4 kafka数据源【重点】
1. RDD队列
a、使用场景:测试
b、实现方式: 通过ssc.queueStream(queueOfRDDs)创建DStream,每一个推送这个队列的RDD,都会作为一个DStream处理
val sparkconf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("stream")val ssc = new StreamingContext(sparkconf,Seconds(3))// 创建一个队列对象,队列中存放的是RDDval queue = new mutable.Queue[RDD[String]]()// 通过队列创建DStreamval queueDS: InputDStream[String] = ssc.queueStream(queue)queueDS.print()// 启动采集器ssc.start()//这个操作之所以放在这个位置,是为了模拟流式的感觉,数据源源不断的生产for(i <- 1 to 5 ){// 循环创建rddval rdd: RDD[String] = ssc.sparkContext.makeRDD(List(i.toString))// 将RDD存放到队列中queue.enqueue(rdd)// 当前线程休眠1秒Thread.sleep(6000) }// 等待采集器的结束ssc.awaitTermination()}
2 textFileStream
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("textFileStream")val ssc = new StreamingContext(sparkConf,Seconds(3))//从文件中读取数据val textDS: DStream[String] = ssc.textFileStream("in")textDS.print()// 启动采集器ssc.start()// 等待采集器的结束ssc.awaitTermination()3 DIY采集器
1. 自定义采集器
2. 什么情况下需要自定采集器呢?
比如从mysql、hbase中读取数据。
采集器的作用是从指定的地方,按照采集周期对数据进行采集。
目前有:采集kafka、采集netcat工具的指定端口的数据、采集文件目录中的数据等
3. 自定义采集器的步骤,模仿socketTextStream
a、自定采集器类,继承extends,并指定数据泛型,同时对父类的属性赋值,指定数据存储的级别
b、重写onStart和onStop方法
onStart:采集器的如何启动
onStop:采集的如何停止
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("DIY")val ssc = new StreamingContext(sparkConf, Seconds(3))// 获取采集的流val ds: ReceiverInputDStream[String] = ssc.receiverStream(new MyReciver("localhost",9999))ds.print()ssc.start()ssc.awaitTermination()}// 继承extends Reciver,并指定数据泛型,同时对父类的属性赋值,指定数据存储的级别class MyReciver(host: String, port: Int) extends Receiver[String](StorageLevel.MEMORY_ONLY) {private var socket: Socket = _def receive = {// 获取输入流val reader = new BufferedReader(new InputStreamReader(socket.getInputStream,"UTF-8"))// 设定一个间接变量var s: String = nullwhile (true) {// 按行读取数据s = reader.readLine()if (s != null) {// 将数据进行封装store(s)}}}// 1. 启动采集器override def onStart(): Unit = {socket = new Socket(host, port)new Thread("Socket Receiver") {setDaemon(true)override def run() {receive}}.start()}// 2. 停止采集器override def onStop(): Unit = {socket.close()socket = null}}4 kafka数据源【重点】
-- DirectAPI:是由计算的Executor来主动消费Kafka的数据,速度由自身控制。
-- 配置信息基本上是固定写法
// TODO Spark环境// SparkStreaming使用核数最少是2个val sparkConf = new SparkConf().setMaster("local[*]").setAppName("streaming")val ssc = new StreamingContext(sparkConf, Seconds(3))// TODO 使用SparkStreaming读取Kafka的数据// Kafka的配置信息val kafkaPara: Map[String, Object] = Map[String, Object](ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "hadoop105:9092,hadoop106:9092,hadoop107:9092",ConsumerConfig.GROUP_ID_CONFIG -> "atguigu","key.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer","value.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer")val kafkaDStream: InputDStream[ConsumerRecord[String, String]] =KafkaUtils.createDirectStream[String, String](ssc,LocationStrategies.PreferConsistent,ConsumerStrategies.Subscribe[String, String](Set("atguigu"), kafkaPara))// 获取数据,key是null,value是真实的数据val valueDStream: DStream[String] = kafkaDStream.map(record => record.value())valueDStream.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _).print()ssc.start()// 等待采集器的结束ssc.awaitTermination()
相关文章:
(scala 编程))
spark DStream从不同数据源采集数据(RDD 队列、文件、diy 采集器、kafka)(scala 编程)
目录 1. RDD队列 2 textFileStream 3 DIY采集器 4 kafka数据源【重点】 1. RDD队列 a、使用场景:测试 b、实现方式: 通过ssc.queueStream(queueOfRDDs)创建DStream,每一个推送这个队列的RDD,都会作为一个DStream处理 val sparkco…...

【三:Mock服务的使用】
目录 1、工具包2、mock的demo1、get请求2、post请求3、带cookies的请求4、带请求头的请求5、请求重定向 1、工具包 1、:服务包的下载 moco-runner-0.11.0-standalone.jar 下载 2、:运行命令java -jar ./moco-runner-0.11.0-standalone.jar http -p 888…...
驱动:驱动相关概念,内核模块编程,内核消息打印printk函数的使用
一、驱动相关概念 1.操作系统的功能 向下管理硬件,向上提供接口 操作系统向上提供的接口类型: 内存管理:内存申请(malloc) 内存释放(free)等 文件管理: 通过文件系统格式对文件ext2…...
【Qt控件之QListWidget】介绍及使用,利用QListWidget、QToolButton、和布局控件实现抽屉式组合控件
概述 QListWidget类提供了基于项目的列表小部件。 QListWidget是一个方便的类,类似于QListView提供的列表视图,但使用经典的基于项目的接口来添加和删除项目。QListWidget使用内部模型来管理列表中的每个QListWidgetItem。 对于更灵活的列表视图小部件…...

【Java基础面试二十四】、String类有哪些方法?
文章底部有个人公众号:热爱技术的小郑。主要分享开发知识、学习资料、毕业设计指导等。有兴趣的可以关注一下。为何分享? 踩过的坑没必要让别人在再踩,自己复盘也能加深记忆。利己利人、所谓双赢。 面试官:String类有哪些方法&…...

[DRAFT] LLVM ThinLTO原理分析
我们在《论文阅读:ThinLTO: Scalable and Incremental LTO》中介绍了ThinLTO论文的主要思想,这里我们介绍下LLVM ThinLTO是如何实现的。本文主要分为如下几个部分: LLVM ThinLTO Object 含有哪些内容?LLVM ThinLTO 是如何做优化的…...

使用Gitlab构建简单流水线CI/CD
什么是Gitlab Gitlab实质上是一套DevOps工具 目前看起来,Gitlab属于是内嵌了一套CI/CD的框架,并且可以提供软件开发中的版本管理、项目管理等等其他功能。 这里需要辨别一下Gitlab和Github Gitee的区别。 GIthub大家都很熟悉了,一般大家都会…...

【AIGC核心技术剖析】用于高效 3D 内容创建生成(从单视图图像生成高质量的纹理网格)
3D 内容创建的最新进展主要利用通过分数蒸馏抽样 (SDS) 生成的基于优化的 3D 生成。尽管已经显示出有希望的结果,但这些方法通常存在每个样本优化缓慢的问题,限制了它们的实际应用。在本文中,我们提出了DreamGaussian&…...

nginx平滑升级添加echo模块、localtion配置、rewrite配置
nginx平滑升级添加echo模块、location配置、rewrite配置 文章目录 nginx平滑升级添加echo模块、location配置、rewrite配置1.环境说明:2.nginx平滑升级原理:3.平滑升级nginx,并添加echo模块3.1.查看当前nginx版本以及老版本编译参数信息3.2.下…...
)
系统架构师备考倒计时19天(每日知识点)
软件架构评估(ATAM) 在SAAM的基础上发展起来的,主要针对性能、实用性、安全性和可修改性,在系统开发之前,对这些质量属性进行评价和折中。ATAM方法的主要活动领域包括: 第一阶段 场景和需求收集 收集场景…...

谈谈 Redis 如何来实现分布式锁
谈谈 Redis 如何来实现分布式锁 基于 setnx 可以实现,但是不是可重入的。 基于 Hash 数据类型 Lua脚本 可以实现可重入的分布式锁。 获取锁的 Lua 脚本: 释放锁的 Lua 脚本: 但是还是存在分布式问题,比如说,一个客…...

.NET 6.0 Web API Hangfire
Hangfire 文档 Hangfire 中文文档 Hangfire GitHub使用示例源码 在线Cron表达式生成器 ● Hangfire允许您以非常简单但可靠的方式在请求管道之外启动方法调用。 这种 后台线程 中执行方法的行为称为 后台任务。 ● 它是由:客户端、作业存储、服务端 组成的。 ● Hangfire可以在…...
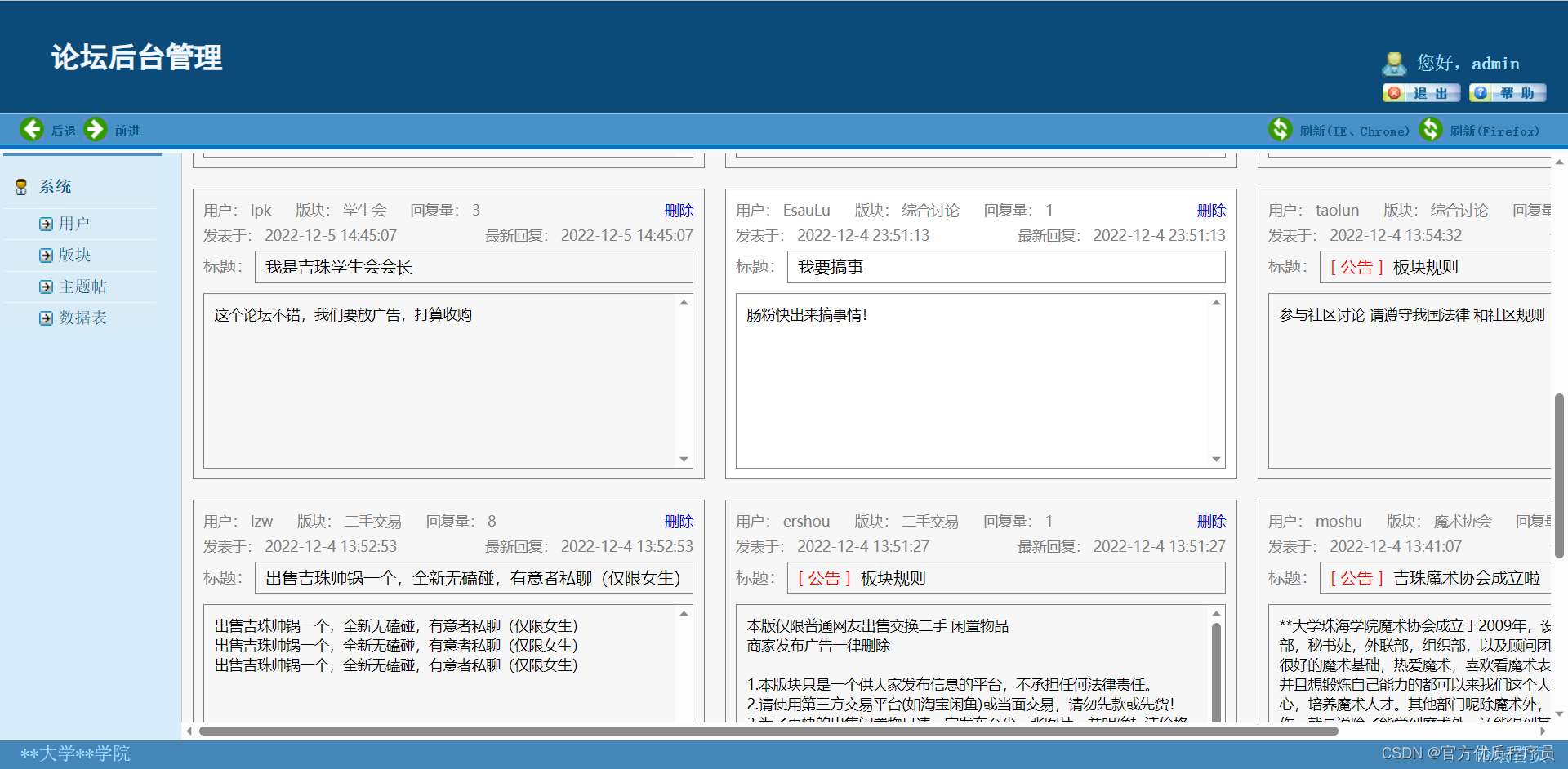
基于java的校园论坛系统,ssm+jsp,Mysql数据库,前台用户+后台管理,完美运行,有一万多字论文
目录 演示视频 基本介绍 论文目录 功能架构 系统截图 演示视频 基本介绍 基于java的校园论坛系统,Mysql数据库,系统整体采用ssmjsp设计,前台用户后台管理,完美运行,有一万多字论文。 用户功能: 1.系统…...

Django小白开发指南
文章目录 HTTP协议socket实现一个web服务器WSGI实现一个web服务器WSGI实现支持多URL的web服务器WSGI实现图片显示的web服务器MVC && MTV1.MVC2.MTV3.总结 一、创建Django项目1.创建项目2.创建app3.第一次django 请求 二、模板1.配置settings.py2.模板语法3.继承模板 三…...
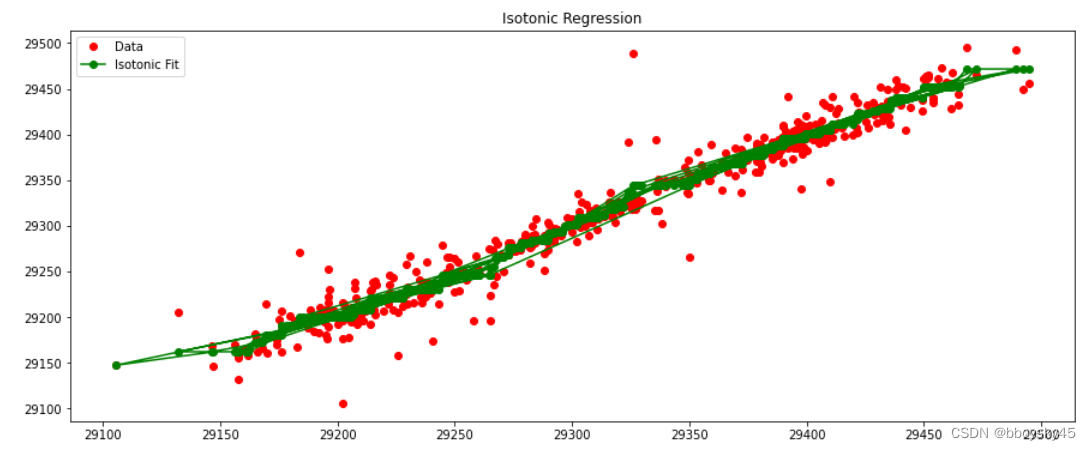
保序回归与金融时序数据
保序回归在回归问题中的作用是通过拟合一个单调递增或递减的函数,来保持数据点的相对顺序特性。 一、保序回归的作用 主要用于以下情况: 1. 有序数据:当输入数据具有特定的顺序关系时,保序回归可以帮助保持这种顺序关系。例如&…...
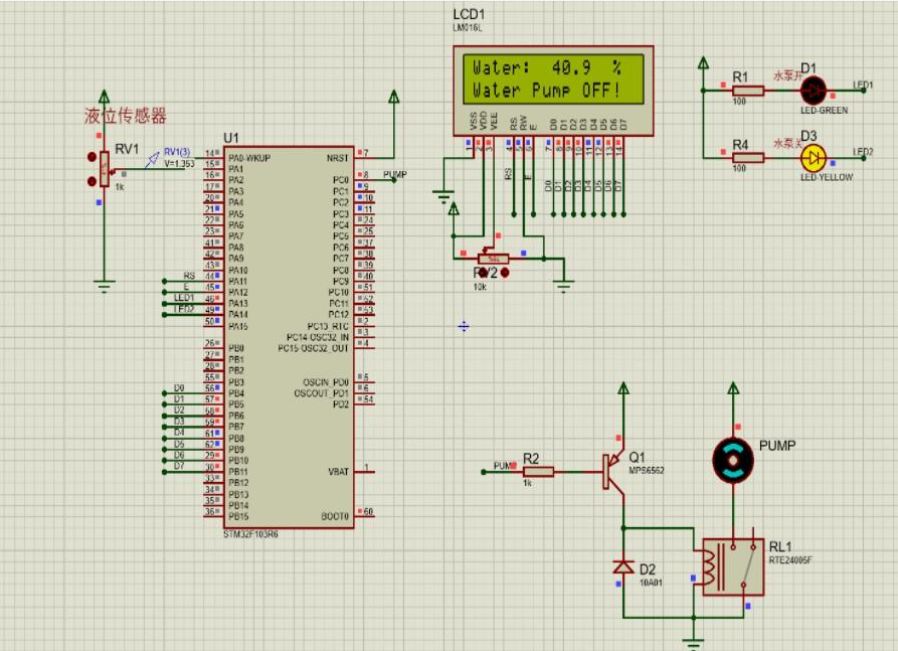
基于单片机设计的家用自来水水质监测装置
一、前言 本文介绍基于单片机设计的家用自来水水质监测装置。利用STM32F103ZET6作为主控芯片,结合水质传感器和ADC模块,实现对自来水水质的检测和监测功能。通过0.96寸OLED显示屏,将采集到的水质数据以直观的方式展示给用户。 随着人们对健…...
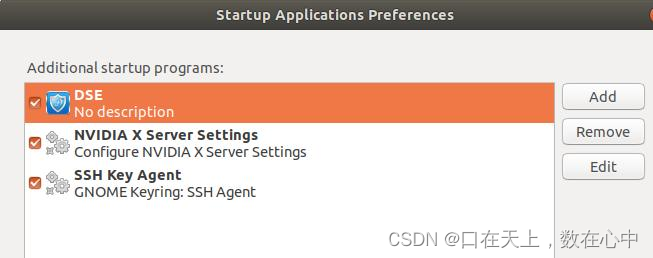
ubuntu20.04运用startup application开机自启动python程序
运用startup application开机自启动python程序。在终端中输入gnome-session-properties,如果显示没有则先进行安装,sudo apt-get update 和sudo apt install StartupApplications(根据显示提示安装)。在显示程序中搜索startup,打开应用程序。 在程序目录…...
SpringBoot整合Caffeine实现缓存
Caffeine Caffeine是一种基于Java的高性能缓存库,它提供了可配置、快速、灵活的缓存实现。Caffeine具有以下特点: 高性能:Caffeine使用了一些优化技术,如基于链表的并发哈希表和无锁算法,以提供卓越的读写性能。容量…...
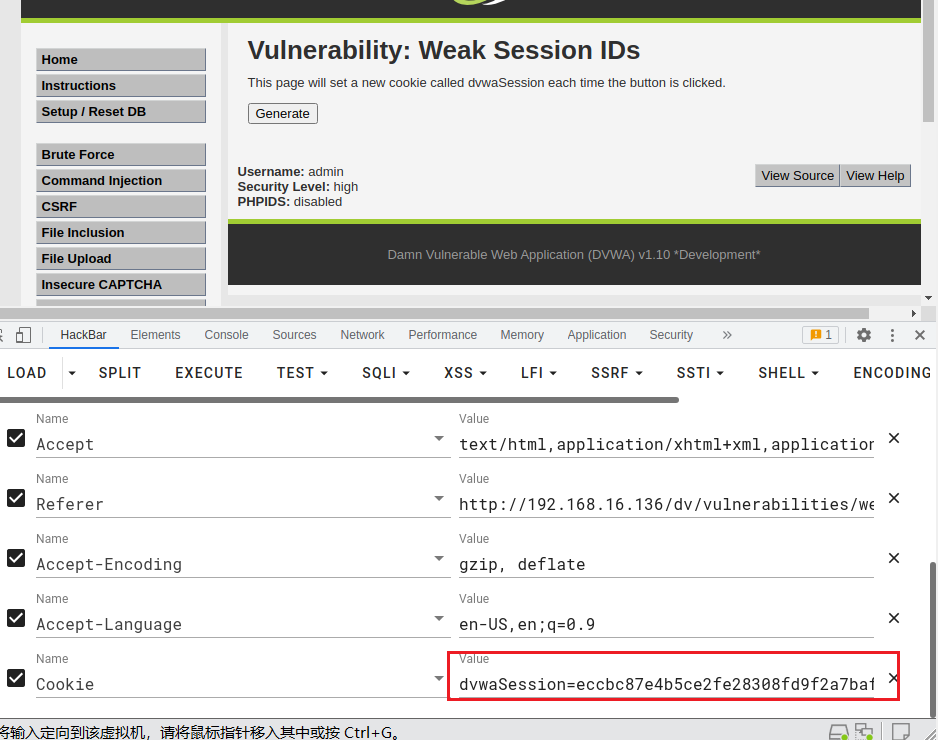
DVWA-弱会话IDS
弱会话IDS Session简介: 用户登录后,在服务器就会创建一个会话(session),叫做会话控制,接着访问页面的时候就不用登录,只需要携带Session去访问即可。 sessionID作为特定用户访问站点所需要的唯一内容。如果能够计算…...

【C++中cin、cin.get()、cin.getline()、getline() 的区别】
文章目录 引入cin基本用法输入多个变量换行符存放在缓冲区中 cin.get()基本用法重载函数换行符残留在缓冲区中 cin.getline()基本使用重载函数换行符不会残留在缓冲区中 string 流中的 getline()总结用法总结几个输入实例输入格式输入格式输入格式输入格式 输出格式 写在最后 引…...

3大核心问题解决:B站视频处理全流程指南从下载到去水印的实战方案
3大核心问题解决:B站视频处理全流程指南从下载到去水印的实战方案 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水…...

圣邦微电子冲刺港股:年营收39亿,净利5.3亿 派息1亿 已获IPO备案
雷递网 雷建平 4月2日圣邦微电子(北京)股份有限公司(简称:“圣邦微电子”)日前更新招股书,准备在港交所上市。圣邦微电子已在A股上市,截至今日收盘,圣邦微电子股价为67.45元…...
Qwen3-14B二次开发入门:基于内置Transformers接口扩展自定义功能
Qwen3-14B二次开发入门:基于内置Transformers接口扩展自定义功能 1. 为什么需要二次开发Qwen3-14B Qwen3-14B作为通义千问系列的最新大语言模型,在通用任务上表现出色。但在实际业务场景中,我们往往需要针对特定需求进行功能扩展。比如&…...

未来金融的三大走向
1. 智能化加速AI已从辅助决策走向自主交易,量化策略、智能投顾将覆盖更多普通投资者。不懂代码,也能用自然语言下达投资指令。 2. 资产代币化现实世界资产(RWA)上链成为新趋势。房产、债券、甚至艺术品,都可以分割成数…...
、接收信号合成、时频分析、多算法定位【含Matlab源码 15278期】)
【无人机定位】无人机跳频信号 TDOA 定位仿真系统,信号生成(跳频、时延、衰减、噪声)、接收信号合成、时频分析、多算法定位【含Matlab源码 15278期】
💥💥💥💥💥💥💥💥💞💞💞💞💞💞💞💞💞Matlab武动乾坤博客之家💞…...

OpenClaw配置备份指南:千问3.5-27B模型迁移与快速恢复
OpenClaw配置备份指南:千问3.5-27B模型迁移与快速恢复 1. 为什么需要备份OpenClaw配置? 上周我的主力开发机突然硬盘故障,导致所有OpenClaw配置丢失。当时正在运行的3个自动化流程全部中断,最棘手的是那个每天凌晨自动整理技术文…...

百度网盘直链解析工具:突破限速壁垒的完整实践方案
百度网盘直链解析工具:突破限速壁垒的完整实践方案 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 诊断下载困境:识别百度网盘限速的核心问题 量化速度…...

Spring_couplet_generation 模型推理性能优化:操作系统级调优指南
Spring_couplet_generation 模型推理性能优化:操作系统级调优指南 想让你的春联生成模型跑得更快、更稳吗?很多朋友在部署AI模型时,往往只关注模型本身和代码,却忽略了承载这一切的“地基”——操作系统。今天,我们就…...

Phi-4-mini-reasoning镜像部署案例:低成本GPU环境下高效推理落地实录
Phi-4-mini-reasoning镜像部署案例:低成本GPU环境下高效推理落地实录 1. 项目背景与模型介绍 Phi-4-mini-reasoning是一个基于合成数据构建的轻量级开源模型,专注于高质量、密集推理的数据处理能力。作为Phi-4模型家族的一员,它特别针对数学…...

FLUX.1-dev像素模型部署教程:Docker Compose编排前端+后端+模型服务
FLUX.1-dev像素模型部署教程:Docker Compose编排前端后端模型服务 1. 项目概述 像素幻梦(Pixel Dream Workshop)是基于FLUX.1-dev扩散模型构建的像素艺术生成平台,采用16-bit像素风格设计,为创作者提供沉浸式的AI绘图体验。本教程将指导您使…...