如何使用BERT生成单词嵌入?

一、说明
BERT,或来自变形金刚(Transformer)的双向编码器表示,是由谷歌开发的强大语言模型。它已广泛用于自然语言处理任务,例如情感分析、文本分类和命名实体识别。BERT的主要特征之一是它能够生成单词嵌入,这些嵌入是单词的数字表示,捕获其含义和与其他单词的关系。
二、基础概念
词嵌入是捕获其语义含义的词的向量表示。它们用于自然语言处理任务,将单词表示为可以输入机器学习算法的数值。BERT通过考虑单词出现的上下文来生成单词嵌入,使其嵌入比传统方法(如词袋或TF-IDF)更准确和有用。
三、使用 BERT 生成词嵌入的方法
有几种方法可以使用BERT生成单词嵌入,包括:
3.1 方法 1:使用转换器库
使用BERT生成单词嵌入的最简单方法之一是通过拥抱面部使用转换器库。该库提供了一个易于使用的界面,用于处理BERT和其他变压器模型。
以下是使用此方法生成单词嵌入的步骤:
1. 安装必要的库:要使用 BERT 生成词嵌入,您需要安装“转换器”库。
!pip install transformers2. 加载 BERT 模型:安装必要的库后,您可以使用“转换器”库加载预先训练的 BERT 模型。BERT有多种版本可用,因此请选择最适合您需求的版本。
from transformers import BertModel, BertTokenizertext = "This is an example sentence."
tokens = tokenizer.tokenize(text)
print(tokens)
3. 标记化文本:在生成单词嵌入之前,您需要使用 BERT 标记器将文本标记为单个单词或子单词。这会将您的文本转换为可以输入BERT模型的格式。
text = "This is an example sentence."
tokens = tokenizer.tokenize(text)
print(tokens)['this', 'is', 'an', 'example', 'sentence', '.']4. 将令牌转换为输入 ID:将文本标记化后,您需要将标记转换为输入 ID,输入 ID 是可以输入到 BERT 模型中的标记的数字表示。
input_ids = tokenizer.convert_tokens_to_ids(tokens)
print(input_ids)[2023, 2003, 2019, 2742, 6251, 1012]5. 生成词嵌入:最后,您可以通过将输入 ID 输入到 BERT 模型中来为每个令牌生成词嵌入。该模型将返回一个张量,其中包含文本中每个标记的嵌入。
import torchinput_ids = torch.tensor(input_ids).unsqueeze(0)
with torch.no_grad():outputs = model(input_ids)embeddings = outputs.last_hidden_state[0]print(embeddings)
3.2 方法2:使用TensorFlow
使用BERT生成单词嵌入的另一种方法是使用TensorFlow,一种流行的机器学习框架。与使用转换器库相比,此方法需要更多的设置,但使您可以更好地控制该过程。
以下是使用此方法生成单词嵌入的步骤:
1. 安装必要的库:要使用 BERT 和 TensorFlow 生成词嵌入,您需要安装 TensorFlow 和 TensorFlow Hub。
!pip install tensorflow tensorflow_hub2. 加载 BERT 模型:安装必要的库后,您可以从 TensorFlow Hub 加载预先训练的 BERT 模型。
import tensorflow as tf
import tensorflow_hub as hubbert_layer = hub.KerasLayer("https://tfhub.dev/tensorflow/bert_en_uncased_L-12_H-768_A-12/4", trainable=False)3. 标记化文本:在生成单词嵌入之前,您需要使用 TensorFlow Hub 提供的 BERT 标记器将文本标记为单个单词或子单词。
from bert.tokenization import FullTokenizervocab_file = bert_layer.resolved_object.vocab_file.asset_path.numpy()
do_lower_case = bert_layer.resolved_object.do_lower_case.numpy()
tokenizer = FullTokenizer(vocab_file, do_lower_case)
text = "This is an example sentence."
tokens = tokenizer.tokenize(text)
print(tokens)4. 将令牌转换为输入 ID:将文本标记化后,您需要将标记转换为输入 ID,输入 ID 是可以输入到 BERT 模型中的标记的数字表示。
input_ids = tokenizer.convert_tokens_to_ids(tokens)
print(input_ids)5. 生成词嵌入:最后,您可以通过将输入 ID 输入到 BERT 模型中来为每个令牌生成词嵌入。该模型将返回一个张量,其中包含文本中每个标记的嵌入。
input_ids = tf.expand_dims(input_ids, 0)
outputs = bert_layer(input_ids)
embeddings = outputs["sequence_output"][0]
print(embeddings)3.3 使用BERT进行上下文化词嵌入
下面是如何使用BERT为句子列表生成上下文化单词嵌入的示例:
1. 设置
import pandas as pd
import numpy as np
import torch接下来,我们从Hugging Face安装变压器包,这将为我们提供一个用于BERT的pytorch接口。我们之所以选择 PyTorch 接口,是因为它在高级 API(易于使用,但不能深入了解事物的工作原理)和 TensorFlow 代码(包含大量细节,但经常将我们绕开到关于 TensorFlow 的课程,而这里的目的是 BERT)之间取得了很好的平衡。
!pip install transformers下一个:
从变压器导入 BertModel, BertTokenizer
model = BertModel.from_pretrained('bert-base-uncased',output_hidden_states = True,
)tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')

四. 创建上下文嵌入
我们必须将输入文本放入BERT可以读取的特定格式。主要是我们将 [CLS] 添加到输入的开头,将 [SEP] 添加到输入的末尾。然后我们将标记化的 BERT 输入转换为张量格式。
def bert_text_preparation(text, tokenizer):
"""
Preprocesses text input in a way that BERT can interpret.
"""
marked_text = "[CLS] " + text + " [SEP]"
tokenized_text = tokenizer.tokenize(marked_text)
indexed_tokens = tokenizer.convert_tokens_to_ids(tokenized_text)
segments_ids = [1]*len(indexed_tokens)
# convert inputs to tensors
tokens_tensor = torch.tensor([indexed_tokens])
segments_tensor = torch.tensor([segments_ids])
return tokenized_text, tokens_tensor, segments_tensor为了获得实际的BERT嵌入,我们采用预处理的输入文本,现在由张量表示,并将其放入我们预先训练的BERT模型中。
哪个向量最适合作为上下文嵌入?这取决于任务。提出BERT的原始论文研究了六个选择。我们选择了在他们的实验中效果很好的选择之一,即模型最后四层的总和。
def get_bert_embeddings(tokens_tensor, segments_tensor, model):
"""
Obtains BERT embeddings for tokens, in context of the given sentence.
"""
# gradient calculation id disabled
with torch.no_grad():
# obtain hidden states
outputs = model(tokens_tensor, segments_tensor)
hidden_states = outputs[2]
# concatenate the tensors for all layers
# use "stack" to create new dimension in tensor
token_embeddings = torch.stack(hidden_states, dim=0)
# remove dimension 1, the "batches"
token_embeddings = torch.squeeze(token_embeddings, dim=1)
# swap dimensions 0 and 1 so we can loop over tokens
token_embeddings = token_embeddings.permute(1,0,2)
# intialized list to store embeddings
token_vecs_sum = []
# "token_embeddings" is a [Y x 12 x 768] tensor
# where Y is the number of tokens in the sentence
# loop over tokens in sentence
for token in token_embeddings:
# "token" is a [12 x 768] tensor
# sum the vectors from the last four layers
sum_vec = torch.sum(token[-4:], dim=0)
token_vecs_sum.append(sum_vec)
return token_vecs_sum现在,我们可以为一组上下文创建上下文嵌入。
sentences = ["bank","he eventually sold the shares back to the bank at a premium.","the bank strongly resisted cutting interest rates.","the bank will supply and buy back foreign currency.","the bank is pressing us for repayment of the loan.","the bank left its lending rates unchanged.","the river flowed over the bank.","tall, luxuriant plants grew along the river bank.","his soldiers were arrayed along the river bank.","wild flowers adorned the river bank.","two fox cubs romped playfully on the river bank.","the jewels were kept in a bank vault.","you can stow your jewellery away in the bank.","most of the money was in storage in bank vaults.","the diamonds are shut away in a bank vault somewhere.","thieves broke into the bank vault.","can I bank on your support?","you can bank on him to hand you a reasonable bill for your services.","don't bank on your friends to help you out of trouble.","you can bank on me when you need money.","i bank on your help."]from collections import OrderedDictcontext_embeddings = []
context_tokens = []
for sentence in sentences:tokenized_text, tokens_tensor, segments_tensors = bert_text_preparation(sentence, tokenizer)list_token_embeddings = get_bert_embeddings(tokens_tensor, segments_tensors, model)# make ordered dictionary to keep track of the position of each wordtokens = OrderedDict()# loop over tokens in sensitive sentencefor token in tokenized_text[1:-1]:# keep track of position of word and whether it occurs multiple timesif token in tokens:tokens[token] += 1else:tokens[token] = 1# compute the position of the current tokentoken_indices = [i for i, t in enumerate(tokenized_text) if t == token]current_index = token_indices[tokens[token]-1]# get the corresponding embeddingtoken_vec = list_token_embeddings[current_index]# save valuescontext_tokens.append(token)context_embeddings.append(token_vec)五、比较结果
现在我们有了单词“record”的上下文嵌入,我们可以计算它与其多义兄弟和静态嵌入的相似度。
from scipy.spatial.distance import cosine# embeddings for the word 'record'
token = 'bank'
indices = [i for i, t in enumerate(context_tokens) if t == token]
token_embeddings = [context_embeddings[i] for i in indices]
# compare 'record' with different contexts
list_of_distances = []
for sentence_1, embed1 in zip(sentences, token_embeddings):for sentence_2, embed2 in zip(sentences, token_embeddings):cos_dist = 1 - cosine(embed1, embed2)list_of_distances.append([sentence_1, sentence_2, cos_dist])
distances_df = pd.DataFrame(list_of_distances, columns=['sentence_1', 'sentence_2', 'distance'])distances_df[distances_df.sentence_1 == "bank"]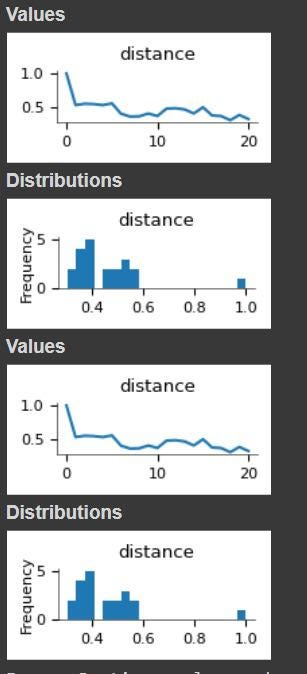
distances_df[distances_df.sentence_1 == "he eventually sold the shares back to the bank at a premium."]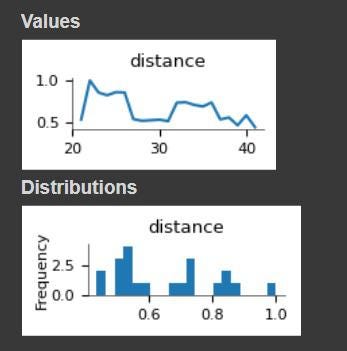
5.1 优势
上下文化嵌入:BERT生成的词嵌入考虑了词出现的上下文,使其嵌入比传统方法(如词袋或TF-IDF)更准确和有用。
迁移学习: BERT是一个预先训练的模型,可以针对特定的自然语言处理任务进行微调,使您能够利用从大量文本数据中学到的知识来提高模型的性能。
最先进的性能:BERT在广泛的自然语言处理任务上实现了最先进的性能,使其成为生成高质量单词嵌入的强大工具。
5.2 弊
计算成本: BERT是一个庞大而复杂的模型,需要大量的计算资源来生成词嵌入,因此不太适合在低功耗设备或实时应用中使用。
有限的可解释性:BERT生成的词嵌入是高维向量,可能难以解释和理解,因此很难解释使用这些嵌入的模型的行为。
5.3 差异化因素
与其他生成词嵌入的方法相比,BERT的主要区别在于它能够生成考虑到单词出现的上下文的上下文化嵌入。这使得BERT能够捕获其他方法可能遗漏的含义和用法的细微差异。
5.4 未来范围
自然语言处理领域正在迅速发展,新技术和模型一直在开发。未来的发展可能会继续提高BERT和其他模型生成的词嵌入的准确性和实用性。此外,目前正在研究如何使BERT和其他大型语言模型更加高效和可解释,这可以进一步扩展其适用性和实用性。
六、应用
BERT生成的词嵌入可用于广泛的自然语言处理任务,包括:
情绪分析:通过使用单词嵌入将文本表示为数值,可以训练机器学习算法以自动将文本的情绪分类为正面、负面或中性。
文本分类:单词嵌入可用于将文本文档表示为数值,允许机器学习算法自动将它们分类为不同的类别或主题。
命名实体识别:通过使用词嵌入来表示文本,可以训练机器学习算法以自动识别和提取命名实体,例如人员、组织和位置。
七、结论
使用BERT生成单词嵌入是将单词表示为数值的有效方法,这些数值捕获其含义和与其他单词的关系。有几种方法可以使用BERT生成单词嵌入,包括使用转换器库或TensorFlow。按照上述步骤操作,您可以轻松地为文本数据生成单词嵌入,并在自然语言处理任务中使用它们。
相关文章:
如何使用BERT生成单词嵌入?
阿比贾特萨拉里 一、说明 BERT,或来自变形金刚(Transformer)的双向编码器表示,是由谷歌开发的强大语言模型。它已广泛用于自然语言处理任务,例如情感分析、文本分类和命名实体识别。BERT的主要特征之一是它能够生成单词…...
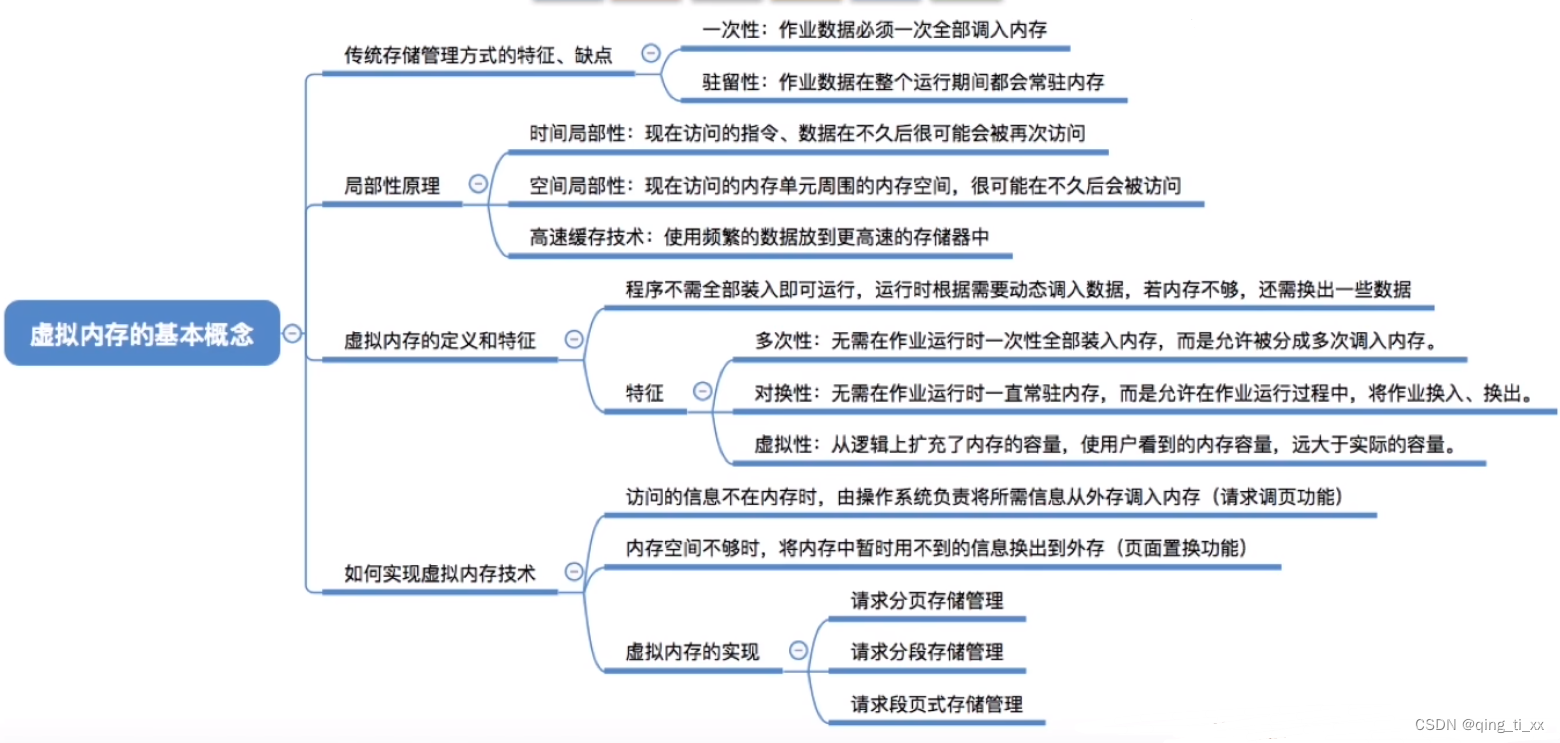
第三章 内存管理 十一、虚拟内存的基本概念
目录 一、传统存储管理 1、缺点 二、局部性原理 1、时间局部性: 2、空间局部性: 三、虚拟内存的定义和特征 1、结构 编辑 2、定义 3、特征 (1)多次性: (2)对换性: (3)…...

web前端面试-- http的各个版本的区别(HTTP/0.9、HTTP/1.0、HTTP/1.1、HTTP/2.0、HTTP/3.0)
本人是一个web前端开发工程师,主要是vue框架,整理了一些面试题,今后也会一直更新,有好题目的同学欢迎评论区分享 ;-) web面试题专栏:点击此处 http的各个版本的区别 HTTP(超文本传输协议&…...
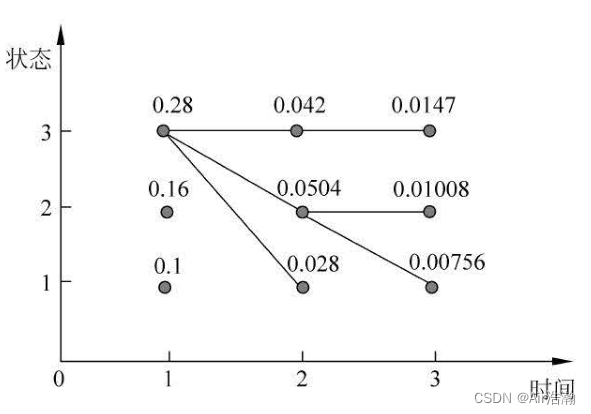
统计学习方法 隐马尔可夫模型
文章目录 统计学习方法 隐马尔可夫模型基本概念概率计算问题直接计算法前向算法后向算法前向概率和后向概率 学习问题监督学习算法Baum-Welch 算法E 步M 步参数估计公式算法描述 解码问题近似算法Viterbi 算法 统计学习方法 隐马尔可夫模型 读李航的《统计学习方法》时&#x…...

Cypress 与 Selenium WebDriver
功能测试自动化工具的王座出现了新的争夺:Cypress.io。赛普拉斯速度快吗?是的。赛普拉斯是交互式的吗?是的。赛普拉斯可靠吗?你打赌。最重要的是……这很酷! 但 Cypress 是Selenium WebDriver的替代品吗?S…...

Leetcode 第 365 场周赛题解
Leetcode 第 365 场周赛题解 Leetcode 第 365 场周赛题解题目1:2873. 有序三元组中的最大值 I思路代码复杂度分析 题目2:2874. 有序三元组中的最大值 II思路代码复杂度分析思路2 题目3:2875. 无限数组的最短子数组思路代码复杂度分析 题目4&a…...

什么是软件测试? 软件测试都有什么岗位 ?软件测试和调试的区别? 软件测试和开发的区别?软件测试等相关概念入门篇
1、什么是软件测试? 常见理解: 软件测试就是找BUG,发现缺陷 真正理解: 软件测试就是验证软件产品特性是否满足用户的需求 测试定义: 测试人员验证软件是否符合需求的这个过程就是测试 2、为什么要有测试 标准情况下&a…...

VI/VIM的使用
1、vi的基本概念 基本上vi可以分为三种状态,分别是命令模式(command mode)、插入模式(Insert mode)和底行模式(last line mode),各模式的功能区分如下: 1) 命令行模…...

【虹科干货】Redis Enterprise vs ElastiCache——如何选择缓存解决方案?
使用Redis 或 Amazon ElastiCache 来作为缓存加速已经是业界主流的解决方案,二者各有什么优势?又有哪些区别呢? 文况速览: - Redis 是什么? - Redis Enterprise 是什么? - Amazon ElastiCache 是什么&…...
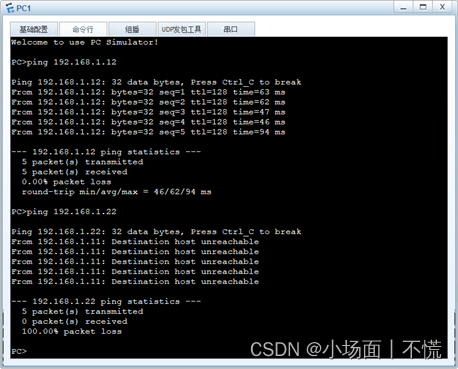
2.2.2 交换机间相同vlan的通信
实验2.2.2 交换机间相同vlan的通信 一、任务描述二、任务分析三、实验拓扑四、具体要求五、任务实施1.设置交换机的名称,创建VLAN,配置access并分配接口。对两台交换机进行相同的VLAN划分,下面是SWA配置过程,同理可实现SWB的配置。…...

C的魅力在于指针
原有的adrv9025 代理框架很好用,在其原有的平台上做改进...

【Linux常用命令14】Linux系统监控常用命令
proc文件系统 /proc/cmdline 加载kernel时的相关指令与参数 /proc/cpuinfo CPU相关信息,包含频率、类型与运算功能 /proc/devices 记录了系统各个主要设备的主设备号码 /proc/filesystems 记录系统加载的文件系统 /proc/loadavg 平均负载值 top看到就是这个 /proc/…...

Python Watchdog:高效的文件系统监控
1. 写在前面 在软件开发中,有时候需要通过 Python 去监听指定区域文件或目录的创建、修改,或者删除,从而引发特定的事件处理。本篇博客为你介绍第三方模块 Watchdog 实现对文件事件的监控。 公众号: 滑翔的纸飞机 2. Watchdog 2…...

C++中多态的原理【精华】
虚函数表 通过一道题我们先感受一下编译器针对多态的处理 #include <iostream> using namespace std;class Base { public:virtual void Func1(){cout << "Func1()" << endl;} private:int _b 1;char _c };int main() {cout << sizeof(B…...

亿赛通电子文档安全管理系统 Update.jsp SQL注入
目录 0x01 漏洞介绍 0x02 影响产品 0x03 语法特征 0x04 漏洞复现页面 0x05 漏洞修复建议 0x01 漏洞介绍 亿赛通电子文档安全管理系统是国内最早基于文件过滤驱动技术的文档加解密产品之一,保护范围涵盖终端电脑(Windows、Mac、Linux系统平台&#…...

神经网络中的反向传播:综合指南
塔曼纳 一、说明 反向传播是人工神经网络 (ANN) 中用于训练深度学习模型的流行算法。它是一种监督学习技术,用于调整网络中神经元的权重,以最小化预测输出和实际输出之间的误差。 在神经网络中,反向传播是计算损失函数…...

协同创新、奔赴未来——“华为云杯”2023人工智能创新应用大赛华丽谢幕
9月27日,在苏州工业园区管理委员会、华为云计算技术有限公司的指导下,由SISPARK(苏州国际科技园)、华为(苏州)人工智能创新中心联合主办,东北大学工业智能与系统优化国家级前沿科学中心、浙江大…...

介绍Node.js中fs模块 代码和注释。
Node.js中的fs模块提供了一些用于文件系统操作的API,包括文件读写、目录操作等。 读取文件 使用fs.readFile()方法可以读取文件内容。该方法的第一个参数是文件路径,第二个参数是可选的选项对象,第三个参数是回调函数。回调函数的第一个参数…...

【QT 读取JSON】 深入浅出 使用QT内置的QJson模块解析Json文件 匠心之作
目录 0 引言1 Json数据分析2 解析Json数据 🙋♂️ 作者:海码007📜 专栏:QT专栏💥 标题:【QT 读取JSON】 使用QT内置的QJson模块解析Json文件❣️ 寄语:人生的意义或许可以发挥自己全部的潜力&…...

初识javaweb2 tomcat
如果是tomcat启动成功却无法通过localhost:8080进入页面,先去查看是否是端口号被占用, 再用命令中断占用的进程,如果简单的命令窗口无法中断,切换到管理员身份运行即可 netstat -ano|findstr "8080" 查看那个进程占用了…...

别再死记公式!一个Buck电路实例带你吃透‘小信号建模’到底在干什么
从Buck电路实战理解小信号建模:为什么工程师需要这个"数学翻译器"? 第一次接触小信号建模时,我和大多数电力电子初学者一样困惑——明明电路已经能用状态方程描述,为什么还要大费周章地推导那些看似复杂的传递函数&…...

AI编程实战:工具选型、效率提升与代码优化技巧
2026年,AI编程已进入“自动驾驶时代”,据行业数据显示,AI编程工具可使开发者效率提升30%-70%,中小企业开发成本降低70%,个人开发者可快速实现产品落地。对于开发者而言,熟练运用AI编程工具,不是…...

效率倍增:用快马生成openclaw在ubuntu的一键部署与docker化脚本
最近在折腾一个开源项目openclaw的部署,发现每次在Ubuntu服务器上手动安装配置特别费时间。作为一个懒人程序员,我决定研究下怎么把整个流程自动化,结果发现用InsCode(快马)平台可以轻松搞定这件事,效率直接翻倍。 传统部署方式的…...

OpenSpeedy高效构建与分发指南:从源码到部署的全流程实践
OpenSpeedy高效构建与分发指南:从源码到部署的全流程实践 【免费下载链接】OpenSpeedy 🎮 An open-source game speed modifier. 项目地址: https://gitcode.com/gh_mirrors/op/OpenSpeedy OpenSpeedy作为一款专注于提升GitHub资源访问速度的开源…...

AI简历被秒拒?项目描述的4个细节,决定你能否拿到面试
AI简历被秒拒?项目描述的4个细节,决定你能否拿到面试金三银四求职季,不少求职者靠着AI工具快速生成简历,却发现投出的简历石沉大海、屡屡秒拒。很多人疑惑,自己的技术栈、项目经验明明符合岗位要求,为什么连…...

选AI面试软件,为何一定要看中防作弊、可解释、全场景?
想象一下:你花了半个月筛选简历,终于确定了100个面试候选人,却发现一半人在用AI生成器写答案、用提词器念稿,甚至找人替考;好不容易拿到AI评分,却看不懂分数怎么来的,候选人质疑时你根本没法解释…...
)
告别黑盒:用Python拆解OpenBCI GUI的滤波与可视化模块(附完整代码)
从零构建Python版OpenBCI数据处理引擎:解码脑电信号处理全流程 在脑机接口开发领域,OpenBCI以其开源特性和专业级性能成为众多研究者的首选硬件平台。然而,其官方GUI虽然功能完善,却像一座封闭的城堡——我们能看到华丽的城墙&…...

短视频 SEO 推广与视频广告投放的区别是什么_短视频 SEO 优化需要结合网站整体 SEO 策略吗
短视频 SEO 推广与视频广告投放的区别是什么_短视频 SEO 优化需要结合网站整体 SEO 策略吗 在当前数字化营销的浪潮中,短视频平台和视频广告投放已经成为许多企业和创作者推广内容、吸引观众的重要手段。对于SEO策略的理解和应用却常常存在误解。今天,我…...

OneDrive导致桌面图标变白的解决方案
OneDrive导致桌面图标变白的原因主要是由于OneDrive的同步功能或图标缓存损坏。当使用OneDrive的“释放空间”功能时,可能会导致图标变为空白页或默认图标。此外,图标缓存损坏也可能导致图标变白。解决方法:1. 调整OneDrive设置:在…...

开发者的软实力:沟通、协作与影响力的修炼手册
在软件开发的精密世界里,代码是骨骼,架构是经脉,而沟通、协作与影响力,则是驱动整个系统顺畅运行的血液与神经。对于软件测试从业者而言,这种认知尤为深刻。我们早已超越了“找Bug”的单一角色,成为质量文化…...