SELECT COUNT(*) 会造成全表扫描吗?
前言
SELECT COUNT(*)会不会导致全表扫描引起慢查询呢?
SELECT COUNT(*) FROM SomeTable
网上有一种说法,针对无 where_clause 的 COUNT(*),MySQL 是有优化的,优化器会选择成本最小的辅助索引查询计数,其实反而性能最高,这种说法对不对呢
针对这个疑问,我首先去生产上找了一个千万级别的表使用 EXPLAIN 来查询了一下执行计划
EXPLAIN SELECT COUNT(*) FROM SomeTable
结果如下

如图所示: 发现确实此条语句在此例中用到的并不是主键索引,而是辅助索引,实际上在此例中我试验了,不管是 COUNT(1),还是 COUNT(*),MySQL 都会用成本最小 的辅助索引查询方式来计数,也就是使用 COUNT(*) 由于 MySQL 的优化已经保证了它的查询性能是最好的!随带提一句,COUNT(*)是 SQL92 定义的标准统计行数的语法,并且效率高,所以请直接使用COUNT(*)查询表的行数!
所以这种说法确实是对的。但有个前提,在 MySQL 5.6 之后的版本中才有这种优化。
那么这个成本最小该怎么定义呢,有时候在 WHERE 中指定了多个条件,为啥最终 MySQL 执行的时候却选择了另一个索引,甚至不选索引?
本文将会给你答案,本文将会从以下两方面来分析
-
SQL 选用索引的执行成本如何计算
-
实例说明
SQL 选用索引的执行成本如何计算
就如前文所述,在有多个索引的情况下, 在查询数据前,MySQL 会选择成本最小原则来选择使用对应的索引,这里的成本主要包含两个方面。
-
IO 成本: 即从磁盘把数据加载到内存的成本,默认情况下,读取数据页的 IO 成本是 1,MySQL 是以页的形式读取数据的,即当用到某个数据时,并不会只读取这个数据,而会把这个数据相邻的数据也一起读到内存中,这就是有名的程序局部性原理,所以 MySQL 每次会读取一整页,一页的成本就是 1。所以 IO 的成本主要和页的大小有关
-
CPU 成本:将数据读入内存后,还要检测数据是否满足条件和排序等 CPU 操作的成本,显然它与行数有关,默认情况下,检测记录的成本是 0.2。
实例说明
为了根据以上两个成本来算出使用索引的最终成本,我们先准备一个表(以下操作基于 MySQL 5.7.18)
CREATE TABLE `person` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `name` varchar(255) NOT NULL, `score` int(11) NOT NULL, `create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (`id`), KEY `name_score` (`name`(191),`score`), KEY `create_time` (`create_time`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
这个表除了主键索引之外,还有另外两个索引, name_score 及 create_time。然后我们在此表中插入 10 w 行数据,只要写一个存储过程调用即可,如下:
CREATE PROCEDURE insert_person()
begin declare c_id integer default 1; while c_id<=100000 do insert into person values(c_id, concat('name',c_id), c_id+100, date_sub(NOW(), interval c_id second)); set c_id=c_id+1; end while;
end
插入之后我们现在使用 EXPLAIN 来计算下统计总行数到底使用的是哪个索引
EXPLAIN SELECT COUNT(*) FROM person

从结果上看它选择了 create_time 辅助索引,显然 MySQL 认为使用此索引进行查询成本最小,这也是符合我们的预期,使用辅助索引来查询确实是性能最高的!
我们再来看以下 SQL 会使用哪个索引
SELECT * FROM person WHERE NAME >'name84059' AND create_time>'2020-05-23 14:39:18'

用了全表扫描!理论上应该用 name_score 或者 create_time 索引才对,从 WHERE 的查询条件来看确实都能命中索引,那是否是使用 SELECT *造成的回表代价太大所致呢,我们改成覆盖索引的形式试一下
SELECT create_time FROM person WHERE NAME >'name84059' AND create_time > '2020-05-23 14:39:18'
结果 MySQL 依然选择了全表扫描!这就比较有意思了,理论上采用了覆盖索引的方式进行查找性能肯定是比全表扫描更好的,为啥 MySQL 选择了全表扫描呢,既然它认为全表扫描比使用覆盖索引的形式性能更好,那我们分别用这两者执行来比较下查询时间吧
-- 全表扫描执行时间: 4.0 ms
SELECT create_time FROM person WHERE NAME >'name84059' AND create_time>'2020-05-23 14:39:18' -- 使用覆盖索引执行时间: 2.0 ms
SELECT create_time FROM person force index(create_time) WHERE NAME >'name84059' AND create_time>'2020-05-23 14:39:18'
从实际执行的效果看使用覆盖索引查询比使用全表扫描执行的时间快了一倍!说明 MySQL 在查询前做的成本估算不准!我们先来看看 MySQL 做全表扫描的成本有多少。
前面我们说了成本主要 IO 成本和 CPU 成本有关,对于全表扫描来说也就是分别和聚簇索引占用的页面数和表中的记录数。执行以下命令
SHOW TABLE STATUS LIKE 'person'

可以发现
也就是说全表扫描的成本是 20052.8 + 353 = 20406。
这个结果对不对呢,我们可以用一个工具验证一下。在 MySQL 5.6 及之后的版本中,我们可以用 optimizer trace 功能来查看优化器生成计划的整个过程 ,它列出了选择每个索引的执行计划成本以及最终的选择结果,我们可以依赖这些信息来进一步优化我们的 SQL。
optimizer_trace 功能使用如下
SET optimizer_trace="enabled=on";
SELECT create_time FROM person WHERE NAME >'name84059' AND create_time > '2020-05-23 14:39:18';
SELECT * FROM information_schema.OPTIMIZER_TRACE;
SET optimizer_trace="enabled=off";
执行之后我们主要观察使用 name_score,create_time 索引及全表扫描的成本。
先来看下使用 name_score 索引执行的的预估执行成本:
{ "index": "name_score", "ranges": [ "name84059 <= name" ], "index_dives_for_eq_ranges": true, "rows": 25372, "cost": 30447
}
可以看到执行成本为 30447,高于我们之前算出来的全表扫描成本:20406。所以没选择此索引执行
注意:这里的 30447 是查询二级索引的 IO 成本和 CPU 成本之和,再加上回表查询聚簇索引的 IO 成本和 CPU 成本之和。
再来看下使用 create_time 索引执行的的预估执行成本:
{ "index": "create_time", "ranges": [ "0x5ec8c516 < create_time" ], "index_dives_for_eq_ranges": true, "rows": 50132, "cost": 60159, "cause": "cost"
}
可以看到成本是 60159,远大于全表扫描成本 20406,自然也没选择此索引。
再来看计算出的全表扫描成本:
{ "considered_execution_plans": [ { "plan_prefix": [ ], "table": "`person`", "best_access_path": { "considered_access_paths": [ { "rows_to_scan": 100264, "access_type": "scan", "resulting_rows": 100264, "cost": 20406, "chosen": true } ] }, "condition_filtering_pct": 100, "rows_for_plan": 100264, "cost_for_plan": 20406, "chosen": true } ]
}
注意看 cost:20406,与我们之前算出来的完全一样!这个值在以上三者算出的执行成本中最小,所以最终 MySQL 选择了用全表扫描的方式来执行此 SQL。
实际上 optimizer trace 详细列出了覆盖索引,回表的成本统计情况,有兴趣的可以去研究一下。
从以上分析可以看出, MySQL 选择的执行计划未必是最佳的,原因有挺多,就比如上文说的行数统计信息不准,再比如 MySQL 认为的最优跟我们认为不一样,我们可以认为执行时间短的是最优的,但 MySQL 认为的成本小未必意味着执行时间短。
总结
本文通过一个例子深入剖析了 MySQL 的执行计划是如何选择的,以及为什么它的选择未必是我们认为的最优的,这也提醒我们,在生产中如果有多个索引的情况,使用 WHERE 进行过滤未必会选中你认为的索引,我们可以提前使用 EXPLAIN,optimizer trace 来优化我们的查询语句。
-
行数是 100264,我们不是插入了 10 w 行的数据了吗,怎么算出的数据反而多了,其实这里的计算是估算 ,也有可能这里的行数统计出来比 10 w 少了,估算方式有兴趣大家去网上查找,这里不是本文重点,就不展开了。得知行数,那我们知道 CPU 成本是
100264 * 0.2 = 20052.8。 -
数据长度是 5783552,InnoDB 每个页面的大小是 16 KB,可以算出页面数量是 353。
相关文章:
SELECT COUNT(*) 会造成全表扫描吗?
前言 SELECT COUNT(*)会不会导致全表扫描引起慢查询呢? SELECT COUNT(*) FROM SomeTable 网上有一种说法,针对无 where_clause 的 COUNT(*),MySQL 是有优化的,优化器会选择成本最小的辅助索引查询计数,其实反而性能…...
)
python考前复习(90题)
文章目录 1.Python特性的是( )。 A. 面向对象 B. 高可移植性 C. 开源、免费 2.临时改变Python语言安装源应当使用的选项是 –index-url 3.Python脚本文件的扩展名为( ) .py 4.安装Python语言的软件包使用的命令是( ) pip install 5 . (单选题)以下哪项是…...

根据SpringBoot Guides完成进行示例学习(详细步骤)
目录 1.打开Spring | Guides官网,或者直接搜索springboot都可 2.选择要学习的内容 3.根据提示的网址,Git到本地 4.将文件用IDEA打开,根据教程完成示例,这里不做细致讲解 5.运行项目 6.在终端查看运行结果 以Scheduling Task…...
waf、yakit和ssh免密登录
WAF安全狗 脏数据适用于所有漏洞绕过waf,但是前提条件垃圾信息必须放在危险信息前,是不能打断原有数据包的结构,不能影响后端对数据包的解析。 以DVWA靶场文件上传为例 新建php文件 上传文件被安全狗拦截 使用bp抓包查看 在数据包Content-…...

【AIGC核心技术剖析】大型语言和视觉助手——LLaVA(论文+源码)
🔥 [新!LLaVA-1.5 在 11 个基准测试上实现了 SoTA,只需对原始 LLaVA 进行简单的修改,利用所有公共数据,在单个 1-A8 节点上在 ~100 天内完成训练,并超越使用数十亿级数据的方法。 LLaVA代表了一种新颖的端到端训练大型多模态模型,结合了视觉编码器和骆马 对于通用的视…...

IBM的WAS简介与基本使用手册
IBM的WAS简介与基本使用手册 1. 基本介绍 WebSphereApplication Server(简称WAS)是IBM的应用服务器 基本结构:单元(cell) ——> 多个节点(node) ——> 多个服务(server) ——> 多个应用(app) 单元是整个分布式网络中一个或多个节点的逻辑分组单元是一个配置概念, 是…...

Deno 快速入门
目录 1、简介 2、安装Deno MacOS下安装 Windows下安装 Linux 下安装 3、创建并运行TypeScript程序 4、内置Web API和Deno命名空间 5、运行时安全 6、导入JavaScript模块 7、远程模块和Deno标准库 8、使用deno.json配置您的项目 9、Node.js API和npm包 10、配置IDE…...
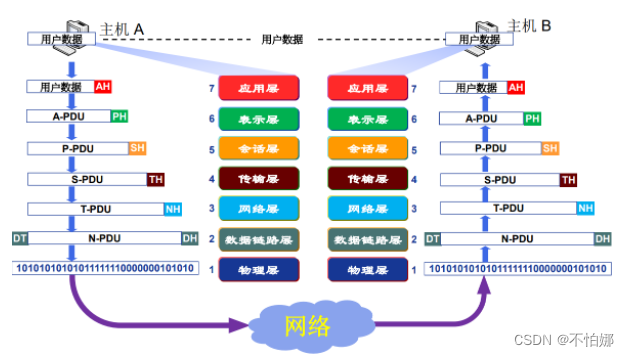
【计算机网络笔记】OSI参考模型基本概念
系列文章目录 什么是计算机网络? 什么是网络协议? 计算机网络的结构 数据交换之电路交换 数据交换之报文交换和分组交换 分组交换 vs 电路交换 计算机网络性能(1)——速率、带宽、延迟 计算机网络性能(2)…...

ConnectTimeout和ReadTimeout所代表的意义
ConnectTimeout和ReadTimeout所代表的意义 ConnectTimeout 指的是建立连接所用的时间,适用于网络状况正常的情况下,两端连接所用的时间。在java中,网络状况正常的情况下,例如使用HttpClient或者HttpURLConnetion连接时设置参数c…...

使用Python计算平面多边形间最短距离,数据需要从excel表格中导入
使用Python计算平面多边形间最短距离,数据需要从excel表格中导入, * 多边形种类包括(圆形、矩形、六边形、五边形、跑道形/胶囊形), * Python代码需要使用gjk算法进行判断两个多边形间是否重叠, * 如果未重…...

华为数通方向HCIP-DataCom H12-831题库(多选题:1-20)
第01题 如图所示,路由器所有的接口开启OSPF,图中标识的ip地址为设备的Loopback0接口的IP地址,R1、R2,R3的Loopback0通告在区域1,R4的Loopback0通告在区域0、R5的Lopback0通告在区域2,下列哪些IP地址之间可以相互Ping通? A、10.0.3.3和10.0.5.5 B、10.0.4.4和10.0.2.2 …...
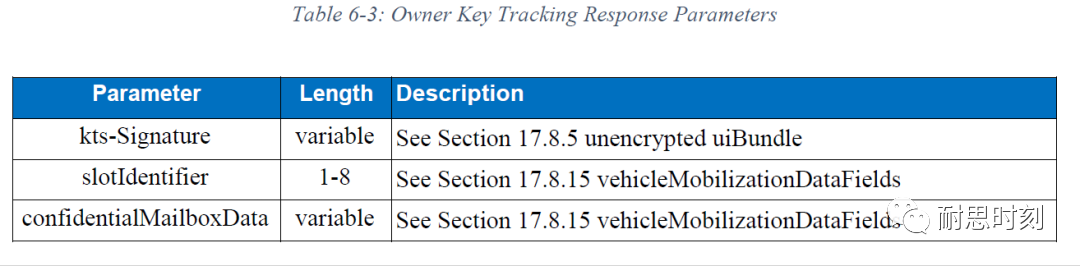
CCC数字钥匙设计【NFC】--通过NFC进行车主配对Phase3
1、车主配对流程介绍 车主配对可以通过车内NFC进行,若支持UWB测距,也可以通过蓝牙/UWB进行。通过NFC进行车主配对总共有5个Phase。本文档主要对Phase3进行介绍。 1) Phase0:准备阶段; 2) Phase1:启动流程࿱…...
开源OA协同办公系统,集成Flowable流程引擎 可拖拽创建个性表单
源码下载:https://download.csdn.net/download/m0_66047725/88403340 源码下载2: 关注我留言 开源OA协同办公系统,集成Flowable流程引擎 可拖拽创建个性表单。基于RuoYi-VUE版本开发。 1、使用RuoYi-Vue的基础上开发。 2、集成flowable&a…...

为什么嵌入通常优于TF-IDF:探索NLP的力量
塔曼纳 一、说明 自然语言处理(NLP)是计算机科学的一个领域,涉及人类语言的处理和分析。它用于各种应用程序,例如聊天机器人、情绪分析、语音识别等。NLP 中的重要任务之一是文本分类,我们根据文本的内容将文本分类为不…...
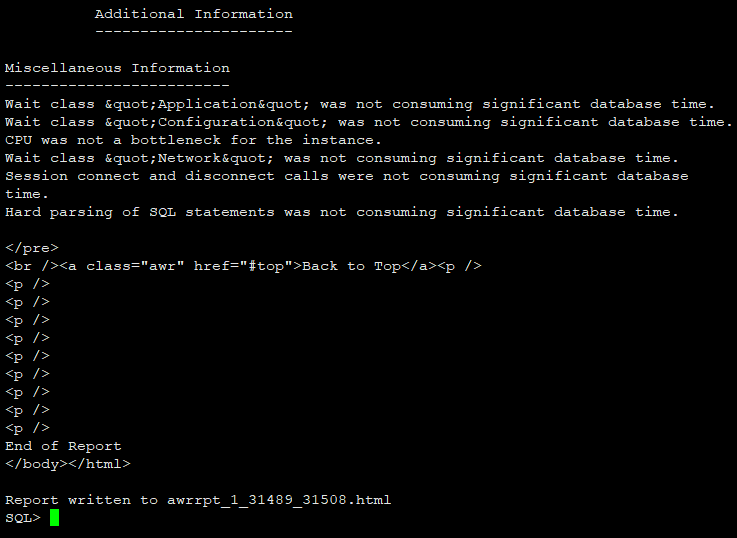
oracle-AWR报告生成方法
AWR报告生成方法 1. 以oracle用户登陆服务器 2. 进入到要保存awr报告的目录 3. 以sysdba身份连接数据库 sqlplus / as sysdba4. 执行生成AWR报告命令 ?/rdbms/admin/awrrpt.sql5. 选择AWR报告的文件格式 6. 选择生成多少天的AWR报告 7. 选择报告的快照起始和结束ID 8. 输入生…...
)
笙默考试管理系统-MyExamTest----codemirror(37)
笙默考试管理系统-MyExamTest----codemirror(36) 目录 一、 笙默考试管理系统-MyExamTest 二、 笙默考试管理系统-MyExamTest 三、 笙默考试管理系统-MyExamTest 四、 笙默考试管理系统-MyExamTest 五、 笙默考试管理系统-MyExamTest 笙默考试…...
【Unity3D编辑器拓展】Unity3D的IMGUI、GUI、GUILayout、EditorGUI、EditorGUILayout、OnGUI【全面总结】
推荐阅读 CSDN主页GitHub开源地址Unity3D插件分享简书地址我的个人博客 大家好,我是佛系工程师☆恬静的小魔龙☆,不定时更新Unity开发技巧,觉得有用记得一键三连哦。 一、前言 在开发中,常常会遇到要使用OnGUI的地方。 也会遇到…...
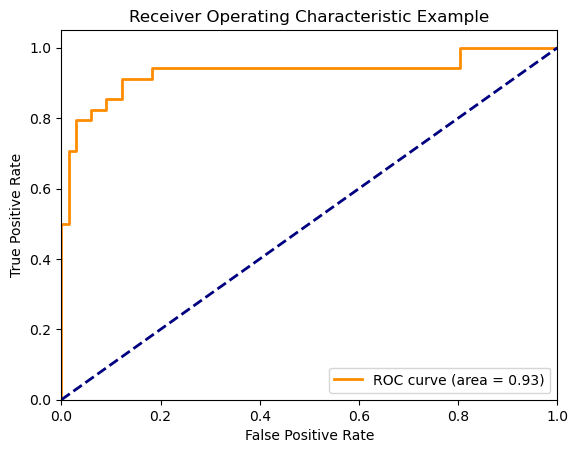
11. 机器学习 - 评价指标2
文章目录 混淆矩阵F-scoreAUC-ROC 更多内容: 茶桁的AI秘籍 Hi, 你好。我是茶桁。 上一节课,咱们讲到了评测指标,并且在文章的最后提到了一个矩阵,我们就从这里开始。 混淆矩阵 在我们实际的工作中,会有一个矩阵&am…...
Nginx的代理和负载均衡
一、nginx的代理方式 1.1 七层代理 七层代理:基于http协议,对请求的内容进行处理,然后转发到后端服务器 七层代理是客户端请求代理服务器,由代理服务器转发客户端的http请求,转发到内部的服务器进行处理(服务器可以是…...

Oracle发布支持Vscode的Java插件
Oracle 发布对 Visual Studio Code 的 Java 插件支持,这个扩展插件通过基于 OpenJDK 的 javac 编译器和调试器接口的语言服务器,为流行的多语言集成开发环境提供 Java 支持。 VS Code 扩展的核心是Java语言服务器:这是一个使用语言服务器协议…...

松下Panasonic伺服调试软件 适配MINAS-A/A3/A4/B/E/S及MDDA/MH...
松下Panasonic 伺服调试 软件 支持MINAS-A A3 A4 B E S 英文版 MDDA、MHDA、MSMA、MSDA、MDMA、可以修改参数、JOG点动调试、参数拷贝、复制等 松下 伺服 软件刚拿到台新拆箱的MHDA-MA3A1A伺服驱动器?或者翻出实验室积灰好几年的MSMA电机搭MDDA A1板子练手ÿ…...
)
UCI心脏病数据集实战:用XGBoost构建预测模型的全流程指南(附特征重要性分析)
UCI心脏病数据集实战:用XGBoost构建预测模型的全流程指南(附特征重要性分析) 医疗数据科学正在重塑现代医学诊断方式。当我在克利夫兰诊所实习期间,亲眼见证了机器学习模型如何辅助医生识别高风险心脏病患者。本文将带您完整复现这…...

PyAutoGUI实战:给你的旧软件做个‘外挂’,自动完成游戏日常或软件测试
PyAutoGUI实战:用Python打造智能自动化助手,解放双手提升效率 在数字时代,重复性任务如同无形的枷锁,消耗着我们的时间和精力。想象一下,每天打开电脑后,你需要重复点击十几个相同的按钮,填写相…...

向量化计算落地难?揭秘阿里/腾讯内部正在用的7个Java Vector API高危避坑场景
第一章:Java Vector API向量化计算落地的现实困境Java Vector API(JEP 338、414、426、448)虽在JDK 16起逐步成熟,但实际工程化部署仍面临多重结构性约束。其核心矛盾在于:API设计高度抽象,而底层硬件适配、…...

Glide框架在Java中的高效集成与动图加载实践
1. 为什么选择Glide处理Java项目中的动图加载 第一次在Android项目里遇到动图加载需求时,我试过用原生ImageView逐帧解析,结果内存直接爆了。后来发现Glide这个宝藏框架,它就像个智能的动图管家,把复杂的解码、内存管理、缓存优化…...

程序员体检报告暗语:甲状腺结节=加班等级说明书
一、当体检报告出现“甲状腺结节”翻开软件测试工程师的体检报告,“甲状腺结节”已成为高频词。医学定义中,甲状腺结节是甲状腺细胞异常增生形成的肿块,随吞咽移动,临床检出率超20%(数据来源:2023年《中国甲…...

STMPE811电阻触摸屏驱动设计与实现
1. 项目概述TS_DISCO_F429ZI 是专为 STMicroelectronics STM32F429ZI 探索套件(DISCO_F429ZI)设计的触摸屏驱动类,其核心职责是抽象并控制该开发板上集成的 LCD 模块所搭载的电阻式触摸屏控制器。该类并非通用型触摸驱动,而是深度…...

实现网页完整捕获:Full Page Screen Capture技术解析与应用指南
实现网页完整捕获:Full Page Screen Capture技术解析与应用指南 【免费下载链接】full-page-screen-capture-chrome-extension One-click full page screen captures in Google Chrome 项目地址: https://gitcode.com/gh_mirrors/fu/full-page-screen-capture-chr…...

数据仓库核心概念:事实表和维度表详解与实战应用
数据仓库核心概念:事实表和维度表详解与实战应用一、引言二、定义:什么是事实表?什么是维度表?2.1 事实表:定义2.2 维度表:定义三、结构流程图:事实表与维度表关联关系3.1 标准星型模型关联流程…...

你的企业还在靠人工处理重复工作?同行已经用 AI 释放人力了 | 2026企业数字化转型指南:基于实在Agent的端到端自动化解决方案
在2026年的数字化浪潮中,企业间的竞争已经从“资源规模”转向了“响应速度”。 当多数企业还在为报表合并、数据搬运、跨系统审核等重复性劳动耗费大量人力时, 领先的行业标杆已经开始通过智能体技术重构底层作业逻辑。 这种转变不仅是工具的更替&#x…...