数据结构-堆排序Java实现
目录
- 一、引言
- 二、算法步骤
- 三、原理演示
- 步骤1: 构建最大堆
- 步骤2: 交换和堆化
- 步骤3: 排序完成
- 四、代码实战
- 五、结论
一、引言
堆排序是一种利用堆这种数据结构所设计的一种排序算法。堆是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。
二、算法步骤
堆排序的核心是建立和维护一个二叉堆,通常是一个最大堆(Max Heap)或最小堆(Min Heap)。在最大堆中,根节点的值是最大的,而在最小堆中,根节点的值是最小的。堆排序的基本思路如下:
- 构建最大堆:将未排序的数组构建成一个最大堆。这通常需要从最后一个非叶子节点开始,逐步向前调整,使整个数组满足最大堆的性质。
- 交换和堆化:将最大堆的根节点与最后一个元素交换,然后减小堆的大小(即排除最后一个元素),再对根节点进行堆化操作,以保持最大堆的性质。
- 重复步骤2:重复执行步骤2,直到堆的大小减小到1,排序完成。
三、原理演示
堆排序是一种基于二叉堆数据结构的排序算法,它通过构建和维护一个最大堆(或最小堆)来对数组进行排序。在这里,我将动态说明堆排序的实现过程,以帮助您更好地理解它。
步骤1: 构建最大堆
假设我们有一个未排序的整数数组作为输入。第一步是将这个数组构建成一个最大堆,确保堆的性质:每个父节点的值都大于或等于其子节点的值。初始数组:
[4, 10, 3, 5, 1]
构建最大堆的过程:
从数组的中间元素开始,即索引为 n/2 - 1,这是最后一个非叶子节点。从这个节点向前遍历,执行堆化操作。
[4, 10, 3, 5, 1]
堆化过程:从根节点开始,比较它与其子节点的值,如果子节点的值更大,则交换它们,然后继续堆化子节点。
[10, 4, 3, 5, 1]
继续堆化直到整个数组成为最大堆。
步骤2: 交换和堆化
在第一步完成后,我们已经构建了一个最大堆,其中根节点包含最大的元素。现在,我们将根节点与最后一个元素交换,将最大元素放到正确的位置。交换和堆化的过程:
交换根节点和最后一个元素:
[1, 4, 3, 5, 10]
减小堆的大小,排除最后一个元素。
对根节点进行堆化操作,以保持最大堆性质。
[5, 4, 3, 1]
重复步骤1和步骤2,直到堆的大小减小到1,排序完成。
步骤3: 排序完成
最终,堆排序完成,数组中的元素按升序排列。
排序完成的数组:
[1, 3, 4, 5, 10]
这就是堆排序的整个过程。它的时间复杂度为O(nlogn),具有稳定性,适用于大型数据集的排序。堆排序的核心是构建和维护堆,确保最大(或最小)元素位于根节点,然后将根节点与数组末尾的元素交换,并逐渐减小堆的大小。
四、代码实战
下面我们使用java演示一下堆排序的过程:
public class HeapSort {public static void main(String[] args) {int[] arr = {12, 11, 13, 5, 6, 7};int n = arr.length;System.out.println("原始数组:");printArray(arr);heapSort(arr);System.out.println("排序后的数组:");printArray(arr);}public static void heapSort(int[] arr) {int n = arr.length;// 构建最大堆for (int i = n / 2 - 1; i >= 0; i--) {heapify(arr, n, i);}// 逐个提取元素并排序for (int i = n - 1; i >= 0; i--) {int temp = arr[0];arr[0] = arr[i];arr[i] = temp;heapify(arr, i, 0);}}public static void heapify(int[] arr, int n, int i) {int largest = i;int left = 2 * i + 1;int right = 2 * i + 2;if (left < n && arr[left] > arr[largest]) {largest = left;}if (right < n && arr[right] > arr[largest]) {largest = right;}if (largest != i) {int swap = arr[i];arr[i] = arr[largest];arr[largest] = swap;heapify(arr, n, largest);}}public static void printArray(int[] arr) {for (int value : arr) {System.out.print(value + " ");}System.out.println();}
}
上述代码演示了堆排序的实现。它首先定义了一个包含整数数组的示例,然后调用 heapSort 方法来对数组进行排序。heapSort 方法首先构建一个最大堆,然后进行排序。heapify 方法用于维护最大堆的性质。
五、结论
我们一起来总结一下:
- 堆排序是一种选择排序的变种,它将待排序序列划分成若干个子序列,每个子序列都满足堆积的性质,即子序列的最大值(或最小值)位于其顶部。
- 堆排序的时间复杂度为O(nlogn),其中n表示待排序序列的长度。这是因为堆排序需要将序列构造成堆,这需要O(nlogn)的时间复杂度,然后需要依次取出每个元素,这需要O(n)的时间复杂度。
- 堆排序的空间复杂度为O(1)。这是因为堆排序只需要在内存中使用常数级别的额外空间来完成排序。
- 堆排序是原地排序算法,也就是说,它不需要额外的存储空间,除了用于存储待排序序列本身的存储空间之外。
- 堆排序是稳定的排序算法,也就是说,它保持了相同元素的相对顺序。
- 堆排序适用于大规模数据的排序,特别是当内存空间有限时,因为它只需要常数级别的额外空间。
- 堆排序算法的实现比较简单,但理解和掌握它需要对数据结构和算法有较深入的理解。
点赞收藏,富婆包养✋✋
相关文章:

数据结构-堆排序Java实现
目录 一、引言二、算法步骤三、原理演示步骤1: 构建最大堆步骤2: 交换和堆化步骤3: 排序完成 四、代码实战五、结论 一、引言 堆排序是一种利用堆这种数据结构所设计的一种排序算法。堆是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或…...
C#进阶——反射(Reflection)
定义:反射指的是在运行时动态地获取、检查和操作程序中的类型信息,而在我们的Unity中反射允许开发者在运行时通过代码来访问和修改对象的属性、方法和字段,而不需要提前知道这些成员的具体信息。 举一个例子,我们使用反射在运行的…...

Oracle 运维篇+应用容器数据库的install、upgrade、patch、uninstall
★ 知识点 ※ DEFAULT_SHARING参数的取值 METADATA: 元数据链接共享数据库对象的元数据,但其数据对于每个容器是唯一的。这些数据库对象被称为元数据链接的应用程序公共对象。此设置为默认设置。DATA: 数据链接共享数据库对象,其数据对于应用程序容器中…...
Affinity Publisher for Mac/Windows最新中文下载 排版神器
Affinity Publisher是一款专业的排版和设计软件,它可以帮助您从简单的文档到复杂的书籍和杂志轻松创建高质量的出版物。 该软件具有直观的界面和强大的功能,使您可以轻松组织和编辑文本、图像和数据,并创建令人惊叹的布局。 Affinity Publi…...
Mac文件对比同步工具 Beyond Compare 4.4.7
Beyond Compare 4 是一款强大的文件和文件夹比较工具。它提供了一个直观的界面,使您可以快速比较和同步文件和文件夹。 Beyond Compare 4 具有许多有用的功能,包括比较和合并文件、文件夹和压缩文件,以及同步文件和文件夹。它支持各种类型的文…...
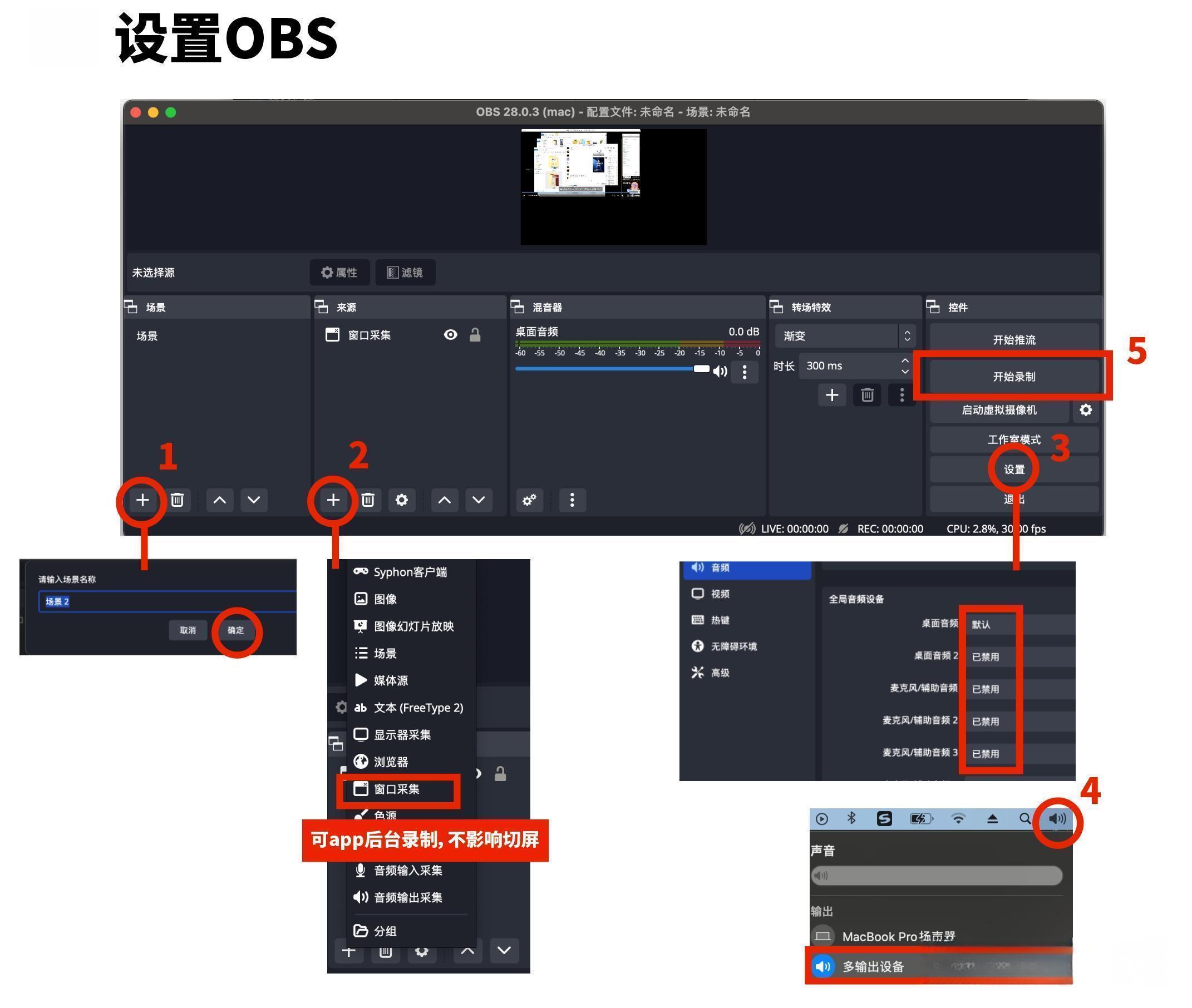
技巧 | 如何解决 OBS 系统声音无法捕获问题 | Mac
技巧 | 如何解决 OBS 系统声音无法捕获问题 | Mac 问题描述 由于 macOS 系统限制,桌面音频被禁止,导致在使用 OBS 无法录制桌面音频,只能使用自带麦克风录制。 解决方法 Loopback 介绍 借助 Loopback 的强大功能,可以轻松地…...
从头开始机器学习:逻辑回归
一、说明 本篇实现线性回归的先决知识是:基本线性代数,微积分(偏导数)、梯度和、Python (NumPy);从线性方程入手,逐渐理解线性回归预测问题。 二、逻辑回归简介 我们将以我们在线性回…...

插入排序 算法
从第二个开始,从后面往前找,如果比其小,就交换,else 就终止 for i 1 i <n i for j i j > 0 (到第二个) j-- if < swap 下面给出源码 //对插入排序来说,直接从第二个元素开始template<ty…...
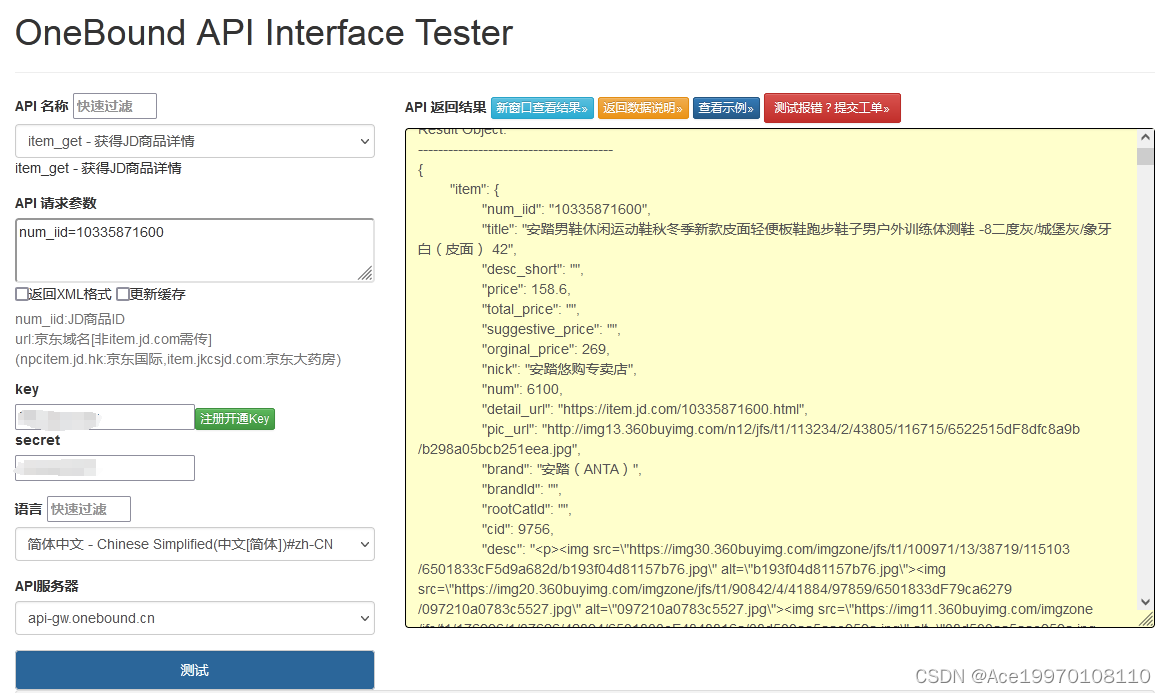
“揭秘!如何通过京东商品详情接口轻松获取海量精准商品信息!“
京东商品详情接口可以通过HTTP GET请求获取商品详情信息。 请求参数包括num_iid,表示JD商品ID。 请求示例: GET /jd/item_get/?num_iid10335871600 HTTP/1.1 Host: api-vx.Taobaoapi2014.cn Connection: close Accept-Encoding: gzip 点击获取…...

已经有多人中招,不要被AI换脸技术骗了!
您好,我是码农飞哥(wei158556),感谢您阅读本文,欢迎一键三连哦。 💪🏻 1. Python基础专栏,基础知识一网打尽,9.9元买不了吃亏,买不了上当。 Python从入门到精…...

solidworks 2024新功能之--保存为低版本 硕迪科技
大家期盼已久的SOLIDWORKS保存低版本文件功能来了,从SOLIDWORKS 2024 开始,您可以将在最新版本的SOLIDWORKS 中创建的SOLIDWORKS零件、装配体和工程图另存为SOLIDWORKS 早期版本的全功能文档(完成的特征树与相关参数)。 将文件另…...
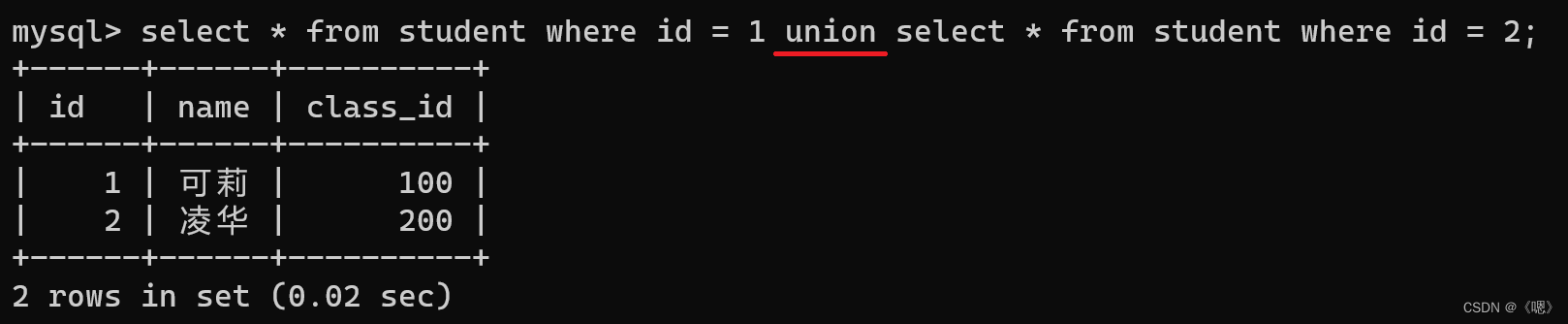
MySQL --- 聚合查询 和 联合查询
聚合查询: 下文中的所有聚合查询的示例操作都是基于此表: 聚合函数 聚合函数都是行与行之间的运算。 count() select count(列名) from 表名; 统计该表中该列的行数,但是 null 值不会统计在内,但是如果写为 count(*) 那么 nu…...
Note——torch.size() umr_maximum() array.max() itertools.product()
torch.size Problem TypeError: ‘torch.Size’ object is not callable Reason Analysis torch.Size函数不可调用 因为torch只可以.size() 或 shape Solution 将y.shape()替换为y.size() 或 y.shape ytorch.normal(0,0.01,y.size())2 return umr_maximum(a, axis, None…...

python学习笔记6-DefaultDict
对于一般的字典来说,如果键不存在会导致【KeyError】,因此可以考虑用DefaultDict # Defining the dict d defaultdict(def_value) d["a"] 1 d["b"] 2print(d["a"]) print(d["b"]) print(d["c"…...

Redis 底层对 String 的 3 个优化
Redis对 String 类型实现了很多优化,通过以下三个重要的优化点来解释: 1. 简单动态字符串(SDS) Redis 的 String 类型内部采用简单动态字符串(SDS)来管理字符串。相比于 C 语言的原生字符串,S…...
简约艺术签名小程序源码/流量主小程序源码/字节跳动抖音小程序
源码简介: 本源码为简约艺术签名小程序、流量主小程序以及字节跳动抖音小程序的源代码。该小程序是一款实用的工具,旨在帮助用户创建各种独特的艺术签名,以便在社交媒体平台上更好地展示用户的个性和创意。 源码链接: 网盘源码 …...
挂载iso文件和配置apt本地源)
Ubuntu(kylin)挂载iso文件和配置apt本地源
版本说明:Ubuntu Server 16.04 LTS解决问题:解决在无任何互联网的环境下,安装软件时缺少依赖包的问题 方法一:通过虚拟机挂载 将镜像挂载到虚拟机以VMware Workstation为例,打开“虚拟机设置”,点击“CD/DVD”选项,将 “设备状态”中的“<...

wps表格求标准差怎么算?
在WPS表格中,要计算标准差,可以使用STDEV函数。标准差是一种衡量数据集合离散程度的统计指标。下面我将详细介绍如何使用STDEV函数来计算标准差。 STDEV函数的语法为:STDEV(range) 其中,range表示要计算标准差的数据范围&#x…...

安达发|制造企业生产排产现状和APS系统的解决方案
随着市场竞争的加剧,制造业企业面临着生产效率、成本控制和客户满意度等方面的巟大压力。在这种背景下,生产排产作为制造业的核心环节,对企业的生产经营具有重要意义。本文将针对制造业的生产排产现状进行分析,并提出相应的APS系统…...
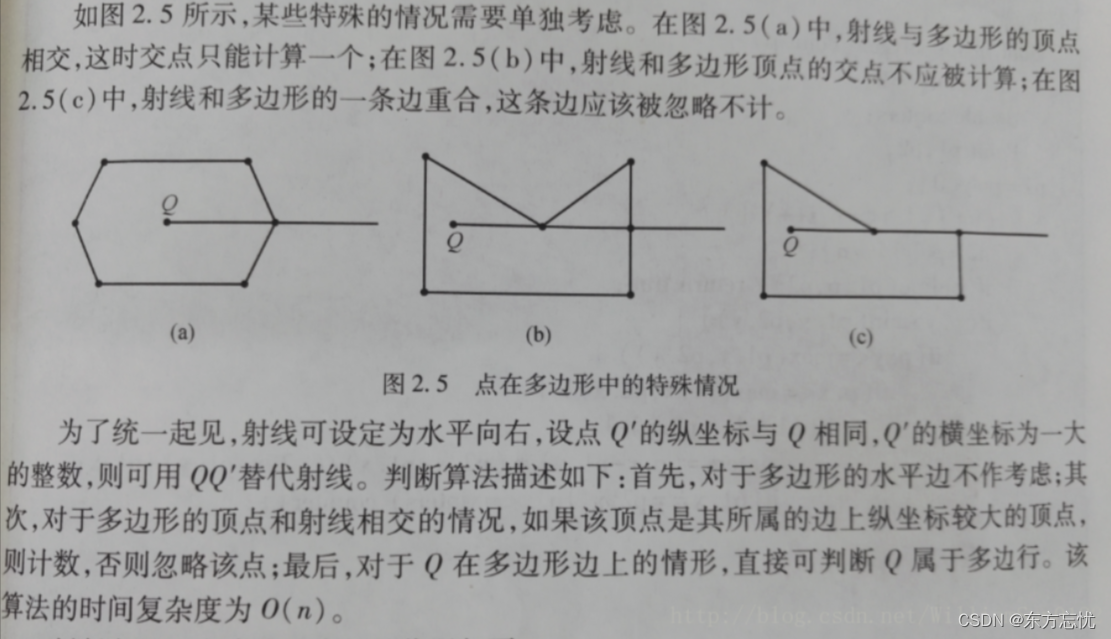
Qt判断一个点在多边形内还是外(支持凸边形和凹变形)
这里实现的方法是转载于https://blog.csdn.net/trj14/article/details/43190653和https://blog.csdn.net/WilliamSun0122/article/details/77994526 来实现的,并且按照Qt的规则进行了调整。 以下实现方法有四种,每种方法的具体讲解在转载的博客中有说明&…...

捡垃圾神器Tesla M40风冷改造全记录:从拆机到上机,Win11双显卡就这么配
Tesla M40风冷改造实战指南:低成本打造高性能计算平台 在硬件DIY的世界里,总有一些被市场低估的"宝藏"等待发掘。Tesla M40计算卡就是这样一个典型代表——它拥有24GB GDDR5显存和3072个CUDA核心,性能接近GTX 1080 Ti,但…...

终极NCM解密指南:3分钟解锁网易云音乐加密格式,让音乐自由播放
终极NCM解密指南:3分钟解锁网易云音乐加密格式,让音乐自由播放 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 还在为下载的网易云音乐NCM格式文件无法在其他播放器播放而烦恼吗?ncmdump是一款简单…...

圆满收官!桥田智能磁力换模硬核闪耀2026国际橡塑展
2026年04月24日,中国,上海为期四天的2026 Chinaplas 国际橡塑展于04月24日圆满结束!作为橡塑行业饱受关注的盛会,本届国际橡塑展上,桥田智能携旗下核心产品与一站式解决方案重磅亮相,与众多行业专家、新老客…...

GetQzonehistory:用Python技术守护你的QQ空间数字记忆
GetQzonehistory:用Python技术守护你的QQ空间数字记忆 【免费下载链接】GetQzonehistory 获取QQ空间发布的历史说说 项目地址: https://gitcode.com/GitHub_Trending/ge/GetQzonehistory 你是否曾试图找回多年前在QQ空间写下的第一条说说,却发现平…...

前端性能监控告警
前端性能监控告警:保障用户体验的关键利器 在当今数字化时代,用户对网页加载速度和交互流畅度的要求越来越高。前端性能的优劣直接影响用户体验、转化率甚至品牌形象。性能问题往往难以通过人工测试全面覆盖,尤其是在复杂的生产环境中。前端…...
:FP16量化+层融合+算子裁剪三重降维)
Python边缘模型瘦身全链路(从PyTorch到ARM Cortex-M7部署):FP16量化+层融合+算子裁剪三重降维
更多请点击: https://intelliparadigm.com 第一章:Python边缘计算模型轻量化概览 在资源受限的边缘设备(如树莓派、Jetson Nano 或工业网关)上部署深度学习模型,面临内存带宽低、算力有限、功耗敏感等核心挑战。Pytho…...

AI动作生成技术:从视频到4D交互模型的突破
1. 项目概述:当计算机学会"脑补"人类动作 在影视特效和游戏开发领域,让虚拟角色与物体进行自然交互一直是个烧钱又耗时的活儿。传统方法需要动作捕捉演员反复表演各种交互场景,而最近来自ArtHOI的研究提出了一种颠覆性方案——只需…...

绿色循环经济下的农业新范式:让每一株蔬菜的“遗骸”化作新生
在山东临沂的兰陵县,一场关于农业废弃物资源化利用的变革正在发生。曾经令人头疼的农业秸秆和牛粪,如今正成为驱动当地蔬菜育苗产业的全新动力。这一变化的起点,是2023年9月正式投产的生升鸿强基质工厂。这家总投资1.1亿元的工厂,…...

Phi-3-mini-4k-instruct-gguf从零开始:中小企业低成本AI助手搭建指南
Phi-3-mini-4k-instruct-gguf从零开始:中小企业低成本AI助手搭建指南 1. 为什么选择Phi-3-mini-4k-instruct-gguf 对于中小企业来说,搭建AI助手需要考虑三个关键因素:成本、易用性和实用性。Phi-3-mini-4k-instruct-gguf正是为这种需求而生…...

终极指南:如何快速解锁VMware macOS虚拟机限制
终极指南:如何快速解锁VMware macOS虚拟机限制 【免费下载链接】auto-unlocker Unlocker for VMWare macOS 项目地址: https://gitcode.com/gh_mirrors/au/auto-unlocker 你是否想在VMware中运行macOS虚拟机,却被系统限制困扰?Auto-Un…...