Flink学习之旅:(三)Flink源算子(数据源)
1.Flink数据源
Flink可以从各种数据源获取数据,然后构建DataStream 进行处理转换。source就是整个数据处理程序的输入端。
数据集合 数据文件 Socket数据 kafka数据 自定义Source
2.案例
2.1.从集合中获取数据
创建 FlinkSource_List 类,再创建个 Student 类(姓名、年龄、性别三个属性就行,反正测试用)
package com.qiyu;import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import java.util.ArrayList;/*** @author MR.Liu* @version 1.0* @data 2023-10-18 16:13*/
public class FlinkSource_List {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);ArrayList<Student> clicks = new ArrayList<>();clicks.add(new Student("Mary",25,1));clicks.add(new Student("Bob",26,2));DataStream<Student> stream = env.fromCollection(clicks);stream.print();env.execute();}
}
运行结果:
Student{name='Mary', age=25, sex=1}
Student{name='Bob', age=26, sex=2}
2.2.从文件中读取数据
文件数据:
spark
hello world kafka spark
hadoop spark
package com.qiyu;import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;/*** @author MR.Liu* @version 1.0* @data 2023-10-18 16:31*/
public class FlinkSource_File {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStream<String> stream = env.readTextFile("input/words.txt");stream.print();env.execute();}
}
运行结果:(没做任何处理)
spark
hello world kafka spark
hadoop spark
2.3.从Socket中读取数据
package com.qiyu;import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;/*** @author MR.Liu* @version 1.0* @data 2023-10-18 17:41*/
public class FlinkSource_Socket {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();// 2. 读取文本流DataStreamSource<String> lineDSS = env.socketTextStream("192.168.220.130",7777);lineDSS.print();env.execute();}
}
运行结果:
服务器上执行:
nc -lk 7777疯狂输出

控制台打印结果
6> hello
7> world
2.4.从Kafka中读取数据
pom.xml 添加Kafka连接依赖
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka_${scala.binary.version}</artifactId><version>${flink.version}</version></dependency>package com.qiyu;import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;import java.util.Properties;/*** @author MR.Liu* @version 1.0* @data 2023-10-19 10:01*/
public class FlinkSource_Kafka {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);Properties properties = new Properties();properties.setProperty("bootstrap.servers", "hadoop102:9092");properties.setProperty("group.id", "consumer-group");properties.setProperty("key.deserializer","org.apache.kafka.common.serialization.StringDeserializer");properties.setProperty("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer");properties.setProperty("auto.offset.reset", "latest");DataStreamSource<String> stream = env.addSource(new FlinkKafkaConsumer<String>("clicks", new SimpleStringSchema(), properties));stream.print("Kafka");env.execute();}
}
启动 zk 和kafka
创建topic
bin/kafka-topics.sh --create --bootstrap-server hadoop102:9092 --replication-factor 1 --partitions 1 --topic clicks生产者、消费者命令
bin/kafka-console-producer.sh --bootstrap-server hadoop102:9092 --topic clicks
bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic clicks --from-beginning启动生产者命令后疯狂输入
运行java类,运行结果:和生产者输入的是一样的
Kafka> flinks
Kafka> hadoop
Kafka> hello
Kafka> nihaop
2.5.从自定义Source中读取数据
大多数情况下,前面几个数据源已经满足需求了。但是遇到特殊情况我们需要自定义的数据源。实现方式如下:
1.编辑自定义源Source
package com.qiyu;import org.apache.flink.streaming.api.functions.source.SourceFunction;import java.util.Calendar;
import java.util.Random;/*** @author MR.Liu* @version 1.0* @data 2023-10-19 10:37*//**** 主要实现2个方法 run() 和 cancel()*/
public class FlinkSource_Custom implements SourceFunction<Student> {// 声明一个布尔变量,作为控制数据生成的标识位private Boolean running = true;@Overridepublic void run(SourceContext<Student> sourceContext) throws Exception {Random random = new Random(); // 在指定的数据集中随机选取数据String[] name = {"Mary", "Alice", "Bob", "Cary"};int[] sex = {1,2};int age = 0;while (running) {sourceContext.collect(new Student(name[random.nextInt(name.length)],sex[random.nextInt(sex.length)],random.nextInt(100)));// 隔 1 秒生成一个点击事件,方便观测Thread.sleep(1000);}}@Overridepublic void cancel() {running = false;}
}
2.编写主程序
package com.qiyu;import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;/*** @author MR.Liu* @version 1.0* @data 2023-10-19 10:46*/
public class FlinkSource_Custom2 {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);
//有了自定义的 source function,调用 addSource 方法DataStreamSource<Student> stream = env.addSource(new FlinkSource_Custom());stream.print("SourceCustom");env.execute();}
}
运行主程序,运行结果:
SourceCustom> Student{name='Mary', age=1, sex=46}
SourceCustom> Student{name='Cary', age=2, sex=52}
SourceCustom> Student{name='Bob', age=1, sex=14}
SourceCustom> Student{name='Alice', age=1, sex=84}
SourceCustom> Student{name='Alice', age=2, sex=82}
SourceCustom> Student{name='Cary', age=1, sex=28}.............
相关文章:
Flink学习之旅:(三)Flink源算子(数据源)
1.Flink数据源 Flink可以从各种数据源获取数据,然后构建DataStream 进行处理转换。source就是整个数据处理程序的输入端。 数据集合数据文件Socket数据kafka数据自定义Source 2.案例 2.1.从集合中获取数据 创建 FlinkSource_List 类,再创建个 Student 类…...

SQL INSERT INTO 语句(在表中插入)
SQL INSERT INTO 语句 INSERT INTO 语句用于向表中插入新的数据行。 SQL INSERT INTO 语法 INSERT INTO 语句可以用两种形式编写。 第一个表单没有指定要插入数据的列的名称,只提供要插入的值,即可添加一行新的数据: INSERT INTO table_n…...
2023年最佳项目管理软件排行榜揭晓!
根据网络数据调查结果显示,今年有77%的组织将效率列为优先事项,而82%的领导人确认投资于新的项目管理和工作管理方案以提高效能。然而随着对价值的重新关注,选择适合的工程项目管理软件变得比以往任何时候都更加重要。好消息是通过对39个主要…...
【java】A卷+B卷)
华为OD DNA序列(100分)【java】A卷+B卷
华为OD统一考试A卷B卷 新题库说明 你收到的链接上面会标注A卷还是B卷。目前大部分收到的都是B卷。 B卷对应20022部分考题以及新出的题目,A卷对应的是新出的题目。 我将持续更新最新题目 获取更多免费题目可前往夸克网盘下载,请点击以下链接进入ÿ…...
idea2023配置maven
看过【黑马程序员Maven全套教程,maven项目管理从基础到高级,Java项目开发必会管理工具maven】https://www.bilibili.com/video/BV1Ah411S7ZE?p9&vd_sourceedf9d91e5a0a27db51e3d6d4b9400637 配置的,前提要素配置也在这个课程里有啦&…...
Python 文件打包成可执行文件
打包 要将Python脚本打包成可执行文件,常见的做法是使用PyInstaller或cx_Freeze工具。下面是使用PyInstaller的基本步骤: 使用conda安装pyinstaller (建议) conda install -c conda-forge pyinstaller上面的命令从conda-forge通…...
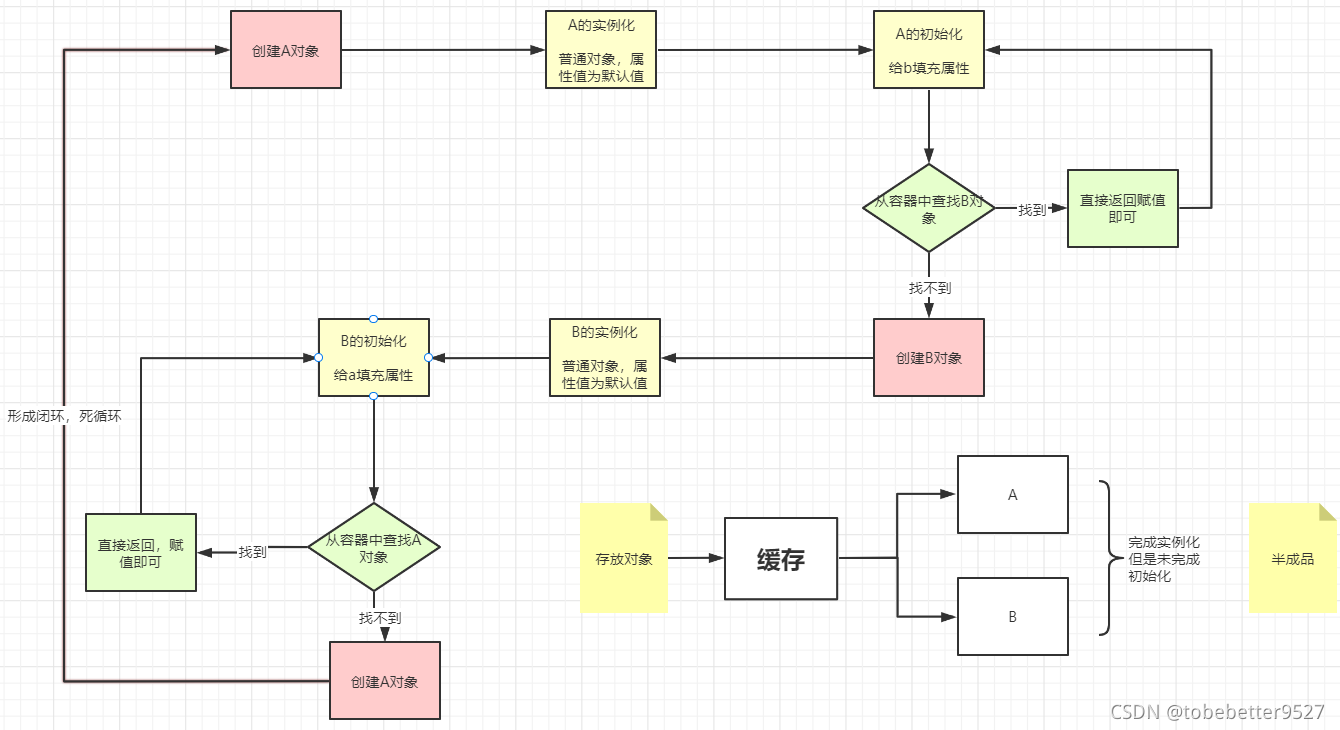
14-bean创建流程5-初始化和循环依赖
文章目录 1.初始化和循环依赖1.1 初始化步骤1.2 循环依赖问题的产生1.3 如何解决循环依赖问题1.4 解决循环依赖二级缓存即可完成,为什么需要三级缓存1.5循环依赖有时报错1.初始化和循环依赖 1.1 初始化步骤 填充属性执行Aware执行BeanPostProcessor的postProcessBeforeInitia…...

drawio模板以及示例
drawio都能做那些事情和模板示例 你可以使用drawio,并使用drawio提供的扩展模板库和大量的形状库,针对很多不同的工业领域创建不同类型的图表。 针对如下的内容中的所有的图,均可以下载源文件并导入到drawio中再次编辑(供学习者…...

YOLOv8改进实战 | 更换主干网络Backbone(四)之轻量化模型MobileNetV3
前言 轻量化网络设计是一种针对移动设备等资源受限环境的深度学习模型设计方法。下面是一些常见的轻量化网络设计方法: 网络剪枝:移除神经网络中冗余的连接和参数,以达到模型压缩和加速的目的。分组卷积:将卷积操作分解为若干个较小的卷积操作,并将它们分别作用于输入的不…...
22-数据结构-内部排序-选择排序
简介:每一趟选择最小或最大的一个,排在前面或后面。主要右简单选择排序和堆排序 一、简单选择排序 1.1简介: 每趟选择最小的,放在前面,一次类推,代码思想:两个循环,外循环是趟数&a…...

utf8和utf8mb4字符集
柠檬(图片)派 有个玩家取了个名字,名字里带柠檬的图片。在发邮件的时候,要把玩家名字拼装成json格式,存储在mysql表中。 C代码和python代码处理都是正常的,但是调用pymysql的接口,执行sql写入到mysql时。 pymysql会报错…...

前端学成在线项目详细解析一
学成在线项目 01-项目目录 网站根目录是指存放网站的第一层文件夹,内部包含当前网站的所有素材,包含 HTML、CSS、图片、JavaScript等等。 首页引入CSS文件 <!-- 顺序要求:先清除再设置 --> <link rel"stylesheet" hre…...
Redis之UV统计
HyperLogLog 首先我们搞懂两个概念: UV:全称Unique Visitor,也叫独立访客量,是指通过互联网访问、浏览这个网页的自然人。1天内同一个用户多次访问该网站,只记录1次。PV:全称Page View,也叫页…...

sqlserver数据库,创建作业,定时执行sql
1 在业务中涉及到定时操作数据表时,可以设置定时作业。先创建一个存储过程,实现要定时执行的业务。 USE [MyDB] go create procedure [PROC_MYPROCEDURE] name varchar(50), score int, remark varchar(50) AS BEGIN insert into [mytable] values (n…...

计算机缺失d3dcompiler_47.dll解决方案,如何修复电脑缺失d3d文件
在计算机系统中,DLL文件(动态链接库)是一种重要的共享库,它包含了可被多个程序使用的代码和数据。然而,当某些DLL文件丢失或损坏时,可能会导致程序无法正常运行。本文将介绍四种解决D3DCompiler_47.dll缺失…...
计算机视觉开源代码汇总
1.【基础网络架构】Regularization of polynomial networks for image recognition 论文地址:https://arxiv.org/pdf/2303.13896.pdf 开源代码:https://github.com/grigorisg9gr/regularized_polynomials 2.【目标检测:域自适应】2PCNet: Two-Phase Cons…...

【C语言必知必会 | 子系列第六篇】深入剖析循环结构(2)
引言 C语言是一门面向过程的、抽象化的通用程序设计语言,广泛应用于底层开发。它在编程语言中具有举足轻重的地位。 此文为【C语言必知必会】第六篇,基于进行C语言循环结构的编程题专项练习,结合专题优质题目,带领读者从0开始&…...
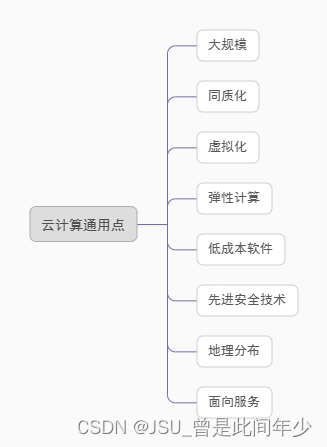
华为ICT——云计算基础知识、计算类技术听课笔记
ICT(information and communications technology):信息与通信技术 传统IT架构缺点 TCO:总体拥有成本 云计算模式 云计算价值 云计算通用点 虚拟化技术:将单台物理服务器虚拟为多台虚拟机使用,多台虚拟机共享物理服务器硬件资源。 虚拟化本质…...

PyTorch入门教学——TensorBoard使用
1、TensorBoard简介 TensorBoard是Google开发的一个机器学习可视化工具。其主要用于记录机器学习过程,例如: 记录损失变化、准确率变化等记录图片变化、语音变化、文本变化等。例如在做GAN时,可以过一段时间记录一张生成的图片绘制模型 2、…...

03 里氏替换原则
官方定义: 里氏替换原则(Liskov Substitution Principle,LSP)是由麻省理工学院计算机科学系教授芭芭拉利斯科夫于 1987 年在“面向对象技术的高峰会议”(OOPSLA)上发表的一篇论文《数据抽象和层次》&#…...

XUnity自动翻译器:打破语言壁垒,让Unity游戏无障碍畅玩
XUnity自动翻译器:打破语言壁垒,让Unity游戏无障碍畅玩 【免费下载链接】XUnity.AutoTranslator 项目地址: https://gitcode.com/gh_mirrors/xu/XUnity.AutoTranslator 你是否曾因语言障碍而错过心仪的游戏?面对精美的日式RPG、精彩的…...

【中等】矩阵的最小路径和-Java:经典动态规划方法
分享一个大牛的人工智能教程。零基础!通俗易懂!风趣幽默!希望你也加入到人工智能的队伍中来!请轻击人工智能教程大家好!欢迎来到我的网站! 人工智能被认为是一种拯救世界、终结世界的技术。毋庸置疑&#x…...

GLM-4.1V-9B-Base与C语言交互:通过本地API实现轻量级集成
GLM-4.1V-9B-Base与C语言交互:通过本地API实现轻量级集成 1. 为什么要在C项目中集成AI能力? 在嵌入式系统和性能敏感型应用中,C语言仍然是无可争议的王者。但传统AI框架往往依赖Python环境,这在资源受限场景下会带来诸多挑战&am…...

基于LangChain与RAG技术构建本地文档智能问答系统
1. 项目概述与核心价值 最近在折腾如何让ChatGPT这类大语言模型能“读懂”我自己的文档,比如本地的一堆技术笔记、PDF报告或者会议纪要。直接复制粘贴给ChatGPT的Web界面,不仅麻烦,而且有长度限制,更别提隐私问题了。我需要一个能…...

神经网络模型容量控制:节点数与层数优化指南
1. 神经网络模型容量控制的核心逻辑在深度学习实践中,模型容量(Model Capacity)直接决定了神经网络的学习能力和泛化表现。就像给不同体型的人挑选衣服——太紧会限制行动(欠拟合),太松又显得臃肿ÿ…...

AWS CDK构造库实战:快速构建生成式AI应用基础设施
1. 项目概述:当CDK遇上生成式AI 如果你正在用AWS构建生成式AI应用,并且已经厌倦了在控制台里手动点击、配置各种服务,或者在CloudFormation模板里反复调试那些复杂的IAM权限和网络配置,那么 awslabs/generative-ai-cdk-construc…...

ARM1020E处理器勘误与硬件调试实战指南
1. ARM1020E Rev1处理器勘误深度解析作为一名长期从事ARM架构开发的工程师,我深知处理器勘误(Errata)对系统稳定性的关键影响。今天我将结合ARM1020E Rev1的实际案例,分享三类勘误的处理经验,特别是硬件调试中的典型问…...

【Linux从入门到精通】第22篇:Shell变量与数据类型——数字与字符串处理
目录 一、引言:变量不只是“存个值” 二、环境变量 vs 局部变量:作用域的秘密 2.1 用实验理解差别 2.2 什么时候用哪种? 2.3 查看当前所有环境变量 2.4 持久化环境变量 三、只读变量与常量保护 3.1 readonly:让变量变成“常…...

2025年MLOps工程师核心能力与实战路线
1. 2025年MLOps精通的战略路径解析过去三年间,我主导过七个不同规模的MLOps落地项目,从金融风控到工业质检,最深的体会是:MLOps工程师正在从"会调参的码农"转变为"懂业务的架构师"。2025年的MLOps知识图谱将呈…...

基于CrewAI与AKShare构建A股多智能体分析系统
1. 项目概述:一个为A股市场量身定制的多智能体分析引擎最近在折腾一个挺有意思的项目,叫“A股智能分析系统”。简单来说,它不是一个简单的数据爬虫或者指标计算器,而是一个由多个专业化AI角色(Agent)组成的…...