使用自定义 PyTorch 运算符优化深度学习数据输入管道
在这篇文章[1]中,我们讨论 PyTorch 对创建自定义运算符的支持,并演示它如何帮助我们解决数据输入管道的性能瓶颈、加速深度学习工作负载并降低训练成本。
构建 PyTorch 扩展
PyTorch 提供了多种创建自定义操作的方法,包括使用自定义模块和/或函数扩展 torch.nn。在这篇文章中,我们感兴趣的是 PyTorch 对集成定制 C++ 代码的支持。此功能很重要,因为某些操作在 C++ 中比在 Python 中更有效和/或更容易地实现。使用指定的 PyTorch 实用程序(例如 CppExtension),可以轻松地将这些操作作为 PyTorch 的“扩展”包含在内,而无需拉取和重新编译整个 PyTorch 代码库。由于我们对这篇文章的兴趣是加速基于 CPU 的数据预处理管道,因此我们只需使用 C++ 扩展即可,不需要 CUDA 代码。
玩具示例
在我们之前的文章中,我们定义了一个数据输入管道,首先解码 533x800 JPEG 图像,然后提取随机的 256x256 裁剪,经过一些额外的转换后,将其输入训练循环。我们使用 PyTorch Profiler 和 TensorBoard 来测量与从文件加载图像相关的时间,并承认解码的浪费。为了完整起见,我们复制以下代码:
import numpy as np
from PIL import Image
from torchvision.datasets.vision import VisionDataset
input_img_size = [533, 800]
img_size = 256
class FakeDataset(VisionDataset):
def __init__(self, transform):
super().__init__(root=None, transform=transform)
size = 10000
self.img_files = [f'{i}.jpg' for i in range(size)]
self.targets = np.random.randint(low=0,high=num_classes,
size=(size),dtype=np.uint8).tolist()
def __getitem__(self, index):
img_file, target = self.img_files[index], self.targets[index]
img = Image.open(img_file)
if self.transform is not None:
img = self.transform(img)
return img, target
def __len__(self):
return len(self.img_files)
transform = T.Compose(
[T.PILToTensor(),
T.RandomCrop(img_size),
RandomMask(),
ConvertColor(),
Scale()])
据推测,如果我们能够仅解码我们感兴趣的作物,我们的管道会运行得更快。不幸的是,截至撰写本文时,PyTorch 不包含支持此功能的函数。然而,使用自定义操作创建工具,我们可以定义并实现我们自己的函数!
自定义 JPEG 图像解码和裁剪函数
libjpeg-turbo 库是一个 JPEG 图像编解码器,与 libjpeg 相比,它包含许多增强和优化。特别是,libjpeg-turbo 包含许多函数,使我们能够仅解码图像中的预定义裁剪,例如 jpeg_skip_scanlines 和 jpeg_crop_scanline。如果您在 conda 环境中运行,可以使用以下命令进行安装:
conda install -c conda-forge libjpeg-turbo
请注意,libjpeg-turbo 已预安装在我们将在下面的实验中使用的官方 AWS PyTorch 2.0 深度学习 Docker 映像中。 在下面的代码块中,我们修改了torchvision 0.15的decode_jpeg函数,以从输入的JPEG编码图像中解码并返回所请求的裁剪。
torch::Tensor decode_and_crop_jpeg(const torch::Tensor& data,
unsigned int crop_y,
unsigned int crop_x,
unsigned int crop_height,
unsigned int crop_width) {
struct jpeg_decompress_struct cinfo;
struct torch_jpeg_error_mgr jerr;
auto datap = data.data_ptr<uint8_t>();
// Setup decompression structure
cinfo.err = jpeg_std_error(&jerr.pub);
jerr.pub.error_exit = torch_jpeg_error_exit;
/* Establish the setjmp return context for my_error_exit to use. */
setjmp(jerr.setjmp_buffer);
jpeg_create_decompress(&cinfo);
torch_jpeg_set_source_mgr(&cinfo, datap, data.numel());
// read info from header.
jpeg_read_header(&cinfo, TRUE);
int channels = cinfo.num_components;
jpeg_start_decompress(&cinfo);
int stride = crop_width * channels;
auto tensor =
torch::empty({int64_t(crop_height), int64_t(crop_width), channels},
torch::kU8);
auto ptr = tensor.data_ptr<uint8_t>();
unsigned int update_width = crop_width;
jpeg_crop_scanline(&cinfo, &crop_x, &update_width);
jpeg_skip_scanlines(&cinfo, crop_y);
const int offset = (cinfo.output_width - crop_width) * channels;
uint8_t* temp = nullptr;
if(offset > 0) temp = new uint8_t[cinfo.output_width * channels];
while (cinfo.output_scanline < crop_y + crop_height) {
/* jpeg_read_scanlines expects an array of pointers to scanlines.
* Here the array is only one element long, but you could ask for
* more than one scanline at a time if that's more convenient.
*/
if(offset>0){
jpeg_read_scanlines(&cinfo, &temp, 1);
memcpy(ptr, temp + offset, stride);
}
else
jpeg_read_scanlines(&cinfo, &ptr, 1);
ptr += stride;
}
if(offset > 0){
delete[] temp;
temp = nullptr;
}
if (cinfo.output_scanline < cinfo.output_height) {
// Skip the rest of scanlines, required by jpeg_destroy_decompress.
jpeg_skip_scanlines(&cinfo,
cinfo.output_height - crop_y - crop_height);
}
jpeg_finish_decompress(&cinfo);
jpeg_destroy_decompress(&cinfo);
return tensor.permute({2, 0, 1});
}
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("decode_and_crop_jpeg",&decode_and_crop_jpeg,"decode_and_crop_jpeg");
}
在下一节中,我们将按照 PyTorch 教程中的步骤将其转换为可在预处理管道中使用的 PyTorch 运算符。
部署 PyTorch 扩展
如 PyTorch 教程中所述,部署自定义运算符有不同的方法。您的部署设计中可能需要考虑许多因素。以下是我们认为重要的一些示例:
-
及时编译:为了确保我们的 C++ 扩展是针对我们训练时使用的同一版本的 PyTorch 进行编译的,我们对部署脚本进行了编程,以便在训练环境中进行训练之前编译代码。 -
多进程支持:部署脚本必须支持从多个进程(例如,多个 DataLoader 工作线程)加载我们的 C++ 扩展的可能性。 -
托管培训支持:由于我们经常在托管培训环境(例如 Amazon SageMaker)中进行培训,因此我们要求部署脚本支持此选项。 (有关定制托管培训环境主题的更多信息,请参阅此处。)
在下面的代码块中,我们定义了一个简单的 setup.py 脚本,用于编译和安装我们的自定义函数,如此处所述。
from setuptools import setup
from torch.utils import cpp_extension
setup(name='decode_and_crop_jpeg',
ext_modules=[cpp_extension.CppExtension('decode_and_crop_jpeg',
['decode_and_crop_jpeg.cpp'],
libraries=['jpeg'])],
cmdclass={'build_ext': cpp_extension.BuildExtension})
我们将 C++ 文件和 setup.py 脚本放在名为 custom_op 的文件夹中,并定义一个 「init」.py 以确保安装脚本由单个进程运行一次:
import os
import sys
import subprocess
import shlex
import filelock
p_dir = os.path.dirname(__file__)
with filelock.FileLock(os.path.join(pkg_dir, f".lock")):
try:
from custom_op.decode_and_crop_jpeg import decode_and_crop_jpeg
except ImportError:
install_cmd = f"{sys.executable} setup.py build_ext --inplace"
subprocess.run(shlex.split(install_cmd), capture_output=True, cwd=p_dir)
from custom_op.decode_and_crop_jpeg import decode_and_crop_jpeg
最后,我们修改数据输入管道以使用新创建的自定义函数:
from torchvision.datasets.vision import VisionDataset
input_img_size = [533, 800]
class FakeDataset(VisionDataset):
def __init__(self, transform):
super().__init__(root=None, transform=transform)
size = 10000
self.img_files = [f'{i}.jpg' for i in range(size)]
self.targets = np.random.randint(low=0,high=num_classes,
size=(size),dtype=np.uint8).tolist()
def __getitem__(self, index):
img_file, target = self.img_files[index], self.targets[index]
with torch.profiler.record_function('decode_and_crop_jpeg'):
import random
from custom_op.decode_and_crop_jpeg import decode_and_crop_jpeg
with open(img_file, 'rb') as f:
x = torch.frombuffer(f.read(), dtype=torch.uint8)
h_offset = random.randint(0, input_img_size[0] - img_size)
w_offset = random.randint(0, input_img_size[1] - img_size)
img = decode_and_crop_jpeg(x, h_offset, w_offset,
img_size, img_size)
if self.transform is not None:
img = self.transform(img)
return img, target
def __len__(self):
return len(self.img_files)
transform = T.Compose(
[RandomMask(),
ConvertColor(),
Scale()])
结果
经过我们描述的优化后,我们的步长时间从 0.72 秒降至 0.48 秒,性能提升了 50%!当然,我们优化的影响与原始 JPEG 图像的大小和我们选择的裁剪大小直接相关。
总结
数据预处理管道中的瓶颈很常见,可能会导致 GPU 饥饿并减慢训练速度。考虑到潜在的成本影响,您必须拥有各种工具和技术来分析和解决这些问题。在这篇文章中,我们回顾了通过创建自定义 C++ PyTorch 扩展来优化数据输入管道的选项,展示了其易用性,并展示了其潜在影响。当然,这种优化机制的潜在收益会根据项目和性能瓶颈的细节而有很大差异。
Reference
Source: https://towardsdatascience.com/how-to-optimize-your-dl-data-input-pipeline-with-a-custom-pytorch-operator-7f8ea2da5206
本文由 mdnice 多平台发布
相关文章:

使用自定义 PyTorch 运算符优化深度学习数据输入管道
在这篇文章[1]中,我们讨论 PyTorch 对创建自定义运算符的支持,并演示它如何帮助我们解决数据输入管道的性能瓶颈、加速深度学习工作负载并降低训练成本。 构建 PyTorch 扩展 PyTorch 提供了多种创建自定义操作的方法,包括使用自定义模块和/或…...

瑞芯微RKNN开发·yolov5
官方预训练模型转换 下载yolov5-v6.0分支源码解压到本地,并配置基础运行环境。下载官方预训练模型 yolov5n.ptyolov5s.ptyolov5m.pt… 进入yolov5-6.0目录下,新建文件夹weights,并将步骤2中下载的权重文件放进去。修改models/yolo.py文件 …...

Flutter之Widget生命周期
目录 初始化构造函数initStatedidChangeDependencies 运行时builddidUpdateWidget 组件移除deactivatedisposereassemble 函数生命周期说明:实际场景App生命周期 前言:生命周期是一个组件加载到卸载的整个周期,熟悉生命周期可以让我们在合适的…...
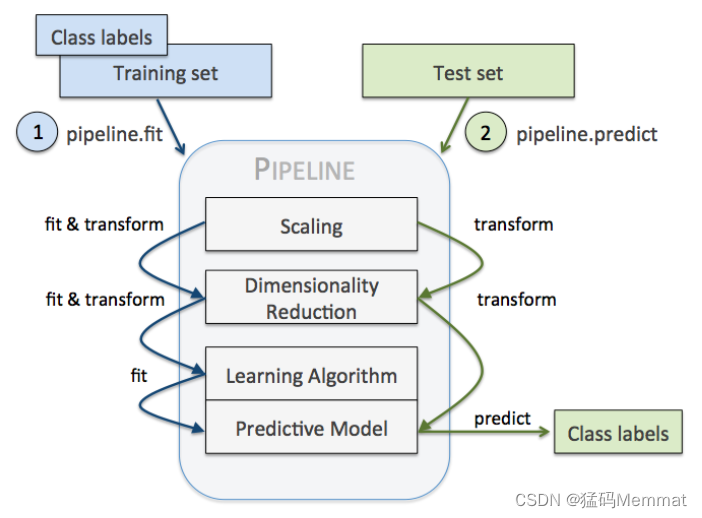
机器学习tip:sklearn中的pipeline
文章目录 1 加载数据集2 构思算法的流程3 Pipeline执行流程的分析ReferenceStatement 一个典型的机器学习构建包含若干个过程 源数据ETL数据预处理特征选取模型训练与验证 一个典型的机器学习构建包含若干个过程 以上四个步骤可以抽象为一个包括多个步骤的流水线式工作&…...
Jmeter项目实战
一,性能测试流程 性能需求分析 性能方案设计 业务建模 脚本优化 执行测试 收集性能数据 结果分析 性能测试报告 二,性能需求分析 项目管理系统业务:登录 注册 搜索(一般最核心的就是登陆,大多只对登录做压测&a…...
Spring学习笔记注解式开发(3)
Spring学习笔记(3) 一、Bean的注解式开发1.1、注解开发的基本和Component1.2 注解式开发8.3、Component的三个衍生注解 二、Bean依赖注入注解开发2.1、依赖注入相关注解2.2、Autowired扩展 三、非自定义Bean注解开发四、Bean配置类的注解开发五、Spring注…...
vue3后台管理框架之技术栈
vue3全家桶技术 基础构建: vue3vite4TypeScript 代码格式 : eslintprettystylelint git生命周期钩子: husky css预处理器: sass ui库: element-plus 模拟数据: mock 网络请求: axios 路由: vue…...
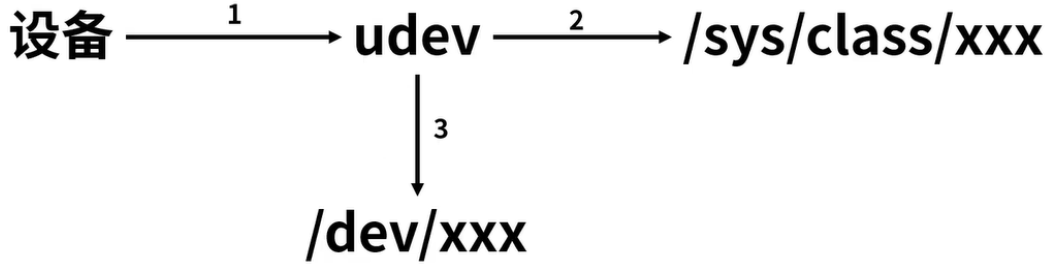
7、Linux驱动开发:设备-自动创建设备节点
目录 🍅点击这里查看所有博文 随着自己工作的进行,接触到的技术栈也越来越多。给我一个很直观的感受就是,某一项技术/经验在刚开始接触的时候都记得很清楚。往往过了几个月都会忘记的差不多了,只有经常会用到的东西才有可能真正记…...
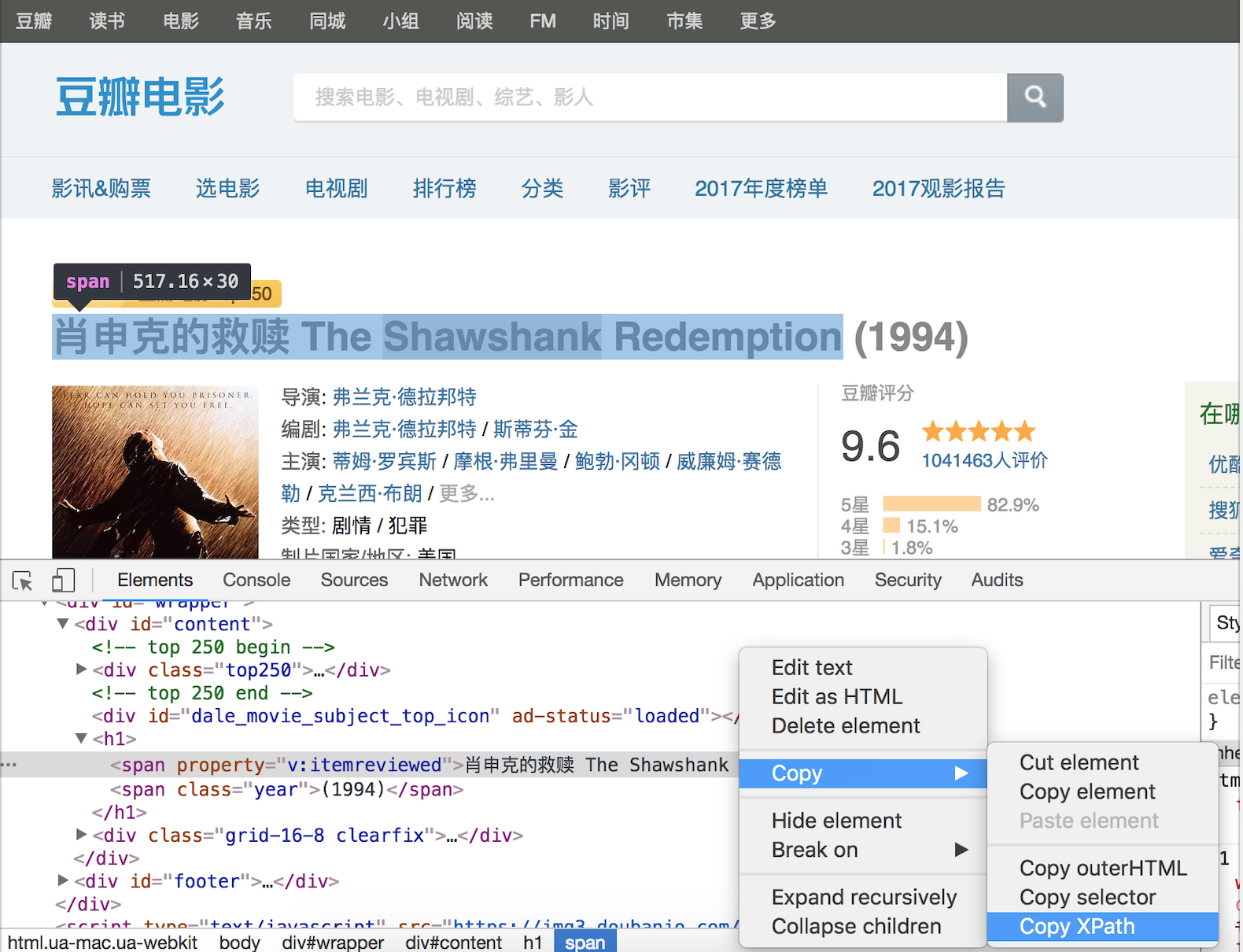
用Python解析HTML页面
用Python解析HTML页面 文章目录 用Python解析HTML页面HTML 页面的结构XPath 解析CSS 选择器解析简单的总结 在前面的课程中,我们讲到了使用 request三方库获取网络资源,还介绍了一些前端的基础知识。接下来,我们继续探索如何解析 HTML 代码&…...

官方认证:研发效能(DevOps)工程师职业技术认证
培养端到端的研发效能人才 为贯彻落实《关于深化人才发展体制机制改革的意见》,推动实施人才强国战略,促进专业技术人员提升职业素养、补充新知识新技能,实现人力资源深度开发,推动经济社会全面发展,根据《中华人民共…...
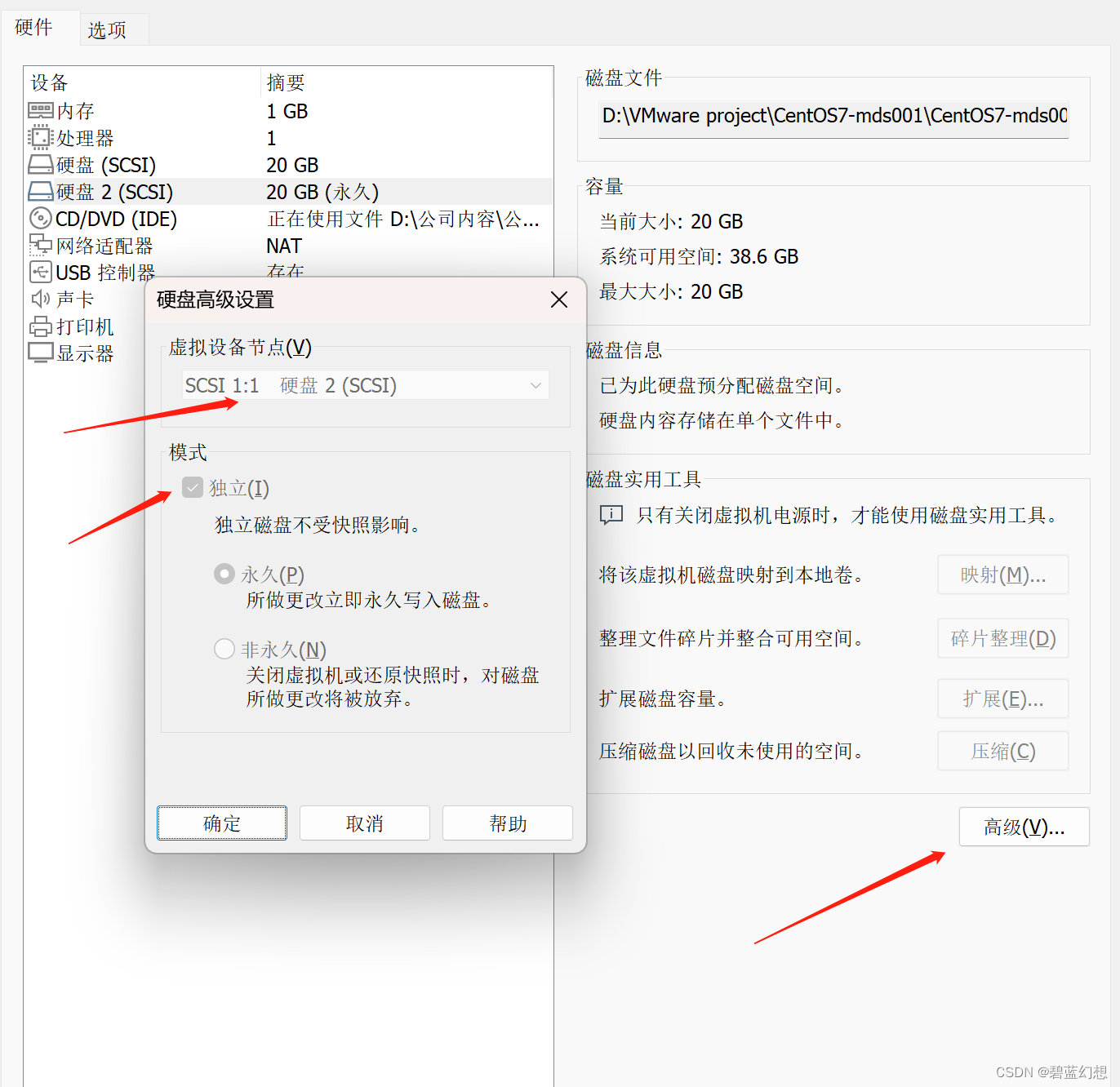
搭建GPFS双机集群
1.环境说明: 系统主机名IP地址内存添加共享磁盘大小Centos7.9gpfs1192.168.10.1012G20GCentos7.9gpfs2192.168.10.1022G20G 2.环境配置: 配置网路IP地址: 修改网卡会话: nmcli connection modify ipv4.method manual ipv4.addre…...

【试题032】C语言关系运算符例题
1.题目:设int a2,b4,c5;,则表达式ab!c>b>a的值为? 2.代码分析: //设int a2,b4,c5;,则表达式ab!c>b>a的值为?int a 2, b 4, c 5;printf("%d\n", (a b ! c > b > a));//分析ÿ…...

系列四、FileReader和FileWriter
一、概述 FileReader 和 FileWriter 是字符流,按照字符来操作IO。 1.1、继承体系 二、FileReader常用方法 new FileReader(File/String)# 每次读取单个字符就返回,如果读取到文件末尾返回-1 read()# 批量读取多个字符到数组,返回读取的字节…...
【C++面向对象】2.构造函数、析构函数
文章目录 【 1. 构造函数 】1.1 带参构造函数--传入数据1.2 无参构造函数--不传入数据1.3 实例1.4 拷贝构造函数 【 2. 析构函数 】 【 1. 构造函数 】 类的构造函数是类的一种特殊的成员函数,它会 在每次创建类的新对象时执行。 构造函数的名称与类的名称是完全相同…...
uniapp:使用subNVue原生子窗体在map上层添加自定义组件
我们想要在地图上层添加自定义组件,比如一个数据提示框,点一下会展开,再点一下收起,在h5段显示正常,但是到app端真机测试发现组件显示不出来,这是因为map是内置原生组件,层级最高,自…...
Flutter开发GridView控件详解
GridView跟ListView很类似,Listview主要以列表形式显示数据,GridView则是以网格形式显示数据,掌握ListView使用方法后,会很轻松的掌握GridView的使用方法。 在某种界面设计中,如果需要很多个类似的控件整齐的排列&…...

Vue3.0里为什么要用 Proxy API 替代 defineProperty API ?
一、Object.defineProperty 定义:Object.defineProperty() 方法会直接在一个对象上定义一个新属性,或者修改一个对象的现有属性,并返回此对象 为什么能实现响应式 通过defineProperty 两个属性,get及set get 属性的 getter 函…...

pytest利用request fixture实现个性化测试需求详解
这篇文章主要为大家详细介绍了pytest如何利用request fixture实现个性化测试需求,文中的示例代码讲解详细,感兴趣的小伙伴可以跟随小编一起了解一下− 前言 在深入理解 pytest-repeat 插件的工作原理这篇文章中,我们看到pytest_repeat源码中有这样一段 import pyt…...
 时间插入、删除和获取随机元素)
算法练习16——O(1) 时间插入、删除和获取随机元素
LeetCode 380 O(1) 时间插入、删除和获取随机元素 实现RandomizedSet 类: RandomizedSet() 初始化 RandomizedSet 对象 bool insert(int val) 当元素 val 不存在时,向集合中插入该项,并返回 true ;否则,返回 false 。 …...

实时数据更新与Apollo:探索GraphQL订阅
前言 「作者主页」:雪碧有白泡泡 「个人网站」:雪碧的个人网站 「推荐专栏」: ★java一站式服务 ★ ★ React从入门到精通★ ★前端炫酷代码分享 ★ ★ 从0到英雄,vue成神之路★ ★ uniapp-从构建到提升★ ★ 从0到英雄ÿ…...
)
从5V到20V:手把手拆解一个PD快充头的‘讨价还价’逻辑(Power Negotiation实战)
从5V到20V:手把手拆解一个PD快充头的‘讨价还价’逻辑 当你把Type-C充电线插入MacBook的瞬间,屏幕右上角的充电图标会经历一场静默的"闪电谈判"——充电器与电脑在毫秒间完成电压、电流和功率的博弈。这场对话的幕后推手,正是USB P…...

MCP SQL Bridge:为AI助手安全连接本地数据库,实现智能数据查询
1. 项目概述:为你的AI助手装上数据库的“眼睛”如果你和我一样,日常开发中有一半的时间都在和数据库打交道,那你肯定也经历过这样的场景:想快速查一下某个表的结构,或者写个稍微复杂点的联表查询,都得在IDE…...

如何快速使用Mem Reduct:面向Windows用户的终极内存管理完整指南
如何快速使用Mem Reduct:面向Windows用户的终极内存管理完整指南 【免费下载链接】memreduct Lightweight real-time memory management application to monitor and clean system memory on your computer. 项目地址: https://gitcode.com/gh_mirrors/me/memredu…...

嵌入式开发环境搭建第一步:在VMware中为Ubuntu 22.04.3 LTS做这些关键初始配置
嵌入式开发环境搭建第一步:VMware中Ubuntu 22.04.3 LTS的10项关键配置 当你刚完成Ubuntu 22.04.3 LTS的基础安装,系统就像毛坯房——有基本框架但远未达到"拎包入住"的开发标准。作为嵌入式开发者,我们需要将这个"裸系统&quo…...

终极Win11优化指南:PowerShell脚本让系统性能飙升40%的秘密
终极Win11优化指南:PowerShell脚本让系统性能飙升40%的秘密 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter a…...

3分钟掌握城通网盘高速下载:开源工具ctfileGet完全指南
3分钟掌握城通网盘高速下载:开源工具ctfileGet完全指南 【免费下载链接】ctfileGet 获取城通网盘一次性直连地址 项目地址: https://gitcode.com/gh_mirrors/ct/ctfileGet 你是否曾经面对城通网盘的下载进度条感到绝望?当网络带宽被限制在每秒几十…...

Windows也能拥有高效终端:WSL2 + Windows Terminal配置
Windows也能拥有高效终端:WSL2 Windows Terminal配置 长期以来,Windows的终端体验一直被开发者诟病,尤其是与Linux和macOS相比。随着微软推出WSL2(Windows Subsystem for Linux 2)和Windows Terminal,这一…...

OpCore Simplify:三步构建完美黑苹果OpenCore EFI的终极指南
OpCore Simplify:三步构建完美黑苹果OpenCore EFI的终极指南 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 对于渴望在PC硬件上体验macOS…...

旅行拼团信用程序,团员爽约记录上链,降低组团风险,方便筛选靠谱伙伴。
旅行拼团信用上链系统设计方案一、实际应用场景描述户外徒步俱乐部“山野行者”定期组织跨省长线徒步(如川西环线、冈仁波齐转山),需提前30天统计人数并预订包车、高山协作及住宿。近一年出现多次“临出发前48小时内无故退团”事件࿰…...

如何在3分钟内掌握VideoDownloadHelper:网页视频下载的终极解决方案
如何在3分钟内掌握VideoDownloadHelper:网页视频下载的终极解决方案 【免费下载链接】VideoDownloadHelper Chrome Extension to Help Download Video for Some Video Sites. 项目地址: https://gitcode.com/gh_mirrors/vi/VideoDownloadHelper VideoDownloa…...