【文献copilot】调用文心一言api对论文逐段总结
文献copilot:调用文心一言api对论文逐段总结
当我读文献的时候,感觉读得太慢了,看翻译软件翻译的又觉得翻译的不好。于是我就写了个程序辅助我读文献,它可以逐段总结,输出格式是:原文+一句话总结+分段总结,每一段间用分割线分割。下面给大家看看输出结果。


输入
一个.txt文件,这个直接从论文的网页上复制粘贴到记事本里就行。我平常看nature的期刊比较多,nature的绝大多数都可以直接复制,很方便。一个小建议是鼠标通过导航栏,找到reference,然后自下而上选择一直到标题,复制粘贴即可。
大家可以用这个论文练练手:https://www.nature.com/articles/s41587-022-01448-2。
这种方法其实没有那么优雅和便捷,我也想过用爬虫直接爬取,不过一是因为每个期刊网站不一样,不太方便;二是因为爬虫其实会更慢一些。我还想过通过pdf直接转txt或者直接用pdf来进行总结,这个可行,因为像chatdoc就做成功了,而且非常好(不过chatdoc也不能自动化地逐段总结,并且收费,个性化程度不高),但是难度较大,并且我觉得没太大必要,这种方法已经满足我的需求了。
运行方式
首先把输入文件和输出文件的路径确定了:
- filepath:论文.txt所在路径(这个斜杠/,不是这个\)
- outpath:输出路径,可以和filepath一样
大家还需要配置一下文心一言的API_KEY、SECRET_KEY,这个网上教程很多。
import json
import os
import sys
import requests
from tqdm import tqdm
from md_translator import *# 下面两行是不同的运行方式
filename = sys.argv[1] # 这是用命令行的方式
# 这是在编辑器运行的方式
# filename = "论文名字.txt"filepath = "D:/"
outpath = "D:/"# 文心一言的API_KEY、SECRET_KEY
API_KEY = "你的API_KEY"
SECRET_KEY = "你的SECRET_KEY"
编译器内运行
赋值filename为对应的文件名就行,要带后缀。
filename = "论文名字.txt"
然后直接运行即可,会显示一个进度条,结束时会自动打开输出目录。

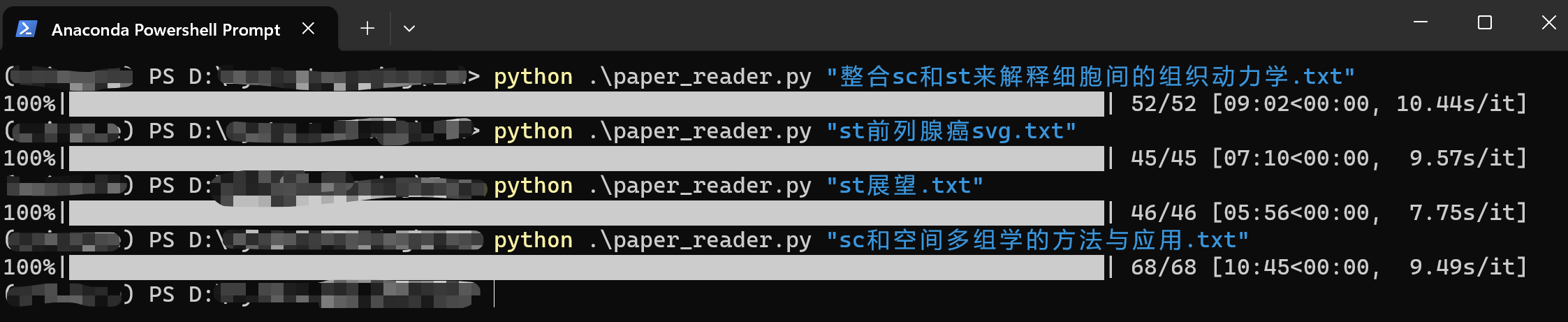
命令行运行
编译器运行比较麻烦,每次得改文件名,还得点击运行,命令行就方便多了。
直接进到程序的目录,然后改好环境,第二个参数改为文件名即可:
python .\paper_reader.py "论文名字.txt"
输出结果
会输出一个名为总结-论文名字.md的文件。
第一行大标题,论文名字,接着用分割线来分割每一段,上面是英文,下面是用中文的一句话总结和分段总结。
源代码
paper_reader.py
import json
import os
import sys
import requests
from tqdm import tqdm
from md_translator import *# 下面两行是不同的运行方式
filename = sys.argv[1] # 这是用命令行的方式
# 这是在编辑器运行的方式
# filename = "论文名字.txt"filepath = "D:/"
outpath = "D:/"# 文心一言的API_KEY、SECRET_KEY
API_KEY = "你的API_KEY"
SECRET_KEY = "你的SECRET_KEY"f = open(outpath + '总结-' + filename.split('.')[0] + '.md', 'w', encoding='utf-8')
old_out = sys.stdout
sys.stdout = fdef ask_Q(question):url = "https://aip.baidubce.com/rpc/2.0/ai_custom/v1/wenxinworkshop/chat/completions?access_token=" + get_access_token()payload = json.dumps({"messages": [{"role": "user","content": question}]})headers = {'Content-Type': 'application/json'}response = requests.request("POST", url, headers=headers, data=payload)return response# print(response.text)def get_access_token():"""使用 AK,SK 生成鉴权签名(Access Token):return: access_token,或是None(如果错误)"""url = "https://aip.baidubce.com/oauth/2.0/token"params = {"grant_type": "client_credentials", "client_id": API_KEY, "client_secret": SECRET_KEY}return str(requests.post(url, params=params).json().get("access_token"))# %%
md_origin = md_df(filepath + filename)# %%
import copymd_res = copy.deepcopy(md_origin)
for i_zyh in tqdm(range(md_origin.shape[0])):# for i_zyh in range(1):try:if md_origin.loc[i_zyh, 'type'] == 'text':# Input = '现在你是一个专业翻译家,一个具有生物学背景的生物信息学教授,你的目标是把生物学领域学术论文中的一段翻译成中文。请翻译时不要带翻译腔,而是要翻译得自然、流畅和地道,使用优美和高雅的表达方式。请注意,提供的段落是markdown格式的,你翻译后需要保留原格式,除了提供给我翻译后的文本,我还需要你分点帮我总结这一段的精要,并且用一句话总结。现在请翻译并总结:' + \# md_origin.loc[i_zyh, 'content']Input = '现在你是一个生物学教授,你的目标是把生物学领域学术论文中的一个"自然段(paragraph)"[分点总结],并且用[一句话总结]。请注意,呈现方式为:“一句话总结\n:……;分段总结(用markdown的有序列表格式):1. ……;2. ……;3. ……、……”,现在请总结:' + \md_origin.loc[i_zyh, 'content']# Input = '晚上吃什么'ans = ask_Q(Input)ans = json.loads(ans.text)md_res.loc[i_zyh, 'content'] = ans['result']if i_zyh == 0:print('# ' + md_origin.loc[i_zyh, 'content'])else:print(md_origin.loc[i_zyh, 'content'])# print("第",i_zyh,"行")if i_zyh != 0:print(ans['result'])# f.write(ans['result'])print('')print('------')else:# print('------')print(md_res.loc[i_zyh, 'content'])print('')print('------')# f.write(md_res.loc[i_zyh, 'content'])except Exception:print('这一段报错了,不过问题不大')
# 恢复原来的输出流
sys.stdout = old_out# 关闭文件
f.close()os.startfile(outpath)
# print('文件输出路径:\n'+outpath + 'out' + filename)md_translator.py
# 导入所需的库
import pandas as pd
import re# 定义一个函数,用于读取markdown文件,并按段落分割
def read_markdown(file):# 打开文件,读取内容with open(file, 'r', encoding='utf-8') as f:content = f.read()# 按换行符分割内容,得到一个列表lines = content.split('\n')# 定义一个空列表,用于存储分割后的段落paragraphs = []# 定义一个空字符串,用于拼接段落paragraph = ''# 遍历每一行for line in lines:# 如果是空行,说明段落结束,将拼接好的段落添加到列表中,并清空字符串if line == '':if paragraph != '':paragraphs.append(paragraph)paragraph = ''# 如果是代码块的开始或结束标志,也说明段落结束,将拼接好的段落添加到列表中,并清空字符串elif line.startswith('```'):if paragraph != '':paragraphs.append(paragraph)paragraph = ''# 将代码块的开始或结束标志也添加到列表中paragraphs.append(line)# 如果是图片链接,也说明段落结束,将拼接好的段落添加到列表中,并清空字符串elif re.match(r'!\[.*\]\(.*\)', line):if paragraph != '':paragraphs.append(paragraph)paragraph = ''# 将图片链接也添加到列表中paragraphs.append(line)# 否则,将当前行拼接到字符串中,并加上换行符else:paragraph += line + '\n'# 如果最后还有未添加的段落,也添加到列表中if paragraph != '':paragraphs.append(paragraph)# 返回分割后的段落列表return paragraphs# 定义一个函数,用于识别每个段落的类型(文本、代码、图片)
def identify_type(paragraph):# 如果是代码块的开始或结束标志,返回'code'if paragraph.startswith('```'):return 'code'# 如果是图片链接,返回'image'elif re.match(r'!\[.*\]\(.*\)', paragraph):return 'image'# 否则,返回'text'else:return 'text'def md_df(filepath):# 调用read_markdown函数,读取markdown文件,并按段落分割# paragraphs = read_markdown(filepath + 'data/CellWalkR_Vignette.md')paragraphs = read_markdown(filepath)# 创建一个空的dataframe,有两列:'content'和'type'md_origin = pd.DataFrame(columns=['content', 'type'])# 遍历每个段落,识别其类型,并添加到dataframe中for paragraph in paragraphs:type = identify_type(paragraph)md_origin = md_origin.append({'content': paragraph, 'type': type}, ignore_index=True)# 找到第二列等于"code"的行的索引code_indices = md_origin[md_origin['type'] == 'code'].index.tolist()# 两个两个地读取索引,并设置这两个索引之间行的第二列为"code"for i in range(0, len(code_indices), 2):start_index = code_indices[i]end_index = code_indices[i + 1] if i + 1 < len(code_indices) else None# 设置这两个索引之间行的第二列为"code"md_origin.loc[start_index:end_index - 1, 'type'] = 'code'# i=0# codes=[]# while i < md_origin.shape[0]-2:# if md_origin.loc[i,'type'] == 'code':# codes.append(1)# md_origin.loc[i+1,'type'] = 'code'# i+=2# i+=1# 将DataFrame保存为CSV文件return md_origin
# md_origin.to_csv('md_df.csv', index=False)
相关文章:
【文献copilot】调用文心一言api对论文逐段总结
文献copilot:调用文心一言api对论文逐段总结 当我读文献的时候,感觉读得太慢了,看翻译软件翻译的又觉得翻译的不好。于是我就写了个程序辅助我读文献,它可以逐段总结,输出格式是:原文一句话总结分段总结&a…...
编译安装Nginx+GeoIP2自动更新+防盗链+防爬虫+限制访问速度+限制连接数
此文章是Nginx的GeoIP2模块和MaxMind国家IP库相互结合,达到客户端IP访问的一个数据记录以及分析,同时还针对一些业务需求做出对Nginx中间件的控制,如:防盗链、防爬虫、限制访问速度、限制连接数等 该篇文章是从一个热爱搞技术的博…...

基于JAVA+SpringBoot+UniApp+Vue的前后端分离的手机移动端图书借阅平台
✌全网粉丝20W,csdn特邀作者、博客专家、CSDN新星计划导师、java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取项目下载方式🍅 一、项目背景介绍: 随着社会信息化的快速…...
华为云CodeArts IDE for Java安装使用教程
本篇内容主要介绍使用华为云CodeArts IDE for Java创建工程、代码补全、运行调试代码、Build构建和测试相关的主要功能。 一、下载安装华为云CodeArts IDE for Java 华为云CodeArts IDE for Java安装要求 至少需要 2 GB RAM ,但是推荐8 GB RAM; 至少需要 2.5 GB 硬…...

MPI并行编程技术
MPI并行编程技术 MPI含义及环境搭建安装点对点通信阻塞型接口MPI_SendMPI_Recv 阻塞式示例tag雅可比迭代示例死锁 MPI含义及环境搭建安装 MPICH官网 Github地址 MPI历史版本下载地址 安装教程 MPI介绍 MPI课程 点对点通信 阻塞型接口 MPI_Send MPI_Recv 阻塞式示例 tag 雅…...

使用 pyspark 进行 Classification 的简单例子
This is the second assignment for the Coursera course “Advanced Machine Learning and Signal Processing” Just execute all cells one after the other and you are done - just note that in the last one you have to update your email address (the one you’ve u…...
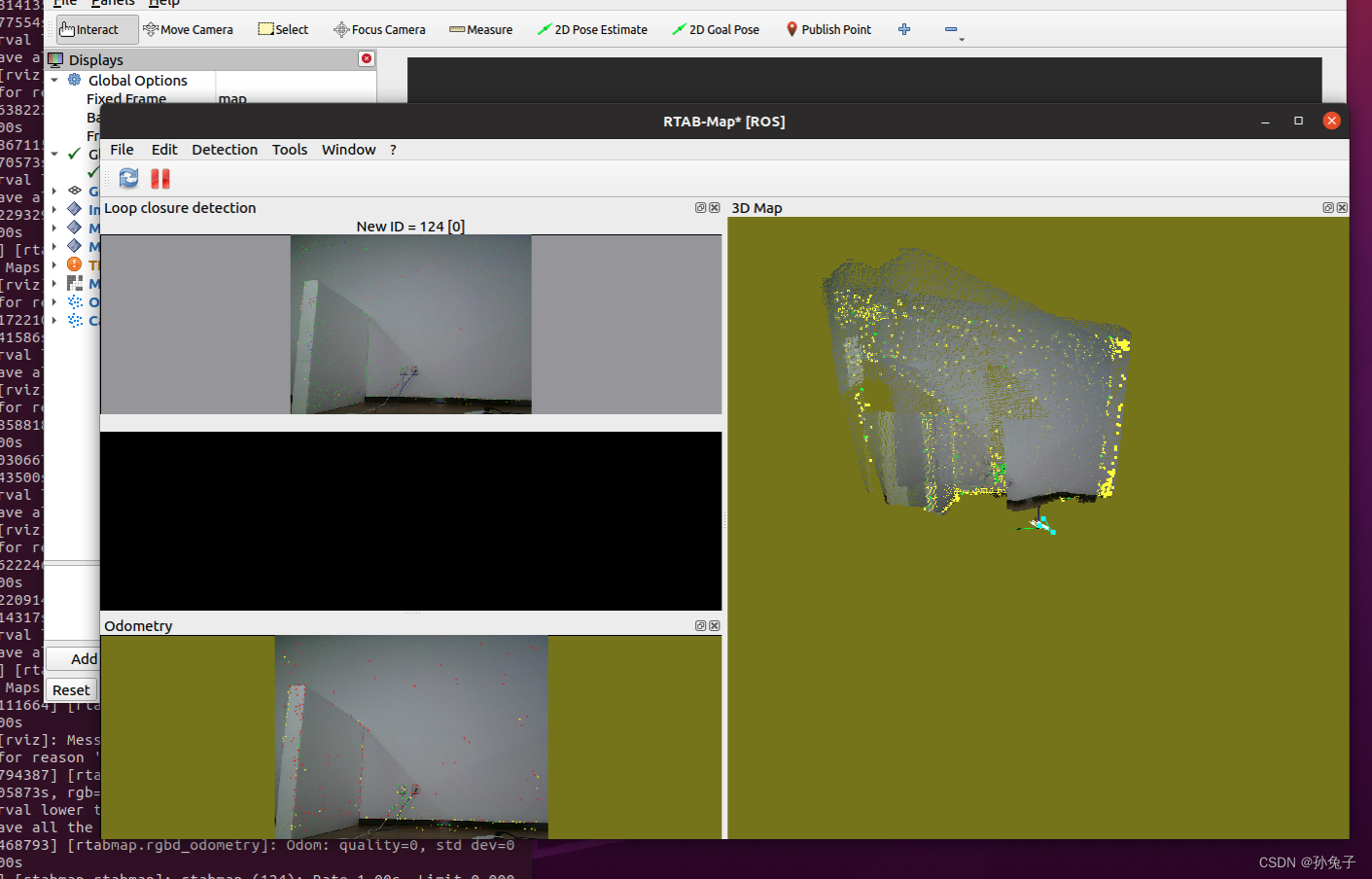
[ROS2系列] ORBBEC(奥比中光)AstraPro相机在ROS2进行rtabmap 3D建图
目录 背景: 一、驱动AstraPro摄像头 二、安装rtabmap error1:缺包 三、尝试 四、参数讲解 五、运行 error2: Did not receive data since 5 seconds! 六、效果编辑 error4: 背景: 1、设备:pc;jeston agx …...
墨迹天气商业版UTF-8模板,Discuz3.4灰白色风格(带教程)
1.版本支持:Discuzx3.4版本,Discuzx3.3版本,DiscuzX3.2版本。包括网站首页,论坛首页,论坛列表页,论坛内容页,论坛瀑布流,资讯列表页(支持多个),产品列表页(支持多个),关于…...
Godot 官方2D C#重构(2):弹幕躲避
前言 Godot 官方 教程 Godot 2d 官方案例C#重构 专栏 Godot 2d 重构 github地址 实现效果 技术点说明 异步函数 Godot的事件不能在Task中运行,因为会导致跨线程的问题。 //这样是不行的,因为跨线程了,而且会阻塞UI线程,具体原因…...

ELK之LogStash插件grok和geoip的配置使用
本文针对LogStash常用插件grok和geoip的使用进行说明: 一、使用grok输出结构化数据 编辑 first-pipeline.conf 文件,修改为如下内容: input{#stdin{type > stdin}file {# 读取文件的路径path > ["/tmp/access.log"]start_…...
基于Python实现的一款轻量、强大、好用的视频处理软件,可缩视频、转码视频、倒放视频、合并片段、根据字幕裁切片段、自动配字幕等
Quick Cut 是一款轻量、强大、好用的视频处理软件。它是一个轻量的工具,而不是像 Davinci Resolve、Adobe Premiere 那样专业的、复杂的庞然大物。Quick Cut 可以满足普通人一般的视频处理需求:压缩视频、转码视频、倒放视频、合并片段、根据字幕裁切片段…...

深入探讨 Golang 中的追加操作
通过实际示例探索 Golang 中的追加操作 简介 在 Golang 编程领域,append 操作是一种多才多艺的工具,使开发人员能够动态扩展切片、数组、文件和字符串。在这篇正式的博客文章中,我们将踏上一段旅程,深入探讨在 Golang 中进行追加…...
三网话费余额查询的API系统 基于thinkphp6.0框架
本套系统是用thinkphp6.0框架开发的,PHP需大于8.2,系统支持用户中心在线查询和通过API接口对接发起查询,用户余额充值是对接usdt接口,源码全开源,支持懂技术的人二次开发~搭建教程1、源码上传后,吧运行目录…...

LeetCode —— dfs和bfs
797. 所有可能的路径 给你一个有 n 个节点的 有向无环图(DAG),请你找出所有从节点 0 到节点 n-1 的路径并输出(不要求按特定顺序)。 graph[i] 是一个从节点 i 可以访问的所有节点的列表(即从节点 i 到节点…...
【ROS 2 基础-常用工具】-7 Rviz仿真机器人
所有内容请查看:博客学习目录_Howe_xixi的博客-CSDN博客...
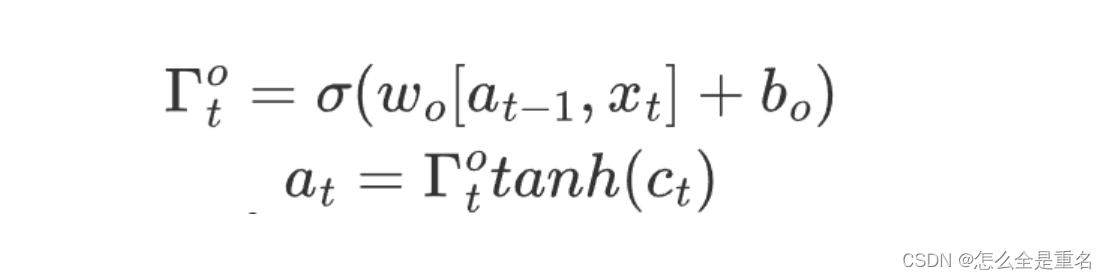
循环神经网络(RNN)
定义 循环神经网络(RNN)是一种深度学习神经网络,专门用于处理序列数据,如文本、语音和时间序列数据。RNN的独特之处在于它具有循环连接,允许信息在网络内持续流动,以便处理先前的输入信息,具体…...

ESP32C3 LuatOS TM1650②动态显示累加整数
--注意:因使用了sys.wait()所有api需要在协程中使用 -- 用法实例 PROJECT "ESP32C3_TM1650" VERSION "1.0.0" _G.sys require("sys") local tm1650 require "tm1650"-- 拆分整数,并把最低位数存放在数组最大索引处 loc…...
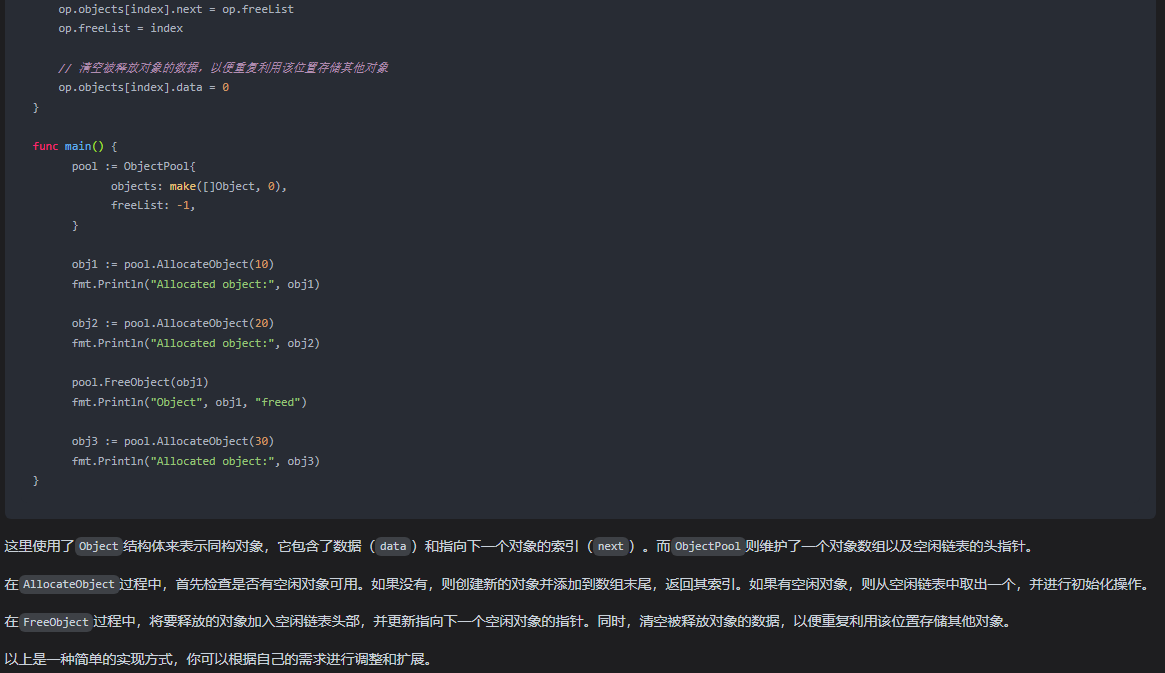
文心一言 VS 讯飞星火 VS chatgpt (117)-- 算法导论10.3 2题
二、用go语言,对一组同构对象用单数组表示法实现,写出过程ALLOCATE-OBJECT和FREE-OBJECT。 文心一言: 在Go语言中,我们通常使用指针和结构体来表示和操作复杂的数据结构。对于一组同构对象,我们可以使用一个数组来存…...
专业修图软件 Affinity Photo 2 mac中文版编辑功能
Affinity Photo for Mac是应用在MacOS上的专业修图软件,支持多种文件格式,包括psD、PDF、SVG、Eps、TIFF、JPEG等。 Affinity Photo mac提供了许多高级图像编辑功能,如无限制的图层、非破坏性操作、高级的选择工具、高级的调整层、HDR合成、全…...
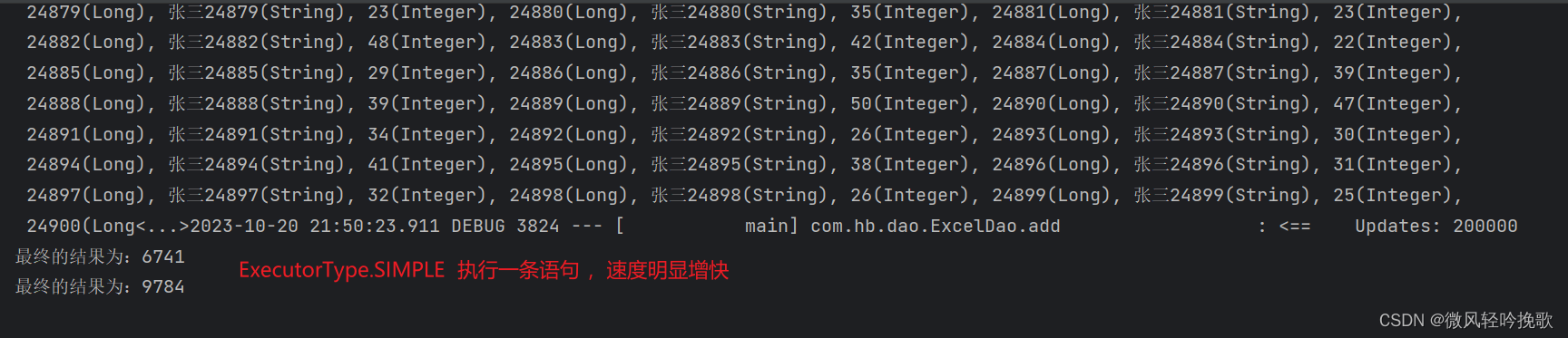
Excel 5s内导入20w条简单数据(不使用多线程)
文章目录 Excel 5s内导入20w条数据1. 生成20w条数据1.1 使用Excel 宏生成20w条数据1.2 生成成功 2. ExecutorType:批量操作执行器类型2.1 ExecutorType.SIMPLE2.2 ExecutorType.BATCH2.3 ExecutorType.REUSE 3. 20w条数据直接插入数据库3.1 使用ExecutorType.SIMPLE…...

nli-MiniLM2-L6-H768代码实例:调用API实现自动化批量分类任务
nli-MiniLM2-L6-H768代码实例:调用API实现自动化批量分类任务 1. 工具介绍 nli-MiniLM2-L6-H768是一款基于cross-encoder/nli-MiniLM2-L6-H768轻量级NLI模型开发的本地零样本文本分类工具。它最大的特点是无需任何微调训练,只需输入文本和自定义标签&a…...

Wan2.2-I2V-A14B镜像优化特性:GPU算力专属调度策略技术白皮书
Wan2.2-I2V-A14B镜像优化特性:GPU算力专属调度策略技术白皮书 1. 镜像概述与核心价值 Wan2.2-I2V-A14B私有部署镜像是一款专为文生视频任务优化的高性能解决方案,针对RTX 4090D 24GB显存显卡进行了深度适配。本镜像开箱即用,内置完整运行环…...

AstrBot主动聊天插件:赋予AI主动关怀能力的完整解决方案
1. 项目概述如果你用过AstrBot,或者玩过其他聊天机器人框架,大概率会有一个共同的感受:Bot总是被动的。它像一个永远在等待指令的助手,只有你主动它、问它,它才会回应。这种交互模式在初期很新鲜,但时间一长…...

上下文工程:让Agent真正用好记忆与知识
拥有记忆和检索能力,只是 Agent 智能化的第一步。如何在有限的上下文窗口内,高效地组织、筛选和利用这些信息,才是决定 Agent 实际表现的关键——这正是上下文工程(Context Engineering)所要解决的问题。 什么是上下文…...

终极指南:让本地视频拥有B站弹幕效果,离线观影也能嗨起来!
终极指南:让本地视频拥有B站弹幕效果,离线观影也能嗨起来! 【免费下载链接】BiliLocal add danmaku to local videos 项目地址: https://gitcode.com/gh_mirrors/bi/BiliLocal 还在羡慕B站视频的弹幕互动氛围吗?想让你硬盘…...

高效项目管理:Backlog.md 文件的结构化应用与团队协作实践
1. 项目概述:一个被低估的“待办清单”文件在项目协作和日常开发中,我们经常会遇到一个看似简单、实则至关重要的文件——Backlog.md。这个由MrLesk维护的模板,远不止是一个简单的任务列表。它更像是一个项目的“战略沙盘”,将零散…...

ACI:专为AI应用设计的轻量级容器运行时,解决环境依赖与构建效率难题
1. 项目概述:ACI,一个为AI应用量身定制的容器运行时如果你正在构建或部署AI应用,尤其是那些依赖特定GPU驱动、CUDA版本或复杂Python环境的模型服务,那么你一定对“依赖地狱”和“环境一致性”这两个词深恶痛绝。传统的容器化方案&…...

7个免费大语言模型学习资源全解析
1. 大语言模型(LLMs)学习资源概览大语言模型(Large Language Models)正在重塑我们与技术交互的方式。作为一名长期跟踪AI技术发展的从业者,我经常被问到如何系统性地学习LLMs相关知识。与付费课程相比,网络…...

如何将微信聊天记录转化为个人数字记忆库:WeChatMsg让你的对话永不遗忘
如何将微信聊天记录转化为个人数字记忆库:WeChatMsg让你的对话永不遗忘 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_T…...

AutoJS无限制版安装使用教程:附送礼物与私信自动化脚本完整源码分享
AutoJS无限制版安装使用教程:附送礼物与私信自动化脚本完整源码分享 作为一名每天都在各种APP里“摸鱼”的打工人,我最近发现那些重复性的点击操作简直是在浪费生命。比如刷直播间、自动领福利、或者是给喜欢的博主发私信,点多了手都酸。 为了彻底解放双手,我研究了一下 A…...