【分布式】入门级NCCL多机并行实践 - 02
# 背景知识
大模型和分布式训练对数据的吞吐量以及并行度都有很高的要求,NCCL就是在这个背景下诞生的。
如果你是一个只会写写Python,调用PyTorch和Horovod的算法萌新,可能对于分布式底层的东西不太了解,在下岗热潮中被主管逼着转变成算子或者通讯库的搬砖工,就会像我一样两眼蒙蔽。因此本文只对自己踩到的坑做一个整理,如果有说错的地方,那就是我说错了。
1. 从PyTorch开始理解结构
以PyTorch为例,其中spmd接口下的相关定义是用于处理分布式的。但主要是处理单机多CPU情况,因此我们今天只考虑多机(多节点)情况。
SPMD(Single Program/Multiple Data),即单程序多份数据进行任务并行。SPMD的本质是对问题进行域分解,它将一个大的问题区域分解成若干个较小的问题区域,然后对其并行求解。
其中用于实现多节点分布式的组件有以下三个:
- Distributed Data-Parallel Training (DDP)
- RPC-Based Distributed Training (RPC)
- Collective Communication (c10d)
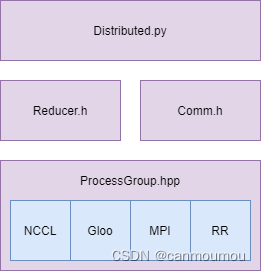
从上图可知,1.6版本左右的PyTorch调用结构如下,最后在ProcessGroup.hpp可以找到对NCCL、Gloo和MPI的调用。
而这些蓝色的部分就是基本的分布式通讯库,他们负责实现通讯和一部分计算功能。
2. 通讯方式
已知显卡与主板通过PCIE相连,任何数据都要从PCIE和CPU穿过,这么做的效率肯定是很低的。
因此在GPUDirect技术出现以后,我们可以把GPU通信分为GPU控制的GPU通信和CPU控制的GPU通信两种。感兴趣相关的细节可以通过此文查看:【研究综述】浅谈GPU通信和PCIe P2P DMA
我们知道通信技术有很多,例如DMA,P2P。DMA和P2P都是一种能力,而非具体的协议。
2.1 DMA & P2P
DMA(Direct Memory Access,直接内存访问),允许在计算机主板上的设备直接把数据发送到内存中去,数据搬运不需要CPU的参与。
传统内存访问需要通过CPU进行数据copy来移动数据,通过CPU将内存中的Buffer1移动到Buffer2中。DMA模式:可以同DMA Engine之间通过硬件将数据从Buffer1移动到Buffer2,而不需要操作系统CPU的参与,大大降低了CPU Copy的开销。
通常,我们也将主机称为节点。
第二代GPUDirect技术被称作GPUDirect P2P(Peer to Peer),重点解决的是节点内GPU通信问题。两个GPU可以通过PCIe P2P直接进行数据搬移,避免了主机内存和CPU的参与。
那么一台机器中的数据搬运是DMA,多台主机的DMA如何实现呢?这就出现了RDMA这一协议。
2.2 RDMA
RDMA( Remote Direct Memory Access )意为远程直接地址访问,通过RDMA,本端节点可以“直接”访问远端节点的内存。所谓直接,指的是可以像访问本地内存一样,绕过传统以太网复杂的TCP/IP网络协议栈读写远端内存,而这个过程对端是不感知的,而且这个读写过程的大部分工作是由硬件而不是软件完成的。
利用机器本身的DMA能力,以及网卡等其他硬件实现的远程DMA。这就和RPC远程过程调用有类似之处。
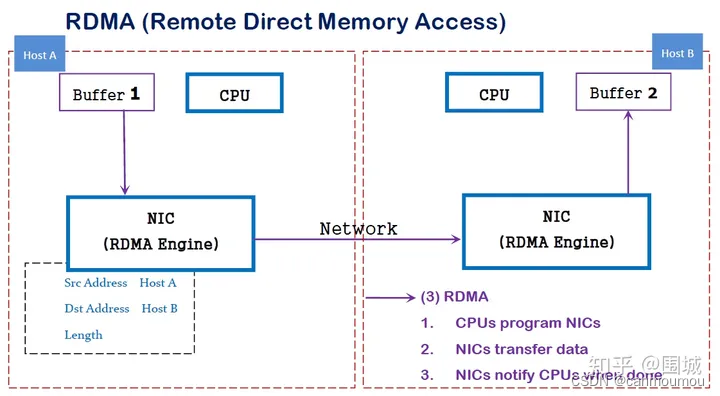
RDMA是一种host-offload, host-bypass技术,允许应用程序(包括存储)在它们的内存空间之间直接做数据传输。具有RDMA引擎的以太网卡(RNIC)--而不是host--负责管理源和目标之间的可靠连接。
为了支持RDMA实现,有以下三种网络协议:
| InfiniBand(IB) | 从一开始就支持RDMA的新一代网络协议。由于这是一种新的网络技术,因此需要支持该技术的网卡和交换机。 |
| RDMA过融合以太网(RoCE) | 即RDMA over Ethernet, 允许通过以太网执行RDMA的网络协议。这允许在标准以太网基础架构(交换机)上使用RDMA,只不过网卡必须是支持RoCE的特殊的NIC。 |
| 互联网广域RDMA协议(iWARP) | 即RDMA over TCP, 允许通过TCP执行RDMA的网络协议。这允许在标准以太网基础架构(交换机)上使用RDMA,只不过网卡要求是支持iWARP(如果使用CPU offload的话)的NIC。否则,所有iWARP栈都可以在软件中实现,但是失去了大部分的RDMA性能优势。 |
IB是最简单的方式,其次是RoCE,当然本文不做赘述,有大篇讲的好的博客,甚至直接看论文和文档也是可以的。NCCL已经支持这些协议。
2.3 MPI
MPI有多种实现方式,例如OpenMPI,MPICH。
MPI 全名叫 Message Passing Interface,即信息传递接口,作用是可以通过 MPI 可以在不同进程间传递消息,从而可以并行地处理任务,即进行并行计算。NCCL中利用MPI来处理多机通讯的部分。
直接下载:
#apt安装mpi
sudo apt-get update
sudo apt install openmpi-bin openmpi-doc libopenmpi-dev
#验证是否安装成功
mpirun --version自己编译可参考前文:分布式学习 - MPICH编译与实践_mpich 编译指定 mpich cc_canmoumou的博客-CSDN博客
3. NCCL
NCCL在单机多卡环境下的编译与运行参考我的前文:【分布式】NCCL部署与测试 - 01_canmoumou的博客-CSDN博客
NCCL本身具备了基本的通信协议支持、环路算法、原语操作等等。
由于数据运输和计算都是在GPU上完成,需要launch kernel,因此阅读源码前要具备基本的CUDA知识。
3.1 NCCL 多机多卡实践
环境配置
1. 两台多卡服务器,需要配置好无密钥登陆(ssh),以及NFS共享目录。NFS挂载方式如果我有空另外再写。
2. 检查IB设备及性能,确定有一块或多块IB网卡,安装nv_peer_mem驱动
3. 配置BIOS:配置IOMMU等
如何检查:
# check system physical memory size
sudo dmidecode -t memory | grep Size: | grep -v "No Module Installed" | awk '{sum+=$2}END{print sum}'sudo cat /var/log/dmesg | grep -e "AMD-Vi: Interrupt remapping enabled" -e "IOMMU enabled"若发现IOMMU被disabled,请到BIOS界面更改:
选择enable Intel VT for Directed I/O (VT-d)选项
或者enable IOMMU选项
4. 打开CPU高性能模式,并配置网络
查看IB网络是否正常
|
|
5. 下载其他依赖,下载NCCL源码并保证单机单卡可以运行,下载mpich。
编译运行
我们通过NCCL-TEST运行程序,其中NCCL原仓库代码不需要重新编译,只有NCCL-TEST需要重新编译,必须增添MPI_HOME,并设置MPI=1
# 单机编译nccl-test:
make CUDA_HOME=/path/to/cuda NCCL_HOME=/path/to/nccl# 多机编译
make CUDA_HOME=/path/to/cuda NCCL_HOME=/path/to/nccl MPI_HOME=/path/to/mpi MPI=1
将编译好的build文件放到NFS目录下,这样两台机器都可以在共享目录看到此文件。
再在共享目录外设置算法拓扑(topo.txt)和图结构(graph.txt),并添加mpi_hosts文件。mpi_hosts文件内放两张机器的ip地址:
# MPI CLUSTERS
X.X.X.X manager slots=1
X.X.X.X worker1 slots=1运行:
|
|
请注意,-np的值为mpi_hosts内各个slots之和。
使用mpich运行的时候,以单机的方式运行,也就是单机四卡是-g 4,多机四卡的参数也是-g 4.
# 总结
相关文章:
【分布式】入门级NCCL多机并行实践 - 02
# 背景知识 大模型和分布式训练对数据的吞吐量以及并行度都有很高的要求,NCCL就是在这个背景下诞生的。 如果你是一个只会写写Python,调用PyTorch和Horovod的算法萌新,可能对于分布式底层的东西不太了解,在下岗热潮中被主管逼着…...

Rust的模式匹配
文章目录 match匹配if let匹配 match匹配 match可以结合枚举使用,例如 enum IpVersion {V4,V6, }fn ParseIpVersion(version: IpVersion) -> String {match version {IpVersion::V4 > String::from("ipv4"),IpVersion::V6 > String::from(&quo…...
操作系统【OS】虚拟机
定义 使用虚拟化技术,将一台物理机器虚化为多台虚拟机器VM,每个虚拟机器都可用独立运行一个操作系统 分类 传统计算机 第一类VMM 第二类VMM...

不写代码、构建一个开源的 ChatGPT,总共需要几步?|Hugging News #1020
每一周,我们的同事都会向社区的成员们发布一些关于 Hugging Face 相关的更新,包括我们的产品和平台更新、社区活动、学习资源和内容更新、开源库和模型更新等,我们将其称之为「Hugging News」。本期 Hugging News 有哪些有趣的消息࿰…...
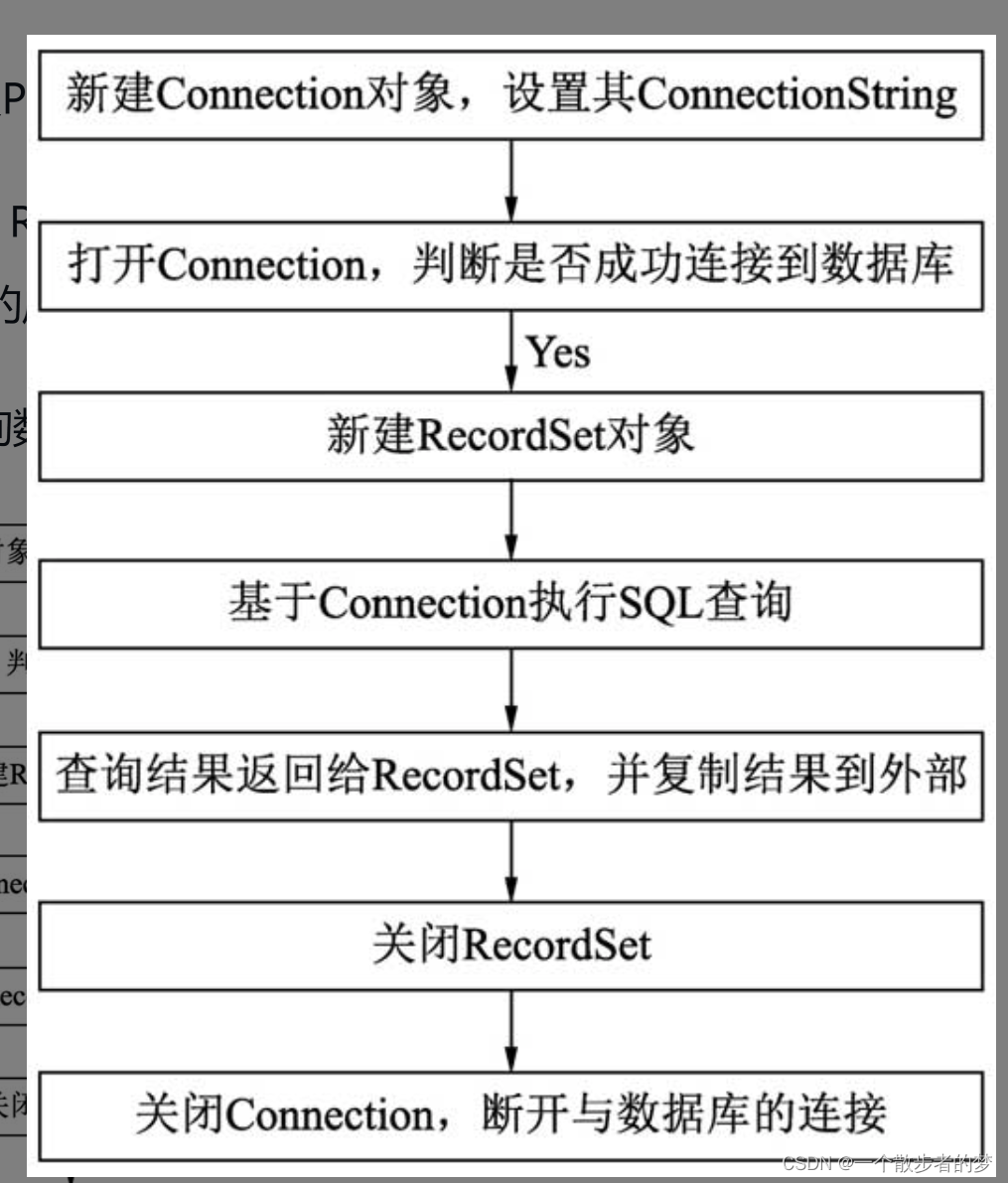
VBA操作数据库
相关背景: 对于数据分析同学,一般SQL,EXCEL是必备技能,但对于VBA和Python可能有的同学不会;在处理本地数据上(诸如excel、txt|csv文本),后续尝试使用VBA或者Python写一个sql查询的GUI界面&…...

【华为OD机试】HJ26 字符串排序
描述 编写一个程序,将输入字符串中的字符按如下规则排序。 规则 1 :英文字母从 A 到 Z 排列,不区分大小写。 如,输入: Type 输出: epTy 规则 2 :同一个英文字母的大小写同时存在时,…...
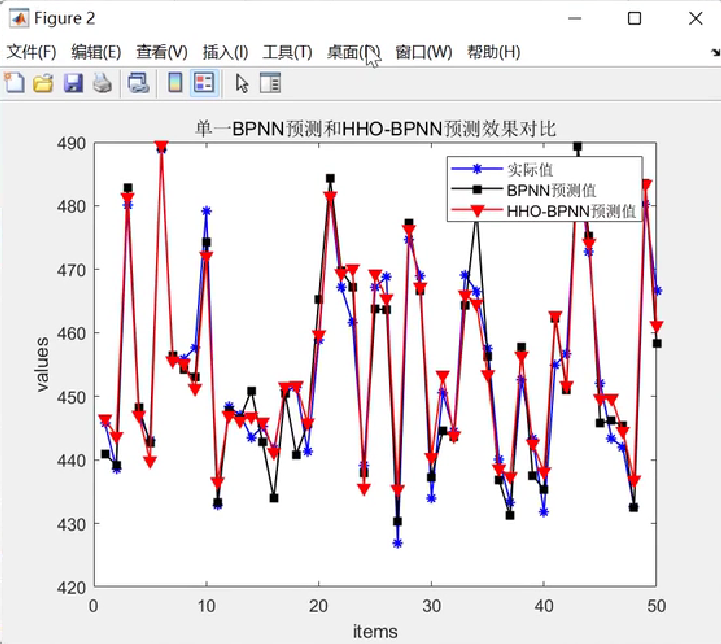
哈里斯鹰算法优化BP神经网络(HHO-BP)回归预测研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
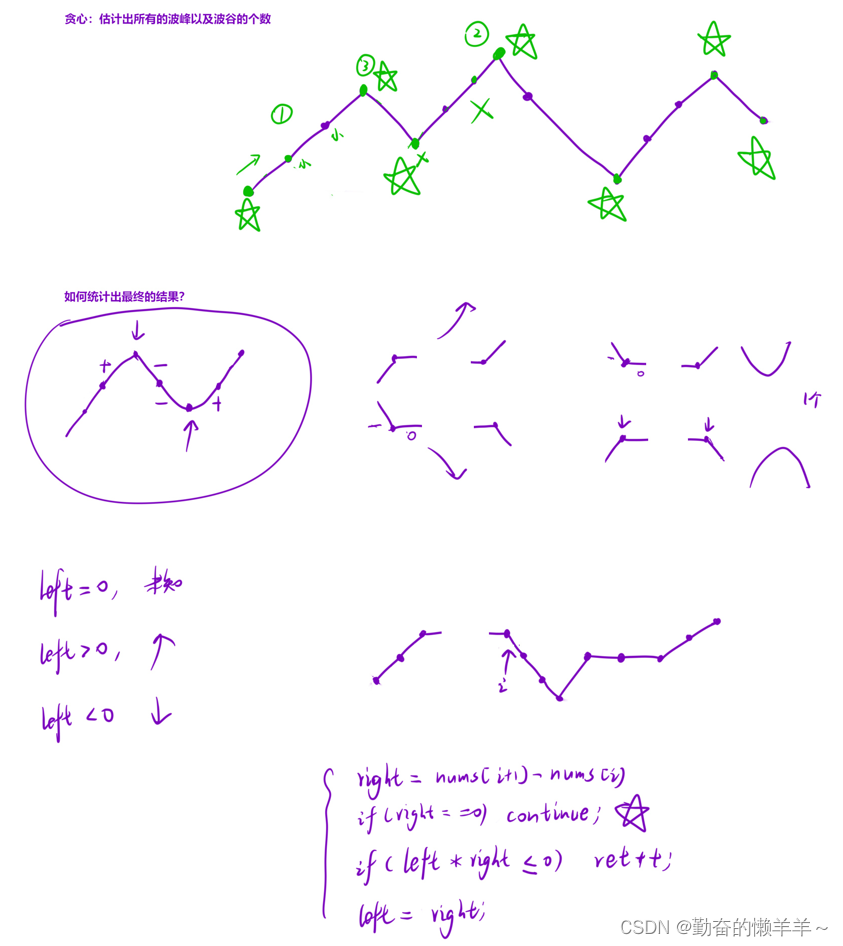
摆动序列【贪心4】
题目 分析 代码 class Solution { public:int wiggleMaxLength(vector<int>& nums) {if(nums.size() < 2) return nums.size();int ret 0,left 0,right 0;for(int i 0;i < nums.size()-1;i){right nums[i1] - nums[i];if(right 0) continue;if(left …...
Youtrack Linux 安装
我们考虑最后应该使用的是 ZIP 方式的安装。 按照官方的说法如何设置运行 YouTrack 应该是非常简单的。 准备环境 根据官方的说法,我们需要做的就是下载 Zip 包,然后把 Zip 包解压到指定的目录中就可以了。 下载 当前官方的下载地址为:Ge…...

分类预测 | MATLAB实现SSA-CNN-LSTM麻雀算法优化卷积长短期记忆神经网络数据分类预测
分类预测 | MATLAB实现SSA-CNN-LSTM麻雀算法优化卷积长短期记忆神经网络数据分类预测 目录 分类预测 | MATLAB实现SSA-CNN-LSTM麻雀算法优化卷积长短期记忆神经网络数据分类预测分类效果基本描述程序设计参考资料 分类效果 基本描述 1.MATLAB实现SSA-CNN-LSTM数据分类预测&…...

飞书-多维文档-计算时间差
1. 选择字段类型 如图所示,字段类型选择 公式 2. 编辑公式 单击 公式编辑器 在弹出的公式编辑框中输入公式 TEXT([终结时间]-[开始时间],"HH:MM") [终结时间] 和 [开始时间] 请替换成你的表格中对应的字段名称HH:MM 表示输出的时间格式为 时:分其中 “…...

【文献copilot】调用文心一言api对论文逐段总结
文献copilot:调用文心一言api对论文逐段总结 当我读文献的时候,感觉读得太慢了,看翻译软件翻译的又觉得翻译的不好。于是我就写了个程序辅助我读文献,它可以逐段总结,输出格式是:原文一句话总结分段总结&a…...
编译安装Nginx+GeoIP2自动更新+防盗链+防爬虫+限制访问速度+限制连接数
此文章是Nginx的GeoIP2模块和MaxMind国家IP库相互结合,达到客户端IP访问的一个数据记录以及分析,同时还针对一些业务需求做出对Nginx中间件的控制,如:防盗链、防爬虫、限制访问速度、限制连接数等 该篇文章是从一个热爱搞技术的博…...

基于JAVA+SpringBoot+UniApp+Vue的前后端分离的手机移动端图书借阅平台
✌全网粉丝20W,csdn特邀作者、博客专家、CSDN新星计划导师、java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取项目下载方式🍅 一、项目背景介绍: 随着社会信息化的快速…...
华为云CodeArts IDE for Java安装使用教程
本篇内容主要介绍使用华为云CodeArts IDE for Java创建工程、代码补全、运行调试代码、Build构建和测试相关的主要功能。 一、下载安装华为云CodeArts IDE for Java 华为云CodeArts IDE for Java安装要求 至少需要 2 GB RAM ,但是推荐8 GB RAM; 至少需要 2.5 GB 硬…...

MPI并行编程技术
MPI并行编程技术 MPI含义及环境搭建安装点对点通信阻塞型接口MPI_SendMPI_Recv 阻塞式示例tag雅可比迭代示例死锁 MPI含义及环境搭建安装 MPICH官网 Github地址 MPI历史版本下载地址 安装教程 MPI介绍 MPI课程 点对点通信 阻塞型接口 MPI_Send MPI_Recv 阻塞式示例 tag 雅…...

使用 pyspark 进行 Classification 的简单例子
This is the second assignment for the Coursera course “Advanced Machine Learning and Signal Processing” Just execute all cells one after the other and you are done - just note that in the last one you have to update your email address (the one you’ve u…...
[ROS2系列] ORBBEC(奥比中光)AstraPro相机在ROS2进行rtabmap 3D建图
目录 背景: 一、驱动AstraPro摄像头 二、安装rtabmap error1:缺包 三、尝试 四、参数讲解 五、运行 error2: Did not receive data since 5 seconds! 六、效果编辑 error4: 背景: 1、设备:pc;jeston agx …...
墨迹天气商业版UTF-8模板,Discuz3.4灰白色风格(带教程)
1.版本支持:Discuzx3.4版本,Discuzx3.3版本,DiscuzX3.2版本。包括网站首页,论坛首页,论坛列表页,论坛内容页,论坛瀑布流,资讯列表页(支持多个),产品列表页(支持多个),关于…...
Godot 官方2D C#重构(2):弹幕躲避
前言 Godot 官方 教程 Godot 2d 官方案例C#重构 专栏 Godot 2d 重构 github地址 实现效果 技术点说明 异步函数 Godot的事件不能在Task中运行,因为会导致跨线程的问题。 //这样是不行的,因为跨线程了,而且会阻塞UI线程,具体原因…...

图像分类中像素缩放算法选择与优化实践
1. 图像分类任务中的像素缩放方法概述在计算机视觉领域,像素缩放是图像预处理环节中最基础却至关重要的步骤。当我们把原始图像输入卷积神经网络(CNN)进行训练或推理时,绝大多数情况下都需要先将图像调整为统一尺寸。这个看似简单的操作,实际…...

Rust重构AutoGPT:高性能自主AI智能体框架深度解析
1. 项目概述:当AI学会“自己动手” 最近在GitHub上看到一个挺有意思的项目,叫 kevin-rs/autogpt 。这名字一看就让人联想到去年那个火遍全网的AutoGPT,没错,它正是那个“让AI自己思考、自己执行任务”的明星项目的Rust语言实现…...

Weka回归算法实战:从入门到工业级应用
1. Weka与回归算法概述Weka作为一款开源的机器学习工具集,以其图形化界面和丰富的算法库闻名于数据科学领域。我第一次接触Weka是在2012年的一个数据挖掘项目中,当时就被它"开箱即用"的特性所吸引。回归分析作为预测建模的核心技术,…...


ARMv8 TLBIRange函数原理与多核优化实践
1. AArch64 TLB管理机制概述在ARMv8架构中,TLB(Translation Lookaside Buffer)作为内存管理单元(MMU)的核心组件,负责缓存虚拟地址到物理地址的转换结果。当处理器需要访问内存时,首先查询TLB获…...

如何5分钟配置TMSpeech:Windows本地语音识别完整教程
如何5分钟配置TMSpeech:Windows本地语音识别完整教程 【免费下载链接】TMSpeech 腾讯会议摸鱼工具 项目地址: https://gitcode.com/gh_mirrors/tm/TMSpeech 还在为会议记录烦恼吗?TMSpeech为您提供一款完全本地运行的Windows实时语音识别工具&…...

microeco:突破微生物功能预测精度瓶颈的R包创新方案
microeco:突破微生物功能预测精度瓶颈的R包创新方案 【免费下载链接】microeco An R package for downstream data analysis of microbiome omics data 项目地址: https://gitcode.com/gh_mirrors/mi/microeco microeco是一个专为微生物组学数据下游分析设计…...

VSCode嵌入式开发效率提升300%的7个隐藏技巧:从Cortex-M启动文件自动补全到RTOS任务可视化调试
更多请点击: https://intelliparadigm.com 第一章:VSCode嵌入式开发效率跃迁的底层逻辑 VSCode 并非原生嵌入式 IDE,其效率跃迁源于可编程扩展架构与标准化协议的深度协同。核心驱动力在于 Language Server Protocol(LSP…...

AAAI 2026 AMD论文Spark方法揭秘:查询感知的 KV 缓存通道剪枝
AAAI 2026 AMD论文Spark方法揭秘:查询感知的 KV 缓存通道剪枝 原文作者:Huanxuan Liao, Yixing Xu, Shizhu He, Guanchen Li, Xuanwu Yin, Dong Li, Emad Barsoum, Jun Zhao, Kang Liu 在这篇博客中,我们将讨论SparK ,一种无需训练…...

5分钟快速上手:知识星球内容爬取与PDF电子书制作终极指南
5分钟快速上手:知识星球内容爬取与PDF电子书制作终极指南 【免费下载链接】zsxq-spider 爬取知识星球内容,并制作 PDF 电子书。 项目地址: https://gitcode.com/gh_mirrors/zs/zsxq-spider 在信息爆炸的数字时代,知识星球已成为众多专…...