图论01-【无权无向】-图的基本表示-邻接矩阵/邻接表
文章目录
- 1. 代码仓库
- 2. 图的基本表示的比较
- 3. 邻接矩阵:Array和TreeSet
- 3.1 图示
- 3.2 Array主要代码解析
- 3.3 测试输出
- 3.4 使用TreeSet的代码
- 4. 邻接表:LinkedList
- 4.1 图示
- 4.2 LinkedList主要代码解析
- 4.3 测试输出
- 5. 完整代码
- 5.1 邻接表 - Array
- 5.2 邻接表-TreeSet
- 5.3 邻接矩阵-LinkedList
- 5.4 输入文件
1. 代码仓库
https://github.com/Chufeng-Jiang/Graph-Theory/tree/main/src/Chapt01_Adjacency
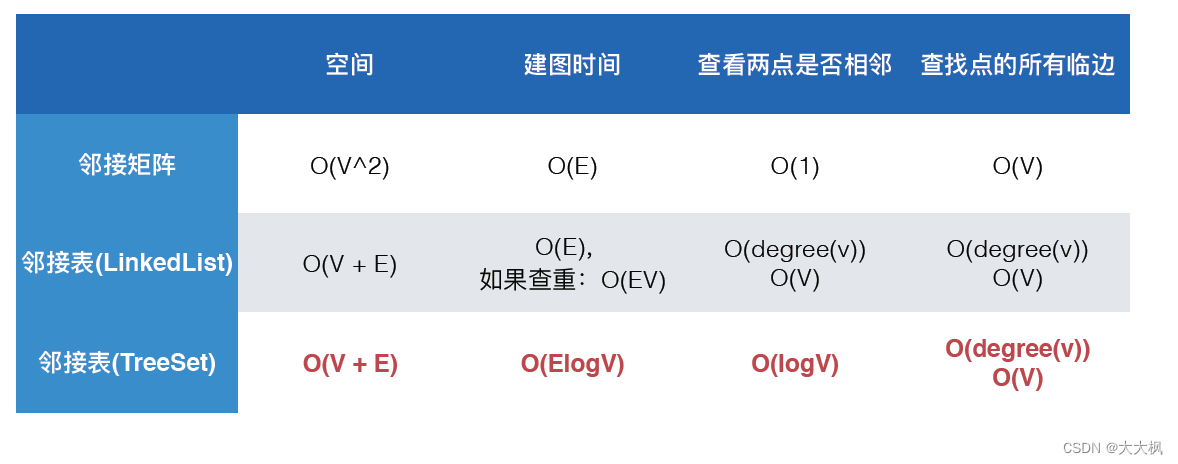
2. 图的基本表示的比较
3. 邻接矩阵:Array和TreeSet
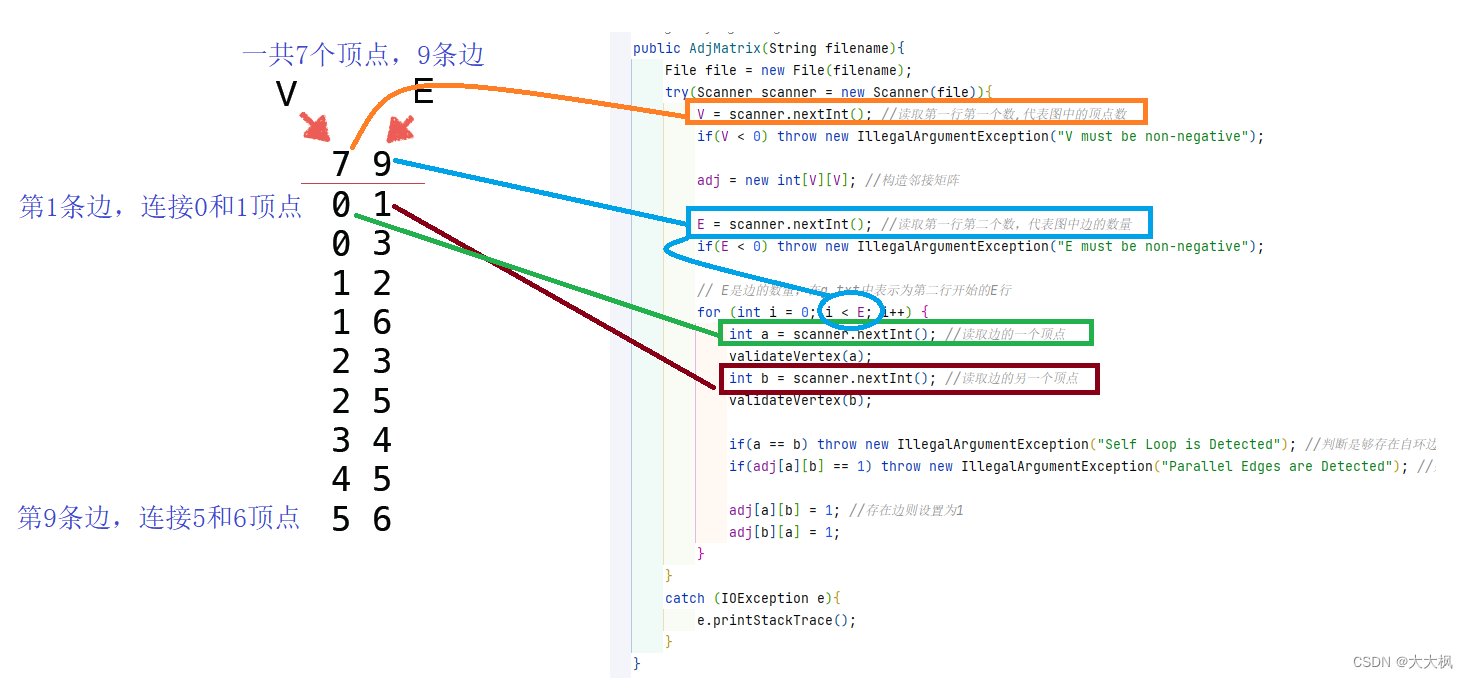
3.1 图示

3.2 Array主要代码解析
代码有删减
public AdjMatrix(String filename){File file = new File(filename);try(Scanner scanner = new Scanner(file)){ V = scanner.nextInt(); //读取第一行第一个数,代表图中的顶点数//构造邻接矩阵adj = new int[V][V]; E = scanner.nextInt(); //读取第一行第二个数,代表图中边的数量// E是边的数量,在g.txt中表示为第二行开始的E行for (int i = 0; i < E; i++) {int a = scanner.nextInt(); //读取边的一个顶点int b = scanner.nextInt(); //读取边的另一个顶点adj[a][b] = 1; //存在边则设置为1adj[b][a] = 1;}}
}
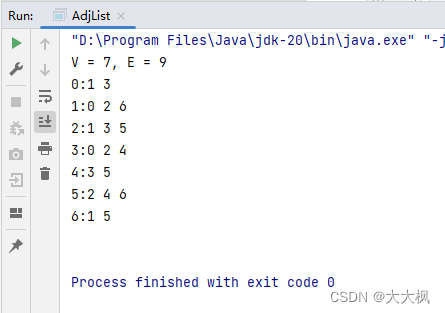
3.3 测试输出
3.4 使用TreeSet的代码
代码有删减
只需要改动一行
adj = new TreeSet[V]; //构造邻接表, V行,V个LinkedList
4. 邻接表:LinkedList
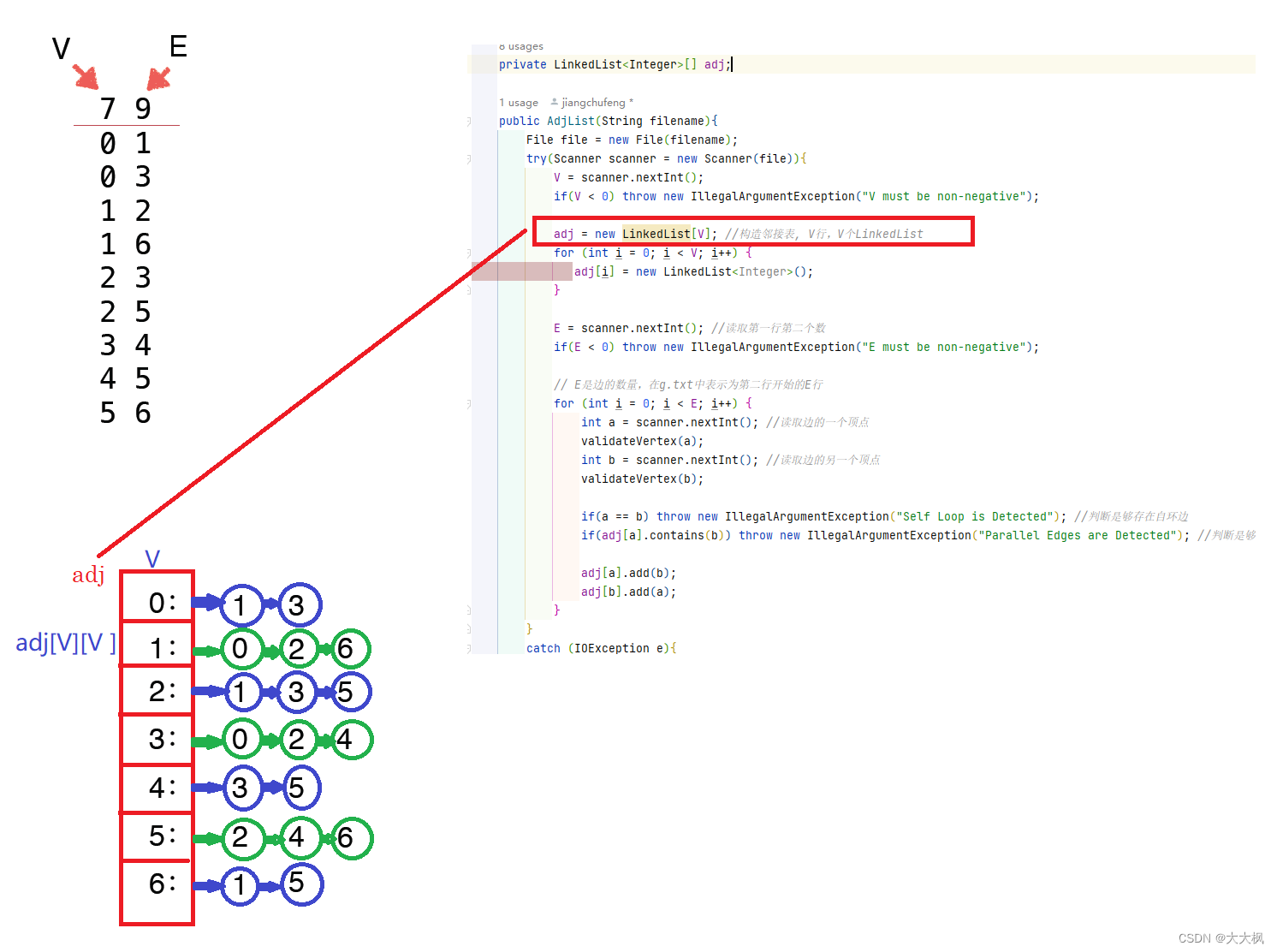
4.1 图示

4.2 LinkedList主要代码解析
代码有删减
public class AdjList {private int V;private int E;private LinkedList<Integer>[] adj;public AdjList(String filename){File file = new File(filename);try(Scanner scanner = new Scanner(file)){V = scanner.nextInt();/*构造邻接表, V行,V个LinkedList*/adj = new LinkedList[V]; for (int i = 0; i < V; i++) {adj[i] = new LinkedList<Integer>();}E = scanner.nextInt(); //读取第一行第二个数// E是边的数量,在g.txt中表示为第二行开始的E行for (int i = 0; i < E; i++) {int a = scanner.nextInt(); //读取边的一个顶点int b = scanner.nextInt(); //读取边的另一个顶点adj[a].add(b);adj[b].add(a);}}}
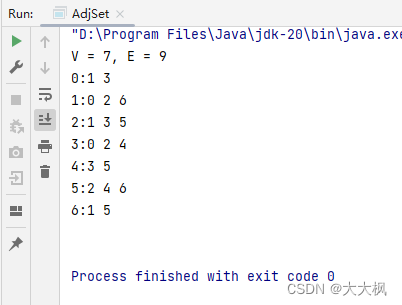
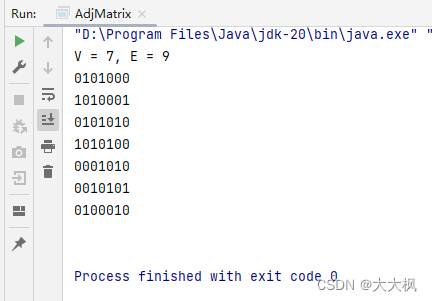
4.3 测试输出
5. 完整代码
5.1 邻接表 - Array
package Chapt01_Adjacency;import java.io.File;
import java.io.IOException;
import java.util.LinkedList;
import java.util.Scanner;public class AdjList {private int V;private int E;private LinkedList<Integer>[] adj;public AdjList(String filename){File file = new File(filename);try(Scanner scanner = new Scanner(file)){V = scanner.nextInt();if(V < 0) throw new IllegalArgumentException("V must be non-negative");adj = new LinkedList[V]; //构造邻接表, V行,V个LinkedListfor (int i = 0; i < V; i++) {adj[i] = new LinkedList<Integer>();}E = scanner.nextInt(); //读取第一行第二个数if(E < 0) throw new IllegalArgumentException("E must be non-negative");// E是边的数量,在g.txt中表示为第二行开始的E行for (int i = 0; i < E; i++) {int a = scanner.nextInt(); //读取边的一个顶点validateVertex(a);int b = scanner.nextInt(); //读取边的另一个顶点validateVertex(b);if(a == b) throw new IllegalArgumentException("Self Loop is Detected"); //判断是够存在自环边if(adj[a].contains(b)) throw new IllegalArgumentException("Parallel Edges are Detected"); //判断是够存在平行l边adj[a].add(b);adj[b].add(a);}}catch (IOException e){e.printStackTrace();}}private void validateVertex(int v){if(v < 0 || v >= V)throw new IllegalArgumentException("vertex" + v + "is invalid");}public int V(){return V;}public int E(){return E;}public boolean hasEdge(int v, int w){validateVertex(v);validateVertex(w);return adj[v].contains(w);}public LinkedList<Integer> adj(int v){validateVertex(v);return adj[v];}public int degree(int v){return adj(v).size();}@Overridepublic String toString(){StringBuilder sb = new StringBuilder();sb.append(String.format("V = %d, E = %d\n", V, E));for (int i = 0; i < V; i++) {sb.append(String.format("%d:",i));for (int w: adj[i]) {sb.append(String.format("%d ",w));}sb.append('\n');}return sb.toString();}public static void main(String[] args){AdjList adjList = new AdjList("g1.txt"); //新建邻接矩阵,并从文件内容初始化System.out.println(adjList);}
}5.2 邻接表-TreeSet
package Chapt01_Adjacency;import java.io.File;
import java.io.IOException;
import java.util.Scanner;
import java.util.TreeSet;public class AdjSet {private int V;private int E;private TreeSet<Integer>[] adj;public AdjSet(String filename){File file = new File(filename);try(Scanner scanner = new Scanner(file)){V = scanner.nextInt();if(V < 0) throw new IllegalArgumentException("V must be non-negative");adj = new TreeSet[V]; //构造邻接表, V行,V个LinkedListfor (int i = 0; i < V; i++) {adj[i] = new TreeSet<Integer>();}E = scanner.nextInt(); //读取第一行第二个数if(E < 0) throw new IllegalArgumentException("E must be non-negative");// E是边的数量,在g.txt中表示为第二行开始的E行for (int i = 0; i < E; i++) {int a = scanner.nextInt(); //读取边的一个顶点validateVertex(a);int b = scanner.nextInt(); //读取边的另一个顶点validateVertex(b);if(a == b) throw new IllegalArgumentException("Self Loop is Detected"); //判断是够存在自环边if(adj[a].contains(b)) throw new IllegalArgumentException("Parallel Edges are Detected"); //判断是够存在平行l边adj[a].add(b);adj[b].add(a);}}catch (IOException e){e.printStackTrace();}}private void validateVertex(int v){if(v < 0 || v >= V)throw new IllegalArgumentException("vertex" + v + "is invalid");}public int V(){return V;}public int E(){return E;}public boolean hasEdge(int v, int w){validateVertex(v);validateVertex(w);return adj[v].contains(w);}public Iterable<Integer> adj(int v){ // 可以是TreeSet,但是数组、链表、红黑树都是实现了Iterable的接口,因此可以统一写成这样validateVertex(v);return adj[v];}public int degree(int v){validateVertex(v);return adj[v].size(); // Iterable没有size()方法}@Overridepublic String toString(){StringBuilder sb = new StringBuilder();sb.append(String.format("V = %d, E = %d\n", V, E));for (int i = 0; i < V; i++) {sb.append(String.format("%d:",i));for (int w: adj[i]) {sb.append(String.format("%d ",w));}sb.append('\n');}return sb.toString();}public static void main(String[] args){AdjSet adjSet = new AdjSet("g1.txt"); //新建邻接矩阵,并从文件内容初始化System.out.println(adjSet);}
}5.3 邻接矩阵-LinkedList
package Chapt01_Adjacency;import java.io.File;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Scanner;public class AdjMatrix {private int V;private int E;private int[][] adj;// 构造函数,从文件内容初始化邻接矩阵public AdjMatrix(String filename){File file = new File(filename);try(Scanner scanner = new Scanner(file)){V = scanner.nextInt(); //读取第一行第一个数,代表图中的顶点数if(V < 0) throw new IllegalArgumentException("V must be non-negative");adj = new int[V][V]; //构造邻接矩阵E = scanner.nextInt(); //读取第一行第二个数,代表图中边的数量if(E < 0) throw new IllegalArgumentException("E must be non-negative");// E是边的数量,在g.txt中表示为第二行开始的E行for (int i = 0; i < E; i++) {int a = scanner.nextInt(); //读取边的一个顶点validateVertex(a);int b = scanner.nextInt(); //读取边的另一个顶点validateVertex(b);if(a == b) throw new IllegalArgumentException("Self Loop is Detected"); //判断是够存在自环边if(adj[a][b] == 1) throw new IllegalArgumentException("Parallel Edges are Detected"); //判断是否存在平行l边adj[a][b] = 1; //存在边则设置为1adj[b][a] = 1;}}catch (IOException e){e.printStackTrace();}}private void validateVertex(int v){if(v < 0 || v >= V)throw new IllegalArgumentException("vertex" + v + "is invalid");}public int V(){return V;}public int E(){return E;}public boolean hasEdge(int v, int w){validateVertex(v);validateVertex(w);return adj[v][w] == 1;}public ArrayList<Integer> adj(int v){validateVertex(v);ArrayList<Integer> res = new ArrayList<>();for (int i = 0; i < V; i++) {if(adj[v][i] == 1) res.add(i);}return res;}public int degree(int v){return adj(v).size(); //adj(v)是上方的adj方法,size()是ArrayList的接口}// 用于在控制台打印该临接矩阵@Overridepublic String toString(){StringBuilder sb = new StringBuilder();sb.append(String.format("V = %d, E = %d\n", V, E)); //打印顶点数和边的数量for (int i = 0; i < V; i++) { //行for (int j = 0; j < V; j++) { //列sb.append(String.format("%d",adj[i][j])); //读取矩阵的值}sb.append('\n'); //行尾换行}return sb.toString(); //返回该邻接矩阵}public static void main(String[] args){AdjMatrix adjMatrix = new AdjMatrix("g1.txt"); //新建邻接矩阵,并从文件内容初始化System.out.println(adjMatrix);}
}5.4 输入文件
7 9
0 1
0 3
1 2
1 6
2 3
2 5
3 4
4 5
5 6相关文章:
图论01-【无权无向】-图的基本表示-邻接矩阵/邻接表
文章目录 1. 代码仓库2. 图的基本表示的比较3. 邻接矩阵:Array和TreeSet3.1 图示3.2 Array主要代码解析3.3 测试输出3.4 使用TreeSet的代码 4. 邻接表:LinkedList4.1 图示4.2 LinkedList主要代码解析4.3 测试输出 5. 完整代码5.1 邻接表 - Array5.2 邻接…...

Bootstrap的列表组相关知识
目录 01-列表组的相关基础知识02-一个简单的列表组示例03-激活或禁用列表组的一行或多行04-设置列表项的颜色05-给列表项添加徽章 01-列表组的相关基础知识 Bootstrap的list-group是一个用于创建列表组件的CSS类,通常用于显示一个项目列表,如导航菜单或…...

Linux简单安装ffmpeg 实现用PHP压缩音频
一、下载安装 1、官方下载地址:Download FFmpeg 2、下载完上传到服务器然 然后解压就算安装完成了 tar -xf ffmpeg-git-amd64-static.tar.xz 3、然后配置一下全局变量(当然也可以不用配置 使用的时候带上文件路径就行) cd /usr/bin ln -s…...
Vue解决 npm -v 报错(一)
报错内容: npm WARN config global --global, --local are deprecated. Use --locationglobal instead. 解决方案: 代码: prefix -g 替换为: prefix --locationglobal 原创作者:吴小糖 创作时间:2023.1…...

IP地址是如何定位的
IP地址定位原理和方法 在互联网时代,了解设备或用户的地理位置对于各种应用和服务至关重要,从广告定向到网络安全。IP地址定位是一种常用的方法,允许确定IP地址背后的实际地理位置。本文将介绍IP地址定位的原理和方法。 IP地址基础…...
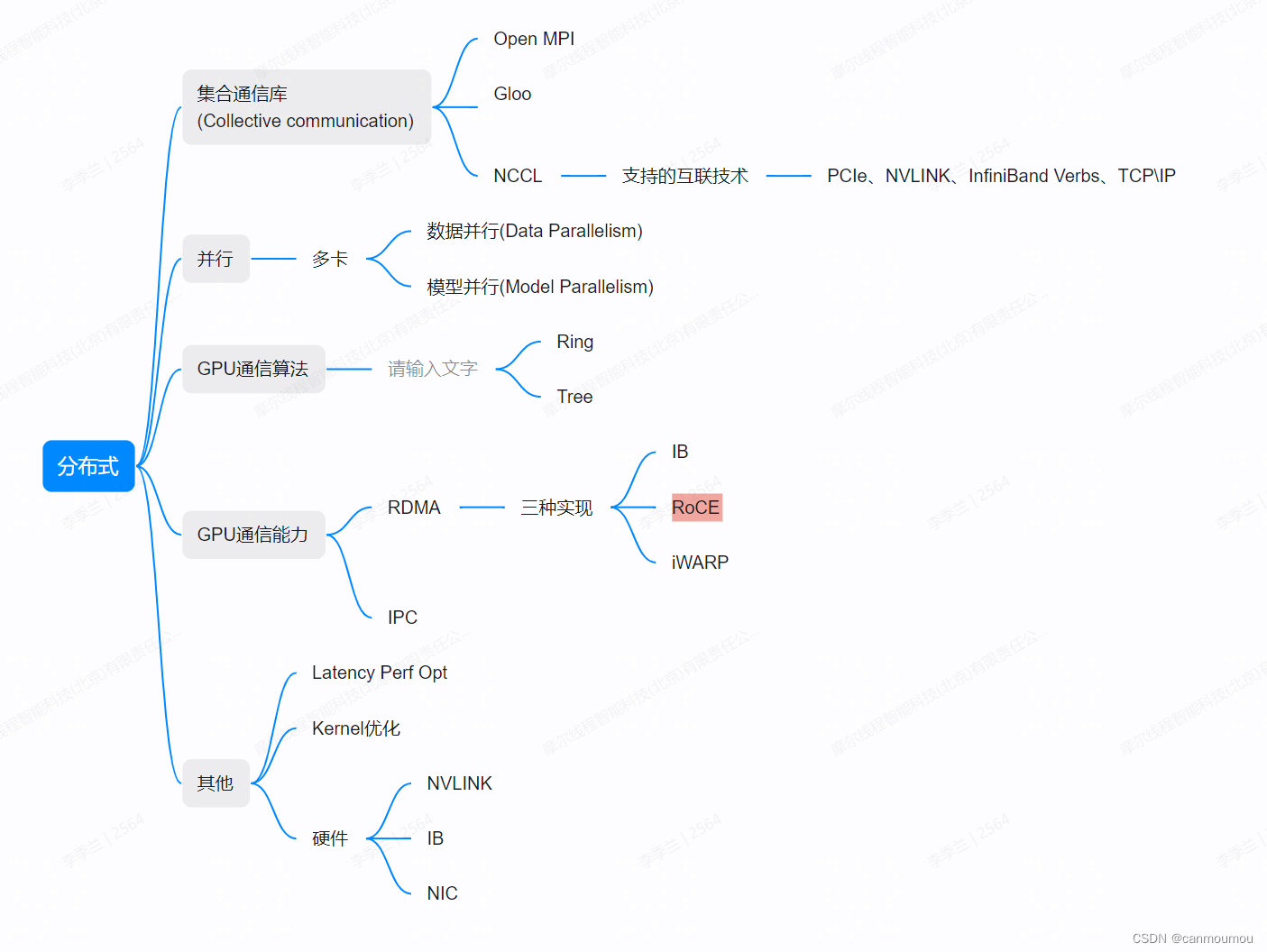
【分布式】入门级NCCL多机并行实践 - 02
# 背景知识 大模型和分布式训练对数据的吞吐量以及并行度都有很高的要求,NCCL就是在这个背景下诞生的。 如果你是一个只会写写Python,调用PyTorch和Horovod的算法萌新,可能对于分布式底层的东西不太了解,在下岗热潮中被主管逼着…...

Rust的模式匹配
文章目录 match匹配if let匹配 match匹配 match可以结合枚举使用,例如 enum IpVersion {V4,V6, }fn ParseIpVersion(version: IpVersion) -> String {match version {IpVersion::V4 > String::from("ipv4"),IpVersion::V6 > String::from(&quo…...
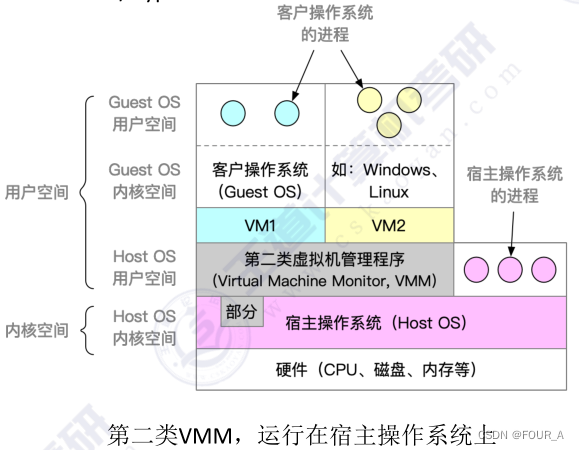
操作系统【OS】虚拟机
定义 使用虚拟化技术,将一台物理机器虚化为多台虚拟机器VM,每个虚拟机器都可用独立运行一个操作系统 分类 传统计算机 第一类VMM 第二类VMM...

不写代码、构建一个开源的 ChatGPT,总共需要几步?|Hugging News #1020
每一周,我们的同事都会向社区的成员们发布一些关于 Hugging Face 相关的更新,包括我们的产品和平台更新、社区活动、学习资源和内容更新、开源库和模型更新等,我们将其称之为「Hugging News」。本期 Hugging News 有哪些有趣的消息࿰…...
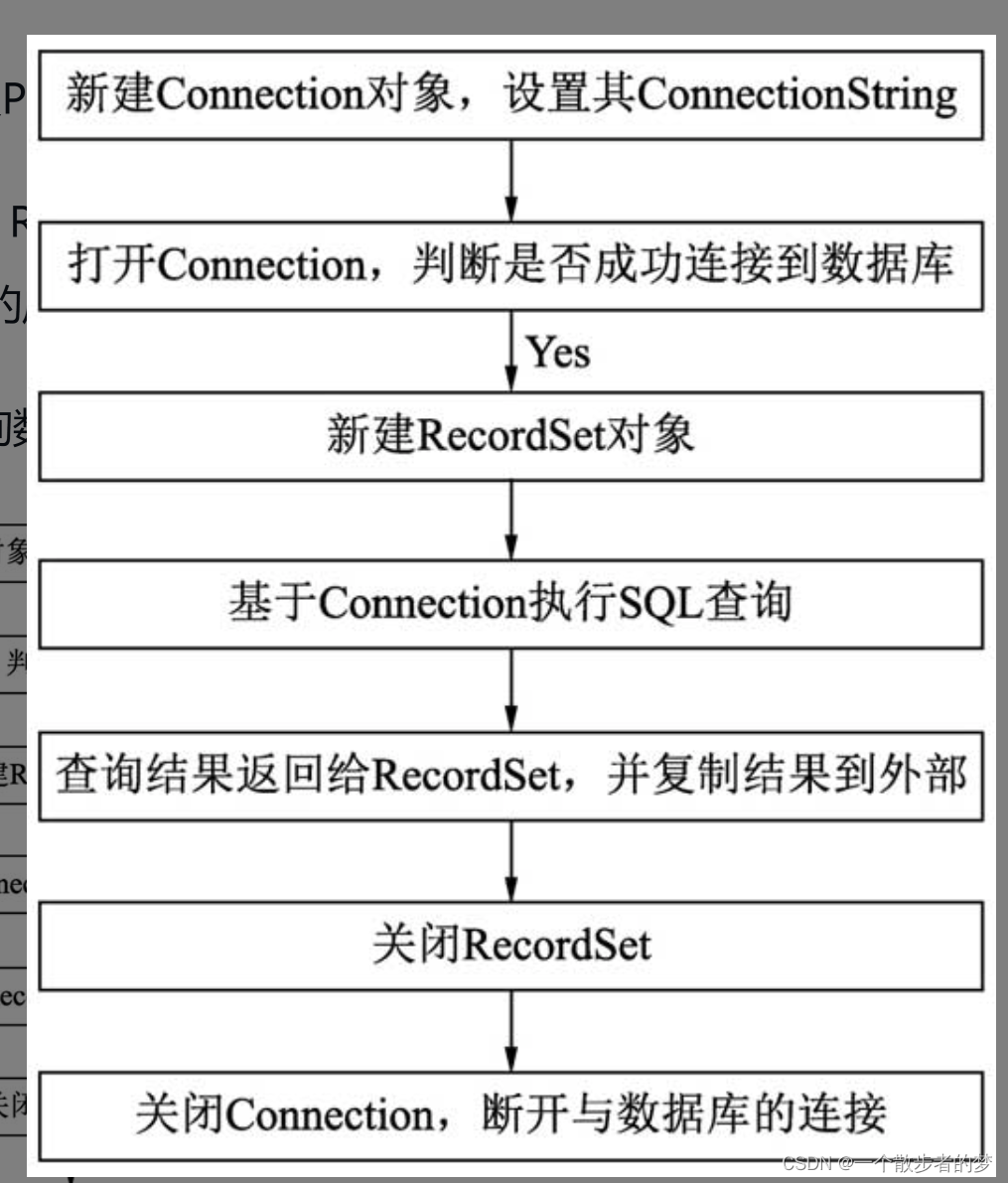
VBA操作数据库
相关背景: 对于数据分析同学,一般SQL,EXCEL是必备技能,但对于VBA和Python可能有的同学不会;在处理本地数据上(诸如excel、txt|csv文本),后续尝试使用VBA或者Python写一个sql查询的GUI界面&…...

【华为OD机试】HJ26 字符串排序
描述 编写一个程序,将输入字符串中的字符按如下规则排序。 规则 1 :英文字母从 A 到 Z 排列,不区分大小写。 如,输入: Type 输出: epTy 规则 2 :同一个英文字母的大小写同时存在时,…...
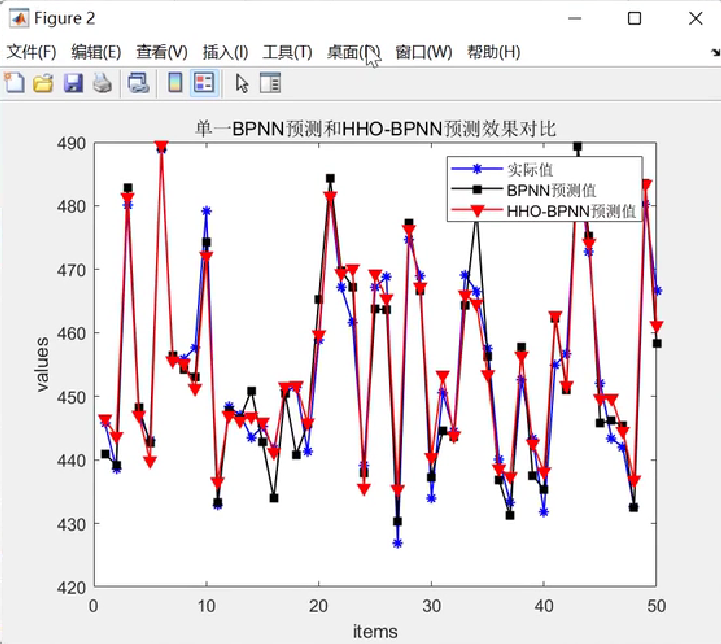
哈里斯鹰算法优化BP神经网络(HHO-BP)回归预测研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
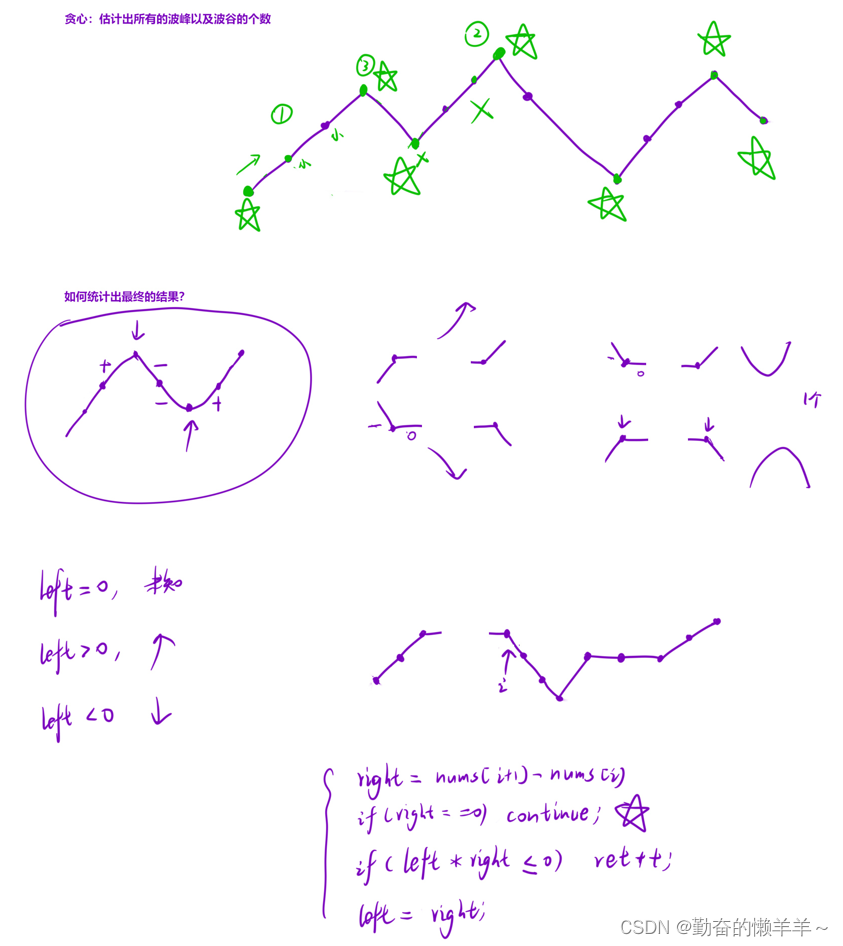
摆动序列【贪心4】
题目 分析 代码 class Solution { public:int wiggleMaxLength(vector<int>& nums) {if(nums.size() < 2) return nums.size();int ret 0,left 0,right 0;for(int i 0;i < nums.size()-1;i){right nums[i1] - nums[i];if(right 0) continue;if(left …...
Youtrack Linux 安装
我们考虑最后应该使用的是 ZIP 方式的安装。 按照官方的说法如何设置运行 YouTrack 应该是非常简单的。 准备环境 根据官方的说法,我们需要做的就是下载 Zip 包,然后把 Zip 包解压到指定的目录中就可以了。 下载 当前官方的下载地址为:Ge…...

分类预测 | MATLAB实现SSA-CNN-LSTM麻雀算法优化卷积长短期记忆神经网络数据分类预测
分类预测 | MATLAB实现SSA-CNN-LSTM麻雀算法优化卷积长短期记忆神经网络数据分类预测 目录 分类预测 | MATLAB实现SSA-CNN-LSTM麻雀算法优化卷积长短期记忆神经网络数据分类预测分类效果基本描述程序设计参考资料 分类效果 基本描述 1.MATLAB实现SSA-CNN-LSTM数据分类预测&…...

飞书-多维文档-计算时间差
1. 选择字段类型 如图所示,字段类型选择 公式 2. 编辑公式 单击 公式编辑器 在弹出的公式编辑框中输入公式 TEXT([终结时间]-[开始时间],"HH:MM") [终结时间] 和 [开始时间] 请替换成你的表格中对应的字段名称HH:MM 表示输出的时间格式为 时:分其中 “…...

【文献copilot】调用文心一言api对论文逐段总结
文献copilot:调用文心一言api对论文逐段总结 当我读文献的时候,感觉读得太慢了,看翻译软件翻译的又觉得翻译的不好。于是我就写了个程序辅助我读文献,它可以逐段总结,输出格式是:原文一句话总结分段总结&a…...
编译安装Nginx+GeoIP2自动更新+防盗链+防爬虫+限制访问速度+限制连接数
此文章是Nginx的GeoIP2模块和MaxMind国家IP库相互结合,达到客户端IP访问的一个数据记录以及分析,同时还针对一些业务需求做出对Nginx中间件的控制,如:防盗链、防爬虫、限制访问速度、限制连接数等 该篇文章是从一个热爱搞技术的博…...

基于JAVA+SpringBoot+UniApp+Vue的前后端分离的手机移动端图书借阅平台
✌全网粉丝20W,csdn特邀作者、博客专家、CSDN新星计划导师、java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取项目下载方式🍅 一、项目背景介绍: 随着社会信息化的快速…...
华为云CodeArts IDE for Java安装使用教程
本篇内容主要介绍使用华为云CodeArts IDE for Java创建工程、代码补全、运行调试代码、Build构建和测试相关的主要功能。 一、下载安装华为云CodeArts IDE for Java 华为云CodeArts IDE for Java安装要求 至少需要 2 GB RAM ,但是推荐8 GB RAM; 至少需要 2.5 GB 硬…...

英语前缀发音总结
第一类:绝大多数普通前缀 对重音的影响:无影响,单词重音仍落在词根上 规律说明:这类前缀不改变词根原有的重音位置。重音通常落在紧接前缀之后的第一个音节(即词根的第一音节)上,前缀本身读作非重读音节,元音常弱化为 /ə/ 或 /ɪ/。 前缀 音标 含义 示例单词 a- /ə…...

毕业季不熬夜:如何用百考通AI高效、规范地搞定你的毕业论文
又到一年毕业季,宿舍的灯总是亮到深夜。屏幕上的空白文档、散落满桌的文献、导师反复的修改意见,以及永远对不上的格式要求……这些场景几乎是每位毕业生的共同记忆。很多时候,阻碍你进度的并不是缺乏思路,而是没人告诉你&…...

深入解析Claude Code:AI编程助手架构、工具系统与安全实践
1. 项目概述与核心价值最近在深入研究AI编程助手领域,特别是那些能够真正理解代码上下文、执行复杂任务并自主学习的智能体(Agent)。在这个过程中,我系统性地拆解和分析了当前市面上一个极具代表性的项目——Claude Code。这不仅仅…...

如何实现SQL简单数据的映射查询_使用CASE表达式替换
CASE表达式在SQL中用于值映射最直接高效,推荐使用搜索型CASE显式处理NULL,避免WHERE中嵌套导致索引失效,聚合统计时优先用COUNT(CASE WHEN...),慎用嵌套及跨库函数。CASE 表达式在 SELECT 中做值映射最直接想把数据库里某个字段的…...
)
容器日志还在切窗口查?VSCode 2026实时查看已支持结构化JSON高亮+错误自动聚类(仅限Insiders 2026.2+)
更多请点击: https://intelliparadigm.com 第一章:VSCode 2026容器日志实时查看功能概览 VSCode 2026 引入了原生集成的容器日志流式监听机制,无需额外安装扩展即可在内置终端或专用日志面板中实时捕获 Docker、Podman 及 Kubernetes Pod 的…...

TV Bro:专为电视遥控器优化的智能浏览器,彻底改变大屏上网体验
TV Bro:专为电视遥控器优化的智能浏览器,彻底改变大屏上网体验 【免费下载链接】tv-bro Simple web browser for android optimized to use with TV remote 项目地址: https://gitcode.com/gh_mirrors/tv/tv-bro 还在为智能电视上网的糟糕体验而烦…...

Kohya_SS:如何零基础掌握AI绘画模型定制技术?
Kohya_SS:如何零基础掌握AI绘画模型定制技术? 【免费下载链接】kohya_ss 项目地址: https://gitcode.com/GitHub_Trending/ko/kohya_ss 你是否曾想过拥有属于自己的AI绘画风格?是否希望训练出能理解你独特创作需求的扩散模型…...

51PR媒体发布平台整合近10万媒体资源,助力企业高效发稿
上海众效科技有限公司旗下51PR媒体发布平台(网站备案名称:媒体发布平台)整合了主流媒体、门户网站、自媒体、短视频媒体等近10万媒体资源,为企业提供一站式新闻稿发布服务,帮助品牌高效构建传播矩阵、快速提升品牌声量…...

【路径规划】基于融合改进A星-麻雀搜索算法求解六边形栅格地图路径规划
✅作者简介:热爱数据处理、数学建模、仿真设计、论文复现、算法创新的Matlab仿真开发者。🍎更多Matlab代码及仿真咨询内容点击主页 🔗:Matlab科研工作室🍊个人信条:格物致知,期刊达人。&#…...

ncmdump终极指南:快速免费解密网易云NCM音乐格式
ncmdump终极指南:快速免费解密网易云NCM音乐格式 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 你是否曾经在网易云音乐下载了喜欢的歌曲,却发现只能在特定平台播放?当你尝试在其他设备或播放器上…...