MXNet中使用双向循环神经网络BiRNN对文本进行情感分类<改进版>
在上一节的情感分类当中,有些评论是负面的,但预测的结果是正面的,比如,"this movie was shit"这部电影是狗屎,很明显就是对这部电影极不友好的评价,属于负类评价,给出的却是positive。
所以这节我们通过专门的“分词”和“扩大词向量维度”这两个途径来改进,提高预测的准确率。
spaCy分词
我们用spaCy分词工具来进行分词看是否能提高准确性。
推荐带上镜像站点来下载并安装。
pip install spacy -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.comimport spacy
>>> spacy.__version__
'3.0.9'安装英文包
python -m spacy download en这种方法我没有安装成功,于是我选择直接下载安装,感觉太慢选择迅雷下载:https://github.com/explosion/spacy-models/releases/download/en_core_web_sm-3.0.0/en_core_web_sm-3.0.0-py3-none-any.whl
或者:
pip install https://github.com/explosion/spacy-models/releases/download/en_core_web_sm-3.0.0/en_core_web_sm-3.0.0-py3-none-any.whl这里选择的是en_core_web_sm语言包,所以也可以直接选择豆瓣镜像下载《推荐这种方法》
pip install en_core_web_sm-3.0.0-py3-none-any.whl -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com安装好之后,就可以通过spacy来加载这个英文包
spacy_en = spacy.load("en_core_web_sm")
>>> spacy_en._path
WindowsPath('D:/Anaconda3/envs/pygpu/lib/site-packages/en_core_web_sm/en_core_web_sm-3.0.0')然后进行分词,将上一节或者说自带的get_tokenized_imdb函数修改下,使用修改的这个函数:
def get_tokenized_imdb(data):def tokenizer(text):return [tok.text for tok in spacy_en.tokenizer(text)]return [tokenizer(review) for review, _ in data]我们训练看下效果如何:
print(d2l.predict_sentiment(net, vocab, ["this", "movie", "was", "shit"]))
print(d2l.predict_sentiment(net, vocab, ["this", "movie", "is", "not", "good"]))
print(d2l.predict_sentiment(net, vocab, ["this", "movie", "is", "so", "bad"]))
'''
training on [gpu(0)]
epoch 1, loss 0.5781, train acc 0.692, test acc 0.781, time 66.0 sec
epoch 2, loss 0.4024, train acc 0.822, test acc 0.839, time 65.4 sec
epoch 3, loss 0.3465, train acc 0.852, test acc 0.844, time 65.6 sec
epoch 4, loss 0.3227, train acc 0.861, test acc 0.856, time 65.9 sec
epoch 5, loss 0.2814, train acc 0.880, test acc 0.859, time 66.2 sec
negative
positive
negative
'''可以看到准确率有提高,而且第一条影评在上一节预测是positive,这里预测为negative,正确识别了这条影评的负类评价。第二条影评的预测错误了,说明没有识别出not good属于负类评价,接下来我们再叠加一个方法来提高准确率。
300维度的词向量
我们将预处理文件的词向量从100维度提高到300维度看下准确度有没有上升,也就是选择glove.6B.300d.txt来替换glove.6B.100d.txt
glove_embedding = text.embedding.create("glove", pretrained_file_name="glove.6B.300d.txt", vocabulary=vocab
)选择更高维度的词向量文档之后,我们做下训练测试看下:
print(d2l.predict_sentiment(net, vocab, ["this", "movie", "was", "shit"]))
print(d2l.predict_sentiment(net, vocab, ["this", "movie", "is", "not", "good"]))
print(d2l.predict_sentiment(net, vocab, ["this", "movie", "is", "so", "bad"]))
print(d2l.predict_sentiment(net, vocab, ["this", "movie", "is", "so", "good"]))
'''
training on [gpu(0)]
epoch 1, loss 0.5186, train acc 0.734, test acc 0.842, time 74.7 sec
epoch 2, loss 0.3411, train acc 0.854, test acc 0.862, time 74.8 sec
epoch 3, loss 0.2851, train acc 0.884, test acc 0.863, time 75.6 sec
epoch 4, loss 0.2459, train acc 0.903, test acc 0.843, time 75.3 sec
epoch 5, loss 0.2099, train acc 0.917, test acc 0.853, time 75.8 sec
negative
negative
negative
positive
'''准确度再次有了提升,四条影评都被正确识别了情绪。
全部代码
import collections
import d2lzh as d2l
from mxnet import gluon, init, nd
from mxnet.contrib import text
from mxnet.gluon import data as gdata, loss as gloss, nn, rnn
import spacy#spacy_en = spacy.load("en")
spacy_en = spacy.load("en_core_web_sm")def get_tokenized_imdb(data):def tokenizer(text):return [tok.text for tok in spacy_en.tokenizer(text)]return [tokenizer(review) for review, _ in data]def get_vocab_imdb(data):"""Get the vocab for the IMDB data set for sentiment analysis."""tokenized_data = get_tokenized_imdb(data)counter = collections.Counter([tk for st in tokenized_data for tk in st])return text.vocab.Vocabulary(counter, min_freq=5, reserved_tokens=["<pad>"])# d2l.download_imdb(data_dir='data')
train_data, test_data = d2l.read_imdb("train"), d2l.read_imdb("test")
tokenized_data = get_tokenized_imdb(train_data)
vocab = get_vocab_imdb(train_data)
features, labels = d2l.preprocess_imdb(train_data, vocab)
batch_size = 64
# train_set = gdata.ArrayDataset(*d2l.preprocess_imdb(train_data, vocab))
train_set = gdata.ArrayDataset(*[features, labels])
test_set = gdata.ArrayDataset(*d2l.preprocess_imdb(test_data, vocab))
train_iter = gdata.DataLoader(train_set, batch_size, shuffle=True)
test_ieter = gdata.DataLoader(test_set, batch_size)"""
for X,y in train_iter:print(X.shape,y.shape)break
"""class BiRNN(nn.Block):def __init__(self, vocab, embed_size, num_hiddens, num_layers, **kwargs):super(BiRNN, self).__init__(**kwargs)# 词嵌入层self.embedding = nn.Embedding(input_dim=len(vocab), output_dim=embed_size)# bidirectional设为True就是双向循环神经网络self.encoder = rnn.LSTM(hidden_size=num_hiddens,num_layers=num_layers,bidirectional=True,input_size=embed_size,)self.decoder = nn.Dense(2)def forward(self, inputs):# LSTM需要序列长度(词数)作为第一维,所以inputs[形状为:(批量大小,词数)]需做转置# 输出就是(词数,批量大小,词向量维度)(500, 64, 100)->全连接层之后的形状(5,1,100)embeddings = self.embedding(inputs.T)# 双向循环所以乘以2(词数,批量大小,词向量维度*2)(500, 64, 200)->全连接层之后的形状(5,1,200)outputs = self.encoder(embeddings)# 将初始时间步和最终时间步的隐藏状态作为全连接层输入# (64, 400)->全连接层之后的形状(1,400)encoding = nd.concat(outputs[0], outputs[-1])outs = self.decoder(encoding)return outs# 创建一个含2个隐藏层的双向循环神经网络
embed_size, num_hiddens, num_layers, ctx = 300, 100, 2, d2l.try_all_gpus()
net = BiRNN(vocab=vocab, embed_size=embed_size, num_hiddens=num_hiddens, num_layers=num_layers
)
net.initialize(init.Xavier(), ctx=ctx)glove_embedding = text.embedding.create("glove", pretrained_file_name="glove.6B.300d.txt", vocabulary=vocab
)
net.embedding.weight.set_data(glove_embedding.idx_to_vec)
net.embedding.collect_params().setattr("grad_req", "null")lr, num_epochs = 0.01, 5
trainer = gluon.Trainer(net.collect_params(), "adam", {"learning_rate": lr})
loss = gloss.SoftmaxCrossEntropyLoss()
d2l.train(train_iter, test_ieter, net, loss, trainer, ctx, num_epochs)print(d2l.predict_sentiment(net, vocab, ["this", "movie", "was", "shit"]))
print(d2l.predict_sentiment(net, vocab, ["this", "movie", "is", "not", "good"]))
print(d2l.predict_sentiment(net, vocab, ["this", "movie", "is", "so", "bad"]))
print(d2l.predict_sentiment(net, vocab, ["this", "movie", "is", "so", "good"]))其中需要注意的是embed_size的大小需设定为300,跟新选择的文件的词向量维度保持一致。
小结:从目前实验结果来看对词语的分词做的更好,对于理解词义是很有帮助的,另外将词映射成的向量维度越高,准确度也在提升。
相关文章:

MXNet中使用双向循环神经网络BiRNN对文本进行情感分类<改进版>
在上一节的情感分类当中,有些评论是负面的,但预测的结果是正面的,比如,"this movie was shit"这部电影是狗屎,很明显就是对这部电影极不友好的评价,属于负类评价,给出的却是positive。…...
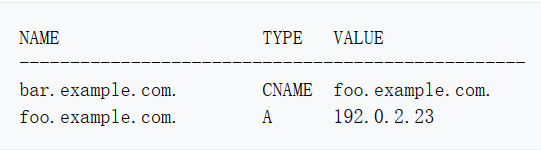
DNS 域名解析
介绍域名 网域名称(英语:Domain Name,简称:Domain),简称域名、网域。 域名是互联网上某一台计算机或计算机组的名称。 域名可以说是一个 IP 地址的代称,目的是为了便于记忆。例如,…...
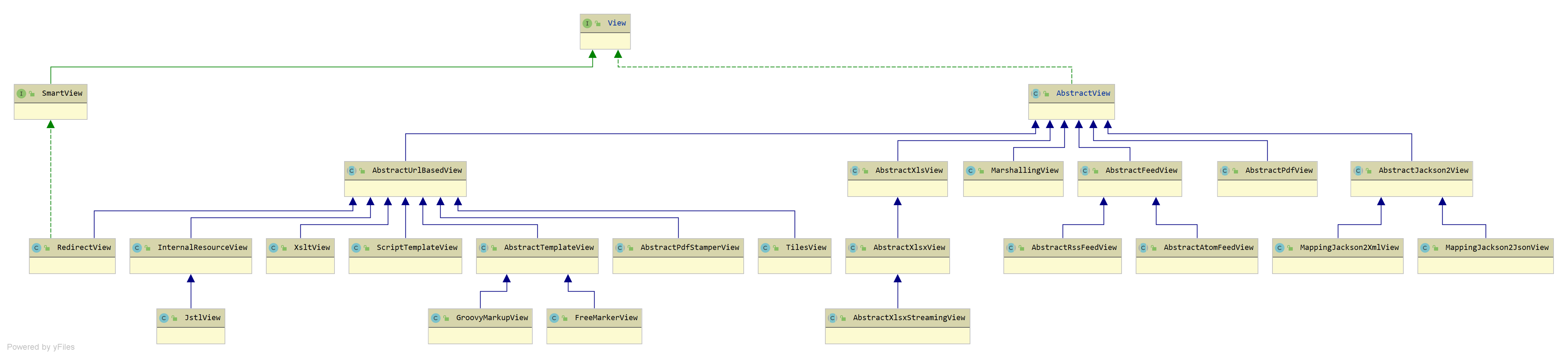
Spring MVC 源码- ViewResolver 组件
ViewResolver 组件ViewResolver 组件,视图解析器,根据视图名和国际化,获得最终的视图 View 对象回顾先来回顾一下在 DispatcherServlet 中处理请求的过程中哪里使用到 ViewResolver 组件,可以回到《一个请求响应的旅行过程》中的 …...
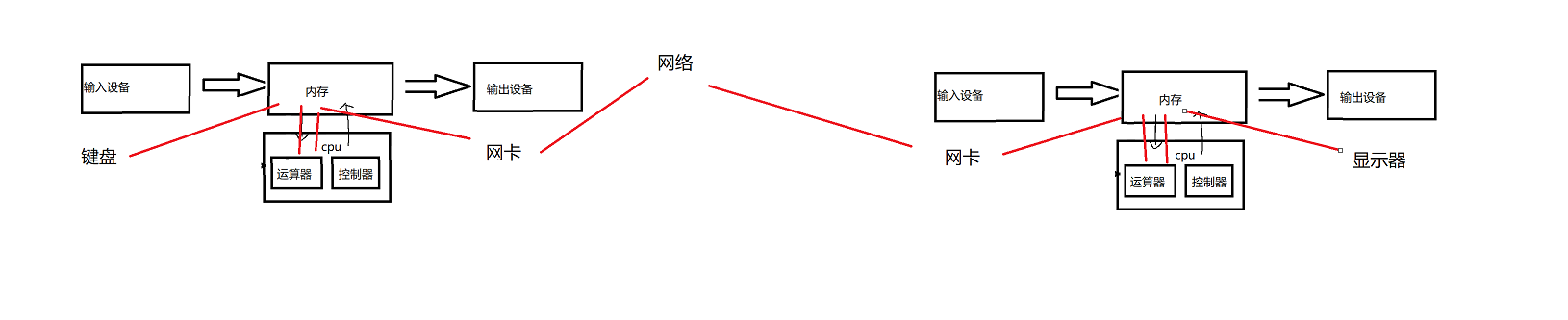
【Hello Linux】初识冯诺伊曼体系
作者:小萌新 专栏:Linux 作者简介:大二学生 希望能和大家一起进步! 本篇博客简介:简单介绍冯诺伊曼体系 冯诺伊曼体系 冯诺伊曼体系结构的合理性 我们在Linux的第一篇博客中讲解了第一台计算机的发明是为了解决导弹的…...

mysql索引,主从多个核心主题去探索问题。
网上收集不错的优化方案 事务 mvcc 详讲 详讲 索引 索引概念 MySQL官方对索引的定义为:索引(index)是帮助MySQL高效获取数据的数据结构(有序)。在数据之外,数据 库系统还维护者满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据, 这样就可以在这些数 据…...
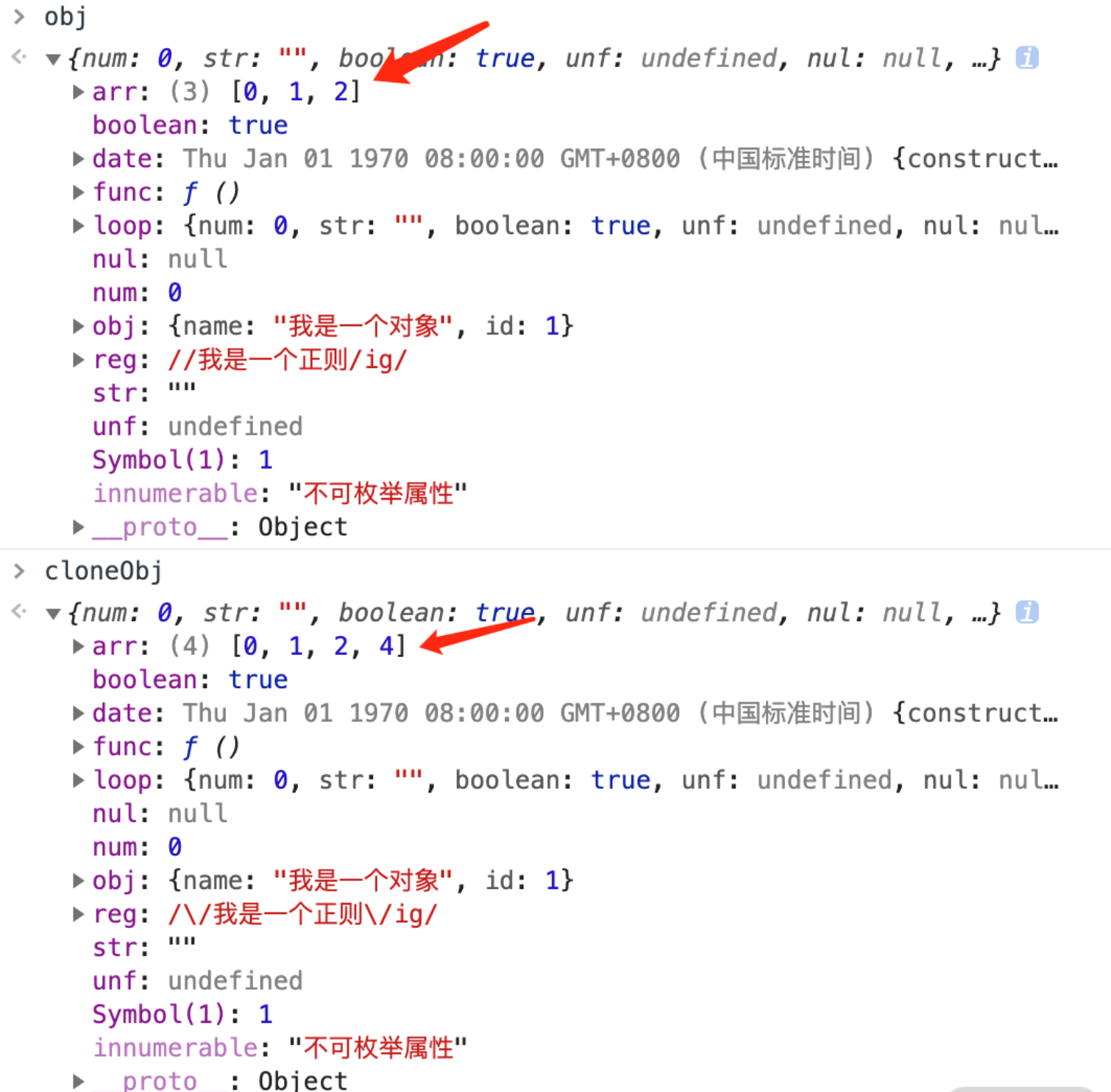
前端一面必会面试题(边面边更)
哪些情况会导致内存泄漏 以下四种情况会造成内存的泄漏: 意外的全局变量: 由于使用未声明的变量,而意外的创建了一个全局变量,而使这个变量一直留在内存中无法被回收。被遗忘的计时器或回调函数: 设置了 setInterval…...
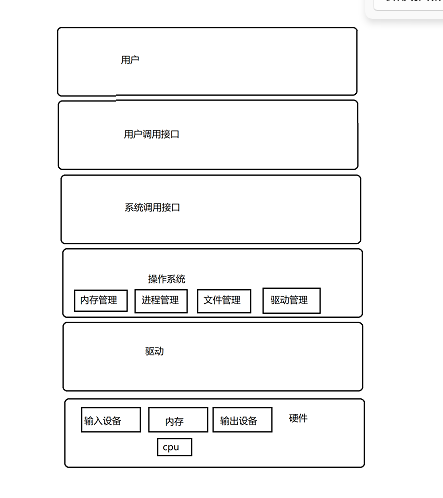
【Hello Linux】初识操作系统
作者:小萌新 专栏:Linux 作者简介:大二学生 希望能和大家一起进步! 本篇博客简介:简单介绍下操作系统的概念 操作系统 操作系统是什么? 操作系统是管理软硬件资源的软件 为什么要设计操作系统 为什么要设…...

完美的vue3动态渲染菜单路由全程
前言: 首先,我们需要知道,动态路由菜单并非一开始就写好的,而是用户登录之后获取的路由菜单再进行渲染,从而可以起到资源节约何最大程度的保护系统的安全性。 需要配合后端,如果后端的值不匹配࿰…...
)
2023年CDGA考试模拟题库(301-400)
2023年CDGA考试模拟题库(301-400) 300.无附加价值的信息通常也不会被删除,因为:[1分] A.它不应该被移除,所有数据都是有价值的 B.我们可能在以后的某个阶段需更这些信息 C.规程中不明确是否应该保留 D.数据是一种资产它很可能在未来被认为是有价值的 E.规程中不明确哪些是…...

Linux-常见命令
🚜关注博主:翻斗花园代码手牛爷爷 🚙Gitee仓库:牛爷爷爱写代码 目录🚒xshell热键🚗Linux基本命令🚗ls指令🚕pwd指令🚖cd指令🚌touch指令🚍mkdir指…...

2.25测试对象分类
一.按照测试对象划分1.界面测试又称UI测试,按照界面的需求(一般是ui设计稿)和界面的设计规则,对我们软件界面所展示的全部内容进行测试和检查.对于非软件来说:颜色,大小,材质,整体是否美观对于软件来说:输入框,按钮,文字,图片...的尺寸,颜色,形状,整体适配,清晰度等等,2.可靠性…...

【Zabbix实战之部署篇】Zabbix客户端的安装部署方法
【Zabbix实战之部署篇】Zabbix客户端的安装部署方法 一、Zabbix-agent2介绍1.Zabbix-agent2简介2.Zabbix-agent2优点3.主动模式和被动模式二、环境规划1.Zabbix服务器部署链接2.IP规划三、配置客户端系统环境1.关闭selinux2.放行端口或关闭防火墙四、安装zabbix-agent21.下载za…...
【CSS】CSS 层叠样式表 ② ( CSS 引入方式 - 内嵌样式 )
文章目录一、CSS 引入方式 - 内嵌样式1、内嵌样式语法2、内嵌样式示例3、内嵌样式完整代码示例4、内嵌样式运行效果一、CSS 引入方式 - 内嵌样式 1、内嵌样式语法 CSS 内嵌样式 , 一般将 CSS 样式写在 HTML 的 head 标签中 ; CSS 内嵌样式 语法如下 : <head><style …...

MySQL事务与索引
MySQL事务与索引 一、事务 1、事务简介 在 MySQL 中只有使用了 Innodb 数据库引擎的数据库或表才支持事务。事务处理可以用来维护数据库的完整性,保证成批的 SQL 语句要么全部执行,要么全部不执行。事务用来管理 insert,update,delete 语句 事务特性…...
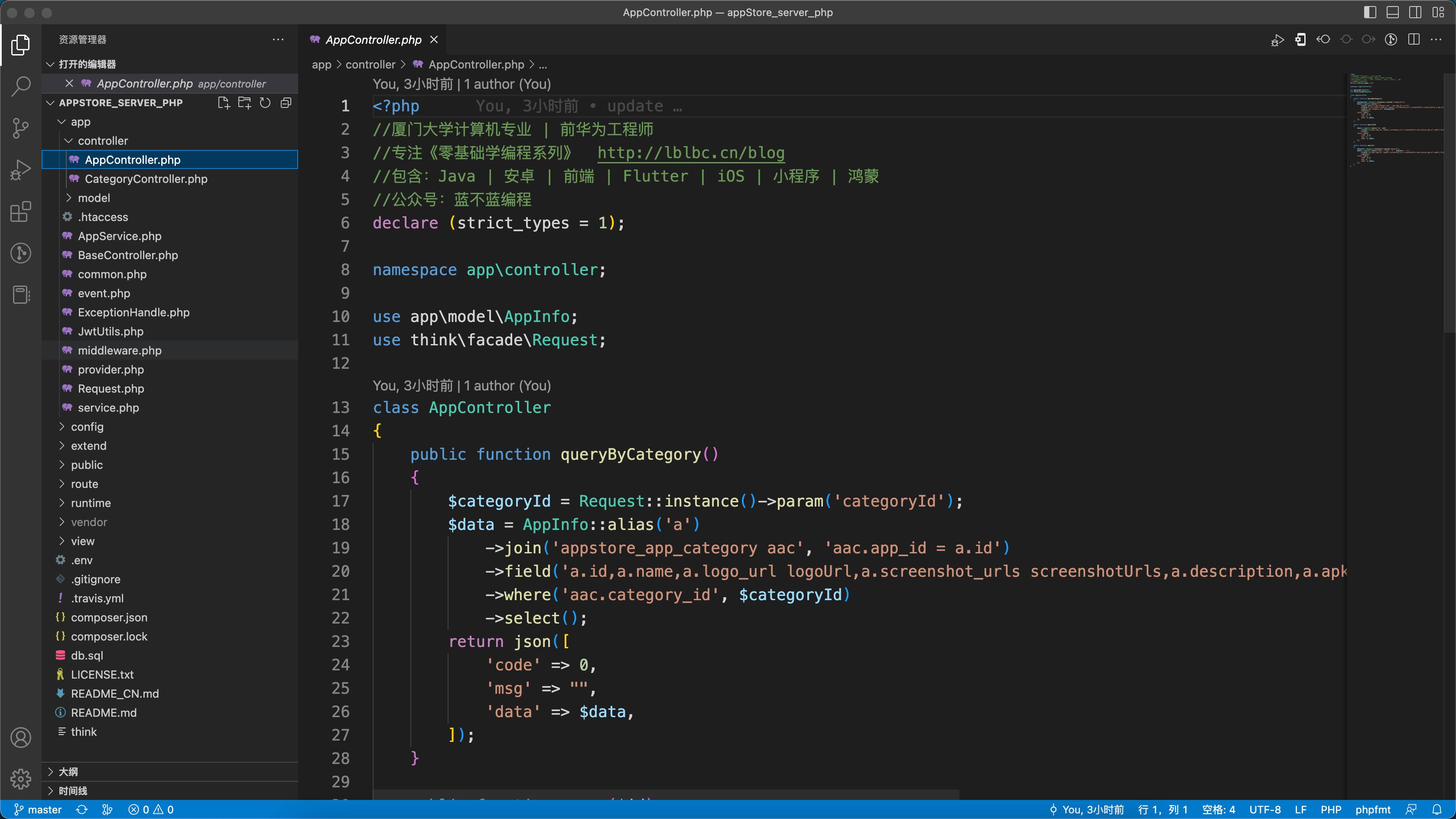
【编程入门】应用市场(php版)
背景 前面已输出多个系列: 《十余种编程语言做个计算器》 《十余种编程语言写2048小游戏》 《17种编程语言10种排序算法》 《十余种编程语言写博客系统》 《十余种编程语言写云笔记》 《N种编程语言做个记事本》 目标 为编程初学者打造入门学习项目,使…...
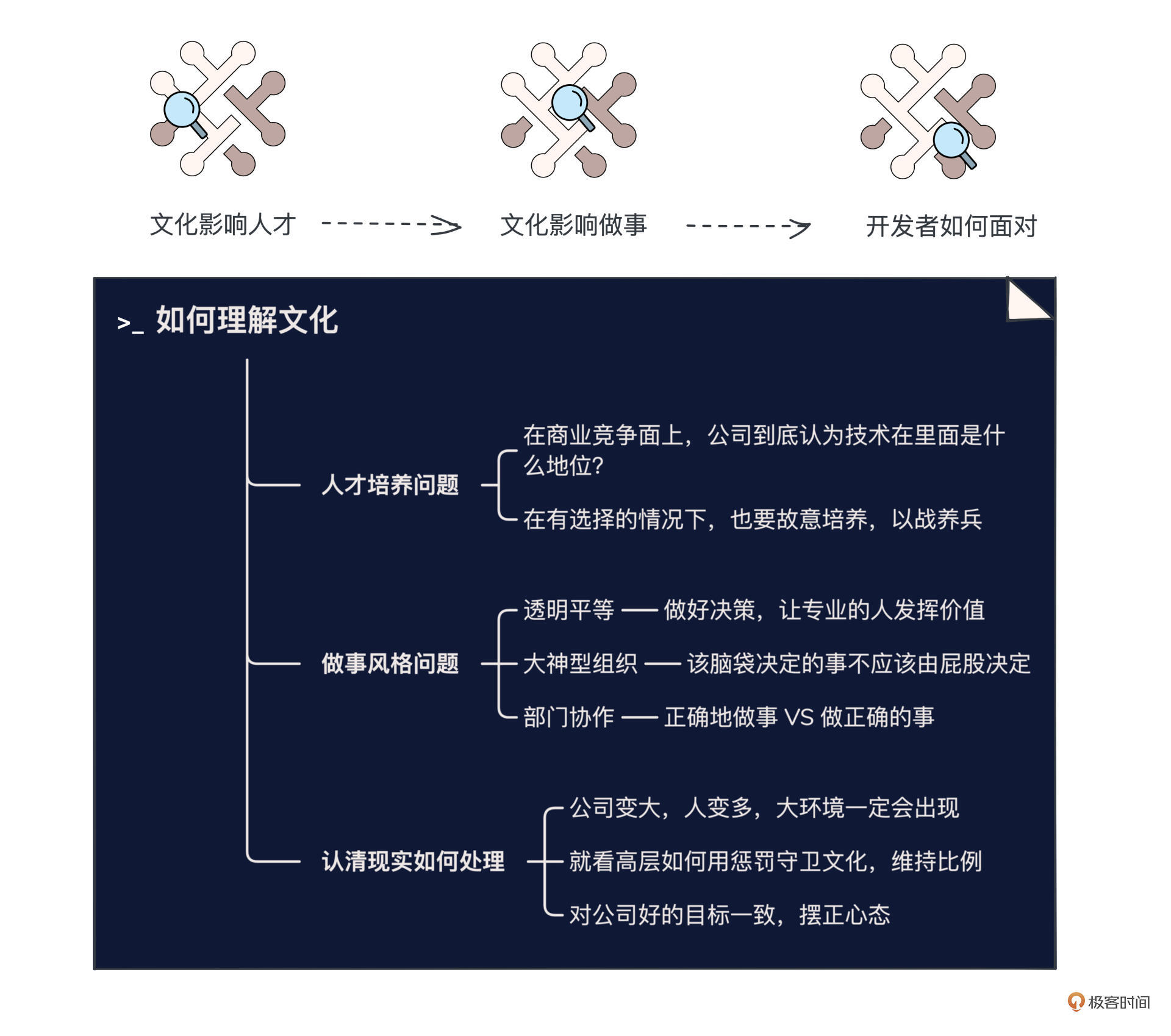
文化:你所在的团队,有多少人敢讲真话?
你好,我是叶芊。 今天我们要讨论的话题是文化,说“文化”这个词你可能会觉得很虚,那我们换个词——“做事风格”,这就和你们团队平时的协作习惯密切相关了。 做事风格,往小了讲,会影响团队成员对开会的认知…...

Linux | 项目自动化构建工具 - make/Makefile
make / Makefile一、前言二、make/Makefile背景介绍1、Makefile是干什么的?2、make又是什么?三、demo实现【见见猪跑🐖】三、依赖关系与依赖方法1、概念理清2、感性理解【父与子】3、深层理解【程序的翻译环境 栈的原理】四、多学一招&#…...

Spring源码该如何阅读?十年架构师带来的Spring源码解析千万不要错过!
写在前面最近学习了一句话,感觉自己的世界瞬间明朗,不再那么紧张焦虑恐慌,同样推荐给大家,希望我们都终有所得。“如果一个人不是发自内心地想要做一件事情,那么,他是无法改变自己的人生的。” 同样这句话用…...
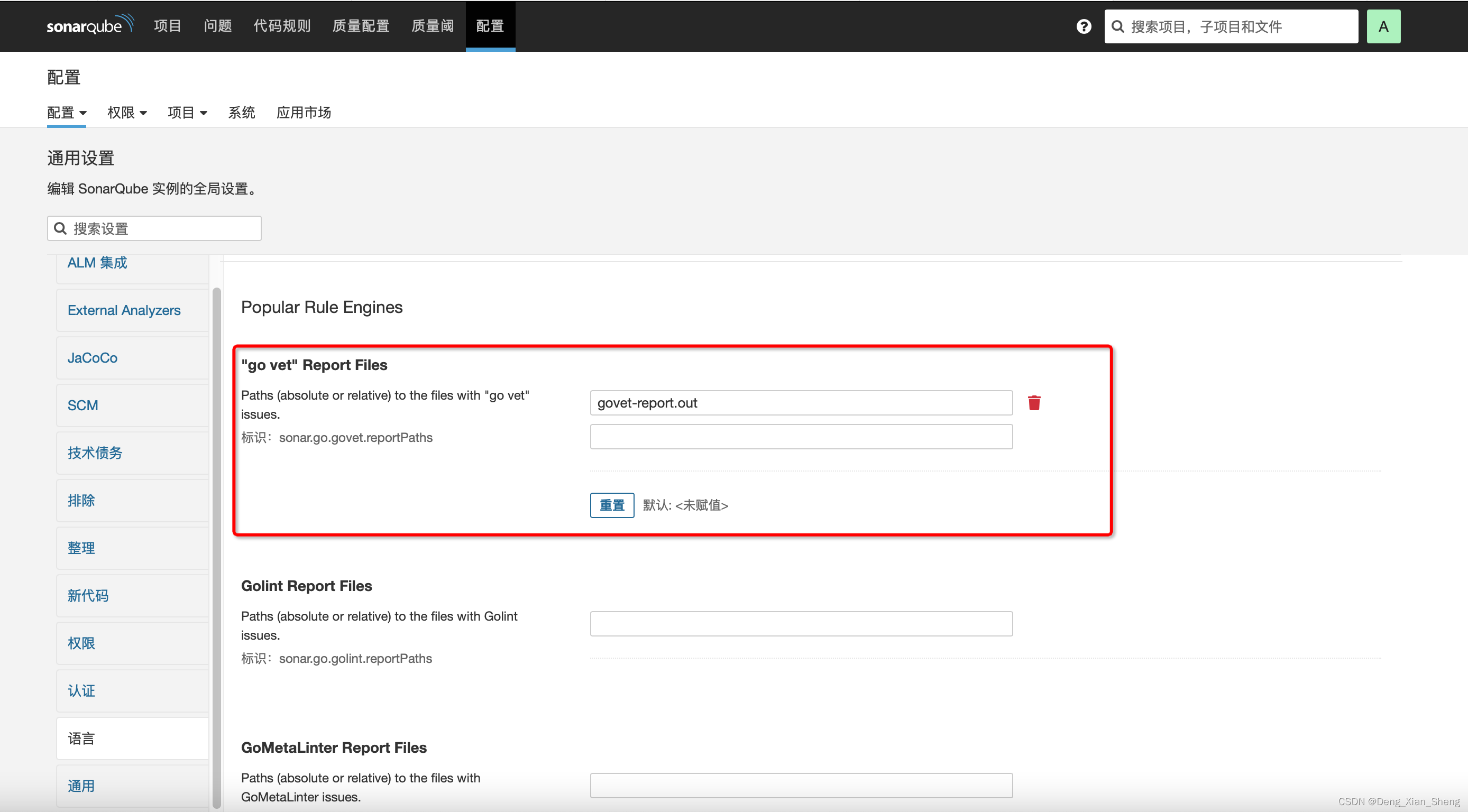
sonarqube 外部扫描器 go vet golangci-lint 无法导入问题
首先,请看[外部分析报告]各种语言的报告生成 go vet 2> govet-report.out#没有golangci-lint,我从网上找到了 golangci-lint run --out-format checkstyle ./... > golangci-lint-report.xml值得注意的是,貌似不支持目录,仅…...

Tesseract-OCR 控制台怎么使用
Tesseract-OCR 控制台是一个命令行工具,可以在 Windows、Linux、macOS 等操作系统中使用。下面是使用 Tesseract-OCR 控制台进行文字识别的基本步骤:安装 Tesseract-OCR:可以到 Tesseract-OCR 的官方网站(https://github.com/tess…...

智能图像分层革命:5分钟将任何图片转换为可编辑PSD图层
智能图像分层革命:5分钟将任何图片转换为可编辑PSD图层 【免费下载链接】layerdivider A tool to divide a single illustration into a layered structure. 项目地址: https://gitcode.com/gh_mirrors/la/layerdivider 你是否曾面对一张精美的插画ÿ…...

Sunshine游戏串流服务器架构深度解析:5个高级性能调优技巧与源码设计实战
Sunshine游戏串流服务器架构深度解析:5个高级性能调优技巧与源码设计实战 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine Sunshine作为一款开源的自托管游戏串流服务器…...

VBA添加超链接:Hyperlinks.Add 方法 完整参数解析
Worksheet.Hyperlinks.Add Cells(j 1, 11), ar(2, j), "", "单击打开:" & ar(1, j), ar(1, j) 每个参数解析、 VBA Hyperlinks.Add 方法 完整参数解析 你这句代码是Excel VBA 给单元格添加超链接的核心语句,我把 Hyperlinks.…...

为什么说Ohook重新定义了Office激活的技术边界?
为什么说Ohook重新定义了Office激活的技术边界? 【免费下载链接】ohook An universal Office "activation" hook with main focus of enabling full functionality of subscription editions 项目地址: https://gitcode.com/gh_mirrors/oh/ohook 当…...

【APP分发系统二开版】app打包一键免IOS免签封包分发平台源码 带绿标
内容目录一、详细介绍二、效果展示1.部分代码2.效果图展示三、学习资料下载一、详细介绍 60gx版APP分发系统在线IOS免签封包分发平台源码免签封装带绿标已对接码支付 这个源码某站卖300,主要是因为他有几个功能比较好。 支持一键IOS在线免签封装。买源码可免费协助…...

终极指南:使用OpenHTMLtoPDF快速构建专业PDF生成器
终极指南:使用OpenHTMLtoPDF快速构建专业PDF生成器 【免费下载链接】openhtmltopdf An HTML to PDF library for the JVM. Based on Flying Saucer and Apache PDF-BOX 2. With SVG image support. Now also with accessible PDF support (WCAG, Section 508, PDF/U…...

集装箱箱号与ISO代码区域检测数据集VOC+YOLO格式887张2类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件)图片数量(jpg文件个数):887标注数量(xml文件个数):887标注数量(txt文件个数):887标注类别数&…...

如何使用 Graphviz 在 5 分钟内创建专业流程图:Python 数据可视化终极指南
如何使用 Graphviz 在 5 分钟内创建专业流程图:Python 数据可视化终极指南 【免费下载链接】graphviz Simple Python interface for Graphviz 项目地址: https://gitcode.com/gh_mirrors/gr/graphviz 想要快速创建专业流程图吗?Graphviz 是一个强…...

TegraRcmGUI终极指南:Windows上最简单的Switch注入工具
TegraRcmGUI终极指南:Windows上最简单的Switch注入工具 【免费下载链接】TegraRcmGUI C GUI for TegraRcmSmash (Fuse Gele exploit for Nintendo Switch) 项目地址: https://gitcode.com/gh_mirrors/te/TegraRcmGUI TegraRcmGUI是一款专为Nintendo Switch设…...

从游戏地图切割到3D模型生成:凸多边形三角剖分在Unity/C++中的实战应用
从游戏地图切割到3D模型生成:凸多边形三角剖分在Unity/C中的实战应用 在游戏开发中,我们经常需要处理复杂的几何形状。无论是为开放世界游戏创建导航网格,还是为3D模型生成优化的三角面片,凸多边形的三角剖分都是核心技能之一。不…...