非关系型数据库-Redis
一、缓存概念
缓存是为了调节速度不一致的两个或多个不同的物质的速度,在中间对速度较慢的一方起到加速作用,比如CPU的一级、二级缓存是保存了CPU最近经常访问的数据,内存是保存CPU经常访问硬盘的数据,而且硬盘也有大小不一的缓存,甚至是物理服务器的raid 卡有也缓存,都是为了起到加速CPU 访问硬盘数据的目的,因为CPU的速度太快了,CPU需要的数据由于硬盘往往不能在短时间内满足CPU的需求,因此CPU缓存、内存、Raid 卡缓存以及硬盘缓存就在一定程度上满足了CPU的数据需求,即CPU 从缓存读取数据可以大幅提高CPU的工作效率。
系统缓存
buffer与cache:
- buffer: 缓冲也叫写缓冲,一般用于写操作,可以将数据先写入内存再写入磁盘,buffer 一般用于写缓冲,用于解决不同介质的速度不一致的缓冲,先将数据临时写入到里自己最近的地方,以提高写入速度,CPU会把数据先写到内存的磁盘缓冲区,然后就认为数据已经写入完成看,然后由内核在后续的时间在写入磁盘,所以服务器突然断电会丢失内存中的部分数据。
- cache: 缓存也叫读缓存,一般用于读操作,CPU读文件从内存读,如果内存没有就先从硬盘读到内存再读到CPU,将需要频繁读取的数据放在里自己最近的缓存区域,下次读取的时候即可快速读取。
缓存保存位置及分层结构
互联网应用领域,提到缓存为王。
- 用户层:浏览器DNS缓存,应用程序DNS缓存,操作系统DNS缓存客户端
- 代理层:CDN,反向代理缓存
- Web层:Web服务器缓存
- 应用层:页面静态化
- 数据层:分布式缓存,数据库
- 系统层:操作系统cache
- 物理层:磁盘cache, Raid Cache
DNS缓存
浏览器的DNS缓存默认为60秒,即60秒之内在访问同一个域名就不在进行DNS解析。
应用层缓存
Nginx、PHP等web服务可以设置应用缓存以加速响应用户请求,另外有些解释性语言,比如:PHP/Python/Java不能直接运行,需要先编译成字节码,但字节码需要解释器解释为机器码之后才能执行,因此字节码也是一种缓存,有时候还会出现程序代码上线后字节码没有更新的现象。所以一般上线新版前,需要先将应用缓存清理,再上线新版。
另外可以利用动态页面静态化技术,加速访问,比如:将访问数据库的数据的动态页面,提前用程序生成静态页面文件html 电商网站的商品介绍,评论信息非实时数据等皆可利用此技术实现。
数据层缓存
分布式缓存服务:
- Redis
- Memcached
数据库:
- MySQL 查询缓存
- innodb缓存、MYISAM缓存
硬件缓存
- CPU缓存(L1的数据缓存和L1的指令缓存)、二级缓存、三级缓存
- 磁盘缓存:Disk Cache
- 磁盘阵列缓存:Raid Cache,可使用电池防止断电丢失数据
关系型数据库与非关系型数据库
关系型数据库
- 关系型数据库是一个结构化的数据库,创建在关系模型(二维表格模型)基础上,一般面向于记录。
- SQL语句(标准数据查询语言)就是一种基于关系型数据库的语言,用于执行对关系型数据库中数据的检索和操作。
- 主流的关系型数据库包括Oracle、 MySQL、SQL Server、Microsoft Access、 DB2、PostgreSQL 等。
以上数据库在使用的时候必须先建库建表设计表结构,然后存储数据的时候按表结构去存,如果数据与表结构不匹配就会存储失败。
非关系型数据库
- NoSQL(NoSQL=NotonlysQL),意思是“不仅仅是SQL",是非关系型数据库的总称。
- 除了主流的关系型数据库外的数据库,都认为是非关系型。
- 不需要预先建库建表定义数据存储表结构,每条记录可以有不同的数据类型和字段个数(比如微信群聊里的文字、图片、视频、音乐等)。
- 主流的NOSQL 数据库有Redis、MongBD、 Hbase(分布式非关系型数据库,大数据使用)、Memcached、ElasticSearch(简称ES,索引型数据库)、TSDB(时续型数据库) 等。
关系型数据库和非关系型数据库区别:
(1)数据存储方式不同
关系型和非关系型数据库的主要差异是数据存储的方式。
- 关系型数据天然就是表格式的,因此存储在数据表的行和列中。数据表可以彼此关联协作存储,也很容易提取数据。
- 与其相反,非关系型数据不适合存储在数据表的行和列中,而是大块组合在一起。非关系型数据通常存储在数据集中,就像文档、键值对或者图结构。你的数据及其特性是选择数据存储和提取方式的首要影响因素。(很容易切换数据类型,一个数据集当中有多种数据类型)
(2)扩展方式不同
SQL和NoSQL数据库最大的差别可能是在扩展方式上,要支持日益增长的需求当然要扩展。
- 要支持更多并发量,SQL数据库是纵向扩展,也就是说提高处理能力,使用速度更快速的计算机,这样处理相同的数据集就更快了。因为数据存储在关系表中,操作的性能瓶颈可能涉及很多个表,这都需要通过提高计算机性能来克服。虽然SQI数据库有很大打展空间,但最终肯定会达到纵向扩展的上限。(数据一般存储在本地的文件系统中。读可以通过读写分离、负载均衡来分摊性能,但读写仍然很消耗IO性能)
- 而NoSQL数据库是横向扩展的。因为非关系型数据存储天然就是分布式的,NoSQL数据库的扩展可以通过给资源池添加更多普通的数据库服务器(节点)来分担负载。(数据分布存储在不同服务器上,可以并发地读写,加快效率)
小贴士:
- 横向扩展:加服务器。(比较便宜)
- 纵向扩展:提高硬件配置,比如换更高性能的CPU、加CPU核数、硬盘、磁盘IO、内存条。(除硬盘外,其他需要停机才能加)
(3)对事务性的支持不同
- 如果数据操作需要高事务性或者复杂数据查询需要控制执行计划,那么传统的SQL数据库从性能和稳定性方面考虑是你的最佳选择。SQL数据库支持对事务原子性细粒度控制,并且易于回滚事务。
- 虽然NoSQL数据库也可以使用事务操作,但稳定性方面没法和关系型数据库比较,所以它们真正闪亮的价值是在操作的扩展性和大数据量处理方面。
- 非关系型数据库在事务的处理和稳定性方面,不如关系型数据库。但读写性能好、易于扩展,处理大数据方面占优势。
关系型数据库:特别适合高事务性要求和需要控制执行计划的任务,事务细粒度控制更好。
非关系型数据库:事务控制会稍显弱势,其价值点在于高扩展性和大数据量处理方面。
非关系型数据库产生背景
可用于应对Web2.0纯动态网站类型的三高问题。
(1)High performance —— 对数据库高并发读写需求。
(2)Hugestorage——对海量数据高效存储与访问需求。
(3)HighScalability&&HighAvailability——对数据库高可扩展性与高可用性需求。
关系型数据库和非关系型数据库都有各自的特点与应用场景,两者的紧密结合将会给web2.0的数据库发展带来新的思路。让关系型数据库关注在关系上和对数据的一致性保障,非关系型数据库关注在存储和高效率上。例如,在读写分离的MySQI数据库环境中,可以把经常访问的数据(即高热数据)存储在非关系型数据库中,提升访问速度。
总结
关系型数据库:
- 实例-->数据库-->表(table)-->记录行(row)、数据字段(column)
非关系型数据库:
- 实例-->数据库-->集合(collection) -->键值对(key-value)
- 非关系型数据库不需要手动建数据库和集合(表)。
Redis简介
Redis (远程字典服务器)是一个 开源的、使用C语言编写的NoSQL 数据库。
Redis 基于内存运行并支持持久化,采用key-value (键值对)的存储形式,是目前分布式架构中不可或缺的一环。
Redis服务器程序是单进程模型,也就是在一台服务器上可以同时启动多个Redis进程,Redis的实际处理速度则是完全依靠于主进程的执行效率。
- 若在服务器上只运行一个Redis进程,当多个客户端同时访问时,服务器的处理能力是会有一定程度的下降;
- 若在同一台服务器上开启多个Redis进程,Redis在提高并发处理能力的同时会给服务器的CPU造成很大压力。
即:在实际生产环境中,需要根据实际的需求来决定开启多少个Redis进程。若对高并发要求更高一些,可能会考虑在同一台服务器上开启多个进程。若CPU资源比较紧张,采用单进程即可。
Redis具有以下几个优点:
(1)具有极高的数据读写速度: 数据读取的速度最高可达到110000 次/s,数据写入速度最高可达到81000次/s。
(2)支持的数据结构: key-value,支持丰富的数据类型:Strings、 Lists、Hashes、 Sets 及Sorted Sets 等数据类型操作。
- Strings 字符串型
- Lists 列表型
- Hashes 哈希(散列)
- Sets 无序集合
- Sorted Sets 有序集合(或称zsets)
(redis也可以做消息队列,可以通过Sorted Sets实现)
(3)支持数据的持久化: 可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
(4)原子性: Redis所有操作都是原子性的。(支持事务,所有操作都作为事务)
(5)支持数据备份: 即 master-salve 模式的数据备份。(支持主从复制)
Redis缺点
- 缓存和数据库双写一致性问题
- 缓存雪崩问题
- 缓存击穿问题
- 缓存的并发竞争问题
Redis的适用场景
- Redis作为基于内存运行的数据库,是一个高性能的缓存,一般应用在session缓存、 队列、排行榜、计数器、最近最热文章、最近最热评论、发布订阅等。
- Redis适用于数据实时性要求高、数据存储有过期和淘汰特征的、不需要持久化或者只需要保证弱一致性、逻辑简单的场景。
Redis为什么这么快?
- 1、Redis是一款纯内存结构,避免了磁盘 I/O 等耗时操作。(基于内存运行)
- 2、Redis命令处理的核心模块为单线程,减少了锁竞争,以及频繁创建线程和销毁线程的代价,减少了线程上下文切换的消耗。(单线程模型)
- 3、采用了 I/O 多路复用机制,大大提升了并发效率。(epoll模式)
Redis与memcached比较
| Memcached | Redis | |
|---|---|---|
| 类型 | Key-value数据库 | Key-value数据库 |
| 过期策略 | 支持 | 支持 |
| 数据类型 | 单一数据类型 | 五大数据类型 |
| 持久化 | 不支持 | 支持 |
| 主从复制 | 不支持 | 支持 |
| 虚拟内存 | 不支持 | 支持 |
Redis安装部署
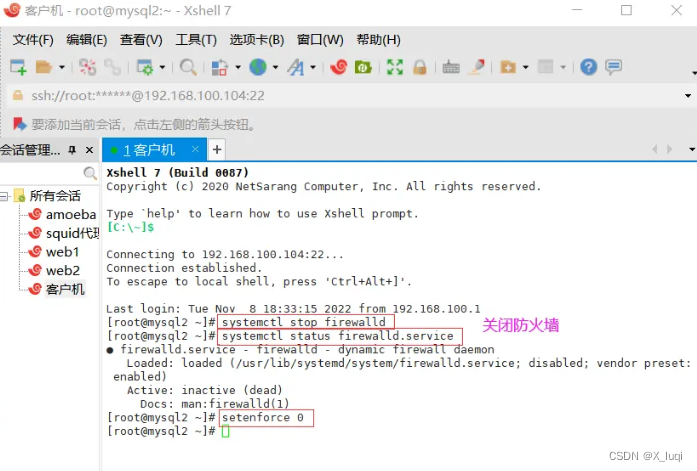
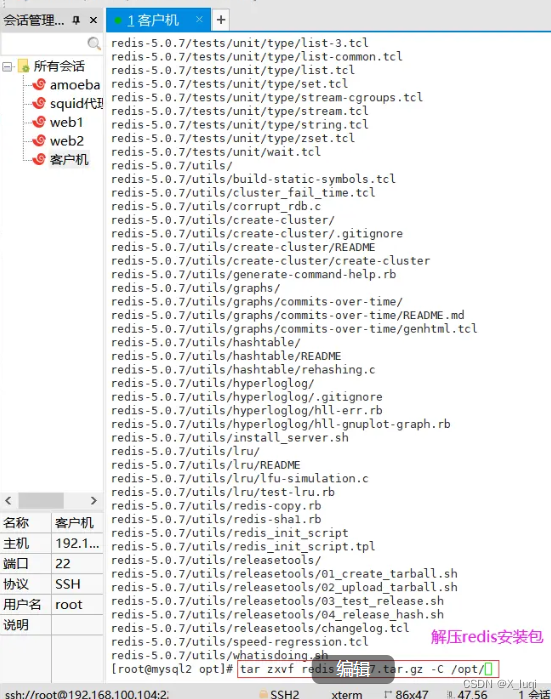
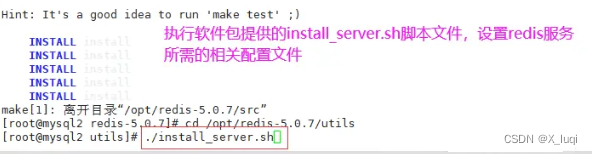
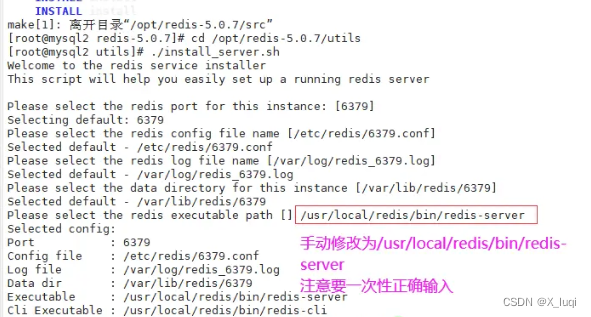
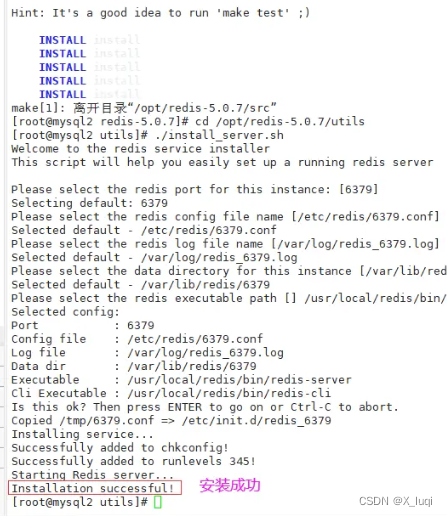
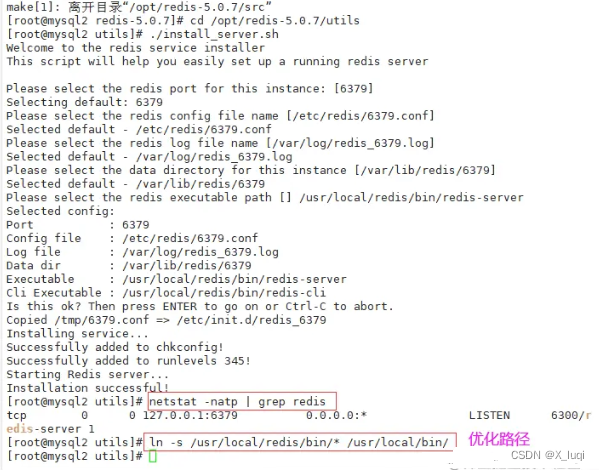
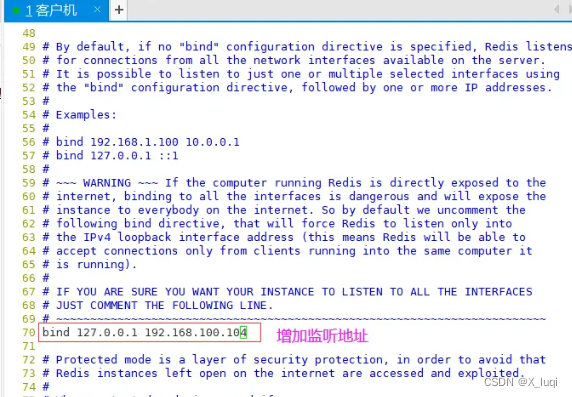
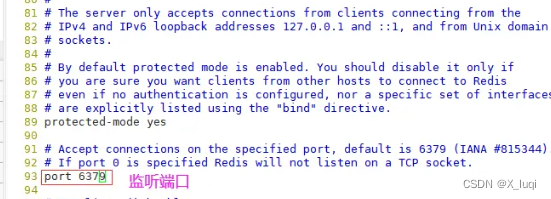
#关闭防火墙 systemctl stop firewalld setenforce 0 #安装环境依赖包 yum install -y gcc gcc-c++ make #上传软件包并解压 cd /opt/ tar zxvf redis-5.0.7.tar.gz -C /opt/ cd /opt/redis-5.0.7/ #开2核编译安装,指定安装路径为/usr/local/redis make -j2 && make PREFIX=/usr/local/redis install #由于Redis源码包中直接提供了Makefile 文件,所以在解压完软件包后,不用先执行./configure 进行配置,可直接执行make与make install命令进行安装。 #执行软件包提供的install_server.sh 脚本文件,设置Redis服务所需要的相关配置文件 cd /opt/redis-5.0.7/utils ./install_server.sh .......#一直回车 Please select the redis executable path [] /usr/local/redis/bin/redis-server #这里默认为/usr/local/bin/redis-server,需要手动修改为/usr/local/redis/bin/redis-server,注意要一次性正确输入#当install_server.sh 脚本运行完毕,Redis 服务就已经启动,默认监听端口为6379 netstat -natp | grep redis #把redis的可执行程序文件放入路径环境变量的目录中便于系统识别 ln -s /usr/local/redis/bin/* /usr/local/bin/ #Redis服务控制 /etc/init.d/redis_6379 stop #停止 /etc/init.d/redis_6379 start #启动 /etc/init.d/redis_6379 restart #重启 /etc/init.d/redis_6379 status #查看状态 #编辑配置文件,参数 vim /etc/redis/6379.conf ...... 70 bind 127.0.0.1 192.168.100.104 #监听的IP地址 93 port 6379 #监听端口 137 daemonize yes #使用守护进程的方式启动,即后台启动 159 pidfile /var/run/redis_6379.pid #Redis的进程号保存位置 172 logfile /var/log/redis_6379.log #日志保存的位置 187 databases 16 #监听库的数量(编号0-15) /etc/init.d/redis_6379 restart #重启redis服务


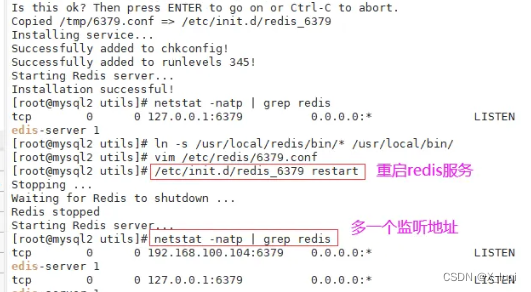
Redis命令工具
| 工具 | 作用 |
|---|---|
| redis-server | 用于启动redis的工具 |
| redis-benchmark | 用于检测redis在本机的运行效率 |
| redis-check-aof | 修复AOF持久化文件 |
| redis-check-rdb | 修复RDB持久化文件 |
| redis-cli | redis命令行工具 |
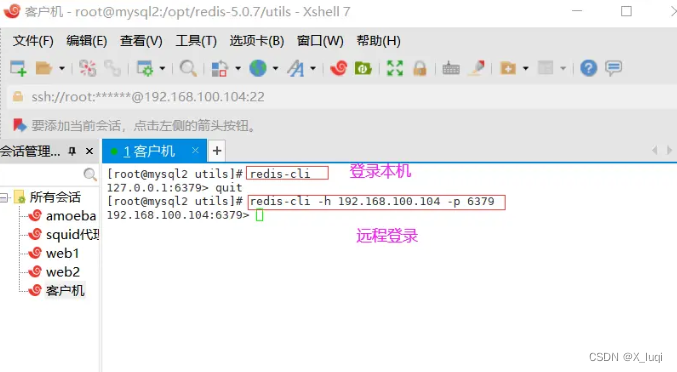
redis-cli:Redis 命令行工具
语法:redis-cli -h host -p port -a password
-h:指定远程主机机 -p:指定Redis服务的端口号 -a:指定密码,未设置数据库密码可以省略-a选项
#-a选项若不添加任何选项表示使用127.0.0.1:6379连接本机上的Redis数据库
#登录本机 redis-cli
#远程登录 redis-cli -h 192.168.100.104 -p 6379 [-a 密码]
 redis-benchmark 测试工具
redis-benchmark 测试工具
redis-benchmark是官方自带的Redis性能测试工具,可以有效的测试Redis服务的性能。
基本的测试语法:redis-benchmark [选项] [选项值]
-h:指定服务器主机名。
-p:指定服务器端口。
-s:指定服务器 socket
-c:指定并发连接数。
-n:指定请求数。
-d:以字节的形式指定SET/GET值的数据大小。
-k:l=keep alive 0=reconnect
-r:SET/GET/INCR 使用随机key,SADD使用随机值
-P:通过管道传输<numreg>请求
-q:强制退出redis,仅显示query/sec值
--csv:以CSV格式输出
-l:生成循环,永久执行测试
-t:仅运行以逗号分隔的测试命令列表
-I:Idle模式,仅打开N个idle连接并等待
向IP地址为192.168.100.104、 端口为6379 的Redis 服务器发送100个并发连接与100000 个请求测试性能。
redis-benchmark -h 192.168.100.104 -p 6379 -c 100 -n 100000 测试存取大小为100字节的数据包的性能。
测试存取大小为100字节的数据包的性能。
redis-benchmark -h 192.168.100.104 -p 6379 -q -d 100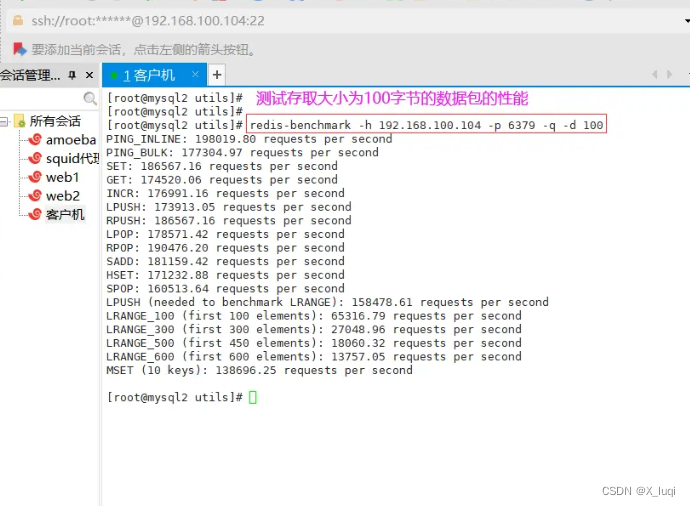 测试本机上Redis 服务在进行 set 与 lpush 操作时的性能。
测试本机上Redis 服务在进行 set 与 lpush 操作时的性能。
redis-benchmark -t set,lpush -n 100000 -q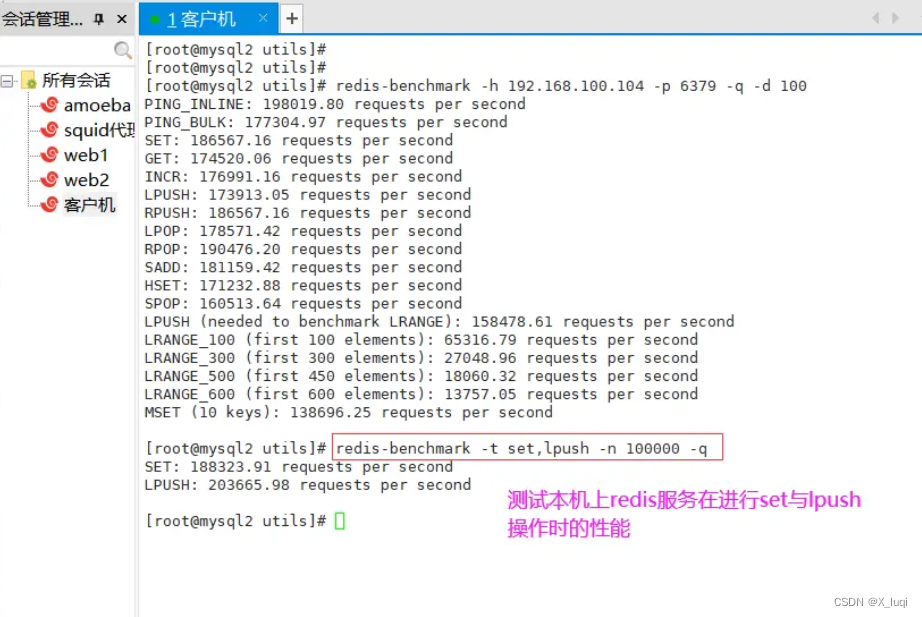 Redis数据库常用命令
Redis数据库常用命令
| 命令 | 作用 |
|---|---|
| set | 存放数据 |
| get | 获取数据 |
| keys * | 查看所有的key |
| keys k? | 查看k开头后面任意一位的数据 |
| exists | 判断键是否存在(存在1,不存在0) |
| del | 删除键 |
| type | 查看键对应的value值类型 |
| rename key1 key2 | 改名,不管key2是否存在都会改名成功。如果存在,key1的值会覆盖key2得值 |
| renamenx key1 key2 | 改名,若key2不存在,可以改名成功。若key2存在则不进行改名 |
| dbsize | 查看当前数据库中key的数目 |
set、get 设置和获取键的值
set:存放数据,命令格式为 set key value
get:获取数据,命令格式为 get key
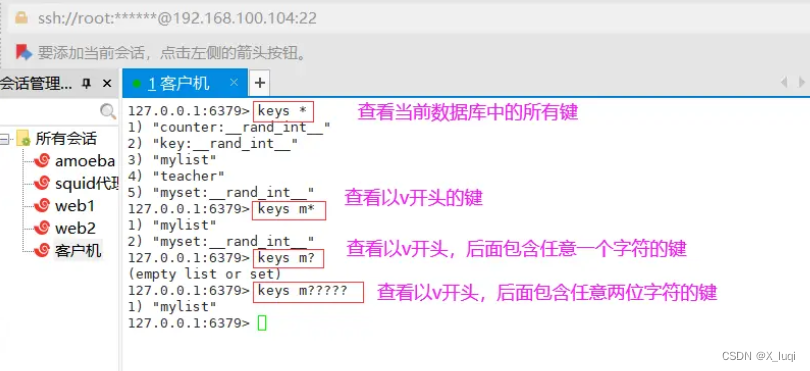
 keys 获取键值列表
keys 获取键值列表
keys命令可以获取符合规则的键值列表,通常情况可以结合 *、? 等选项来使用。
#先创建几个键 127.0.0.1:6379>set k1 1 127.0.0.1:6379>set k2 2 127.0.0.1:6379>set k3 3 127.0.0.1:6379>set v1 4 127.0.0.1:6379>set v5 5 127.0.0.1:6379>set v22 6 127.0.0.1:6379>set v33 7
127.0.0.1:6379>keys * #查看当前数据库中所有键
127.0.0.1:6379>keys v* #查看当前数据库中以v开头的键
127.0.0.1:6379>keys v? #查看当前数据库中以v开头,后面包含任意一位字符的键 127.0.0.1:6379>keys v?? #查看当前数据库中以v开头,后面包含任意两位字符的键
 exists 判断键是否存在
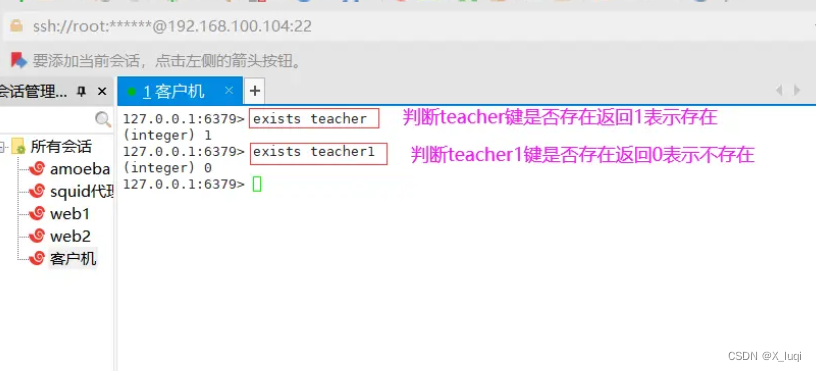
exists 判断键是否存在
exists 命令可以判断键是否存在。
返回1,表示键存在。
返回0,表示键不存在。
127.0.0.1:6379> exists teacher #判断teacher键是否存在,返回1表示存在 (integer) 1 127.0.0.1:6379> exists student #判断studen键是否存在,返回0表示存在 (integer) 0
 del 删除键
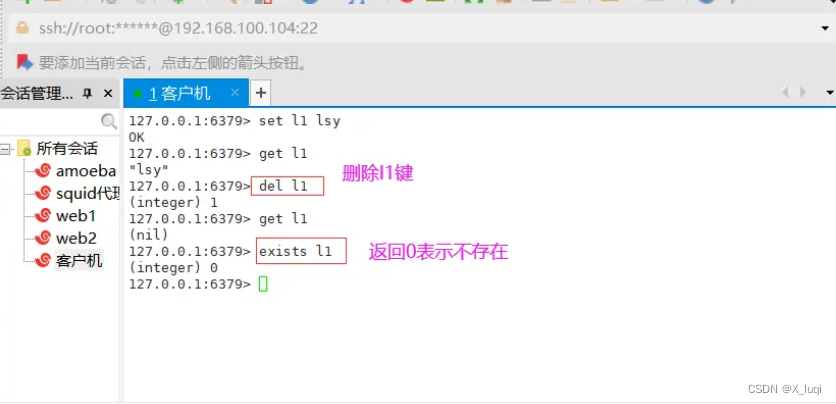
del 删除键
del 命令可以删除当前数据库的指定key。
127.0.0.1:6379> get k1 "1"
127.0.0.1:6379> del k1 #删除k1键
(integer) 1 127.0.0.1:6379> get k1 (nil)
127.0.0.1:6379> exists k1 #k1键已不存在 (integer) 0
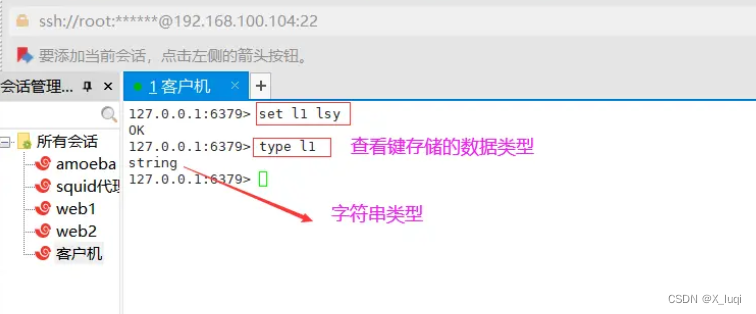
 type 查看键存储的数据类型
type 查看键存储的数据类型
type 命令可以获取 key 对应的 value 值类型。
127.0.0.1:6379> get k2 "2" 127.0.0.1:6379> type k2 string #字符串类型
 rename 重命名
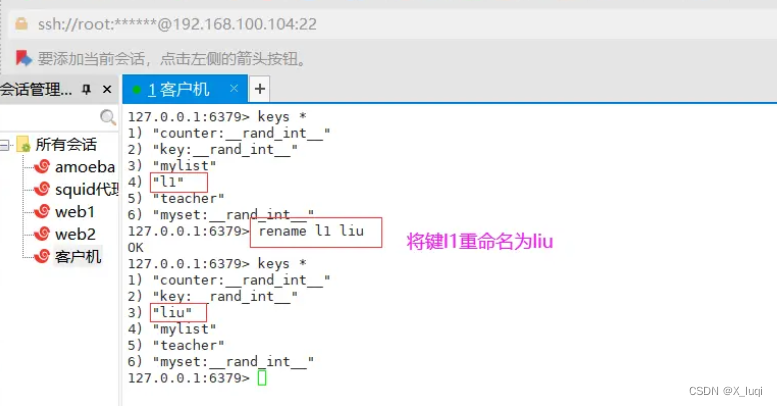
rename 重命名
rename 命令是对已有 key 进行重命名。(覆盖)
- 使用rename命令进行重命名时,无论目标key是否存在都会进行重命名,且源key的值会覆盖目标key的值。
- 在实际使用过程中,建议先用exists命令查看目标key 是否存在,然后再决定是否执行rename 命令,以避免覆盖重要数据。
命令格式: rename 源key 目标key
 renamenx 会检查目标键名是否已存在
renamenx 会检查目标键名是否已存在
renamenx 命令的作用是对已有key进行重命名,并检测新名是否存在,如果目标key存在则不进行重命名。(不覆盖)
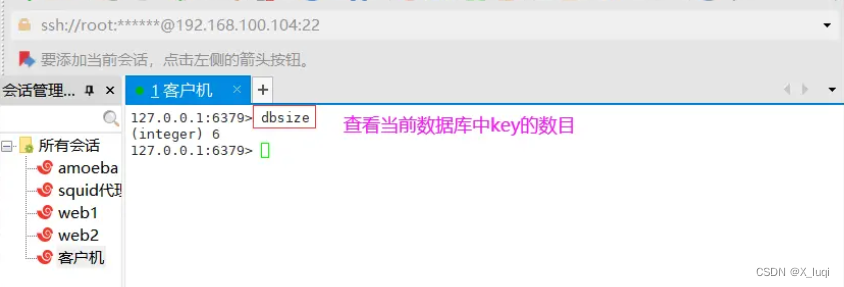
 dbsize查看键数目
dbsize查看键数目
dbsize 命令的作用是查看当前数据库中key的数目。
127.0.0.1:6379> dbsize #查看键数目 (integer) 11
#一共11个键 127.0.0.1:6379>
 设置和清空密码
设置和清空密码
1、设置和查看密码
使用 config set requirepass password 命令设置密码。(一旦设置密码,必须先验证通过密码,否则所有操作不可用)
使用 config get requirepass 命令查看密码。
127.0.0.1:6379> config set requirepass 123456 #设置密码 OK 192.168.100.104:6379> config get requirepass (error) NOAUTH Authentication required. #设置密码后,需要先验证密码才能操作其他命令
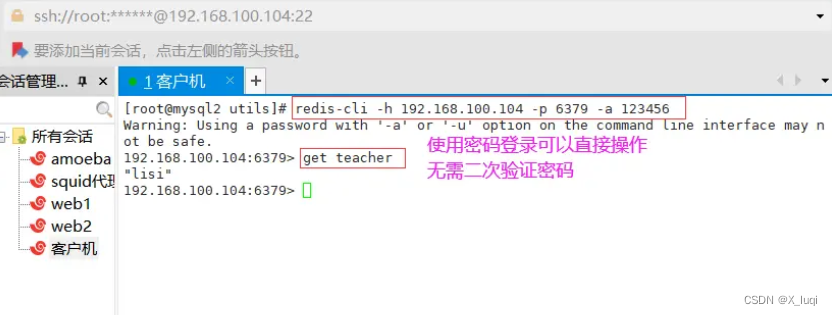
127.0.0.1:6379> auth 123456 #验证密码 OK 192.168.100.104:6379> config get requirepass #查看密码
1) "requirepass" 2) "123456" #设置密码后,使用密码登录可以直接操作,不需要二次验证
# redis-cli -h 192.168.72.60 -p 6379 -a 123456
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe. 192.168.100.104:6379> get teacher "lisi"

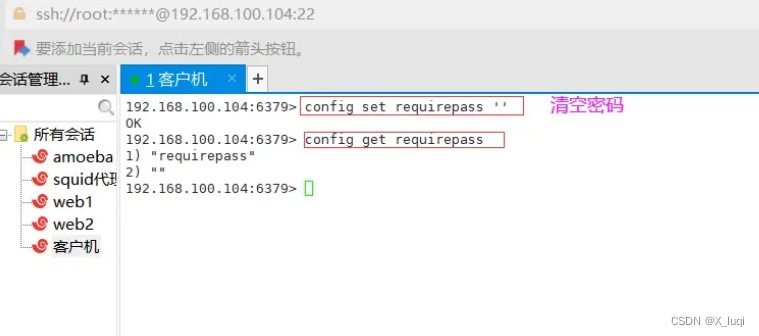
 清空密码:
清空密码:
使用 config set requirepass '' 清空密码。
192.168.100.104:6379> config set requirepass '' #清空密码 OK 192.168.100.104:6379> config get requirepass
1) "requirepass" 2) "" #密码已为空
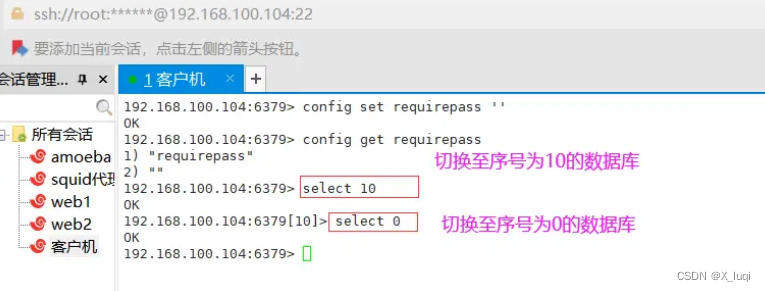
 Redis多数据库操作
Redis多数据库操作
Redis 支持多数据库,Redis默认情况下包含16个数据库,数据库名称是用数字0-15来依次命名的。
使用redis-cli连接Redis数据库后,默认使用的是序号为0的数据库。
多数据库相互独立,互不干扰。
命令格式:select 序号 #使用redis-cli连接Redis数据库后,默认使用的是序号为0的数据库。 127.0.0.1:6379>select 10 #切换至序号为10的数据库 127.0.0.1:6379[10]>select 15 #切换至序号为15的数据库 127.0.0.1:6379[15]>select 0 #切换至序号为0的数据库 127.0.0.1:6379[0]>
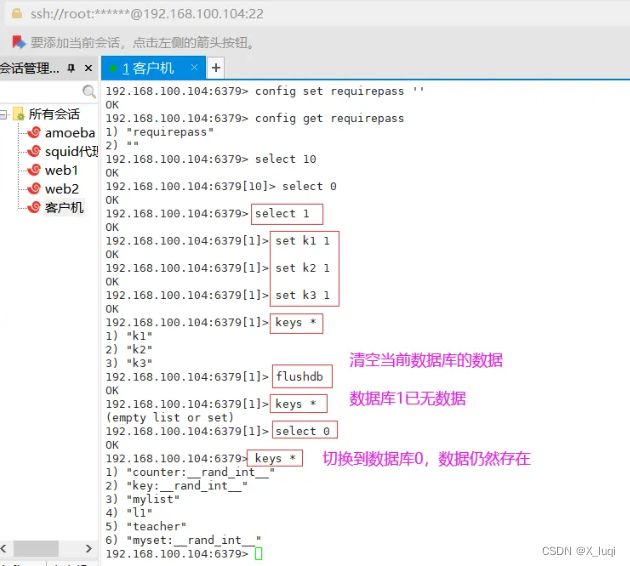
 多数据库间移动数据
多数据库间移动数据
命令格式:move 键值 序号
清除数据库内数据
FLUSHDB:清空当前数据库数据 FLUSHALL:清空所有数据库的数据,慎用!!!
相关文章:
非关系型数据库-Redis
一、缓存概念 缓存是为了调节速度不一致的两个或多个不同的物质的速度,在中间对速度较慢的一方起到加速作用,比如CPU的一级、二级缓存是保存了CPU最近经常访问的数据,内存是保存CPU经常访问硬盘的数据,而且硬盘也有大小不一的缓存…...

HTML基本讲解与使用
目录 html的由来: 什么是HTML: HTML的主要特点: HTML文档结构: HTML元素: HTML元素属性: 文本和格式化: 链接和图像: 列表: 表格: 表单: 嵌套和结构: HTML注释: 样式…...

linux uname详解 -s -r -a 查看内核版本
简介 uname命令用于显示操作系统信息,例如内核版本、主机名、处理器类型等 uname常用的有-a,-r,-rs 参数 --help 显示帮助。-a 或--all 显示全部信息,包括内核名、主机名、内核版本、处理器类型和硬件架构等…...

Linux常用命令——cmp命令
在线Linux命令查询工具 cmp 比较两个文件是否有差异 补充说明 cmp命令用来比较两个文件是否有差异。当相互比较的两个文件完全一样时,则该指令不会显示任何信息。若发现有差异,预设会标示出第一个不通之处的字符和列数编号。若不指定任何文件名称或是…...
C语言之排序
1.冒泡排序 冒泡排序就不多说了,只需要两层循环嵌套,两两比较确定相对正确的顺序即可。 2.插入排序 插入排序的思想就是每一次向后寻找一个再将其与前面有序的部分进行对比,寻找合适位置插入。 这里关键要避免让前移超出目前读取的数字&…...
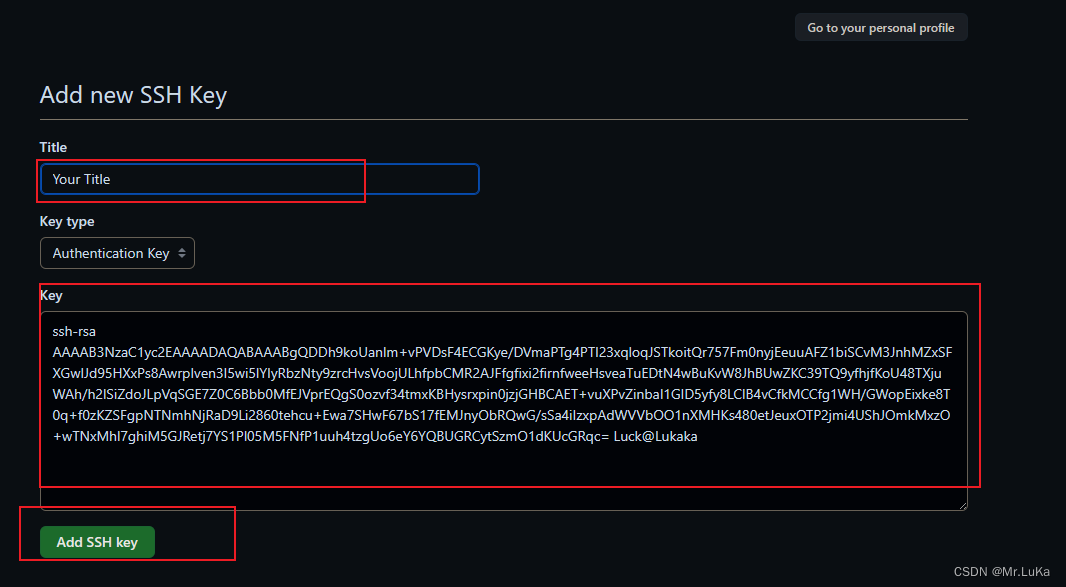
GitHub-使用 Git工具 创建密钥id_rsa.pub
快速导航 步骤1 打开Git Bash步骤2 输入指令【ssh-keygen】步骤3 打开创建的公钥文件步骤4 复制其中所有内容步骤5 打开GitHub中的Setting界面步骤6 添加SSH keys 步骤1 打开Git Bash 打开Git Bash 工具 步骤2 输入指令【ssh-keygen】 输入指令【ssh-keygen】,并…...

C++多重、多层、分层继承
在本文中,您将学习C 编程中的不同继承模型:带有示例的多继承,多层和分层继承。 继承是面向对象编程语言的核心功能之一。它允许软件开发人员从现有的类派生一个新的类。派生类继承基类(现有类)的功能。C 编程中有多种…...

ThingsBoard的数据分析-自定义节点来订阅kafka stream的消息
1、概述 在ThingsBoard官方文档中有说明:ThingsBoard 规则引擎支持对传入遥测数据的基本分析,例如阈值交叉。规则引擎背后的想法是提供基于设备属性或数据本身将数据从物联网设备路由到不同插件的功能。 然而,大多数现实生活中的用例也需要高级分析的支持:机器学习、预测分…...

Python WSGI HTTP Server - Gunicorn
基本概念 Gunicorn,也称为“Green Unicorn”,是一个Python WSGI HTTP Server,用于运行Python Web应用程序。WSGI(Web Server Gateway Interface)是Python应用程序和Web服务器之间的一个接口,允许应用程序和…...

[论文笔记]GPT-2
引言 今天继续GPT系列论文, 这次是Language Models are Unsupervised Multitask Learners,即GPT-2,中文题目的意思是 语言模型是无监督多任务学习器。 自然语言任务,比如问答、机器翻译、阅读理解和摘要,是在任务相关数据集上利用监督学习的典型方法。作者展示了语言模型…...

第十三届蓝桥杯模拟赛第三期
A.填空题 问题描述 请问十六进制数 2021ABCD 对应的十进制是多少? 参考答案 539077581 import java.math.*; public class Main {public static void main(String[] args) {String strnew BigInteger("2021ABCD",16).toString(10);System.out.printl…...
)
代碼隨想錄算法訓練營|第四十四天|01背包问题 二维、01背包问题 一维、416. 分割等和子集。刷题心得(c++)
目录 01背包問題 - DP二維數組 01 背包問題描述 暴力解 動態規劃 確認DP數組以及下標的含意 確定遞推公式 01背包问题 一维 一维DP 数組(滾動数組) 動態規劃五部曲 定義DP数組以及其下標含意 遞推公式 初始化 遍歷順序 讀題 416. 分割等和子集 自己看到题目的第…...
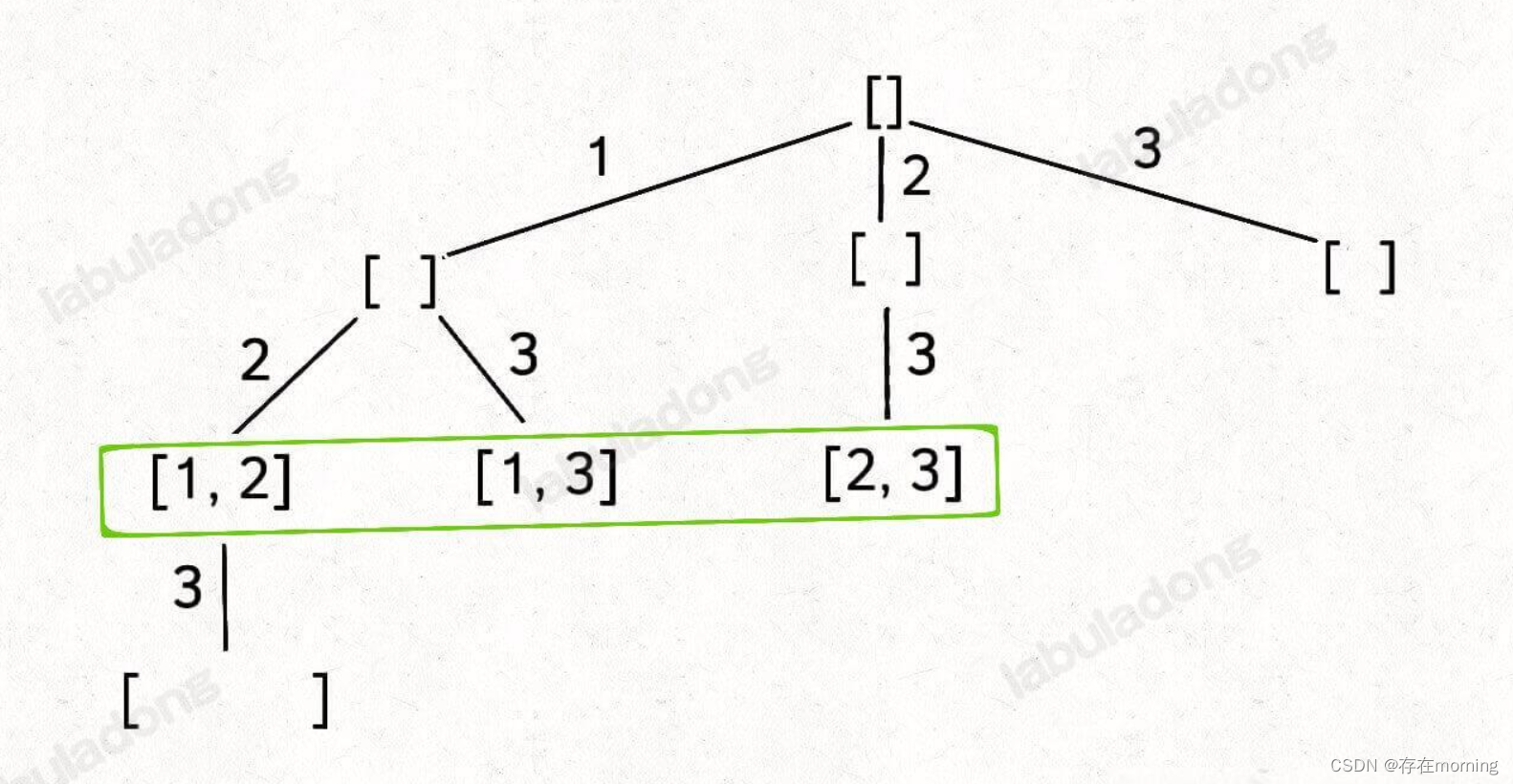
【算法训练-回溯算法 零】回溯算法解题框架
抽象地说,解决一个回溯问题,实际上就是遍历一棵决策树的过程,树的每个叶子节点存放着一个合法答案。你把整棵树遍历一遍,把叶子节点上的答案都收集起来,就能得到所有的合法答案。站在回溯树的一个节点上,你…...

GAN.py
原代码地址:github.com/zqhang/MTGFLOW 目录 def ConvEncoder() def ConvDecoder() class CNNAE(torch.nn.Module): class R_Net(torch.nn.Module): class D_Net(torch.nn.Module): def R_Loss() def D_Loss()…...
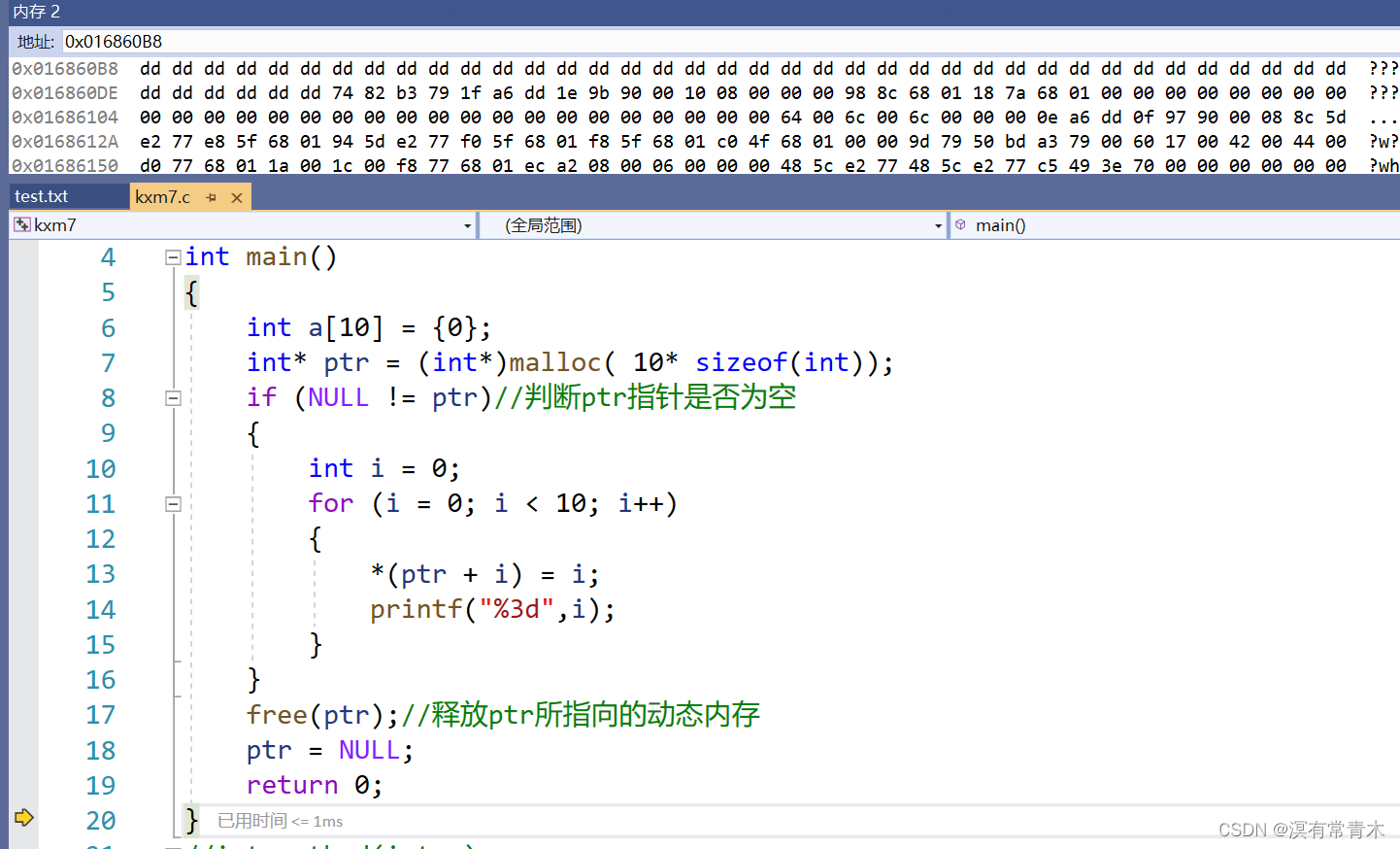
C语言动态内存管理
1.为什么要动态内存分配? int val 20; int a[10]{0};上面我们声明并定义了一个大小为4字节的整型变量,一个容量为10*4字节的整型数组。 开辟方式:我们在栈上开辟。 开辟空间的方式有两个特点: 1. 空间开辟 大小是固定 的。 2. 数组在申明…...
)
小红书商品详情API接口(商品详情页面数据接口)
小红书商品详情API接口(商品详情页面数据接口 小红书商品详情API接口(商品详情页面数据接口)代码对接如下: 1.公共参数 名称类型必须描述keystring是get请求方式拼接在url中,点击获取api_namestring是 api接口名称cachestrin…...

nginx配置文件的内容解释和简化方案
文章目录 配置文件内容理解配置文件精简nginx.confapp1.conf 配置文件内容理解 events {worker_connections 1024; }http {include mime.types;default_type application/octet-stream;sendfile on;keepalive_timeout 65;client_max_body_size 50m;client…...
)
Java设计模式之访问者模式(Visitor Pattern)
访问者模式(Visitor Pattern)是一种行为型设计模式,它允许在不修改现有对象结构的情况下定义新的操作。该模式将操作封装在一个访问者对象中,使得可以在不改变被访问对象的类的前提下,通过访问者对象对被访问对象进行新…...
others-AppLovin广告接入
title: others-AppLovin广告接入 categories: Others tags: [广告, AppLovin] date: 2023-10-20 10:07:01 comments: false mathjax: true toc: true others-AppLovin广告接入 前篇 官方 - https://www.applovin.com/ Android sdk - https://github.com/AppLovin/AppLovin-MAX…...
ESP32集成开发环境Espressif-IDE安装 – Windows
陈拓 2023/10/15-2023/10/16 1. 概述 Espressif IDE是一个基于Eclipse CDT的集成开发环境(IDE),用于使用ESP-IDF框架开发物联网应用程序。这是一个专门为ESP-IDF构建的独立定制IDE。Espressif IDE附带了IDF Eclipse插件、重要的Eclipse CDT插…...

2024终极指南:如何选择开源疫情监测系统?10款顶尖工具深度对比
2024终极指南:如何选择开源疫情监测系统?10款顶尖工具深度对比 【免费下载链接】awesome-healthcare Curated list of awesome open source healthcare software, libraries, tools and resources. 项目地址: https://gitcode.com/GitHub_Trending/aw/…...

平板电脑Linux内核显示配置实战:绕过HDMI探测,手动指定DP-1接口与分辨率
平板电脑Linux内核显示配置实战:绕过HDMI探测,手动指定DP-1接口与分辨率 在嵌入式设备开发中,显示配置往往是工程师面临的第一个挑战。不同于标准PC环境,平板电脑、工控设备等定制化硬件通常采用固定连接的显示屏,缺乏…...

「智库智能」获数亿元融资,凯傲集团战略入股,苏州国资加持
导语大家好,这里是智能仓储物流技术研习社:专注分享智能制造和智能仓储物流等内容。专业书籍:《智能物流系统构成与技术实践》|《智能仓储项目英语手册》|《智能仓储项目必坑手册》|《智能仓储项目甲方必读》|《12大行业智能仓储实战指南》近…...

XGBoost实战:从原理到部署的完整指南
1. XGBoost:为什么它成为机器学习竞赛的常胜将军?第一次接触XGBoost是在2016年的Kaggle竞赛中,当时超过半数的获胜方案都使用了这个算法。作为传统梯度提升树(GBDT)的进化版本,XGBoost通过一系列工程优化和…...

终极指南:FastLED文档自动生成与部署全流程 - Doxygen与GitHub Pages完美结合
终极指南:FastLED文档自动生成与部署全流程 - Doxygen与GitHub Pages完美结合 【免费下载链接】FastLED The FastLED library for colored LED animation on Arduino. Please direct questions/requests for help to the FastLED Reddit community: http://fastled.…...

Meta计划5月裁员约10%,约8000人受影响,此前AI领域投资巨大
Meta新一轮裁员:约8000人将告别据彭博社公布的Meta首席人力官珍妮尔盖尔(Janelle Gale)的备忘录显示,Meta计划在5月裁员约10%,这意味着约8000人将被裁。同时,盖尔还表示,Meta还将关闭约6000个招…...

DeepEar:基于多智能体协作的金融信息自动化研究框架实践
1. 项目概述:从噪音中捕捉信号,一个量化研究者的新工具在信息爆炸的时代,金融市场的噪音从未如此刺耳。每天,海量的新闻、社交媒体讨论、研报和公告如潮水般涌来,对于分析师和投资者而言,核心挑战不再是信息…...

CDA数据分析师证书适合哪些人考?学生党、在职人、转行人分别怎么看
一、数据分析师:谁学?为何学?数据分析已渗透到各行各业,从互联网大厂的用户增长,到传统金融机构的风险控制,再到零售企业的精准营销,都离不开数据的支撑。二、学生学生的诉求是补充实践经历、增…...

Amlogic S9xxx盒子无线网卡终极适配指南:5分钟搞定RTL8822CS驱动
Amlogic S9xxx盒子无线网卡终极适配指南:5分钟搞定RTL8822CS驱动 【免费下载链接】amlogic-s9xxx-armbian Supports running Armbian on Amlogic, Allwinner, and Rockchip devices. Support a311d, s922x, s905x3, s905x2, s912, s905d, s905x, s905w, s905, s905l…...

免费TCP路由追踪终极指南:3分钟快速掌握网络诊断神器
免费TCP路由追踪终极指南:3分钟快速掌握网络诊断神器 【免费下载链接】tracetcp tracetcp. Traceroute utility that uses tcp syn packets to trace network routes. 项目地址: https://gitcode.com/gh_mirrors/tr/tracetcp 你是否遇到过这样的网络困扰&am…...