基于Pytorch的CNN手写数字识别
作为深度学习小白,我想把自己学习的过程记录下来,作为实践部分,我会写一个通用框架,并会不断完善这个框架,作为自己的入门学习。因此略过环境搭建和基础知识的步骤,直接从代码实战开始。
一.下载数据集并加载
在这里使用MINST开源数字识别数据集。
首先导入必要的库,设置训练的设备(gpu或cpu),设置训练的轮次(epoch),然后设置数据集train_data、test_data,并使用torchvision的datasets来读取,下载的MINSt数据集被保存在当前路径的dataset文件夹下,对于训练集和测试集分别设置train的参数,最后把它转成tensor张量。
接着对设置好的数据集进行读取,调用了torch.utils.data下的DataLoader,分别读取训练集和测试集,同时设置batch_size,即为每一次读取多少张图片,然后对训练集数据进行展平(通常测试集不需要)。
# 搭建CNN卷积神经网络对MNIST数据集实现数字识别import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from torch.optim.lr_scheduler import StepLR
import cv2
import matplotlib.pyplot as plt
import numpy as npdevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")
epoch = 10train_data = datasets.MNIST("./dataset", train=True,download=True,transform=transforms.ToTensor())
test_data = datasets.MNIST("./dataset", train=False, download=True,transform=transforms.ToTensor())train_loader = DataLoader(train_data, batch_size=16, shuffle=True)
test_loader = DataLoader(test_data, batch_size=16, shuffle=False)二.定义训练网络
其中super().__init__()允许我们调用父类(nn.Module)的方法,
对于卷积操作nn.Conv2d(输入通道数,输出通道数,卷积核尺寸,步长,padding大小)参数如此,因为输入为灰度图,则对于第一个卷积的输入通道数等于1,最后线性层会输出一个包含10个数据的变量,分别代表10个数字(类别)的概率。
然后,我们实例化model为网络的对象,定义损失函数为交叉熵损失函数,使用Adam优化器对参数(model.parameters())进行优化,初始化学习率为0.001,并调用学习率更新器。
class Dight(nn.Module):def __init__(self):super().__init__()self.model = nn.Sequential(nn.Conv2d(1, 10, 5), #输入:batch*1*28*28 输出:batch*10*24*24(28 -5 + 1)nn.ReLU(), #保持shape不变 输出:batch*10*24*24(28 -5 + 1)nn.MaxPool2d(2), #输入:batch*10*24*24(28 -5 + 1) 输出:batch*10*12*12nn.Conv2d(10, 20, 3), #输入:batch*10*12*12 输出:batch*20*10*10(12 - 3 + 1)nn.ReLU(),nn.Flatten(),nn.Linear(20*10*10, 500), #输入:batch2000 输出:batch 500nn.ReLU(), #保持shape不变nn.Linear(500, 10) #输入:batch 500 输出:batch 10)def forward(self, x):return self.model(x)model = Dight()
model = model.to(device)
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.to(device)
optimizer = optim.Adam(model.parameters(), lr = 0.001)
scheduler = StepLR(optimizer, step_size = 5, gamma = 0.5)三.开始训练
使用model.train()开始训练,使用for循环遍历数据集中的数据(imgs)和标签(targets),对梯度初始化,将数据传入model进行前向传播,并输出前向传播结果(outputs),根据outputs和给定的标签targets计算交叉熵损失loss,根据loss进行反向传播,根据反向传播更新模型参数。
同时,每1000步打印一下当前的步数和loss,用于观察训练进度和效果。
#定义训练方法
def train():#模型训练model.train()train_step = 0for batch_index, (imgs, targets) in enumerate(train_loader):#部署到device上imgs, targets = imgs.to(device), targets.to(device)#梯度初始化为0optimizer.zero_grad()#训练后的结果outputs = model(imgs)#计算损失loss = loss_fn(outputs, targets) #交叉熵损失,适用于多分类任务,二分类适用于sigmoid#反向传播loss.backward()#参数更新optimizer.step()train_step += 1if train_step % 1000 == 0:print(f"train Epoch: {train_step} , Loss: {loss.item()}")四.测试方法
我们会使用测试集对网络进行验证,通过model.eval()对模型进行验证,因为验证时不会计算梯度也不算反向传播,所以与训练不同的是需要使用语句with torch.no_grad(),同样的对测试集进行遍历(这里也可以仿照训练时的写法),之后,同样的计算outputs和loss,还会对test_loss和accuracy进行累计,观察网络在测试集的效果
#定义测试方法
def test():#模型验证model.eval()#正确率accuracy = 0.0#测试损失test_loss = 0.0with torch.no_grad(): #不会计算梯度也不会反向传播for imgs, targets in test_loader:#部署到device上imgs, targets = imgs.to(device), targets.to(device)#测试数据outputs = model(imgs)#计算测试损失loss = loss_fn(outputs, targets)test_loss += loss.item()#累计正确的值accuracy += (outputs.argmax(1) == targets).sum().item()test_loss /= len(test_loader)accuracy /= len(test_data)print(f"整体测试集上的损失: {test_loss},准确率 : {accuracy}")
五.模型保存
调用
torch.save(model, "my_CNN.pth")
print("模型已保存")
即可
整合上面代码
if __name__ == "__main__":#调用方法for epoch in range(1, epoch + 1):print(f"-------------------第{epoch}轮训练开始------------------")train()# 调整学习率scheduler.step()test()torch.save(model, "my_CNN.pth")print("模型已保存")
六.结果测试
创建另一个py文件,输入任意一张数字图片,对图片的数字进行预测(多分类)。
打开image,并将它resize为28*28,如这里使用的3.jpg为
用torch.load()加载模型
from PIL import Image
import torchvision
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequentialimg_path = "/home/lm/数字识别/picture/3.jpg"
image = Image.open(img_path)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")transform = torchvision.transforms.Compose([torchvision.transforms.Resize((28, 28)),torchvision.transforms.ToTensor()])image = transform(image)class Dight(nn.Module):def __init__(self):super().__init__()self.model = nn.Sequential(nn.Conv2d(1, 10, 5), #输入:batch*1*28*28 输出:batch*10*24*24(28 -5 + 1)nn.ReLU(), #保持shape不变 输出:batch*10*24*24(28 -5 + 1)nn.MaxPool2d(2), #输入:batch*10*24*24(28 -5 + 1) 输出:batch*10*12*12nn.Conv2d(10, 20, 3), #输入:batch*10*12*12 输出:batch*20*10*10(12 - 3 + 1)nn.ReLU(),nn.Flatten(),nn.Linear(20*10*10, 500), #输入:batch2000 输出:batch 500nn.ReLU(), #保持shape不变nn.Linear(500, 10) #输入:batch 500 输出:batch 10)def forward(self, x):return self.model(x)model = torch.load("/home/lm/数字识别/my_CNN.pth")image = torch.reshape(image, (1,1,28,28)).to(device)
model.eval()
with torch.no_grad():output = model(image)
print(output)print(output.argmax(1))最终输出为
tensor([[-14.0138, -4.8722, -7.2821, -11.5329, 6.1589, -8.7089, -7.8535,
-6.8521, -5.4265, -7.6144]], device='cuda:0')
tensor([4], device='cuda:0')
可以看出模型可以正确预测出图片类别
七.数据集转换
问题
在上一步加载图片时,我们使用了MINST数据集的图片,但是我们下载的MINST数据集的格式是这样的
数据集介绍
MNIST数据集来自美国国家标准与技术研究所, National Institute of Standards and Technology (NIST)。训练集(training set)由来自250个不同人手写的
数字构成,其中50%是高中学生,50%来自人口普查局(the Census Bureau)的工作人员。测试集(test set)也是同样比例的手写数字数据,但保证了测试集和训练集
的作者集不相交。
MNIST数据集一共有7万张图片,其中6万张是训练集,1万张是测试集。每张图片是28 × 28 28\times 2828×28的0 − 9 0-90−9的手写数字图片组成。每个图片是黑底
白字的形式,黑底用0表示,白字用0-1之间的浮点数表示,越接近1,颜色越白。每个元素表示图片对应的数字出现的概率,显然,该向量标签表示的是数字5。
MNIST数据集下载地址是http://yann.lecun.com/exdb/mnist/,它包含了4 44个部分:
(1)训练数据集:train-images-idx3-ubyte.gz (9.45 MB,包含60,000个样本)。
(2)训练数据集标签:train-labels-idx1-ubyte.gz(28.2 KB,包含60,000个标签)。
(3)测试数据集:t10k-images-idx3-ubyte.gz(1.57 MB ,包含10,000个样本)。
(4)测试数据集标签:t10k-labels-idx1-ubyte.gz(4.43 KB,包含10,000个样本的标签)。
数据集转换
编写一个脚本把原二进制格式的数据转换成jpg格式,这里先转换100张
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import cv2
import numpy as npwith open("./dataset/MNIST/raw/train-images-idx3-ubyte", "rb") as f:file = f.read()for i in range(1,100):image1 = [int(str(item).encode('ascii'), 16) for item in file[16+784*(i-1) : 16+784*i]]print(image1)image1_np = np.array(image1, dtype = np.uint8).reshape(28, 28, 1)cv2.imwrite(f"./picture/{i}.jpg", image1_np)最后,可在picture文件夹下找到转换完成的jpg数据,再用它进行结果测试即可
八.总结
本文介绍了一个通用简单的pytorch框架,还有很多不足和缺点,后续会在本系列继续完善框架
相关文章:
基于Pytorch的CNN手写数字识别
作为深度学习小白,我想把自己学习的过程记录下来,作为实践部分,我会写一个通用框架,并会不断完善这个框架,作为自己的入门学习。因此略过环境搭建和基础知识的步骤,直接从代码实战开始。 一.下载数据集并加…...
)
Java设计模式之观察者模式(Observer Pattern)
观察者模式(Observer Pattern)是一种常用的软件设计模式,它用于在对象之间建立一种一对多的依赖关系,当一个对象的状态发生变化时,它的所有依赖对象都会得到通知并自动更新。观察者模式属于行为型模式。 在观察者模式…...
最优化:建模、算法与理论(最优性理论2
5.7 约束优化最优性理论应用实例 5.7.1 仿射空间的投影问题 考虑优化问题 min x ∈ R n 1 2 ∣ ∣ x − y ∣ ∣ 2 2 , s . t . A x b \min_{x{\in}R^n}\frac{1}{2}||x-y||_2^2,\\ s.t.{\quad}Axb x∈Rnmin21∣∣x−y∣∣22,s.t.Axb 其中 A ∈ R m n , b ∈ R m …...

redis一主一从搭建
1.复制一份redis.conf并将6380都改成6379 [redist3-dtpoc-dtpoc-web06 conf]$ cp redis.conf redis_6380.conf [redist3-dtpoc-dtpoc-web06 conf]$ vi redis_6380.conf port 6380 daemonize yes pidfile "/home/redis/redis/logs/redis_6380.pid" logfile "/hom…...
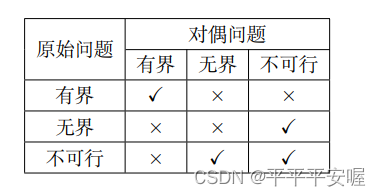
【MySql】8- 实践篇(六)
文章目录 1. MySql保证主备一致1.1 MySQL 主备的基本原理1.2 binlog 的三种格式对比1.3 循环复制问题 2. MySql保证高可用2.1 主备延迟2.2 主备延迟的来源2.3 可靠性优先策略2.4 可用性优先策略 3. 备库为何会延迟很久-备库并行复制能力3.1 MySQL 5.6 版本的并行复制策略3.2 Ma…...

Spring篇---第七篇
系列文章目录 文章目录 系列文章目录一、说说事务的传播级别二、Spring 事务实现方式三、Spring框架的事务管理有哪些优点一、说说事务的传播级别 Spring事务定义了7种传播机制: PROPAGATION_REQUIRED:默认的Spring事物传播级别,若当前存在事务,则加入该事务,若 不存在事务…...
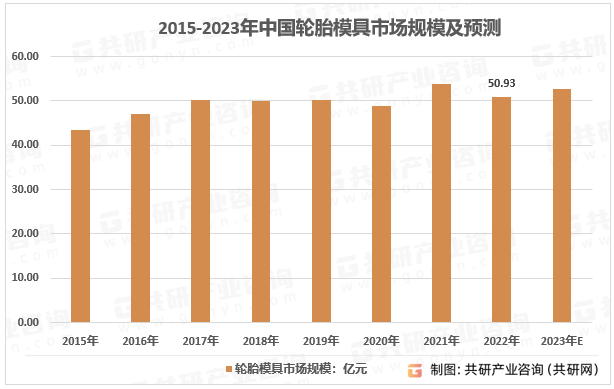
2023年中国轮胎模具需求量、竞争格局及行业市场规模分析[图]
轮胎模具是轮胎生产线中的硫化成形装备,是高技术含量、高精度及高附加值的个性化模具产品,尤其是轮胎的花纹、图案、字体以及其他外观特征的成形都依赖于轮胎模具,因此其制造技术难度较高。其主要功能是通过所成型材料(主要是橡塑…...
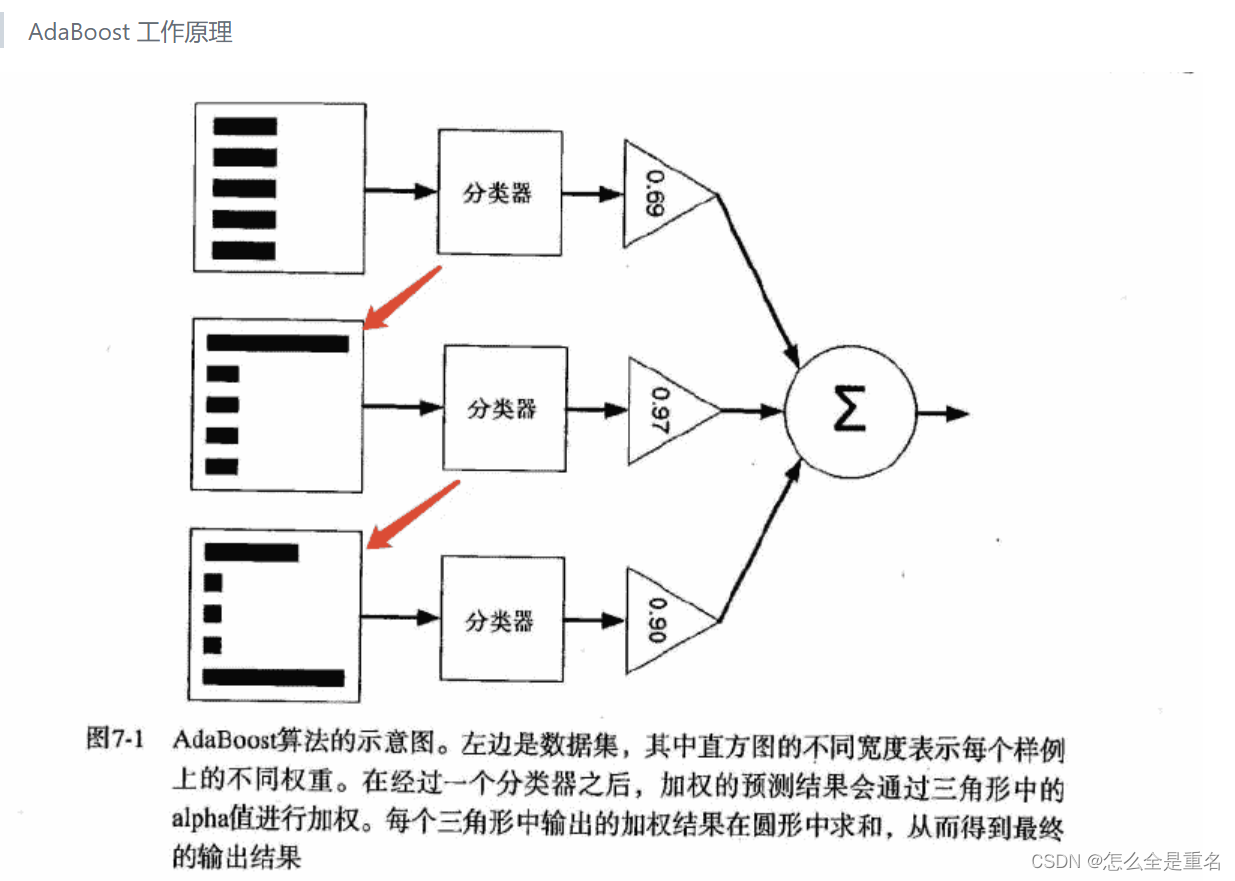
集成学习方法(随机森林和AdaBoost)
释义 集成学习很好的避免了单一学习模型带来的过拟合问题 根据个体学习器的生成方式,目前的集成学习方法大致可分为两大类: Bagging(个体学习器间不存在强依赖关系、可同时生成的并行化方法) 流行版本:随机森林(random forest)Boosting(个体…...

PeopleCode中Date函数的用法
语法 Date(date_num) 描述 The Date function takes a number in the form YYYYMMDD and returns a corresponding Date value. If the date is invalid, Date displays an error message. Date函数输入是一个形如“YYYYMMDD”的数字,返回一个相应的Date类型的值…...

解决 el-tree setChecked 方法偶尔失效的方法
目前在大多数公司中,菜单的权限控制都是不可或缺的功能 在和后端配合做权限控制的时候不可避免的会用到 el-tree 然而这个组件本身带的坑不少 我们需要回显对应角色拥有的菜单,在不严格的模式下,父节点的选中会连带子节点的选中 如果 &a…...
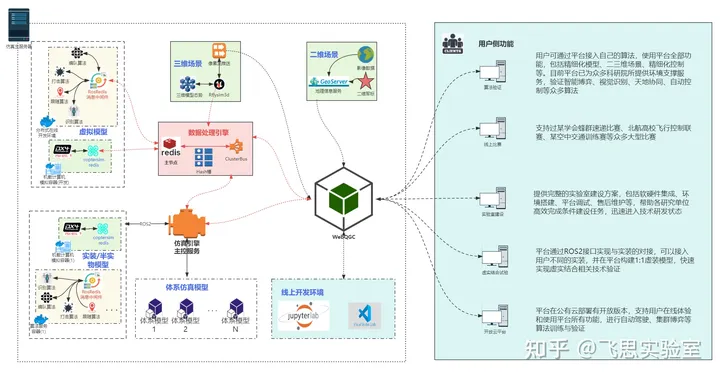
重磅发布!RflySim Cloud 智能算法云仿真平台亮相,助力大规模集群算法高效训练
RflySim Cloud智能算法云仿真平台(以下简称RflySim Cloud平台)是由卓翼智能及飞思实验室为无人平台集群算法验证、大规模博弈对抗仿真、人工智能模型训练等前沿研究领域研发的平台。主要由环境仿真模块、物理效应计算模块、多智能体仿真模块、分布式网络…...
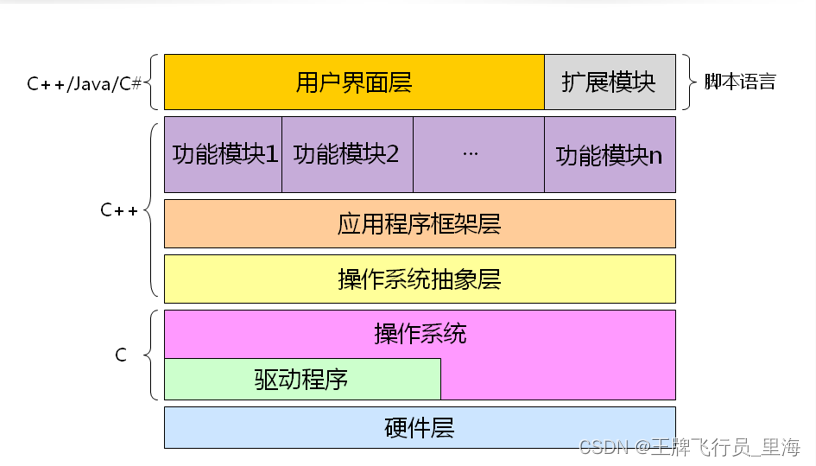
C++ 01.学习C++的意义-狄泰软件学院
一些历史 UNIX操作系统诞生之初是用汇编语言编写的随着UNIX系统的发展,汇编语言的开发效率成为瓶颈,所以需要一个新的语言替代汇编语言1971年通过对B语言改良,使其能直接产生机器代码,C语言诞生UNIX使用C语言重写,同时…...

微软正式发布开源应用平台 Radius平台
“ 10 月 18 日,微软 Azure 孵化团队正式发布开源应用平台 Radius,该平台将应用程序置于每个开发阶段的中心,重新定义应用程序的构建、管理与理解方式。” 简单的概括就是,它和Kubernetes不一样,Radius将应用程序放在每…...
)
排序算法(python)
排序算法 冒泡排序 一次比较相邻的两个数,每轮之后末尾的数字是确定的。 时间复杂度为 O ( n 2 ) O(n^2) O(n2),空间复杂度为 O ( 1 ) O(1) O(1),稳定。 def BUB(nums):for i in range(len(nums)):count 0for j in range(len(nums)-i-1)…...
一款简单漂亮的WPF UI - AduSkin
前言 经常会有同学会问,有没有好看简单的WPF UI库推荐的。今天就给大家推荐一款简单漂亮的WPF UI,融合多个开源框架组件:AduSkin。 WPF是什么? WPF 是一个强大的桌面应用程序框架,用于构建具有丰富用户界面的 Windo…...
)
Java面试题-Java核心基础-第七天(String)
目录 一、String、StringBuffer、StringBuilder的区别 二、String为什么是不可变的 三、字符串拼接用""还是用StringBuilder 四、String 中的equals和Object中的equals的区别 五、字符串常量池的作用了解吗? 六、String s1 new String("abc&qu…...

路飞项目多方式登录、手机号短信验证注册接口
登录注册页面分析 用户板块需要写的接口 用户名密码登录(多方式登录)获取手机验证码接口手机号验证码登录注册接口验证手机号是否存在接口 验证手机号是否存在 视图类 from rest_framework.viewsets import ViewSet from rest_framework.decorator…...

信息学奥赛一本通-编程启蒙3003:练2.1 春节快乐
3003:练2.1 春节快乐 时间限制: 1000 ms 内存限制: 65536 KB 提交数: 10805 通过数: 7830 【题目描述】 一年一度的春节到啦!试着把你的春节祝福表达在代码中吧。 【输入】 无 【输出】 输出一行"Happy Spring Festival!" 【输入…...
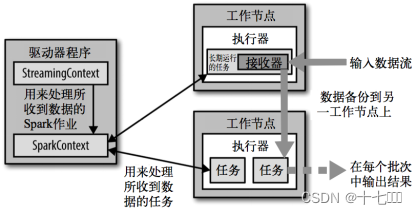
SparkStreaming入门
概述 实时/离线 实时:Spark是每个3秒或者5秒更新一下处理后的数据,这个是按照时间切分的伪实时。真正的实时是根据事件触发的数据计算,处理精度达到ms级别。离线:数据是落盘后再处理,一般处理的数据是昨天的数据&…...
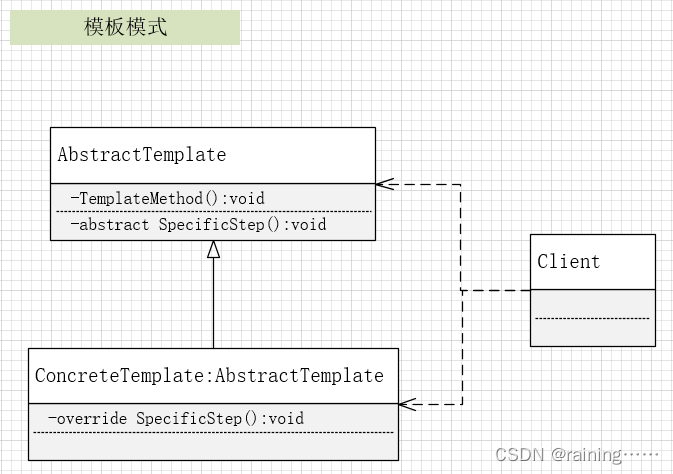
设计模式:模板模式(C#、JAVA、JavaScript、C++、Python、Go、PHP)
简介: 模板模式,它是一种行为型设计模式,它定义了一个操作中的算法的框架,将一些步骤延迟到子类中实现,使得子类可以不改变一个算法的结构即可重定义该算法的某些特定步骤。 通俗地说,模板模式就是将某一行…...

量子数据加载编译框架:误差分配与混合状态制备技术
1. 量子数据加载编译框架概述量子计算正逐步从理论走向实际应用,而数据加载作为连接经典与量子世界的桥梁,其效率直接影响整个量子算法的可行性。传统量子数据加载方法往往采用"一刀切"策略,忽视了不同数据类型和精度需求之间的差异…...

基于STM32G474的微型逆变器设计方案:源代码、原理图及PCB布局一体化展示
400w微型逆变器, 基于stm32g474实现 设计方案,不是成品 带有源代码、原理图(AD)、PCB(AD)系统概述 本系统基于STM32G474微控制器实现了一个400W微型逆变器的核心控制功能。系统采用先进的双ADC同步采样架构,结合多种保护机制,实现了高效、可靠…...

Stream-rec直播录制神器:5分钟搭建你的专属录播系统
Stream-rec直播录制神器:5分钟搭建你的专属录播系统 【免费下载链接】stream-rec Automatic streaming record tool. Live stream and bullet comments recorder. 虎牙/抖音/斗鱼/Twitch/PandaTV/微博直播,弹幕自动录制 项目地址: https://gitcode.com…...

终极抢票神器:大麦助手DamaiHelper完整使用指南
终极抢票神器:大麦助手DamaiHelper完整使用指南 【免费下载链接】damaihelper 支持大麦网,淘票票、缤玩岛等多个平台,演唱会演出抢票脚本 项目地址: https://gitcode.com/gh_mirrors/dam/damaihelper 还在为抢不到演唱会门票而烦恼吗&…...
)
保姆级教程:用Python为你的硬件写一个ROS2驱动节点(附完整代码)
从零构建ROS2硬件驱动节点:Python实战指南 为什么需要为硬件编写ROS2驱动节点? 在机器人开发中,硬件设备与ROS系统的无缝对接是项目成功的关键。想象一下,当你拿到一款全新的激光雷达或电机控制器时,如何让它成为ROS生…...

ArcGIS栅格重分类:从土地利用到灾害评估,5个实战场景带你玩转Reclassify
ArcGIS栅格重分类实战指南:5个场景解锁空间分析新维度 当GIS分析从实验室走向真实世界,栅格重分类技术便成了连接数据与决策的关键桥梁。不同于基础教程中机械化的按钮操作,真正的重分类艺术在于如何将原始数据转化为具有地理意义的决策图层。…...

ArcGIS Pro二次开发:用C#和Geoprocessing工具5分钟搞定面要素重叠检查
ArcGIS Pro二次开发:5分钟实现面要素拓扑检查的自动化方案 地理信息系统(GIS)工作中,面要素的拓扑检查是确保数据质量的关键环节。传统手动操作不仅耗时费力,还容易因操作失误导致结果偏差。本文将展示如何利用ArcGIS Pro SDK和C#代码&#x…...

如何快速掌握FMA音乐分析数据集:终极开源音乐AI研究指南
如何快速掌握FMA音乐分析数据集:终极开源音乐AI研究指南 【免费下载链接】fma FMA: A Dataset For Music Analysis 项目地址: https://gitcode.com/gh_mirrors/fm/fma FMA音乐分析数据集是音乐信息检索(MIR)和人工智能音乐分析领域的宝…...

LazyLLM:低代码多智能体应用框架,简化AI开发与部署
1. 项目概述:LazyLLM,为“懒人”而生的多智能体应用构建框架如果你和我一样,在尝试构建一个像样的AI应用时,感到无比头疼——不是被各种框架的API调用、服务部署、模型切换、数据流编排搞得焦头烂额,就是被“快速迭代”…...

别再只用3σ了!用MATLAB的filloutliers函数,基于MAD法5分钟搞定数据离群值清洗
别再只用3σ了!用MATLAB的filloutliers函数,基于MAD法5分钟搞定数据离群值清洗 数据分析中,离群值就像隐藏在数据集中的"捣蛋鬼",稍不留神就会扭曲统计结果、误导模型训练。传统3σ方法虽然简单,但当数据分布…...