绘制核密度估计图
简介
核密度估计图(Kernel Density Estimation,KDE)是一种用于估计数据分布的非参数方法,通常用于可视化和理解数据的分布情况。它通过平滑地估计数据的概率密度函数(PDF)来显示数据的分布特征,尤其在连续变量上非常有用。
KDE图通常表现为一条平滑的曲线,描述了数据在特定值附近的密度。这条曲线称为核密度估计。核密度估计是通过将每个数据点视为一个小的概率分布(通常是高斯分布或其他核函数)并将它们叠加而得到的。这样,核密度估计提供了一个对数据分布的连续估计,而不仅仅是一个直方图或散点图。
特点
核密度估计图的主要特点包括:
-
平滑性: KDE图是平滑的,不受特定的数据点的影响。这使得它可以更好地捕捉数据的分布特征。
-
面积为1: KDE图的总面积在整个范围内等于1,因为它是概率密度函数的估计。
-
峰值和谷值: KDE图上的峰值表示数据集中的高密度区域,而谷值表示稀疏区域。
-
帮助比较: 使用KDE图,你可以比较不同数据集的分布,或者比较数据在不同条件下的分布。这对于发现数据之间的差异和相似性非常有用。
KDE图通常用于探索数据的分布,分析数据的形状和特性,以及为其他分析和建模任务提供数据的可视化表示。你可以使用数据可视化工具(如Seaborn或Matplotlib)来创建KDE图以更好地理解数据。
绘制
可以使用Python中的Seaborn库的seaborn.kdeplot()函数来绘制核密度估计图(Kernel Density Estimation,KDE)。核密度估计图是一种用于估计数据分布的非参数方法,通常用于可视化数据的连续分布。以下是绘制核密度估计图的示例代码:
import matplotlib.pyplot as plt
import seaborn as sns
# 防止中文乱码
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False
import pandas as pddf = pd.read_csv('data/data.csv').dropna()# 分离正负样本
positive_samples = df[df['label'] == 0]
negative_samples = df[df['label'] == 1]# 创建一个4x4的子图布局,每行4个子图
fig, axes = plt.subplots(4, 4, figsize=(32, 32), dpi=100)
fig.subplots_adjust(hspace=0.5)# 循环遍历每个特征列,绘制核密度估计图
for i, feature in enumerate(df.columns[:-1]): # 不包括标签列row, col = i // 4, i % 4 # 确定子图的位置ax = axes[row, col]# 绘制正负样本的核密度估计图sns.kdeplot(positive_samples[feature], label='标签0', shade=True, ax=ax)sns.kdeplot(negative_samples[feature], label='标签1', shade=True, ax=ax)ax.set_title(feature)ax.set_xlabel('Value')ax.set_ylabel('Density')ax.legend()# 如果名称太长,可以旋转x轴标签,以免重叠
for ax in axes.flat:ax.tick_params(axis='x', rotation=45)# 显示图形
plt.show()
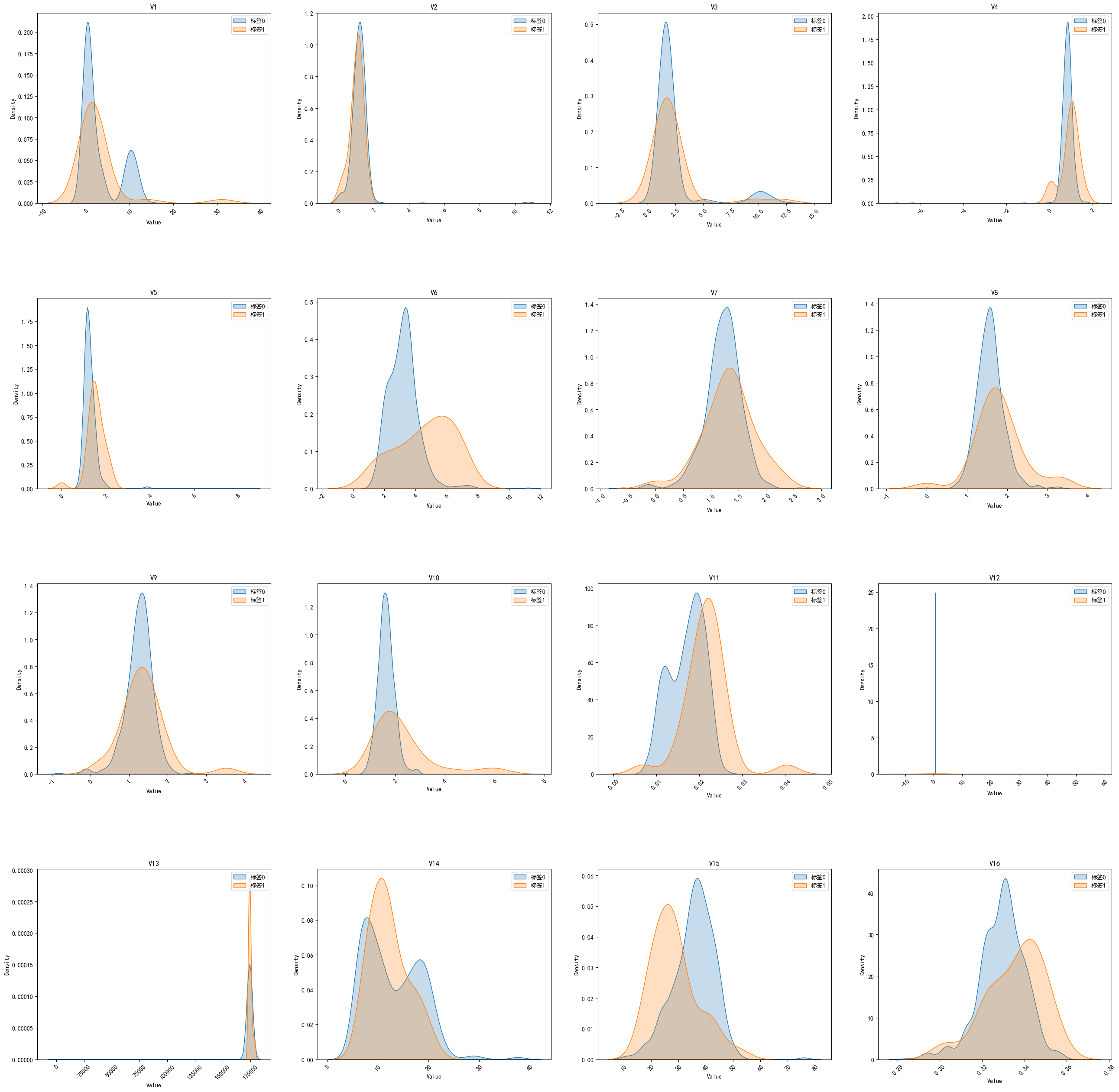
分析
以下是一些可以从核密度估计图中分析的信息:
-
数据分布比较: 通过观察核密度估计图,可以了解每个特征在正样本和负样本中的数据分布情况。这有助于识别数据中是否存在重叠,以及正负样本之间的相似性或差异。
-
峰值和谷值: 核密度估计图上的峰值表示数据中的密集区域,而谷值表示数据中的稀疏区域。可以观察正负样本的峰值和谷值,以确定它们在特征空间中的分布。
-
交叉点: 在核密度估计图中,正负样本的核密度曲线交叉的地方可能是有用的特征。如果两个曲线在某个特征值上交叉,这意味着这个特征可能不太适合区分正负样本。
-
重叠区域: 如果核密度估计图显示正负样本的核密度曲线在某些特征值上有重叠,那么这些特征值可能不太能区分正负样本。
-
明显分离的峰值: 如果核密度估计图显示在某些特征值上正负样本的核密度曲线有明显的分离峰值,那么这些特征值可能对区分正负样本有很好的区分能力。
-
特征之间的比较: 如果绘制了多个特征的核密度估计图,可以比较它们来确定哪些特征对正负样本的区分最为有效。通常情况下,具有更大的分离性和较小的重叠的特征更适合用来区分正负样本。
总之,核密度估计图可以帮助你直观地了解数据的分布情况,以及哪些特征对于区分正负样本是有帮助的。在正负样本不平衡的情况下,分析核密度估计图有助于确定哪些特征可能是有助于构建分类模型的重要特征。
另外,如果使用的是训练集和测试集,对比训练集和验证集的核密度估计图在特征筛选中可以发挥关键作用。这种对比有助于评估特征对模型的性能和泛化能力的影响。以下是一些使用对比核密度估计图来筛选特征的方法以及其用途:
-
检测特征的分布差异: 通过绘制训练集和验证集的核密度估计图,可以比较它们的形状和分布。如果特征在训练集和验证集之间的分布差异很大,这可能表明特征在模型的泛化性能上存在问题。较大的差异可能意味着模型在验证集上的性能会下降。
-
确定稳定性: 稳定性是指特征在不同数据集上的表现是否一致。如果特征在训练集和验证集上的核密度估计图非常相似,那么这些特征可能是稳定的,有助于模型的泛化。
-
特征选择: 通过对比核密度估计图,可以识别那些在验证集上表现稳定且分布差异较小的特征。这些特征可能是有用的,可以用来构建稳健的模型。相反,那些在验证集上表现差异大的特征可能需要谨慎考虑是否保留。
-
减少过拟合风险: 如果特征在训练集上有很好的性能,但在验证集上表现较差,可能表示过拟合。对比核密度估计图有助于确定是哪些特征引起了过拟合问题,从而进行特征筛选或正则化以减少过拟合的风险。
相关文章:
绘制核密度估计图
简介 核密度估计图(Kernel Density Estimation,KDE)是一种用于估计数据分布的非参数方法,通常用于可视化和理解数据的分布情况。它通过平滑地估计数据的概率密度函数(PDF)来显示数据的分布特征,…...
基于深度学习网络的蔬菜水果种类识别算法matlab仿真
目录 1.算法运行效果图预览 2.算法运行软件版本 3.部分核心程序 4.算法理论概述 4.1数据集准备 4.2构建深度学习模型 4.3模型训练 4.4模型评估 5.算法完整程序工程 1.算法运行效果图预览 2.算法运行软件版本 matlab2022a 3.部分核心程序 clc; clear; close all; wa…...
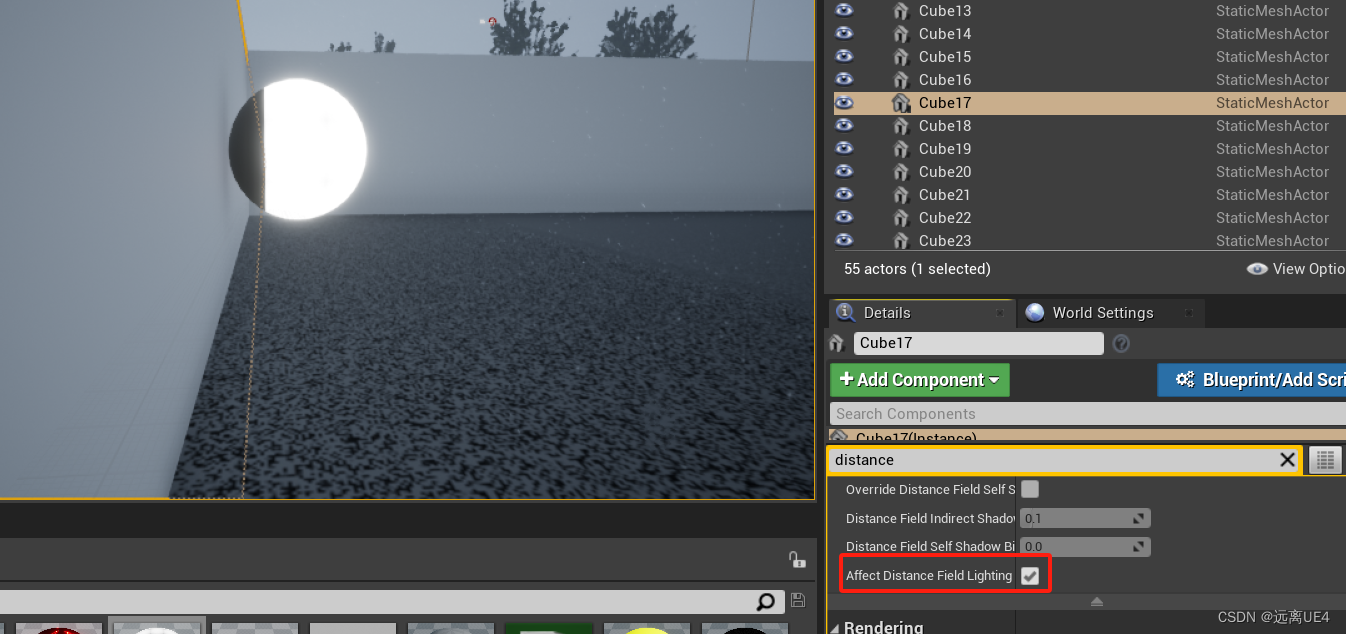
UE4 距离场
在项目设置的渲染模块可打开距离场 把该节点连上,该节点的意思是,距离表面越近,材质显示值为0 不接近表面时: 接近表面时 可勾选该值即可看到距离场具体效果: 未接触表面时: 接触表面时: 产生…...
】26 - QNX Ethernet MAC 驱动 之 emac_rx_thread_handler 数据接收线程 源码分析)
【SA8295P 源码分析 (四)】26 - QNX Ethernet MAC 驱动 之 emac_rx_thread_handler 数据接收线程 源码分析
【SA8295P 源码分析】26 - QNX Ethernet MAC 驱动 之 emac_rx_thread_handler 数据接收线程 源码分析 一、emac_rx_thread_handler():通过POLL 轮询方式获取数据二、emac_rx_poll_mq():调用 pdata->clean_rx() 来处理消息三、emac_configure_rx_fun_ptr():配置 pdata->…...

VR全景广告:让消费者体验沉浸式交互,让营销更有趣
好的产品都是需要广告宣传的,随着科技的不断发展,市面上的广告也和多年前的传统广告不同,通过VR技术,可以让广告的观赏性以及科技感更加强烈,并且相比于视频广告,成本也更低。 在广告营销中,关键…...
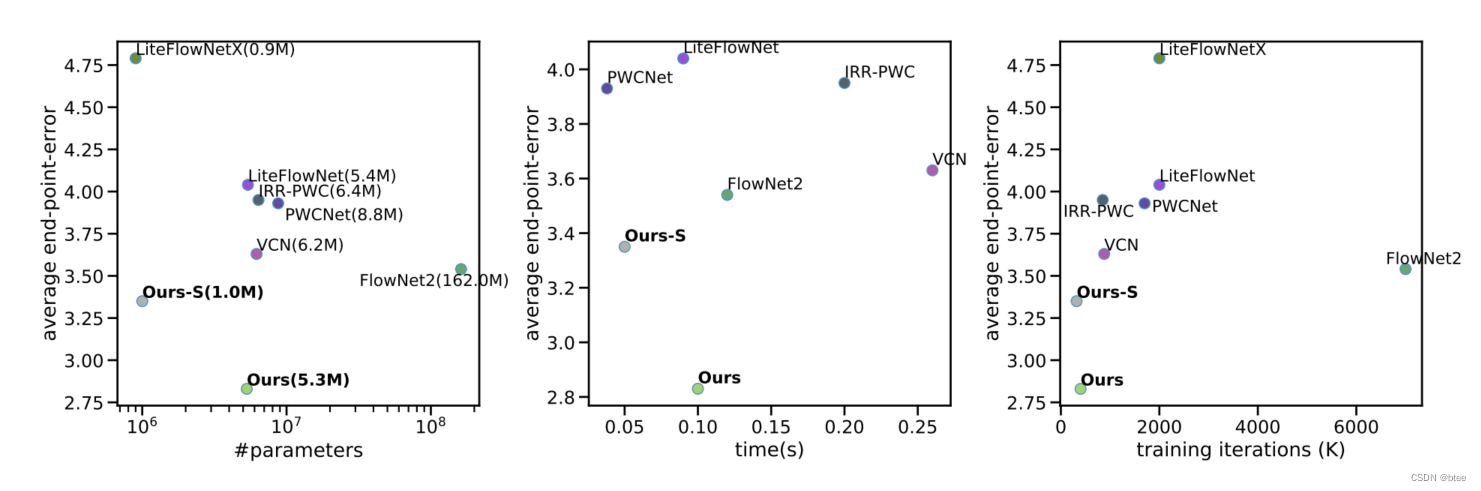
论文阅读 | RAFT: Recurrent All-Pairs Field Transforms for Optical Flow
RAFT: Recurrent All-Pairs Field Transforms for Optical Flow ECCV2020光流任务best paper 论文地址:【here】 代码地址:【here】 介绍 光流是对两张相邻图像中的逐像素运动的一种估计。目前碰到的一些困难包括:物体的快速运动ÿ…...

神经网络的发展历史
神经网络的发展历史可以追溯到上世纪的数学理论和生物学研究。以下是神经网络发展史的详细概述: 早期的神经元模型: 1943年,Warren McCulloch和Walter Pitts提出了一种神经元模型,被称为MCP神经元模型,它模拟了生物神经…...

【单元测试】--单元测试最佳实践
一、单元测试代码风格 编写单元测试代码时,遵循一致的风格和最佳实践是非常重要的,因为它有助于提高代码的可读性、可维护性和可靠性。以下是一些常见的单元测试代码风格和最佳实践: 命名约定: 测试方法的名称应当清晰、描述性&…...
llava1.5-部署
llava1.5 ——demo部署 下载代码和权重 新建weights文件夹,并下载到LLaVA/weights/中。->需要修改文件名为llava-版本,例如llava-v1.5-7b. 运行 启动控制台 python -m llava.serve.controller --host 0.0.0.0 --port 4006启动gradio python -m…...

倒计时 1 天|KCD 2023 杭州站
距离「KCD 2023 杭州站」开始只有 1 天啦 大家快点预约到现场哦~ KCD 2023 活动介绍 HANGZHOU 关于 KCD Kubernetes Community Days(KCD)由云原生计算基金会(CNCF)发起,由全球各国当地的 CNCF 大使、CNCF 员…...
什么是模拟芯片,模拟芯片都有哪些测试指标?
模拟芯片又称处理模拟信号的集成电路 模拟集成电路主要是指由电容、电阻、晶体管等组成的模拟电路集成在一起用来处理模拟信号的集成电路。有许多的模拟集成电路,如运算放大器、模拟乘法器、锁相环、电源管理芯片等。 模拟集成电路的主要构成电路有:放…...

C++-json(2)-unsigned char-unsigned char*-memcpy-strcpy-sizeof-strlen
1.类型转换: //1.赋值一个不知道长度的字符串unsigned char s[] "kobe8llJfFwFSPiy"; //1.用一个字符串初始化变量 unsigned int s_length strlen((char*)s); //2.获取字符串长度//2.字符串里有双引号"" 需要…...
python安装第三方包
1 命令行下载 pip install 包名称 进入命令行输入该命令 由于pip是连接的国外的网站进行包的下载,所以有的时候会速度很慢。 我们可以通过如下命令,让其连接国内的网站进行包的安装: pip install -i https://pypi.tuna.tsinghua.edu.cn/s…...
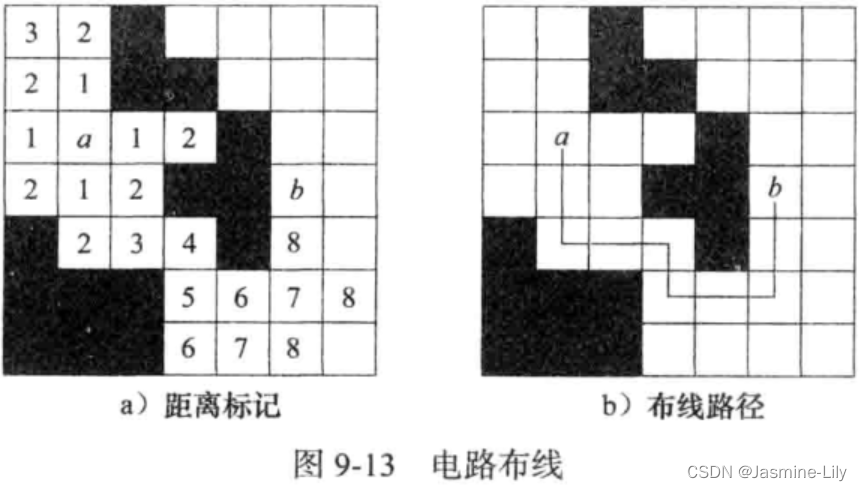
《数据结构、算法与应用C++语言描述》-队列的应用-电路布线问题
《数据结构、算法与应用C语言描述》-队列的应用-电路布线问题 问题描述 在 迷宫老鼠问题中,可以寻找从迷宫入口到迷宫出口的一条最短路径。这种在网格中寻找最短路径的算法有许多应用。例如,在电路布线问题的求解中,一个常用的方法就是在布…...

GC overhead limit exceeded问题
1.问题现象 程序包运行时候发生了java.lang.OutOfMemoryError: GC overhead limit exceeded异常, 详细信息如下 org.apache.ibatis.exceptions.PersistenceException: ### Error querying database. Cause: org.jboss.util.NestedSQLException: Error; - nested t…...

What‘s new in Arana v0.2.0
Arana 定位于云原生数据库代理,它可以以 sidecar 模式部署为数据库服务网格,项目地址是 https://github.com/arana-db/arana 。Arana 提供透明的数据访问能力,当用户在使用时,可以不用关心数据库的 “分片” 细节,像使…...

STM32 串口接收中断被莫名关闭
使用cubeidestm32f4进行调试,发现UART4串口会被莫名的关掉,导致不能接收数据,经过排查如下: HAL_StatusTypeDef HAL_UART_Transmit(UART_HandleTypeDef *huart, uint8_t *pData, uint16_t Size, uint32_t Timeout) {uint8_t *pd…...
接口测试vs功能测试
接口测试和功能测试的区别: 本文主要分为两个部分: 第一部分:主要从问题出发,引入接口测试的相关内容并与前端测试进行简单对比,总结两者之前的区别与联系。但该部分只交代了怎么做和如何做?并没有解释为什…...
)
前端面试题整理(1.0)
1.nextTick原理 Vue是异步执行Dom更新的,一旦观察到数据变化,Vue就会开启一个队列,然后把在同一个事件循环(event loop)当中观察到数据变化的Watcher推送到这个队列。如果这个Watcher被触发多次,智慧被推送…...

使用Spire.PDF for Python插件从PDF文件提取文字和图片信息
目录 一、Spire.PDF插件的安装 二、从PDF文件提取文字信息 三、从PDF文件提取图片信息 四、提取图片和文字信息的进阶应用 总结 在Python中,提取PDF文件的文字和图片信息是一种常见的需求。为了满足这个需求,许多开发者会选择使用Spire.PDF插件&…...

从用户操作反推设计:如何用ABAP ALV的SEL_MODE参数优化你的SAP报表体验?
从用户操作反推设计:如何用ABAP ALV的SEL_MODE参数优化你的SAP报表体验? 在SAP系统开发中,ALV(ABAP List Viewer)报表是业务用户最常接触的界面之一。作为ABAP开发者,我们往往过于关注功能实现而忽略了交互…...
)
【仅限首批信创集成商内部流通】Docker 27 国产化适配白皮书(含17个真实POC环境日志+4类CPU架构差异对照表)
第一章:Docker 27 国产化适配总体技术路线与政策背景近年来,国家密集出台《“十四五”数字经济发展规划》《关键信息基础设施安全保护条例》及《信创产业三年行动计划(2023–2025)》等政策文件,明确将容器技术纳入基础…...

从‘饱和’与‘残存失调’聊起:手把手分析OOS与IOS两种失调消除技术该怎么选
从‘饱和’与‘残存失调’谈OOS与IOS技术选型:工程师的决策指南 在高速高精度比较器设计中,失调消除技术的选择往往成为影响整体性能的关键决策点。当您面对一个增益设计较高的前置放大器时,输出饱和风险与残余失调容忍度之间的矛盾会变得尤为…...
)
保姆级教程:用Vector Configurator Pro配置AUTOSAR Dem模块的通用参数(附避坑清单)
保姆级教程:用Vector Configurator Pro配置AUTOSAR Dem模块的通用参数(附避坑清单) 在汽车电子领域,诊断事件管理(Dem)模块是AUTOSAR架构中至关重要的组成部分,负责处理故障诊断相关功能。对于刚…...

案例真题详解:Redis 主从复制~终于搞懂了
今天,我们以25年5月架构师的案例真题为引,来拆解下Redis主从复制的详细流程(当然你学了,拿去“吊打”面试官也是可以的): 主从复制分为初始化阶段(全量同步)和运行阶段(增…...

DFM可制造性设计核心原则
DFM可制造性设计:定义、原则与应用实例 1. 定义与核心理念 可制造性设计,是一种将产品设计与其制造工艺深度融合的系统化工程方法。其核心目标是在产品设计阶段,就充分考虑并优化所有相关的制造、装配、测试和成本因素,以确保设…...
)
别让输入法偷走你的快捷键!手把手教你用OpenArk排查Windows热键冲突(附搜狗/微软拼音排查法)
别让输入法偷走你的快捷键!手把手教你用OpenArk排查Windows热键冲突(附搜狗/微软拼音排查法) 每次按下CtrlShiftF准备全局搜索代码时,却发现输入法弹出了符号面板——这种突如其来的快捷键冲突,就像咖啡洒在键盘上一样…...

无名杀:开启免费开源三国杀网页版的策略革命
无名杀:开启免费开源三国杀网页版的策略革命 【免费下载链接】noname 项目地址: https://gitcode.com/GitHub_Trending/no/noname 在当今数字化游戏时代,无名杀作为一款免费开源的三国杀网页版卡牌游戏,为玩家提供了无需下载、跨平台…...

ATPG实战避坑:那些被工具标记为‘UT’的故障,真的可以不管吗?
ATPG实战避坑:那些被工具标记为‘UT’的故障,真的可以不管吗? 在芯片测试领域,ATPG(自动测试模式生成)工具是工程师们不可或缺的得力助手。它能够自动生成测试模式,帮助我们发现芯片中的潜在故障…...

前端包管理工具对比
前端包管理工具对比:选择最适合你的利器 在现代前端开发中,包管理工具是不可或缺的一环。无论是管理项目依赖、提升开发效率,还是优化构建流程,选择合适的工具都至关重要。目前主流的前端包管理工具包括npm、Yarn和pnpmÿ…...