【TensorFlow1.X】系列学习笔记【基础一】
【TensorFlow1.X】系列学习笔记【基础一】
大量经典论文的算法均采用 TF 1.x 实现, 为了阅读方便, 同时加深对实现细节的理解, 需要 TF 1.x 的知识
文章目录
- 【TensorFlow1.X】系列学习笔记【基础一】
- 前言
- 线性回归
- 非线性回归
- 逻辑回归
- 总结
前言
本篇博主将用最简洁的代码由浅入深实现几个小案例,让读者直观体验深度学习模型面对线性回归、非线性回归以及逻辑回归的处理逻辑和性能表现。【代码参考】
线性回归
线性回归是一种常见回归分析方法,它假设目标值与特征之间存在线性关系。线性回归模型通过拟合线性函数来预测目标值。线性回归模型的形式比较单一的,即满足一个多元一次方程。常见的线性方程如: y = w × x + b {\rm{y}} = w \times x + b y=w×x+b,但是观测到的数据往往是带有噪声,于是给现有的模型一个因子 ε \varepsilon ε,并假设该因子符合标准正态分布: y = w × x + b + ε {\rm{y}} = w \times x + b + \varepsilon y=w×x+b+ε。对于线性模型,深度学习可以通过构建单层神经网络来描述,这个单层神经网络通常被称为全连接层(Fully Connected Layer)或线性层(Linear Layer),其中每个神经元都与上一层的所有神经元相连接,且没有非线性激活函数。
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt# 随机生成100个数据点,服从“0~1”均匀分布
x_data = np.random.rand(100)# 提升维度(100)-->(100,1)
x_data = x_data[:, np.newaxis]# 制作噪声,shape与x_data一致
noise = np.random.normal(0, 0.02, x_data.shape)# 构造目标公式
y_data = 0.8 * x_data + 0.1 + noise# 输入层:placeholder用于接收训练的数据
x = tf.placeholder(tf.float32, [None, 1], name="x_input")
y = tf.placeholder(tf.float32, [None, 1], name="y_input")# 构造线性模型
b = tf.Variable(0., name="bias")
w = tf.Variable(0., name="weight")
out = w * x_data + b# 构建损失函数
loss = 1/2*tf.reduce_mean(tf.square(out - y))
# print(loss)# 定义优化器
optim = tf.train.GradientDescentOptimizer(0.1)
# print(optim)# 最小化损失函数
train_step = optim.minimize(loss)# 初始化全部的变量
init = tf.global_variables_initializer()# 训练迭代
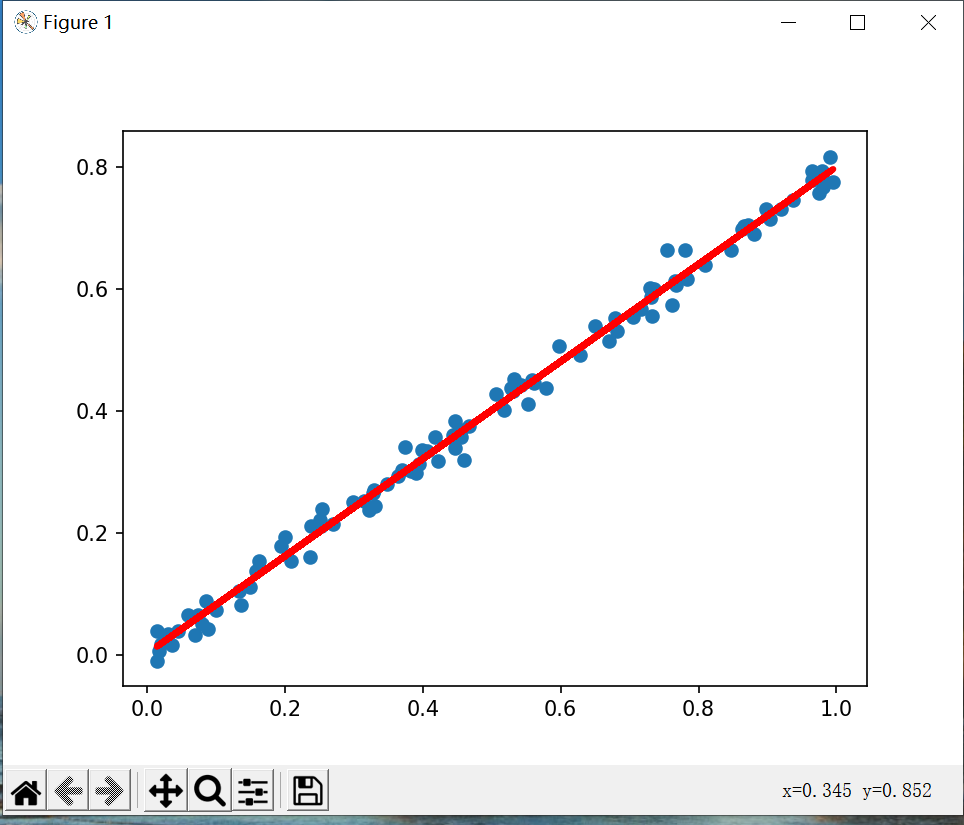
with tf.Session() as sess:sess.run(init)for step in range(2000):sess.run([loss, train_step], {x: x_data, y: y_data})if step % 200 == 0:w_value, b_value, loss_value = sess.run([w, b, loss], {x: x_data, y: y_data})print("step={}, k={}, b={}, loss={}".format(step, w_value, b_value, loss_value))prediction_value = sess.run(out, feed_dict={x: x_data})plt.figure()
plt.scatter(x_data, y_data)
plt.plot(x_data, prediction_value, "r-", lw=3)
plt.show()
非线性回归
非线性回归也是一种常见回归分析方法,它假设目标值与特征之间存在非线性关系。与线性回归不同,非线性回归模型可以拟合复杂的非线性关系。通过拟合非线性函数到数据中,非线性回归模型可以找到最佳的函数参数,以建立一个能够适应数据的非线性关系的模型。非线性回归模型的形式可以是多项式函数、指数函数、对数函数、三角函数等任意形式的非线性函数,这些函数可以包含自变量的高次项、交互项或其他非线性变换。常见的非线性方程如: y = x 2 {\rm{y}} = {x^2} y=x2,但是观测到的数据往往是带有噪声,于是给现有的模型一个因子 ε \varepsilon ε,并假设该因子符合标准正态分布: y = x 2 + ε {\rm{y}} = {x^2} + \varepsilon y=x2+ε。深度学习模型通常由多个神经网络层组成,每一层都包含许多神经元。每个神经元接收来自前一层的输入,并通过激活函数对输入进行非线性转换,然后将结果传递给下一层,通过多个层的堆叠,深度学习模型可以学习到多个抽象层次的特征表示。
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt# 生成200个数据点,从“-0.5~0.5”均匀排布
x_data = np.linspace(-0.5, 0.5, 200)# 提升维度(200)-->(200,1)
x_data = x_data[:, np.newaxis]# 制作噪声,shape与x_data一致
noise = np.random.normal(0, 0.02, x_data.shape)# 构造目标公式
y_data = np.square(x_data) + noise# 输入层:placeholder用于接收训练的数据
x = tf.placeholder(tf.float32, [None, 1], name="x_input")
y = tf.placeholder(tf.float32, [None, 1], name="y_input")# 隐藏层
W_1 = tf.Variable(tf.random_normal([1, 10]))
b_1 = tf.Variable(tf.zeros([1, 10]))
a_1 = tf.matmul(x, W_1) + b_1
out_1 = tf.nn.tanh(a_1)# 输出层
W_2 = tf.Variable(tf.random_normal([10, 1]))
b_2 = tf.Variable(tf.zeros([1, 1]))
a_2 = tf.matmul(out_1, W_2) + b_2
out_2 = tf.nn.tanh(a_2)# 构建损失函数
loss = 1/2*tf.reduce_mean(tf.square(out_2- y))# 定义优化器
optim = tf.train.GradientDescentOptimizer(0.1)# 最小化损失函数
train_step = optim.minimize(loss)# 初始化全部的变量
init = tf.global_variables_initializer()# 训练
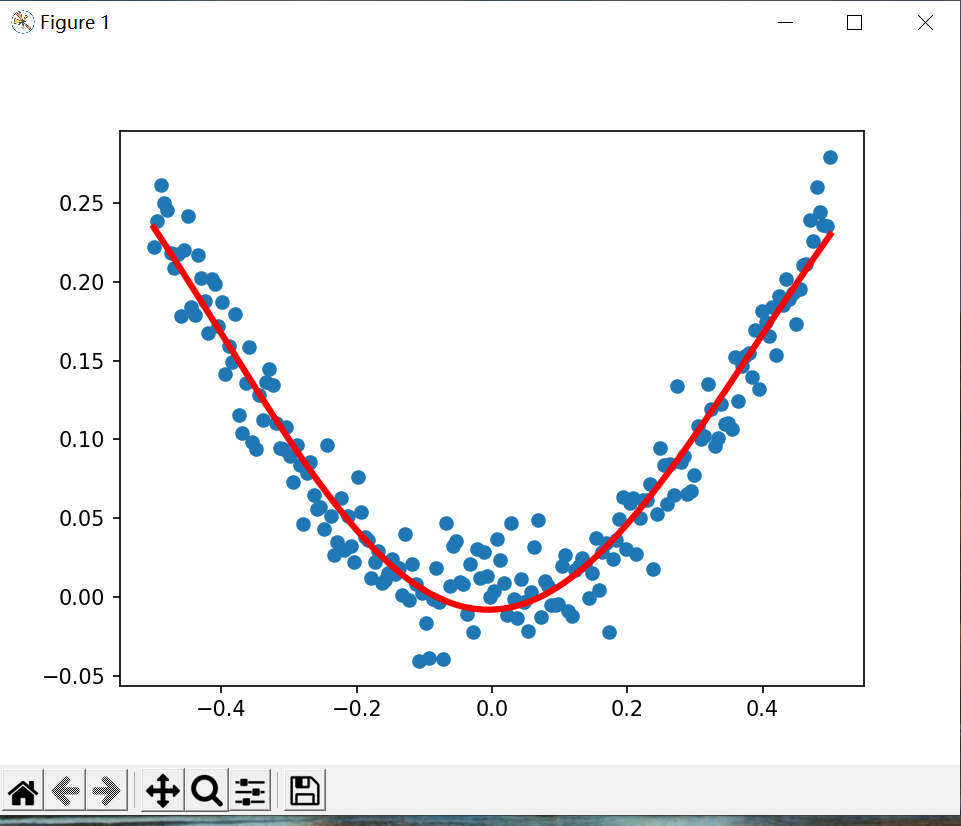
with tf.Session() as sess:sess.run(init)for epc in range(10000):sess.run([loss, train_step], {x:x_data,y:y_data})if epc % 1000 == 0:loss_value = sess.run([loss], {x:x_data,y:y_data})print("epc={}, loss={}".format(epc, loss_value))prediction_value = sess.run(out_2, feed_dict={x:x_data})plt.figure()
plt.scatter(x_data, y_data)
plt.plot(x_data, prediction_value, "r-", lw=3)
plt.show()
逻辑回归
逻辑回归是一种用于分类问题的统计模型,它假设目标变量与特征之间存在概率关系。逻辑回归模型通过线性函数和逻辑函数的组合来建模概率,以预测样本属于某个类别的概率。逻辑回归本身是一个简单的线性分类模型,但深度学习可以自动地学习特征表示,并通过多层非线性变换来模拟更复杂的关系。MNIST数据集通常被认为是深度学习的入门级别任务之一,可以帮助初学者熟悉深度学习的基本概念、模型构建和训练过程。虽然MNIST是一个入门级别的任务,但它并不能完全代表实际应用中的复杂视觉问题。在实践中,还需要面对更大规模的数据集、多类别分类、图像分割、目标检测等更具挑战性的问题。
import numpy as np
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import matplotlib.pyplot as plt# 载入数据集:首次调用时自动下载数据集(MNIS 数据集)并将其保存到指定的目录中。
mnist = input_data.read_data_sets("MNIST", one_hot=True)# 设置batch_size的大小
batch_size = 50
# (几乎)所有数据集被用于训练所需的次数
n_batchs = mnist.train.num_examples // batch_size# 输入层:placeholder用于接收训练的数据
# 这里图像大小是28×28,对数据集进行压缩28×28=782
x = tf.placeholder(tf.float32, [None, 784],name="x-input")
# 10分类(数字0~9)
y = tf.placeholder(tf.float32, [None, 10], name="y-input")# 隐藏层
w = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([1,10]))
# 全连接层
prediction = tf.matmul(x, w) + b
prediction_softmax = tf.nn.softmax(prediction)
# 交叉熵损失函数+计算张量在指定维度(默认0维)上的平均值
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=prediction, labels=y))# 定义优化器
optim = tf.train.GradientDescentOptimizer(0.01)# 最小化损失函数
train_step = optim.minimize(loss)# 初始化全部的变量
init = tf.global_variables_initializer()# 计算准确率:选择概率最大的数字作为预测值与真实值进行比较,统计正确的个数再计算准确率
correct_prediction = tf.equal(tf.argmax(prediction_softmax, 1), tf.argmax(y, 1))
accuarcy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))# GPU使用和显存分配:最大限度为1/3
gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=0.333)
# 用于配置 GPU
sess = tf.Session(config=tf.ConfigProto(gpu_options=gpu_options))epoch_arr = np.array([])
acc_arr = np.array([])
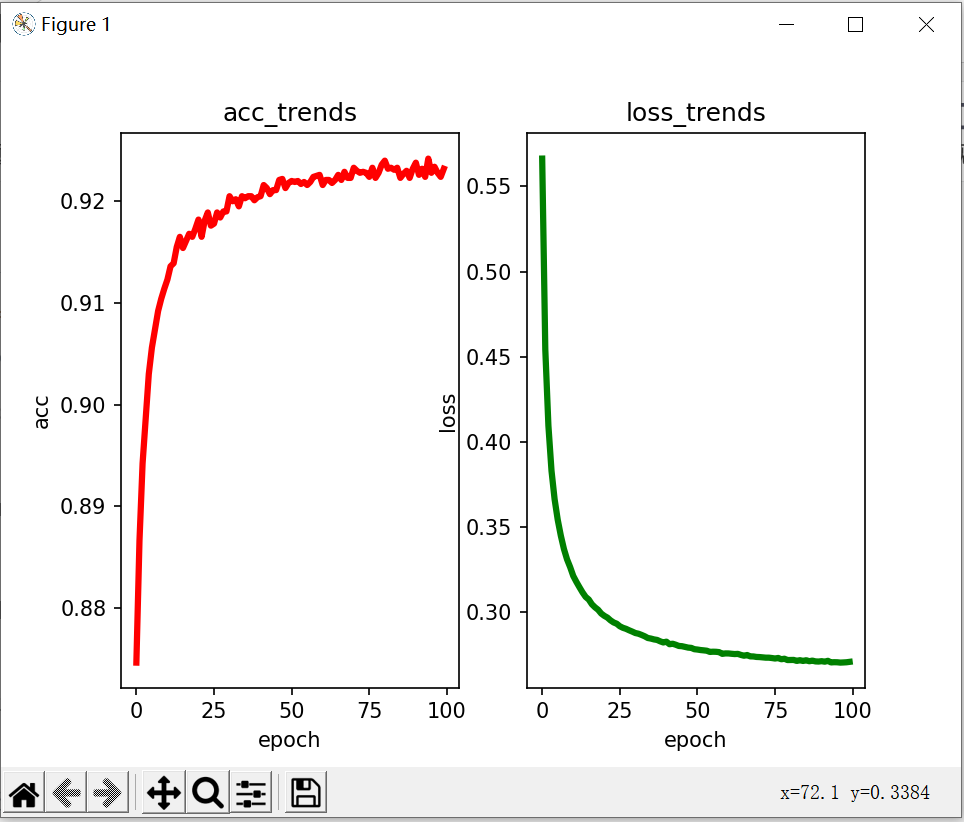
loss_arr = np.array([])with tf.Session() as sess:sess.run(init)# 训练总次数for epoch in range(200):# 每轮训练的迭代次数for batch in range(n_batchs):batch_x, batch_y = mnist.train.next_batch(batch_size)sess.run([train_step],{x:batch_x, y: batch_y})# 用训练集每完成一次训练,则用测试集验证acc, los = sess.run([accuarcy, loss], feed_dict = {x:mnist.test.images, y:mnist.test.labels})epoch_arr= np.append(epoch_arr, epoch)acc_arr = np.append(acc_arr, acc)loss_arr = np.append(loss_arr, los)print("epoch: ", epoch, "acc: ",acc, "loss: ", los)# 分别显示精度上升趋势和损失下降趋势
fig, (ax1, ax2) = plt.subplots(1, 2)ax1.set_title('acc_trends')
ax1.set_xlabel('epoch')
ax1.set_ylabel('acc')
ax1.plot(epoch_arr, acc_arr, "r-", lw=3)ax2.set_title('loss_trends')
ax2.set_xlabel('epoch')
ax2.set_ylabel('loss')
ax2.plot(epoch_arr, loss_arr, "g-", lw=3)
plt.show()
总结
训练深度学习模型通常需要大量的标记数据和计算资源。一种常用的训练算法是反向传播算法,它通过最小化损失函数来优化模型参数。常见的损失函数是均方误差损失函数和交叉熵损失函数,可以度量模型输出的概率分布与实际标签之间的差异。在实际应用中,深度学习通常用于处理非线性回归,而逻辑回归和线性回归则是其中的一些特殊情况。
相关文章:
【TensorFlow1.X】系列学习笔记【基础一】
【TensorFlow1.X】系列学习笔记【基础一】 大量经典论文的算法均采用 TF 1.x 实现, 为了阅读方便, 同时加深对实现细节的理解, 需要 TF 1.x 的知识 文章目录 【TensorFlow1.X】系列学习笔记【基础一】前言线性回归非线性回归逻辑回归总结 前言 本篇博主将用最简洁的代码由浅入…...

Linux 基础操作手记三(内存篇)
Linux 基础操作手记三 释放内存虚拟机彻底无网络测试网速设置虚拟内存交换空间未使用虚拟机设置虚拟内存无法开机问题GParted - 分配内存系统盘扩容自己 释放内存 sync && echo 3 > /proc/sys/vm/drop_caches 虚拟机彻底无网络 还原默认设置,静静的等待…...

NodeJS的初使用,以及引入第三方插件和安装淘宝镜像的教程
NodeJs 命令 npm init -y 生成package.json文件npm i jquery --save–dev 开发依赖(jQuery后面还可以跟模块,可以有多个)npm i jquery --save 生产依赖npm i jquery --D 开发依赖npm uninstall jquery 卸载删除npm i 把删掉的模块,全部重新加载回来 1.介绍 1.什么是NodeJs?…...

Java读取文件的N种方法
1.概述 在这篇文章里, 我们将探索不同的方式从文件中读取数据。 首先, 学习通过标准的的Java类,从classpath、URL或者Jar中加载文件。 然后,学习通用BufferedReader, Scanner, StreamTokenizer, DataInputStream, SequenceInput…...

子类的构造与析构过程
一、简介 父类,也称基类,其构造方法和析构方法不能被继承; 子类,也称派生类,继承父类的方法和属性,但要加入新的构造和析构函数。 二、构造与析构过程 构造:先调用父类——>再调用子类 析构&…...

位运算相关笔记
位运算 Part 1:基础 左移:左移一位,相当于某数乘以 2 2 2。左移 x x x位,相当于该数乘以 2 x 2^x 2x。 右移:右移一位,相当于某数除以 2 2 2。右移 x x x位,相当于该数除以 2 x 2^x 2x。 与运算&…...
uniapp 安装 u-view 组件库
u-view 组件库安装教程:https://uviewui.com/components/install.html 注:以下使用 HBuilderx 安装 u-view 2.0 版本,不适用于其它版本。 1.安装 u-view 组件库 2、注册并登录 HBuilderx 账号,点击下载 u-view 组件库。 3、点击…...

Go 语言的成功案例:谁在使用 Go?
Go 语言,也被称为 Golang,是一门由Google开发的开源编程语言。自从2009年首次亮相以来,它在编程社区中崭露头角,并吸引了越来越多的开发者和组织。Go 以其高效的并发性、出色的性能和简单易懂的语法而闻名。在本文中,我…...

UG\NX二次开发 实时查看 NX 日志文件
文章作者:里海 来源网站:王牌飞行员_里海_里海NX二次开发3000例,里海BlockUI专栏,C\C++-CSDN博客 感谢粉丝订阅 感谢 a18037198459 订阅本专栏,非常感谢。 简介 实时查看 NX 日志文件,有助于分析保存时间等。打开WindowsPowerShell并实时获取日志文件内容的小功能。 效果 代…...

ZooKeeper+HBase分布式集群环境搭建
安装版本:hadoop-2.10.1、zookeeper-3.4.12、hbase-2.3.1 一、zookeeper集群搭建与配置 1.下载zookeeper安装包 2.解压移动zookeeper 3.修改配置文件(创建文件夹) 4.进入conf/ 5.修改zoo.cfg文件 6.进入/usr/local/zookeeper-3.4.12/zkdata…...
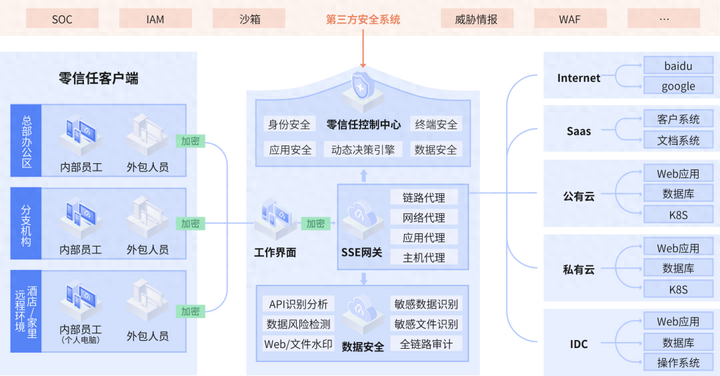
喜讯!持安科技入选2023年北京市知识产权试点单位!
近日,北京市知识产权局发布了“2023年度北京市知识产权试点示范单位及2020年度北京市知识产权试点示范单位复审通过名单”名单。 经过严格的初审、形式审核和专家评审,北京持安科技有限公司入选“2023年北京市知识产权试点单位”。 北京市知识产权试点示…...
)
笙默考试管理系统-MyExamTest----codemirror(39)
笙默考试管理系统-MyExamTest----codemirror(39) 目录 一、 笙默考试管理系统-MyExamTest 二、 笙默考试管理系统-MyExamTest 三、 笙默考试管理系统-MyExamTest 四、 笙默考试管理系统-MyExamTest 五、 笙默考试管理系统-MyExamTest 笙默考试…...
抛砖引玉:Redis 与 接口自动化测试框架的结合
接口自动化测试已成为保证软件质量和稳定性的重要手段。而Redis作为一个高性能的缓存数据库,具备快速读写、多种数据结构等特点,为接口自动化测试提供了强大的支持。勇哥这里粗略介绍如何结合Python操作Redis,并将其应用于接口自动化测试框架…...

网站如何才能不被黑,如何做好网络安全
当企业网站受到攻击时,首页文件可能被篡改,百度快照也可能被劫持并重定向到其他网站。首要任务是加强网站的安全防护。然而,许多企业缺乏建立完善的网站安全防护体系的知识。因此,需要专业的网站安全公司来提供相应的保护措施。今…...

人脸写真FaceChain风格写真的试玩(二)
接着上一篇【人脸写真FaceChain的简单部署记录(一)】来试玩一下。 1 无限风格写真 参考:让你拥有专属且万能的AI摄影师AI修图师——FaceChain迎来最大版本更新 1.1 人物形象训练 这里的步骤比较简单,就是选择照片,然…...
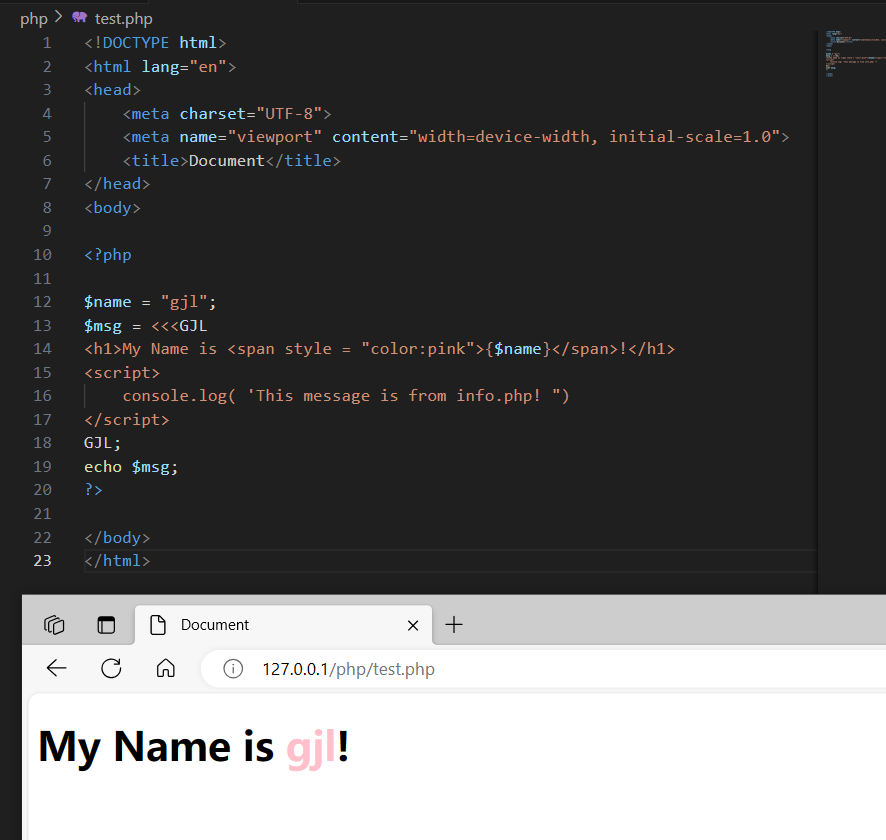
PHP 变量
变量 变量的声明、使用、释放 变量定义 形式 $ 变量名;严格区分大小写 $name; $Name; $NAME //三个变量不是同一个变量字母、数字、下划线组成,不能以数字开头,不能包含其他字符(空白字符、特殊字符) 驼峰式命名法、下划线式命名法 $first_name; $fi…...

牛客小白月赛79
给定一个数字n,你可以对它进行接下来的操作—— 选择数字中任意一个数位删除 例如对1024选择操作百位,数字则变成了124;对1024选择操作千位,数字则变成了024 我们称一个数字是干净的,当且仅当数字满足以下任意一种…...
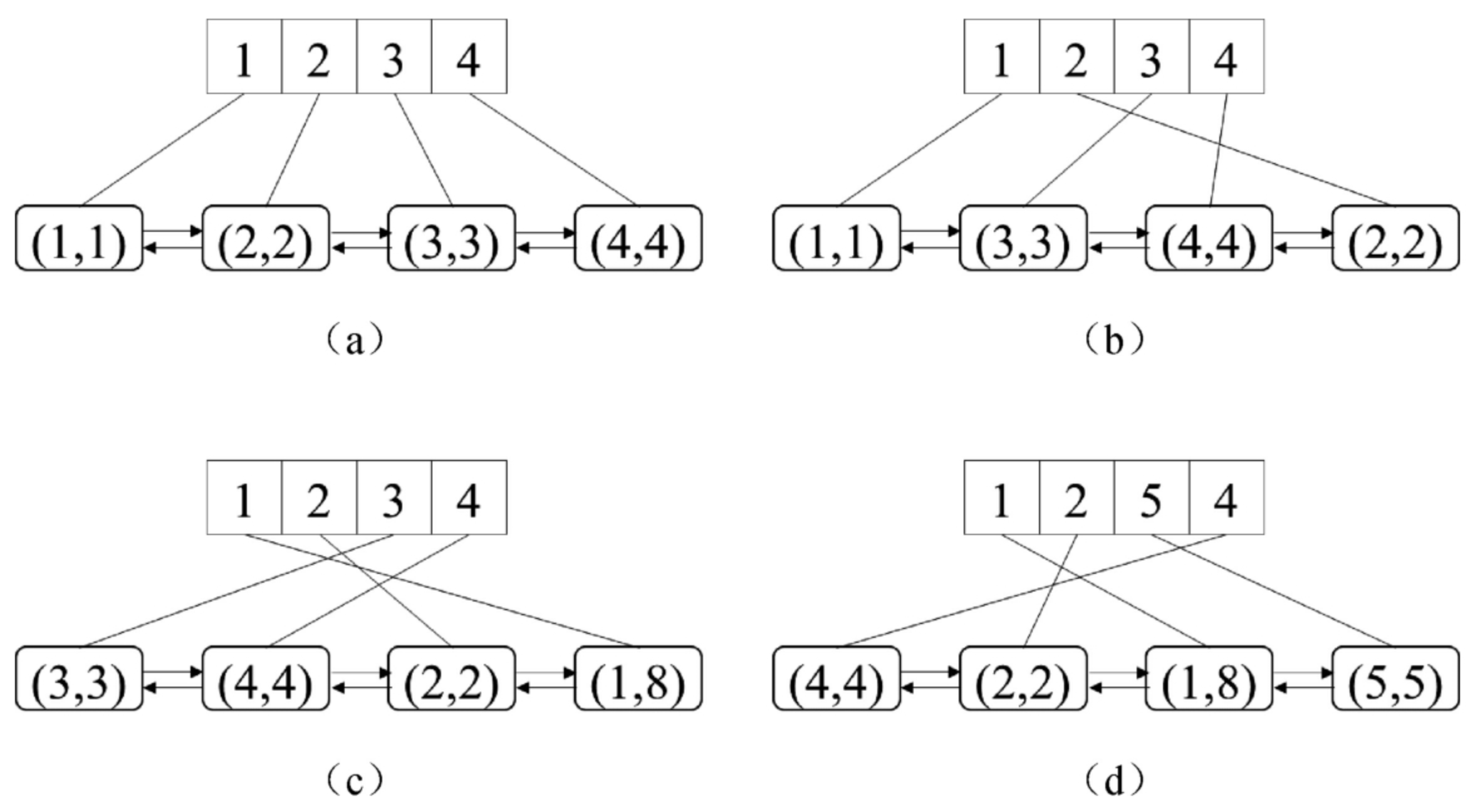
面试算法31:最近最少使用缓存
题目 请设计实现一个最近最少使用(Least Recently Used,LRU)缓存,要求如下两个操作的时间复杂度都是O(1)。 get(key):如果缓存中存在键key,则返回它对应的值…...

如何处理前端SEO(搜索引擎优化)?
聚沙成塔每天进步一点点 ⭐ 专栏简介 前端入门之旅:探索Web开发的奇妙世界 欢迎来到前端入门之旅!感兴趣的可以订阅本专栏哦!这个专栏是为那些对Web开发感兴趣、刚刚踏入前端领域的朋友们量身打造的。无论你是完全的新手还是有一些基础的开发…...
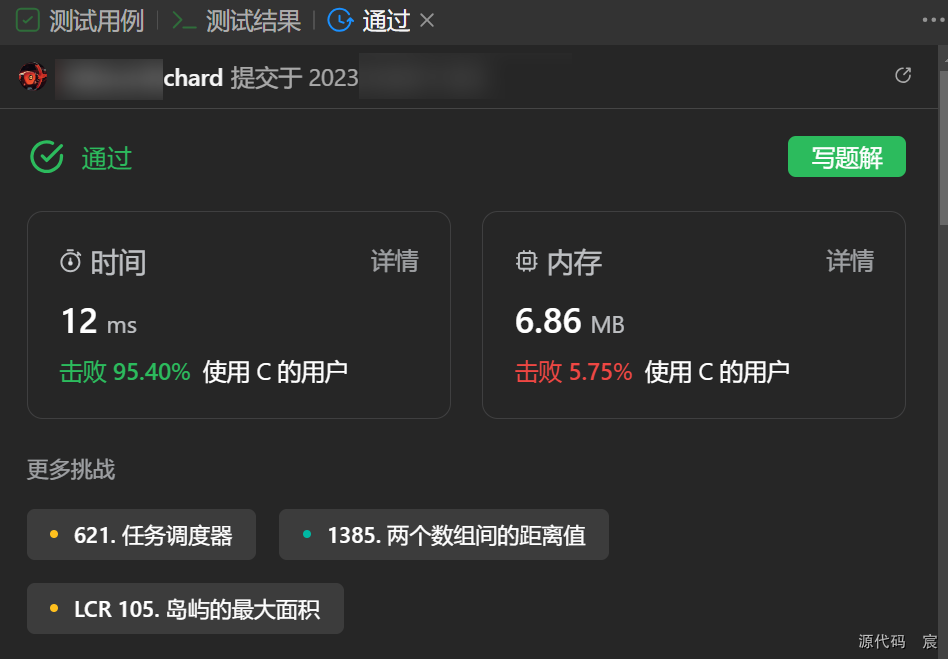
Leetcode—2529.正整数和负整数的最大计数【简单】
2023每日刷题(四) Leetcode—2529.正整数和负整数的最大计数 遍历法实现代码 int maximumCount(int* nums, int numsSize){int i;int neg 0, pos 0;for(i 0; i < numsSize; i) {if(nums[i] < 0) {neg;}if(nums[i] > 0) {pos;}}return (neg…...

语言模型记忆架构:KV与FFN记忆技术解析
1. 语言模型记忆架构:从理论到实践的深度解析在当今大规模语言模型(LLM)快速发展的背景下,如何高效地存储和检索海量知识成为关键挑战。传统Transformer架构将所有知识编码在稠密参数中,导致模型体积庞大且推理效率低下…...

打造企业级网络监控:自定义插件开发终极指南
打造企业级网络监控:自定义插件开发终极指南 【免费下载链接】SmokePing The Active Monitoring System 项目地址: https://gitcode.com/gh_mirrors/smo/SmokePing 在当今复杂的网络环境中,构建可靠的自定义网络监控插件已成为技术团队的核心竞争…...

抖音批量下载终极指南:告别手动保存,5分钟掌握高效下载技巧
抖音批量下载终极指南:告别手动保存,5分钟掌握高效下载技巧 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browse…...

real-anime-z镜像合规审计:GDPR/CCPA数据处理条款适配情况说明
real-anime-z镜像合规审计:GDPR/CCPA数据处理条款适配情况说明 1. 镜像概述与部署方式 real-anime-z是基于Z-Image基础镜像构建的LoRA模型,专门用于生成高质量的动画风格图片。该镜像使用Xinference框架进行部署,并通过Gradio提供了用户友好…...

给ESP8266智能时钟加个‘离线记忆’:断网后如何用ArduinoJson缓存天气数据?
ESP8266智能时钟的离线生存指南:用ArduinoJson实现数据持久化 当WiFi信号突然消失,你的智能时钟是否变成了"智障"时钟?这个问题困扰着许多物联网开发者。本文将带你深入探索如何为ESP8266智能时钟打造可靠的离线数据缓存系统&#…...
Mybatis-Plus字段策略FieldStrategy深度对比:NOT_NULL、NOT_EMPTY、IGNORED到底怎么选?(附Spring Boot 3.x配置示例)
MyBatis-Plus字段策略实战指南:如何为不同业务场景选择最优FieldStrategy? 在数据持久层开发中,空值处理是个看似简单却暗藏玄机的问题。想象一下这样的场景:用户修改个人资料时,清空昵称字段应该更新为NULL还是保持原…...

导数概念解析:从基础计算到实际应用
1. 导数概念的本质与直观理解微积分中的导数概念,本质上描述的是函数在某一点处的瞬时变化率。想象你正在驾驶汽车行驶在高速公路上,仪表盘上的速度表指针不断摆动——这个实时显示的速度值,就是你的位置函数关于时间的导数。在数学表达上&am…...

番茄小说下载器完整指南:永久保存心爱小说的终极解决方案
番茄小说下载器完整指南:永久保存心爱小说的终极解决方案 【免费下载链接】fanqienovel-downloader 下载番茄小说 项目地址: https://gitcode.com/gh_mirrors/fa/fanqienovel-downloader 还在为番茄小说中的精彩内容担心下架而烦恼吗?fanqienovel…...

别再瞎调了!Fluent DPM模型这3个参数设置不对,仿真结果差十倍
Fluent DPM模型参数优化实战:避开颗粒追踪的三大陷阱 在计算流体动力学(CFD)仿真中,离散相模型(DPM)的准确设置往往是决定仿真成败的关键。许多工程师在使用Fluent进行喷雾、粉尘或颗粒两相流分析时,常常陷入"参数调参师"的困境——…...

Jable视频下载终极指南:5分钟掌握永久保存高清视频技巧
Jable视频下载终极指南:5分钟掌握永久保存高清视频技巧 【免费下载链接】jable-download 方便下载jable的小工具 项目地址: https://gitcode.com/gh_mirrors/ja/jable-download 你是否曾经遇到过这样的情况?好不容易在Jable.tv找到一部心仪的视频…...