4、Kafka 消费者
5.1 Kafka 消费方式

5.2 Kafka 消费者工作流程
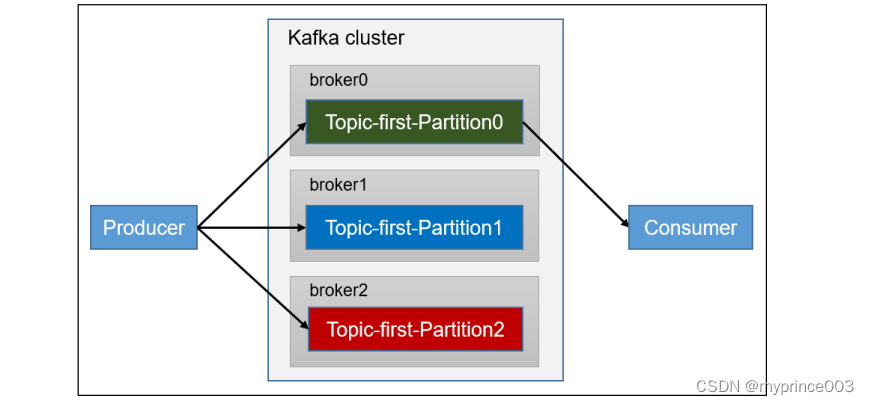
5.2.1 消费者总体工作流程
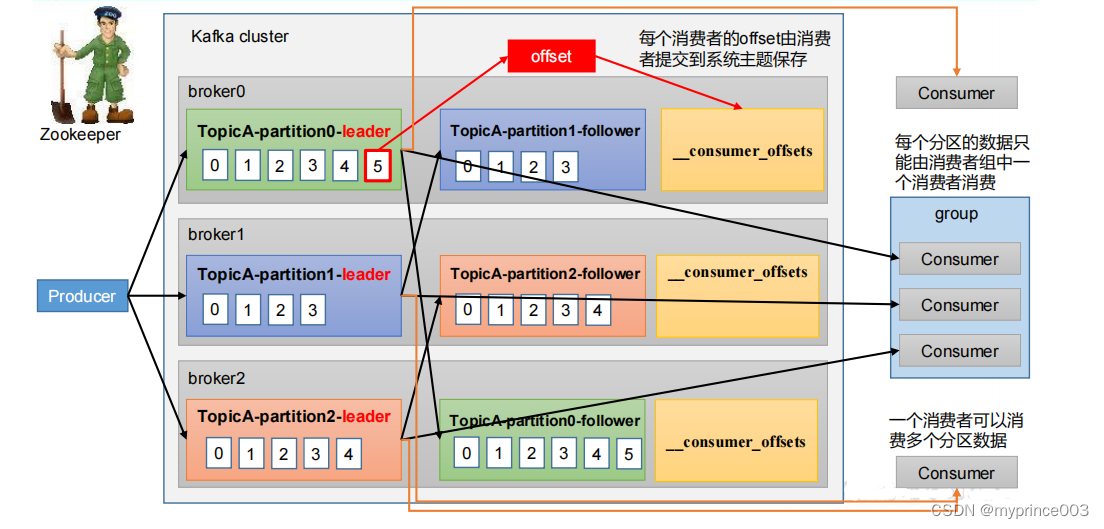
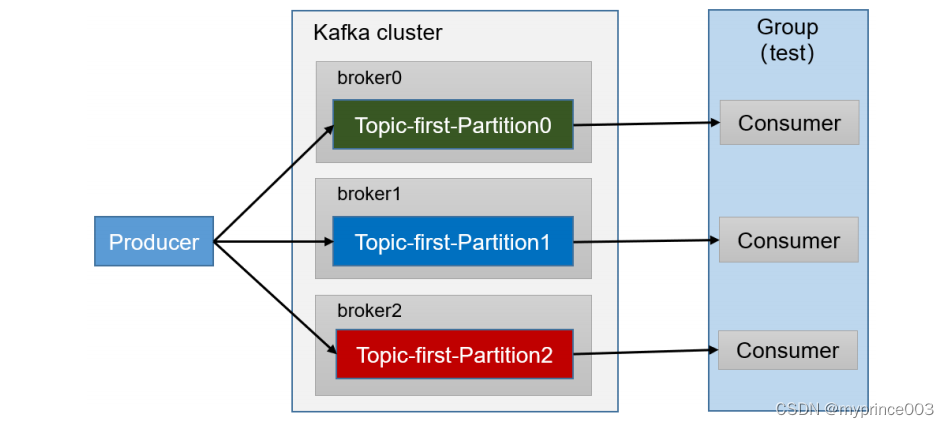
5.2.2 消费者组原理
Consumer Group(CG):消费者组,由多个consumer组成。形成一个消费者组的条件,是所有消费者的groupid相同。
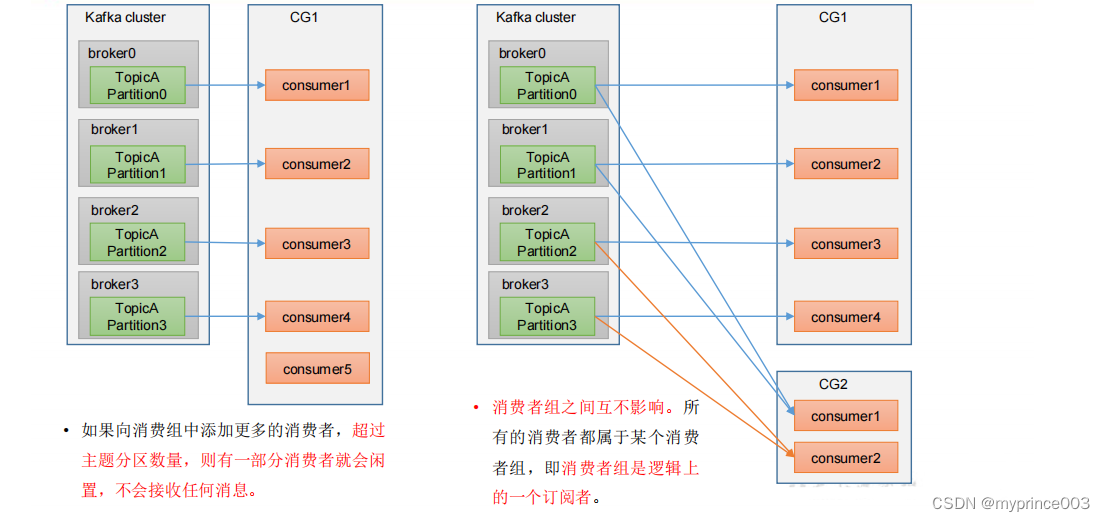
• 消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费。
• 消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。

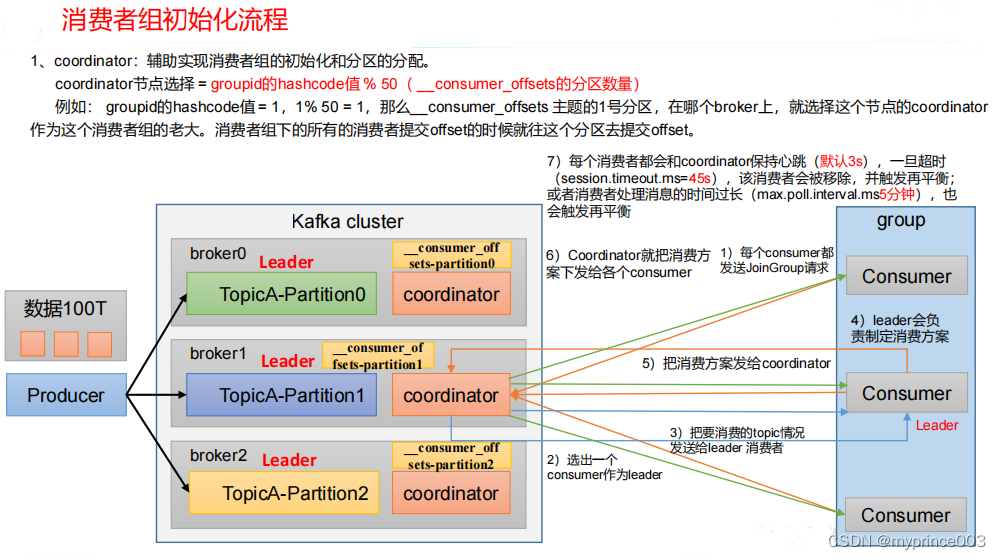
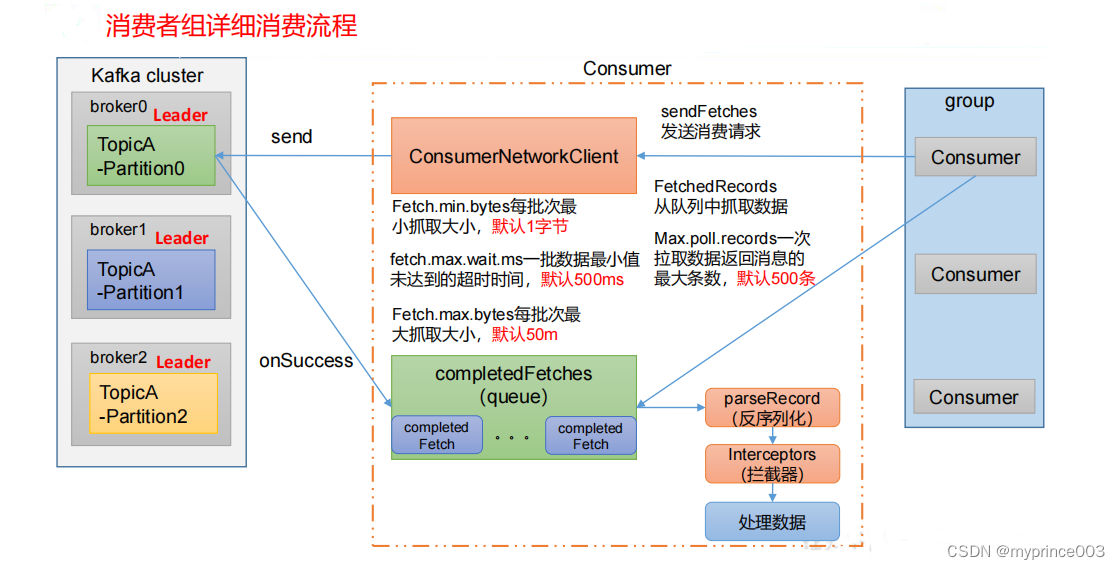
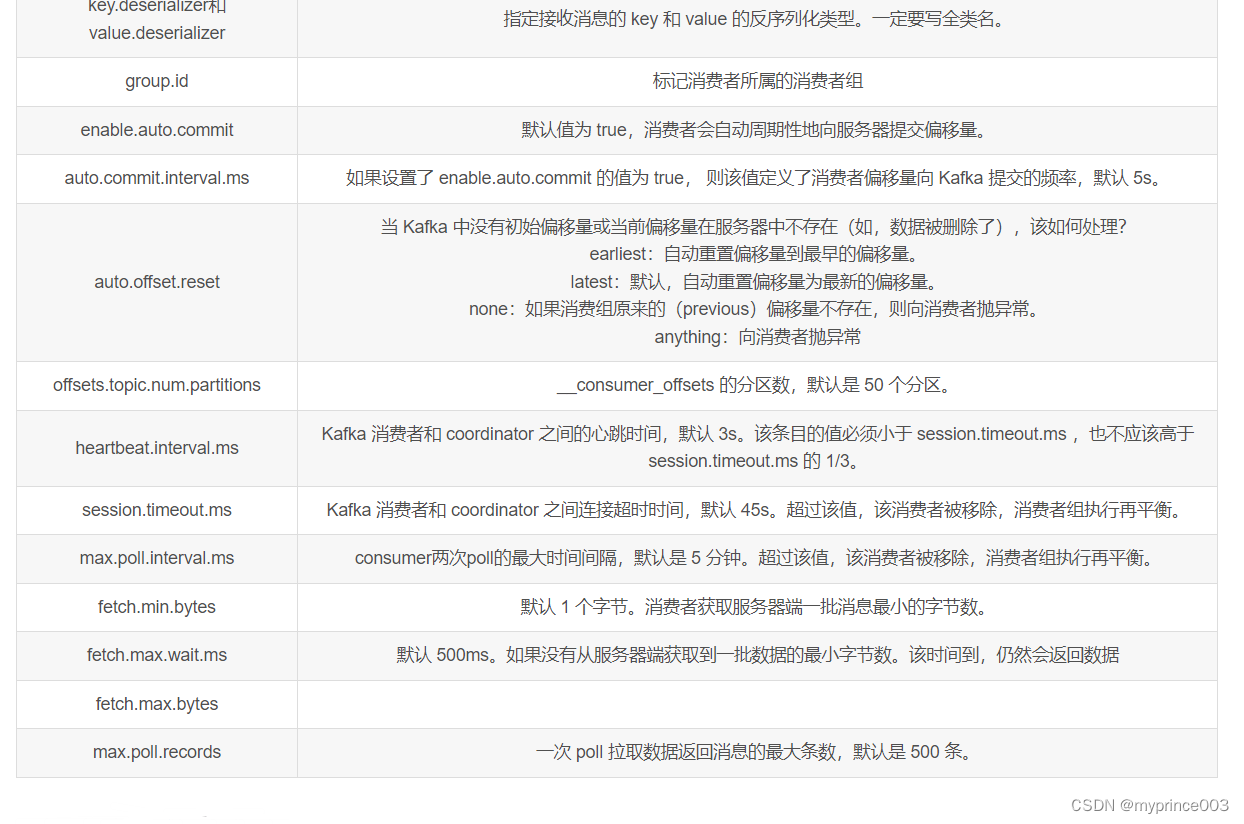
5.2.3 消费者重要参数
5.3 消费者 API
5.3.1 独立消费者案例(订阅主题)
1)需求:
创建一个独立消费者,消费 first 主题中数据。

注意:在消费者 API 代码中必须配置消费者组 id。命令行启动消费者不填写消费者组
id 会被自动填写随机的消费者组 id。
2)实现步骤
(1)创建包名:com.atguigu.kafka.consumer
(2)编写代码
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.time.Duration;
import java.util.ArrayList;
import java.util.Properties;
public class CustomConsumer {public static void main(String[] args) {// 1.创建消费者的配置对象Properties properties = new Properties();// 2.给消费者配置对象添加参数properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,
"hadoop102:9092");// 配置序列化 必须
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());// 配置消费者组(组名任意起名) 必须properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test");// 创建消费者对象KafkaConsumer<String, String> kafkaConsumer = new
KafkaConsumer<String, String>(properties);// 注册要消费的主题(可以消费多个主题)ArrayList<String> topics = new ArrayList<>();topics.add("first");kafkaConsumer.subscribe(topics);// 拉取数据打印while (true) {// 设置 1s 中消费一批数据ConsumerRecords<String, String> consumerRecords =
kafkaConsumer.poll(Duration.ofSeconds(1));// 打印消费到的数据for (ConsumerRecord<String, String> consumerRecord :
consumerRecords) {System.out.println(consumerRecord);}}}
}
(2)在 Kafka 集群控制台,创建 Kafka 生产者,并输入数据。
[hadoop102 kafka]$ bin/kafka-console-producer.sh --
bootstrap-server hadoop102:9092 --topic first>hello
(3)在 IDEA 控制台观察接收到的数据。
ConsumerRecord(topic = first, partition = 1, leaderEpoch = 3,
offset = 0, CreateTime = 1629160841112, serialized key size = -1,
serialized value size = 5, headers = RecordHeaders(headers = [],
isReadOnly = false), key = null, value = hello)
5.3.2 独立消费者案例(订阅分区)
1)需求:创建一个独立消费者,消费 first 主题 0 号分区的数据。
2)实现步骤
(1)代码编写。
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.TopicPartition;
import java.time.Duration;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Properties;
public class CustomConsumerPartition {public static void main(String[] args) {Properties properties = new Properties();properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102
:9092");
// 配置序列化 必须
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());// 配置消费者组(必须),名字可以任意起properties.put(ConsumerConfig.GROUP_ID_CONFIG,"test");KafkaConsumer<String, String> kafkaConsumer = new
KafkaConsumer<>(properties);// 消费某个主题的某个分区数据ArrayList<TopicPartition> topicPartitions = new
ArrayList<>();topicPartitions.add(new TopicPartition("first", 0));kafkaConsumer.assign(topicPartitions);while (true){ConsumerRecords<String, String> consumerRecords =
kafkaConsumer.poll(Duration.ofSeconds(1));for (ConsumerRecord<String, String> consumerRecord :
consumerRecords) {System.out.println(consumerRecord);}}}
}
3)测试
(1)在 IDEA 中执行消费者程序。
(2)在 IDEA 中执行生产者程序 CustomProducerCallback()在控制台观察生成几个 0 号
分区的数据。
first 0 381
first 0 382
first 2 168
first 1 165
first 1 166
(3)在 IDEA 控制台,观察接收到的数据,只能消费到 0 号分区数据表示正确。
ConsumerRecord(topic = first, partition = 0, leaderEpoch = 14,
offset = 381, CreateTime = 1636791331386, serialized key size = -
1, serialized value size = 9, headers = RecordHeaders(headers =
[], isReadOnly = false), key = null, value = atguigu 0)
ConsumerRecord(topic = first, partition = 0, leaderEpoch = 14,
offset = 382, CreateTime = 1636791331397, serialized key size = -
1, serialized value size = 9, headers = RecordHeaders(headers =
[], isReadOnly = false), key = null, value = atguigu 1)
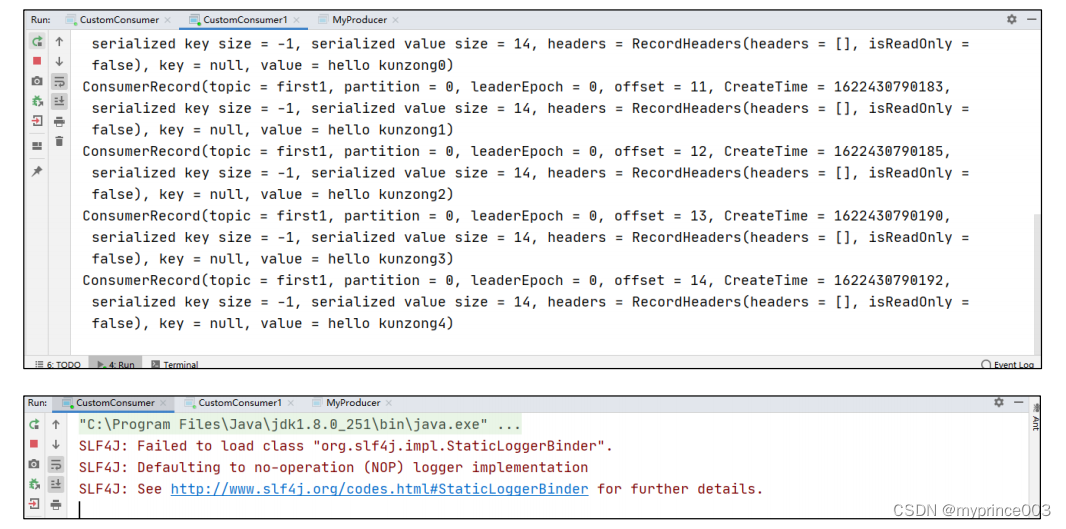
5.3.3 消费者组案例
1)需求:测试同一个主题的分区数据,只能由一个消费者组中的一个消费。
2)案例实操
(1)复制一份基础消费者的代码,在 IDEA 中同时启动,即可启动同一个消费者组中
的两个消费者。
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.time.Duration;
import java.util.ArrayList;
import java.util.Properties;
public class CustomConsumer1 {public static void main(String[] args) {// 1.创建消费者的配置对象Properties properties = new Properties();// 2.给消费者配置对象添加参数properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092");// 配置序列化 必须properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());// 配置消费者组 必须properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test");// 创建消费者对象KafkaConsumer<String, String> kafkaConsumer = newKafkaConsumer<String, String>(properties);// 注册主题ArrayList<String> topics = new ArrayList<>();topics.add("first");kafkaConsumer.subscribe(topics);// 拉取数据打印while (true) {// 设置 1s 中消费一批数据ConsumerRecords<String, String> consumerRecords =kafkaConsumer.poll(Duration.ofSeconds(1));// 打印消费到的数据for (ConsumerRecord<String, String> consumerRecord :consumerRecords) {System.out.println(consumerRecord);}}}
}
(2)启动代码中的生产者发送消息,在 IDEA 控制台即可看到两个消费者在消费不同
分区的数据(如果只发生到一个分区,可以在发送时增加延迟代码 Thread.sleep(2);)。
ConsumerRecord(topic = first, partition = 0, leaderEpoch = 2,
offset = 3, CreateTime = 1629169606820, serialized key size = -1,
serialized value size = 8, headers = RecordHeaders(headers = [],
isReadOnly = false), key = null, value = hello1)
ConsumerRecord(topic = first, partition = 1, leaderEpoch = 3,
offset = 2, CreateTime = 1629169609524, serialized key size = -1,
serialized value size = 6, headers = RecordHeaders(headers = [],
isReadOnly = false), key = null, value = hello2)
ConsumerRecord(topic = first, partition = 2, leaderEpoch = 3,
offset = 21, CreateTime = 1629169611884, serialized key size = -1,
serialized value size = 6, headers = RecordHeaders(headers = [],
isReadOnly = false), key = null, value = hello3)
(3)重新发送到一个全新的主题中,由于默认创建的主题分区数为 1,可以看到只能
有一个消费者消费到数据。
5.4 生产经验——分区的分配以及再平衡


5.4.1 Range 以及再平衡
1)Range 分区策略原理
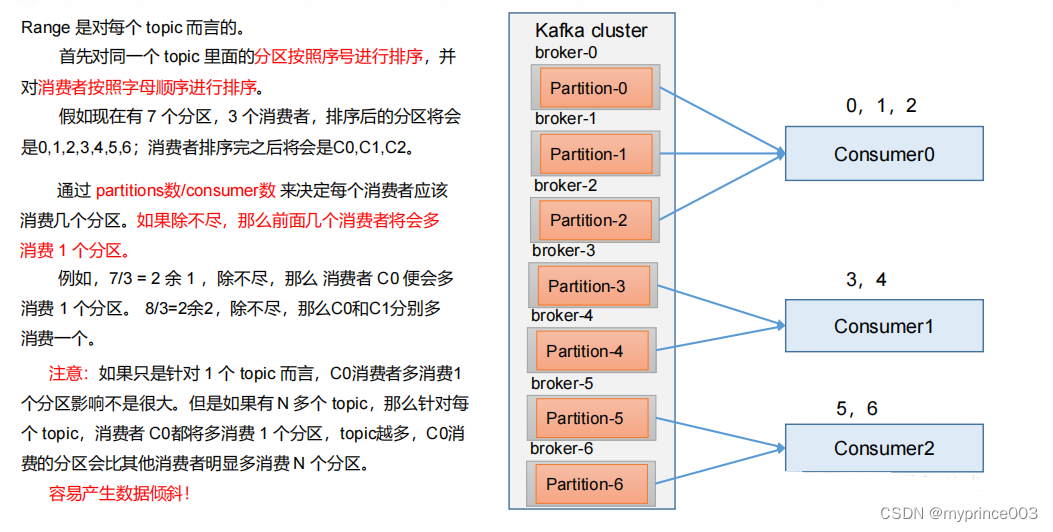
2)Range 分区分配策略案例
(1)修改主题 first 为 7 个分区。
[hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server
hadoop102:9092 --alter --topic first --partitions 7
注意:分区数可以增加,但是不能减少。
(2)复制 CustomConsumer 类,创建 CustomConsumer2。这样可以由三个消费者
CustomConsumer、CustomConsumer1、CustomConsumer2 组成消费者组,组名都为“test”,
同时启动 3 个消费者。

(3)启动 CustomProducer 生产者,发送 500 条消息,随机发送到不同的分区。
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
public class CustomProducer {public static void main(String[] args) throwsInterruptedException {Properties properties = new Properties();properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092");properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());KafkaProducer<String, String> kafkaProducer = newKafkaProducer<>(properties);for (int i = 0; i < 7; i++) {kafkaProducer.send(new ProducerRecord<>("first", i,"test", "prince"));}kafkaProducer.close();}
}
说明:Kafka 默认的分区分配策略就是 Range + CooperativeSticky,所以不需要修改策
略。
(4)观看 3 个消费者分别消费哪些分区的数据。
3)Range 分区分配再平衡案例
(1)停止掉 0 号消费者,快速重新发送消息观看结果(45s 以内,越快越好)。
1 号消费者:消费到 3、4 号分区数据。
2 号消费者:消费到 5、6 号分区数据。
0 号消费者的任务会整体被分配到 1 号消费者或者 2 号消费者。
说明:0 号消费者挂掉后,消费者组需要按照超时时间 45s 来判断它是否退出,所以需
要等待,时间到了 45s 后,判断它真的退出就会把任务分配给其他 broker 执行。
(2)再次重新发送消息观看结果(45s 以后)。
1 号消费者:消费到 0、1、2、3 号分区数据。
2 号消费者:消费到 4、5、6 号分区数据。
说明:消费者 0 已经被踢出消费者组,所以重新按照 range 方式分配。
5.4.2 RoundRobin 以及再平衡
1)RoundRobin 分区策略原理
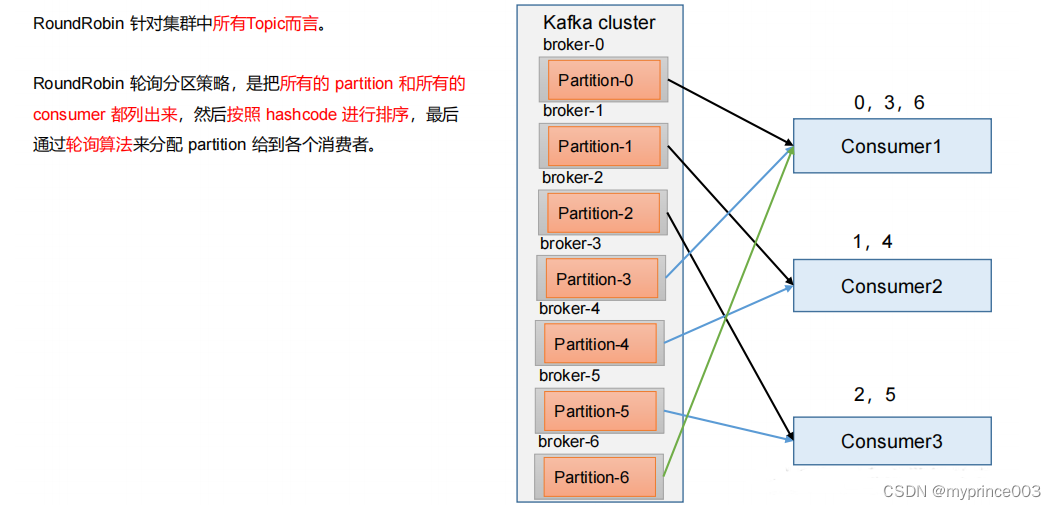
2)RoundRobin 分区分配策略案例
(1)依次在 CustomConsumer、CustomConsumer1、CustomConsumer2 三个消费者代
码中修改分区分配策略为 RoundRobin
// 修改分区分配策略
properties.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFI
G, "org.apache.kafka.clients.consumer.RoundRobinAssignor");
(2)重启 3 个消费者,重复发送消息的步骤,观看分区结果。
3)RoundRobin 分区分配再平衡案例
(1)停止掉 0 号消费者,快速重新发送消息观看结果(45s 以内,越快越好)。
1 号消费者:消费到 2、5 号分区数据
2 号消费者:消费到 4、1 号分区数据
0 号消费者的任务会按照 RoundRobin 的方式,把数据轮询分成 0 、6 和 3 号分区数据,
分别由 1 号消费者或者 2 号消费者消费。
说明:0 号消费者挂掉后,消费者组需要按照超时时间 45s 来判断它是否退出,所以需
要等待,时间到了 45s 后,判断它真的退出就会把任务分配给其他 broker 执行。
(2)再次重新发送消息观看结果(45s 以后)。
1 号消费者:消费到 0、2、4、6 号分区数据
2 号消费者:消费到 1、3、5 号分区数据
说明:消费者 0 已经被踢出消费者组,所以重新按照 RoundRobin 方式分配。
5.4.3 Sticky 以及再平衡
粘性分区定义:可以理解为分配的结果带有“粘性的”。即在执行一次新的分配之前,
考虑上一次分配的结果,尽量少的调整分配的变动,可以节省大量的开销。
粘性分区是 Kafka 从 0.11.x 版本开始引入这种分配策略,首先会尽量均衡的放置分区
到消费者上面,在出现同一消费者组内消费者出现问题的时候,会尽量保持原有分配的分
区不变化。
1)需求
设置主题为 first,7 个分区;准备 3 个消费者,采用粘性分区策略,并进行消费,观察
消费分配情况。然后再停止其中一个消费者,再次观察消费分配情况。
2)步骤
(1)修改分区分配策略为粘性。
注意:3 个消费者都应该注释掉,之后重启 3 个消费者,如果出现报错,全部停止等
会再重启,或者修改为全新的消费者组
// 修改分区分配策略
ArrayList<String> startegys = new ArrayList<>();
startegys.add("org.apache.kafka.clients.consumer.StickyAssignor");
properties.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG,
startegys);
(2)使用同样的生产者发送 500 条消息。
可以看到会尽量保持分区的个数近似划分分区。
3)Sticky 分区分配再平衡案例
(1)停止掉 0 号消费者,快速重新发送消息观看结果(45s 以内,越快越好)。
1 号消费者:消费到 2、5、3 号分区数据。
2 号消费者:消费到 4、6 号分区数据。
0 号消费者的任务会按照粘性规则,尽可能均衡的随机分成 0 和 1 号分区数据,分别
由 1 号消费者或者 2 号消费者消费。
说明:0 号消费者挂掉后,消费者组需要按照超时时间 45s 来判断它是否退出,所以需
要等待,时间到了 45s 后,判断它真的退出就会把任务分配给其他 broker 执行。
(2)再次重新发送消息观看结果(45s 以后)。
1 号消费者:消费到 2、3、5 号分区数据。
2 号消费者:消费到 0、1、4、6 号分区数据。
说明:消费者 0 已经被踢出消费者组,所以重新按照粘性方式分配。
5.5 offset 位移
5.5.1 offset 的默认维护位置
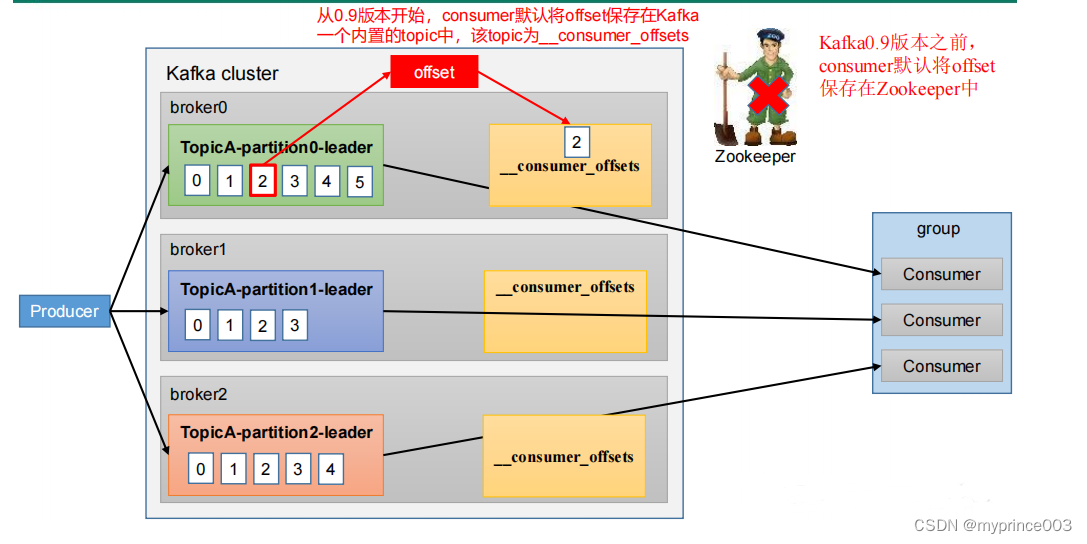
__consumer_offsets 主题里面采用 key 和 value 的方式存储数据。key 是 group.id+topic+
分区号,value 就是当前 offset 的值。每隔一段时间,kafka 内部会对这个 topic 进行
compact,也就是每个 group.id+topic+分区号就保留最新数据。
1)消费 offset 案例
(0)思想:__consumer_offsets 为 Kafka 中的 topic,那就可以通过消费者进行消费。
(1)在配置文件 config/consumer.properties 中添加配置 exclude.internal.topics=false,
默认是 true,表示不能消费系统主题。为了查看该系统主题数据,所以该参数修改为 false。
(2)采用命令行方式,创建一个新的 topic。
[hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server
hadoop102:9092 --create --topic atguigu --partitions 2 --
replication-factor 2
(3)启动生产者往 atguigu 生产数据。
[hadoop102 kafka]$ bin/kafka-console-producer.sh --topic
atguigu --bootstrap-server hadoop102:9092
(4)启动消费者消费 atguigu 数据。
[hadoop104 kafka]$ bin/kafka-console-consumer.sh --
bootstrap-server hadoop102:9092 --topic atguigu --group test
注意:指定消费者组名称,更好观察数据存储位置(key 是 group.id+topic+分区号)。
(5)查看消费者消费主题__consumer_offsets。
[hadoop102 kafka]$ bin/kafka-console-consumer.sh --topic
__consumer_offsets --bootstrap-server hadoop102:9092 --
consumer.config config/consumer.properties --formatter
"kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageForm
atter" --from-beginning
[offset,atguigu,1]::OffsetAndMetadata(offset=7,
leaderEpoch=Optional[0], metadata=, commitTimestamp=1622442520203,
expireTimestamp=None)
[offset,atguigu,0]::OffsetAndMetadata(offset=8,
leaderEpoch=Optional[0], metadata=, commitTimestamp=1622442520203,
expireTimestamp=None)
5.5.2 自动提交 offset
为了使我们能够专注于自己的业务逻辑,Kafka提供了自动提交offset的功能。
5s
自动提交offset的相关参数:
⚫ enable.auto.commit:是否开启自动提交offset功能,默认是true
⚫ auto.commit.interval.ms:自动提交offset的时间间隔,默认是5s


1)消费者自动提交 offset
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.util.Arrays;
import java.util.Properties;
public class CustomConsumerAutoOffset {public static void main(String[] args) {// 1. 创建 kafka 消费者配置类Properties properties = new Properties();// 2. 添加配置参数// 添加连接properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092");// 配置序列化 必须properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer");properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer");// 配置消费者组properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test");// 是否自动提交 offsetproperties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,true);// 提交 offset 的时间周期 1000ms,默认 5sproperties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG,1000);//3. 创建 kafka 消费者KafkaConsumer<String, String> consumer = newKafkaConsumer<>(properties);//4. 设置消费主题 形参是列表consumer.subscribe(Arrays.asList("first"));//5. 消费数据while (true){// 读取消息ConsumerRecords<String, String> consumerRecords =consumer.poll(Duration.ofSeconds(1));// 输出消息for (ConsumerRecord<String, String> consumerRecord :consumerRecords) {System.out.println(consumerRecord.value());}}}
}
5.5.3 手动提交 offset
此Kafka还提供了手动提交offset的API。
手动提交offset的方法有两种:分别是commitSync(同步提交)和commitAsync(异步提交)。两者的相
同点是,都会将本次提交的一批数据最高的偏移量提交;不同点是,同步提交阻塞当前线程,一直到提交成
功,并且会自动失败重试(由不可控因素导致,也会出现提交失败);而异步提交则没有失败重试机制,故
有可能提交失败。
• commitSync(同步提交):必须等待offset提交完毕,再去消费下一批数据。
• commitAsync(异步提交) :发送完提交offset请求后,就开始消费下一批数据了。
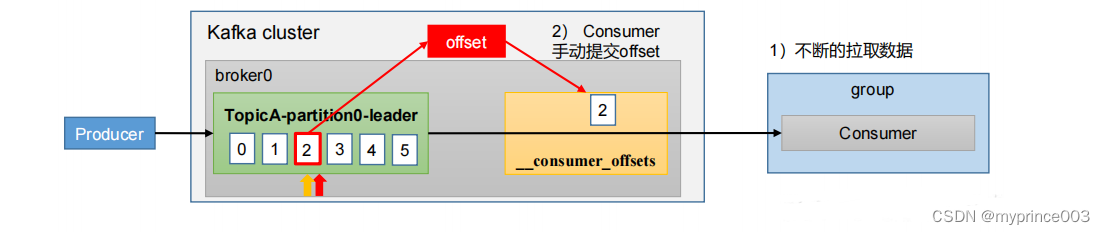
1)同步提交 offset
由于同步提交 offset 有失败重试机制,故更加可靠,但是由于一直等待提交结果,提
交的效率比较低。以下为同步提交 offset 的示例。
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.util.Arrays;
import java.util.Properties;
public class CustomConsumerByHandSync {public static void main(String[] args) {// 1. 创建 kafka 消费者配置类Properties properties = new Properties();// 2. 添加配置参数// 添加连接properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092");// 配置序列化 必须properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer");properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer");// 配置消费者组properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test");// 是否自动提交 offsetproperties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,false);//3. 创建 kafka 消费者KafkaConsumer<String, String> consumer = newKafkaConsumer<>(properties);//4. 设置消费主题 形参是列表consumer.subscribe(Arrays.asList("first"));//5. 消费数据while (true){// 读取消息ConsumerRecords<String, String> consumerRecords =consumer.poll(Duration.ofSeconds(1));// 输出消息for (ConsumerRecord<String, String> consumerRecord :consumerRecords) {System.out.println(consumerRecord.value());}// 同步提交 offsetconsumer.commitSync();}}
}
2)异步提交 offset
虽然同步提交 offset 更可靠一些,但是由于其会阻塞当前线程,直到提交成功。因此
吞吐量会受到很大的影响。因此更多的情况下,会选用异步提交 offset 的方式。
以下为异步提交 offset 的示例:
import org.apache.kafka.common.TopicPartition;
import java.util.Arrays;
import java.util.Map;
import java.util.Properties;
public class CustomConsumerByHandAsync {public static void main(String[] args) {// 1. 创建 kafka 消费者配置类Properties properties = new Properties();// 2. 添加配置参数// 添加连接properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092");// 配置序列化 必须properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer");properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer");// 配置消费者组properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test");// 是否自动提交 offsetproperties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,"false");//3. 创建 Kafka 消费者KafkaConsumer<String, String> consumer = newKafkaConsumer<>(properties);//4. 设置消费主题 形参是列表consumer.subscribe(Arrays.asList("first"));//5. 消费数据while (true){// 读取消息ConsumerRecords<String, String> consumerRecords =consumer.poll(Duration.ofSeconds(1));// 输出消息for (ConsumerRecord<String, String> consumerRecord :consumerRecords) {System.out.println(consumerRecord.value());}// 异步提交 offsetconsumer.commitAsync();}}
}
5.5.4 指定 Offset 消费
auto.offset.reset = earliest | latest | none 默认是 latest。
当 Kafka 中没有初始偏移量(消费者组第一次消费)或服务器上不再存在当前偏移量
时(例如该数据已被删除),该怎么办?
(1)earliest:自动将偏移量重置为最早的偏移量,–from-beginning。
(2)latest(默认值):自动将偏移量重置为最新偏移量。
(3)none:如果未找到消费者组的先前偏移量,则向消费者抛出异常。

(4)任意指定 offset 位移开始消费
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.ArrayList;
import java.util.HashSet;
import java.util.Properties;
import java.util.Set;
public class CustomConsumerSeek {public static void main(String[] args) {// 0 配置信息Properties properties = new Properties();// 连接properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092");// key value 反序列化properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test2");// 1 创建一个消费者KafkaConsumer<String, String> kafkaConsumer = newKafkaConsumer<>(properties);// 2 订阅一个主题ArrayList<String> topics = new ArrayList<>();topics.add("first");kafkaConsumer.subscribe(topics);Set<TopicPartition> assignment= new HashSet<>();while (assignment.size() == 0) {kafkaConsumer.poll(Duration.ofSeconds(1));// 获取消费者分区分配信息(有了分区分配信息才能开始消费)assignment = kafkaConsumer.assignment();}// 遍历所有分区,并指定 offset 从 1700 的位置开始消费for (TopicPartition tp: assignment) {kafkaConsumer.seek(tp, 1700);}// 3 消费该主题数据while (true) {ConsumerRecords<String, String> consumerRecords =kafkaConsumer.poll(Duration.ofSeconds(1));for (ConsumerRecord<String, String> consumerRecord :consumerRecords) {System.out.println(consumerRecord);}}}
}
注意:每次执行完,需要修改消费者组名;
5.5.5 指定时间消费
需求:在生产环境中,会遇到最近消费的几个小时数据异常,想重新按照时间消费。
例如要求按照时间消费前一天的数据,怎么处理?
操作步骤:
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.*;
public class CustomConsumerForTime {public static void main(String[] args) {// 0 配置信息Properties properties = new Properties();// 连接properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092");// key value 反序列化properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test2");// 1 创建一个消费者KafkaConsumer<String, String> kafkaConsumer = newKafkaConsumer<>(properties);// 2 订阅一个主题ArrayList<String> topics = new ArrayList<>();topics.add("first");kafkaConsumer.subscribe(topics);Set<TopicPartition> assignment = new HashSet<>();while (assignment.size() == 0) {kafkaConsumer.poll(Duration.ofSeconds(1));// 获取消费者分区分配信息(有了分区分配信息才能开始消费)assignment = kafkaConsumer.assignment();}HashMap<TopicPartition, Long> timestampToSearch = newHashMap<>();// 封装集合存储,每个分区对应一天前的数据for (TopicPartition topicPartition : assignment) {timestampToSearch.put(topicPartition,System.currentTimeMillis() - 1 * 24 * 3600 * 1000);}// 获取从 1 天前开始消费的每个分区的 offsetMap<TopicPartition, OffsetAndTimestamp> offsets =kafkaConsumer.offsetsForTimes(timestampToSearch);// 遍历每个分区,对每个分区设置消费时间。for (TopicPartition topicPartition : assignment) {OffsetAndTimestamp offsetAndTimestamp =offsets.get(topicPartition);// 根据时间指定开始消费的位置if (offsetAndTimestamp != null){kafkaConsumer.seek(topicPartition,offsetAndTimestamp.offset());}}// 3 消费该主题数据while (true) {ConsumerRecords<String, String> consumerRecords =kafkaConsumer.poll(Duration.ofSeconds(1));for (ConsumerRecord<String, String> consumerRecord :consumerRecords) {System.out.println(consumerRecord);}}}
}
5.5.6 漏消费和重复消费
重复消费:已经消费了数据,但是 offset 没提交。
漏消费:先提交 offset 后消费,有可能会造成数据的漏消费。

思考:怎么能做到既不漏消费也不重复消费呢?详看消费者事务。
5.6 生产经验——消费者事务
如果想完成Consumer端的精准一次性消费,那么需要Kafka消费端将消费过程和提交offset
过程做原子绑定。此时我们需要将Kafka的offset保存到支持事务的自定义介质(比 如
MySQL)。这部分知识会在后续项目部分涉及。
5.7 生产经验——数据积压(消费者如何提高吞吐量)


相关文章:
4、Kafka 消费者
5.1 Kafka 消费方式 5.2 Kafka 消费者工作流程 5.2.1 消费者总体工作流程 5.2.2 消费者组原理 Consumer Group(CG):消费者组,由多个consumer组成。形成一个消费者组的条件,是所有消费者的groupid相同。 • 消费者组内…...
CSS3 渐变
CSS3 渐变可以让你在两个或多个指定的颜色之间显示平稳的过渡。 CSS3渐变有两种类型:线性渐变(Linear Gradients)和径向渐变(Radial Gradients)。 线性渐变(Linear Gradients): 线性…...

【Python 千题 —— 基础篇】分割有效信息
题目描述 题目描述 有时候我们需要截取字符串以获取有用的信息,比如对于字符串 “日期:2010-10-29”,我们需要截取后面的 10 个字符来获取日期,以便进行进一步分析。编写一个程序,输入一个字符串,然后输出…...

webrtc基于DTLS的端口复用技术
DTLS协议: DTLS(Datagram Transport Layer Security)数据包安全传输协议,用于在不可靠的数据包传输协议上(如UDP)提供数据的安全传输。 UDP多路复用: 一个UDP多路复用,被用来处理共享同一个UDP端口的多个并发的UDT连接。类似同一个tcp port上创建多个socket connec…...

【2024秋招】2023-9-20 度小满信贷系统平台部二面
1 面试官的部门介绍 我们部门是信贷系统平台部,主要是为度小满做一个服务,你应该也接触过信用卡,跟这种差不多,用户可以打进我们的系统申请一个额度,整个部门的规模大概是400-500人左右,我个人来自平台数据…...
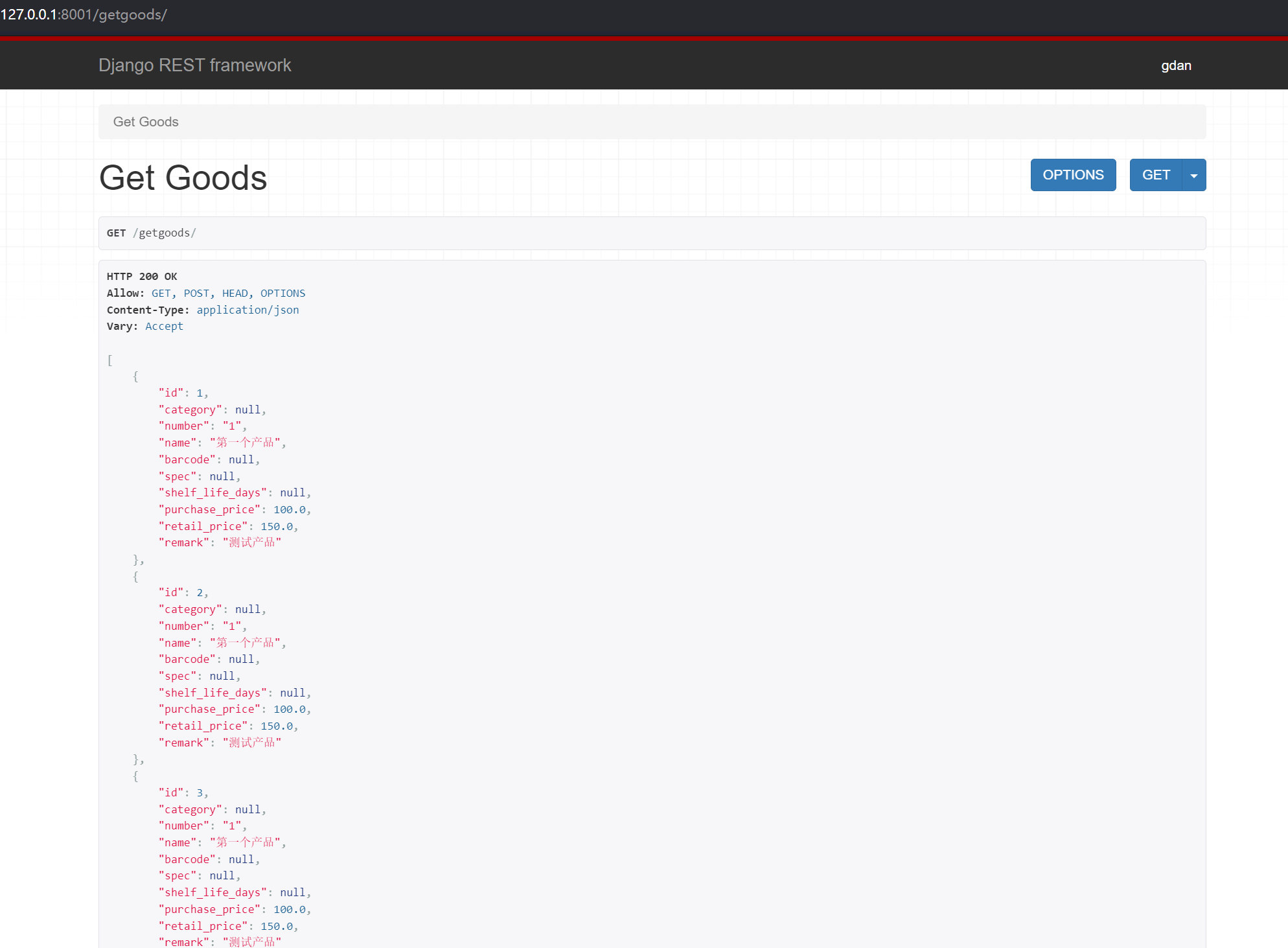
【Django 04】Serialization 序列化的高级使用
序列化器 serializers 序列化器的作用 序列化将 queryset 和 instance 转换为 json/xml/yaml 返回给前端 反序列化与序列化则相反 定义序列化器 定义类,继承自 Serializer 通常新建一个 serializers.py 文件 撰写序列化内容 suah as 目前只支持 read_only 只…...
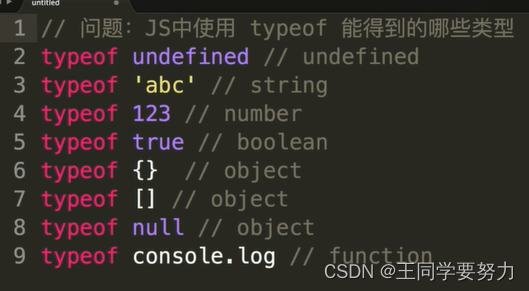
【前端学习】—变量类型和计算(五)
【前端学习】—变量类型和计算(五) 一、JS中使用typeof能得到哪些类型 字符串(String):表示文本数据,用单引号或双引号括起来。 数字(Number):表示数值数据,包括整数和浮点数。 布尔值(Boolean):表示真或假(true或false)的逻辑值。 空值(Null):表示一个空…...
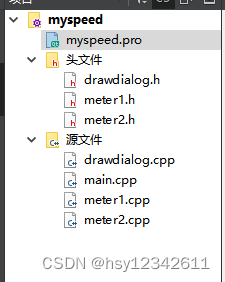
QT中窗口自绘制效果展示
项目中需要使用QT进行窗口自绘,前期先做一下技术探索,参考相关资料代码熟悉流程。本着代码是最好的老师原则,在此记录一下。 目录 1.运行效果 2.代码结构 3.具体代码 1.运行效果 2.代码结构 3.具体代码 myspeed.pro QT core gui…...

Android Studio 直接获取Spinner的值
最近做一个小demo 使用Spinner下拉框来让用户选择地区、周数(第1-12周) 然后参考了一下别人的文章 这里引用这位博主博文: AndroidStudio使用spinner控件并添加监听(极简)_安卓spinner监听事件_天王老子来了我也不…...

渗透测试工具(3)Burpsuite
笔记目录 渗透测试工具(1)wireshark渗透测试工具(2)Nmap渗透测试工具(3)Burpsuite 1.简介 是Web应用程序测试,请求的拦截和修改,扫描web应用程序漏洞,以暴力破解登陆表单,执行会话令牌等多种的随机性检查。 (1)模块介绍 ①Intercept:用于显示和修改Ht…...

大数据之LibrA数据库系统上下电管理
系统上电 操作场景 系统管理员进行例行维护停机后需要重新启动服务器与FusionInsight LibrA集群。如果安装双机Manager,上电后HA将确定主备管理节点。系统启动完成后需要启动依赖集群运行的上层业务。 对系统的影响 系统上电完成以前集群不可用。 前提条件 获…...

Node.js、Vue的安装与使用(Linux OS)
Vue的安装与使用(Linux OS) Node.js的安装Vue的安装Vue的使用 操作系统:Ubuntu 20.04 LTS Node.js的安装 安装Node.js Node.js官方下载地址 1.选择合适的系统架构(可通过uname -m查看)版本安装 2.下载文件为tar.xz格…...

SparkSQL入门
概述 两种模式 Spark on Hive: 语法是Spark SQL语法,实际上是在IDEA上编写java叠加SQL的代码。 Hive on Spark: 只是替换了Hadoop的MR,改为了Spark的计算引擎。 发展历史 RDD > DataFrame > DataSet: 都有惰性机制,遇…...

AC修炼计划(AtCoder Regular Contest 167)
传送门:AtCoder Regular Contest 167 - AtCoder 再次感谢樱雪喵大佬的题解,讲的很详细,Orz。 大佬的博客链接如下:Atcoder Regular Contest 167 - 樱雪喵 - 博客园 (cnblogs.com) 第一题很签到,就省略掉了。 第二题…...

暄桐四阶课程「自在行草」学习装备指南
在2011年,暄桐成立的最初,课程便是面向零基础的成年人设计的。在十余年的教学实践中,暄桐教室为同学们提供了一种系统、有趣、扎实,并可持续进阶的学习可能。许多同学都是在来到暄桐以后,才第一次拿起毛笔,…...
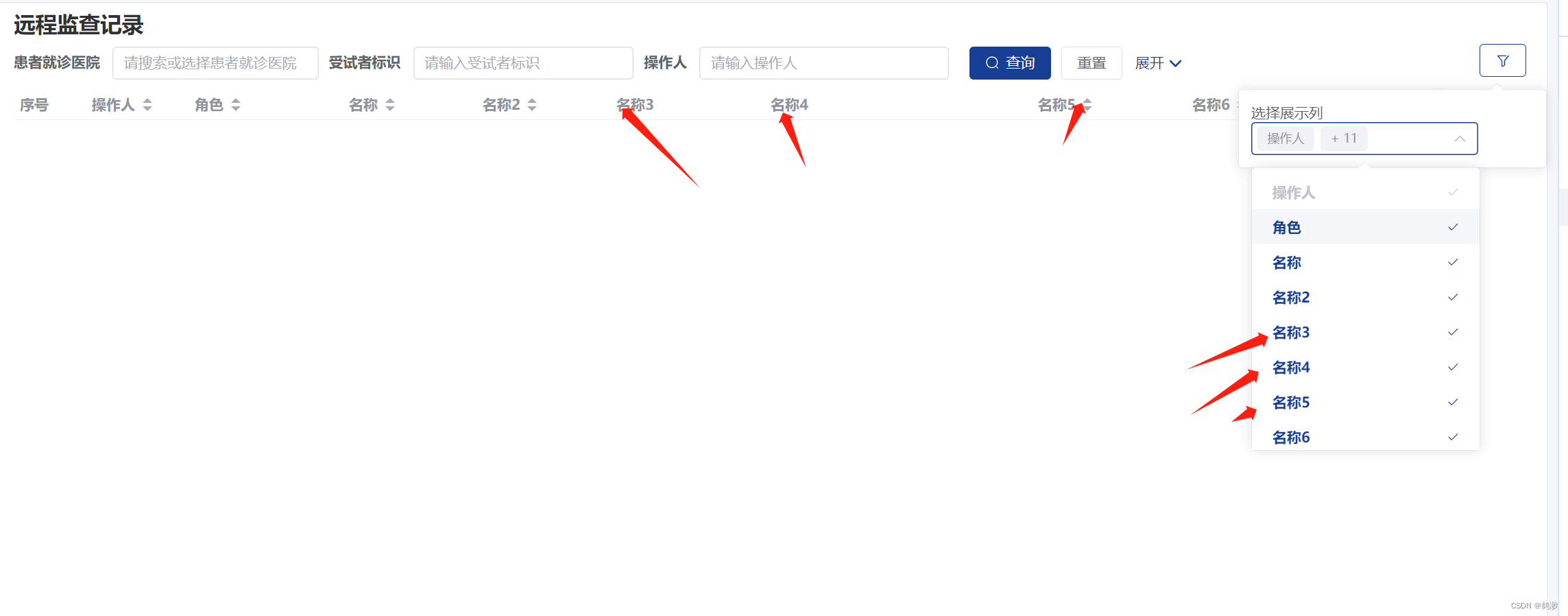
vue3 列表页开发【选择展示列】功能
目录 背景描述: 开发流程: 详细开发流程: 总结: 背景描述: 这个功能是基于之前写的 封装列表页 的功能继续写的,加了一个选择展示列的功能,可以随时控制表格里展示那些列的数据…...
uniapp——自定义组件插槽及使用
案例样式 自定义组件pageBox.vue <template><view><view class"bgColor" :style"{ height: bgHeight rpx }"></view><view class"main"><!-- 主要内容放这里 --><slot></slot></view>&…...
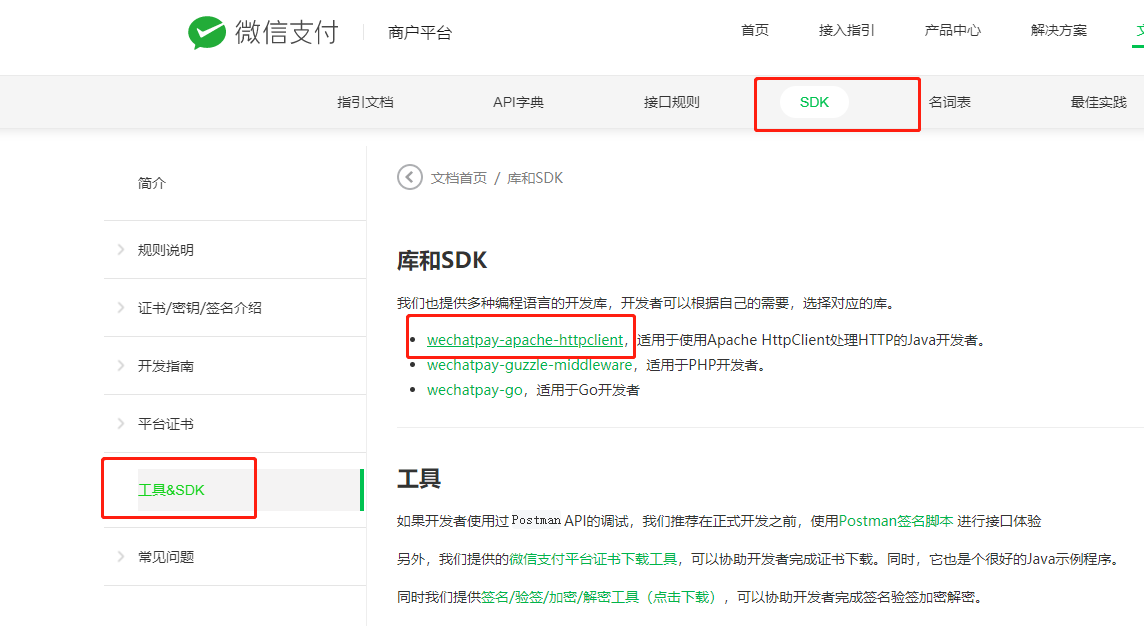
微信native-v3版支付对接流程及demo
1.将p12证书转为pem证书,得到商户私钥 openssl pkcs12 -in apiclient_cert.p12 -out apiclient_cert.pem -nodes 密码是:商户id 2.将获取到的apiclient_cert.pem证书,复制出这一块内容,其他的不要 3.下载这个工具包 https://gi…...

租用服务器后需要注意什么
租用服务器后需要注意什么 1、从IDC服务商中接收到服务器时,需要对服务器的各项性能进行测试确认,并做好记录以便对服务器的性能做到心中有数。 2、在服务器租用交接时,要了解服务器的安全设置情况,对服务器安全技术方面不了解的…...
【公众号开发】图像文字识别 · 模板消息推送 · 素材管理 · 带参数二维码的生成与事件的处理
【公众号开发】(4) 文章目录 【公众号开发】(4)1. 图像文字识别功能1.1 百度AI图像文字识别接口申请1.2 查看文档学习如何调用百度AI1.3 程序开发1.3.1 导入依赖:1.3.2 公众号发来post请求格式1.3.3 对image类型的消息…...

在 HarmonyOS6 中实现 Material Design 3 导航栏
文章目录一、什么是 Material Design 3?二、Elevation 层级系统2.1 层级概念2.2 项目中的枚举定义2.3 Elevation 转换为 shadow 参数三、色彩系统3.1 色彩角色定义3.2 浅色与深色两套配色3.3 应用到标签栏四、主题切换4.1 切换逻辑4.2 Elevation 动态调节五、完整标…...

Dify文档解析配置实战手册:从PDF乱码到结构化知识库,97%用户忽略的4个关键参数设置
第一章:Dify文档解析配置的核心价值与典型痛点Dify 的文档解析配置是构建高质量 RAG(检索增强生成)应用的基石。它决定了原始 PDF、Word、Markdown 等非结构化文档如何被切分、清洗、元数据注入及向量化,直接影响后续检索的准确性…...

富士胶片ApeosPort 3410SD网络扫描配置踩坑实录:从共享文件夹到SMB协议,保姆级避坑指南
富士胶片ApeosPort 3410SD网络扫描配置实战:共享文件夹与SMB协议深度解析 办公室里那台新到的富士胶片ApeosPort 3410SD激光一体机静静地闪着蓝灯,看起来人畜无害——直到你尝试配置它的网络扫描功能。作为一款面向中小企业和SOHO用户的高性价比设备&…...

C#对接Bartender打印踩坑实录:从COM引用到多线程打印的避坑指南
C#对接Bartender打印踩坑实录:从COM引用到多线程打印的避坑指南 在工业级标签打印场景中,Bartender作为行业标杆软件,其稳定性与功能完备性毋庸置疑。但当开发者尝试通过C#调用Bartender的COM接口时,往往会遭遇各种"水土不服…...
)
保姆级教程:用PyQtGraph和Python打造你的专属股票分析桌面应用(附完整源码)
从零构建专业级股票分析桌面应用:PyQtGraph实战指南 在金融科技快速发展的今天,拥有一个定制化的本地股票分析工具已成为许多开发者和量化交易爱好者的刚需。与在线平台相比,本地应用不仅能保护数据隐私,还能根据个人交易策略灵活…...

Windows Terminal + WSL2 真香搭配:从安装到高效配置的完整指南
Windows Terminal WSL2 终极配置指南:打造开发者专属命令行工作流 在Windows生态中,WSL2的出现彻底改变了开发者的工作方式。它不再是简单的Linux模拟环境,而是通过完整的Linux内核支持,提供了近乎原生的性能体验。但要让这套系统…...

从模组混乱到游戏秩序:Scarab如何重塑《空洞骑士》的模组体验
从模组混乱到游戏秩序:Scarab如何重塑《空洞骑士》的模组体验 【免费下载链接】Scarab An installer for Hollow Knight mods written in Avalonia. 项目地址: https://gitcode.com/gh_mirrors/sc/Scarab 还记得第一次为《空洞骑士》安装模组时的迷茫吗&…...

N_m3u8DL-RE实战指南:从零掌握跨平台流媒体高效下载技术
N_m3u8DL-RE实战指南:从零掌握跨平台流媒体高效下载技术 【免费下载链接】N_m3u8DL-RE Cross-Platform, modern and powerful stream downloader for MPD/M3U8/ISM. English/简体中文/繁體中文. 项目地址: https://gitcode.com/GitHub_Trending/nm3/N_m3u8DL-RE …...

手把手教你用STM32CubeMX配置SPI2,5分钟搞定RC522门禁卡读写
STM32CubeMX实战:5分钟完成RC522门禁卡系统开发 在物联网和智能硬件快速发展的今天,门禁系统作为安防领域的重要组成部分,正经历着从传统向智能化的转变。而RFID技术凭借其非接触式识别的特性,成为门禁系统的核心技术之一。本文将…...
)
Prompt Engineering实战:如何用ChatGPT API构建高效提示词模板(附LangChain代码示例)
Prompt Engineering实战:用ChatGPT API构建高效提示词模板 在AI应用开发领域,Prompt Engineering已经从简单的聊天技巧演变为一门系统的工程学科。随着大模型API的普及,如何将零散的提示词转化为可复用的工程组件,成为开发者提升效…...