SparkSQL入门
概述
两种模式
Spark on Hive: 语法是Spark SQL语法,实际上是在IDEA上编写java叠加SQL的代码。
Hive on Spark: 只是替换了Hadoop的MR,改为了Spark的计算引擎。
发展历史
RDD => DataFrame => DataSet:
- 都有惰性机制,遇到行动算子才会执行。
- 三者都会根据Spark的内存情况自动缓存运算
- 三者都有分区的概念
特点
- 易整合:无缝的整合了SQL查询和Spark编程
- 统一的数据访问方式:使用相同的方式连接不同的数据源
- 兼容Hive:在已有的仓库上直接运行SQL或者HQL
- 标准的数据连接:通过JDBC或者ODBC来连接
数据的加载和保存
json文件:spark数据读取时,读取后会自动解析JSON,并且附加上列名和属性类型。并且兼容RDD的算子操作,
public class SQL_Test {public static void main(String[] args) {SparkConf sparkConf = new SparkConf().setAppName("SparkSQL").setMaster("local[*]");SparkSession spark = SparkSession.builder().config(sparkConf).getOrCreate();DataFrameReader read = spark.read();//读取后会自动解析JSON,并且附加上列名和属性类型Dataset<Row> userJSON = read.json("input/user.json");//打印数据类型userJSON.printSchema();userJSON.show();//即收集又打印spark.close();}
}
自定义函数
UDF操作单个数据,产生单个数据
import org.apache.spark.SparkConf;
import org.apache.spark.sql.*;
import org.apache.spark.sql.api.java.UDF2;
import org.apache.spark.sql.types.DataTypes;
/**
-
title:
-
@Author 浪拍岸
-
@Create 19/10/2023 上午8:52
-
@Version 1.0
/
public class SQL_UDF {
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf().setAppName(“SparkSQL”).setMaster("local[]");
SparkSession spark = SparkSession.builder().config(sparkConf).getOrCreate();DataFrameReader read = spark.read();//读取后会自动解析JSON,并且附加上列名和属性类型Dataset<Row> userJSON = read.json("input/user.json");userJSON.createOrReplaceTempView("t1");//注册函数spark.udf().register("myudf", new UDF2<String, Long, String>() {@Overridepublic String call(String s, Long integer) throws Exception {if(integer >= 18){return s+"大侠";}else{return s+"小虾米";}//return null;}}, DataTypes.StringType);//spark.sql("select myudf(name,age) from t1").show();spark.close();}
}
UDAF操作多个数据,产生单个数据
import org.apache.spark.SparkConf;
import org.apache.spark.sql.*;
import org.apache.spark.sql.api.java.UDF2;
import org.apache.spark.sql.types.DataTypes;
import static org.apache.spark.sql.functions.udaf;public class SQL_UDAF {public static void main(String[] args) {SparkConf sparkConf = new SparkConf().setAppName("SparkSQL").setMaster("local[*]");SparkSession spark = SparkSession.builder().config(sparkConf).getOrCreate();DataFrameReader read = spark.read();//读取后会自动解析JSON,并且附加上列名和属性类型Dataset<Row> userJSON = read.json("input/user.json");userJSON.createOrReplaceTempView("t1");//注册函数spark.udf().register("ageAVG", udaf(new AgeAvg(), Encoders.LONG()));//spark.sql("select name,ageAVG(age) from t1 group by name").show();spark.close();}
}
文件的读取和转换保存
- json格式
- csv格式
- parquet、orc格式
Hive交互
- 开启Hive支持enableHiveSupport()
- 用户权限造假
System.setProperty("HADOOP_USER_NAME","atguigu"); - 添加hive-site.xml到resource目录下
import org.apache.spark.SparkConf;
import org.apache.spark.sql.SparkSession;/*** title:** @Author 浪拍岸* @Create 19/10/2023 下午3:35* @Version 1.0*/
public class HiveTest {public static void main(String[] args) {System.setProperty("HADOOP_USER_NAME","atguigu");SparkConf sparkConf = new SparkConf().setAppName("SparkSQL").setMaster("local[*]");SparkSession spark = SparkSession.builder().enableHiveSupport().config(sparkConf).getOrCreate();// spark.sql("show tables").show();spark.sql("select * from stu where id = 1").createOrReplaceTempView("t1");spark.sql("select * from t1").show();spark.close();}
}
相关文章:

SparkSQL入门
概述 两种模式 Spark on Hive: 语法是Spark SQL语法,实际上是在IDEA上编写java叠加SQL的代码。 Hive on Spark: 只是替换了Hadoop的MR,改为了Spark的计算引擎。 发展历史 RDD > DataFrame > DataSet: 都有惰性机制,遇…...

AC修炼计划(AtCoder Regular Contest 167)
传送门:AtCoder Regular Contest 167 - AtCoder 再次感谢樱雪喵大佬的题解,讲的很详细,Orz。 大佬的博客链接如下:Atcoder Regular Contest 167 - 樱雪喵 - 博客园 (cnblogs.com) 第一题很签到,就省略掉了。 第二题…...

暄桐四阶课程「自在行草」学习装备指南
在2011年,暄桐成立的最初,课程便是面向零基础的成年人设计的。在十余年的教学实践中,暄桐教室为同学们提供了一种系统、有趣、扎实,并可持续进阶的学习可能。许多同学都是在来到暄桐以后,才第一次拿起毛笔,…...
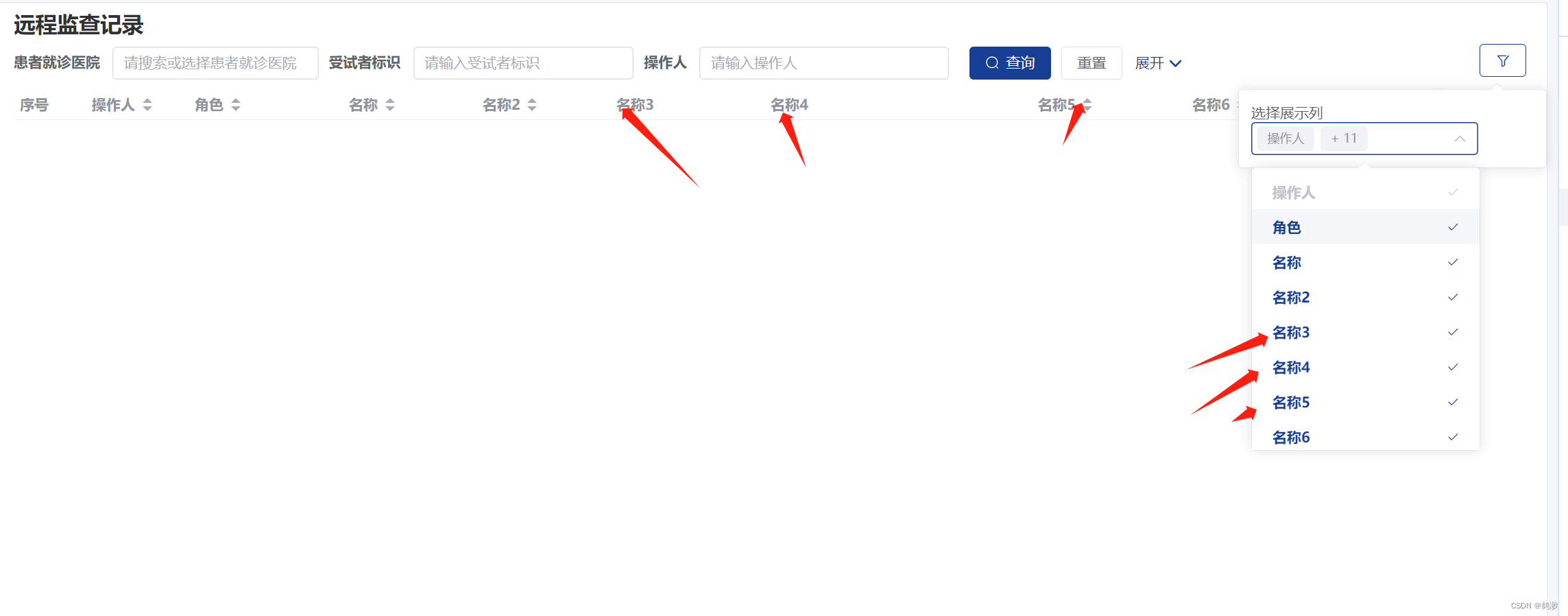
vue3 列表页开发【选择展示列】功能
目录 背景描述: 开发流程: 详细开发流程: 总结: 背景描述: 这个功能是基于之前写的 封装列表页 的功能继续写的,加了一个选择展示列的功能,可以随时控制表格里展示那些列的数据…...
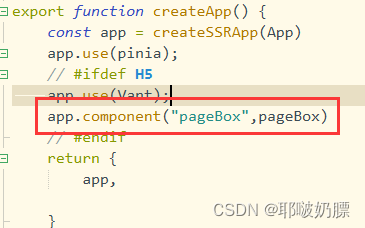
uniapp——自定义组件插槽及使用
案例样式 自定义组件pageBox.vue <template><view><view class"bgColor" :style"{ height: bgHeight rpx }"></view><view class"main"><!-- 主要内容放这里 --><slot></slot></view>&…...
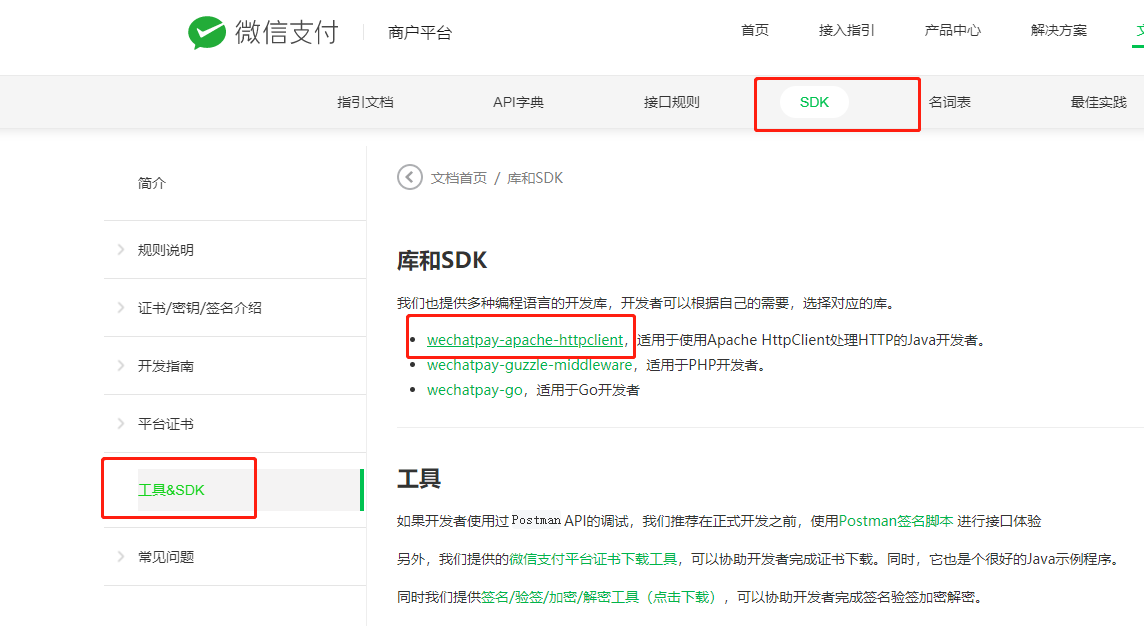
微信native-v3版支付对接流程及demo
1.将p12证书转为pem证书,得到商户私钥 openssl pkcs12 -in apiclient_cert.p12 -out apiclient_cert.pem -nodes 密码是:商户id 2.将获取到的apiclient_cert.pem证书,复制出这一块内容,其他的不要 3.下载这个工具包 https://gi…...

租用服务器后需要注意什么
租用服务器后需要注意什么 1、从IDC服务商中接收到服务器时,需要对服务器的各项性能进行测试确认,并做好记录以便对服务器的性能做到心中有数。 2、在服务器租用交接时,要了解服务器的安全设置情况,对服务器安全技术方面不了解的…...
【公众号开发】图像文字识别 · 模板消息推送 · 素材管理 · 带参数二维码的生成与事件的处理
【公众号开发】(4) 文章目录 【公众号开发】(4)1. 图像文字识别功能1.1 百度AI图像文字识别接口申请1.2 查看文档学习如何调用百度AI1.3 程序开发1.3.1 导入依赖:1.3.2 公众号发来post请求格式1.3.3 对image类型的消息…...

Linux---(三)基本指令大全
前提引入:历史上先出现的键盘还是鼠标? 答案:键盘 ✨所以刚开始的时候绝对没有图形化界面,因此操作系统刚开始兴起的时候绝对没有图形化界面,因为当时没有鼠标。 ✨因为没有图形化界面,只有键盘,…...
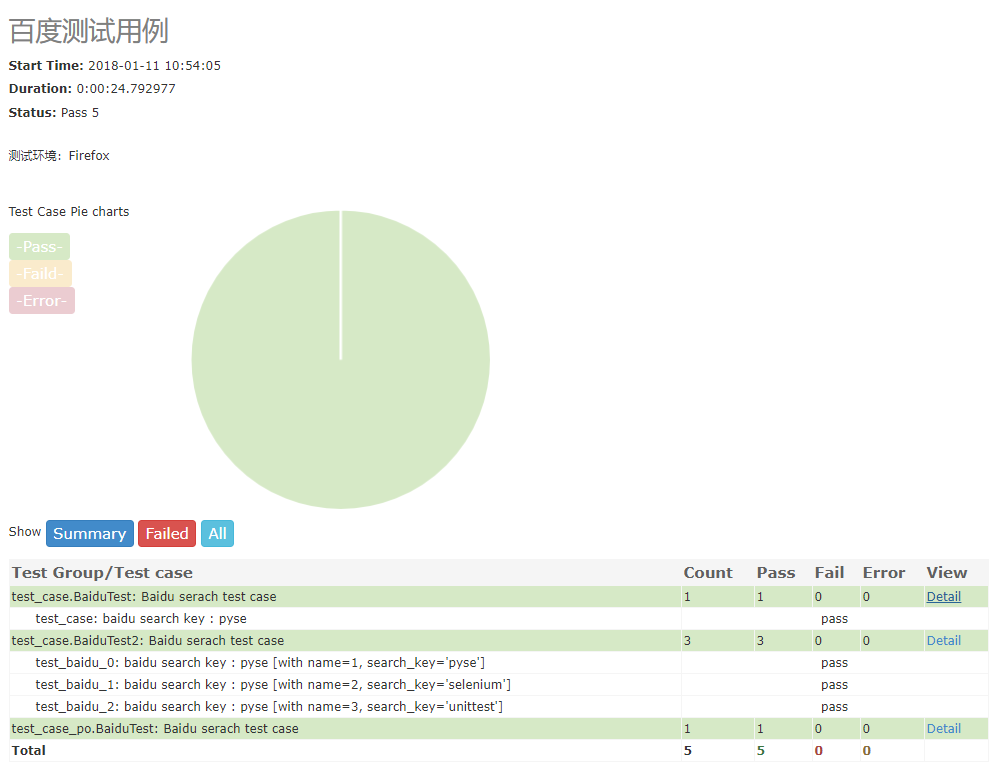
基于selenium的pyse自动化测试框架
介绍: pyse基于selenium(webdriver)进行了简单的二次封装,比selenium所提供的方法操作更简洁。 特点: 默认使用CSS定位,同时支持多种定位方法(id\name\class\link_text\xpath\css)…...
【微服务 SpringCloudAlibaba】实用篇 · Nacos注册中心
微服务(5) 文章目录 微服务(5)1. 认识和安装Nacos2. 服务注册到nacos和拉取服务1)引入依赖2)配置nacos地址3)重启 3. 服务分级存储模型3.1 给user-service配置集群3.2 同集群优先的负载均衡 4. …...

华为手机安卓扫描安装包apk在哪
1、在文件管理器里找,有的安装包没有搜索到2、在应用市场-我的-安装包管理,它会扫描整个手机,推荐...
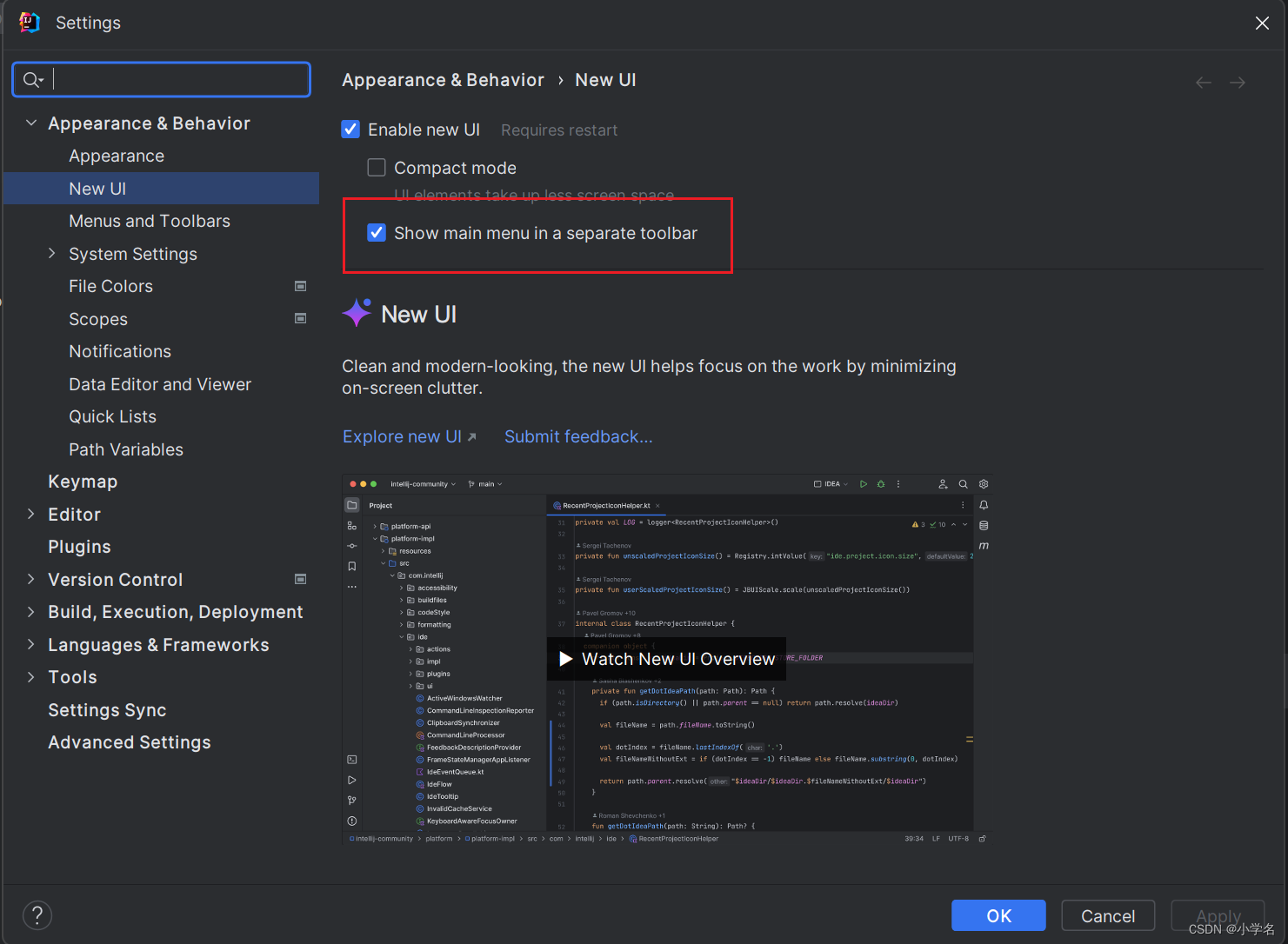
IDEA 新版本设置菜单展开
使用了新版本的IDEA 新UI后,常用的file,view,菜单看不见了,不太适应,找了一下,有个配置可以修改。 打开settings里面把show main menu in a separate toolbar勾选上,应用保存就可以了...

Leetcode 350:两个数组的交集II
给你两个整数数组 nums1 和 nums2 ,请你以数组形式返回两数组的交集。返回结果中每个元素出现的次数,应与元素在两个数组中都出现的次数一致(如果出现次数不一致,则考虑取较小值)。可以不考虑输出结果的顺序。 示例 1…...
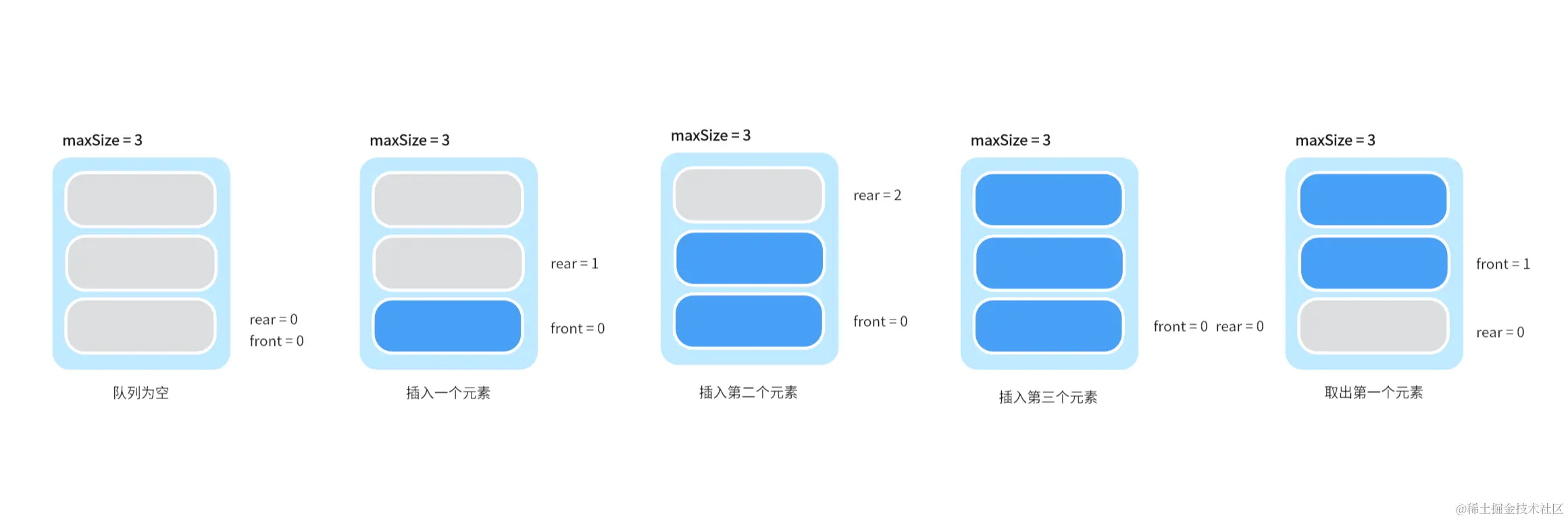
【数据结构】队列的实现与优化指南
一、前言 队列是一种重要的数据结构,它按照“先入先出”(FIFO)的原则管理数据。本文将介绍队列的概念、应用场景,以及如何使用数组实现普通队列和环形队列。 二、内容 2.1 概述 (1)什么是队列࿱…...
视频太大怎么压缩变小?三分钟学会视频压缩
随着科技的不断发展,视频已经成为了我们日常生活中不可或缺的一部分,然而,大尺寸的视频文件常常会给我们带来诸多困扰,例如发送不便、存储空间不足等等,那么,如何将这些过大的视频文件压缩变小呢࿱…...

Rust 泛型
泛型 Generics泛型详解 使用泛型参数,有一个先决条件,必需在使用前对其进行声明: fn largest<T>(list: &[T]) -> T {该泛型函数的作用是从列表中找出最大的值,其中列表中的元素类型为 T。首先 largest<T> 对…...
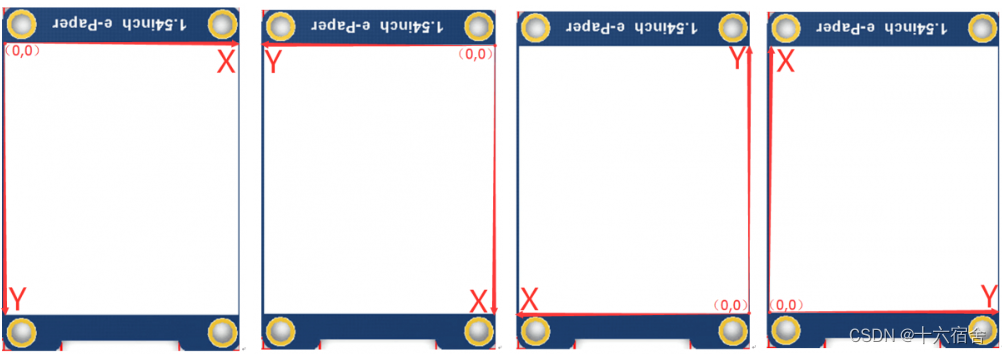
STM32+2.9inch微雪墨水屏(电子纸)实现显示
本篇文章从硬件原理以及嵌入式编程等角度完整的介绍了墨水屏驱动过程,本例涉及的墨水屏为2.9inch e-Paper V2,它采用的是“微胶囊电泳显示”技术进行图像显示,其基本原理是悬浮在液体中的带电纳米粒子受到电场作用而产生迁移,从而改变显示屏各…...

Hadoop3教程(二十九):(生产调优篇)集群扩容及缩容(白名单与黑名单)
文章目录 (150)添加白名单(151)服役新服务器(152)服务器间数据均衡(153)黑名单退役服务器参考文献 这一章还算是比较重要的。 (150)添加白名单 白名单&#…...
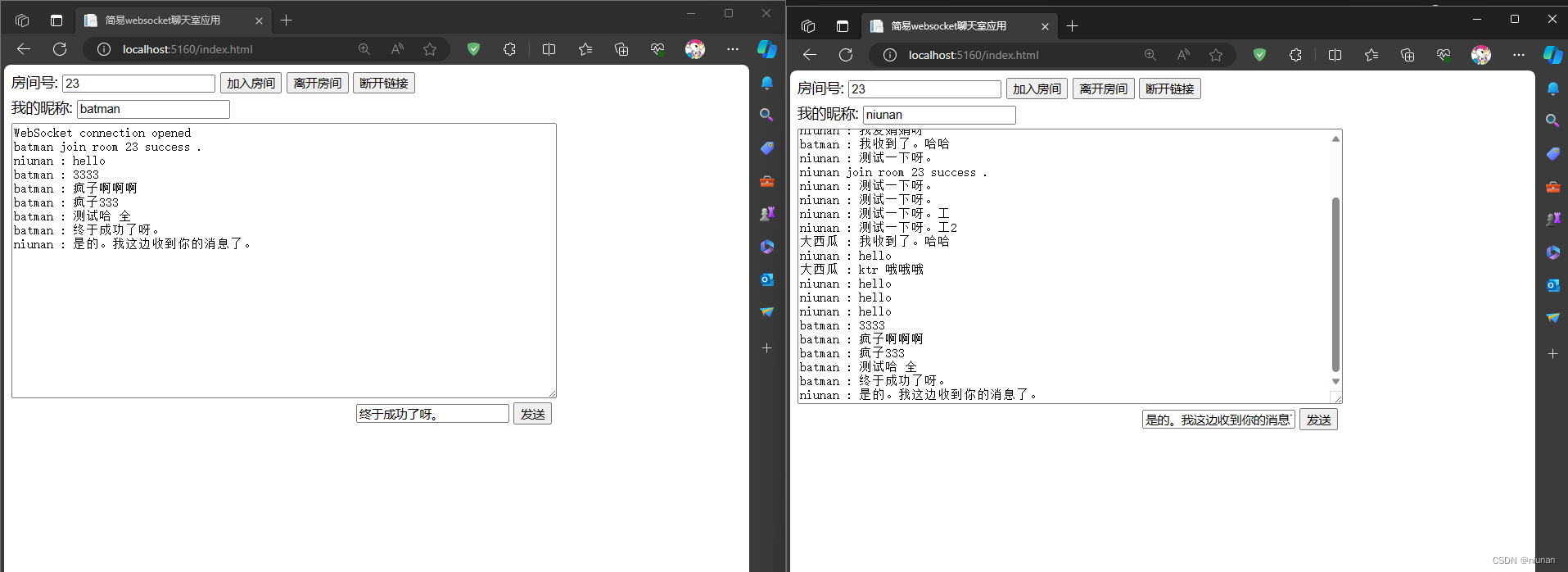
NET7下用WebSocket做简易聊天室
NET7下用WebSocket做简易聊天室 步骤: 建立NET7的MVC视图模型控制器项目创建websocket之间通信的JSON字符串对应的实体类一个房间用同一个Websocketwebsocket集合类,N个房间创建websocket中间件代码Program.cs中的核心代码,使用Websocket聊…...
)
PyQt5 + HFSS:给你的仿真脚本做个专属GUI界面(零基础搭建指南)
PyQt5 HFSS:零基础打造专业仿真GUI全攻略 当你的HFSS脚本开始变得复杂,每次运行都要在命令行里输入一堆参数时,是否想过给它穿上得体的"外衣"?想象一下:一个直观的界面,同事只需点击几下就能启动…...

Llama-3.2V-11B-cot实操案例:电商平台主图合规检测+改进建议推理生成
Llama-3.2V-11B-cot实操案例:电商平台主图合规检测改进建议推理生成 1. 项目背景与价值 在电商运营中,商品主图的质量直接影响转化率。据统计,合规性不足的主图会导致点击率下降30%以上。传统人工审核方式效率低下,平均每张图片…...

别再被dom4j的‘前言中不允许有内容’搞懵了!手把手教你用XmlMapper搞定Java对象转XML
告别dom4j解析噩梦:用Jackson XmlMapper优雅处理Java对象转XML 深夜调试代码时,突然蹦出org.dom4j.DocumentException: 前言中不允许有内容的报错——这场景Java开发者都不陌生。当我们需要将Java对象转为XML格式时,传统dom4j库对XML格式的严…...

从ESMM到MMoE:当推荐系统多目标‘闹矛盾’时,Google的‘多门控专家’怎么当和事佬?
从ESMM到MMoE:多任务学习模型如何化解推荐系统的目标冲突 推荐系统发展到今天,早已不再是简单的点击率预测工具。当我们需要同时优化点击率、转化率、观看时长、互动率等多个指标时,单任务学习模型就显得力不从心了。这就像让一个厨师同时做川…...
)
手把手教你用STM32F103的SPI2驱动FPGA(附Verilog从机代码)
STM32与FPGA的SPI通信实战:从硬件连接到代码调试全解析 在嵌入式系统开发中,处理器与可编程逻辑器件的协同工作变得越来越常见。STM32作为广泛使用的微控制器,与FPGA的高速通信是实现复杂系统功能的关键。本文将带你从零开始,完成…...

【Docker 27安全沙箱增强配置终极指南】:20年运维专家亲授生产环境零漏洞落地实践
第一章:Docker 27安全沙箱增强配置的核心演进与生产意义Docker 27 引入了基于 Linux 内核 eBPF 和 seccomp v2 的细粒度系统调用拦截机制,显著强化容器运行时的隔离边界。其安全沙箱不再仅依赖传统的 capabilities 剥离与 user namespace 映射࿰…...

Vivado 2017下Zynq-7000 PS端UDP通信实战:从lwIP配置到性能调优全记录
Vivado 2017环境下Zynq-7000 PS端UDP通信全流程实战指南 在嵌入式系统开发中,网络通信功能的实现往往面临工具链版本限制的挑战。本文将深入探讨如何在Vivado 2017这一相对陈旧的开发环境中,为Zynq-7000系列芯片的PS端构建完整的UDP通信功能。不同于新版…...

如何快速解锁NVIDIA消费级GPU虚拟化功能:完整操作指南
如何快速解锁NVIDIA消费级GPU虚拟化功能:完整操作指南 【免费下载链接】vgpu_unlock Unlock vGPU functionality for consumer grade GPUs. 项目地址: https://gitcode.com/gh_mirrors/vg/vgpu_unlock 在虚拟化环境中使用NVIDIA GPU加速一直是专业领域的特权…...
)
保姆级教程:在AirSim仿真中手把手教你用Python实现Q-learning无人机寻路(附完整代码)
从零构建AirSim无人机强化学习实战:Q-learning寻路全流程拆解 当第一次看到无人机在虚拟环境中自主寻找目标时,那种"代码产生智能"的震撼感至今难忘。本文将带你用Python和AirSim搭建完整的Q-learning训练系统,从环境配置到算法调优…...

经济研究论文排版终极指南:如何用LaTeX模板快速完成学术投稿
经济研究论文排版终极指南:如何用LaTeX模板快速完成学术投稿 【免费下载链接】Chinese-ERJ 《经济研究》杂志 LaTeX 论文模板 - LaTeX Template for Economic Research Journal 项目地址: https://gitcode.com/gh_mirrors/ch/Chinese-ERJ 还在为《经济研究》…...