Rust逆向学习 (1)
文章目录
- Hello, Rust Reverse
- 0x01. main函数定位
- 0x02. main函数分析
- line 1
- line 2
- line 3
- line 4~9
- 0x03. IDA反汇编
- 0x04. 总结
近年来,Rust语言的热度越来越高,很多人都对Rust优雅的代码和优秀的安全性赞不绝口。对于开发是如此,对于CTF也是如此,在逆向题和pwn题中都有出现。从本文开始我们将开始进行Rust逆向的学习,笔者将尽可能通过现有的IDA(7.7版本)对Rust ELF文件中包含的特性进行分析与总结,尽可能地减少Rust逆向的难度,尽可能地解决分析过程中产生的每一个问题,最终争取达到能够通过IDA反汇编结果还原Rust代码的程度。
本系列将跟随《Rust权威指南》的学习路线完成Rust逆向工程的学习。
阅读本文前,建议首先掌握:
- ✅ x86-64逆向的基础知识
- ✅ Rust语言的基本使用
Hello, Rust Reverse
首先我们写一个流程较猜数字稍简单一些的Rust程序,完成Rust ELF的第一次分析。
以下是Rust源码:
use std::io;fn main() {let mut input: String = String::new();io::stdin().read_line(&mut input).expect("Read Error!");let mut num = input.trim().parse().expect("Input not a number!");println!("{}", match num {1 => "one",2 => "two",x if x < 10 => "Something smaller than 10",_ => "Something not smaller than 10"});
}
使用cargo build编译后将ELF文件放入IDA中进行分析。这个ELF文件没有去除符号表,便于分析。
0x01. main函数定位
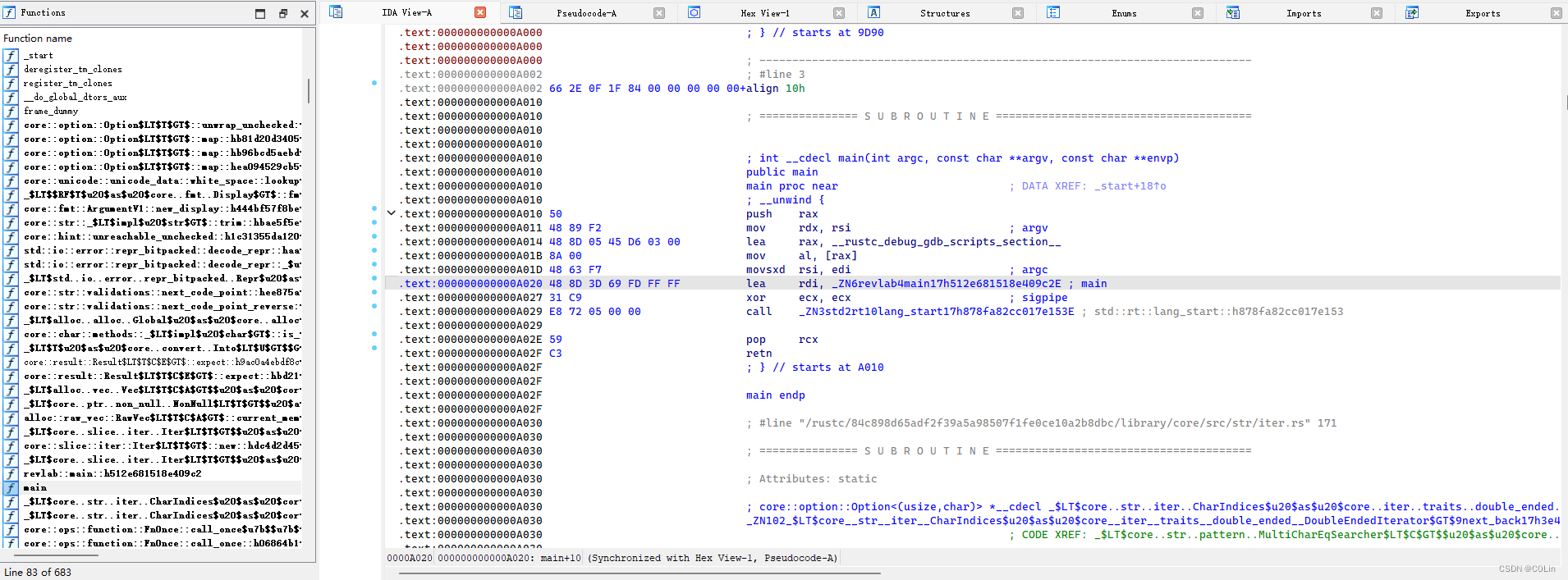
反汇编完成后,可以看到,左边栏的函数名大多很长,但也有一些规律可循。定位到main函数发现,main函数本身只有很少的几行代码,但Rust真正的main函数也不难找。看到0xA020处有一个main函数,这个项目笔者将其命名为revlab,而这个函数名中也正好就有revlab,因此可以推测出,这就是我们要找的Rust main函数。
但我们可以先不急着查看main函数的具体内容,单是这个main函数名就有一番研究的必要。_ZN6revlab4main17h512e681518e409c2E,这是Rust编译器赋予我们自己的main函数的函数名。有没有觉得这个函数名的命名规则很熟悉呢?没错,这种函数命名方式被称为name mangling,与C++编译器对函数的命名规则类似。这里参考资料。我们就可以将这个函数名进行简单的翻译:revlab::main,前面的_ZN是固定开头,6代表下一个模块的名字长度,也就是后面的revlab,4相同,即解析main,17h后面是函数的哈希值,可以忽略。这里通过左边栏可以看到,IDA能够自动为我们完成函数名的解析。
0x02. main函数分析
别看我们第一次写的main函数只有短短的几行,转换成汇编之后却有点让人头疼。考虑到这是我们第一次进行分析,笔者尝试借助其他的工具辅助分析——传送门。这个网站可以帮助我们将源代码与汇编代码对应起来,帮助我们进行分析。
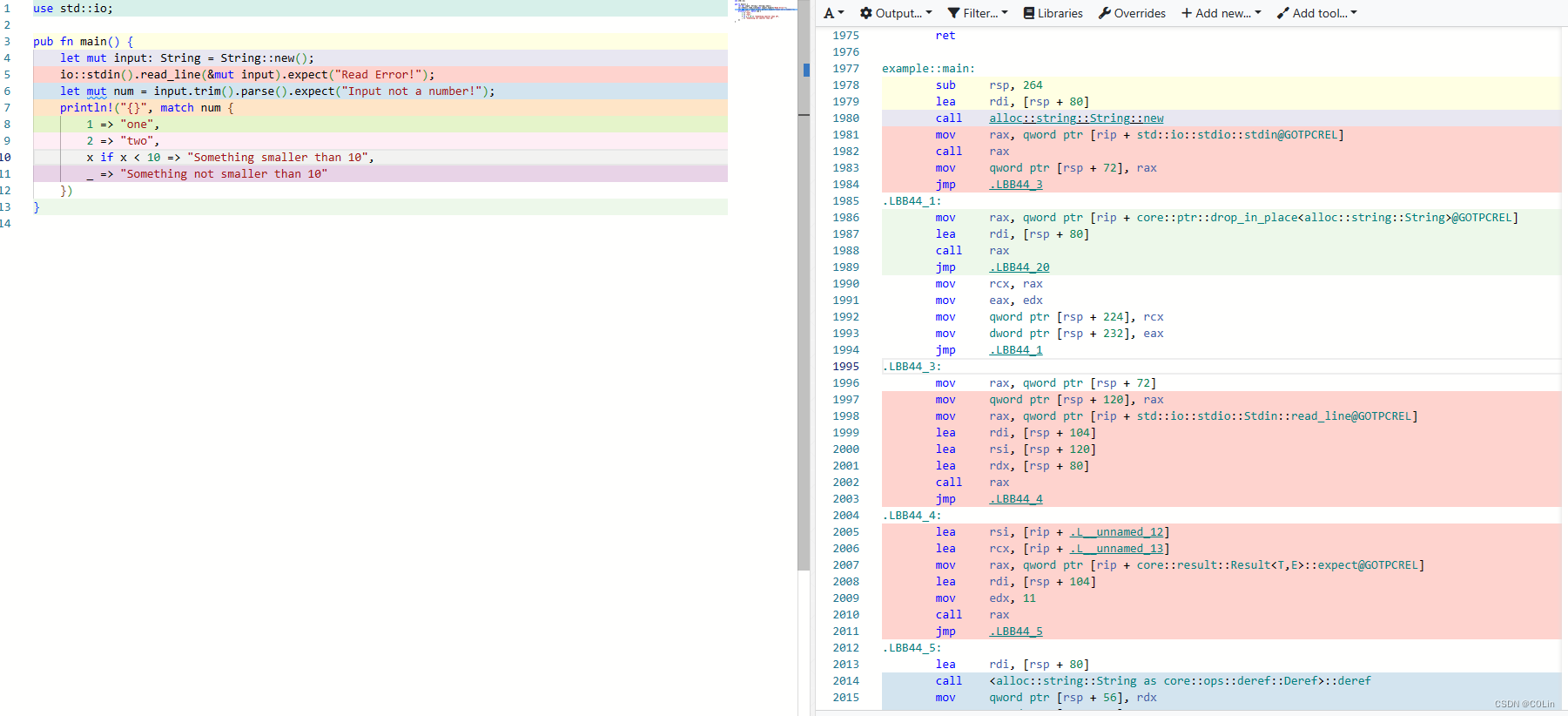
可以看到,main函数的汇编逻辑还是比较复杂的,这也是Rust ELF的一个特点,使得Rust反汇编较C/C++更难。
line 1
第一行定义了一个字符串变量,使用String::new()方法。但是在汇编中可以发现,call调用String::new()函数并没有对返回值进行操作,而是将rdi进行了赋值,这与C语言不同,如果按照C语言的逻辑,则更像是String::new(&input)。随后,笔者修改了代码进行试验,发现Vec的new方法流程类似。可见各个对象的new方法实际上是传了参的。
line 2
第二行就比第一行热闹多了,由于io::stdin()返回的是Stdin,代码中使用的返回值与C语言一样,保存在rax中。不过这里是首先将函数地址赋值给rax,通过call rax完成调用。调用完stdin()后,Rust不知道为什么用了一个jmp指令,跨越了几条指令再继续执行后面的read_line方法。对于read_line方法,可以看到前3个寄存器进行了赋值。其中rsi是io::stdin()的返回值,也就是Stdin对象实例,rdx是字符串input的地址,这一点可以通过第一行对[rsp+80]赋值得知,那么rdi是什么呢?这里就需要返回到IDA界面查看。

从上图可知,IDA将第一个参数解析为self,类型为core::result::Result<usize,std::io::error::Error>,而这个是read_line函数的返回值。这与io::stdin()不同,也是没有将返回值保存到rax。随后,代码继续向下,继续调用了expect方法,传入的d第一个参数就是Result实例,第二个参数是我们设置的错误字符串Read Error!地址,第三个参数为11,推测是错误字符串的长度,第四个参数通过查看发现,是这段汇编代码对应的源代码在工程中的路径。由此我们可以发现,如果今后我们需要分析一个不带符号的Rust ELF,发现有一个函数有4个参数,其中第2、4个参数均为字符串,且第4个参数是源文件地址、第3个参数是第2个参数字符串的长度,那么这个函数很有可能就是expect,通过跟踪第一个参数Result对象,可以继续进行分析。
汇编代码看到这里,我们能够发现,即使代码顺序执行,Rust编译器也一定要在一个函数调用结束后插入一个jmp指令,这一点可以从调用read_line方法可以得知,向下不断滑动窗口也能发现,整个main函数似乎是被许多jmp指令划分为许多小部分。
line 3
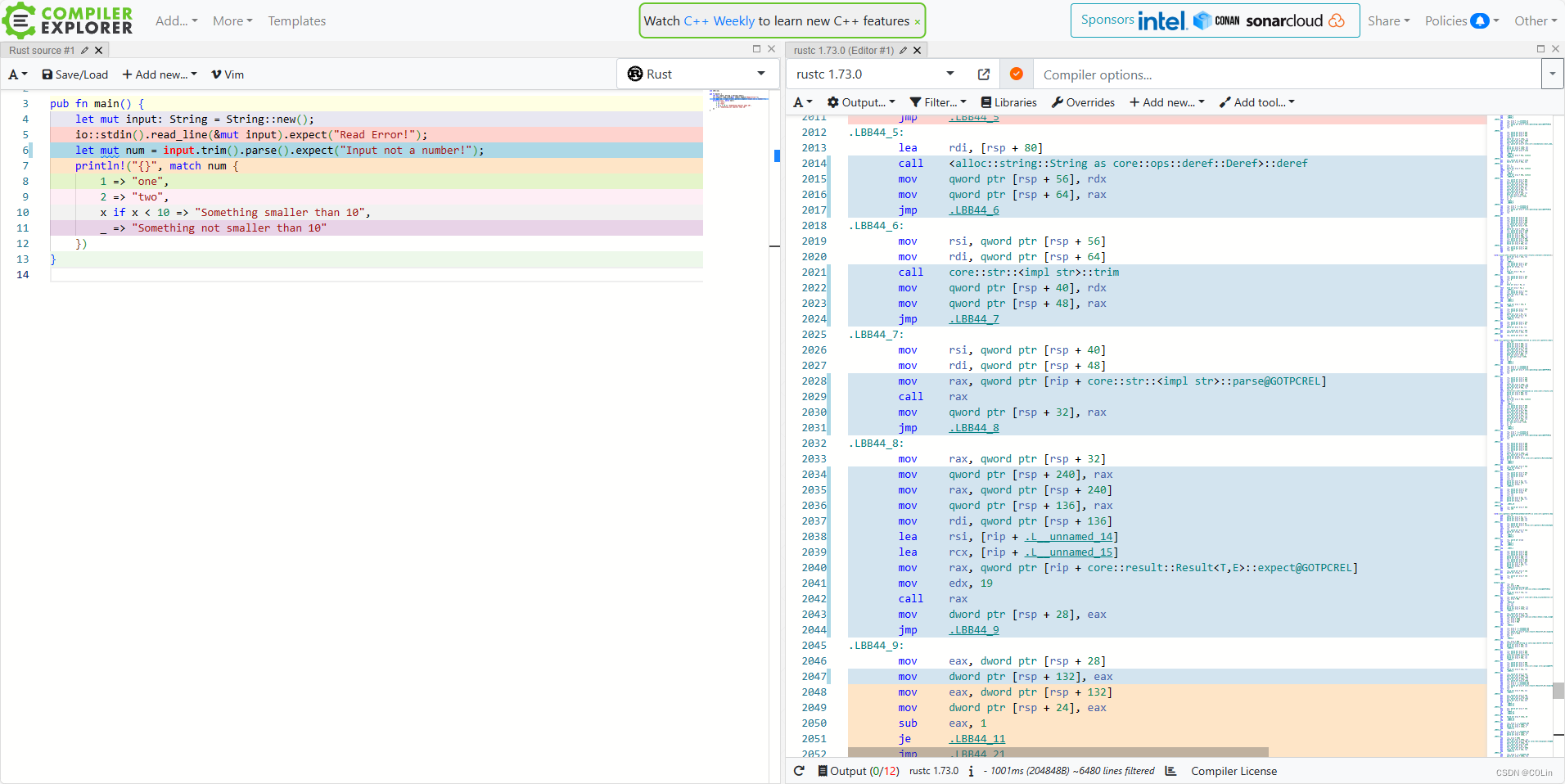
第三行首先看到,代码中使用了deref这个方法,至于为什么使用这个方法其实很好理解。deref传入的是String实例,返回的是字符串切片&str,而trim方法实际上是以切片作为self的,因此这里Rust隐式地将String转成切片之后再执行trim。
调用deref方法后需要注意,这里将rdx和rax保存到了栈中。记得在学习字符串切片的时候,书中有提及字符串切片实际上由两个部分组成——指针与长度。这里我们只通过静态分析无法判断rdx和rax到底是多少,虽然我们心中可能已经知道答案,但这里还是通过简单的调试来验证一下。

可以看到,这与我们的预期是相同的,rdx保存的是长度,rax保存的是字符串指针。因此我们知道了,String类型的deref方法会将返回值保存在两个寄存器——rdx与rax中。
好继续往下看。随后就是trim方法的调用,传入的第1个参数是字符串指针,第2个参数是长度。其返回值依然是保存在两个寄存器中。可见对于返回值为&str的Rust方法,其返回的方式也有一定规律。
trim之后是parse,返回值是Result类型,和read_line不同的是,read_line返回的Result实例没有泛型(Result<usize>),但是parse的返回值是Result<F, F::Err>,可能是这个原因,导致read_line可以将Result指针直接作为参数传递,而parse只能通过rax返回。不过目前这只是猜测,有关于Rust编译器对泛型的处理,就留到后面的文章中进行分析吧。
随后,有几行看似没有意义的汇编代码,像是mov qword ptr [rsp + 240], rax,这里的[rsp+240]在main函数自始至终只有这里被使用过。所以直接忽略。随后expect的传参与之前规则相同。
不过这里的expect是需要将返回值保存在num中的,也就是mov dword ptr [rsp + 28], eax这条语句,可见num是保存在[rsp+0x28]的位置。
line 4~9
下面的几行是一个println!一个match语句的值。在学Rust的时候我们了解到,match语句可以实现类似于lambda函数的功能,每一个分支的=>后都可以看成这个条件下match的返回值。就如这几行是将match的每一个分支语句都定义一个字符串切片作为传入println!
的格式化参数。
在上一行语句执行结束后,汇编代码首先将num的值放到eax中,随后进行分支判断。判断顺序是:是否等于1、是否等于2、是否小于10,而且match的判断语句是统一写在前面,具体的语句内容则放在后面。
通过对分支语句简单分析,容易得到match语句的“返回值”是保存在[rsp+208]和[rsp+216],因为这个是&str,所以要用0x10大小保存。
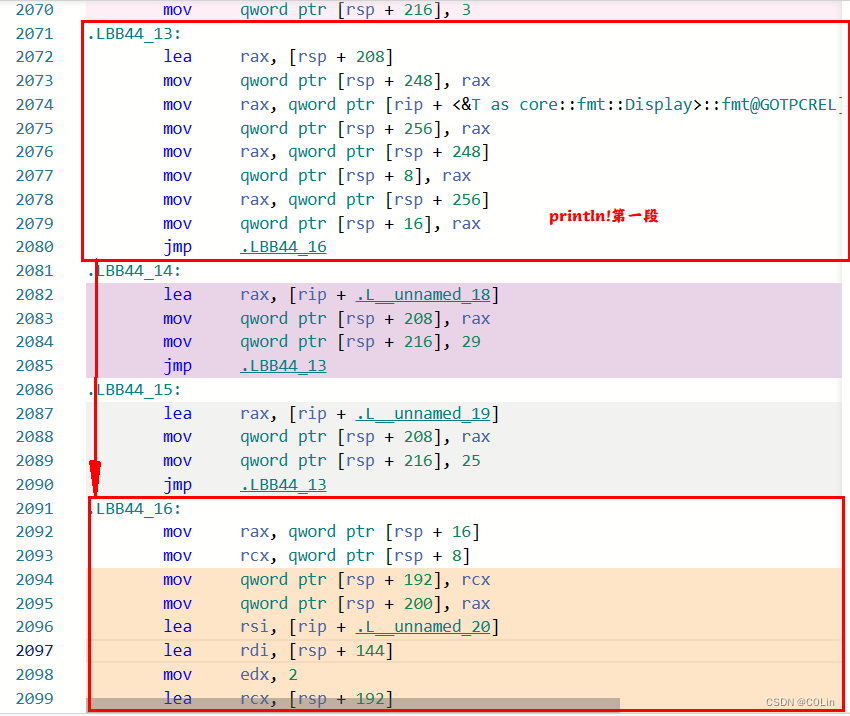
不过在汇编代码中,println!的处理流程可能不是都在所有match流程之后,而是在中间插入了一段,随后又在跳转到后面。使用1.69.0的rustc版本编译发现所有的match分支都位于println!之后,而更新版本的1.73.0则是将println!前半部分放在match分支部分中间。
随后则是println!的宏展开部分,考虑到println!太常见,通过IDA的反汇编输出的源代码可以识别出其特征。可以看到在汇编中调用了core::fmt::ArgumentV1::new_display、core::fmt::Arguments::new_v1、std::io::stdio::_print这三个方法。其中前面两个推测是Rust宏的转换函数,也就是将宏中大括号部分替换为具体的参数,而最后一个方法则是输出内容到控制台。
对于第一个函数,其唯一一个参数是match返回的字符串切片的栈地址。而对于第二个函数,传参情况则比较复杂。根据下文的_print函数传入的参数判断,第一个参数应该是返回值字符串的地址,第二个参数指向一个换行符的地址,但意义不明,第三个参数为2,第四个参数为第一个函数的返回值rax内容。第五个参数为1。目前只能确定第1个参数的含义,因此我们需要请求gdb的帮助。
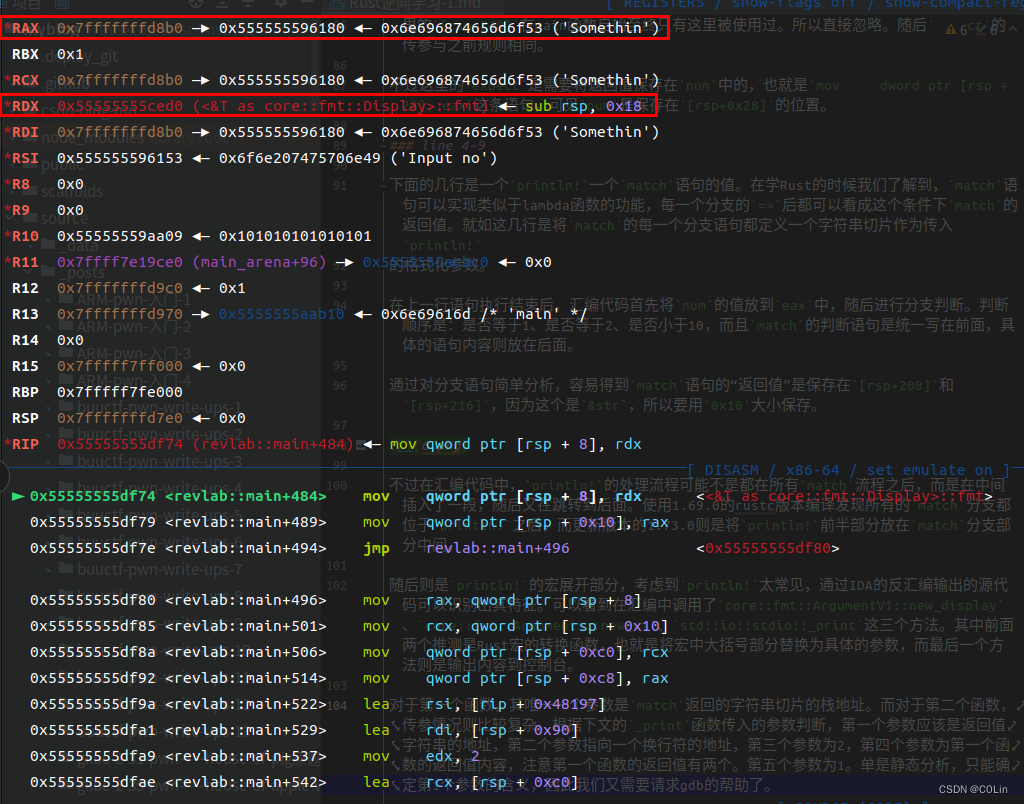
可以看到,第1个函数返回的rax是要输出的字符串。注意到在ELF中并没有找到左右大括号{}这个字符串,判断可能是Rust使用了其他的方式进行解析。但是除了第一个参数之外其他参数的意义还是不明。我们不妨稍稍修改一下println!格式化字符串的值,看看代码有什么变化。
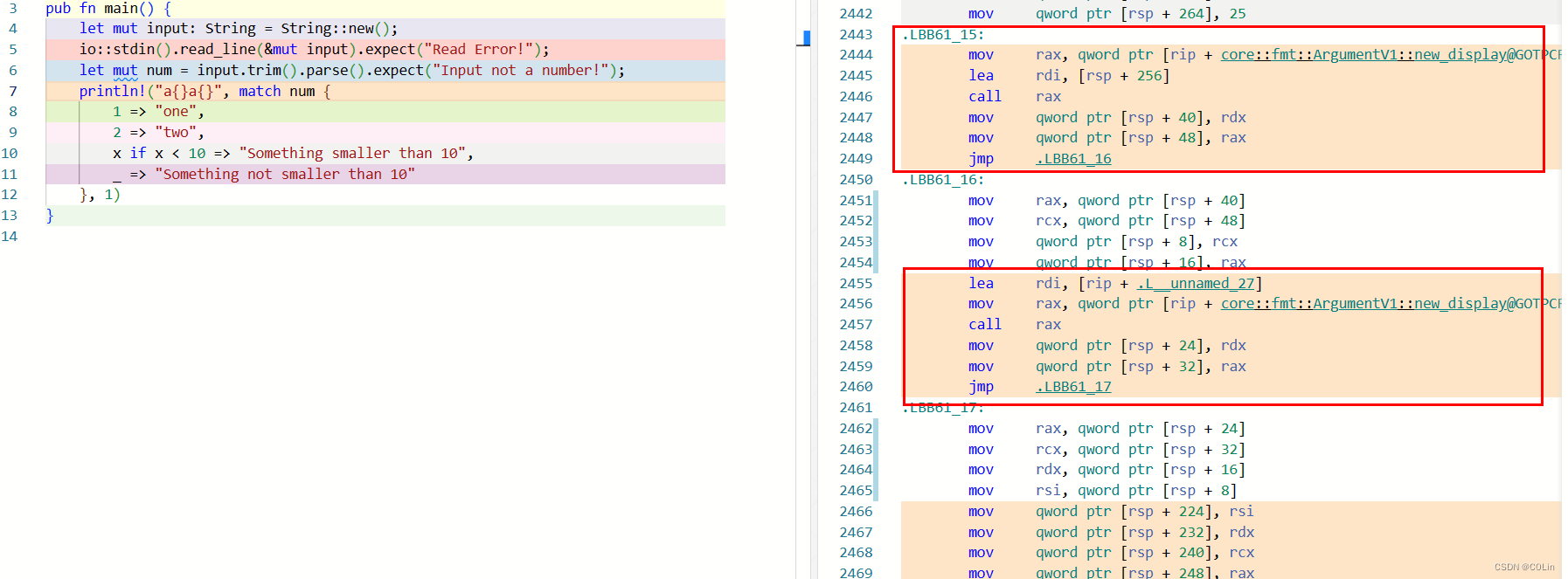
这里我们将字符串修改为a{}a{},在后面添加一个1作为第二个括号的占位符。随后我们发现,core::fmt::ArgumentV1::new_display函数被调用了两次。第一次调用传入match返回的字符串,而第二次调用传入的是这个东西:
.L__unnamed_27:.asciz "\001\000\000"
这不正好就是1吗?也就是说,core::fmt::ArgumentV1::new_display这个函数是用来解析println!后面的参数的,将其转换为字符串切片,有几个大括号就需要调用几次。随后继续进行分析,发现汇编代码将两个函数解析得到的两个字符串切片放到了一个连续的栈地址空间,并将其作为参数4(rcx)传入。
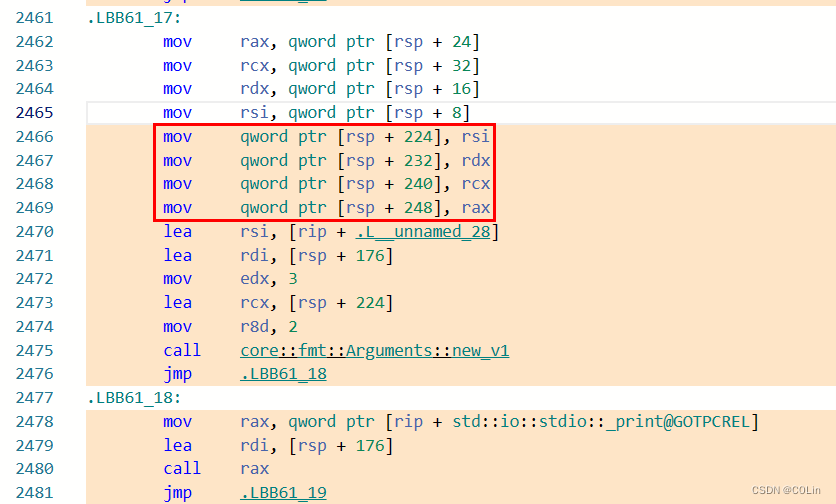
如上图所示,这里红框部分就是赋值过程,这个地方像是一个数组的结构,按照顺序排列每个大括号对应的字符串切片。由此便可以判断出参数5(r8d)的含义,其实就是解析的字符串切片的数量。
接下来我们再看一下参数2到底是什么东西。参数2指向了一个这样的结构:
.L__unnamed_28:.quad .L__unnamed_36.asciz "\001\000\000\000\000\000\000".quad .L__unnamed_36.asciz "\001\000\000\000\000\000\000".quad .L__unnamed_37.asciz "\001\000\000\000\000\000\000"
其中有:
.L__unnamed_36:.byte 97 ; 'a'.L__unnamed_37:.byte 10 ; '\n'
这样看来,这里的含义也就清楚了。编译器在对宏进行展开时转义大括号的内容是这样操作的:
- 首先将含有大括号的字符串以大括号分隔,并形成上面的这个数组结构。
- 对于每一个大括号,都调用一次转义函数进行转义,在栈中形成一个
&str的数组。 - 随后再调用另外一个函数(
core::fmt::Arguments::new_v1)将这些切片拼起来组成最终的字符串。
core::fmt::Arguments::new_v1的5个参数含义分别就是:
rdi:输出字符串指针rsi:预编译的数组结构,表示宏不需要转义的字符串部分rdx:预编译数组结构的长度rcx:运行时解析的已经被转义的&str数组r8:运行时解析的&str数组长度
这个函数调用完之后,就可以进行宏展开的后续代码了。对于println!而言是输出,也即调用std::io::stdio::_print。
输出之后,后面就没有多少代码了:
.LBB60_18:lea rdi, [rsp + 80]call qword ptr [rip + core::ptr::drop_in_place<alloc::string::String>@GOTPCREL]add rsp, 248retmov rax, qword ptr [rip + core::panicking::panic_cannot_unwind@GOTPCREL]call raxud2
.LBB60_20:mov rdi, qword ptr [rsp + 224]call _Unwind_Resume@PLTud2
这里的core::ptr::drop_in_place应该是Rust将这个String对象实例回收了。随后将栈上抬,main函数就正常返回了。
0x03. IDA反汇编
上一节我们对Rust ELF的分析大多是基于汇编层面进行的,当代码量比较多的时候,基本块之间的跳转关系可能会更加复杂,不利于我们的分析。不过IDA提供了非常实用的反汇编功能,在分析时,笔者认为如果我们能够将反汇编的内容与纯汇编代码相结合,效果会更好。
但IDA的反汇编功能一开始毕竟是为C/C++设计的,对于Rust的反汇编结果不很直观也是正常的。

在反汇编的输出结果中,出现了比较奇怪的地方。
最为明显的就是字符串的解析。通过查看ELF中保存字符串的地方可以发现,Rust的字符串与字符串之间有的是以换行符隔开的,有的根本就没有分割的字符,这与C/C++使用0字符分割每个字符串不同。因为Rust字符串切片的特性,对一个字符串切片的操作必然需要使用到这个切片的长度。既然已经知道了字符串的长度,字符串与字符串之间的分隔就显得没有那么必要了。
不过庆幸的是,反汇编中对于main函数的主要逻辑的解析还是比较清楚的,第一行的String::new()表示创建了一个String实例,随后多个函数的调用连在一起就组成了第二行的读取字符串内容,就是expect函数的解析看上去不是很舒服,毕竟其与C/C++的函数调用规则有些许不同。
再往下,可以看到deref、trim、parse、expect,这些函数组成了第三行的内容。
对于接下来的match,在反汇编界面中是将其解析成了多个if-else语句。随后就是println!的宏展开,输出字符串。输出后通过drop_in_place删除了一开始创建的String实例,函数返回。
0x04. 总结
以上就是我们的第一次Rust逆向尝试,还是有很多收获的,下面是本文的总结:
- Rust的main函数与ELF中的main不同,但很好找。
- Rust编译器喜欢将代码用
jmp指令分割为一个个小部分。 - 对于返回
&str的方法,是将切片的指针和长度分别保存在rax和rdx之中。 - 对于
struct的new方法,一般可在反汇编界面中直接识别,在汇编中实际执行的更像是通过xxx.new(&target)的方式进行初始化。 - Rust对宏展开的处理有一定的规律,可通过这些规律在反汇编界面中识别出宏展开的部分。
不得不说,Rust编译器在汇编层面的处理还是有点意思的。在后面的文章中,我们将尝试分析更加复杂的代码,尝试整理出更多Rust语言特性在汇编层面中的实现方式。
相关文章:
Rust逆向学习 (1)
文章目录 Hello, Rust Reverse0x01. main函数定位0x02. main函数分析line 1line 2line 3line 4~9 0x03. IDA反汇编0x04. 总结 近年来,Rust语言的热度越来越高,很多人都对Rust优雅的代码和优秀的安全性赞不绝口。对于开发是如此,对于CTF也是如…...

【Golang | reflect】利用反射实现方法的调用
引言 go语言中,如果某个数据类型实现了一系列的方法,如何批量去执行呢,这时候就可以利用反射里的func (v Value) Call(in []Value) []Value 方法。 // Call calls the function v with the input arguments in. // For example, if len(in)…...

Teleport
从官网中获取到的代码如下 App.vue <template><div class"outer"><h3>Tooltips with Vue 3 Teleport</h3><div><MyModal /></div></div> </template> <script setup> import MyModal from "./My…...

flutter与原生 相互通信实战
一、原生和flutter 通信 ios 通信类 CommonUtil.swift import Foundation import Flutterpublic class CommonUtil {public static func emitEvent(channel: FlutterMethodChannel, method: String, type: String, errCode: Int32?, errMsg: String?, data: Any?){safeMa…...

结构光相机原理
结构光相机原理...

ubuntu安装Anaconda
下载 Anaconda 进入 Ubuntu,自己新建下载路径,输入以下命令开始下载 注意,如果不是 x86_64,需要去镜像看对应的版本(https://mirrors.bfsu.edu.cn/anaconda/archive/?CM&OA) wget https://mirrors.…...

【RNA structures】RNA转录的重构和前沿测序技术
文章目录 RNA转录重建1 先简单介绍一下测序相关技术2 Map to Genome Methods2.1 Step1 Mapping reads to the genome2.2 Step2 Deal with spliced reads2.3 Step 3 Resolve individual transcripts and their expression levels 3 Align-de-novo approaches3.1 Step 1: Generat…...

4、Kafka 消费者
5.1 Kafka 消费方式 5.2 Kafka 消费者工作流程 5.2.1 消费者总体工作流程 5.2.2 消费者组原理 Consumer Group(CG):消费者组,由多个consumer组成。形成一个消费者组的条件,是所有消费者的groupid相同。 • 消费者组内…...
CSS3 渐变
CSS3 渐变可以让你在两个或多个指定的颜色之间显示平稳的过渡。 CSS3渐变有两种类型:线性渐变(Linear Gradients)和径向渐变(Radial Gradients)。 线性渐变(Linear Gradients): 线性…...

【Python 千题 —— 基础篇】分割有效信息
题目描述 题目描述 有时候我们需要截取字符串以获取有用的信息,比如对于字符串 “日期:2010-10-29”,我们需要截取后面的 10 个字符来获取日期,以便进行进一步分析。编写一个程序,输入一个字符串,然后输出…...

webrtc基于DTLS的端口复用技术
DTLS协议: DTLS(Datagram Transport Layer Security)数据包安全传输协议,用于在不可靠的数据包传输协议上(如UDP)提供数据的安全传输。 UDP多路复用: 一个UDP多路复用,被用来处理共享同一个UDP端口的多个并发的UDT连接。类似同一个tcp port上创建多个socket connec…...

【2024秋招】2023-9-20 度小满信贷系统平台部二面
1 面试官的部门介绍 我们部门是信贷系统平台部,主要是为度小满做一个服务,你应该也接触过信用卡,跟这种差不多,用户可以打进我们的系统申请一个额度,整个部门的规模大概是400-500人左右,我个人来自平台数据…...
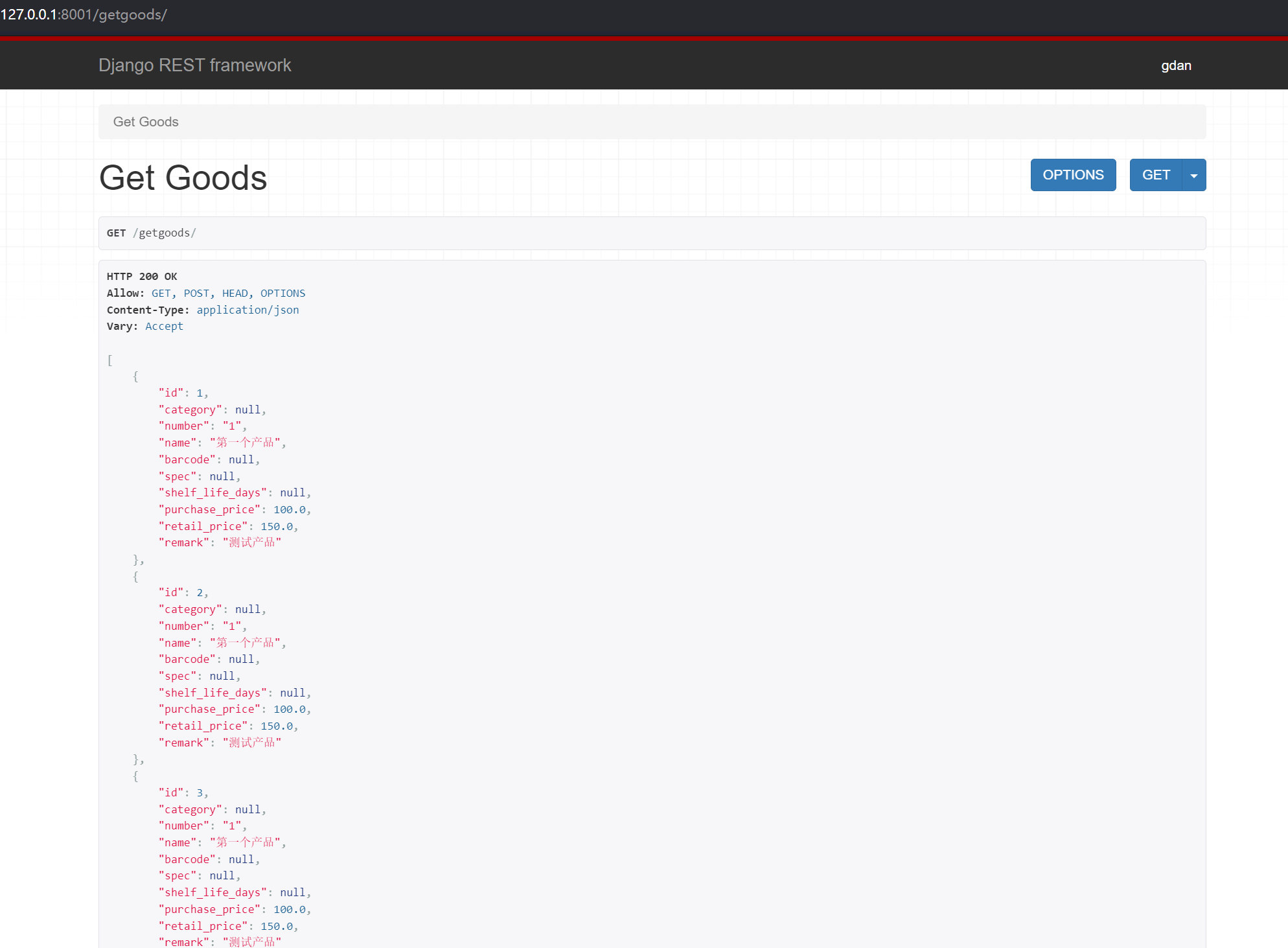
【Django 04】Serialization 序列化的高级使用
序列化器 serializers 序列化器的作用 序列化将 queryset 和 instance 转换为 json/xml/yaml 返回给前端 反序列化与序列化则相反 定义序列化器 定义类,继承自 Serializer 通常新建一个 serializers.py 文件 撰写序列化内容 suah as 目前只支持 read_only 只…...
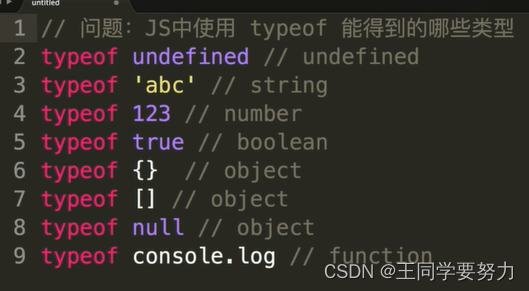
【前端学习】—变量类型和计算(五)
【前端学习】—变量类型和计算(五) 一、JS中使用typeof能得到哪些类型 字符串(String):表示文本数据,用单引号或双引号括起来。 数字(Number):表示数值数据,包括整数和浮点数。 布尔值(Boolean):表示真或假(true或false)的逻辑值。 空值(Null):表示一个空…...
QT中窗口自绘制效果展示
项目中需要使用QT进行窗口自绘,前期先做一下技术探索,参考相关资料代码熟悉流程。本着代码是最好的老师原则,在此记录一下。 目录 1.运行效果 2.代码结构 3.具体代码 1.运行效果 2.代码结构 3.具体代码 myspeed.pro QT core gui…...

Android Studio 直接获取Spinner的值
最近做一个小demo 使用Spinner下拉框来让用户选择地区、周数(第1-12周) 然后参考了一下别人的文章 这里引用这位博主博文: AndroidStudio使用spinner控件并添加监听(极简)_安卓spinner监听事件_天王老子来了我也不…...

渗透测试工具(3)Burpsuite
笔记目录 渗透测试工具(1)wireshark渗透测试工具(2)Nmap渗透测试工具(3)Burpsuite 1.简介 是Web应用程序测试,请求的拦截和修改,扫描web应用程序漏洞,以暴力破解登陆表单,执行会话令牌等多种的随机性检查。 (1)模块介绍 ①Intercept:用于显示和修改Ht…...

大数据之LibrA数据库系统上下电管理
系统上电 操作场景 系统管理员进行例行维护停机后需要重新启动服务器与FusionInsight LibrA集群。如果安装双机Manager,上电后HA将确定主备管理节点。系统启动完成后需要启动依赖集群运行的上层业务。 对系统的影响 系统上电完成以前集群不可用。 前提条件 获…...

Node.js、Vue的安装与使用(Linux OS)
Vue的安装与使用(Linux OS) Node.js的安装Vue的安装Vue的使用 操作系统:Ubuntu 20.04 LTS Node.js的安装 安装Node.js Node.js官方下载地址 1.选择合适的系统架构(可通过uname -m查看)版本安装 2.下载文件为tar.xz格…...

SparkSQL入门
概述 两种模式 Spark on Hive: 语法是Spark SQL语法,实际上是在IDEA上编写java叠加SQL的代码。 Hive on Spark: 只是替换了Hadoop的MR,改为了Spark的计算引擎。 发展历史 RDD > DataFrame > DataSet: 都有惰性机制,遇…...

RV1126+IMX214摄像头调试避坑实录:从I2C通信失败到成功抓取RAW图
RV1126IMX214摄像头调试实战:从硬件排查到RAW数据抓取全解析 调试嵌入式摄像头系统就像一场精密的外科手术,每一个环节都可能成为阻碍图像数据流动的"血栓"。当我在Owl开发板上首次尝试让IMX214传感器与RV1126芯片协同工作时,一连串…...
)
Wallpaper Engine 壁纸自定义全攻略:从零开始打造动态交互壁纸(附常见问题解决方案)
Wallpaper Engine 交互式壁纸设计进阶指南:从参数配置到性能调优 在数字个性化时代,动态壁纸已成为展示创意与技术融合的最佳载体。Wallpaper Engine作为目前最强大的实时壁纸创作工具,其真正的魅力不仅在于呈现精美动画,更在于让…...

从战场到物流:多无人机路径规划中的A*、RRT和MPC到底该怎么选?
从战场到物流:多无人机路径规划中的A*、RRT和MPC到底该怎么选? 当无人机从军事领域走向民用场景,路径规划算法的选择直接决定了项目成败。在智慧物流园区巡检中,一架误判障碍物的无人机可能撞毁价值百万的货物;在城市应…...

Keras图像数据增强实战:提升模型泛化能力
1. 图像数据增强在Keras中的配置指南在计算机视觉项目中,数据不足是常见挑战。我曾在多个实际项目中验证过,合理使用图像数据增强技术能使模型准确率提升15-30%。Keras提供的ImageDataGenerator类让这项技术变得触手可及。数据增强的本质是通过对原始图像…...

信息论安全多方计算协议突破
某机构Tal Rabin荣获分布式计算领域Dijkstra奖 该奖项旨在表彰某机构首席首席科学家、宾夕法尼亚大学教授提出的一项协议,该协议实现了信息论安全多方计算的理论极限。 作者:Larry Hardesty 2024年2月8日 6分钟阅读 安全多方计算简介 安全多方计算&#…...

盛合晶微科创板上市,开盘市值近1858亿,无锡国资投资回报率超600%
盛合晶微上市:募资50.28亿,市值飙升至1418亿4月21日,集成电路晶圆级先进封测企业盛合晶微半导体有限公司在上交所科创板挂牌,发行价19.68元,预计募资总额约50.28亿元。上市首日,盛合晶微开盘大涨406.71%报9…...

终极网盘直链下载助手完整指南:如何一键获取八大网盘真实下载地址
终极网盘直链下载助手完整指南:如何一键获取八大网盘真实下载地址 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动…...

别再只调饱和度了!从人眼视觉到sRGB:深入理解CCM在手机拍照里的‘隐形’作用
手机摄影的色彩密码:揭开CCM如何重塑你的每一张照片 清晨的阳光洒在公园长椅上,你用不同品牌的手机拍摄同一片郁金香花海——华为的鲜艳夺目、iPhone的真实自然、小米的浓郁厚重。这些风格差异的背后,藏着一个被99%用户忽略的关键技术&#x…...

Vivado 2017下Zynq-7000 PS端UDP通信实战:从lwIP配置到性能调优全记录
Vivado 2017环境下Zynq-7000 PS端UDP通信全流程实战指南 在嵌入式系统开发中,网络通信功能的实现往往面临工具链版本限制的挑战。本文将深入探讨如何在Vivado 2017这一相对陈旧的开发环境中,为Zynq-7000系列芯片的PS端构建完整的UDP通信功能。不同于新版…...

鸿蒙 Electron 跨平台应用开发:文字战斗系统与英雄系统进阶开发详解——自定义英雄参战
欢迎加入开源鸿蒙PC社区: https://harmonypc.csdn.net/ atomgit开源仓库地址: https://atomgit.com/feng8403000/electron_TextGame_DIVBOSS 示例效果 项目背景 在游戏开发中,玩家对游戏的定制化需求越来越高。为了满足玩家的个性化需求&am…...