Golang爬虫入门指南
引言
网络爬虫是一种自动化程序,用于从互联网上收集信息。随着互联网的迅速发展,爬虫技术在各行各业中越来越受欢迎。Golang作为一种高效、并发性好的编程语言,也逐渐成为爬虫开发的首选语言。本文将介绍使用Golang编写爬虫的基础知识和技巧。
一、环境准备
在开始编写Golang爬虫之前,我们需要先准备好开发环境。首先,确保你已经安装了Golang,并配置好了GOPATH。其次,我们需要安装一些必要的库,比如net/http用于发送HTTP请求,golang.org/x/net/html用于解析HTML等。可以使用go get命令来安装这些库。
go get -u golang.org/x/net/html
二、发送HTTP请求
在编写爬虫之前,我们需要先了解如何发送HTTP请求。Golang提供了net/http包,可以方便地发送GET和POST请求。
package mainimport ("fmt""io/ioutil""net/http"
)func main() {resp, err := http.Get("https://www.example.com")if err != nil {fmt.Println("请求发送失败:", err)return}defer resp.Body.Close()body, err := ioutil.ReadAll(resp.Body)if err != nil {fmt.Println("读取响应失败:", err)return}fmt.Println(string(body))
}
上面的代码中,我们使用http.Get发送了一个GET请求,并得到了响应。然后我们使用ioutil.ReadAll来读取响应的内容,并将其打印出来。
三、解析HTML
一般来说,我们爬取的数据都是存储在HTML中的。因此,我们需要学会如何解析HTML。Golang提供了golang.org/x/net/html包来帮助我们解析HTML。
package mainimport ("fmt""net/http""golang.org/x/net/html"
)func main() {resp, err := http.Get("https://www.example.com")if err != nil {fmt.Println("请求发送失败:", err)return}defer resp.Body.Close()doc, err := html.Parse(resp.Body)if err != nil {fmt.Println("解析HTML失败:", err)return}// 在这里进行HTML解析操作...}
上面的代码中,我们使用html.Parse函数来解析HTML,并得到一个表示整个HTML文档的树状结构。在这个树状结构中,我们可以使用不同的方法来查找和提取我们需要的数据。
package mainimport ("fmt""net/http""golang.org/x/net/html"
)func main() {resp, err := http.Get("https://www.example.com")if err != nil {fmt.Println("请求发送失败:", err)return}defer resp.Body.Close()doc, err := html.Parse(resp.Body)if err != nil {fmt.Println("解析HTML失败:", err)return}findLinks(doc)
}func findLinks(n *html.Node) {if n.Type == html.ElementNode && n.Data == "a" {for _, a := range n.Attr {if a.Key == "href" {fmt.Println(a.Val)}}}for c := n.FirstChild; c != nil; c = c.NextSibling {findLinks(c)}
}
上面的代码中,我们定义了一个递归函数findLinks来查找HTML中的所有链接。我们使用html.Node的Type和Data属性来判断当前节点是否为<a>标签,并使用Attr属性来获取链接的地址。
四、并发爬虫
并发是Golang的一个重要特性,能够提高爬虫的效率。我们可以使用Golang的并发机制来同时发送多个HTTP请求,加快网页的爬取速度。
package mainimport ("fmt""net/http""golang.org/x/net/html"
)func main() {urls := []string{"https://www.example.com/page1","https://www.example.com/page2","https://www.example.com/page3",}ch := make(chan string)for _, url := range urls {go fetch(url, ch)}for range urls {fmt.Println(<-ch)}
}func fetch(url string, ch chan<- string) {resp, err := http.Get(url)if err != nil {ch <- fmt.Sprintf("请求 %s 发送失败:%v", url, err)return}defer resp.Body.Close()doc, err := html.Parse(resp.Body)if err != nil {ch <- fmt.Sprintf("解析 %s 失败:%v", url, err)return}// 在这里进行HTML解析操作...ch <- fmt.Sprintf("请求 %s 完成", url)
}
上面的代码中,我们定义了一个ch通道用于接收爬虫的结果。然后,我们使用go关键字来开启多个协程,每个协程负责爬取一个网页的内容并进行解析。最后,我们使用<-ch来从通道中获取结果并打印出来。
五、数据存储
爬取到的数据通常需要保存到数据库或者文件中。Golang提供了各种数据库驱动和文件操作函数,可以方便地进行数据存储。
package mainimport ("fmt""net/http""golang.org/x/net/html""os""io"
)func main() {resp, err := http.Get("https://www.example.com")if err != nil {fmt.Println("请求发送失败:", err)return}defer resp.Body.Close()file, err := os.Create("output.html")if err != nil {fmt.Println("创建文件失败:", err)return}defer file.Close()_, err = io.Copy(file, resp.Body)if err != nil {fmt.Println("保存文件失败:", err)return}fmt.Println("文件保存成功")
}
上面的代码中,我们使用os.Create函数创建了一个名为output.html的文件,并使用io.Copy函数将HTTP响应的内容保存到文件中。
六、案例
案例一:爬取网页标题
package mainimport ("fmt""net/http""golang.org/x/net/html"
)func main() {resp, err := http.Get("https://www.example.com")if err != nil {fmt.Println("请求发送失败:", err)return}defer resp.Body.Close()doc, err := html.Parse(resp.Body)if err != nil {fmt.Println("解析HTML失败:", err)return}title := findTitle(doc)fmt.Println("网页标题:", title)
}func findTitle(n *html.Node) string {if n.Type == html.ElementNode && n.Data == "title" {return n.FirstChild.Data}for c := n.FirstChild; c != nil; c = c.NextSibling {title := findTitle(c)if title != "" {return title}}return ""
}
在上面的例子中,我们使用findTitle函数来查找网页的标题。我们通过递归遍历HTML树,如果遇到<title>标签,我们就返回其内容。
案例二:爬取图片链接
package mainimport ("fmt""net/http""golang.org/x/net/html"
)func main() {resp, err := http.Get("https://www.example.com")if err != nil {fmt.Println("请求发送失败:", err)return}defer resp.Body.Close()doc, err := html.Parse(resp.Body)if err != nil {fmt.Println("解析HTML失败:", err)return}images := findImages(doc)fmt.Println("图片链接:")for _, img := range images {fmt.Println(img)}
}func findImages(n *html.Node) []string {var images []stringif n.Type == html.ElementNode && n.Data == "img" {for _, attr := range n.Attr {if attr.Key == "src" {images = append(images, attr.Val)}}}for c := n.FirstChild; c != nil; c = c.NextSibling {images = append(images, findImages(c)...)}return images
}
在上面的例子中,我们使用findImages函数来查找网页中的所有图片链接。我们通过递归遍历HTML树,如果遇到<img>标签,我们就将其src属性的值添加到结果集中。
案例三:爬取动态生成内容
package mainimport ("fmt""net/http""io/ioutil"
)func main() {resp, err := http.Get("https://api.example.com/data")if err != nil {fmt.Println("请求发送失败:", err)return}defer resp.Body.Close()body, err := ioutil.ReadAll(resp.Body)if err != nil {fmt.Println("读取响应失败:", err)return}fmt.Println("动态生成内容:", string(body))
}
在上面的例子中,我们通过发送HTTP请求获取了一个动态生成的内容。这个内容可能是通过API接口返回的,而不是直接通过HTML页面展示的。我们使用ioutil.ReadAll函数来读取响应的内容,并将其打印出来。
以上就是三个使用Golang编写爬虫的案例。通过这些案例,你可以更好地理解和应用Golang爬虫的基础知识和技巧。当然,实际的爬虫开发还需要根据具体的需求和场景进行更复杂的处理和优化。希望这些案例对你有所启发,让你能够更好地掌握Golang爬虫的开发。
结论
通过学习本文介绍的知识和技巧,我们可以使用Golang编写一个简单但功能强大的爬虫。当然,爬虫的开发还有很多其他的技术和工具可以学习和使用,但是本文所介绍的内容已经足够帮助我们入门和实践了。希望本文对你有所帮助,也希望你能够继续深入学习和探索爬虫技术的更多细节。
相关文章:

Golang爬虫入门指南
引言 网络爬虫是一种自动化程序,用于从互联网上收集信息。随着互联网的迅速发展,爬虫技术在各行各业中越来越受欢迎。Golang作为一种高效、并发性好的编程语言,也逐渐成为爬虫开发的首选语言。本文将介绍使用Golang编写爬虫的基础知识和技巧…...
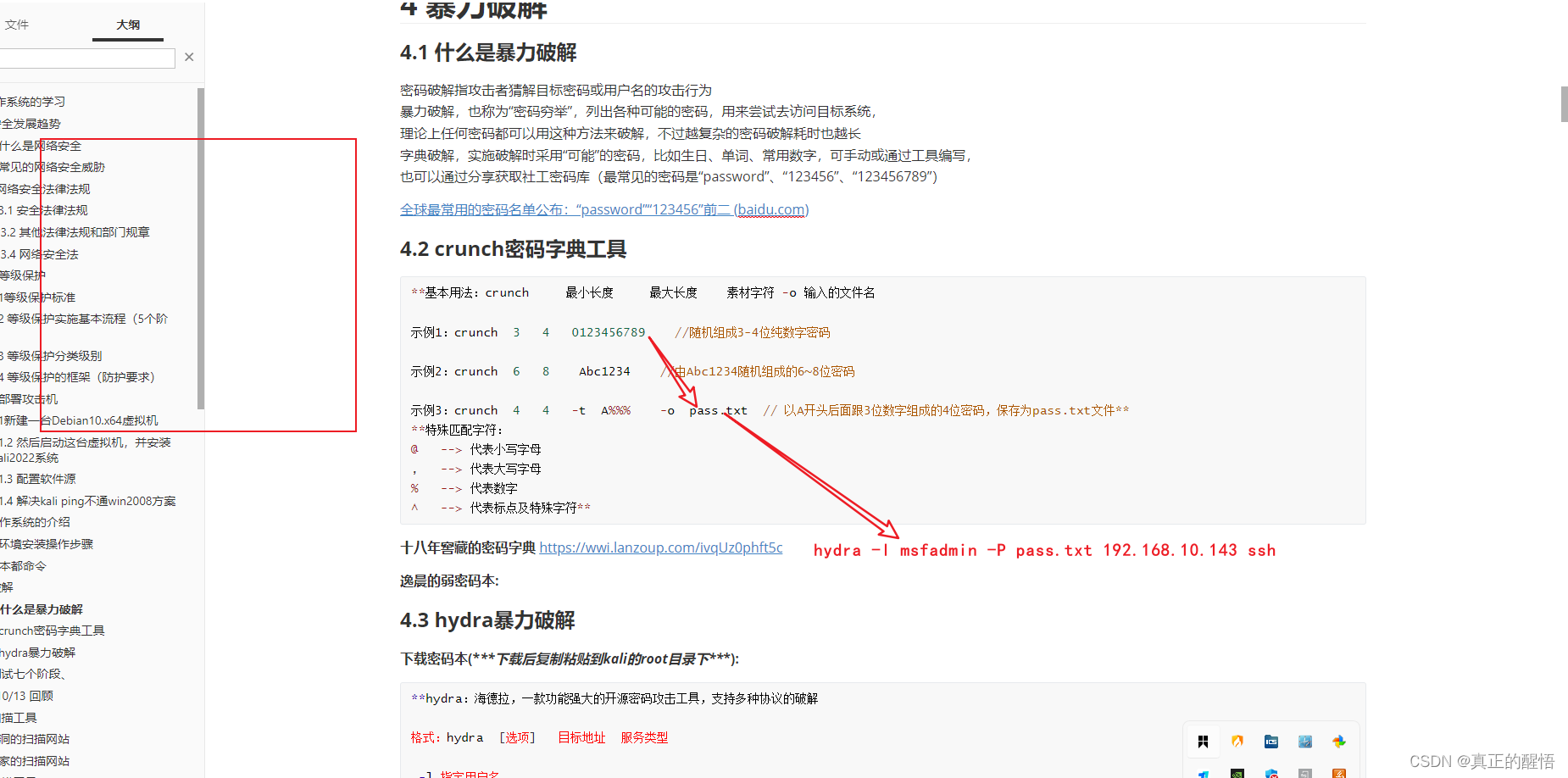
1024渗透测试如何暴力破解其他人主机的密码(第十一课)
1024渗透测试如何暴力破解其他人主机的密码(第十一课) 1 crunch 工具 crunch是一个密码生成器,一般用于在渗透测试中生成随机密码或者字典攻击。下面是常见的一些使用方法: 生成密码字典 生成6位数字的字典:crunch 6 6 -t -o dict.txt …...

记录一次线下渗透电气照明系统(分析与实战)
项目地址:https://github.com/MartinxMax/S-Clustr 注意 本次行动未造成任何设备损坏,并在道德允许范围内测试 >ethical hacking< 发现过程 在路途中,发现一个未锁的配电柜,身为一个电工自然免不了好奇心(非专业人士请勿模仿,操作不当的话220V人就直了) 根据照片,简…...

Android ADB 常用命令及详解
Android ADB 常用命令及详解 Android Debug Bridge(ADB)是 Android 开发工具包(SDK)的一部分,用于与 Android 设备通信和执行各种任务。无论你是 Android 开发者还是普通用户,了解 ADB 命令是非常有用的&a…...
)
GO 工程下载依赖操作流程(go mod)
1. 写一个main.go文件 package main import ("fmt""net/http""github.com/ClickHouse/clickhouse-go" ) func main() {fmt.Println("服务启动......")http.HandleFunc("/hello", func(w http.ResponseWriter, r *http.Requ…...
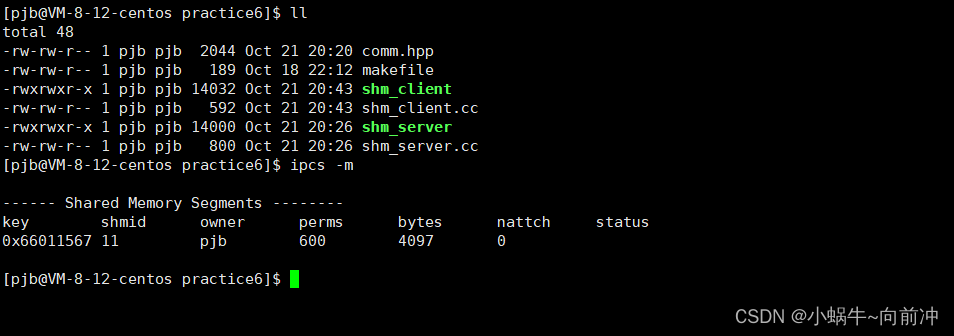
[Linux打怪升级之路]-system V共享内存
前言 作者:小蜗牛向前冲 名言:我可以接受失败,但我不能接受放弃 如果觉的博主的文章还不错的话,还请点赞,收藏,关注👀支持博主。如果发现有问题的地方欢迎❀大家在评论区指正 本期学习目标&…...
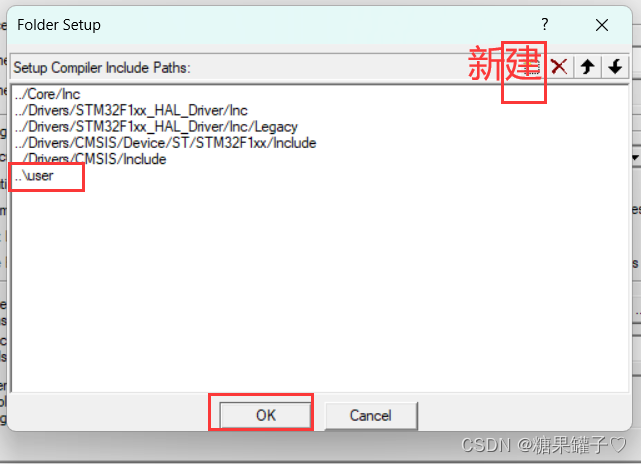
STM32不使用 cubeMX实现外部中断
这篇文章将介绍如何不使用 cubeMX完成外部中断的配置和实现。 文章目录 前言一、文件加入工程二、代码解析exti.cexti.hmain.c 注意:总结 前言 实验开发板:STM32F103C8T6。所需软件:keil5 , cubeMX 。实验目的:如何不…...
Nautilus Chain 与 Coin98 生态达成合作,加速 Zebec 生态亚洲战略进
目前,行业内首个模块化 Layer3 架构公链 Nautilus Chain 已经上线主网,揭示了模块化区块链领域迎来了全新的进程。在主网上线后,Nautilus Chain 将扮演 Zebec 生态中最重要的底层设施角色,并将为 Zebec APP 以及 Zebec Payroll 规…...
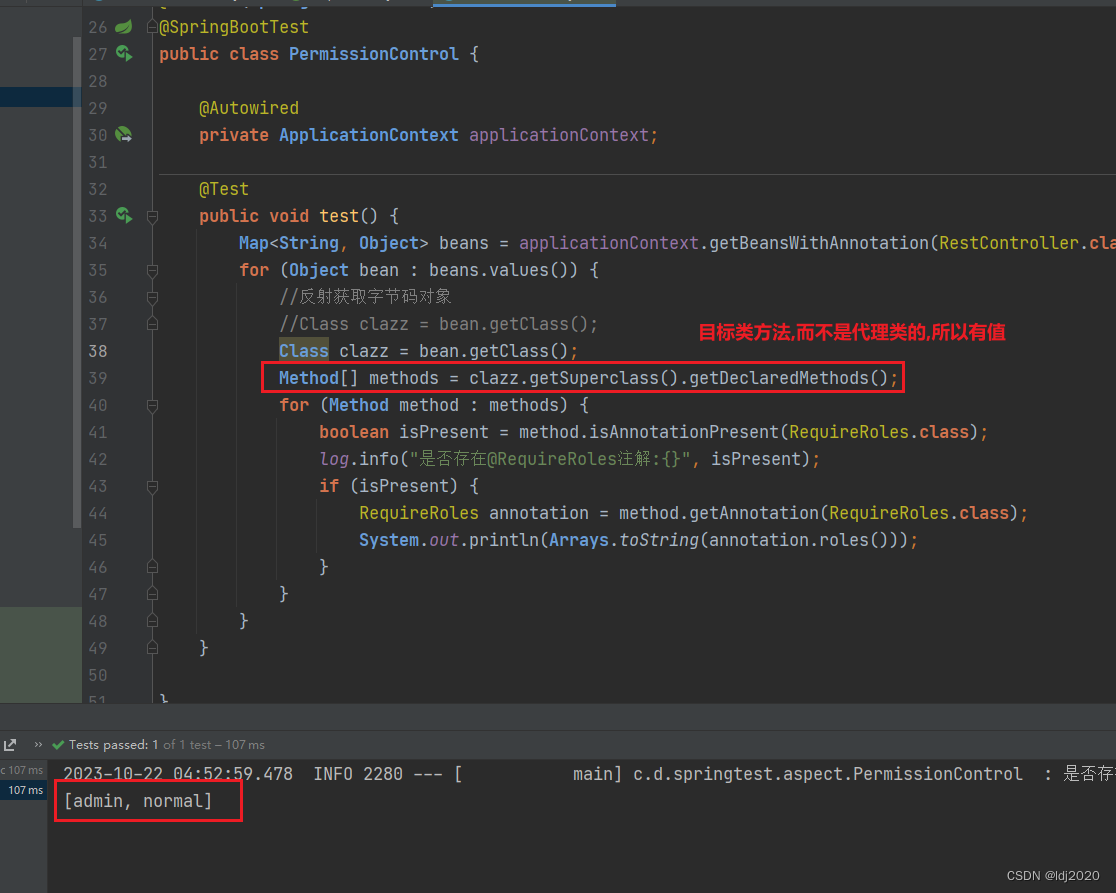
method.isAnnotationPresent(Xxx.class)一直为null
package com.dj.springtest.aspect;import com.dj.springtest.annotation.RequireRoles; import lombok.extern.slf4j.Slf4j; import org.junit.Test; import org.junit.runner.RunWith; import org.springframework.beans.factory.annotation.Autowired; import org.s…...
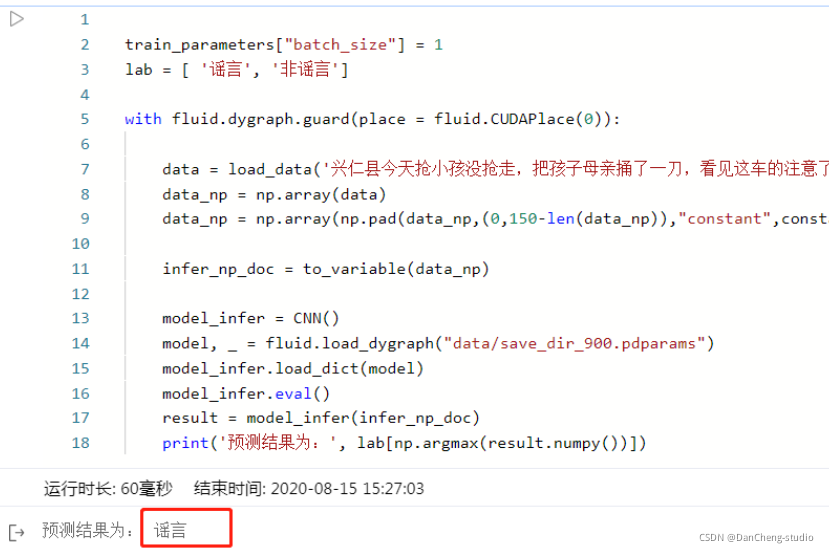
基于CNN实现谣言检测 - python 深度学习 机器学习 计算机竞赛
文章目录 1 前言1.1 背景 2 数据集3 实现过程4 CNN网络实现5 模型训练部分6 模型评估7 预测结果8 最后 1 前言 🔥 优质竞赛项目系列,今天要分享的是 基于CNN实现谣言检测 该项目较为新颖,适合作为竞赛课题方向,学长非常推荐&am…...

MySQL——七、MySQL备份恢复
MySQL 一、MySQL日志管理1、MySQL日志类型2、错误日志3、通用查询日志4、慢查询日志5、二进制日志5.1 开启日志5.2 二进制日志的管理5.3 日志查看5.4 二进制日志还原数据 二、MySQL备份1、备份类型逻辑备份优缺点 2、备份内容3、备份工具3.1 MySQL自带的备份工具3.2 文件系统备…...
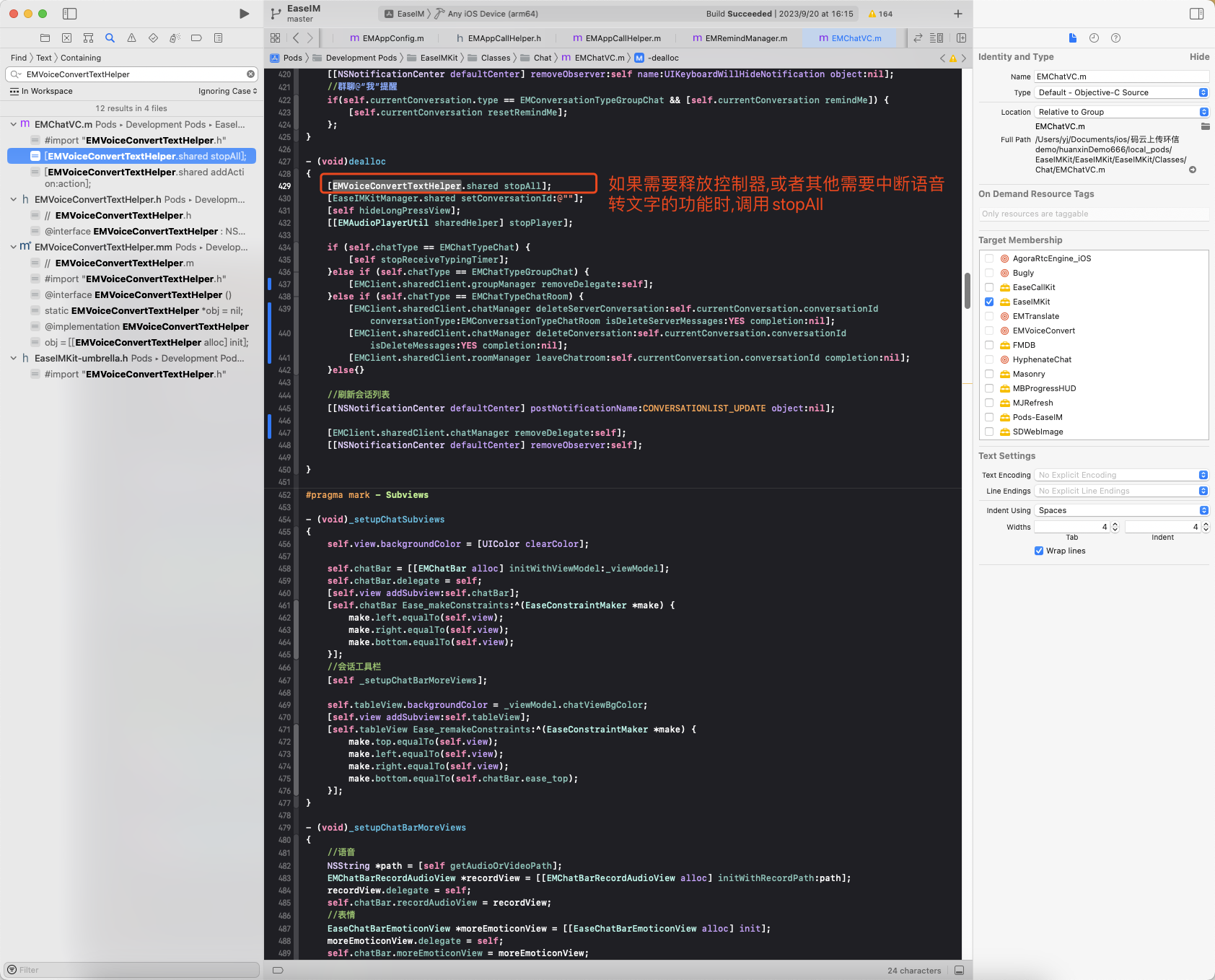
iOS如何实现语音转文字功能?
1.项目中添加权限 Privacy - Speech Recognition Usage Description : 需要语音识别权限才能实现语音转文字功能 2.添加头文件 #import <AVFoundation/AVFoundation.h> #import<Speech/Speech.h> 3.实现语音转文字逻辑: 3.1 根据wav语音文件创建请求 SFSpeechU…...
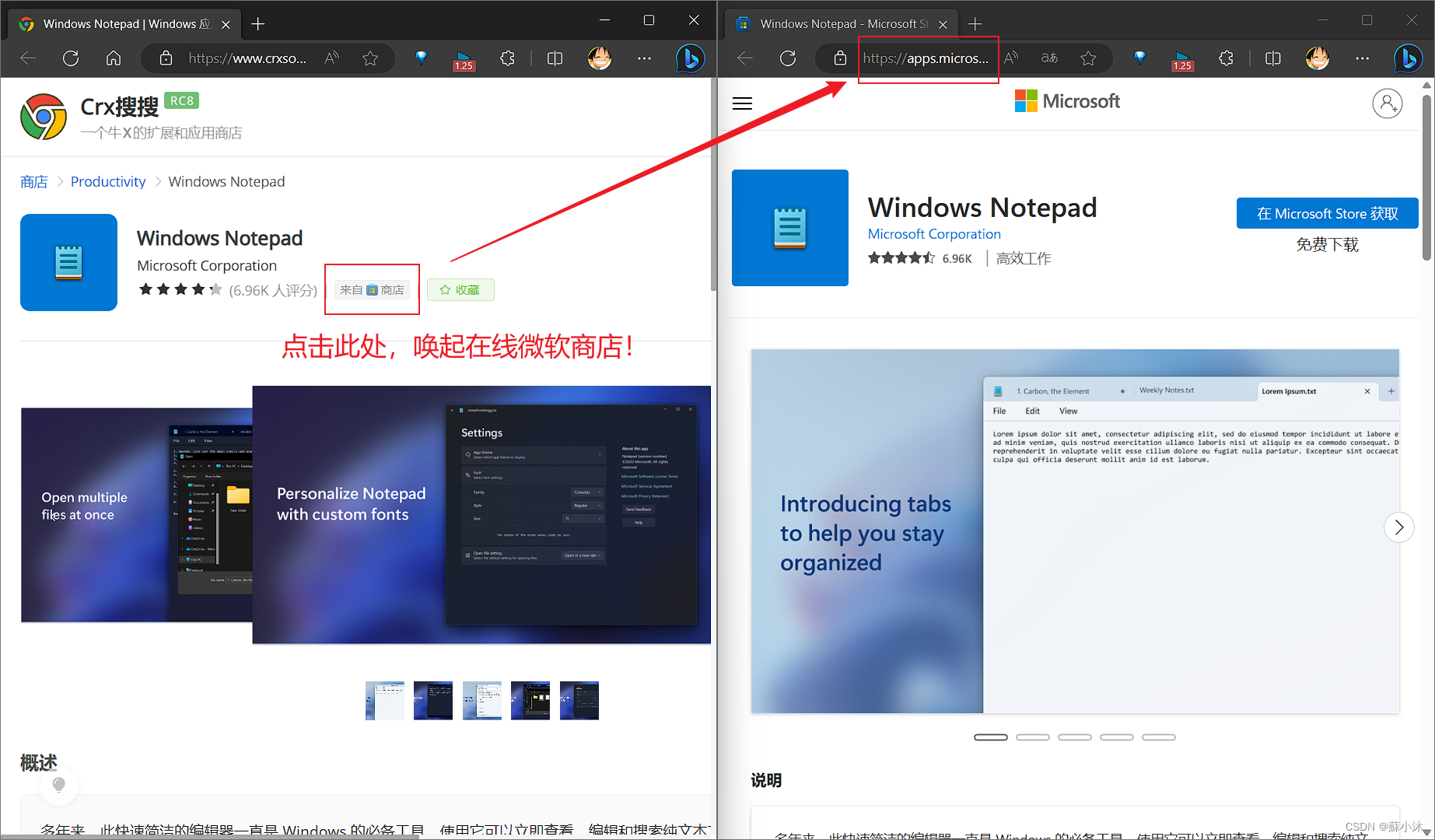
【下载器篇】获取微软应用商店应用安装包的方法
【下载器篇】获取微软应用商店应用安装包的方法 微软应用商店历史版本应用下载方法,部分历史版本无法搜索到—【蘇小沐】 文章目录 【下载器篇】获取微软应用商店应用安装包的方法1.实验环境 (一)微软商店的在线链接生成器1、复制该应用的在…...

云安全—集群攻击入口攻与防
0x00 前言 说到云安全肯定不能避免的是集群相关的内容,最出色的就是Kubernetes,也就是k8s。当然docker相关的内容也算是集群的一部分。但是docker容器本身的问题还是归属于容器本身。 0x01 概述 在集群攻击入口处的内容主要为: 应用安全恶…...
“传统”开发与AI开发的区别与联系(更新了GPT3.5的反馈)
1、传统开发的算法和软件整体,也可以看成是一个“大模型”,其中有不同层次的处理,最终能够完成从输入到输出的计算,不过,其中的计算都是人工定义的,一般依赖于研究成果的应用。研究成果在实际中的应用处理。…...
Unity 文字显示动画(2)
针对第一版的优化,自动适配文字大小,TextMeshPro可以拓展各种语言。第一版字母类语言效果更好。 using System.Collections; using System.Collections.Generic; using TMPro; using UnityEngine; using UnityEngine.UI;public partial class TextBeat…...

力扣每日一题53:最大子数组和
题目描述: 给你一个整数数组 nums ,请你找出一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。 子数组 是数组中的一个连续部分。 示例 1: 输入:nums [-2,1,-3,4,-1,2,1,…...
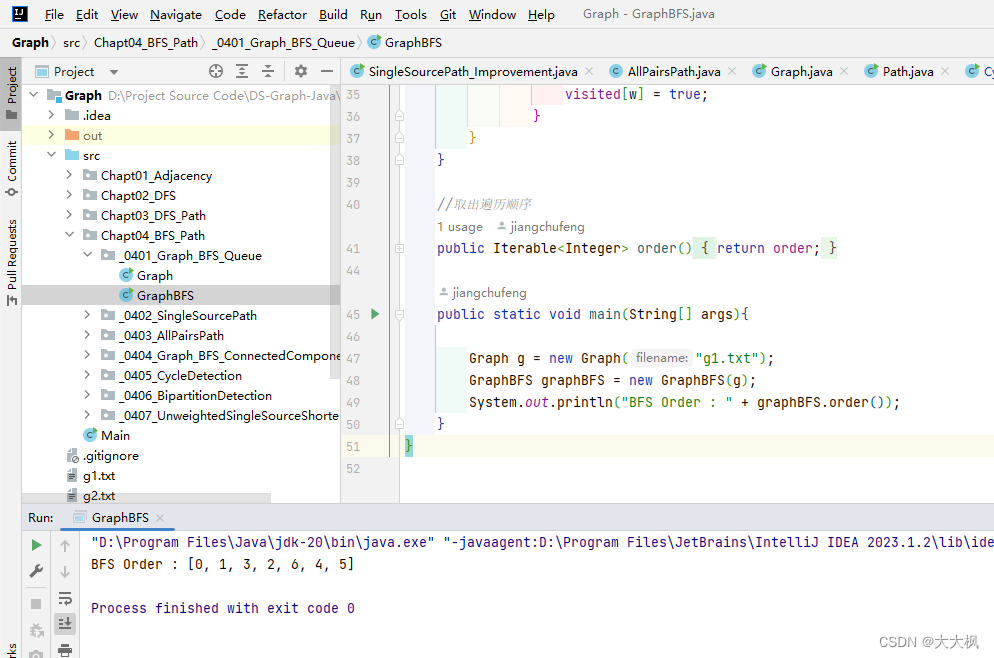
图论04-【无权无向】-图的广度优先遍历
文章目录 1. 代码仓库2. 广度优先遍历图解3.主要代码4. 完整代码 1. 代码仓库 https://github.com/Chufeng-Jiang/Graph-Theory 2. 广度优先遍历图解 3.主要代码 原点入队列原点出队列的同时,将与其相邻的顶点全部入队列下一个顶点出队列出队列的同时,将…...

layui的一些问题
为什么table.render, ins1.config有时候获取的值是上一次的?例如ins1.conf.page.curr? 这是一段table.render代码 let ins1 table.render({...})一般情况下ins1.conf可以获得表格的当前页,页数等;但是有时候获得的页数是上一次的;主要是因为在table.reload后没有继续赋值的…...
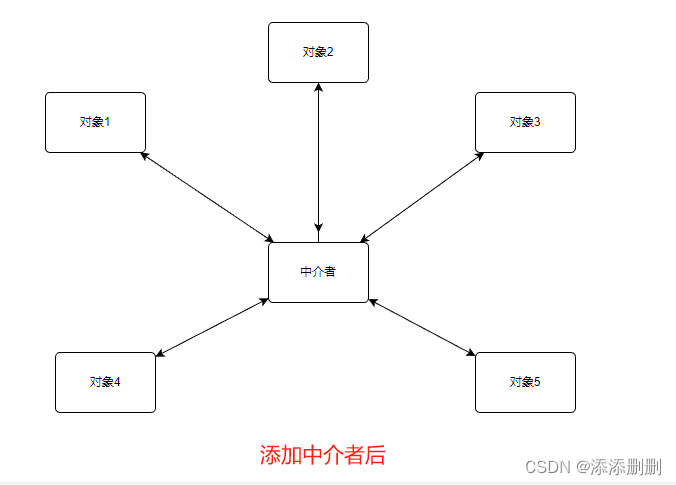
设计模式_中介者模式
中介者模式 介绍 设计模式定义案例问题堆积在哪里解决办法中介者代替了多个对象之间的互动 使对象1 2 3 之间的互动 变为: 对象1->中介 对象2->中介 对象3->中介好友之间 约饭好友1 通知 好友2 -3 -4 等等加一个群 谁想吃饭就 通知一下 类图 代码 角色 …...

3步完成Windows平台ADB和Fastboot驱动一键安装完整指南
3步完成Windows平台ADB和Fastboot驱动一键安装完整指南 【免费下载链接】Latest-adb-fastboot-installer-for-windows A Simple Android Driver installer tool for windows (Always installs the latest version) 项目地址: https://gitcode.com/gh_mirrors/la/Latest-adb-f…...

别再死磕毕业论文了!Paperxie 这波操作,把本科写作的 “坑” 全填上了
paperxie-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/期刊论文https://www.paperxie.cn/ai/dissertationhttps://www.paperxie.cn/ai/dissertation 打开论文文档,盯着空白页面发呆;选题被导师打回 N 次,改到怀疑人生…...

终极指南:如何用grepWin正则表达式工具快速搜索替换Windows文件内容
终极指南:如何用grepWin正则表达式工具快速搜索替换Windows文件内容 【免费下载链接】grepWin A powerful and fast search tool using regular expressions 项目地址: https://gitcode.com/gh_mirrors/gr/grepWin 还在为海量文件中查找特定文本而烦恼吗&…...

Adobe-GenP 3.0终极指南:如何高效解锁Adobe CC全系列软件
Adobe-GenP 3.0终极指南:如何高效解锁Adobe CC全系列软件 【免费下载链接】Adobe-GenP Adobe CC 2019/2020/2021/2022/2023 GenP Universal Patch 3.0 项目地址: https://gitcode.com/gh_mirrors/ad/Adobe-GenP 在创意设计领域,Adobe Creative Cl…...

免费开源在线PPT制作工具:浏览器中打造专业演示文稿的终极指南
免费开源在线PPT制作工具:浏览器中打造专业演示文稿的终极指南 【免费下载链接】PPTist PowerPoint-ist(/pauəpɔintist/), An online presentation application that replicates most of the commonly used features of MS PowerPoint, all…...

PowerToys中文版:让Windows效率翻倍的终极神器
PowerToys中文版:让Windows效率翻倍的终极神器 【免费下载链接】PowerToys-CN PowerToys Simplified Chinese Translation 微软增强工具箱 自制汉化 项目地址: https://gitcode.com/gh_mirrors/po/PowerToys-CN 你是否曾因Windows系统操作繁琐而烦恼…...
烧录镜像方法)
【ESP32S3】ESP32-S3 WiFi 无线 OTA(升级)烧录镜像方法
【ESP32S3】ESP32-S3 WiFi 无线 OTA(升级)烧录镜像方法一、ESP32-S3 WiFi 无线 OTA(最常用)二、Arduino 完整可运行代码三、如何生成固件并提供下载一、ESP32-S3 WiFi 无线 OTA(最常用) 原理: …...

从代码到财富:程序员的量化投资跃迁之路
《A股因子投资实战:从理论到策略实现》 推荐序言 当你计划阅读本专栏时,你可能正站在一个重要的十字路口——一边是熟悉的代码世界,另一边是充满挑战但也机遇无限的金融市场。作为程序员,你已经掌握了这个时代最重要的技能之一&am…...

别再手动写乘法器了!Vivado IP核里的Multiplier和Complex Multiplier到底怎么选?
Vivado乘法器IP核深度解析:从基础配置到高阶实战 在FPGA开发中,乘法运算作为数字信号处理的核心操作,其实现方式直接影响系统性能和资源利用率。Vivado提供的乘法器IP核家族(Multiplier和Complex Multiplier)看似简单…...

iOS设备支持文件最佳实践:跨版本调试实战指南
iOS设备支持文件最佳实践:跨版本调试实战指南 【免费下载链接】iOSDeviceSupport All versions of iOS Device Support 项目地址: https://gitcode.com/gh_mirrors/ios/iOSDeviceSupport iOS设备支持文件是企业级iOS应用开发中不可或缺的关键组件,…...