DataFrame窗口函数操作
文章最前: 我是Octopus,这个名字来源于我的中文名--章鱼;我热爱编程、热爱算法、热爱开源。所有源码在我的个人github ;这博客是记录我学习的点点滴滴,如果您对 Python、Java、AI、算法有兴趣,可以关注我的动态,一起学习,共同进步。
相关文章:
- PySpark 概述
- Spark连接快速入门
- Spark上使用pandas API快速入门
创建pyspark对象
import warnings
warnings.filterwarnings('ignore')
#import pandas as pd
#import numpy as np
from datetime import timedelta, date, datetime
import time
import gc
import os
import argparse
import sysfrom pyspark.sql import SparkSession, functions as fn
from pyspark.ml.feature import StringIndexer
from pyspark.ml.recommendation import ALS
from pyspark.sql.types import *
from pyspark import StorageLevel
spark = SparkSession \.builder \.appName("stockout_test") \.config("hive.exec.dynamic.partition.mode", "nonstrict") \.config("spark.sql.sources.partitionOverwriteMode", "dynamic")\.config("spark.driver.memory", '20g')\.config("spark.executor.memory", '40g')\.config("spark.yarn.executor.memoryOverhead", '1g')\.config("spark.executor.instances", 8)\.config("spark.executor.cores", 8)\.config("spark.kryoserializer.buffer.max", '128m')\.config("spark.yarn.queue", 'root.algo')\.config("spark.executorEnv.OMP_NUM_THREADS", 12)\.config("spark.executorEnv.ARROW_PRE_0_15_IPC_FORMAT", 1) \.config("spark.default.parallelism", 800)\.enableHiveSupport() \.getOrCreate()
spark.sql("set hive.exec.dynamic.partition.mode = nonstrict")
spark.sql("set hive.exec.dynamic.partition=true")
spark.sql("set spark.sql.autoBroadcastJoinThreshold=-1")创建DataFrame
employee_salary = [("zhangsan", "IT", 8000),("lisi", "IT", 7000),("wangwu", "IT", 7500),("zhaoliu", "ALGO", 10000),("qisan", "IT", 8000),("bajiu", "ALGO", 12000),("james", "ALGO", 11000),("wangzai", "INCREASE", 7000),("carter", "INCREASE", 8000),("kobe", "IT", 9000)]columns= ["name", "department", "salary"]
df = spark.createDataFrame(data = employee_salary, schema = columns)
df.show()+--------+----------+------+ | name|department|salary| +--------+----------+------+ |zhangsan| IT| 8000| | lisi| IT| 7000| | wangwu| IT| 7500| | zhaoliu| ALGO| 10000| | qisan| IT| 8000| | bajiu| ALGO| 12000| | james| ALGO| 11000| | wangzai| INCREASE| 7000| | carter| INCREASE| 8000| | kobe| IT| 9000| +--------+----------+------+
row_number()
from pyspark.sql.window import Window
import pyspark.sql.functions as FwindowSpec = Window.partitionBy("department").orderBy(F.desc("salary"))
df.withColumn("row_number", F.row_number().over(windowSpec)).show(truncate=False)+--------+----------+------+----------+ |name |department|salary|row_number| +--------+----------+------+----------+ |carter |INCREASE |8000 |1 | |wangzai |INCREASE |7000 |2 | |kobe |IT |9000 |1 | |zhangsan|IT |8000 |2 | |qisan |IT |8000 |3 | |wangwu |IT |7500 |4 | |lisi |IT |7000 |5 | |bajiu |ALGO |12000 |1 | |james |ALGO |11000 |2 | |zhaoliu |ALGO |10000 |3 | +--------+----------+------+----------+
Rank()
from pyspark.sql.window import Window
import pyspark.sql.functions as FwindowSpec = Window.partitionBy("department").orderBy(F.desc("salary"))
df.withColumn("rank",F.rank().over(windowSpec)).show(truncate=False)+--------+----------+------+----+ |name |department|salary|rank| +--------+----------+------+----+ |carter |INCREASE |8000 |1 | |wangzai |INCREASE |7000 |2 | |kobe |IT |9000 |1 | |qisan |IT |8000 |2 | |zhangsan|IT |8000 |2 | |wangwu |IT |7500 |4 | |lisi |IT |7000 |5 | |bajiu |ALGO |12000 |1 | |james |ALGO |11000 |2 | |zhaoliu |ALGO |10000 |3 | +--------+----------+------+----+
dense_rank()
from pyspark.sql.window import Window
import pyspark.sql.functions as FwindowSpec = Window.partitionBy("department").orderBy(F.desc("salary"))
df.withColumn("dense_rank",F.dense_rank().over(windowSpec)).show()+--------+----------+------+----------+ | name|department|salary|dense_rank| +--------+----------+------+----------+ | carter| INCREASE| 8000| 1| | wangzai| INCREASE| 7000| 2| | kobe| IT| 9000| 1| | qisan| IT| 8000| 2| |zhangsan| IT| 8000| 2| | wangwu| IT| 7500| 3| | lisi| IT| 7000| 4| | bajiu| ALGO| 12000| 1| | james| ALGO| 11000| 2| | zhaoliu| ALGO| 10000| 3| +--------+----------+------+----------+
lag()
from pyspark.sql.window import Window
import pyspark.sql.functions as FwindowSpec = Window.partitionBy("department").orderBy(F.desc("salary"))
df.withColumn("lag",F.lag("salary",1).over(windowSpec)).show()+--------+----------+------+-----+ | name|department|salary| lag| +--------+----------+------+-----+ | carter| INCREASE| 8000| null| | wangzai| INCREASE| 7000| 8000| | kobe| IT| 9000| null| |zhangsan| IT| 8000| 9000| | qisan| IT| 8000| 8000| | wangwu| IT| 7500| 8000| | lisi| IT| 7000| 7500| | bajiu| ALGO| 12000| null| | james| ALGO| 11000|12000| | zhaoliu| ALGO| 10000|11000| +--------+----------+------+-----+
lead()
from pyspark.sql.window import Window
import pyspark.sql.functions as FwindowSpec = Window.partitionBy("department").orderBy(F.desc("salary"))
df.withColumn("lead",F.lead("salary", 1).over(windowSpec)).show()+--------+----------+------+-----+ | name|department|salary| lead| +--------+----------+------+-----+ | carter| INCREASE| 8000| 7000| | wangzai| INCREASE| 7000| null| | kobe| IT| 9000| 8000| |zhangsan| IT| 8000| 8000| | qisan| IT| 8000| 7500| | wangwu| IT| 7500| 7000| | lisi| IT| 7000| null| | bajiu| ALGO| 12000|11000| | james| ALGO| 11000|10000| | zhaoliu| ALGO| 10000| null| +--------+----------+------+-----+
Aggregate Functions
from pyspark.sql.window import Window
import pyspark.sql.functions as FwindowSpec = Window.partitionBy("department").orderBy(F.desc("salary"))
windowSpecAgg = Window.partitionBy("department")df.withColumn("row", F.row_number().over(windowSpec)) \.withColumn("avg", F.avg("salary").over(windowSpecAgg)) \.withColumn("sum", F.sum("salary").over(windowSpecAgg)) \.withColumn("min", F.min("salary").over(windowSpecAgg)) \.withColumn("max", F.max("salary").over(windowSpecAgg)) \.withColumn("count", F.count("salary").over(windowSpecAgg)) \.withColumn("distinct_count", F.approx_count_distinct("salary").over(windowSpecAgg)) \.show()+--------+----------+------+---+-------+-----+-----+-----+-----+--------------+ | name|department|salary|row| avg| sum| min| max|count|distinct_count| +--------+----------+------+---+-------+-----+-----+-----+-----+--------------+ | carter| INCREASE| 8000| 1| 7500.0|15000| 7000| 8000| 2| 2| | wangzai| INCREASE| 7000| 2| 7500.0|15000| 7000| 8000| 2| 2| | kobe| IT| 9000| 1| 7900.0|39500| 7000| 9000| 5| 4| |zhangsan| IT| 8000| 2| 7900.0|39500| 7000| 9000| 5| 4| | qisan| IT| 8000| 3| 7900.0|39500| 7000| 9000| 5| 4| | wangwu| IT| 7500| 4| 7900.0|39500| 7000| 9000| 5| 4| | lisi| IT| 7000| 5| 7900.0|39500| 7000| 9000| 5| 4| | bajiu| ALGO| 12000| 1|11000.0|33000|10000|12000| 3| 3| | james| ALGO| 11000| 2|11000.0|33000|10000|12000| 3| 3| | zhaoliu| ALGO| 10000| 3|11000.0|33000|10000|12000| 3| 3| +--------+----------+------+---+-------+-----+-----+-----+-----+--------------+
from pyspark.sql.window import Window
import pyspark.sql.functions as F
# 需要注意的是 approx_count_distinct() 函数适用于窗函数的统计,
# 而在groupby中通常用countDistinct()来代替该函数,用来求组内不重复的数值的条数。
# approx_count_distinct()取的是近似的数值,不太准确,使用需注意 windowSpec = Window.partitionBy("department").orderBy(F.desc("salary"))
windowSpecAgg = Window.partitionBy("department")df.withColumn("row", F.row_number().over(windowSpec)) \.withColumn("avg", F.avg("salary").over(windowSpecAgg)) \.withColumn("sum", F.sum("salary").over(windowSpecAgg)) \.withColumn("min", F.min("salary").over(windowSpecAgg)) \.withColumn("max", F.max("salary").over(windowSpecAgg)) \.withColumn("count", F.count("salary").over(windowSpecAgg)) \.withColumn("distinct_count", F.approx_count_distinct("salary").over(windowSpecAgg)) \.where(F.col("row")==1).select("department","avg","sum","min","max","count","distinct_count") \.show()+----------+-------+-----+-----+-----+-----+--------------+ |department| avg| sum| min| max|count|distinct_count| +----------+-------+-----+-----+-----+-----+--------------+ | INCREASE| 7500.0|15000| 7000| 8000| 2| 2| | IT| 7900.0|39500| 7000| 9000| 5| 4| | ALGO|11000.0|33000|10000|12000| 3| 3| +----------+-------+-----+-----+-----+-----+--------------+
相关文章:

DataFrame窗口函数操作
文章最前: 我是Octopus,这个名字来源于我的中文名--章鱼;我热爱编程、热爱算法、热爱开源。所有源码在我的个人github ;这博客是记录我学习的点点滴滴,如果您对 Python、Java、AI、算法有兴趣,可以关注我的…...

【德哥说库系列】-RHEL8环境源码编译安装MySQL8.0
📢📢📢📣📣📣 哈喽!大家好,我是【IT邦德】,江湖人称jeames007,10余年DBA及大数据工作经验 一位上进心十足的【大数据领域博主】!😜&am…...

Sandboxie+Buster Sandbox Analyzer打造个人沙箱
一、运行环境和需要安装的软件 实验环境:win7_x32或win7_x64 用到的软件:WinPcap_4_1_3.exe、Sandboxie-3-70.exe、Buster Sandbox Analyzer 重点是Sandboxie必须是3.70版本。下载地址:https://github.com/sandboxie-plus/sandboxie-old/blo…...

源码解析flink的GenericWriteAheadSink为什么做不到精确一次输出
背景 GenericWriteAheadSink是可以用于几乎是精准一次输出的场景,为什么说是几乎精准一次呢?我们从源码的角度分析一下 GenericWriteAheadSink做不到精准一次输出的原因 首先我们看一下flink检查点完成后通知GenericWriteAheadSink开始进行分段的记录…...
)
C#经典十大排序算法(完结)
C#冒泡排序算法 简介 冒泡排序算法是一种基础的排序算法,它的实现原理比较简单。核心思想是通过相邻元素的比较和交换来将最大(或最小)的元素逐步"冒泡"到数列的末尾。 详细文章描述 https://mp.weixin.qq.com/s/z_LPZ6QUFNJcw…...

C/C++文件操作(细节满满,part2)
该文章上一篇:C/C文件操作(细节满满,part1)_仍有未知等待探索的博客-CSDN博客 个人主页:仍有未知等待探索_C语言疑难,数据结构,小项目-CSDN博客 专题分栏:C语言疑难_仍有未知等待探索的博客-CSDN博客 目录 …...
web前端面试-- 手写原生Javascript方法(new、Object.create)
web面试题 本人是一个web前端开发工程师,主要是vue框架,整理了一些面试题,今后也会一直更新,有好题目的同学欢迎评论区分享 ;-) web面试题专栏:点击此处 手动实现Object.create 通过Object.create&#…...

C++前缀和算法的应用:得到连续 K 个 1 的最少相邻交换次数 原理源码测试用例
本文涉及的基础知识点 C算法:前缀和、前缀乘积、前缀异或的原理、源码及测试用例 包括课程视频 滑动窗口 题目 给你一个整数数组 nums 和一个整数 k 。 nums 仅包含 0 和 1 。每一次移动,你可以选择 相邻 两个数字并将它们交换。 请你返回使 nums 中包…...

目标检测YOLO实战应用案例100讲-基于YOLOv5的航拍图像旋转目标检测
目录 前言 国内外研究历史与现状 目标检测技术的研究历史与现状...
H5前端开发——BOM
H5前端开发——BOM BOM(Browser Object Model)是指浏览器对象模型,它提供了一组对象和方法,用于与浏览器窗口进行交互。 通过 BOM 对象,开发人员可以操作浏览器窗口的行为和状态,实现与用户的交互和数据传…...

stable diffusion如何解决gradio外链无法开启的问题
问题确认 为了确认gradio开启不了是gradio库的问题还是stable diffusion的问题,可以先执行这样一段demo代码 import gradio as grdef greet(name):return "Hello " name "!"demo gr.Interface(fngreet, inputs"text", outputs&q…...

SpringMvc-面试用
一、SpringMvc常用注解 1、修饰在类的 RestController RequestMapping("/test")RestController是什么?其实是一个复合注解 Controller //其实就是Component ResponseBody //独立的注解 public interface RestController {}RequestMapping 也可以认…...

并发编程 # 3
文章目录 一、进程和线程的比较二、GIL全局解释器锁1.引入2.Python解释器的种类结论:在CPython解释其中,同一个进程下开启的多线程,同一时刻只能有一个线程执行,无法利用多核优势。得出结论:GIL锁就是保证在同一时刻只…...

ESP32C3 LuatOS TM1650①驱动测试
合宙TM1650驱动资料 TM1650.lua源码 引脚连接 TM1650ESP32C3SCLGPIO5SDAGPIO4 下载TM1650.lua源码,并以文件形式保存在项目文件夹中 驱动测试源码 --注意:因使用了sys.wait()所有api需要在协程中使用 -- 用法实例 PROJECT "ESP32C3_TM1650" VERSION …...

TCP为什么需要三次握手和四次挥手?
一、三次握手 三次握手(Three-way Handshake)其实就是指建立一个TCP连接时,需要客户端和服务器总共发送3个包 主要作用就是为了确认双方的接收能力和发送能力是否正常、指定自己的初始化序列号为后面的可靠性传送做准备 过程如下ÿ…...
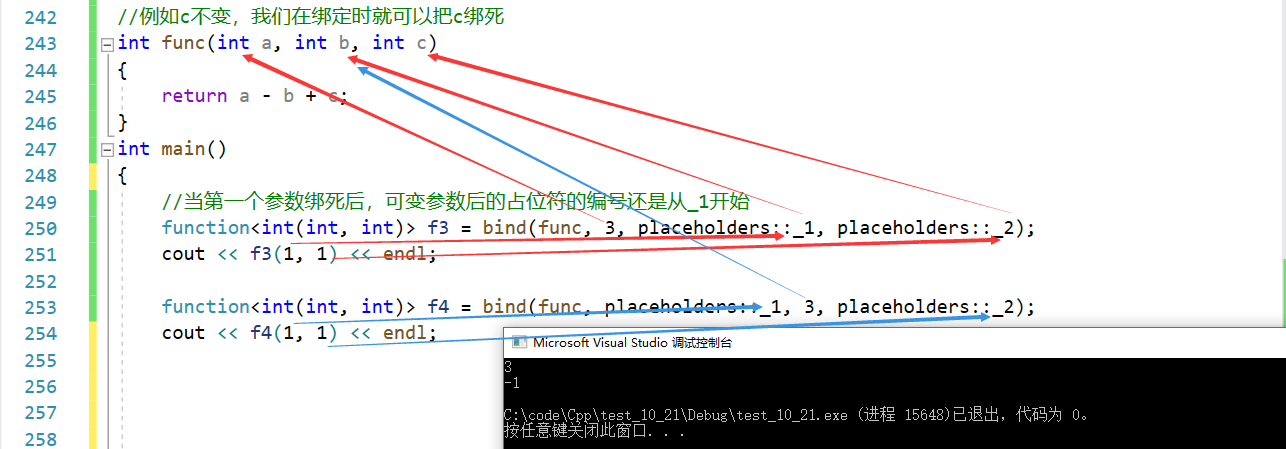
【C++】一些C++11特性
C特性 1. 列表初始化1.1 {}初始化1.2 initializer_list 2. 声明2.1 auto2.2 typeid2.3 decltype2.4 nullptr 3. STL3.1 新容器3.2 新接口 4. 右值引用5. 移动构造与移动赋值6. lambda表达式7. 可变参数模板8. 包装器9. bind 1. 列表初始化 1.1 {}初始化 C11支持所有内置类型和…...

leetcode 647. 回文子串、516. 最长回文子序列
647. 回文子串 给你一个字符串 s ,请你统计并返回这个字符串中 回文子串 的数目。 回文字符串 是正着读和倒过来读一样的字符串。 子字符串 是字符串中的由连续字符组成的一个序列。 具有不同开始位置或结束位置的子串,即使是由相同的字符组成&#…...

Vue Router 刷新当前页面
Vue项目, 在实际工作中, 有些时候需要在 加载完某些数据之后对当前页面进行刷新, 以期 onMounted 等生命周期函数, 或者 数据重新加载. 总之是期望页面可以重新加载一次. 目前总结有三种途径可实现以上需求: 一, reload 直接刷新页面 window.location.reload(); $router.go(…...

lstm 回归实战、 分类demo
预备知识 lstm 参数 输入、输出格式 nn.LSTM(input_dim,hidden_dim,num_layers); imput_dim 特征数 input:(样本数、seq, features_num) h0,c0 (num_layers,seq, hidden_num) output: (样本数、seq, hidden_dim) 再加一个全连接层,将 outpu…...

实践DDD模拟电商系统总结
目录 一、事件风暴 二、系统用例 三、领域上下文 四、架构设计 (一)六边形架构 (二)系统分层 五、系统实现 (一)项目结构 (二)提交订单功能实现 (三࿰…...

3分钟突破百度网盘密码屏障:baidupankey终极解决方案
3分钟突破百度网盘密码屏障:baidupankey终极解决方案 【免费下载链接】baidupankey 项目地址: https://gitcode.com/gh_mirrors/ba/baidupankey 你是否曾在百度网盘资源面前束手无策?当急需的学习资料、工作文件或娱乐资源就在眼前,却…...

终极指南:如何一键恢复B站经典界面,重温小电视播放器的美好时代
终极指南:如何一键恢复B站经典界面,重温小电视播放器的美好时代 【免费下载链接】Bilibili-Old 恢复旧版Bilibili页面,为了那些念旧的人。 项目地址: https://gitcode.com/gh_mirrors/bi/Bilibili-Old 你是否怀念那个简洁明了的B站界面…...

**发散创新:基于Go语言的日志指标采集与可视化实战**在现代分布式系统中,**日志 + 指标*
发散创新:基于Go语言的日志指标采集与可视化实战 在现代分布式系统中,日志 指标已成为运维监控的核心支柱。如何高效地从服务中提取关键指标(如请求耗时、错误率、QPS),并将其结构化存储用于后续分析?本文…...

终极指南:Navicat Premium macOS版无限试用重置脚本完全解析
终极指南:Navicat Premium macOS版无限试用重置脚本完全解析 【免费下载链接】navicat_reset_mac navicat mac版无限重置试用期脚本 Navicat Mac Version Unlimited Trial Reset Script 项目地址: https://gitcode.com/gh_mirrors/na/navicat_reset_mac 对于…...

思源宋体TTF字体:7种字重的中文排版技术方案
思源宋体TTF字体:7种字重的中文排版技术方案 【免费下载链接】source-han-serif-ttf Source Han Serif TTF 项目地址: https://gitcode.com/gh_mirrors/so/source-han-serif-ttf 在中文数字内容创作中,字体选择直接影响用户体验和视觉传达效果。思…...

从代码到天空:深入APM飞控的`AP_Arming.cpp`,看它如何守护你的无人机第一道安全防线
从代码到天空:深入APM飞控的AP_Arming.cpp,看它如何守护你的无人机第一道安全防线 当遥控器的摇杆被推向解锁位置时,无人机并非立即响应这个动作。在电机真正开始旋转前的毫秒级瞬间,飞控系统正执行着数十项精密的安全检查。这些隐…...

Qt Creator + GitHub Copilot 深度集成指南:解锁C++/Qt开发的AI生产力
1. 为什么你需要Qt Creator和GitHub Copilot这对黄金搭档 作为一个C/Qt开发者,我深知在UI设计、信号槽连接和业务逻辑编写这些日常工作中,重复性的代码编写有多让人头疼。直到我遇到了GitHub Copilot这个AI编程助手,配合Qt Creator使用后&…...

避开Fluent计算崩溃:用这3种网格划分策略彻底解决floating error问题
避开Fluent计算崩溃:3种网格划分策略彻底解决floating error问题 在CFD仿真工程师的日常工作中,没有什么比看到"floating point error"这个报错更令人沮丧的了。这个看似简单的错误提示背后,往往隐藏着复杂的数值计算问题。根据我们…...

番茄小说下载器完整教程:5步打造永不消失的个人数字图书馆
番茄小说下载器完整教程:5步打造永不消失的个人数字图书馆 【免费下载链接】fanqienovel-downloader 下载番茄小说 项目地址: https://gitcode.com/gh_mirrors/fa/fanqienovel-downloader 你是否曾经为心爱的小说突然下架而心痛?是否因为网络信号…...

如何快速掌握LRC歌词制作:面向初学者的完整指南
如何快速掌握LRC歌词制作:面向初学者的完整指南 【免费下载链接】lrc-maker 歌词滚动姬|可能是你所能见到的最好用的歌词制作工具 项目地址: https://gitcode.com/gh_mirrors/lr/lrc-maker LRC Maker是一款免费开源的歌词制作工具,专为…...