使用 ClickHouse 深入了解 Apache Parquet (一)
【squids.cn】 全网zui低价RDS,免费的迁移工具DBMotion、数据库备份工具DBTwin、SQL开发工具等
自2013年作为Hadoop的列存储发布以来,Parquet几乎已经成为一种无处不在的文件交换格式,它提供了高效的存储和检索。这种采纳使其成为更近期的数据湖格式的基础,例如Apache Iceberg。在这个博客系列中,我们探讨如何使用ClickHouse读写这种格式,然后更详细地深入了解Parquet。对于更有经验的Parquet用户,我们还讨论了用户在使用ClickHouse编写Parquet文件时可以进行的一些优化,以最大化压缩,以及一些最近的开发,以使用并行化优化读取性能。
在我们的示例中,我们使用了英国房价数据集。这包含了从1995年到写作时的英格兰和威尔士的房地产价格支付数据。我们在公共s3桶s3://datasets-documentation/uk-house-prices/parquet/中以Parquet格式分发这些数据。
ClickHouse 本地版
在我们的示例中,我们使用本地和S3托管的Parquet文件,并使用ClickHouse本地版对其进行查询。ClickHouse本地版是ClickHouse的一个易于使用的版本,非常适合需要在本地和远程文件上使用SQL进行快速处理而不必安装完整的数据库服务器的开发人员。为了使用您的笔记本电脑或工作站上的本地计算资源进行数据分析而设计并优化,用户可以使用仅使用SQL且无需编写一行Python代码的方式查询、筛选和转换几乎任何格式的数据文件。我们建议查看这篇最近的博客文章,以了解这个工具的功能概述。最重要的是,ClickHouse本地版和ClickHouse服务器对于Parquet的读写使用相同的代码,因此任何解释都适用于两者。
什么是Parquet?
Apache Parquet的官方描述为我们提供了一个关于其设计和属性的出色概述:“Apache Parquet是一个开源的、面向列的数据文件格式,旨在实现高效的数据存储和检索。”
与ClickHouse的MergeTree格式类似,数据是面向列存储的。这实际上意味着同一列的值存储在一起,与面向行的文件格式(例如,Avro)形成对比,后者的行数据是共同存放的。
这种数据方向,加上支持多种适合现代处理器管道的编码技术,允许实现高压缩率和高效存储属性。列方向还最大限度地减少了读取的数据量,因为只从存储中读取必要的列以进行分组等分析查询。当与高压缩率和每列提供的内部统计数据(存储为元数据)结合时,Parquet还承诺快速检索。
这后一个属性在很大程度上取决于完全利用元数据、任何查询引擎中的并行化程度,以及存储数据时所做的决策。我们将在下面讨论与ClickHouse的关系。
在我们深入了解Parquet的内部结构之前,我们将介绍ClickHouse如何支持写入和读取这种格式。
使用ClickHouse查询Parquet
在下面的示例中,我们假设我们的房价数据已导出到一个名为house_prices.parquet的文件,并使用ClickHouse Local进行查询,除非另有说明。
读取模式
可以使用DESCRIBE语句和文件表函数来识别任何文件的模式:
DESCRIBE TABLE file('house_prices.parquet')┌─name──────┬─type─────────────┬│ price │ Nullable(UInt32) ││ date │ Nullable(UInt16) ││ postcode1 │ Nullable(String) ││ postcode2 │ Nullable(String) ││ type │ Nullable(Int8) ││ is_new │ Nullable(UInt8) ││ duration │ Nullable(Int8) ││ addr1 │ Nullable(String) ││ addr2 │ Nullable(String) ││ street │ Nullable(String) ││ locality │ Nullable(String) ││ town │ Nullable(String) ││ district │ Nullable(String) ││ county │ Nullable(String) |└───────────┴──────────────────┴
查询本地文件
上述文件表功能可作为SELECT查询的输入,允许我们执行对Parquet文件的查询。下面,我们计算伦敦房产每年的平均价格。
SELECTtoYear(toDate(date)) AS year,round(avg(price)) AS price,bar(price, 0, 2000000, 100)FROM file('house_prices.parquet')WHERE town = 'LONDON'GROUP BY yearORDER BY year ASC┌─year─┬───price─┬─bar(round(avg(price)), 0, 2000000, 100)──────────────┐│ 1995 │ 109120 │ █████▍ ││ 1996 │ 118672 │ █████▉ ││ 1997 │ 136530 │ ██████▊ ││ 1998 │ 153014 │ ███████▋ ││ 1999 │ 180639 │ █████████ ││ 2000 │ 215860 │ ██████████▊ ││ 2001 │ 232998 │ ███████████▋ ││ 2002 │ 263690 │ █████████████▏ ││ 2003 │ 278423 │ █████████████▉ ││ 2004 │ 304666 │ ███████████████▏ ││ 2005 │ 322886 │ ████████████████▏ ││ 2006 │ 356189 │ █████████████████▊ ││ 2007 │ 404065 │ ████████████████████▏ ││ 2008 │ 420741 │ █████████████████████ ││ 2009 │ 427767 │ █████████████████████▍ ││ 2010 │ 480329 │ ████████████████████████ ││ 2011 │ 496293 │ ████████████████████████▊ ││ 2012 │ 519473 │ █████████████████████████▉ ││ 2013 │ 616182 │ ██████████████████████████████▊ ││ 2014 │ 724107 │ ████████████████████████████████████▏ ││ 2015 │ 792274 │ ███████████████████████████████████████▌ ││ 2016 │ 843685 │ ██████████████████████████████████████████▏ ││ 2017 │ 983673 │ █████████████████████████████████████████████████▏ ││ 2018 │ 1016702 │ ██████████████████████████████████████████████████▊ ││ 2019 │ 1041915 │ ████████████████████████████████████████████████████ ││ 2020 │ 1060936 │ █████████████████████████████████████████████████████││ 2021 │ 968152 │ ████████████████████████████████████████████████▍ ││ 2022 │ 967439 │ ████████████████████████████████████████████████▎ ││ 2023 │ 830317 │ █████████████████████████████████████████▌ │└──────┴─────────┴──────────────────────────────────────────────────────┘29 rows in set. Elapsed: 0.625 sec. Processed 28.11 million rows, 750.65 MB (44.97 million rows/s., 1.20 GB/s.)
查询S3上的文件
虽然上述文件功能可以与ClickHouse服务器实例一起使用,但它要求文件存在于配置的user_files_path目录下的服务器文件系统上。在这些情况下,Parquet文件更自然地从S3读取。这在数据湖使用案例中是一个常见的需求,需要进行即席分析。在这种情况下,上述文件功能可以用s3功能替代,用于类似AWS Athena的查询:
SELECTtoYear(toDate(date)) AS year,round(avg(price)) AS price,bar(price, 0, 2000000, 100)
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/uk-house-prices/parquet/house_prices_all.parquet')
WHERE town = 'LONDON'
GROUP BY year
ORDER BY year ASC┌─year─┬───price─┬─bar(round(avg(price)), 0, 2000000, 100)───────────────┐
│ 1995 │ 109120 │ █████▍ │
│ 1996 │ 118672 │ █████▉ │
│ 1997 │ 136530 │ ██████▊ │
│ 1998 │ 153014 │ ███████▋ │
│ 1999 │ 180639 │ █████████ │...29 rows in set. Elapsed: 2.069 sec. Processed 28.11 million rows, 750.65 MB (13.59 million rows/s., 362.87 MB/s.)查询多个文件
这两个功能都支持通配符模式,允许选择文件的子集。正如我们稍后将讨论的,这不仅仅提供了跨文件查询的优势 - 主要是读取的并行化。下面我们将查询限制在所有带有年份后缀的house_prices_文件上 - 这假设我们每年有一个文件(见下文)。
SELECTtoYear(toDate(date)) AS year,round(avg(price)) AS price,bar(price, 0, 2000000, 100)
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/uk-house-prices/parquet/house_prices_{1..2}*.parquet')
WHERE town = 'LONDON'
GROUP BY year
ORDER BY year ASC29 rows in set. Elapsed: 3.387 sec. Processed 28.11 million rows, 750.65 MB (8.30 million rows/s., 221.66 MB/s.)用户还应该了解s3Cluster功能,该功能允许从集群中的多个节点并行处理文件 - 尤其与ClickHouse Cloud用户相关。在需要读取许多文件的情况下,这可以提供显著的性能优势(允许工作分布)。
用ClickHouse写Parquet
在ClickHouse中将表数据写入Parquet文件可以通过几种方式实现。这里的首选选项通常取决于你是使用ClickHouse Server还是ClickHouse Local。在下面的示例中,我们假设uk_price_paid表已经填充了数据。关于加载这些数据的详细信息,请看这里。
写本地文件
使用INTO FUNCTION子句,我们可以使用与读取相同的文件函数写parquet。这最适合于ClickHouse Local,文件可以写入本地文件系统的任何位置。ClickHouse服务器将它们写入由配置参数user_files_path指定的目录。
INSERT INTO FUNCTION file('house_prices.parquet') SELECT *
FROM uk_price_paid0 rows in set. Elapsed: 12.490 sec. Processed 28.11 million rows, 1.32 GB (2.25 million rows/s., 105.97 MB/s.)dalemcdiarmid@dales-mac houseprices % ls -lh house_prices.parquet
-rw-r----- 1 dalemcdiarmid staff 243M 17 Apr 16:59 house_prices.parquet在大多数情况下,包括 ClickHouse Cloud,本地服务器文件系统是不可访问的。在这些情况下,用户可以通过连接clickhouse-client并利用 INTO OUTFILE 子句将 parquet 文件写入客户端的文件系统。此处将根据文件扩展名自动检测所需的输出格式。
SELECT *
FROM uk_price_paid
INTO OUTFILE 'house_prices.parquet'28113076 rows in set. Elapsed: 15.690 sec. Processed 28.11 million rows, 2.47 GB (1.79 million rows/s., 157.47 MB/s.)clickhouse@clickhouse-mac ~ % ls -lh house_prices.parquet
-rw-r--r-- 1 dalemcdiarmid staff 291M 17 Apr 18:23 house_prices.parquet或者,用户可以简单地发出 SELECT 查询,指定输出格式为 Parquet,并将结果重定向到文件。在这个例子中,我们将--query参数从终端传递给客户端。
clickhouse@clickhouse-mac ~ % ./clickhouse client --query "SELECT * FROM uk_price_paid FORMAT Parquet" > house_price.parquet最后两种方法产生的文件比我们之前的文件函数方法稍大。我们将在本系列的第 2 部分中解释原因,但目前建议用户尽可能使用早期的INSERT INTO FUNCTION方法以获得更佳的尺寸。
将文件写入S3
通常,客户端存储是有限的。在这些情况下,用户可能希望将文件写入对象存储,例如 S3 和 GCS。这些都通过用于读取的相同s3 函数来支持。请注意,需要凭证 - 在下面的示例中,我们将它们作为函数参数传递,但也支持 IAM 凭证。
INSERT INTO FUNCTION s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/uk-house-prices/parquet/house_prices_sample.parquet', '<aws_access_key_id>', '<aws_secret_access_key>') SELECT *
FROM uk_price_paid
LIMIT 10000 rows in set. Elapsed: 0.726 sec. Processed 2.00 thousand rows, 987.86 KB (2.75 thousand rows/s., 1.36 MB/s.)写入多个文件
最后,通常需要限制任何单个 Parquet 文件的大小。为了帮助写入文件,用户可以将 PARTITION BY 子句与该INTO FUNCTION子句结合使用。它接受任何 SQL 表达式来为结果集中的每一行创建分区 id。parition_id反过来,这可以在文件路径中使用,以确保将行分配给不同的文件。在下面的示例中,我们按年份进行分区。因此,同一年的房屋销售情况将写入同一文件。文件将以其各自的年份作为后缀,如图所示。
INSERT INTO FUNCTION file('house_prices_{_partition_id}.parquet') PARTITION BY toYear(date) SELECT * FROM uk_price_paid0 rows in set. Elapsed: 23.281 sec. Processed 28.11 million rows, 1.32 GB (1.21 million rows/s., 56.85 MB/s.)clickhouse@clickhouse-mac houseprices % ls house_prices_*
house_prices_1995.parquet house_prices_2001.parquet house_prices_2007.parquet house_prices_2013.parquet house_prices_2019.parquet
house_prices_1996.parquet house_prices_2002.parquet house_prices_2008.parquet house_prices_2014.parquet house_prices_2020.parquet
house_prices_1997.parquet house_prices_2003.parquet house_prices_2009.parquet house_prices_2015.parquet house_prices_2021.parquet
house_prices_1998.parquet house_prices_2004.parquet house_prices_2010.parquet house_prices_2016.parquet house_prices_2022.parquet
house_prices_1999.parquet house_prices_2005.parquet house_prices_2011.parquet house_prices_2017.parquet house_prices_2023.parquet
house_prices_2000.parquet house_prices_2006.parquet house_prices_2012.parquet house_prices_2018.parquet同样的方法可以用于 s3 函数。
INSERT INTO FUNCTION s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/uk-house-prices/parquet/house_prices_sample_{_partition_id}.parquet', '<aws_access_key_id>', '<aws_secret_access_key>') PARTITION BY toYear(date) SELECT *
FROM uk_price_paid
LIMIT 1000
在撰写本文时,INTO OUTFILE不支持这个PARTITION BY子句。
转换文件到Parquet格式
结合以上内容,我们可以使用ClickHouse Local在格式之间转换文件。在下面的示例中,我们使用ClickHouse Local和文件函数读取CSV格式的本地副本房价数据集,该数据集包含所有的2800万行,然后将其写入S3作为Parquet。正如之前所示,这些文件按年对数据进行了分区。
INSERT INTO FUNCTION s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/uk-house-prices/parquet/house_prices_sample_{_partition_id}.parquet', '<aws_access_key_id>', '<aws_secret_access_key>') PARTITION BY toYear(date) SELECT *
FROM file('house_prices.csv')0 rows in set. Elapsed: 223.864 sec. Processed 28.11 million rows, 5.87 GB (125.58 thousand rows/s., 26.24 MB/s.)
将 Parquet 文件插入 ClickHouse
前面的所有示例都假设用户正在查询本地和 S3 托管的文件以进行临时分析,或将数据从 ClickHouse 迁移到 Parquet 进行分发。虽然 Parquet 是一种与数据存储无关的文件分发格式,但它的查询效率不如 ClickHouse MergeTree 表,后者能够利用索引和特定于格式的优化。考虑以下查询的性能,该查询使用本地 Parquet 文件和具有推荐架构的MergeTree 表(均在 Macbook Pro 2021 上运行)计算伦敦房产的每年平均价格:
SELECTtoYear(toDate(date)) AS year,round(avg(price)) AS price,bar(price, 0, 2000000, 100)FROM file('house_prices.parquet')WHERE town = 'LONDON'GROUP BY yearORDER BY year ASC29 rows in set. Elapsed: 0.625 sec. Processed 28.11 million rows, 750.65 MB (44.97 million rows/s., 1.20 GB/s.)SELECTtoYear(toDate(date)) AS year,round(avg(price)) AS price,bar(price, 0, 2000000, 100)FROM uk_price_paidWHERE town = 'LONDON'GROUP BY yearORDER BY year ASC29 rows in set. Elapsed: 0.022 sec.
这里的差异是巨大的,并且解释了为什么对于需要实时性能的大型数据集,用户将 Parquet 文件加载到 ClickHouse 中。下面我们假设该uk_price_paid表已预先创建。
从本地文件加载
可以使用该子句从客户端计算机加载文件INFILE。clickhouse-client以下查询从本地客户端的文件系统执行并读取数据。
INSERT INTO uk_price_paid FROM INFILE 'house_price.parquet' FORMAT Parquet28113076 rows in set. Elapsed: 15.412 sec. Processed 28.11 million rows, 1.27 GB (1.82 million rows/s., 82.61 MB/s.)
如果用户的数据分布在多个 Parquet 文件中,此方法还支持 glob 模式。clickhouse-client或者,可以使用以下参数将 Parquet 文件重定向到--query:
clickhouse@clickhouse-mac ~ % ~/clickhouse client --query "INSERT INTO uk_price_paid FORMAT Parquet" < house_price.parquet从 S3 加载
由于客户端存储通常有限,并且随着基于对象存储的数据湖的兴起,Parquet 文件通常驻留在 S3 或 GCS 上。同样,我们可以使用 s3 函数读取这些文件,并使用INSERT INTO SELECT子句将它们的数据插入到 MergeTree 表中。在下面的示例中,我们利用 glob 模式读取按年份分区的文件,并在三节点 ClickHouse Cloud 集群上执行此查询。
INSERT INTO uk_price_paid SELECT *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/uk-house-prices/parquet/house_prices_{1..2}*.parquet')0 rows in set. Elapsed: 12.028 sec. Processed 28.11 million rows, 4.64 GB (2.34 million rows/s., 385.96 MB/s.)与读取类似,可以使用s3Cluster函数来加速。为了确保插入和读取分布在整个集群中,parallel_distributed_insert_select必须启用该设置(否则,仅分布读取,而插入将发送到协调节点)。以下查询在上一个示例中使用的同一云集群上运行,显示了并行化这项工作的好处。
SET parallel_distributed_insert_select=1
INSERT INTO uk_price_paid SELECT *
FROM s3Cluster('default', 'https://datasets-documentation.s3.eu-west-3.amazonaws.com/uk-house-prices/parquet/house_prices_{1..2}*.parquet')0 rows in set. Elapsed: 6.425 sec. Processed 28.11 million rows, 4.64 GB (4.38 million rows/s., 722.58 MB/s.)结论
在本系列的第一部分中,我们介绍了 Parquet 格式,并展示了如何使用 ClickHouse 查询和编写该格式。在下一篇文章中,我们将更详细地探讨该格式,进一步探索 ClickHouse 集成以及最近的性能改进和优化查询的技巧。
作者:Dale McDiarmid
更多内容请关注公号【云原生数据库】
squids.cn,云数据库RDS,迁移工具DBMotion,云备份DBTwin等数据库生态工具。
相关文章:
使用 ClickHouse 深入了解 Apache Parquet (一)
【squids.cn】 全网zui低价RDS,免费的迁移工具DBMotion、数据库备份工具DBTwin、SQL开发工具等 自2013年作为Hadoop的列存储发布以来,Parquet几乎已经成为一种无处不在的文件交换格式,它提供了高效的存储和检索。这种采纳使其成为更近期的…...

【每周一测】Java阶段二第四周学习
目录 1、request中的getParameter(String name)方法的功能是 2、request中的getParameter(String name)方法的功能是 3、spring创建bean对象没有以下哪个方式 4、spring依赖注入中没有以下哪个方式 5、RequestParam、RequestBody、PathVariable的应用场景及区别 6、Cooki…...

系统设计 - 我们如何通俗的理解那些技术的运行原理 - 第四部分:微服务架构
本心、输入输出、结果 文章目录 系统设计 - 我们如何通俗的理解那些技术的运行原理 - 第四部分:微服务架构前言典型的微服务架构是什么样的微服务的优势 微服务最佳实践在开发微服务时,我们需要遵循以下最佳实践: 微服务通常使用什么技术堆栈…...

顺序表ArrayList
作者简介: zoro-1,目前大二,正在学习Java,数据结构等 作者主页: zoro-1的主页 欢迎大家点赞 👍 收藏 ⭐ 加关注哦!💖💖 顺序表 概念Arraylist构造方法相关方法遍历操作 自…...

python软件安装技巧
安装软件时候加上源地址去安装,快速稳 pip install openni -ihttps://pypi.tuna.tsinghua.edu.cn/simple...
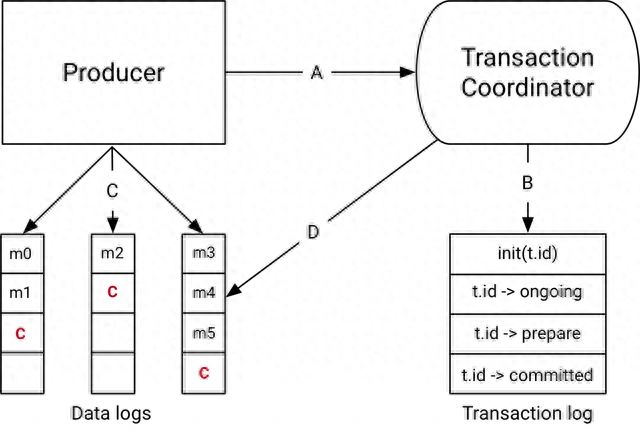
解析Apache Kafka中的事务机制
这篇博客文章并不是关于使用事务细节的教程,我们也不会深入讨论设计细节。相反,我们将在适当的地方链接到JavaDocs或设计文档,以供希望深入研究的读者使用。 为什么交易? 我们在Kafka中设计的事务主要用于那些显示“读-进程-写”模式的应用…...

Vue虚拟节点和渲染函数
1.虚拟节点 虚拟节点(dom)本质上就是一个普通的JS对象,用于描述视图的界面结构 2.渲染函数render():接收一个 createElement()函数创建的VNode Vue.component("board", {render: function(createElement) {return cr…...
后台交互-首页->与后台数据进行交互,wsx的使用
与后台数据进行交互wsx的使用 1.与后台数据进行交互 // index.js // 获取应用实例 const app getApp() const apirequire("../../config/app.js") const utilrequire("../../utils/util.js") Page({data: {imgSrcs:[{"img": "https://cd…...

【微服务保护】Sentinel 流控规则 —— 深入探索 Sentinel 的流控模式、流控效果以及对热点参数进行限流
文章目录 前言一、快速掌握 Sentinel 的使用1.1 什么是簇点链路1.2 Sentinel 的简单使用示例 二、Sentinel 流控模式2.1 直接模式2.2 关联模式2.3 链路模式 三、流控效果3.1 快速失败3.2 预热模式3.3 排队等待 四、对热点参数的流控4.1 热点规则4.2 热点规则演示 前言 微服务架…...
ZXing.Net 的Core平台生成二维码
一、引用 二、代码 帮助类 /// <summary>/// ZXing.NET 二维码帮助类/// </summary>public class ZXingHelper{/// <summary>/// 站点二维码的目录/// </summary>private static string QRCodeDirectory "QRCode";/// <summary>/// 使…...

【C++】假设给类分配的是栈的空间,那么计算机是如何访问栈中不同位置的对象的数据的呢?
2023年10月22日,周日上午 当在栈上创建一个对象时,计算机会为该对象分配一块连续的内存空间。该内存空间的位置在栈帧中,栈帧是用来存储函数调用信息和局部变量的一块内存区域。 栈帧中包含一个指针,称为栈指针(stack…...

iOS使用CoreML运用小型深度神经网络架构对图像进行解析
查找一个图片选择器 我用的是ImagePicker 项目有点老了,需要做一些改造,下面是新的仓库 platform :ios, 16.0use_frameworks!target learnings dosource https://github.com/CocoaPods/Specs.gitpod ImagePicker, :git > https://github.com/KevinS…...

使用Python打造微信高效自动化操作教程
引言 在如今数字化时代,人们对于效率的追求越来越强烈,尤其是在工作和学习中。自动化操作成为了提高生产力的有效途径之一,而PyAutoGUI和Pyperclip作为Python中的两个强大库,为我们实现自动化操作提供了便利。本文将向大家介绍如…...

怎么在爬虫中使用ip代理服务器,爬虫代理IP的好处有哪些?
随着互联网的快速发展,网络爬虫已经成为数据采集、分析和整理的重要工具。然而,随着网络技术的不断发展,许多网站都会采取反爬虫措施,以避免数据被恶意获取。在这种情况下,代理IP服务器就成为了爬虫们的必本备文工将具…...

Typora的相关配置(Typora主题、字体、快捷键、习惯)
Typora的相关配置(Typora主题、字体、快捷键、习惯) 文章目录 Typora的相关配置(Typora主题、字体、快捷键、习惯)[toc]一、主题配置二、字体配置查看字体名称是否可以被识别:如果未能正确识别: 三、习惯配置四、快捷键配置更改提供的功能的快捷键&#…...
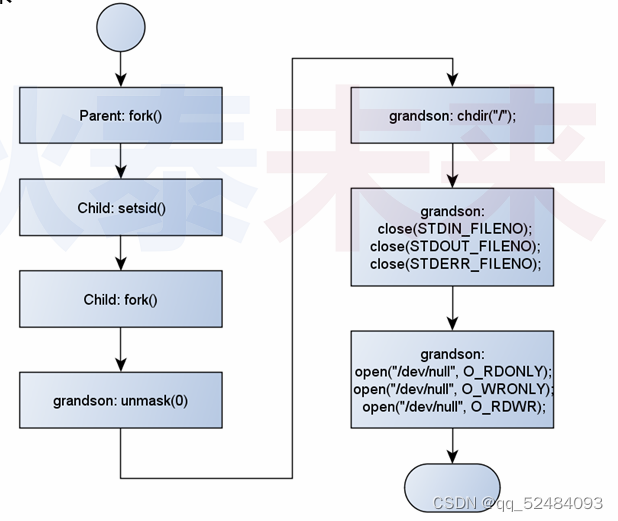
守护进程深度分析
思考 代码中创建的会话,如何关联控制终端? 新会话关联控制终端的方法 会话首进程成功打开终端设备 (设备打开前处于空闲状态) 1、关闭标准输入输出和标准错误输出2、将 stdin 关联到终端设备:STDIN_FILENO > 03、将 stdout 关联到终端设…...

SpringAMQP
SpringAMQT RabbitMQ安装与部署RabbitMQ结构简单队列模型 SpringAMQP依赖引入配置RabbitMQ连接信息基本模型简单队列模型WorkQueue模型 发布订阅模型FanoutExchangeDirectExchangeTopicExchange 消息转换器 消息队列是实现异步通讯的一种方式,我们将从RabbitMQ为例开…...
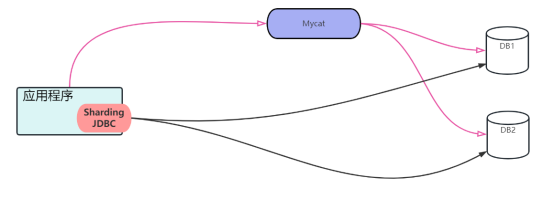
深入探索Sharding JDBC:分库分表的利器
随着互联网应用的不断发展和用户量的不断增加,传统的数据库在应对高并发和大数据量的场景下面临着巨大的挑战。为了解决这一问题,分库分表成为了一个非常流行的方案。分库分表主流的技术包括MyCat和Sharding JDBC。我们来通过一张图来了解这两者有什么区…...
Java后端模拟面试 题集④
1.你先作个自我介绍吧 面试官您好,我叫张睿超,来自湖南长沙,大学毕业于湖南农业大学,是一名智能科学与技术专业的统招一本本科生。今天主要过来面试贵公司的Java后端开发工程师岗位。 大学里面主修的课程是Java、Python、数字图…...

中国5G产业全景图谱报告2022_挚物AIoT产业研究院
中国5G产业全景图谱报告2022_挚物AIoT产业研究院 产业结构 5G 产业结构主要包括接入网、传输网、核心网、电信运营商、网络配套服务商、5G 应用生态及产业服务 7 个主要板块。根据各版块中主要市场参与者提供的产品和服务,又下分子版块。 (1ÿ…...
)
告别绿屏!5分钟学会用FFmpeg命令行无损转换AVC编码MP4视频(保姆级参数详解)
5分钟掌握FFmpeg:AVC编码MP4视频无损转换实战指南 每次遇到视频播放时出现绿屏、卡顿或音画不同步,都让人抓狂。这背后往往是AVC编码的兼容性问题在作祟——不同设备对H.264标准的支持程度参差不齐。作为从业多年的多媒体工程师,我发现最可靠…...

python学习-xx10-2进程与线程【⭐】
1进程详解与应用1、概念进程:程序运行的实例,执行的过程,它是系统调度与资源分配基本单元比如使用python运行一个.py的过程,这就是一个进程,当它运行的时候系统/计算机就会为它分配相应的运行空间,当它运行…...

如何智能配置系统防休眠:Move Mouse实战指南与高效方案
如何智能配置系统防休眠:Move Mouse实战指南与高效方案 【免费下载链接】movemouse Move Mouse is a simple piece of software that is designed to simulate user activity. 项目地址: https://gitcode.com/gh_mirrors/mo/movemouse 你是否曾在远程会议中短…...

如何快速掌握HiveWE:魔兽地图编辑的完整创作指南
如何快速掌握HiveWE:魔兽地图编辑的完整创作指南 【免费下载链接】HiveWE A Warcraft III world editor. 项目地址: https://gitcode.com/gh_mirrors/hi/HiveWE 还在为魔兽争霸III地图制作而烦恼吗?HiveWE作为一款专注于速度和易用性的魔兽争霸II…...

从‘准静态’到‘高效率’:ANSYS Workbench冲压仿真简化建模与计算加速技巧
从‘准静态’到‘高效率’:ANSYS Workbench冲压仿真简化建模与计算加速技巧 冲压成形仿真在工业设计中扮演着越来越重要的角色,但计算资源的消耗和仿真周期的延长常常成为工程师面临的瓶颈。当面对一个复杂的冲压件时,如何在保证工程精度的前…...

WarcraftHelper终极指南:如何让魔兽争霸3在现代Windows系统完美运行
WarcraftHelper终极指南:如何让魔兽争霸3在现代Windows系统完美运行 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为经典游戏魔兽争…...

抖音批量下载终极指南:5分钟掌握高效视频管理技巧
抖音批量下载终极指南:5分钟掌握高效视频管理技巧 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support. …...

从MATLAB频谱到SignalTap波形:深度调试FPGA中的DDS+ADC/DAC数据链
从MATLAB频谱到SignalTap波形:FPGA中DDS与ADC/DAC数据链的深度调试实战 在FPGA开发中,构建一个完整的数字信号处理链路往往只是第一步。真正的挑战在于如何验证系统性能、定位潜在问题并进行精确调优。本文将带您深入探索基于DDS(直接数字频…...

轴承二维圆柱、二维球模型及三维深沟球有限元模型,ANSYS仿真计算必备,新手易上手教程资料包
轴承(二维圆柱和二维球模型)和三维深沟球有限元模型画好网格,可直接拿去ansys仿真计算,适合小白学习上手较快。 以上都是博主学习过程中的一部分成果,保证真实有效。 可以看到轴承的动态受力图。 另外,资料…...

终极动物森友会存档编辑器:NHSE完全指南与3步快速上手教程
终极动物森友会存档编辑器:NHSE完全指南与3步快速上手教程 【免费下载链接】NHSE Animal Crossing: New Horizons save editor 项目地址: https://gitcode.com/gh_mirrors/nh/NHSE 你是否厌倦了在动物森友会中花费数小时收集稀有物品?是否梦想着能…...