分布式Trace:横跨几十个分布式组件的慢请求要如何排查?
目录
前言
一、问题的出现?
二、一体化架构中的慢请求排查如何做
三、分布式 Trace原理
四、如何来做分布式 Trace
前言
在分布式服务架构下,一个 Web 请求从网关流入,有可能会调用多个服务对请求进行处理,拿到最终结果。这个过程中每个服务之间的通信又是单独的网络请求,无论请求经过的哪个服务出了故障或者处理过慢都会对前端造成影响。
处理一个Web请求要调用的多个服务,为了能更方便的查询哪个环节的服务出现了问题,现在常用的解决方案是为整个系统引入分布式链路跟踪。
一、问题的出现?
通过监控发现,系统的核心下单接口在晚高峰的时候,会有少量的慢请求,用户也投诉在 APP 上下单时,等待的时间比较长。而下单的过程可能会调用多个RPC 服务,或者使用多个资源,一时之间,你很难快速判断,究竟是哪个服务或者资源出了问题,从而导致整体流程变慢,于是,你和你的团队开始想办法如何排查这个问题。
二、一体化架构中的慢请求排查如何做
因为在分布式环境下,请求要在多个服务之间调用,所以对于慢请求问题的排查会更困难,我们不妨从简单的入手,先看看在一体化架构中,是如何排查这个慢请求的问题的。
最简单的思路是:打印下单操作的每一个步骤的耗时情况,然后通过比较这些耗时的数据,找到延迟最高的一步,然后再来看看这个步骤要如何的优化。如果有必要的话,你还需要针对步骤中的子步骤,再增加日志来继续排查,简单的代码就像下面这样:
long start = System.currentTimeMillis(); processA(); Logs.info("process A cost " + (System.currentTimeMillis() - start));// 打印 A 步 start = System.currentTimeMillis(); processB(); Logs.info("process B cost " + (System.currentTimeMillis() - start));// 打印 B 步 start = System.currentTimeMillis(); processC(); Logs.info("process C cost " + (System.currentTimeMillis() - start));// 打印 C 步这是最简单的实现方式,打印出日志后,我们可以登录到机器上,搜索关键词来查看每个步骤的耗时情况。
虽然这个方式比较简单,但你可能很快就会遇到问题:由于同时会有多个下单请求并行处理,所以,这些下单请求的每个步骤的耗时日志,是相互穿插打印的。你无法知道这些日志,哪些是来自于同一个请求,也就不能很直观地看到,某一次请求耗时最多的步骤是哪一步了。那么,你要如何把单次请求,每个步骤的耗时情况串起来呢?
一个简单的思路是:给同一个请求的每一行日志,增加一个相同的标记。这样,只要拿到这个标记就可以查询到这个请求链路上,所有步骤的耗时了,我们把这个标记叫做requestId,我们可以在程序的入口处生成一个 requestId,然后把它放在线程的上下文中,这样就可以在需要时,随时从线程上下文中获取到 requestId 了。简单的代码实现就像下面这样:
String requestId = UUID.randomUUID().toString(); //requestId 存储在线程上下文中
ThreadLocal<String> tl = new ThreadLocal<String>() { @Override protected String initialValue() { return requestId; } }; long start = System.currentTimeMillis(); processA(); Logs.info("rid : " + tl.get() + ", process A cost " + (System.currentTimeMillis() - start));start = System.currentTimeMillis(); processB(); Logs.info("rid : " + tl.get() + ", process B cost " + (System.currentTimeMillis() - start));start = System.currentTimeMillis(); processC(); Logs.info("rid : " + tl.get() + ", process C cost " + (System.currentTimeMillis() - start));有了 requestId,你就可以清晰地了解一个调用链路上的耗时分布情况了。于是,你给你的代码增加了大量的日志,来排查下单操作缓慢的问题。很快, 你发现是某一个数据库查询慢了才导致了下单缓慢,然后你优化了数据库索引,问题最终得到了解决。
正当你要松一口气的时候,问题接踵而至:又有用户反馈某些商品业务打开缓慢;商城首页打开缓慢。你开始焦头烂额地给代码中增加耗时日志,而这时你意识到,每次排查一个接口就需要增加日志、重启服务,这并不是一个好的办法,于是你开始思考解决的方案。
其实,从我的经验出发来说,一个接口响应时间慢,一般是出在跨网络的调用上,比如说请求数据库、缓存或者依赖的第三方服务。所以,我们只需要针对这些调用的客户端类,做切面编程,通过插入一些代码打印它们的耗时就好了。
一次请求可能要打印十几条日志,如果你的电商系统的 QPS 是 10000 的话,就是每秒钟会产生十几万条日志,对于磁盘 I/O 的负载是巨大的,那么这时,你就要考虑如何减少日志的数量。
你可以考虑对请求做采样,采样的方式也简单,比如你想采样 10% 的日志,那么你可以只打印“requestId%10==0”的请求。
有了这些日志之后,当给你一个 requestId 的时候,你发现自己并不能确定这个请求到了哪一台服务器上,所以你不得不登陆所有的服务器,去搜索这个 requestId 才能定位请求。这样无疑会增加问题排查的时间。
你可以考虑的解决思路是:把日志不打印到本地文件中,而是发送到消息队列里,再由消息处理程序写入到集中存储中,比如 Elasticsearch。这样,你在排查问题的时候,只需要拿着 requestId 到 Elasticsearch 中查找相关的记录就好了。在加入消息队列和Elasticsearch 之后,我们这个排查程序的架构图也会有所改变:
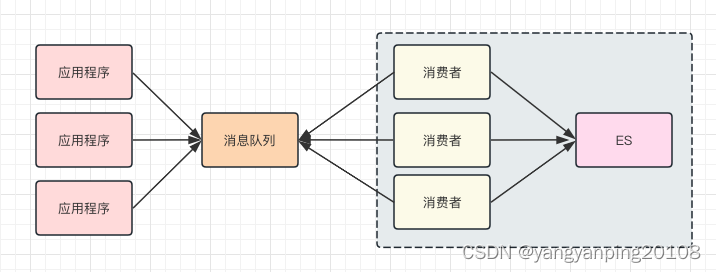
三、分布式 Trace原理
在分布式链路跟踪中有两个重要的概念:跟踪(trace)和 跨度( span)。trace 是请求在分布式系统中的整个链路视图,span 则代表整个链路中不同服务内部的视图,span 组合在一起就是整个 trace 的视图。
在整个请求的调用链中,请求会一直携带 traceid 往下游服务传递,每个服务内部也会生成自己的 spanid 用于生成自己的内部调用视图,并和traceid一起传递给下游服务。
traceid 在请求的整个调用链中始终保持不变,所以在日志中可以通过 traceid 查询到整个请求期间系统记录下来的所有日志。请求到达每个服务后,服务都会为请求生成spanid,而随请求一起从上游传过来的上游服务的 spanid 会被记录成parent-spanid或者叫 pspanid。当前服务生成的 spanid 随着请求一起再传到下游服务时,这个spanid 又会被下游服务当做 pspanid 记录。
通过在访问日志和业务日志里记录的traceid、spanid 和 pspanid 能完整的还原出整个请求的调用链路视图,对错误排查能起到很大的帮助。
上面就是分布式链路跟踪的原理,我们可以自己实现,也可以依赖 opentracing 这种开源的解决方案。一般是在请求到达网关的开始,生成本次请求的traceid 和 在网关服务内的spanid ,将他们放在HTTP 请求头或者RPC调用的元数据里,在调用下游服务时继续向下传递。下游的RESTful API服务的全局路由中间件和RPC服务的拦截器里会接收请求携带的traceid 和生成当次请求在服务内部的spanid,从上游接收到的 spanid 在这里会被转换成 pspanid。除此之外我们甚至可以把 traceid 和 spanid 注入到一些数据库连接池应用里,让记录的慢SQL日志里同样能打上 traceid 和 spanid 信息,为请求的响应过慢提供有效的分析数据。
四、如何来做分布式 Trace
你可能会问:题目既然是“分布式 Trace:横跨几十个分布式组件的慢请求要如何排查?”,那么我为什么要花费大量的篇幅,来说明在一体化架构中如何排查问题呢?这是因为在分布式环境下,你基本上也是依据上面,我提到的这几点来构建分布式追踪的中间件的。
在一体化架构中,单次请求的所有的耗时日志,都被记录在一台服务器上,而在微服务的场景下,单次请求可能跨越多个 RPC 服务,这就造成了,单次的请求的日志会分布在多个服务器上。
当然,你也可以通过 requestId 将多个服务器上的日志串起来,但是仅仅依靠 requestId很难表达清楚服务之间的调用关系,所以从日志中,就无法了解服务之间是谁在调用谁。因此,我们采用 traceId + spanId 这两个数据维度来记录服务之间的调用关系(这里traceId 就是 requestId),也就是使用 traceId 串起单次请求,用 spanId 记录每一次RPC 调用。说起来可能比较抽象,我给你举一个具体的例子。
比如,你的请求从用户端过来,先到达 A 服务,A 服务会分别调用 B 和 C 服务,B 服务又会调用 D 和 E 服务。
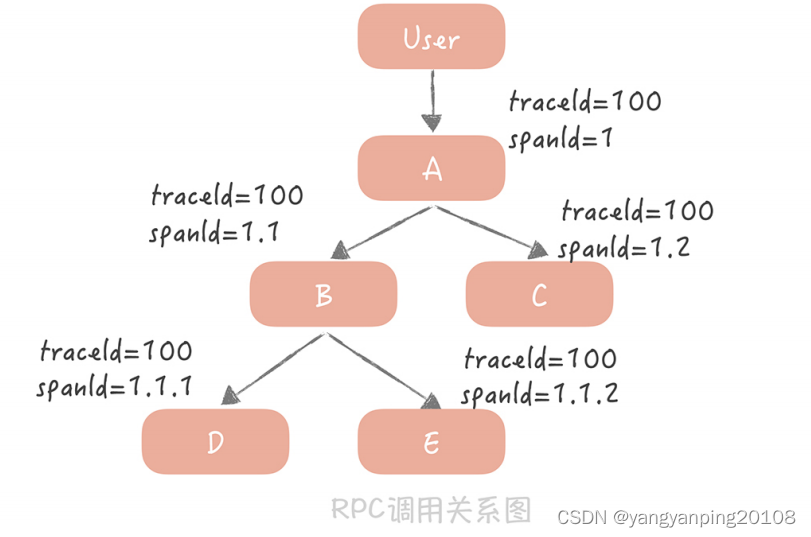
我来给你讲讲图中的内容:
用户到 A 服务之后会初始化一个 traceId 为 100,spanId 为 1;A 服务调用 B 服务时,traceId 不变,而 spanId 用 1.1 标识,代表上一级的 spanId 是1,这一级的调用次序是 1;A 调用 C 服务时,traceId 依然不变,spanId 则变为了 1.2,代表上一级的 spanId 还是 1,而调用次序则变成了 2,以此类推。
通过这种方式,我们可以在日志中,清晰地看出服务的调用关系是如何的,方便在后续计算中调整日志顺序,打印出完整的调用链路。那么 spanId 是何时生成的,又是如何传递的呢?
首先,A 服务在发起 RPC 请求服务 B 前,先从线程上下文中获取当前的 traceId 和spanId,然后,依据上面的逻辑生成本次 RPC 调用的 spanId,再将 spanId 和 traceId 序列化后,装配到请求体中,发送给服务方 B。
服务方 B 获取请求后,从请求体中反序列化出 spanId 和 traceId,同时设置到线程上下文中,以便给下次 RPC 调用使用。在服务 B 调用完成返回响应前,计算出服务 B 的执行时间发送给消息队列。
当然,在服务 B 中,你依然可以使用切面编程的方式,得到所有调用的数据库、缓存、HTTP 服务的响应时间,只是在发送给消息队列的时候,要加上当前线程上下文中的spanId 和 traceId。
这样,无论是数据库等资源的响应时间,还是 RPC 服务的响应时间就都汇总到了消息队列中,在经过一些处理之后,最终被写入到 Elasticsearch 中以便给开发和运维同学查询使用。
而在这里,你大概率会遇到的问题还是性能的问题,也就是因为引入了分布式追踪中间件,导致对于磁盘 I/O 和网络 I/O 的影响,而我给你的“避坑”指南就是:如果你是自研的分布式 trace 中间件,那么一定要提供一个开关,方便在线上随时将日志打印关闭;如果使用开源的组件,可以开始设置一个较低的日志采样率,观察系统性能情况再调整到一个合适的数值。
相关文章:
分布式Trace:横跨几十个分布式组件的慢请求要如何排查?
目录 前言 一、问题的出现? 二、一体化架构中的慢请求排查如何做 三、分布式 Trace原理 四、如何来做分布式 Trace 前言 在分布式服务架构下,一个 Web 请求从网关流入,有可能会调用多个服务对请求进行处理,拿到最终结果。这个…...
【计算机毕设选题推荐】口腔助手小程序SpringBoot+Vue+小程序
前言:我是IT源码社,从事计算机开发行业数年,专注Java领域,专业提供程序设计开发、源码分享、技术指导讲解、定制和毕业设计服务 项目名 基于SpringBoot的口腔助手小程序 技术栈 SpringBootVue小程序MySQLMaven 文章目录 一、口腔…...
【C/C++笔试练习】初始化列表、构造函数、析构函数、两种排序方法、求最小公倍数
文章目录 C/C笔试练习1. 初始化列表(1)只能在列表初始化的变量 2.构造函数(2)函数体赋值(3)构造函数的概念(4)构造函数调用次数(5)构造函数调用次数ÿ…...

分享 | 对 电商API 平台的再思考
API 是推动现代企业数字化转型的基础。它不但连接了内部应用程序、合作伙伴和客户,同时也快速持续地向市场提供了各种新产品、版本和功能。 但当下还是以集中式的 API 交付为主。一个企业的对外 API 交付过程通常都是冗余而繁琐的,对企业内部的敏捷性、速…...
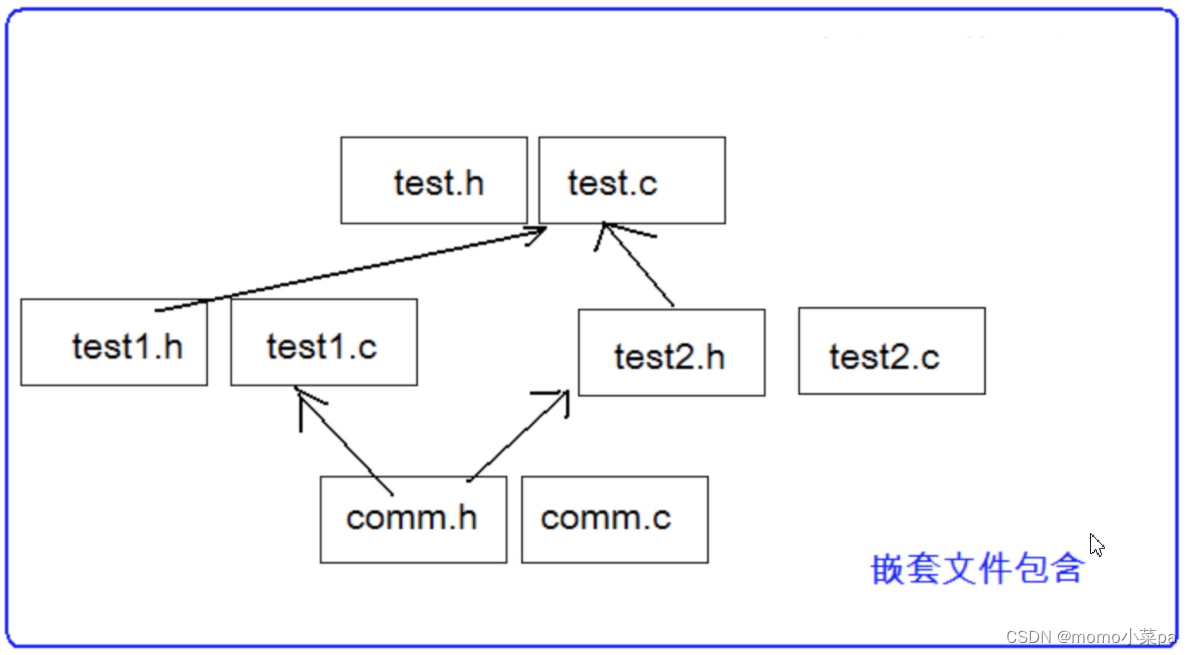
C语言--程序环境和预处理
前言 本章就是c语言的最后一个板块了,学完这章节,我们将知道写出的代码如何变成可执行程序的,这是非常重要的一个章节,那让我们一起进入本章的学习吧。 本章重点: 程序的翻译环境程序的执行环境详解:C语言程…...

深度学习笔记_5 经典卷积神经网络LeNet-5 解决MNIST数据集
1、定义LeNet-5模型,包括卷积层和全连接层。 import torch import torch.nn as nn import torch.optim as optim from torchvision import datasets, transforms# 导入必要的库# 定义 LeNet-5 模型 class LeNet5(nn.Module):def __init__(self):super(LeNet5, self…...

国内智能客服机器人都有哪些?
随着人工智能技术的不断发展,智能客服机器人已经成为了企业客户服务的重要工具。国内的智能客服机器人市场也迎来了飞速发展,越来越多的企业开始采用智能客服机器人来提升客户服务效率和质量。 在这篇文章中,我将详细介绍国内知名的智能客服机…...

Matlab/C++源码实现RGB通道与HSV通道的转换(效果对比Halcon)
HSV通道的含义 HSV通道是指图像处理中的一种颜色模型,它由色调(Hue)、饱和度(Saturation)和明度(Value)三个通道组成。色调表示颜色的种类,饱和度表示颜色的纯度或鲜艳程度…...

【C进阶】动态内存管理
一、为什么存在动态内存分配 我们之前学的都是开辟固定大小的空间,但有时候需要空间的大小只有在程序运行时才能知道,那么就引入了动态内存开辟 内存分布所在: 二、动态内存函数的介绍 2.1malloc和free 动态内存开辟的函数 void * malloc…...

神经网络的梯度优化方法
神经网络的梯度优化是深度学习中至关重要的一部分,它有助于训练神经网络以拟合数据。下面将介绍几种常见的梯度优化方法,包括它们的特点、优缺点以及原理。 梯度下降法 (Gradient Descent): 特点: 梯度下降是最基本的优化算法,它试图通过迭代…...

linux 装机教程(自用备忘)
文章目录 安装 pyenv 管理多版本 python 环境安装使用使用 pyenv 和 virtualenv 管理虚拟 python 环境 vscode 连接远程服务器tmux 美化zsh 安装 pyenv 管理多版本 python 环境 安装 (教程参考:https://www.modb.pro/db/155036) sudo apt-…...
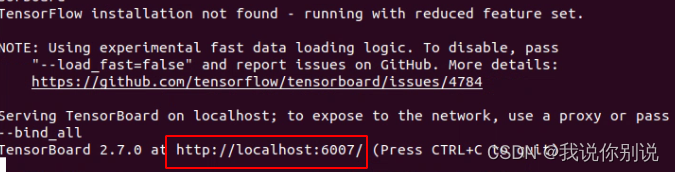
Tensorboard安装及简单使用
Tensorboard 1. tensorboard 简单介绍2. 安装必备环境3. Tensorboard安装4. 可视化命令 1. tensorboard 简单介绍 TensorBoard是一个可视化的模块,该模块功能强大,可用于深度学习网络模型训练查看模型结构和训练效果(预测结果、网络模型结构…...
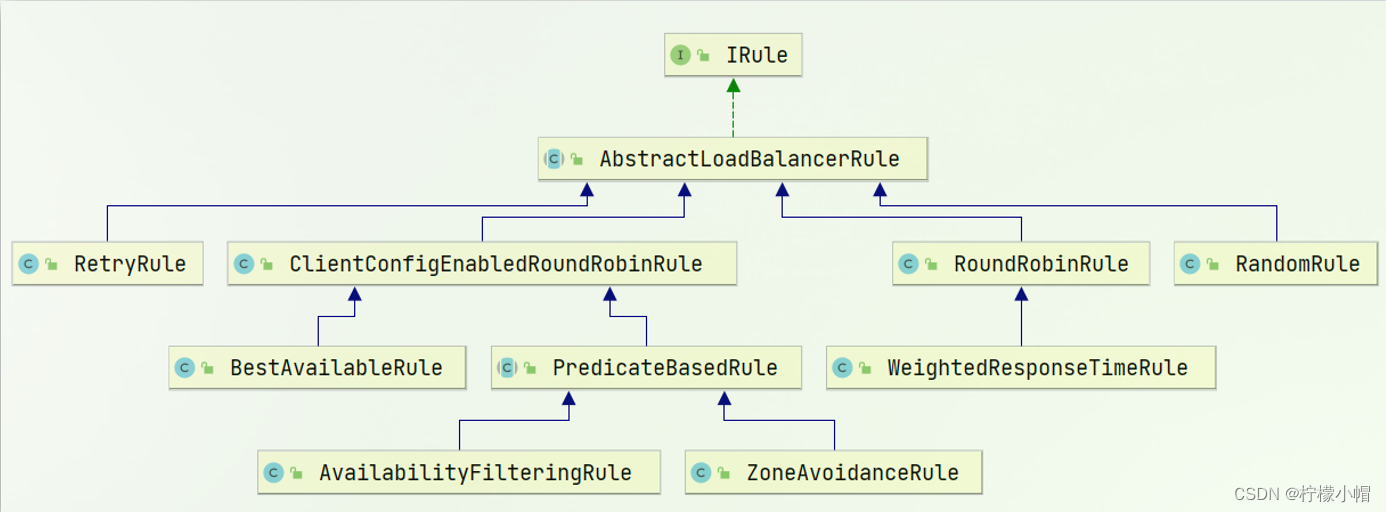
SpringCloud 微服务全栈体系(二)
第三章 Eureka 注册中心 假如我们的服务提供者 user-service 部署了多个实例,如图: 思考几个问题: order-service 在发起远程调用的时候,该如何得知 user-service 实例的 ip 地址和端口?有多个 user-service 实例地址…...

flutter 常用组件:列表ListView
文章目录 总结#1、通过构造方法直接构建 ListView 提供了一个默认构造函数 ListView,我们可以通过设置它的 children 参数,很方便地将所有的子 Widget 包含到 ListView 中。 不过,这种创建方式要求提前将所有子 Widget 一次性创建好,而不是等到它们真正在屏幕上需要显示时才…...
十四天学会C++之第七天:STL(标准模板库)
1. STL容器 什么是STL容器,为什么使用它们。向量(vector):使用向量存储数据。列表(list):使用列表实现双向链表。映射(map):使用映射实现键值对存储。 什么…...

Linux 下安装 miniconda,管理 Python 多环境
安装 miniconda 1、下载安装包 Miniconda3-py37_22.11.1-1-Linux-x86_64.sh,或者自行选择版本 2、把安装包上传到服务器上,这里放在 /home/software 3、安装 bash Miniconda3-py37_22.11.1-1-Linux-x86_64.sh 4、按回车 Welcome to Miniconda3 py37…...
Django和jQuery,实现Ajax表格数据分页展示
1.需求描述 当存在重新请求接口才能返回数据的功能时,若页面的内容很长,每次点击一个功能,页面又回到了顶部,对于用户的体验感不太友好,我们希望当用户点击这类的功能时,能直接加载到数据,请求…...
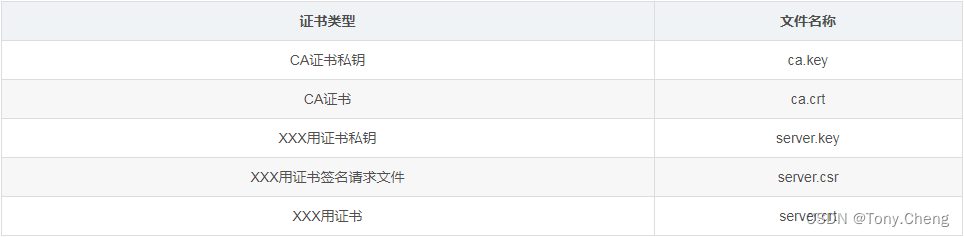
k8s认证
1. 证书介绍 服务端保留公钥和私钥,客户端使用root CA认证服务端的公钥 一共有多少证书: *Etcd: Etcd对外提供服务,要有一套etcd server证书Etcd各节点之间进行通信,要有一套etcd peer证书Kube-APIserver访问Etcd&a…...
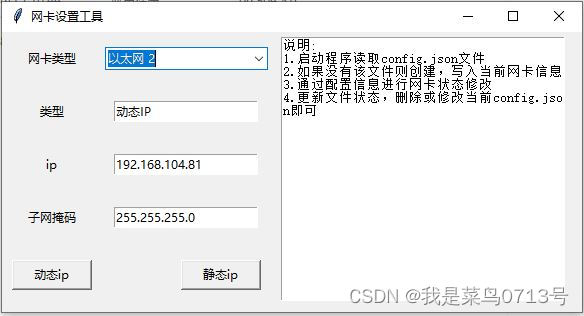
基于python开发的IP修改工具
工作中调试设备需要经常修改电脑IP,非常麻烦,这里使用Pythontkinter做了一个IP修改工具 说明: 1.启动程序读取config.json文件2.如果没有该文件则创建,写入当前网卡信息3.通过配置信息进行网卡状态修改4.更新文件状态,删除或修…...
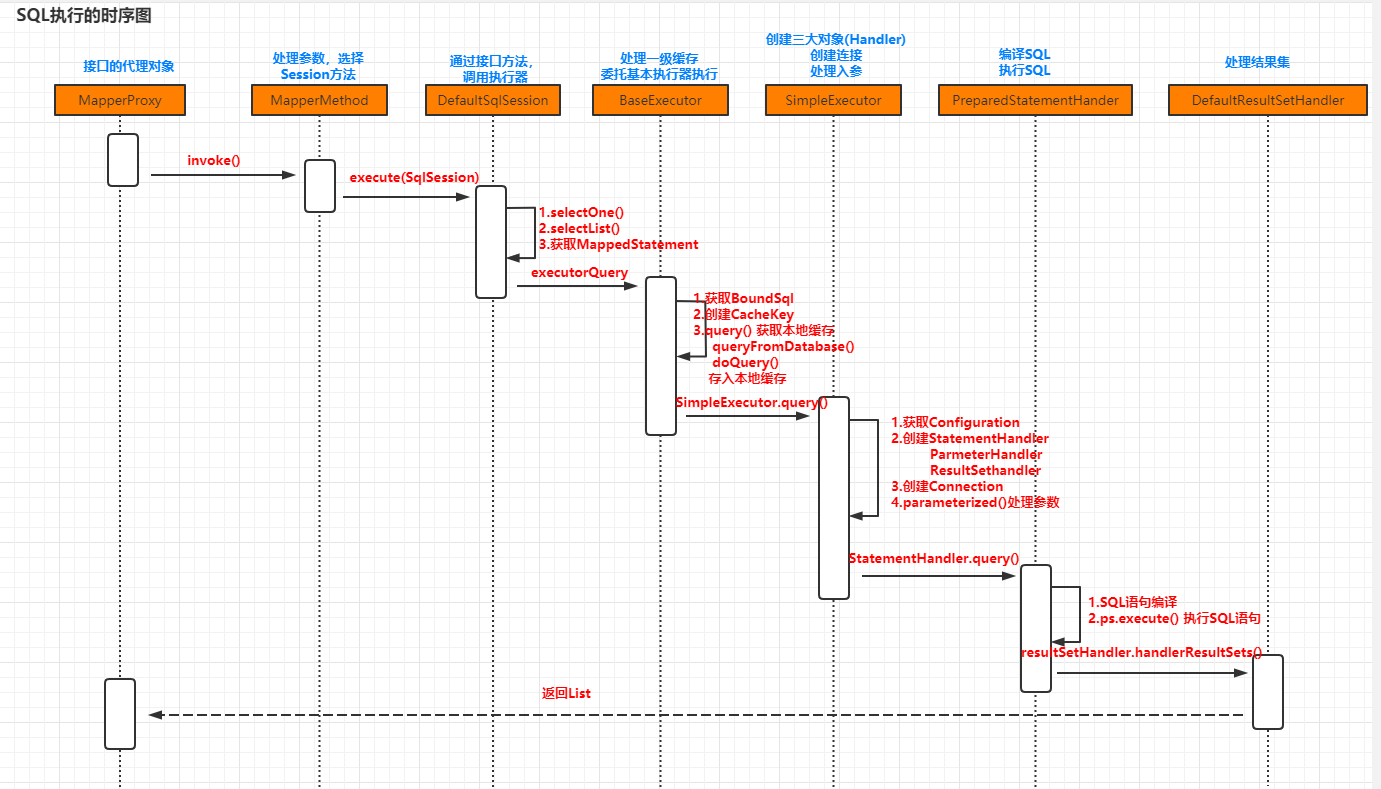
Mybatis源码分析
1. Mybatis整体三层设计 SSM中,Spring、SpringMVC已经在前面文章源码分析总结过了,Mybatis源码相对Spring和SpringMVC而言是的简单的,只有一个项目,项目下分了很多包。从宏观上了解Mybatis的整体框架分为三层,分别是基…...

华为S5735S交换机iStack堆叠实战:从零配置到业务上线
1. 为什么选择iStack堆叠技术 第一次接触华为S5735S交换机堆叠时,我也被各种堆叠技术名词绕晕了。iStack、CSS、堆叠卡、业务口堆叠...后来在实际项目中摸爬滚打才发现,电口堆叠才是中小型网络的最优解。就拿最近一个客户案例来说,他们原有单…...

如何备份大量小表组成的数据库_并行导出与多文件并发写入.txt
PHP开发无需选机箱,真正关键的是CPU单核性能、RAM容量和SSD读写延迟;生产服务器的硬件选型属于运维范畴,与PHP编码、调试、本地运行无关。PHP 是运行在服务器端的脚本语言,源码开发阶段根本不需要考虑机箱、散热或 PCIe 插槽——这…...

《QClaw隐藏的GitHub自动化神级用法》
大多数程序员每天都会在GitHub上重复大量机械性操作,从创建仓库时填写各种配置项,到初始化项目结构,再到设置分支保护规则和自动化工作流,这些看似简单的步骤累积起来会消耗大量宝贵的开发时间。很多人没有意识到,这些…...

2026年降AI工具免费版和付费版区别:哪些场景下付费版才值得买
2026年降AI工具免费版和付费版区别:哪些场景下付费版才值得买 研究生群里聊起AI率的问题,发现十个人里起码六七个都在用工具降。主流的选择其实就那几款,关键是选对了能省很多麻烦。 综合价格和效果,我主推嘎嘎降AI(…...

不只是关弹窗:从中标麒麟试用提示聊聊国产Linux系统的授权与日常维护
中标麒麟系统试用机制解析与深度维护指南 当你在深夜赶项目时,屏幕右下角突然弹出的试用到期提示框是否让你抓狂?这背后其实隐藏着国产操作系统独特的商业模式和技术架构。作为国内最早实现商用的Linux发行版之一,中标麒麟的试用提示机制恰似…...

告别‘True’焦虑:TensorFlow-GPU安装后,用这5个测试方法彻底验证你的CUDA环境是否真的能用
深度验证TensorFlow-GPU环境:超越is_gpu_available()的5种实战诊断方案 当你看到tf.test.is_gpu_available()返回True时,是否曾暗自怀疑这个结果的可信度?许多开发者发现,即便终端显示GPU已启用,模型训练速度却未见提升…...
)
不止于连接:用ADB命令深度管理你的华为荣耀V9(文件传输、进程查看实战)
不止于连接:用ADB命令深度管理你的华为荣耀V9(文件传输、进程查看实战) 当你已经成功用ADB连接上荣耀V9,就像拿到了一把通往Android系统深处的钥匙。但大多数人只用来开个门就停下了——其实门后藏着整套工具间。上周帮同事调试应…...

3分钟上手:B站视频数据分析工具快速指南
3分钟上手:B站视频数据分析工具快速指南 【免费下载链接】Bilivideoinfo Bilibili视频数据爬虫 精确爬取完整的b站视频数据,包括标题、up主、up主id、精确播放数、历史累计弹幕数、点赞数、投硬币枚数、收藏人数、转发人数、发布时间、视频时长、视频简介…...

DDrawCompat三步部署指南:让Windows 10/11经典游戏重获新生
DDrawCompat三步部署指南:让Windows 10/11经典游戏重获新生 【免费下载链接】DDrawCompat DirectDraw and Direct3D 1-7 compatibility, performance and visual enhancements for Windows Vista, 7, 8, 10 and 11 项目地址: https://gitcode.com/gh_mirrors/dd/D…...

如何在Mac上免费解锁百度网盘SVIP下载速度:完整指南
如何在Mac上免费解锁百度网盘SVIP下载速度:完整指南 【免费下载链接】BaiduNetdiskPlugin-macOS For macOS.百度网盘 破解SVIP、下载速度限制~ 项目地址: https://gitcode.com/gh_mirrors/ba/BaiduNetdiskPlugin-macOS 还在为百度网盘缓慢的下载速度而烦恼吗…...