自然语言处理---Self Attention自注意力机制
Self-attention介绍
Self-attention是一种特殊的attention,是应用在transformer中最重要的结构之一。attention机制,它能够帮助找到子序列和全局的attention的关系,也就是找到权重值wi。Self-attention相对于attention的变化,其实就是寻找权重值的wi过程不同。
- 为了能够产生输出的向量yi,self-attention其实是对所有的输入做了一个加权平均的操作,这个公式和上面的attention是一致的。
- j代表整个序列的长度,并且j个权重的相加之和等于1。值得一提的是,这里的 wij并不是一个需要神经网络学习的参数,它是来源于xi和xj的之间的计算的结果(这里wij的计算发生了变化)。它们之间最简单的一种计算方式,就是使用点积的方式。
xi和xj是一对输入和输出。对于下一个输出的向量yi+1,有一个全新的输入序列和一个不同的权重值。
- 这个点积的输出的取值范围在负无穷和正无穷之间,所以要使用一个softmax把它映射到[0,1] 之间,并且要确保它们对于整个序列而言的和为1。
- 以上这些就是self-attention最基本的操作。
Self-attention和Attention使用方法
根据他们之间的重要区别,可以区分在不同任务中的使用方法:
- 在神经网络中,通常来说会有输入层(input),应用激活函数后的输出层(output),在RNN当中会有状态(state)。如果attention (AT) 被应用在某一层的话,它更多的是被应用在输出或者是状态层上,而当使用self-attention(SA),这种注意力的机制更多的实在关注input上。
- Attention (AT) 经常被应用在从编码器(encoder)转换到解码器(decoder)。比如说,解码器的神经元会接受一些AT从编码层生成的输入信息。在这种情况下,AT连接的是**两个不同的组件**(component),编码器和解码器。但是如果用**SA**,它就不是关注的两个组件,它只是在关注应用的**那一个组件**。那这里就不会去关注解码器了,就比如说在Bert中,使用的情况,就没有解码器。
- SA可以在一个模型当中被多次的、独立的使用(比如说在Transformer中,使用了18次;在Bert当中使用12次)。但是,AT在一个模型当中经常只是被使用一次,并且起到连接两个组件的作用。
- SA比较擅长在一个序列当中,寻找不同部分之间的关系。比如说,在词法分析的过程中,能够帮助去理解不同词之间的关系。AT却更擅长寻找两个序列之间的关系,比如说在翻译任务当中,原始的文本和翻译后的文本。这里也要注意,在翻译任务重,SA也很擅长,比如说Transformer。
- AT可以连接两种不同的模态,比如说图片和文字。SA更多的是被应用在同一种模态上,但是如果一定要使用SA来做的话,也可以将不同的模态组合成一个序列,再使用SA。
- 其实有时候大部分情况,SA这种结构更加的general,在很多任务作为降维、特征表示、特征交叉等功能尝试着应用,很多时候效果都不错。
Self-attetion实现步骤
- 这里实现的注意力机制是现在比较流行的点积相乘的注意力机制
- self-attention机制的实现步骤
- 第一步: 准备输入
- 第二步: 初始化参数
- 第三步: 获取key,query和value
- 第四步: 给input1计算attention score
- 第五步: 计算softmax
- 第六步: 给value乘上score
- 第七步: 给value加权求和获取output1
- 第八步: 重复步骤4-7,获取output2,output3
1. 准备输入
# 这里随机设置三个输入, 每个输入的维度是一个4维向量
import torch
x = [[1, 0, 1, 0], # Input 1[0, 2, 0, 2], # Input 2[1, 1, 1, 1] # Input 3
]
x = torch.tensor(x, dtype=torch.float32)2. 初始化参数
# 每一个输入都有三个表示,分别为key(橙黄色),query(红色),value(紫色)。
# 每一个表示,希望是一个3维的向量。由于输入是4维,所以参数矩阵为 4*3 维。# 为了能够获取这些表示,每一个输入(绿色)要和key,query和value相乘
# 在例子中,使用如下的方式初始化这些参数。
w_key = [[0, 0, 1],[1, 1, 0],[0, 1, 0],[1, 1, 0]
]
w_query = [[1, 0, 1],[1, 0, 0],[0, 0, 1],[0, 1, 1]
]
w_value = [[0, 2, 0],[0, 3, 0],[1, 0, 3],[1, 1, 0]
]
w_key = torch.tensor(w_key, dtype=torch.float32)
w_query = torch.tensor(w_query, dtype=torch.float32)
w_value = torch.tensor(w_value, dtype=torch.float32)print("w_key: \n", w_key)
print("w_query: \n", w_query)
print("w_value: \n", w_value)3. 获取key,query和value
# 使用向量化获取keys的值
[0, 0, 1]
[1, 0, 1, 0] [1, 1, 0] [0, 1, 1]
[0, 2, 0, 2] x [0, 1, 0] = [4, 4, 0]
[1, 1, 1, 1] [1, 1, 0] [2, 3, 1]# 使用向量化获取values的值
[0, 2, 0]
[1, 0, 1, 0] [0, 3, 0] [1, 2, 3]
[0, 2, 0, 2] x [1, 0, 3] = [2, 8, 0]
[1, 1, 1, 1] [1, 1, 0] [2, 6, 3]# 使用向量化获取querys的值
[1, 0, 1]
[1, 0, 1, 0] [1, 0, 0] [1, 0, 2]
[0, 2, 0, 2] x [0, 0, 1] = [2, 2, 2]
[1, 1, 1, 1] [0, 1, 1] [2, 1, 3]
# 将query key value分别进行计算
keys = x @ w_key
querys = x @ w_query
values = x @ w_value
print("Keys: \n", keys)
print("Querys: \n", querys)
print("Values: \n", values)
4. 给input1计算attention score
# 获取input1的attention score,使用点乘来处理所有的key和query,包括自己的key和value。
# 这样就能够得到3个key的表示(因为有3个输入),就获得了3个attention score(蓝色)
[0, 4, 2]
[1, 0, 2] x [1, 4, 3] = [2, 4, 4]
[1, 0, 1]# 注意: 这里只用input1举例。其他的输入的query和input1做相同的操作.
attn_scores = querys @ keys.T
print(attn_scores)5. 计算softmax
from torch.nn.functional import softmaxattn_scores_softmax = softmax(attn_scores, dim=-1)
print(attn_scores_softmax)
attn_scores_softmax = [[0.0, 0.5, 0.5],[0.0, 1.0, 0.0],[0.0, 0.9, 0.1]
]
attn_scores_softmax = torch.tensor(attn_scores_softmax)
print(attn_scores_softmax)softmax([2, 4, 4]) = [0.0, 0.5, 0.5]6. 给value乘上score
使用经过softmax后的attention score乘以它对应的value值(紫色),这样就得到了3个weighted values(黄色)
1: 0.0 * [1, 2, 3] = [0.0, 0.0, 0.0]
2: 0.5 * [2, 8, 0] = [1.0, 4.0, 0.0]
3: 0.5 * [2, 6, 3] = [1.0, 3.0, 1.5]
weighted_values = values[:,None] * attn_scores_softmax.T[:,:,None]
print(weighted_values)7. 给value加权求和获取output1
把所有的weighted values(黄色)进行element-wise的相加。
[0.0, 0.0, 0.0]
+ [1.0, 4.0, 0.0]
+ [1.0, 3.0, 1.5]
------------------------
= [2.0, 7.0, 1.5]
得到结果向量[2.0, 7.0, 1.5](深绿色)就是ouput1的和其他key交互的query representation
8. 重复步骤4-7,获取output2,output3
outputs = weighted_values.sum(dim=0)
print(outputs)相关文章:

自然语言处理---Self Attention自注意力机制
Self-attention介绍 Self-attention是一种特殊的attention,是应用在transformer中最重要的结构之一。attention机制,它能够帮助找到子序列和全局的attention的关系,也就是找到权重值wi。Self-attention相对于attention的变化,其实…...
推荐收藏系列!2万字图解Hadoop
今天我用图解的方式讲解pandas的用法,内容较长建议收藏,梳理不易,点赞支持。 学习 Python 编程,给我的经验就是:技术要学会分享、交流,不建议闭门造车。一个人可能走的很快、但一堆人可以走的更远。如果你…...
:生成器)
Python高级篇(08):生成器
一、生成器定义和作用 定义:Python中,一边循环一边计算的机制,生成器对象也是迭代器对象,支持for循环、next()方法…等。作用:循环的过程中不断推算出后续的元素,这样就不必创建完整的list,从而…...
)
力扣100114. 元素和最小的山形三元组 II(中等)
题目描述: 给你一个下标从 0 开始的整数数组 nums 。 如果下标三元组 (i, j, k) 满足下述全部条件,则认为它是一个 山形三元组 : i < j < knums[i] < nums[j] 且 nums[k] < nums[j] 请你找出 nums 中 元素和最小 的山形三元组…...
--lcdseg - 段式lcd)
LuatOS-SOC接口文档(air780E)--lcdseg - 段式lcd
常量 常量 类型 解释 lcdseg.BIAS_STATIC number 没偏置电压(bias) lcdseg.BIAS_ONEHALF number 1/2偏置电压(bias) lcdseg.BIAS_ONETHIRD number 1/3偏置电压(bias) lcdseg.BIAS_ONEFOURTH number 1/4偏置电压(bias) lcdseg.DUTY_STATIC number 100%占空比(d…...

实现图像处理和分析的关键技术
在计算机视觉中,我们可以利用摄像头捕捉到的图像来进行各种分析和处理。以下是一些常见的计算机视觉任务: 对象检测:识别图像中的特定对象并标注其位置。人脸识别:识别和验证人脸身份。姿态估计:估计人体的姿态和动作…...

【C++学习笔记】内联函数
1. 概念 以inline修饰的函数叫做内联函数,编译时C编译器会在调用内联函数的地方展开,没有函数调 用建立栈帧的开销,内联函数提升程序运行的效率。 如果在上述函数前增加inline关键字将其改成内联函数,在编译期间编译器会用函数…...
macOS Sonoma 14.1RC(23B73)发布
黑果魏叔10 月 18 日消息,苹果今日向 Mac 电脑用户推送了 macOS 14.1 RC更新(内部版本号:23B73),本次更新距离上次发布隔了 7 天。 macOS Sonoma 14.1RC(23B73)的更新内容主要包括以下方面&…...
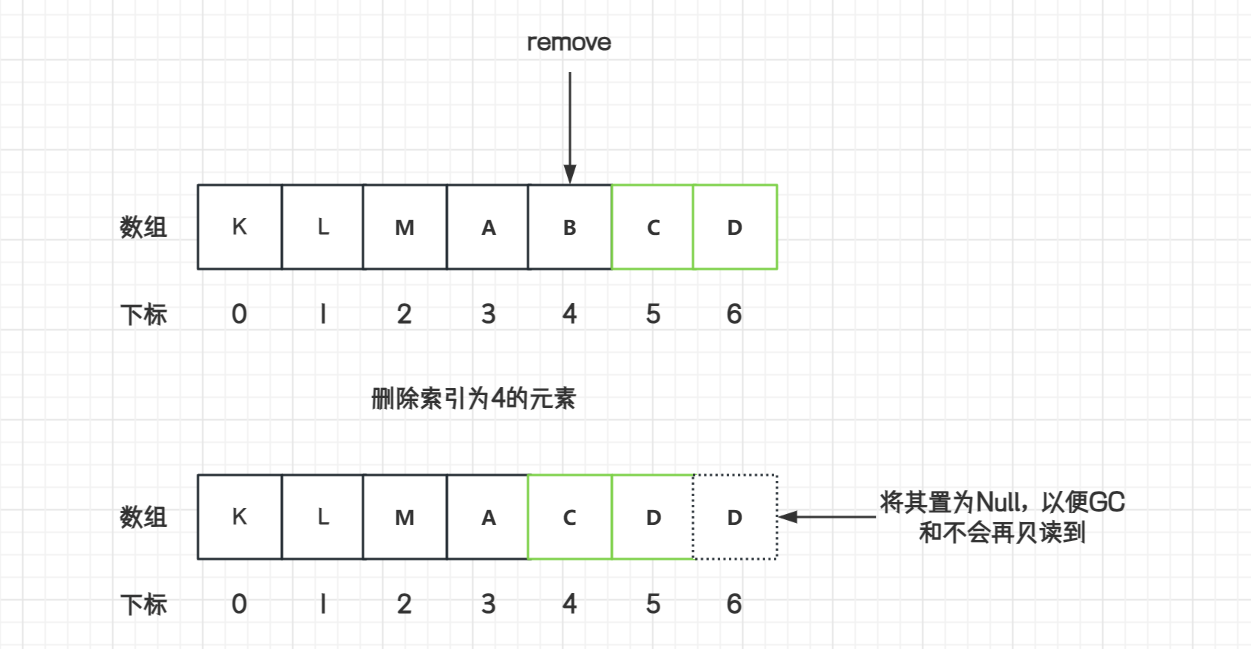
数据结构数组 Array 手写实现,扩容原理
数组数据结构 数组(Array)是一种线性表数据结构。它用一组连续的内存空间,来存储一组具有相同类型数据的集合。 数组的特点: 数组是相同数据类型的元素集合(int 不能存放 double)数组中各元素的存储是有先…...
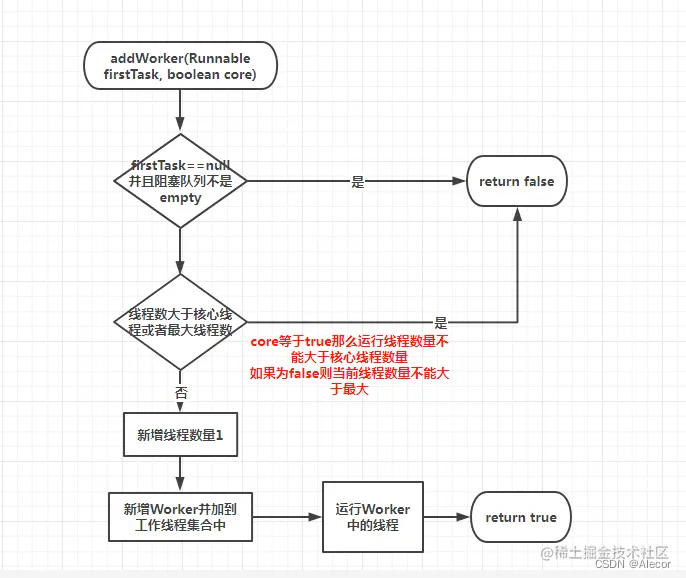
工作中几个问题的思考
对于需要并行多公司并行处理的任务,方案是什么? 多线程、并行流、并发库(ExecutorService、Futrue、Callable),分布式计算(1)按照公司ID分片 (2)按照业务类型分片 处理…...
Jmeter的性能测试
性能测试的概念 定义:软件的性能是软件的一种非功能特性,它关注的不是软件是否能够完成特定的功能,而是在完成该功能时展示出来的及时性。 由定义可知性能关注的是软件的非功能特性,所以一般来说性能测试介入的时机是在功能测试…...
IntelliJ IDEA 2020.2.1白票安装使用方法
先安装好idear Plugins 内手动添加第三方插件仓库地址:https://plugins.zhile.io 搜索:IDE Eval Reset插件进行安装 输入https://plugins.zhile.io 手动安装离线插件方法 安装包可以去笔者的CSDN资源库下载 安装mybaties插件...

【UCAS自然语言处理作业一】利用BeautifulSoup爬取中英文数据,计算熵,验证齐夫定律
文章目录 前言中文数据爬取爬取界面爬取代码 数据清洗数据分析实验结果 英文数据爬取爬取界面动态爬取 数据清洗数据分析实验结果 结论 前言 本文分别针对中文,英文语料进行爬虫,并在两种语言上计算其对应的熵,验证齐夫定律github: ShiyuNee…...

微信小程序之个人中心授权登录
🎬 艳艳耶✌️:个人主页 🔥 个人专栏 :《Spring与Mybatis集成整合》《Vue.js使用》 ⛺️ 越努力 ,越幸运。 1.了解微信授权登录 微信登录官网: 小程序登录https://developers.weixin.qq.com/miniprogram/d…...
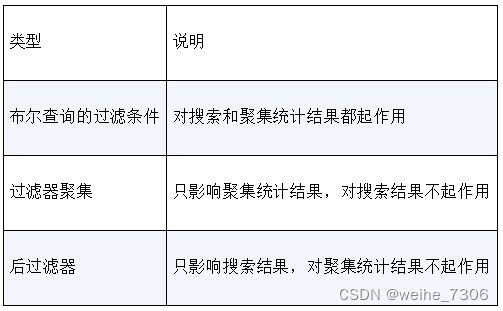
Elasticsearch的聚集统计,可以进行各种统计分析
说明: Elasticsearch不仅是一个大数据搜索引擎,也是一个大数据分析引擎。它的聚集(aggregation)统计的REST端点可用于实现与统计分析有关的功能。Elasticsearch提供的聚集分为三大类。 度量聚集(Metric aggregation):度量聚集可以用于计算搜…...

Webpack 理解 input output 概念
一、介绍 如果还没用过 Webpack 请先阅读 Webpack & 基础入门 再回头看本文。 Webpack 的核心只做两件事,输入管理(Input Management)和输出管理(Output Management),什么花里胡哨的插件和配置都离不…...

【字符函数】
✨博客主页:小钱编程成长记 🎈博客专栏:进阶C语言 🎈相关博文:字符串函数(一)、字符串函数(二) 字符函数 字符函数1.字符分类函数1.1 iscntrl - 判断是否是控制字符1.2 i…...
git创建与合并分支
文章目录 创建与合并分支分支管理的概念实际操作 解决冲突分支管理策略Bug分支Feature分支多人协作 创建与合并分支 分支管理的概念 分支在实际中有什么用呢?假设你准备开发一个新功能,但是需要两周才能完成,第一周你写了50%的代码…...

【电子通识】USB TYPE-A 2.0/3.0连接器接口
基础知识 USB TYPE-A连接器又可称为USB-A,现在不少PC、PC周边、手机充电器等等都依然采用了这种扁平的矩形接口,是目前普及度最高的USB接口了。 USB-A亦有分为插头与插座。常见的USB-A数据线的A端就是插头,而充电器上的则是插座。插头和插座…...

org.apache.sshd的SshClient客户端 连接服务器执行命令 示例
引入依赖 <dependency><groupId>org.apache.sshd</groupId><artifactId>sshd-core</artifactId><version>2.9.1</version></dependency>示例代码,可以直接执行,也可以做替换命令、维护session等修改 p…...

LeetCode 插入排序 题解
LeetCode 插入排序 题解 题目描述 实现插入排序算法,对一个整数数组进行排序。 示例 1: 输入:nums [5,2,3,1] 输出:[1,2,3,5]示例 2: 输入:nums [5,1,1,2,0,0] 输出:[0,0,1,1,2,5]解题思路 方…...

# Bug 报告:openai-codex provider broken since 2026.4.5 �� Cloudflare challenge + missing OAuth scope /
Bug 报告:openai-codex provider broken since 2026.4.5 �� Cloudflare challenge + missing OAuth scope / openai-codex provider broken since 2026.4.5 - Cloudflare challenge + missing OAuth scope 链接: https://blog.csdn.net/cosmoslife 作者: cosmoslife 日期: 2…...

NaViL-9B多模态模型应用:智能识别图片内容,轻松实现图文对话
NaViL-9B多模态模型应用:智能识别图片内容,轻松实现图文对话 1. NaViL-9B模型概述 NaViL-9B是上海人工智能实验室研发的原生多模态大语言模型,具备同时处理文本和图像信息的能力。与传统的单一模态模型不同,NaViL-9B能够理解图片…...

具身智能表征的ImageNet来了!机器人终于看懂了人类世界
机器人在现实中总“翻车”?只因跨不过那道模态鸿沟。今天,具身智能真正的 ImageNet 时刻终于到来。从 2025 年春晚的《秧 BOT》,到 2026 年春晚里走进武术、小品等不同节目,机器人已经不只是舞台上的技术点缀,它们的动…...
)
树莓派4B无头模式极简指南:5分钟搞定SSH+WiFi预配置(含国内源加速)
树莓派4B无头模式极简配置:SSHWiFi预配置与国内源加速实战 1. 无头模式的核心价值与准备工作 无头模式(Headless Mode)彻底解放了树莓派对显示器和外设的依赖,让这块信用卡大小的计算机真正成为物联网项目的隐形引擎。想象一下&am…...
)
保姆级教程:用MATLAB实现锂电池模型参数在线辨识(附NEDC工况数据)
从零实现锂电池参数在线辨识:MATLAB实战指南与NEDC工况解析 锂电池参数辨识是电池管理系统(BMS)开发中的核心技术难点。许多工程师在阅读相关论文时,常会遇到算法原理清晰但代码实现困难的窘境。本文将提供一个完整的MATLAB实现方…...
)
别再手动画框了!用YOLOv10给你的数据集做‘预标注’,效率提升90%(附Python代码)
用YOLOv10实现智能预标注:告别低效手工作业的完整指南 标注数据是AI开发过程中最耗时却又无法绕过的环节。我曾在一个工业质检项目中,面对3万张待标注的螺丝缺陷图像,团队标注师连续工作两周才完成初步标注。直到我们发现预标注技术ÿ…...

别再盲目升级GPU!92%的代码生成延迟其实源于AST解析器阻塞——一线大厂内部性能压测文档首次公开
第一章:智能代码生成性能优化技巧 2026奇点智能技术大会(https://ml-summit.org) 智能代码生成模型(如基于LLM的Copilot类工具)在实际工程落地中常面临响应延迟高、上下文吞吐低、生成结果不稳定等问题。优化其端到端性能需兼顾推理效率、缓…...

【Android 进阶】深度解密 Kotlin 协程:从状态机到底层调度机制
一、 重新认识协程:它到底是什么?1. 概念定义协程(Coroutines) 并不是操作系统层面的概念,而是由编译器和运行时库在用户态实现的一套“轻量级线程”框架。对比进程、线程与协程:进程(Process&a…...

PADS新手避坑指南:三种获取PCB封装的实战方法,别再傻傻画半天了
PADS新手避坑指南:三种获取PCB封装的实战方法,别再傻傻画半天了 刚接触PADS的工程师常会遇到这样的困境:面对一个需要封装的元件,要么花几小时从头绘制,要么在茫茫库文件中迷失方向。实际上,高效获取PCB封装…...