CUDA学习笔记(三)CUDA简介
本篇博文转载于https://www.cnblogs.com/1024incn/tag/CUDA/,仅用于学习。
前言
线程的组织形式对程序的性能影响是至关重要的,本篇博文主要以下面一种情况来介绍线程组织形式:
- 2D grid 2D block
线程索引
矩阵在memory中是row-major线性存储的:

在kernel里,线程的唯一索引非常有用,为了确定一个线程的索引,我们以2D为例:
- 线程和block索引
- 矩阵中元素坐标
- 线性global memory 的偏移
首先可以将thread和block索引映射到矩阵坐标:
ix = threadIdx.x + blockIdx.x * blockDim.x
iy = threadIdx.y + blockIdx.y * blockDim.y
之后可以利用上述变量计算线性地址:
idx = iy * nx + ix
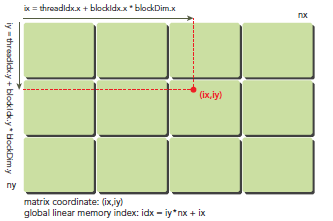
上图展示了block和thread索引,矩阵坐标以及线性地址之间的关系,谨记,相邻的thread拥有连续的threadIdx.x,也就是索引为(0,0)(1,0)(2,0)(3,0)...的thread连续,而不是(0,0)(0,1)(0,2)(0,3)...连续,跟我们线代里玩矩阵的时候不一样。
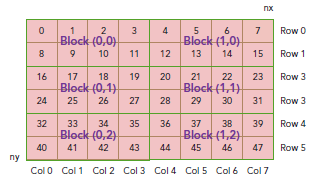
现在可以验证出下面的关系:
thread_id(2,1)block_id(1,0) coordinate(6,1) global index 14 ival 14
下图显示了三者之间的关系:
代码
int main(int argc, char **argv) {printf("%s Starting...\n", argv[0]);// set up deviceint dev = 0;cudaDeviceProp deviceProp;CHECK(cudaGetDeviceProperties(&deviceProp, dev));printf("Using Device %d: %s\n", dev, deviceProp.name);CHECK(cudaSetDevice(dev)); // set up date size of matrixint nx = 1<<14;int ny = 1<<14;int nxy = nx*ny;int nBytes = nxy * sizeof(float);printf("Matrix size: nx %d ny %d\n",nx, ny);// malloc host memoryfloat *h_A, *h_B, *hostRef, *gpuRef;h_A = (float *)malloc(nBytes);h_B = (float *)malloc(nBytes);hostRef = (float *)malloc(nBytes);gpuRef = (float *)malloc(nBytes);// initialize data at host sidedouble iStart = cpuSecond();initialData (h_A, nxy);initialData (h_B, nxy);double iElaps = cpuSecond() - iStart;memset(hostRef, 0, nBytes);memset(gpuRef, 0, nBytes);// add matrix at host side for result checksiStart = cpuSecond();sumMatrixOnHost (h_A, h_B, hostRef, nx,ny);iElaps = cpuSecond() - iStart;// malloc device global memoryfloat *d_MatA, *d_MatB, *d_MatC;cudaMalloc((void **)&d_MatA, nBytes);cudaMalloc((void **)&d_MatB, nBytes);cudaMalloc((void **)&d_MatC, nBytes);// transfer data from host to devicecudaMemcpy(d_MatA, h_A, nBytes, cudaMemcpyHostToDevice);cudaMemcpy(d_MatB, h_B, nBytes, cudaMemcpyHostToDevice);// invoke kernel at host sideint dimx = 32;int dimy = 32;dim3 block(dimx, dimy);dim3 grid((nx+block.x-1)/block.x, (ny+block.y-1)/block.y);iStart = cpuSecond();sumMatrixOnGPU2D <<< grid, block >>>(d_MatA, d_MatB, d_MatC, nx, ny);cudaDeviceSynchronize();iElaps = cpuSecond() - iStart;printf("sumMatrixOnGPU2D <<<(%d,%d), (%d,%d)>>> elapsed %f sec\n", grid.x,grid.y, block.x, block.y, iElaps);// copy kernel result back to host sidecudaMemcpy(gpuRef, d_MatC, nBytes, cudaMemcpyDeviceToHost);// check device resultscheckResult(hostRef, gpuRef, nxy);// free device global memorycudaFree(d_MatA);cudaFree(d_MatB);cudaFree(d_MatC);// free host memoryfree(h_A);free(h_B);free(hostRef);free(gpuRef);// reset devicecudaDeviceReset();return (0);
}编译运行:
$ nvcc -arch=sm_20 sumMatrixOnGPU-2D-grid-2D-block.cu -o matrix2D $ ./matrix2D
输出:
./a.out Starting... Using Device 0: Tesla M2070 Matrix size: nx 16384 ny 16384 sumMatrixOnGPU2D <<<(512,512), (32,32)>>> elapsed 0.060323 sec Arrays match.
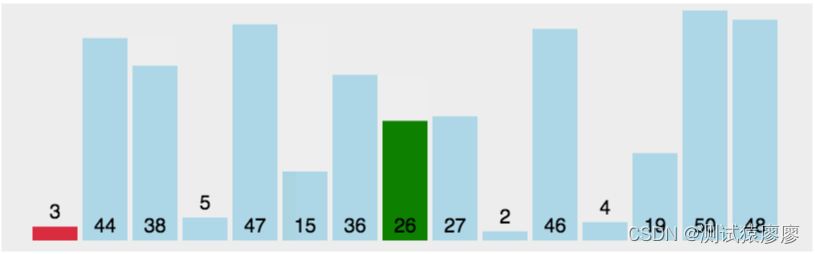
接下来,我们更改block配置为32x16,重新编译,输出为:
sumMatrixOnGPU2D <<<(512,1024), (32,16)>>> elapsed 0.038041 sec
可以看到,性能提升了一倍,直观的来看,我们会认为第二个配置比第一个多了一倍的block所以性能提升一倍,实际上也确实是因为block增加了。但是,如果你继续增加block的数量,则性能又会降低:
sumMatrixOnGPU2D <<< (1024,1024), (16,16) >>> elapsed 0.045535 sec
下图展示了不同配置的性能;

关于性能的分析将在之后的博文中总结,现在只是了解下,本文在于掌握线程组织的方法。
相关文章:
CUDA学习笔记(三)CUDA简介
本篇博文转载于https://www.cnblogs.com/1024incn/tag/CUDA/,仅用于学习。 前言 线程的组织形式对程序的性能影响是至关重要的,本篇博文主要以下面一种情况来介绍线程组织形式: 2D grid 2D block 线程索引 矩阵在memory中是row-major线性…...
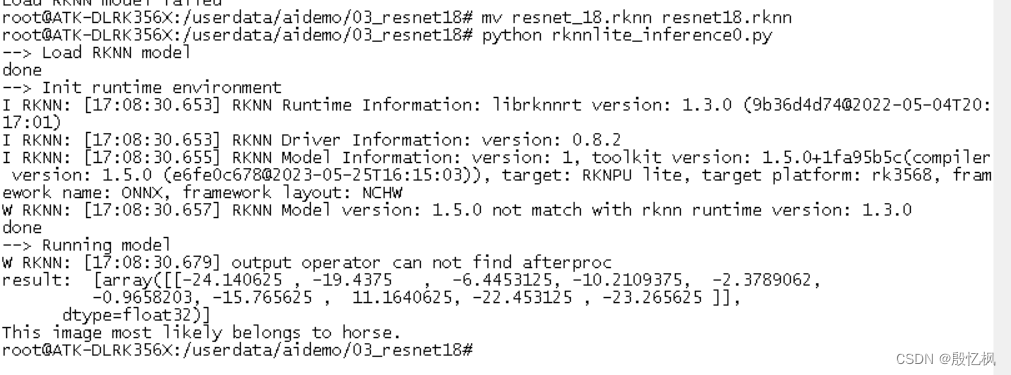
RK3568笔记三:基于ResNet18的Cifar-10分类识别训练部署
若该文为原创文章,转载请注明原文出处。 本篇文章参考的是野火-lubancat的rk3568教程,本篇记录了在正点原子的ATK-DLK3568部署。 一、介绍 ResNet18 是一种卷积神经网络,它有 18 层深度,其中包括带有权重的卷积层和全连接层。它…...

块状数据结构学习笔记
分块 分块的思想和珂朵莉树很类似,就是把原序列分成若干个块,对块进行操作的奇妙思想。复杂度通常带根号。分块的块长也有讲究,通常对于大小为 n n n 的数组,取距离 n \sqrt n n 最近的 2 2 2 的幂数或直接取 n \sqrt n n…...
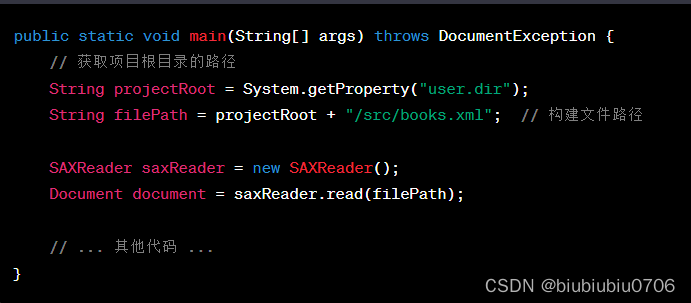
DOM4J解析.XML文件
<?xml version"1.0" encoding"utf-8" ?> <books><book id"SN123123413241"><name>java编程思想</name><author>华仔</author><price>9.9</price></book><book id"SN1234…...
黑豹程序员-架构师学习路线图-百科:MVC的演变终点SpringMVC
MVC发展史 在我们开发小型项目时,我们代码是混杂在一起的,术语称为紧耦合。 如最终写ASP、PHP。里面既包括服务器端代码,数据库操作的代码,又包括前端页面代码、HTML展现的代码、CSS美化的代码、JS交互的代码。可以看到早期编程就…...
二、BurpSuite Intruder暴力破解
一、介绍 解释: Burp Suite Intruder是一款功能强大的网络安全测试工具,它用于执行暴力破解攻击。它是Burp Suite套件的一部分,具有高度可定制的功能,能够自动化和批量化执行各种攻击,如密码破解、参数枚举和身份验证…...
solidworks 2024新功能之-让您的工作更加高效
您可以创建杰出的设计,并将这些杰出的设计将融入产品体验中。为了帮您简化和加快由概念到成品的产品开发流程,SOLIDWORKS 2024 涵盖全新的用户驱动型增强功能,致力于帮您实现更智能、更快速地与您的团队和外部合作伙伴协同工作。 SOLIDWORKS…...
华为eNSP配置专题-VRRP的配置
文章目录 华为eNSP配置专题-VRRP的配置0、参考文档1、前置环境1.1、宿主机1.2、eNSP模拟器 2、基本环境搭建2.1、基本终端构成和连接 2.VRRP的配置2.1、PC1的配置2.2、接入交换机acsw的配置2.3、核心交换机coresw1的配置2.4、核心交换机coresw2的配置2.5、配置VRRP2.6、配置出口…...
--lcd - lcd驱动模块)
LuatOS-SOC接口文档(air780E)--lcd - lcd驱动模块
常量 常量 类型 解释 lcd.font_opposansm8 font 8号字体 lcd.font_unifont_t_symbols font 符号字体 lcd.font_open_iconic_weather_6x_t font 天气字体 lcd.font_opposansm10 font 10号字体 lcd.font_opposansm12 font 12号字体 lcd.font_opposansm16 font…...
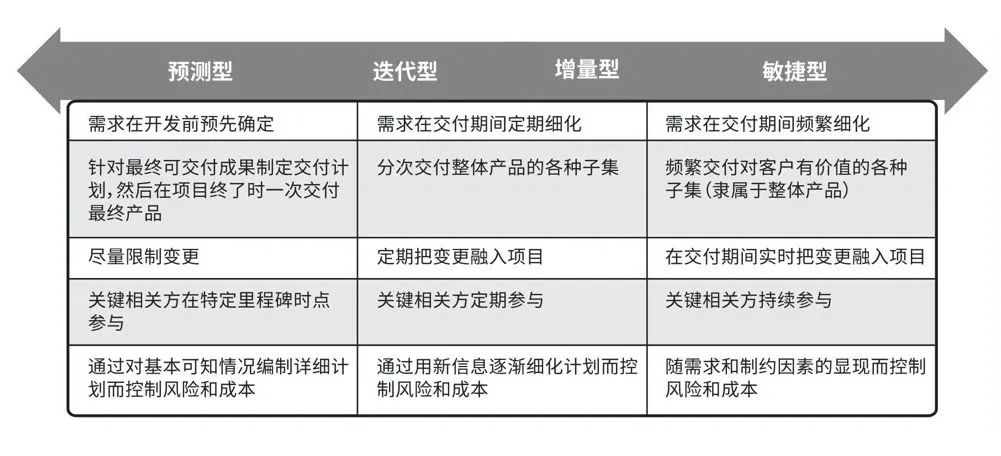
敏捷是怎么提高工作效率的
敏捷管理是一门极力减少不必要工作量的艺术。 谷歌、亚马逊、苹果、微信、京东等全球 500 强企业都在用的管理方法,适用于各行各业,被盛赞为应获“管理学的诺贝尔奖”。 它专注于让员工不受种种杂事的羁绊,激发个体斗志,释放出巨大…...

【C++】哈希的应用 -- 布隆过滤器
文章目录 一、布隆过滤器提出二、布隆过滤器概念三、布隆过滤器哈希函数个数的选择四、布隆过滤器的实现1.布隆过滤器的插入2.布隆过滤器的查找3.布隆过滤器删除4.完整代码实现 五、布隆过滤器总结1.布隆过滤器优点2.布隆过滤器缺陷3.布隆过滤器的应用4.布隆过滤器相关面试题 一…...

如何在Git中修改远程仓库地址
原文(可不登录复制代码):如何在Git中修改远程仓库地址-北的杂货间 Git是广泛使用的分布式版本控制系统,它允许开发者在本地仓库上工作,并将更改上传到远程仓库。然而,有时候你可能需要修改远程仓库的地址&…...
函数)
Go语言的sync.Once()函数
sync.Once 是 Go 语言标准库 sync 包提供的一个类型,它用于确保一个函数只会被执行一次,即使在多个 goroutine 中同时调用。 sync.Once 包含一个 Do 方法,其签名如下: func (o *Once) Do(f func()) Do 方法接受一个函数作为参数…...

修改 Stable Diffusion 使 api 接口增加模型参数
参考:https://zhuanlan.zhihu.com/p/644545784 1、修改 modules/api/models.py 中的 StableDiffusionTxt2ImgProcessingAPI 增加模型名称 StableDiffusionTxt2ImgProcessingAPI PydanticModelGenerator("StableDiffusionProcessingTxt2Img",StableDiff…...
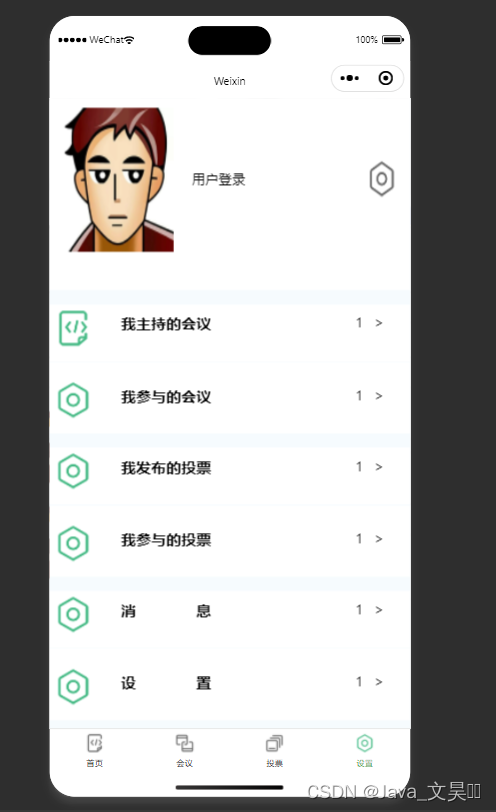
微信小程序自定义组件及会议管理与个人中心界面搭建
一、自定义tabs组件 1.1 创建自定义组件 新建一个components文件夹 --> tabs文件夹 --> tabs文件 创建好之后win7 以上的系统会报个错误:提示代码分析错误,已经被其他模块引用,只需要在 在project.config.json文件里添加两行配置 &…...
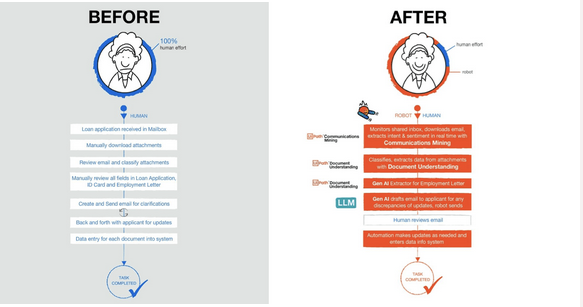
UiPath:一家由生成式AI驱动的流程自动化软件公司
来源:猛兽财经 作者:猛兽财经 总结: (1)UiPath(PATH)的股价并没有因为生成式AI的炒作而上涨,但很可能会成为主要受益者。 (2)即使在严峻的宏观环境下,UiPath的收入还在不…...

使用AI编写测试用例——详细教程
随着今年chatGPT的大热,每个行业都试图从这项新技术当中获得一些收益我之前也写过一篇测试领域在AI技术中的探索:软件测试中的AI——运用AI编写测试用例现阶段AI还不能完全替代人工测试用例编写,但是如果把AI当做一个提高效率的工具ÿ…...
又哭又笑,这份面试宝典要是早遇到就好了
01、算法原理 选择排序(Selection sort)是一种简单直观的排序算法。 第一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,然后再从剩余的未排序元素中寻找到最小(大)元素&#…...
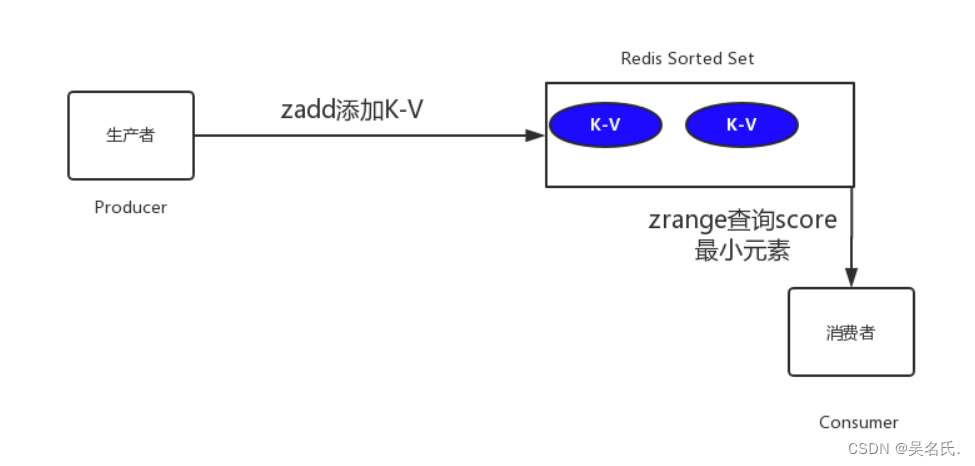
订单30分钟自动关闭的五种解决方案
1 前言 在开发中,往往会遇到一些关于延时任务的需求。例如 生成订单30分钟未支付,则自动取消生成订单60秒后,给用户发短信 对上述的任务,我们给一个专业的名字来形容,那就是延时任务 。那么这里就会产生一个问题,这…...

【vSphere 8 自签名 VMCA 证书】企业 CA 签名证书替换 vSphere VMCA CA 证书Ⅰ—— 生成 CSR
目录 替换拓扑图证书关系示意图说明 & 关联博文1. 默认证书截图2. 使用 certificate-manager 生成CSR2.1 创建存放CSR的目录2.2 记录PNID和IP2.3 生成CSR2.4 验证CSR 参考资料 替换拓扑图 证书关系示意图 本系列博文要实现的拓扑是 说明 & 关联博文 因为使用企业 …...

012、张量与数据布局:内存模型与对齐策略
012、张量与数据布局:内存模型与对齐策略 上周调一个卷积性能问题,在某个边缘设备上跑得比预期慢了三倍。用perf抓热点发现大量时间花在非对齐内存访问上——明明数据尺寸都是4的倍数,为什么还会不对齐?最后定位到问题:张量在内存中的布局和编译器假设的不一致,导致生成…...

7个简单步骤实现Windows系统级音频优化:Equalizer APO终极解决方案
7个简单步骤实现Windows系统级音频优化:Equalizer APO终极解决方案 【免费下载链接】equalizerapo Equalizer APO mirror 项目地址: https://gitcode.com/gh_mirrors/eq/equalizerapo 你是否厌倦了Windows系统音频平淡无奇的表现?游戏中的脚步声听…...

MATLAB 2020b 中文版安装避坑指南:断网、杀软、中文路径,一个都不能错
MATLAB 2020b 中文版安装避坑指南:断网、杀软、中文路径,一个都不能错 每次打开MATLAB都卡在启动界面?安装进度条走到99%就再也不动了?这些让人抓狂的问题,很可能是因为忽略了几个关键安装细节。作为一款功能强大的数学…...

5分钟搞定Unity游戏插件框架:BepInEx新手零基础入门指南
5分钟搞定Unity游戏插件框架:BepInEx新手零基础入门指南 【免费下载链接】BepInEx Unity / XNA game patcher and plugin framework 项目地址: https://gitcode.com/GitHub_Trending/be/BepInEx 还在为游戏功能单一而烦恼?想要为心爱的Unity游戏添…...
)
告别CAN总线?手把手教你用ISO 13400和DoIP实现车载远程诊断(附Python示例)
从CAN到以太网:基于ISO 13400的DoIP诊断实战指南 当传统CAN总线在带宽和远程诊断需求面前逐渐力不从心,车载以太网正以百兆甚至千兆的传输速率重塑车辆电子架构。作为诊断协议的新载体,DoIP(Diagnostic over Internet Protocol&am…...

你的小米路由器在‘隔离’设备吗?详解无线加密模式如何影响局域网互访
小米路由器无线加密模式对局域网互访的影响与解决方案 家里的小米路由器突然让所有设备"形同陌路"?明明连着同一个WiFi,手机传文件给电脑却像隔了堵墙,智能家居设备集体失联,甚至局域网游戏都卡在连接界面——这可能是路…...

从零复现RetinaNet:PyTorch环境搭建与COCO数据集实战避坑指南
1. 环境准备:从零搭建PyTorch开发环境 在Windows系统上搭建PyTorch环境就像组装一台新电脑——选对配件才能避免后续的兼容性问题。我建议使用Anaconda作为基础环境管理器,它能有效隔离不同项目的依赖关系。下面是我反复验证过的安装流程: 首…...

Allegro 17.4 + Samacsys Library Loader 避坑全记录:从安装到成功调用3D模型的完整流程
Allegro 17.4与Samacsys Library Loader深度整合实战:从安装到3D模型调用的完整避坑指南 作为一名长期使用Cadence Allegro进行PCB设计的工程师,我最近在尝试将Samacsys Library Loader与Allegro 17.4整合时,遭遇了一系列令人头疼的问题。从安…...

Claude Opus 4.7 相比 Opus4.6 关键改善总结
Claude Opus 4.7 相比之前的 4.6 版本,最核心的提升集中在视觉分辨率、自主编程能力以及指令遵循的严谨性。以下是关键改善点的详细总结: 1. 视觉能力的质跃 (Vision) 分辨率提升 3 倍:支持最高 2576px / 3.75MP 的图像,而 4.6 …...

如何通过d2s-editor实现暗黑破坏神2存档的全面自定义配置
如何通过d2s-editor实现暗黑破坏神2存档的全面自定义配置 【免费下载链接】d2s-editor 项目地址: https://gitcode.com/gh_mirrors/d2/d2s-editor d2s-editor是一款专为《暗黑破坏神2》玩家设计的开源存档编辑器,支持原版及重制版(D2R)存档文件的深度编辑。…...