论文阅读-多目标强化学习-envelope MOQ-learning
introduction
一种多目标强化学习算法,来自2019 Nips《A Generalized Algorithm for Multi-Objective Reinforcement Learning and Policy Adaptation》本文引用代码全部来源于论文中的链接。主要参考run_e3c_double.py文件
1 总体思想
1.将输入中加入多目标的偏好参数。 2. 在输出中改本为标量的状态价值为向量的状态价值。 3. 实现了可以在多个目标上寻找帕累托前沿,也即多目标最优解的算法。
2 算法
虽然论文中用的是Q-learning的架构,但是在提供的代码中,采用的是A3C的架构,使用envelope 网络作为价值网络,估计状态价值用于更新,所以接下来以代码为准,结合论文思想,展示用到的输入、输出和损失函数。

2.1 输入
以多目标马里奥环境为例,输入为连续四帧状态 S,随机采样的偏好w。w的值均为正数,且和为1,每一位的值,代表对该维目标的偏好大小。
2.2 输出
Actor 网络和Value网络共享同一个特征提取网络,Actor网络输出维度为所有可能动作数,Value网络输出维度为偏好的维度,也即多目标的目标维度数。
2.3 损失函数
2.3.1 Critic loss
mse = nn.MSELoss()critic_loss_l1 = mse(wvalue, wtarget)critic_loss_l2 = mse(value.view(-1), target_batch.view(-1))loss += 0.5 * (self.beta * critic_loss_l1 + (1-self.beta) * critic_loss_l2)Critic 网络的损失由critic loss1和critic loss2加权和组成,critic loss2 理解为多目标损失函数,即当Critic网络能够准确评估多目标状态时,所有pareto前沿上的点都满足critic loss2 为零。因此用梯度下降优化CL2显得不平滑且困难(因为它的解不止一个,而是很多个)。所以引入critic loss1 来减少这种不平滑,critic loss 1 是某种偏好下,critic网络的TD LOSS,因为偏好确定了,所以解只有一个,作者认为这样的损失函数更容易优化,更平滑。
操作上,wvalue和wtarget的唯独都是(batch_size, 1) ; 而 value和target的维度都是(batch_size,reward_size)。显然也是前者的优化更简单。
2.3.2 Actor loss
wadv_batch = torch.bmm(adv_batch.unsqueeze(1), w_batch.unsqueeze(2)).squeeze()
actor_loss = -m.log_prob(action_batch) * wadv_batchactor loss形式上和带基线的policy gradient的损失函数类似,只不过Critic网络输出的维度不是1而是reward_size,优势adv先与偏好权重w矩阵相乘,得到维度为1的优势adv后再输入actor loss中,这也说明actor loss 的优化方向是朝着使得当前偏好的期望回报最大的方向优化的。
2.4 更新方式
2.4.1 数据收集方式
论文中伪代码表示用类似Q-learning 离线更新的方式, 给出的代码中使用类A3C在线更新的方式,以下以代码为准。
在一个epsiode开始前,随机初始化一个preference,并用这个偏好贯穿这一幕,直至结束。
explore_w = generate_w(args.num_worker, pref_param)每一步,模型输入状态和偏好,输出动作
while True:actions = agent.get_action(states, explore_w)for parent_conn in parent_conns:s, r, d, rd, mor, sc = parent_conn.recv()将一幕中数据以此收齐后立即用于更新神经网络参数(因为A3C是在线算法,所以E3C也是在线)
2.4.2 参数更新方式
value, next_value, policy = agent.forward_transition(total_state, total_next_state, total_update_w)1.将收集到的状态,下一状态,偏好的序列输入网络,得到价值(5维)下一状态价值(5维)策略(和动作维度相同)
for idx in range(args.num_worker):target = make_train_data(args,total_moreward[idx*args.num_step+idw*ofs : (idx+1)*args.num_step+idw*ofs],total_done[idx*args.num_step+idw*ofs: (idx+1)*args.num_step+idw*ofs],value[idx*args.num_step+idw*ofs : (idx+1)*args.num_step+idw*ofs],next_value[idx*args.num_step+idw*ofs : (idx+1)*args.num_step+idw*ofs],reward_size)2.从最后一状态以此计算 TD-error中的taget,target = r+v(s'),target也是五维
> (ps:一直不知道为什么在线算法要从最后一步一直迭代倒推到第一步,都用r+γv(s')来做代表当前状态价值,导致第一个状态v(s0)=r0+γ*r1+γ**2+....+γ**nV(Sn),导致方差很大。为什么不每一步直接从价值网络导出,这样v(s0)=r0+v(s1),这样方差小的方法呢?很奇怪)
total_target, total_adv = envelope_operator(args, update_w, total_target, value, reward_size, global_step)3. 使用envelope operator函数对target做处理,在训练初期,只计算优势 adv = target - value,
在训练中后期用于从随机采样的多个偏好(代码默认八个偏好,总和维度为(8,5))中,挑选出能使target最大的一种偏好。和Q-learning中取q=r+qmax(s')有点像。[这里的reshape我也有点看不懂,此观点只做参考]
agent.train_model()
actor_loss = -m.log_prob(action_batch) * wadv_batch# Entropy(for more exploration)
entropy = m.entropy()# Critic lossmse = nn.MSELoss()
critic_loss_l1 = mse(wvalue, wtarget)
critic_loss_l2 = mse(value.view(-1), target_batch.view(-1))# Total loss (don't compute tempreture)loss = actor_loss.mean()loss += 0.5 * (self.beta * critic_loss_l1 + (1-self.beta) * critic_loss_l2)loss -= self.entropy_coef * entropy.mean()4.计算loss,反向传播。这一部分就很明了了,计算前面提到的几种loss,给与不同权重后反向传播,唯一特别注意的是,actor loss中使用的优势adv,不知出于什么理由,使用了优势向量与偏好向量做内积后的偏好,(可能是因为解唯一,优化方便)
5.其他注意事项:1、用于和环境交互的偏好并不被保存,更新参数时会重新抽样偏好,这样做有什么理论依据嘛?暂时还没想明白。
2.5 损失函数中偏好和输入网络偏好的关系
从伪代码,和代码中可见,在进行前向推导时输入网络的preference 和在训练时使用的preference并不是同一个。并且,前向时所用的preference并没有被replayer buffer记录下来。训练时actor 和 critic里用的偏好仍然是随机抽取的偏好。
3 其他bug和优化技巧
1.为达到论文所示的训练速度,需要使用简化后的Mario-v3环境,并且跳5帧。
2.由于A3C是异步算法,有多个环境并行采样,所以环境初始化的位置应在启动进程的代码之后,即在multiprocess的run函数之中再reset环境,否则会发生内存地址错误,找不到创造的环境的错误。
对于文中的问题,欢迎有不同见解的同学在评论区讨论交流学习,祝你学习愉快!
相关文章:
论文阅读-多目标强化学习-envelope MOQ-learning
introduction 一种多目标强化学习算法,来自2019 Nips《A Generalized Algorithm for Multi-Objective Reinforcement Learning and Policy Adaptation》本文引用代码全部来源于论文中的链接。主要参考run_e3c_double.py文件 1 总体思想 1.将输入中加入多目标的偏…...

【原创】【考法总结】指针*与++结合的题目考法总结
代码均已调试出结果,放心食用,大致总共5种考法 【理论铺垫】①a[i]恒等价于(ai)即*(&a[0]i);i类似偏移量(别忘a代表数组首元素地址即&a[0]) ②*(&a[i])恒等价于a[i]:&a[i]表示a[i]的地址&a…...
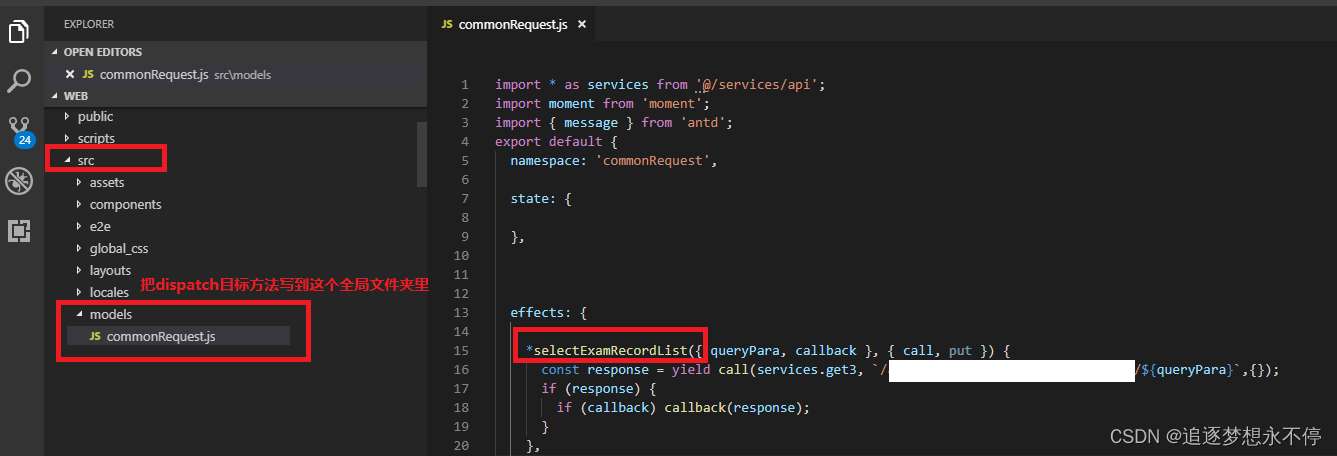
react dispatch不生效的坑
一、前言 最近写react antd项目,在A页面中使用了dispatch方法,然后B页面中嵌套A页面,没有问题; 但是在C页面中嵌套A页面的时候,就发现dispatch方法没有执行,也不报错,就很奇怪; 还…...
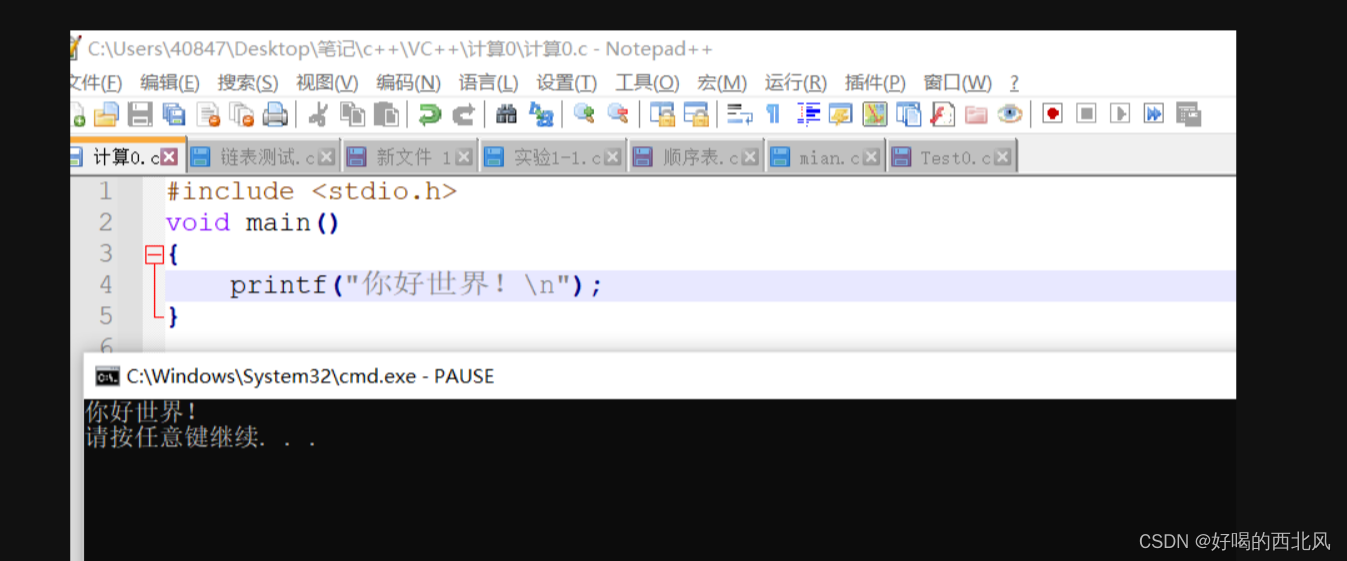
Mingw快捷安装教程 并完美解决出现的下载错误:The file has been downloaded incorrectly
安装c语言编译器的时候,老是出现The file has been downloaded incorrectly,真的让人 直接去官网拿压缩包:https://sourceforge.net/projects/mingw-w64/files/ (往下拉找到那个x86_64-win32-seh的链接,点击后会自动…...
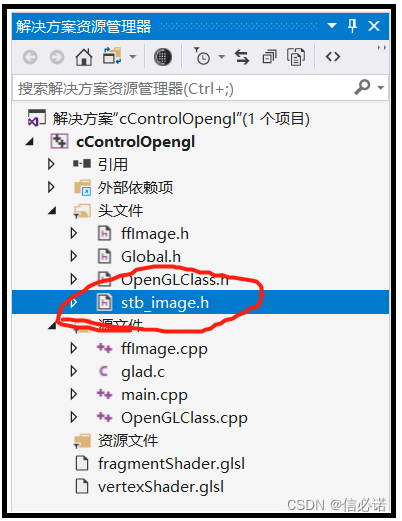
OpenGL —— 2.6、绘制一个正方体并贴图(附源码,glfw+glad)
源码效果 C源码 纹理图片 需下载stb_image.h这个解码图片的库,该库只有一个头文件。 具体代码: vertexShader.glsl #version 330 corelayout(location 0) in vec3 aPos; layout(location 1) in vec2 aUV;out vec2 outUV;uniform mat4 _viewMatrix; u…...

JavaWeb从入门到起飞笔记——导学课程
学完这一节,我不知道学Web开发究竟能干什么?你知道吗? 以下是黑马程序员Java从入门到起飞的笔记 一、学完Javaweb能干什么? 学完Java后我们可以独立开发一些后台管理系统,例如CRMER器,京东和淘宝&#x…...

【LeetCode:1402. 做菜顺序 | 动态规划 + 贪心】
🚀 算法题 🚀 🌲 算法刷题专栏 | 面试必备算法 | 面试高频算法 🍀 🌲 越难的东西,越要努力坚持,因为它具有很高的价值,算法就是这样✨ 🌲 作者简介:硕风和炜,…...

基于FPGA的图像拉普拉斯变换实现,包括tb测试文件和MATLAB辅助验证
目录 1.算法运行效果图预览 2.算法运行软件版本 3.部分核心程序 4.算法理论概述 5.算法完整程序工程 1.算法运行效果图预览 2.算法运行软件版本 matlab2022a vivado2019.2 3.部分核心程序 timescale 1ns / 1ps // // Company: // Engineer: // // Create Date: 202…...

高校教务系统登录页面JS分析——巢湖学院
高校教务系统密码加密逻辑及JS逆向 本文将介绍高校教务系统的密码加密逻辑以及使用JavaScript进行逆向分析的过程。通过本文,你将了解到密码加密的基本概念、常用加密算法以及如何通过逆向分析来破解密码。 本文仅供交流学习,勿用于非法用途。 一、密码加…...

人工智能、机器学习、深度学习的区别
人工智能涵盖范围最广,它包含了机器学习;而机器学习是人工智能的重要研究内容,它又包含了深度学习。 人工智能(AI) 人工智能是一门以计算机科学为基础,融合了数学、神经学、心理学、控制学等多个科目的交…...

Element Plus el-select选择框失去焦点blur
正常情况下,可以使用 el-select 自带的方法 blur 事件来使select失去焦点 示例: <el-select v-model"value" ref"selectRef"><el-optionv-for"item in options":key"item.value":label"item.la…...
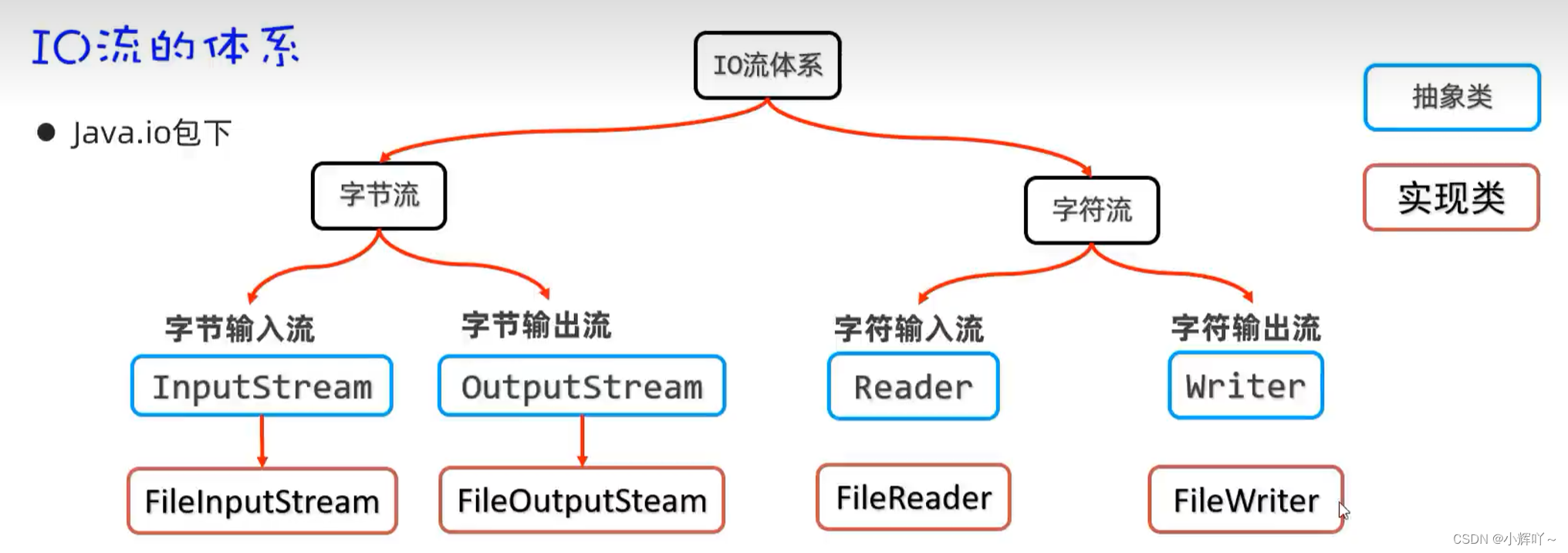
Java File与IO流学习笔记
内存中存放的都是临时数据,但是在断电或者程序终止时都会丢失 而硬盘则可以长久存储数据,即使断电,程序终止,也不会丢失 File File是java.io.包下的类,File类的对象,用于代表当前操作系统的文件(可以是文…...
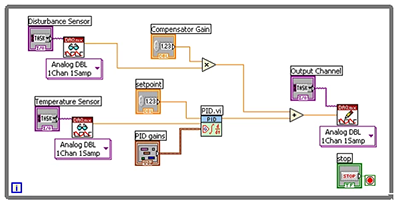
LabVIEW中PID控制的的高级功能
LabVIEW中PID控制的的高级功能 比例-积分-微分(PID)控制占当今控制和自动化应用的90%以上,主要是因为它是一种有效且简单的解决方案。虽然PID算法最初用于线性、时不变系统,但现在已经发展到控制具有复杂动力学的系统。在现实世界…...
STM32基于HAL库RT-Thread Demo测试
STM32基于HAL库RT-Thread Demo测试 🎈源码地址:https://github.com/RT-Thread/rt-thread/tree/master📌基于STM32CUBEMX中间件安装《基于 CubeMX 移植 RT-Thread Nano》📍环境搭建《使用 Env 创建 RT-Thread 项目工程》ǵ…...
找素数)
萌新小白必做题(2)找素数
一.思路分析 先来看看素数的性质: 素数又称质数,是指除了1和本身外没有其它因数的自然数。素数有许多有趣的性质和应用,例如可以用于加密算法和数学证明等。比如2、3、5、7等都是素数,而4、6、8、9等则不是素数。素数的研究是数…...
 目录(两种方式))
《基于 Vue 组件库 的 Webpack5 配置》8.在生成打包文件之前清空 output(dist) 目录(两种方式)
方式一 如果 webpack 是 v5.20.0,直接使用属性 output.clean,配置如下: module.exports {//...output: {clean: true}, };方式二 如果使用较低版本,可以使用插件 clean-webpack-plugin: 先安装:npm…...

3、Kafka Broker
4.1 Kafka Broker 工作流程 4.1.1 Zookeeper 存储的 Kafka 信息 (1)启动 Zookeeper 客户端。 [hadoop102 zookeeper-3.5.7]$ bin/zkCli.sh(2)通过 ls 命令可以查看 kafka 相关信息。 [zk: localhost:2181(CONNECTED) 2] ls /kaf…...

数字孪生智慧建筑可视化系统,提高施工效率和建造质量
随着科技的不断进步和数字化的快速发展,数字孪生成为了建筑行业的一个重要的概念,被广泛应用于智能化建筑的开发与管理中。数字孪生是将现实世界的实体与数字世界的虚拟模型进行连接和同步,从而实现实时的数据交互和模拟仿真。数字孪生在建筑…...
SpringCloud: feign整合sentinel实现降级
一、加依赖: <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0"xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation"http://maven.apache…...

List<LinkedHashMap<String, String>>类型的数据转换为Map<String, List<String>>类型数据
import java.util.*;public class Main {public static void main(String[] args) {// 示例数据:List<LinkedHashMap>List<LinkedHashMap<String, String>> keyParamList new ArrayList<>();LinkedHashMap<String, String> map1 ne…...

3步掌握Blender化学品插件:从分子结构到3D打印的终极指南
3步掌握Blender化学品插件:从分子结构到3D打印的终极指南 【免费下载链接】blender-chemicals Draws chemicals in Blender using common input formats (smiles, molfiles, cif files, etc.) 项目地址: https://gitcode.com/gh_mirrors/bl/blender-chemicals …...

开源无人机身份识别解决方案:ArduRemoteID完全指南
开源无人机身份识别解决方案:ArduRemoteID完全指南 【免费下载链接】ArduRemoteID RemoteID support using OpenDroneID 项目地址: https://gitcode.com/gh_mirrors/ar/ArduRemoteID 在无人机监管日益严格的今天,FAA RemoteID合规性已成为全球无人…...

OPC UA Client终极指南:快速实现工业自动化数据采集与监控
OPC UA Client终极指南:快速实现工业自动化数据采集与监控 【免费下载链接】opc-ua-client Visualize and control your enterprise using OPC Unified Architecture (OPC UA) and Visual Studio. 项目地址: https://gitcode.com/gh_mirrors/op/opc-ua-client …...

5大核心模块:重新定义英雄联盟游戏辅助体验
5大核心模块:重新定义英雄联盟游戏辅助体验 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit League Akari是一款基于LCU API开发的英…...

思源宋体TTF字体实战指南:5步解决中文排版核心难题
思源宋体TTF字体实战指南:5步解决中文排版核心难题 【免费下载链接】source-han-serif-ttf Source Han Serif TTF 项目地址: https://gitcode.com/gh_mirrors/so/source-han-serif-ttf 还在为中文排版效果不佳而烦恼吗?思源宋体TTF字体集或许就是…...

告别AI开发混乱:用Spec Workflow MCP + Cursor/Claude,实现从需求到代码的规范流水线
告别AI开发混乱:用Spec Workflow MCP Cursor/Claude实现规范化的需求到代码流水线 当你在深夜第12次修改同一个登录模块时,是否怀疑过AI辅助开发反而让工作变得更复杂?我们常陷入这样的循环:向AI助手抛出一句模糊的指令ÿ…...

WiFiAnalyzer深度解析:Android上不可或缺的Wi-Fi网络优化利器
1. WiFiAnalyzer:你的无线网络诊断专家 每次刷视频卡顿、游戏延迟飙升时,你是不是也对着路由器咬牙切齿?作为一款专为Android设计的开源工具,WiFiAnalyzer就像给手机装上了X光机,能透视周围所有Wi-Fi信号的"身体状…...
)
Nsight Systems实战:用命令行nsys profile分析Docker容器内的CUDA应用性能(附远程分析技巧)
Nsight Systems实战:用命令行nsys profile分析Docker容器内的CUDA应用性能(附远程分析技巧) 在容器化技术席卷开发领域的今天,如何高效分析运行在Docker环境中的CUDA应用性能成为工程师们必须掌握的技能。传统依赖GUI的性能分析工…...

中小企业本地部署即时通讯:预算有限怎么把功能配齐
对于员工规模在50人到300人之间的中小企业来说,本地部署即时通讯时,核心不是一味追求功能越多越好,而是要先解决三个现实问题:数据能不能放在自己服务器上,日常沟通和文件传输够不够稳定,以及整体部署成本能…...

实测DeepSeek-OCR-WEBUI:中文识别精准,复杂背景也能搞定
实测DeepSeek-OCR-WEBUI:中文识别精准,复杂背景也能搞定 1. 从“看不清”到“读得懂”的跨越 你有没有遇到过这样的场景?拍了一张会议白板的照片,上面的字迹有些潦草,背景还有各种投影仪的影子,想用手机上…...