3、Kafka Broker
4.1 Kafka Broker 工作流程
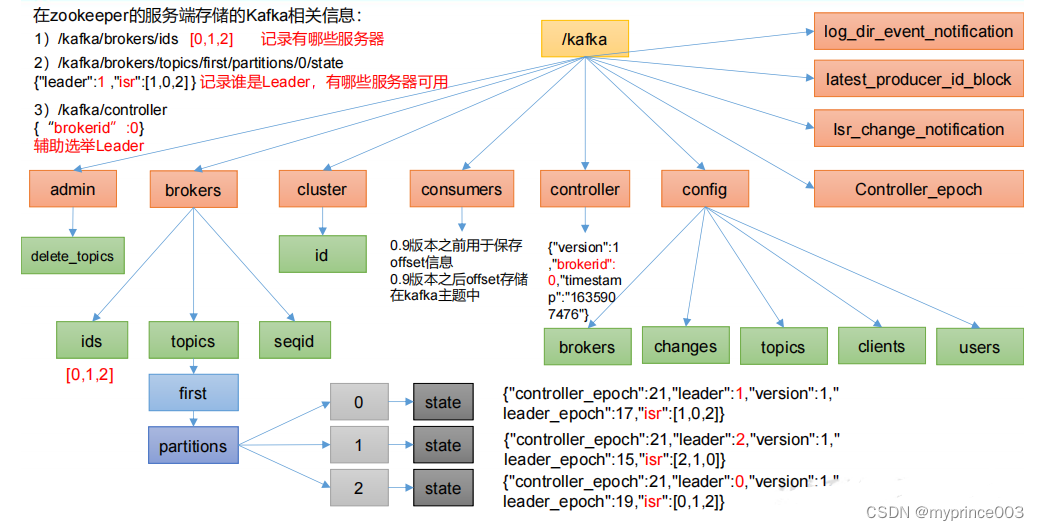
4.1.1 Zookeeper 存储的 Kafka 信息
(1)启动 Zookeeper 客户端。
[hadoop102 zookeeper-3.5.7]$ bin/zkCli.sh
(2)通过 ls 命令可以查看 kafka 相关信息。
[zk: localhost:2181(CONNECTED) 2] ls /kafka
4.1.2 Kafka Broker 总体工作流程
1)模拟 Kafka 上下线,Zookeeper 中数据变化
(1)查看/kafka/brokers/ids 路径上的节点。
[zk: localhost:2181(CONNECTED) 2] ls /kafka/brokers/ids
[0, 1, 2]
(2)查看/kafka/controller 路径上的数据。
[zk: localhost:2181(CONNECTED) 15] get /kafka/controller
{"version":1,"brokerid":0,"timestamp":"1637292471777"}
(3)查看/kafka/brokers/topics/first/partitions/0/state 路径上的数据
[zk: localhost:2181(CONNECTED) 16] get
/kafka/brokers/topics/first/partitions/0/state
{"controller_epoch":24,"leader":0,"version":1,"leader_epoch":18,"
isr":[0,1,2]}
(4)停止 hadoop104 上的 kafka。
[hadoop104 kafka]$ bin/kafka-server-stop.sh
(5)再次查看/kafka/brokers/ids 路径上的节点。
[zk: localhost:2181(CONNECTED) 3] ls /kafka/brokers/ids
[0, 1]
(6)再次查看/kafka/controller 路径上的数据。
[zk: localhost:2181(CONNECTED) 15] get /kafka/controller
{"version":1,"brokerid":0,"timestamp":"1637292471777"}
(7)再次查看/kafka/brokers/topics/first/partitions/0/state 路径上的数据。
[zk: localhost:2181(CONNECTED) 16] get
/kafka/brokers/topics/first/partitions/0/state
{"controller_epoch":24,"leader":0,"version":1,"leader_epoch":18,"
isr":[0,1]}
(8)启动 hadoop104 上的 kafka。
[hadoop104 kafka]$ bin/kafka-server-start.sh -
daemon ./config/server.properties
(9)再次观察(1)、(2)、(3)步骤中的内容
4.1.3 Broker 重要参数

2. 节点服役和退役
2.1 服役新节点
1)新节点准备
(1)关闭 hadoop104,并右键执行克隆操作。
(2)开启 hadoop105,并修改 IP 地址。
[root@hadoop104 ~]# vim /etc/sysconfig/network-scripts/ifcfgens33
DEVICE=ens33
TYPE=Ethernet
ONBOOT=yes
BOOTPROTO=static
NAME="ens33"
IPADDR=192.168.10.105
PREFIX=24
GATEWAY=192.168.10.2
DNS1=192.168.10.2
(3)在 hadoop105 上,修改主机名称为 hadoop105。
[root@hadoop104 ~]# vim /etc/hostname
hadoop105
(4)重新启动 hadoop104、hadoop105。
(5)修改 haodoop105 中 kafka 的 broker.id 为 3。
(6)删除 hadoop105 中 kafka 下的 datas 和 logs。
[hadoop105 kafka]$ rm -rf datas/* logs/*
(7)启动 hadoop102、hadoop103、hadoop104 上的 kafka 集群。
[hadoop102 ~]$ zk.sh start
[hadoop102 ~]$ kf.sh start
(8)单独启动 hadoop105 中的 kafka。
[hadoop105 kafka]$ bin/kafka-server-start.sh -
daemon ./config/server.properties
2)执行负载均衡操作
(1)创建一个要均衡的主题。
[hadoop102 kafka]$ vim topics-to-move.json
{"topics": [{"topic": "first"}],"version": 1
}
(2)生成一个负载均衡的计划。
[hadoop102 kafka]$ bin/kafka-reassign-partitions.sh --
bootstrap-server hadoop102:9092 --topics-to-move-json-file
topics-to-move.json --broker-list "0,1,2,3" --generate
Current partition replica assignment
{"version":1,"partitions":[{"topic":"first","partition":0,"replic
as":[0,2,1],"log_dirs":["any","any","any"]},{"topic":"first","par
tition":1,"replicas":[2,1,0],"log_dirs":["any","any","any"]},{"to
pic":"first","partition":2,"replicas":[1,0,2],"log_dirs":["any","
any","any"]}]}
Proposed partition reassignment configuration
{"version":1,"partitions":[{"topic":"first","partition":0,"replic
as":[2,3,0],"log_dirs":["any","any","any"]},{"topic":"first","par
tition":1,"replicas":[3,0,1],"log_dirs":["any","any","any"]},{"to
pic":"first","partition":2,"replicas":[0,1,2],"log_dirs":["any","
any","any"]}]}
(3)创建副本存储计划(所有副本存储在 broker0、broker1、broker2、broker3 中)。
[hadoop102 kafka]$ vim increase-replication-factor.json
输入如下内容:
{"version":1,"partitions":[{"topic":"first","partition":0,"replic
as":[2,3,0],"log_dirs":["any","any","any"]},{"topic":"first","par
tition":1,"replicas":[3,0,1],"log_dirs":["any","any","any"]},{"to
pic":"first","partition":2,"replicas":[0,1,2],"log_dirs":["any","
any","any"]}]}
(4)执行副本存储计划。
[atguigu@hadoop102 kafka]$ bin/kafka-reassign-partitions.sh –
bootstrap-server hadoop102:9092 --reassignment-json-file
increase-replication-factor.json --execute
(5)验证副本存储计划。
[hadoop102 kafka]$ bin/kafka-reassign-partitions.sh --
bootstrap-server hadoop102:9092 --reassignment-json-file
increase-replication-factor.json --verify
Status of partition reassignment:
Reassignment of partition first-0 is complete.
Reassignment of partition first-1 is complete.
Reassignment of partition first-2 is complete.
Clearing broker-level throttles on brokers 0,1,2,3
Clearing topic-level throttles on topic first
4.2.2 退役旧节点
1)执行负载均衡操作
先按照退役一台节点,生成执行计划,然后按照服役时操作流程执行负载均衡。
(1)创建一个要均衡的主题。
[hadoop102 kafka]$ vim topics-to-move.json
{"topics": [{"topic": "first"}],"version": 1
}
(2)创建执行计划。
[hadoop102 kafka]$ bin/kafka-reassign-partitions.sh --
bootstrap-server hadoop102:9092 --topics-to-move-json-file
topics-to-move.json --broker-list "0,1,2" --generate
Current partition replica assignment
{"version":1,"partitions":[{"topic":"first","partition":0,"replic
as":[2,0,1],"log_dirs":["any","any","any"]},{"topic":"first","par
tition":1,"replicas":[3,1,2],"log_dirs":["any","any","any"]},{"to
pic":"first","partition":2,"replicas":[0,2,3],"log_dirs":["any","
any","any"]}]}
Proposed partition reassignment configuration
{"version":1,"partitions":[{"topic":"first","partition":0,"replic
as":[2,0,1],"log_dirs":["any","any","any"]},{"topic":"first","par
tition":1,"replicas":[0,1,2],"log_dirs":["any","any","any"]},{"to
pic":"first","partition":2,"replicas":[1,2,0],"log_dirs":["any","
any","any"]}]}
(3)创建副本存储计划(所有副本存储在 broker0、broker1、broker2 中)。
[hadoop102 kafka]$ vim increase-replication-factor.json
{"version":1,"partitions":[{"topic":"first","partition":0,"replic
as":[2,0,1],"log_dirs":["any","any","any"]},{"topic":"first","par
tition":1,"replicas":[0,1,2],"log_dirs":["any","any","any"]},{"to
pic":"first","partition":2,"replicas":[1,2,0],"log_dirs":["any","
any","any"]}]}
(4)执行副本存储计划。
[hadoop102 kafka]$ bin/kafka-reassign-partitions.sh --
bootstrap-server hadoop102:9092 --reassignment-json-file
increase-replication-factor.json --execute
(5)验证副本存储计划。
[hadoop102 kafka]$ bin/kafka-reassign-partitions.sh --
bootstrap-server hadoop102:9092 --reassignment-json-file
increase-replication-factor.json --verify
Status of partition reassignment:
Reassignment of partition first-0 is complete.
Reassignment of partition first-1 is complete.
Reassignment of partition first-2 is complete.
Clearing broker-level throttles on brokers 0,1,2,3
Clearing topic-level throttles on topic first
2)执行停止命令
在 hadoop105 上执行停止命令即可。
[hadoop105 kafka]$ bin/kafka-server-stop.sh
4.3 Kafka 副本
4.3.1 副本基本信息
(1)Kafka 副本作用:提高数据可靠性。
(2)Kafka 默认副本 1 个,生产环境一般配置为 2 个,保证数据可靠性;太多副本会
增加磁盘存储空间,增加网络上数据传输,降低效率。
(3)Kafka 中副本分为:Leader 和 Follower。Kafka 生产者只会把数据发往 Leader,
然后 Follower 找 Leader 进行同步数据。
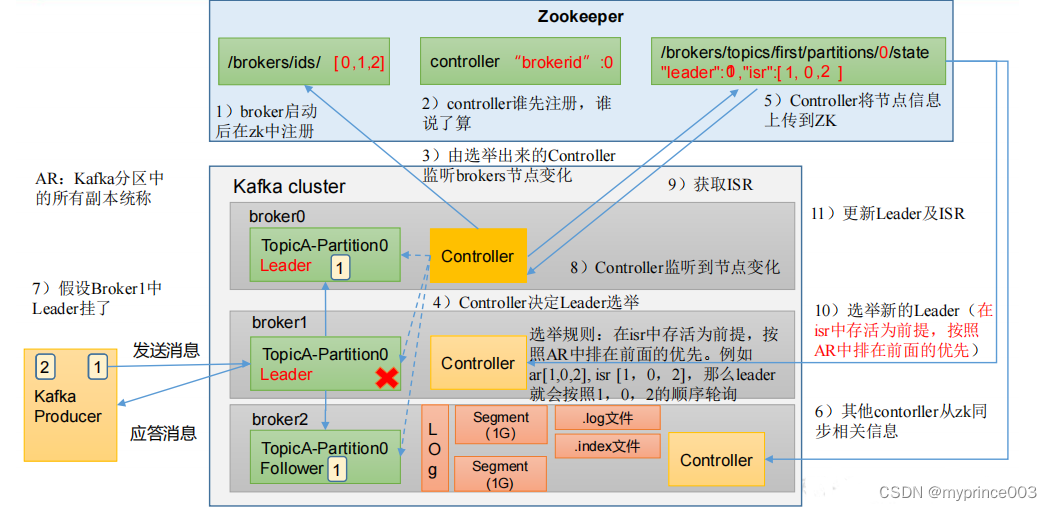
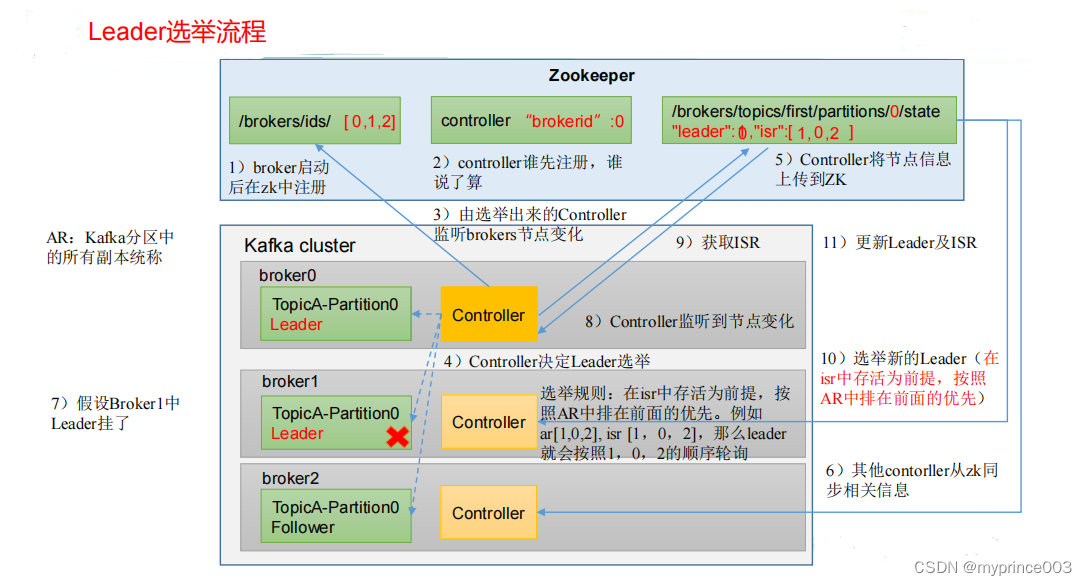
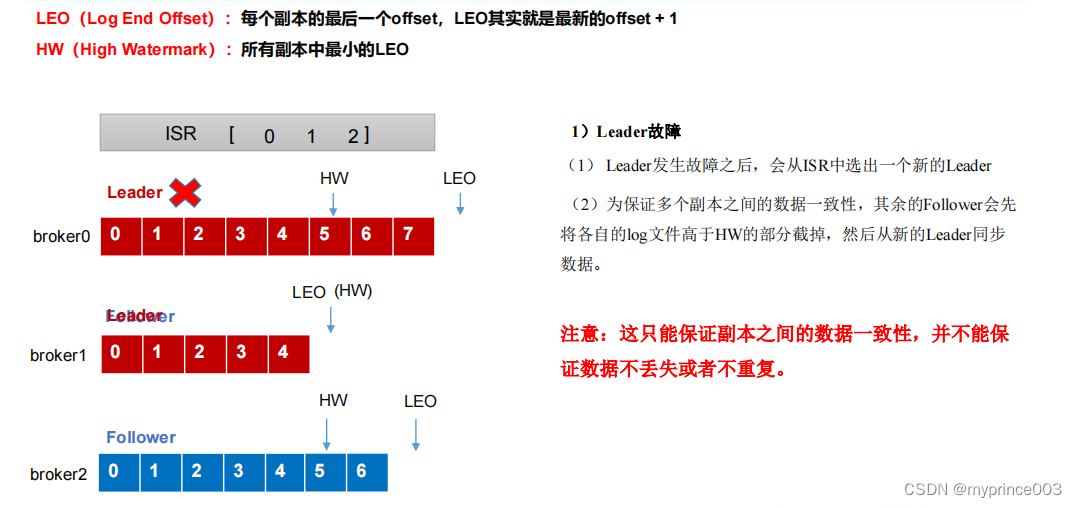
(4)Kafka 分区中的所有副本统称为 AR(Assigned Repllicas)。
AR = ISR + OSR
ISR,表示和 Leader 保持同步的 Follower 集合。如果 Follower 长时间未向 Leader 发送
通信请求或同步数据,则该 Follower 将被踢出 ISR。该时间阈值由 replica.lag.time.max.ms
参数设定,默认 30s。Leader 发生故障之后,就会从 ISR 中选举新的 Leader。
OSR,表示 Follower 与 Leader 副本同步时,延迟过多的副本。
4.3.2 Leader 选举流程
Kafka 集群中有一个 broker 的 Controller 会被选举为 Controller Leader,负责管理集群
broker 的上下线,所有 topic 的分区副本分配和 Leader 选举等工作。
Controller 的信息同步工作是依赖于 Zookeeper 的
(1)创建一个新的 topic,4 个分区,4 个副本
[hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server
hadoop102:9092 --create --topic atguigu1 --partitions 4 --replication-factor
4
Created topic atguigu1.
(2)查看 Leader 分布情况
[hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --describe
--topic atguigu1
Topic: atguigu1 TopicId: awpgX_7WR-OX3Vl6HE8sVg PartitionCount: 4 ReplicationFactor: 4
Configs: segment.bytes=1073741824
Topic: atguigu1 Partition: 0 Leader: 3 Replicas: 3,0,2,1 Isr: 3,0,2,1
Topic: atguigu1 Partition: 1 Leader: 1 Replicas: 1,2,3,0 Isr: 1,2,3,0
Topic: atguigu1 Partition: 2 Leader: 0 Replicas: 0,3,1,2 Isr: 0,3,1,2
Topic: atguigu1 Partition: 3 Leader: 2 Replicas: 2,1,0,3 Isr: 2,1,0,3
(3)停止掉 hadoop105 的 kafka 进程,并查看 Leader 分区情况
[hadoop105 kafka]$ bin/kafka-server-stop.sh
[hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --describe
--topic atguigu1
Topic: atguigu1 TopicId: awpgX_7WR-OX3Vl6HE8sVg PartitionCount: 4 ReplicationFactor: 4
Configs: segment.bytes=1073741824
Topic: atguigu1 Partition: 0 Leader: 0 Replicas: 3,0,2,1 Isr: 0,2,1
pic: atguigu1 Partition: 1 Leader: 1 Replicas: 1,2,3,0 Isr: 1,2,0
Topic: atguigu1 Partition: 2 Leader: 0 Replicas: 0,3,1,2 Isr: 0,1,2
Topic: atguigu1 Partition: 3 Leader: 2 Replicas: 2,1,0,3 Isr: 2,1,0
(4)停止掉 hadoop104 的 kafka 进程,并查看 Leader 分区情况
[hadoop104 kafka]$ bin/kafka-server-stop.sh
[hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --describe
--topic atguigu1
Topic: atguigu1 TopicId: awpgX_7WR-OX3Vl6HE8sVg PartitionCount: 4 ReplicationFactor: 4
Configs: segment.bytes=1073741824
Topic: atguigu1 Partition: 0 Leader: 0 Replicas: 3,0,2,1 Isr: 0,1
Topic: atguigu1 Partition: 1 Leader: 1 Replicas: 1,2,3,0 Isr: 1,0
Topic: atguigu1 Partition: 2 Leader: 0 Replicas: 0,3,1,2 Isr: 0,1
Topic: atguigu1 Partition: 3 Leader: 1 Replicas: 2,1,0,3 Isr: 1,0
(5)启动 hadoop105 的 kafka 进程,并查看 Leader 分区情况
[hadoop105 kafka]$ bin/kafka-server-start.sh -daemon config/server.properties
[hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --describe
--topic atguigu1
Topic: atguigu1 TopicId: awpgX_7WR-OX3Vl6HE8sVg PartitionCount: 4 ReplicationFactor: 4
Configs: segment.bytes=1073741824
Topic: atguigu1 Partition: 0 Leader: 0 Replicas: 3,0,2,1 Isr: 0,1,3
Topic: atguigu1 Partition: 1 Leader: 1 Replicas: 1,2,3,0 Isr: 1,0,3
Topic: atguigu1 Partition: 2 Leader: 0 Replicas: 0,3,1,2 Isr: 0,1,3
Topic: atguigu1 Partition: 3 Leader: 1 Replicas: 2,1,0,3 Isr: 1,0,3
(6)启动 hadoop104 的 kafka 进程,并查看 Leader 分区情况
[hadoop104 kafka]$ bin/kafka-server-start.sh -daemon config/server.properties
[hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --describe
--topic atguigu1
Topic: atguigu1 TopicId: awpgX_7WR-OX3Vl6HE8sVg PartitionCount: 4 ReplicationFactor: 4
Configs: segment.bytes=1073741824
Topic: atguigu1 Partition: 0 Leader: 0 Replicas: 3,0,2,1 Isr: 0,1,3,2
Topic: atguigu1 Partition: 1 Leader: 1 Replicas: 1,2,3,0 Isr: 1,0,3,2
Topic: atguigu1 Partition: 2 Leader: 0 Replicas: 0,3,1,2 Isr: 0,1,3,2
Topic: atguigu1 Partition: 3 Leader: 1 Replicas: 2,1,0,3 Isr: 1,0,3,2
(7)停止掉 hadoop103 的 kafka 进程,并查看 Leader 分区情况
[hadoop103 kafka]$ bin/kafka-server-stop.sh
[hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --describe
--topic atguigu1
Topic: atguigu1 TopicId: awpgX_7WR-OX3Vl6HE8sVg PartitionCount: 4 ReplicationFactor: 4
Configs: segment.bytes=1073741824
Topic: atguigu1 Partition: 0 Leader: 0 Replicas: 3,0,2,1 Isr: 0,3,2
Topic: atguigu1 Partition: 1 Leader: 2 Replicas: 1,2,3,0 Isr: 0,3,2
Topic: atguigu1 Partition: 2 Leader: 0 Replicas: 0,3,1,2 Isr: 0,3,2
Topic: atguigu1 Partition: 3 Leader: 2 Replicas: 2,1,0,3 Isr: 0,3,2
4.3.3 Leader 和 Follower 故障处理细节

4.3.4 分区副本分配
如果 kafka 服务器只有 4 个节点,那么设置 kafka 的分区数大于服务器台数,在 kafka
底层如何分配存储副本呢?
1)创建 16 分区,3 个副本
(1)创建一个新的 topic,名称为 second。
[hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server
hadoop102:9092 --create --partitions 16 --replication-factor 3 --
topic second
(2)查看分区和副本情况。
[hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server
hadoop102:9092 --describe --topic second
Topic: second4 Partition: 0 Leader: 0 Replicas: 0,1,2 Isr: 0,1,2
Topic: second4 Partition: 1 Leader: 1 Replicas: 1,2,3 Isr: 1,2,3
Topic: second4 Partition: 2 Leader: 2 Replicas: 2,3,0 Isr: 2,3,0
Topic: second4 Partition: 3 Leader: 3 Replicas: 3,0,1 Isr: 3,0,1
Topic: second4 Partition: 4 Leader: 0 Replicas: 0,2,3 Isr: 0,2,3
Topic: second4 Partition: 5 Leader: 1 Replicas: 1,3,0 Isr: 1,3,0
Topic: second4 Partition: 6 Leader: 2 Replicas: 2,0,1 Isr: 2,0,1
Topic: second4 Partition: 7 Leader: 3 Replicas: 3,1,2 Isr: 3,1,2
Topic: second4 Partition: 8 Leader: 0 Replicas: 0,3,1 Isr: 0,3,1
Topic: second4 Partition: 9 Leader: 1 Replicas: 1,0,2 Isr: 1,0,2
Topic: second4 Partition: 10 Leader: 2 Replicas: 2,1,3 Isr: 2,1,3
Topic: second4 Partition: 11 Leader: 3 Replicas: 3,2,0 Isr: 3,2,0
Topic: second4 Partition: 12 Leader: 0 Replicas: 0,1,2 Isr: 0,1,2
Topic: second4 Partition: 13 Leader: 1 Replicas: 1,2,3 Isr: 1,2,3
Topic: second4 Partition: 14 Leader: 2 Replicas: 2,3,0 Isr: 2,3,0
Topic: second4 Partition: 15 Leader: 3 Replicas: 3,0,1 Isr: 3,0,1
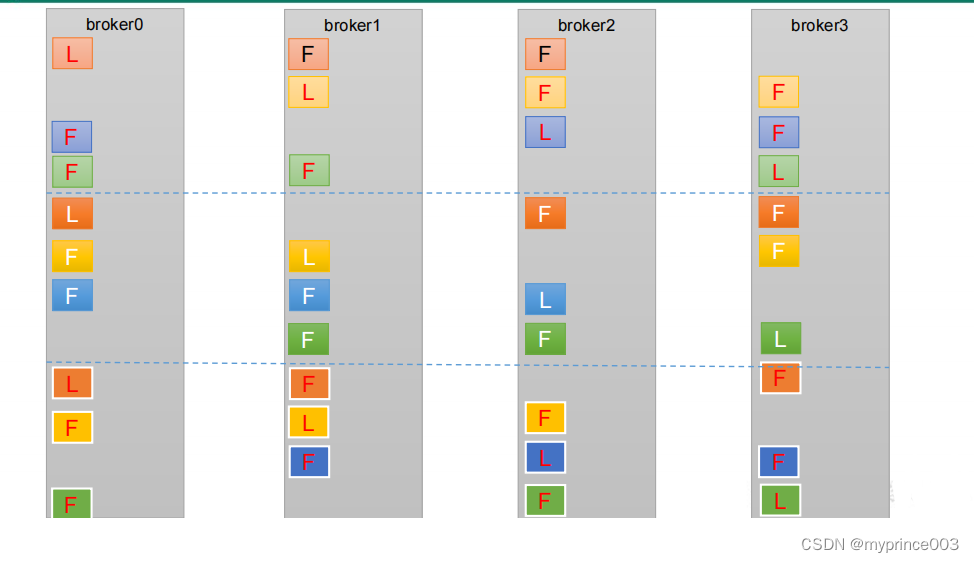
4.3.5 生产经验——手动调整分区副本存储
生产经验——手动调整分区副本存储
在生产环境中,每台服务器的配置和性能不一致,但是Kafka只会根据自己的代码规则创建对应的分区副
本,就会导致个别服务器存储压力较大。所有需要手动调整分区副本的存储。
需求:创建一个新的topic,4个分区,两个副本,名称为three。将 该topic的所有副本都存储到broker0和
broker1两台服务器上。
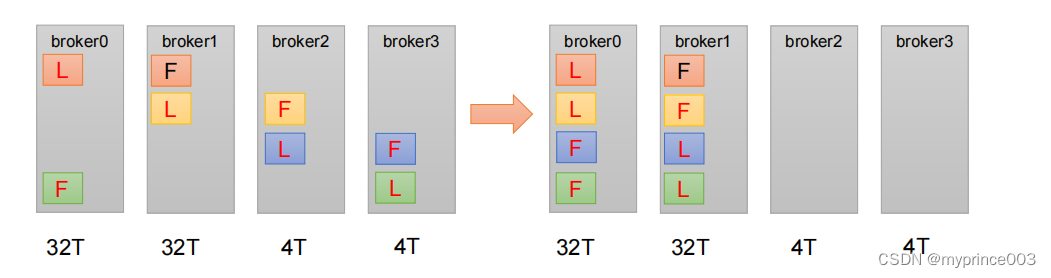
手动调整分区副本存储的步骤如下:
(1)创建一个新的 topic,名称为 three。
[hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server
hadoop102:9092 --create --partitions 4 --replication-factor 2 --
topic three
(2)查看分区副本存储情况。
[hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server
hadoop102:9092 --describe --topic three
(3)创建副本存储计划(所有副本都指定存储在 broker0、broker1 中)。
[hadoop102 kafka]$ vim increase-replication-factor.json
输入如下内容:
{
"version":1,
"partitions":[{"topic":"three","partition":0,"replicas":[0,1]},
{"topic":"three","partition":1,"replicas":[0,1]},
{"topic":"three","partition":2,"replicas":[1,0]},
{"topic":"three","partition":3,"replicas":[1,0]}]
}
(4)执行副本存储计划。
[hadoop102 kafka]$ bin/kafka-reassign-partitions.sh --
bootstrap-server hadoop102:9092 --reassignment-json-file
increase-replication-factor.json --execute
(5)验证副本存储计划。
[hadoop102 kafka]$ bin/kafka-reassign-partitions.sh --
bootstrap-server hadoop102:9092 --reassignment-json-file
increase-replication-factor.json --verify
(6)查看分区副本存储情况。
[hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server
hadoop102:9092 --describe --topic three
4.3.6 生产经验——Leader Partition 负载平衡

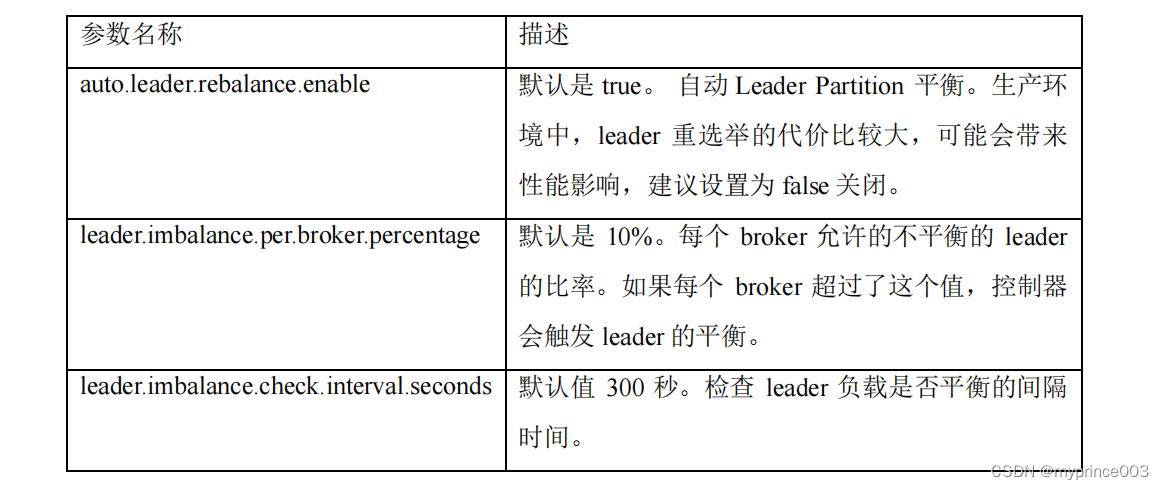
4.3.7 生产经验——增加副本因子
在生产环境当中,由于某个主题的重要等级需要提升,我们考虑增加副本。副本数的
增加需要先制定计划,然后根据计划执行。
1)创建 topic
[hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server
hadoop102:9092 --create --partitions 3 --replication-factor 1 --
topic four
2)手动增加副本存储
(1)创建副本存储计划(所有副本都指定存储在 broker0、broker1、broker2 中)。
[hadoop102 kafka]$ vim increase-replication-factor.json
输入如下内容:
{"version":1,"partitions":[{"topic":"four","partition":0,"replica
s":[0,1,2]},{"topic":"four","partition":1,"replicas":[0,1,2]},{"t
opic":"four","partition":2,"replicas":[0,1,2]}]}
(2)执行副本存储计划。
[hadoop102 kafka]$ bin/kafka-reassign-partitions.sh --
bootstrap-server hadoop102:9092 --reassignment-json-file
increase-replication-factor.json --execute
4.4 文件存储
4.4.1 文件存储机制
1)Topic 数据的存储机制
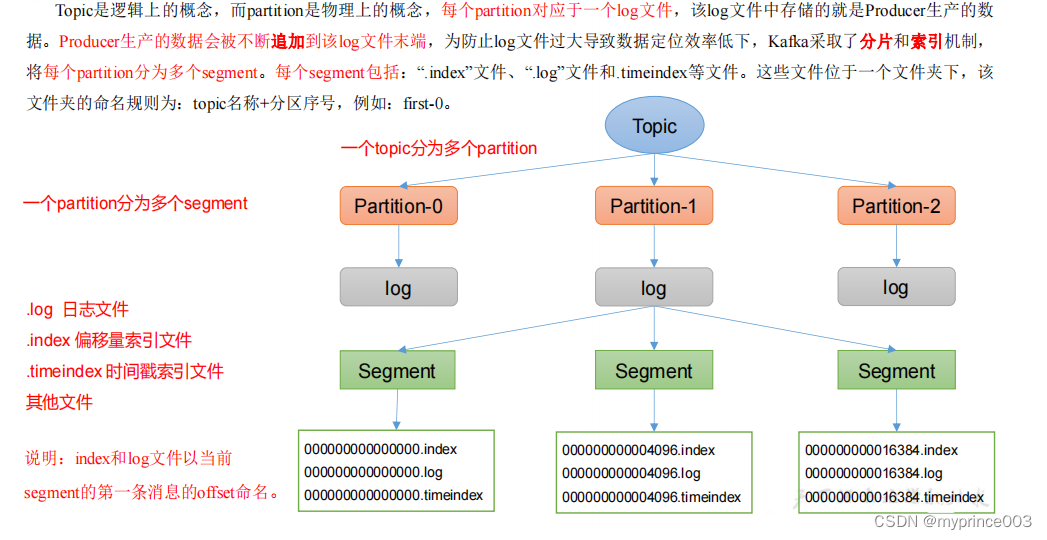
2)思考:Topic 数据到底存储在什么位置?
(1)启动生产者,并发送消息。
[hadoop102 kafka]$ bin/kafka-console-producer.sh --
bootstrap-server hadoop102:9092 --topic first
>hello world(2)查看 hadoop102(或者 hadoop103、hadoop104)的/opt/module/kafk
a/datas/first-1(first-0、first-2)路径上的文件。
[hadoop104 first-1]$ ls
00000000000000000092.index
00000000000000000092.log
00000000000000000092.snapshot
00000000000000000092.timeindex
leader-epoch-checkpoint
partition.metadata
(3)直接查看 log 日志,发现是乱码。
[hadoop104 first-1]$ cat 00000000000000000092.log
\CYnF|©|©ÿÿÿÿÿÿÿÿÿÿÿÿÿÿ"hello world
(4)通过工具查看 index 和 log 信息。
[hadoop104 first-1]$ kafka-run-class.sh kafka.tools.DumpLogSegments
--files ./00000000000000000000.index
Dumping ./00000000000000000000.index
offset: 3 position: 152
[atguigu@hadoop104 first-1]$ kafka-run-class.sh kafka.tools.DumpLogSegments
--files ./00000000000000000000.log
Dumping datas/first-0/00000000000000000000.log
Starting offset: 0
baseOffset: 0 lastOffset: 1 count: 2 baseSequence: -1 lastSequence: -1 producerId: -1
producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position:
0 CreateTime: 1636338440962 size: 75 magic: 2 compresscodec: none crc: 2745337109 isvalid:
true
baseOffset: 2 lastOffset: 2 count: 1 baseSequence: -1 lastSequence: -1 producerId: -1
producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position:
75 CreateTime: 1636351749089 size: 77 magic: 2 compresscodec: none crc: 273943004 isvalid:
true
baseOffset: 3 lastOffset: 3 count: 1 baseSequence: -1 lastSequence: -1 producerId: -1
producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position:
152 CreateTime: 1636351749119 size: 77 magic: 2 compresscodec: none crc: 106207379 isvalid:
true
baseOffset: 4 lastOffset: 8 count: 5 baseSequence: -1 lastSequence: -1 producerId: -1
producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position:
229 CreateTime: 1636353061435 size: 141 magic: 2 compresscodec: none crc: 157376877 isvalid:
true
baseOffset: 9 lastOffset: 13 count: 5 baseSequence: -1 lastSequence: -1 producerId: -1
producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position:
370 CreateTime: 1636353204051 size: 146 magic: 2 compresscodec: none crc: 4058582827 isvalid:
true
3)index 文件和 log 文件详解
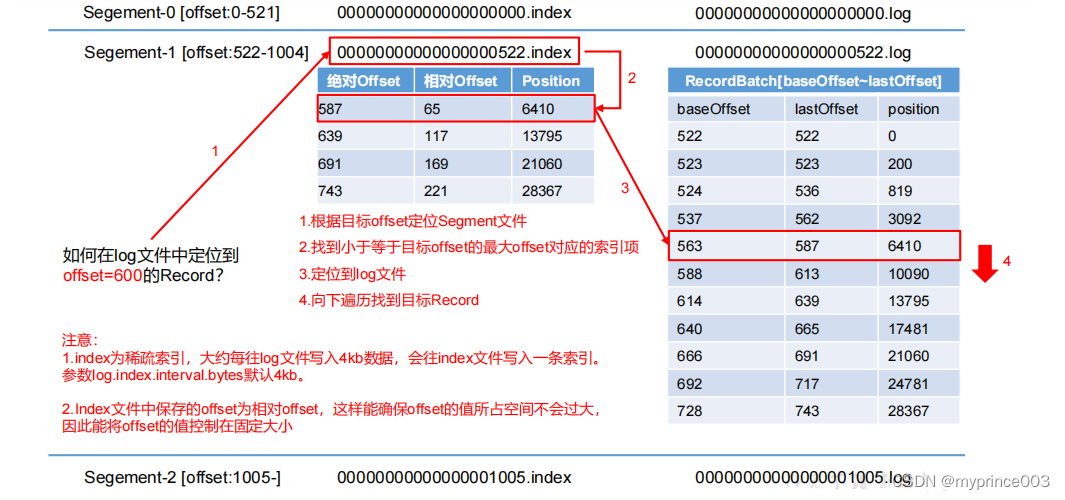

4.4.2 文件清理策略
Kafka 中默认的日志保存时间为 7 天,可以通过调整如下参数修改保存时间。
⚫ log.retention.hours,最低优先级小时,默认 7 天。
⚫ log.retention.minutes,分钟。
⚫ log.retention.ms,最高优先级毫秒。
⚫ log.retention.check.interval.ms,负责设置检查周期,默认 5 分钟。
那么日志一旦超过了设置的时间,怎么处理呢?
Kafka 中提供的日志清理策略有 delete 和 compact 两种。
1)delete 日志删除:将过期数据删除
⚫ log.cleanup.policy = delete 所有数据启用删除策略
(1)基于时间:默认打开。以 segment 中所有记录中的最大时间戳作为该文件时间戳。
(2)基于大小:默认关闭。超过设置的所有日志总大小,删除最早的 segment。
log.retention.bytes,默认等于-1,表示无穷大。
思考:如果一个 segment 中有一部分数据过期,一部分没有过期,怎么处理?
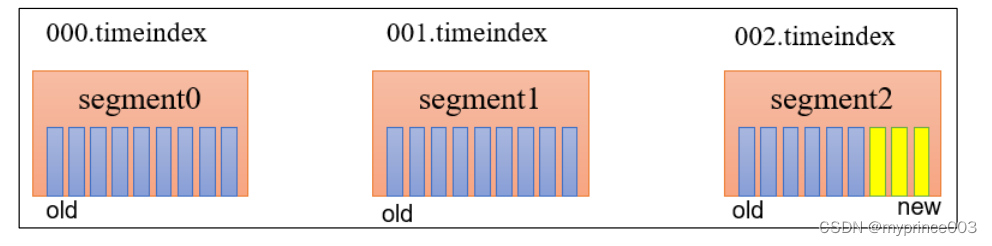
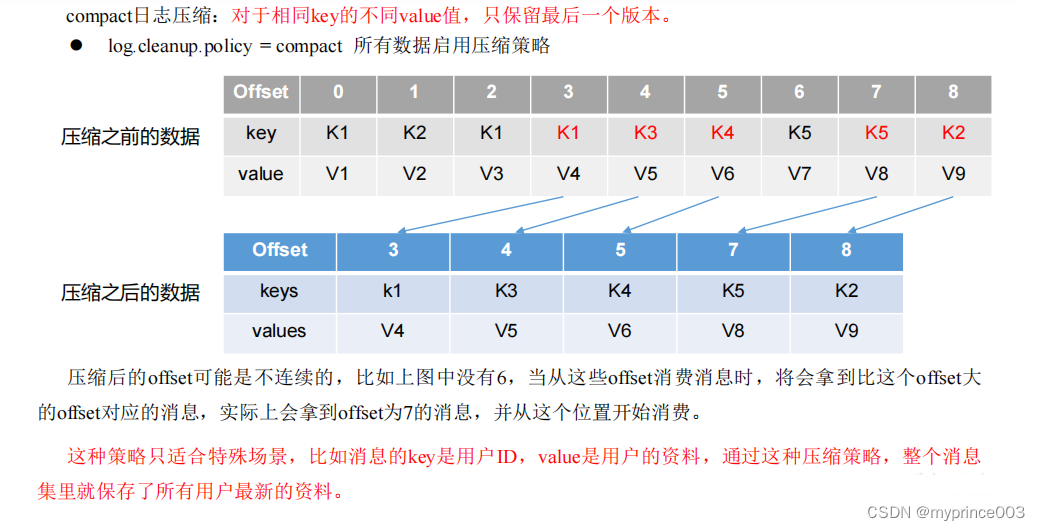
2)compact 日志压缩
4.5 高效读写数据
1)Kafka 本身是分布式集群,可以采用分区技术,并行度高
2)读数据采用稀疏索引,可以快速定位要消费的数据
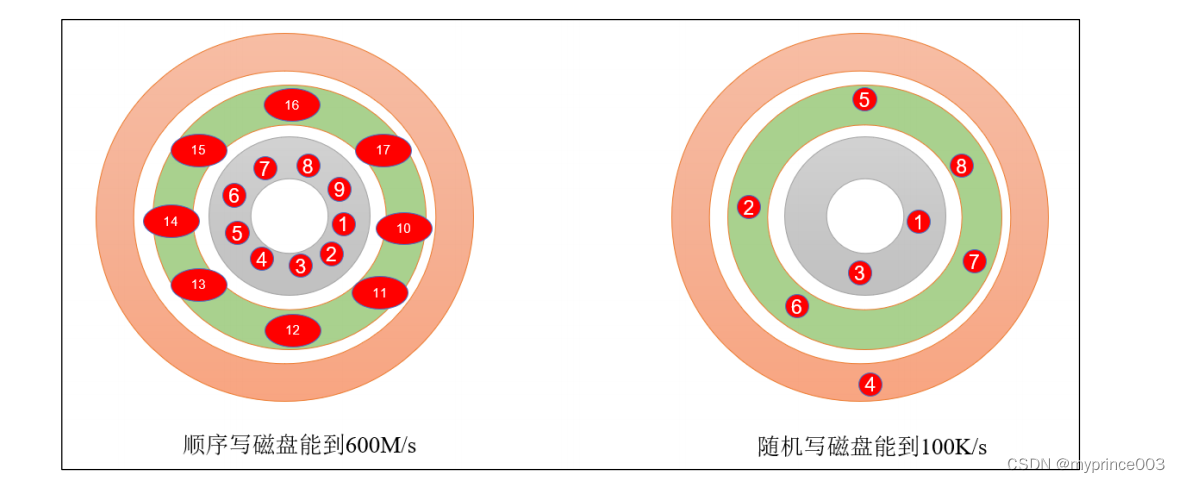
3)顺序写磁盘
Kafka 的 producer 生产数据,要写入到 log 文件中,写的过程是一直追加到文件末端,
为顺序写。官网有数据表明,同样的磁盘,顺序写能到 600M/s,而随机写只有 100K/s。这
与磁盘的机械机构有关,顺序写之所以快,是因为其省去了大量磁头寻址的时间。
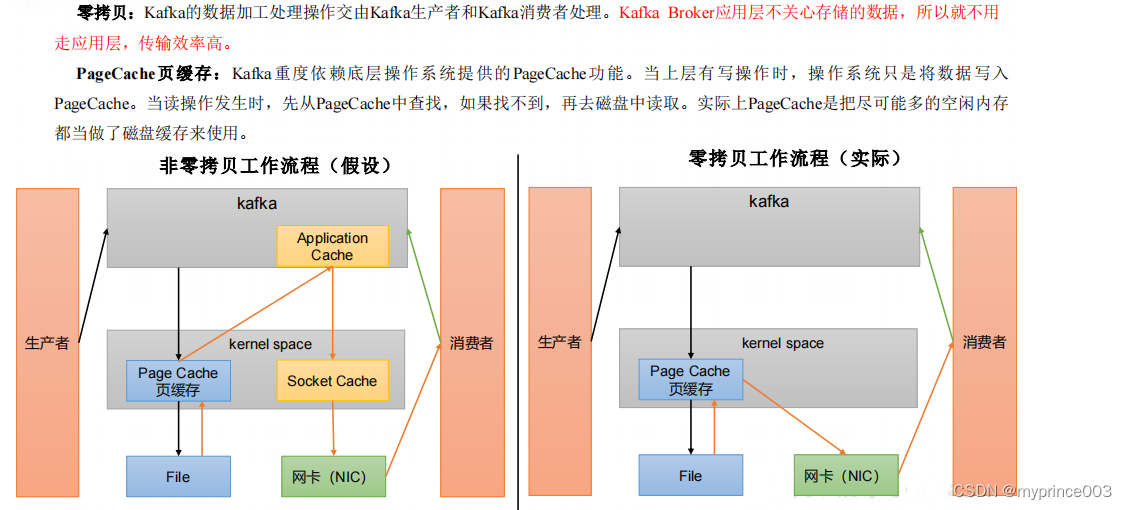
4)页缓存 + 零拷贝技术

相关文章:
3、Kafka Broker
4.1 Kafka Broker 工作流程 4.1.1 Zookeeper 存储的 Kafka 信息 (1)启动 Zookeeper 客户端。 [hadoop102 zookeeper-3.5.7]$ bin/zkCli.sh(2)通过 ls 命令可以查看 kafka 相关信息。 [zk: localhost:2181(CONNECTED) 2] ls /kaf…...

数字孪生智慧建筑可视化系统,提高施工效率和建造质量
随着科技的不断进步和数字化的快速发展,数字孪生成为了建筑行业的一个重要的概念,被广泛应用于智能化建筑的开发与管理中。数字孪生是将现实世界的实体与数字世界的虚拟模型进行连接和同步,从而实现实时的数据交互和模拟仿真。数字孪生在建筑…...
SpringCloud: feign整合sentinel实现降级
一、加依赖: <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0"xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation"http://maven.apache…...

List<LinkedHashMap<String, String>>类型的数据转换为Map<String, List<String>>类型数据
import java.util.*;public class Main {public static void main(String[] args) {// 示例数据:List<LinkedHashMap>List<LinkedHashMap<String, String>> keyParamList new ArrayList<>();LinkedHashMap<String, String> map1 ne…...

react 学习 —— 16、使用 ref 操作 DOM
什么时候使用 ref 操作 DOM? 有时你可能需要访问由 React 管理的 DOM 元素 —— 例如,让一个节点获得焦点、滚动到它或测量它的尺寸和位置。在 React 中没有内置的方法来做这些事情,所以你需要一个指向 DOM 节点的 ref 来实现。 怎么使用 r…...
Qt planeGame day10
Qt planeGame day10 Game基本框架 qt中没有现成的游戏框架可以用,我们需要自己搭框架首先创建一个QGame类作为框架,这个基本框架里面应该有如下功能:游戏初始化 void init(const QSize& siez,const QString& title);游戏反初始化(…...
贪吃蛇项目实践
游戏背景: 贪吃蛇是久负盛名的游戏,它也和俄罗斯⽅块,扫雷等游戏位列经典游戏的⾏列。 实现基本的功能: 贪吃蛇地图绘制 蛇吃⻝物的功能 (上、下、左、右⽅向键控制蛇的动作) 蛇撞墙死亡 蛇撞⾃⾝死亡 计…...
【C++】哈希应用——海量数据面试题
哈希应用——海量数据面试题 一、位图应用1、给定100亿个整数,设计算法找到只出现一次的整数?2、给两个文件,分别有100亿个整数,我们只有1G内存,如何找到两个文件交集?(1)用一个位图…...
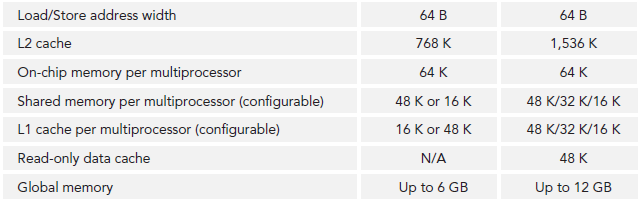
CUDA学习笔记(五)GPU架构
本篇博文转载于https://www.cnblogs.com/1024incn/tag/CUDA/,仅用于学习。 GPU架构 SM(Streaming Multiprocessors)是GPU架构中非常重要的部分,GPU硬件的并行性就是由SM决定的。 以Fermi架构为例,其包含以下主要组成…...
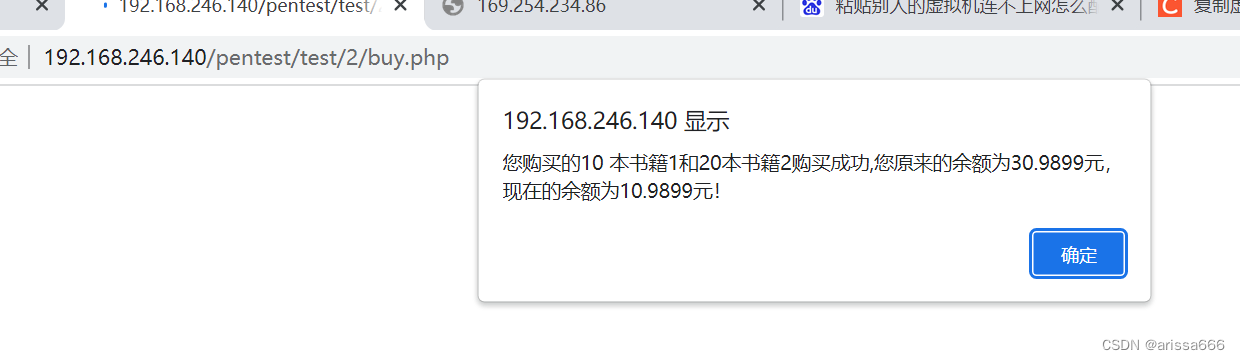
逻辑漏洞详解
原理: 没有固定的概念,一般都是不符合常识的情况。比如任意用户注册,短信炸弹,占用资源,交易支付、密码修改、密码找回、越权修改、越权查询、突破限制。 根据实际业务逻辑进行比对,购物的可以根据数量&a…...
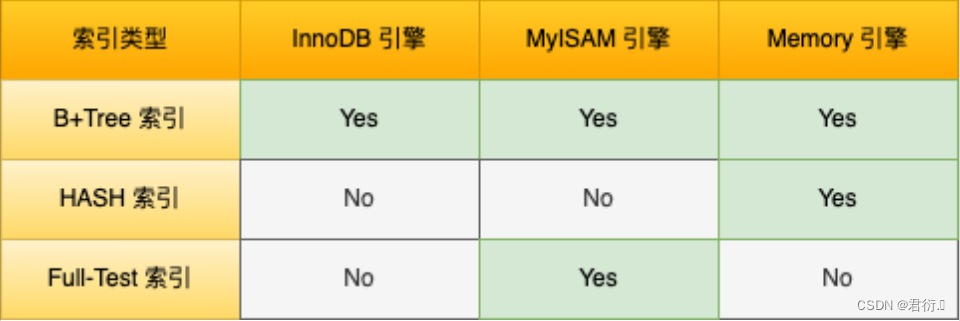
MySQL——八、MySQL索引视图
MySQL 一、视图1、什么是视图2、为什么需要视图3、视图的作用和优点4、创建视图5、视图使用规则6、修改视图7、删除视图 二、索引1、什么是索引2、索引优缺点3、索引分类4、索引的设计原则5、创建索引5.1 创建表是创建索引5.2 create index5.3 ALTER TABLE 6、删除索引7、MySQL…...
)
力扣100097. 合法分组的最少组数(哈希+贪心)
题目描述: 给你一个长度为 n 下标从 0 开始的整数数组 nums 。 我们想将下标进行分组,使得 [0, n - 1] 内所有下标 i 都 恰好 被分到其中一组。 如果以下条件成立,我们说这个分组方案是合法的: 对于每个组 g ,同一…...
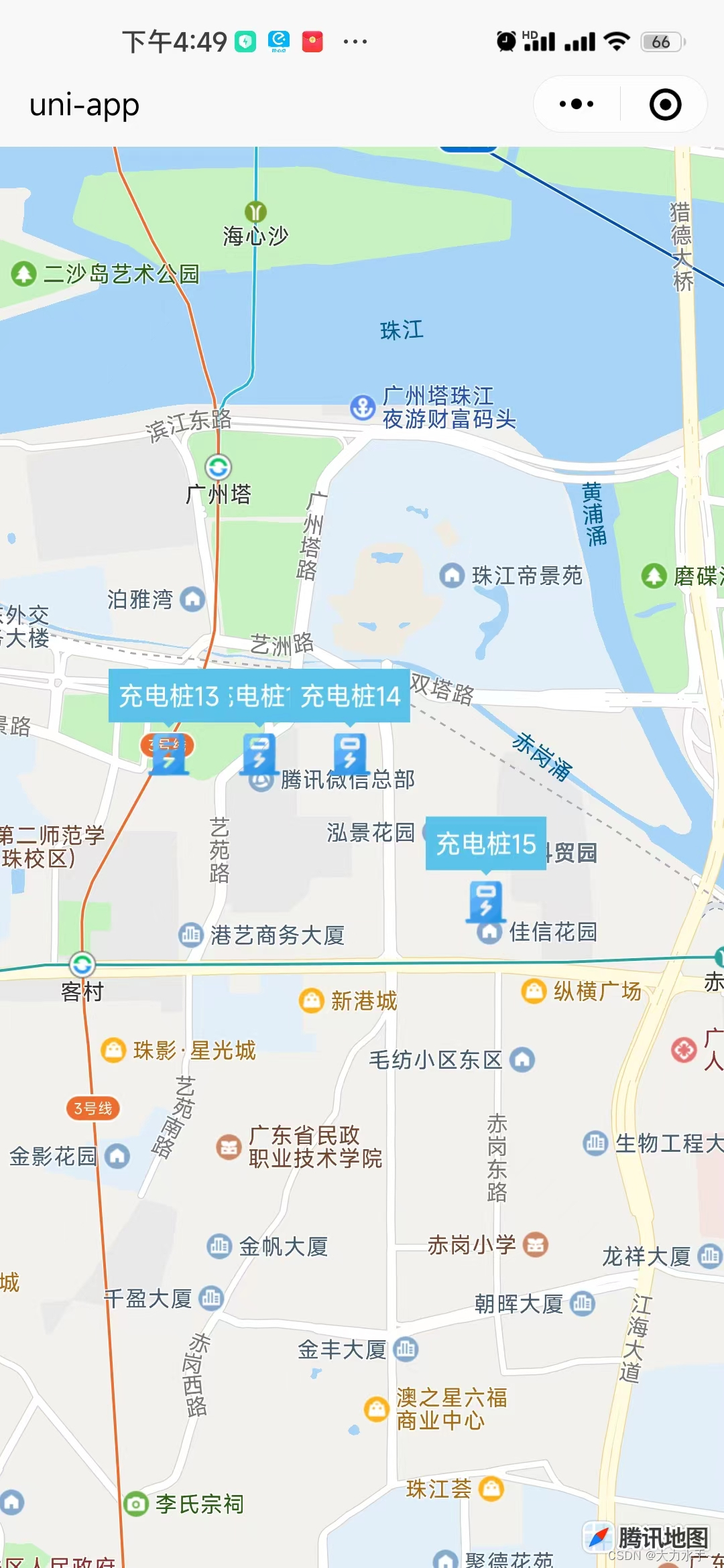
uniapp map地图实现marker聚合点,并点击marker触发事件
1.uniapp官方文档说明 2.关键代码片段 // 仅调用初始化,才会触发 on.("markerClusterCreate", (e) > {})this._mapContext.initMarkerCluster({enableDefaultStyle: false, // 是否使用默认样式zoomOnClick: true, // 点击聚合的点,是否…...
【Mysql】Mysql中的B+树索引(六)
概述 从上一章节我们了解到InnoDB 的数据页都是由7个部分组成,然后各个数据页之间可以组成一个双向链表 ,而每个数据页中的记录会按照主键值从小到大的顺序组成一个单向链表 ,每个数据页都会为存储在它里边儿的记录生成一个页目录 ÿ…...
【Dockerfile镜像实战】构建LNMP环境并运行Wordpress网站平台
这里写目录标题 一、项目背景和要求二、项目环境三、部署过程1)创建自定义网络2)部署NginxStep1 创建工作目录并上传相关软件包Step2 编写Dockerfile文件Step3 编写配置文件nginx.confStep4 创建nginx镜像Step5 运行容器 3)部署MysqlStep1 创…...

【工具】利用ffmpeg将网页中的.m3u8视频文件转化为.mp4格式
目录 0.环境 1.背景 2.前提 3.详细描述 1)在网站上找到你想下载的视频的.m3u8链接 2)打开命令行,用ffmpeg命令进行转化 3)过程&结果截图 0.环境 windows64 ffmpeg 1.背景 网页上有个.m3u8格式的视频文件,…...

Git简洁安装方式和使用方式【附安装包资源,Git基础操作,如拉取项目、上传代码、拉取代码】
文章目录 软件安装包安装步骤常用使用方式注意拉取项目上传代码或文件选择文件添加到本地Git存储库的缓存区将缓存区的更改提交到本地Git存储库,并设置提交信息将本地Git存储库的更新推送到远程Git仓库中上传示例拉取别人所上传的代码 常见问题上传代码失败…...
【29】c++设计模式——>策略模式
策略模式 C中的策略模式(Strategy Pattern)是一种行为型设计模式,它允许在运行时选择算法的行为。策略模式通过将算法封装成独立的类,并且使它们可以互相替换,从而使得算法的变化独立于使用算法的客户端。 策略模式通…...
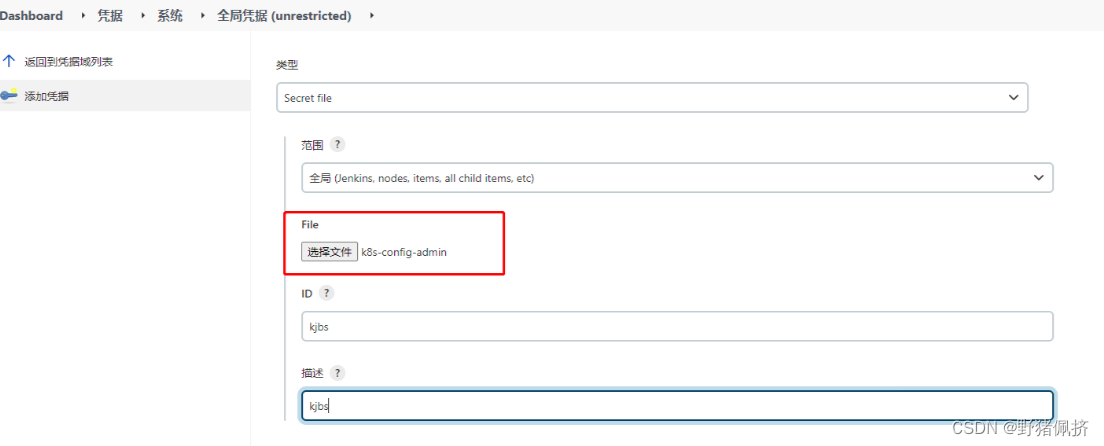
2023Jenkins连接k8s
首先配置k8s config文件 1.方式获取k8s密钥 cat .kube/config 2.导出方式或者密钥 kubectl config view --raw > k8s-config-admin pipeline {agent {kubernetes {yaml apiVersion: v1kind: Podmetadata:labels:some-label: devopsspec:containers:- name: dockerimage: d…...
SpringBoot 入门 参数接收 必传参数 数组 集合 时间接收
接口声明 RestController //表示该类为请求处理类public class HttpDeal {RequestMapping("/login")//这个方法处理哪一个地址过来的请求public String hello(){return "返回给浏览器";}}接收参数 RequestMapping("/login")public String logi…...

Blender化学品插件:3步搞定专业分子可视化
Blender化学品插件:3步搞定专业分子可视化 【免费下载链接】blender-chemicals Draws chemicals in Blender using common input formats (smiles, molfiles, cif files, etc.) 项目地址: https://gitcode.com/gh_mirrors/bl/blender-chemicals 还在为科研论…...

AdaIN在StyleGAN中的应用:从风格迁移到图像生成的进阶之路
AdaIN在StyleGAN中的应用:从风格迁移到图像生成的进阶之路 当你在深夜刷到一张梵高风格的宠物照片时,可能不会想到这背后藏着怎样的技术魔法。这种将艺术风格瞬间迁移到任意内容图像的能力,正是自适应实例归一化(AdaIN)…...

揭秘 Android 开发:利用 adb 命令轻松获取手机软硬件 build 信息的秘籍
在 Android 开发的广阔天地中,获取设备的详细软硬件信息是一项基础且至关重要的任务。无论是为了调试应用在不同设备上的表现,还是为了收集设备数据以优化应用功能,准确获取手机的 build 信息都是开发者不可或缺的技能。今天,就让…...

解决STM32生成Bin文件时Error: Q0122E的路径配置全攻略
1. 遇到Error: Q0122E时发生了什么? 当你正在STM32项目中使用Keil MDK进行开发,准备生成Bin文件时,突然弹出一个错误提示"Error: Q0122E: Could not open file"。这个错误通常意味着编译器无法找到fromelf.exe工具或输出文件的路径…...

收藏!AI时代就业趋势解析:小白程序员如何抓住机遇,避免被替代?
智联招聘数据显示,AI短期内替代部分岗位,如编辑、翻译等,但人工智能工程师、AI产品经理等需求激增。初级职位衰减,中级与高级职位增长。企业招聘需求从“专业分工”转向“跨界融合”,对软技能、实践应用能力和专业判断…...

全国产传感器信号的实时处理-信号校准与标定调试
随着物联网、工业自动化和智能感知技术的快速发展,传感器作为连接物理世界与数字世界的核心桥梁,其测量精度直接影响着整个系统的可靠性与决策质量。然而,传感器在实际应用中不可避免地会受到制造工艺差异、环境条件波动以及器件老化等多种因…...
)
OCR训练成本直降73%!2026奇点大会披露“渐进式伪标签闭环”框架(含GitHub可运行代码)
第一章:OCR训练成本直降73%!2026奇点大会核心成果概览 2026奇点智能技术大会(https://ml-summit.org) 本届奇点大会首次公开发布轻量级OCR联合蒸馏框架DocDistill-26,通过多粒度教师模型协同调度与动态分辨率感知训练策略,在保持…...
)
伺服调试手记:用Wireshark抓包分析CanOpen SDO 0x80错误(附真实报文解读)
伺服调试手记:用Wireshark抓包分析CanOpen SDO 0x80错误 那天下午三点,车间里的伺服驱动器突然亮起了报警灯。显示屏上赫然显示着"SDO 0x80错误"——这个在CanOpen通信中常见的错误代码,背后可能藏着参数越界、子索引不存在等多种问…...

Sora API:生成 AI 视频
简介 在数字内容创作日益重要的今天,视频生成技术逐渐成为开发者的热门选择。Sora API 是由 Ace Data Cloud 提供的一个强大工具,允许用户通过简单的 REST API 接口,将文本和图像转化为高质量的视频。无论是为社交媒体创建短视频,…...

X-AnyLabeling3.2实战:从零部署到自定义模型自动标注
1. X-AnyLabeling3.2安装与环境配置 第一次接触X-AnyLabeling这个开源标注工具时,我就被它的自动标注功能吸引了。相比传统的手动标注,它能节省80%以上的时间。不过安装过程确实有些坑要避开,这里分享我的实战经验。 首先需要准备Anaconda环境…...