k8s pod根据指标自动扩缩容举例
目录
基于 内存 指标实现pod自动扩缩容 举例配置
基于 cpu 指标实现pod自动扩缩容 举例配置
基于请求数(次/秒) 指标实现pod自动扩缩容 举例配置
基于 http请求响应时间 (ms) 指标实现pod自动扩缩容 举例配置
基于 Java GC暂停时间 (ms) 指标实现pod自动扩缩容 举例配置
扩展点
prometheus对所有pod进行流量监控 配置举例
基于 内存 指标实现pod自动扩缩容 举例配置
首先,需要在Kubernetes集群中部署一个HPA(Horizontal Pod Autoscaler),它可以基于内存使用量自动调整Pod的数量。
以下是HPA的示例配置:
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata: name: my-app-hpa
spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: my-app-deployment minReplicas: 2 maxReplicas: 10 metrics: - type: Resource resource: name: memory targetAverageUtilization: 80 # 目标内存使用率(%)上述配置中,HPA会根据内存使用量自动调整Pod的数量。
scaleTargetRef指定了要扩展的Pod对象(这里是一个Deployment)。
minReplicas和maxReplicas分别指定了Pod的最小和最大数量。
metrics指定了度量指标,这里使用的是内存使用量。
targetAverageUtilization设置了一个目标内存使用率,当内存使用率超过这个值时,HPA会自动扩展Pod的数量。
为了能够正确地监测内存使用量,需要为Pod配置相应的监控指标。这可以通过加入resources字段来实现,如下所示:
apiVersion: v1
kind: Pod
metadata: name: my-app-pod
spec: containers: - name: my-app-container resources: requests: memory: "64Mi" # 请求64MB内存 limits: memory: "128Mi" # 限制128MB内存 # ...其他配置...在这个例子中,Pod中的容器会根据配置的内存限制来运行。
requests指定了Pod启动所需的最小内存,而limits则指定了Pod运行过程中所能够使用的最大内存。这些配置可以帮助Kubernetes更好地管理资源,避免资源浪费和竞争。
基于 cpu 指标实现pod自动扩缩容 举例配置
下面是一个基于CPU使用率实现Kubernetes Pod自动扩展的示例配置。
首先,需要在Kubernetes集群中部署一个HPA(Horizontal Pod Autoscaler),它可以基于CPU使用率自动调整Pod的数量。
以下是HPA的示例配置:
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata: name: my-app-hpa
spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: my-app-deployment minReplicas: 2 maxReplicas: 10 metrics: - type: Resource resource: name: cpu targetAverageUtilization: 80 # 目标CPU使用率(%)上述配置中,HPA会根据CPU使用率自动调整Pod的数量。
scaleTargetRef指定了要扩展的Pod对象(这里是一个Deployment)。
minReplicas和maxReplicas分别指定了Pod的最小和最大数量。
metrics指定了度量指标,这里使用的是CPU使用率。
targetAverageUtilization设置了一个目标CPU使用率,当CPU使用率超过这个值时,HPA会自动扩展Pod的数量。
需要注意的是,为了能够正确地监测CPU使用率,需要为Pod配置相应的监控指标。这可以通过在Pod中加入resources字段来实现,例如:
apiVersion: v1
kind: Pod
metadata: name: my-app-pod
spec: containers: - name: my-app-container resources: requests: cpu: "100m" # 请求1个CPU核心100毫核(m核) limits: cpu: "200m" # 限制2个CPU核心200毫核(m核) # ...其他配置...在这个例子中,Pod中的容器会根据配置的CPU资源限制来运行。
requests指定了Pod启动所需的最小CPU资源,
limits则指定了Pod运行过程中所能够使用的最大CPU资源。
基于请求数(次/秒) 指标实现pod自动扩缩容 举例配置
下面是一个基于每秒请求数(Requests per second,RPS)实现Kubernetes Pod自动扩展的示例配置。
首先,需要使用一个HTTP代理或服务来监控每个Pod的RPS,比如一个Prometheus Operator。以下是一个Prometheus Operator的示例配置:
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata: name: prometheus-operator
subjects:
- kind: ServiceAccount name: prometheus-operator namespace: kube-system
roleRef: kind: ClusterRole name: prometheus-operator接下来,创建一个Prometheus ServiceMonitor资源以监视HTTP代理的RPS
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata: name: myapp-requests
spec: jobLabel: "myapp" selector: matchLabels: myapp: my-app relabelings: - sourceLabels: [__meta_service_namespace, __meta_service_name] targetLabel: source action: keep - sourceLabels: [__meta_kubernetes_pod_container_id] targetLabel: container_id action: keep - sourceLabels: [__meta_kubernetes_pod_name] targetLabel: pod_name action: keep - sourceLabels: [__meta_kubernetes_pod_label_myapp] targetLabel: myapp action: keep metricsPath: /metrics scheme: http httpGet: path: /metrics port: 8000在这个示例中,ServiceMonitor资源将根据Pod的标签选择器和HTTP Get请求监视my-app服务的RPS。请注意,您需要根据您的应用程序和环境进行自定义。
最后,创建一个HPA(Horizontal Pod Autoscaler)来根据RPS自动调整Pod的数量:
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata: name: my-app-hpa
spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: my-app-deployment minReplicas: 2 maxReplicas: 100 metrics: - type: PodsMetricSource podsMetricSource: metricName: "requests_per_second" # 指定要监视的指标名称(例如:requests_per_second) targetAverageValue: 10 # 目标RPS(例如:每秒10个请求)在这个示例中,HPA将根据Pod的RPS自动调整Pod的数量。当RPS超过设定的目标值时,HPA将增加更多的Pod,以保持服务的高可用性和响应能力。
基于 http请求响应时间 (ms) 指标实现pod自动扩缩容 举例配置
首先,需要创建一个自定义度量源(Custom Metric Source),这里假设你的度量源是由Prometheus Operator提供的,可以按照以下步骤进行操作:
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata: name: my-app-http-response-time
spec: http: servicePort: 9090 metrics: - name: http_response_time_seconds_count help: Count of HTTP requests with response time greater than 1 second. expression: sum(rate(http_request_duration_seconds_count{job="my-app"}[1m])) by (job)上述配置中定义了一个Prometheus资源,用于收集HTTP请求的响应时间指标。
http_request_duration_seconds_count是一个Prometheus指标,用于表示每秒HTTP请求的计数,通过rate()函数计算每分钟的平均请求速率,并使用sum()函数对所有job进行聚合。最终,通过by(job)对每个job进行分组,以便与Pod数量进行关联。
接下来,使用以下配置创建一个HPA对象:
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata: name: my-app-hpa
spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: my-app-deployment minReplicas: 2 maxReplicas: 10 metrics: - type: PodsMetricSource podsMetricSource: metricName: http_response_time_seconds_count targetAverageValue: 100 # 目标平均响应时间(秒) thresholds: - type: PodsMetricSource podsMetricSource: metricName: http_response_time_seconds_count targetAverageValue: 5 # 每秒HTTP请求的目标计数(可根据需求调整)上述配置中,HPA使用了
PodsMetricSource类型的度量源,该度量源从Pod级别的度量指标中获取数据。
metricName设置为http_response_time_seconds_count,表示使用之前创建的自定义度量源来收集HTTP请求响应时间的指标数据。
targetAverageValue设置了一个目标响应时间的平均值,单位为秒。在此示例中,目标响应时间为5秒。同时,为了更好地控制扩缩容的灵敏度,还添加了一个额外的阈值(threshold),该阈值使用相同的度量指标,但设置了每秒HTTP请求的目标计数。在此示例中,如果每秒HTTP请求的数量超过5,HPA将触发扩容操作。
请注意,上述示例仅为了演示如何基于HTTP请求响应时间实现Pod自动扩缩容,并提供了基本的配置示例。实际应用中,可能需要根据具体需求进行调整和优化。
基于 Java GC暂停时间 (ms) 指标实现pod自动扩缩容 举例配置
基于Java GC暂停时间实现自动扩缩容可以用来优化应用性能,避免由于GC暂停时间过长导致的应用延迟或卡顿。以下是一个基于GC暂停时间实现Pod自动扩缩容的示例配置,假设使用Kubernetes和Prometheus作为监控工具。
创建自定义度量源:
首先,需要从Prometheus中获取GC暂停时间的指标数据。可以使用以下配置创建一个自定义度量源,从Prometheus中获取GC暂停时间的指标数据:
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata: name: my-app-gc-pause-time
spec: http: servicePort: 9091 metrics: - name: gc_pause_time_seconds_sum help: Total GC pause time in seconds. expression: sum(irate(gc_pause_time_seconds_sum[5m])) by (pod)上述配置中,创建了一个Prometheus资源,用于收集GC暂停时间的指标数据。
gc_pause_time_seconds_sum表示GC暂停时间的总和,使用irate()函数计算最近5分钟内每分钟的平均暂停时间,并使用sum()函数对所有Pod进行聚合。最终,通过by(pod)对每个Pod进行分组,以便与Pod数量进行关联。
接下来,使用以下配置创建一个HPA对象:
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata: name: my-app-hpa
spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: my-app-deployment minReplicas: 2 maxReplicas: 10 metrics: - type: PodsMetricSource podsMetricSource: metricName: gc_pause_time_seconds_sum targetAverageValue: 10 # 目标平均GC暂停时间(秒) thresholds: - type: PodsMetricSource podsMetricSource: metricName: gc_pause_time_seconds_sum targetAverageValue: 2 # 每分钟GC暂停时间的目标计数(可根据需求调整)上述配置中,HPA使用了
PodsMetricSource类型的度量源,该度量源从Pod级别的度量指标中获取数据。
metricName设置为gc_pause_time_seconds_sum,表示使用之前创建的自定义度量源来收集GC暂停时间的指标数据。
targetAverageValue设置了一个目标GC暂停时间的平均值。在此示例中,目标GC暂停时间为2秒。同时,为了更好地控制扩缩容的灵敏度,还添加了一个额外的阈值(threshold),该阈值使用相同的度量指标,但设置了每分钟GC暂停时间的目标计数。在此示例中,如果每分钟GC暂停时间超过2,HPA将触发扩容操作。
请注意,上述示例仅为了演示如何基于Java GC暂停时间实现Pod自动扩缩容,并提供了基本的配置示例。实际应用中,可能需要根据具体的应用场景、GC类型、监控工具等进行调整和优化。
扩展点
prometheus对所有pod进行流量监控 配置举例
Prometheus是一个开源的监控和告警工具,它可以用于监控各种系统和应用程序的性能。要使用Prometheus监控所有Pod的流量,您可以按照以下步骤进行设置:
-
安装和配置Prometheus:首先,您需要在您的Kubernetes集群中安装和配置Prometheus。这可以通过使用Kubernetes的Helm Chart或类似的工具来完成。您可以参考Prometheus的官方文档以获取更详细的安装和配置说明。
-
创建ServiceMonitor资源:在您的Kubernetes集群中,为每个要监控的Pod或服务创建一个ServiceMonitor资源。ServiceMonitor资源允许Prometheus监控指定服务的指标。以下是一个示例ServiceMonitor资源的配置:
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata: name: my-pod-service-monitor
spec: namespace: your-namespace # 指定要监控的Pod所属的命名空间 selector: matchLabels: app: your-pod-app-label # 指定要监控的Pod的标签 endpoints: - basicAuth: password: name: your-pod-metrics-password # 指定metrics服务的密码 key: password username: your-pod-metrics-username # 指定metrics服务的用户名 path: /metrics # 指定metrics服务的路径 port: your-pod-metrics-port # 指定metrics服务的端口根据您的实际情况修改上述示例中的命名空间、标签、用户名、密码和端口等信息
3. 创建Prometheus目标:在Prometheus的配置文件(通常是prometheus.yml)中,创建一个新的目标,用于监控Pod的流量。以下是一个示例配置:
scrape_configs: - job_name: 'pod-traffic' kubernetes_sd_configs: - role: pod relabel_configs: - source_labels: [__meta_kubernetes_pod_label_app] target_label: pod_app_label - source_labels: [__meta_kubernetes_pod_container_id] target_label: pod_container_id - source_labels: [__address__] target_label: pod_address regex: ([^:]+)(?::\d+)? - source_labels: [__metrics_path__] target_label: pod_metrics_path上述配置中,我们指定了
job_name为pod-traffic,并配置了kubernetes_sd_configs以发现Pod。relabel_configs用于重标记指标的元数据,以便更方便地识别和组织指标数据。
4. 重新加载Prometheus配置:保存并关闭Prometheus的配置文件后,使用以下命令重新加载Prometheus配置:
curl -X POST http://<prometheus-address>:9090/-/reload其中<prometheus-address>是Prometheus服务的主机名或IP地址。
5. 监视Pod流量:现在,Prometheus将会收集所有指定Pod的流量指标,并在其查询界面上显示它们。您可以使用Prometheus的查询语言(PromQL)来编写查询,以获取有关Pod流量的度量标准和趋势等信息。例如,以下查询可以获取所有Pod的总请求计数:
sum(rate(http_requests_total{job="pod-traffic"}[1m])) by (pod_app_label)相关文章:

k8s pod根据指标自动扩缩容举例
目录 基于 内存 指标实现pod自动扩缩容 举例配置 基于 cpu 指标实现pod自动扩缩容 举例配置 基于请求数(次/秒) 指标实现pod自动扩缩容 举例配置 基于 http请求响应时间 (ms) 指标实现pod自动扩缩容 举例配置 基于 Java GC暂停时间 (ms) 指标实现…...

深、浅拷贝之间的关系
深、浅拷贝之间的关系 什么是赋值 赋值是将某一数值或对象赋给某个变量的过程,分为下面 2 部分 基本数据类型:赋值,赋值之后两个变量互不影响引用数据类型:赋址,两个变量具有相同的引用,指向同一个对象&…...

服务器数据恢复-某银行服务器硬盘数据恢复案例
服务器故障&分析: 某银行的某一业务模块崩溃,无法正常使用。排查服务器故障,发现运行该业务模块的服务器中多块硬盘离线,导致上层应用崩溃。 故障服务器内多块硬盘掉线,硬盘掉线数量超过服务器raid阵列冗余级别所允…...
仪器器材经营小程序商城的作用是什么
互联网发展下,数字化转型已经成为常态,仅依赖传统线下经营模式将很难再增长。 作为产品销售及客户维护度高的仪器器材行业,拥有自营商城平台是必要的,不仅可以解决以上难题,还利于打造自身品牌多渠道传播,…...

京东数据分析:2023年9月京东洗烘套装品牌销量排行榜!
鲸参谋监测的京东平台9月份洗烘套装市场销售数据已出炉! 根据鲸参谋平台的数据显示,今年9月份,京东平台洗烘套装的销量为7100,环比下降约37%,同比增长约87%;销售额为6000万,环比下降约48%&#…...

论文阅读-多目标强化学习-envelope MOQ-learning
introduction 一种多目标强化学习算法,来自2019 Nips《A Generalized Algorithm for Multi-Objective Reinforcement Learning and Policy Adaptation》本文引用代码全部来源于论文中的链接。主要参考run_e3c_double.py文件 1 总体思想 1.将输入中加入多目标的偏…...

【原创】【考法总结】指针*与++结合的题目考法总结
代码均已调试出结果,放心食用,大致总共5种考法 【理论铺垫】①a[i]恒等价于(ai)即*(&a[0]i);i类似偏移量(别忘a代表数组首元素地址即&a[0]) ②*(&a[i])恒等价于a[i]:&a[i]表示a[i]的地址&a…...
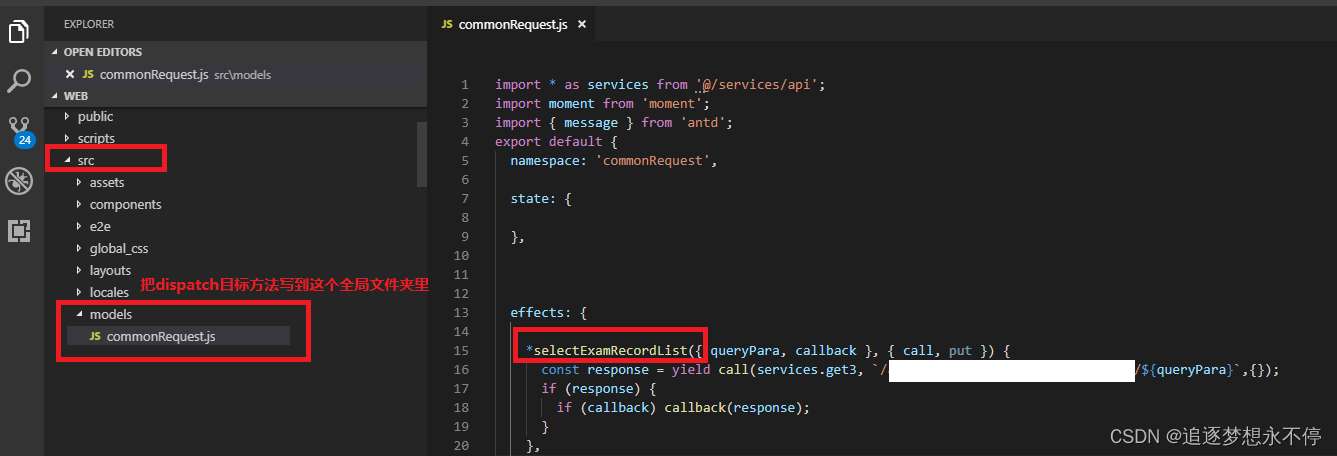
react dispatch不生效的坑
一、前言 最近写react antd项目,在A页面中使用了dispatch方法,然后B页面中嵌套A页面,没有问题; 但是在C页面中嵌套A页面的时候,就发现dispatch方法没有执行,也不报错,就很奇怪; 还…...
Mingw快捷安装教程 并完美解决出现的下载错误:The file has been downloaded incorrectly
安装c语言编译器的时候,老是出现The file has been downloaded incorrectly,真的让人 直接去官网拿压缩包:https://sourceforge.net/projects/mingw-w64/files/ (往下拉找到那个x86_64-win32-seh的链接,点击后会自动…...
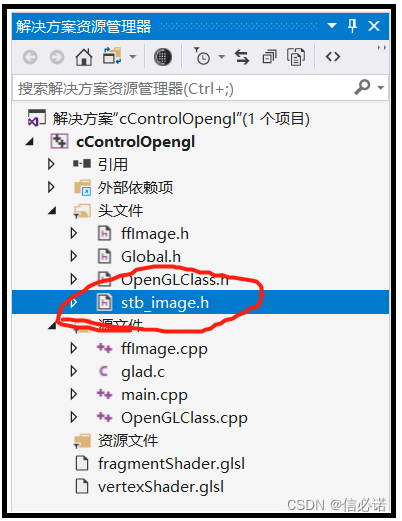
OpenGL —— 2.6、绘制一个正方体并贴图(附源码,glfw+glad)
源码效果 C源码 纹理图片 需下载stb_image.h这个解码图片的库,该库只有一个头文件。 具体代码: vertexShader.glsl #version 330 corelayout(location 0) in vec3 aPos; layout(location 1) in vec2 aUV;out vec2 outUV;uniform mat4 _viewMatrix; u…...

JavaWeb从入门到起飞笔记——导学课程
学完这一节,我不知道学Web开发究竟能干什么?你知道吗? 以下是黑马程序员Java从入门到起飞的笔记 一、学完Javaweb能干什么? 学完Java后我们可以独立开发一些后台管理系统,例如CRMER器,京东和淘宝&#x…...

【LeetCode:1402. 做菜顺序 | 动态规划 + 贪心】
🚀 算法题 🚀 🌲 算法刷题专栏 | 面试必备算法 | 面试高频算法 🍀 🌲 越难的东西,越要努力坚持,因为它具有很高的价值,算法就是这样✨ 🌲 作者简介:硕风和炜,…...

基于FPGA的图像拉普拉斯变换实现,包括tb测试文件和MATLAB辅助验证
目录 1.算法运行效果图预览 2.算法运行软件版本 3.部分核心程序 4.算法理论概述 5.算法完整程序工程 1.算法运行效果图预览 2.算法运行软件版本 matlab2022a vivado2019.2 3.部分核心程序 timescale 1ns / 1ps // // Company: // Engineer: // // Create Date: 202…...

高校教务系统登录页面JS分析——巢湖学院
高校教务系统密码加密逻辑及JS逆向 本文将介绍高校教务系统的密码加密逻辑以及使用JavaScript进行逆向分析的过程。通过本文,你将了解到密码加密的基本概念、常用加密算法以及如何通过逆向分析来破解密码。 本文仅供交流学习,勿用于非法用途。 一、密码加…...

人工智能、机器学习、深度学习的区别
人工智能涵盖范围最广,它包含了机器学习;而机器学习是人工智能的重要研究内容,它又包含了深度学习。 人工智能(AI) 人工智能是一门以计算机科学为基础,融合了数学、神经学、心理学、控制学等多个科目的交…...

Element Plus el-select选择框失去焦点blur
正常情况下,可以使用 el-select 自带的方法 blur 事件来使select失去焦点 示例: <el-select v-model"value" ref"selectRef"><el-optionv-for"item in options":key"item.value":label"item.la…...
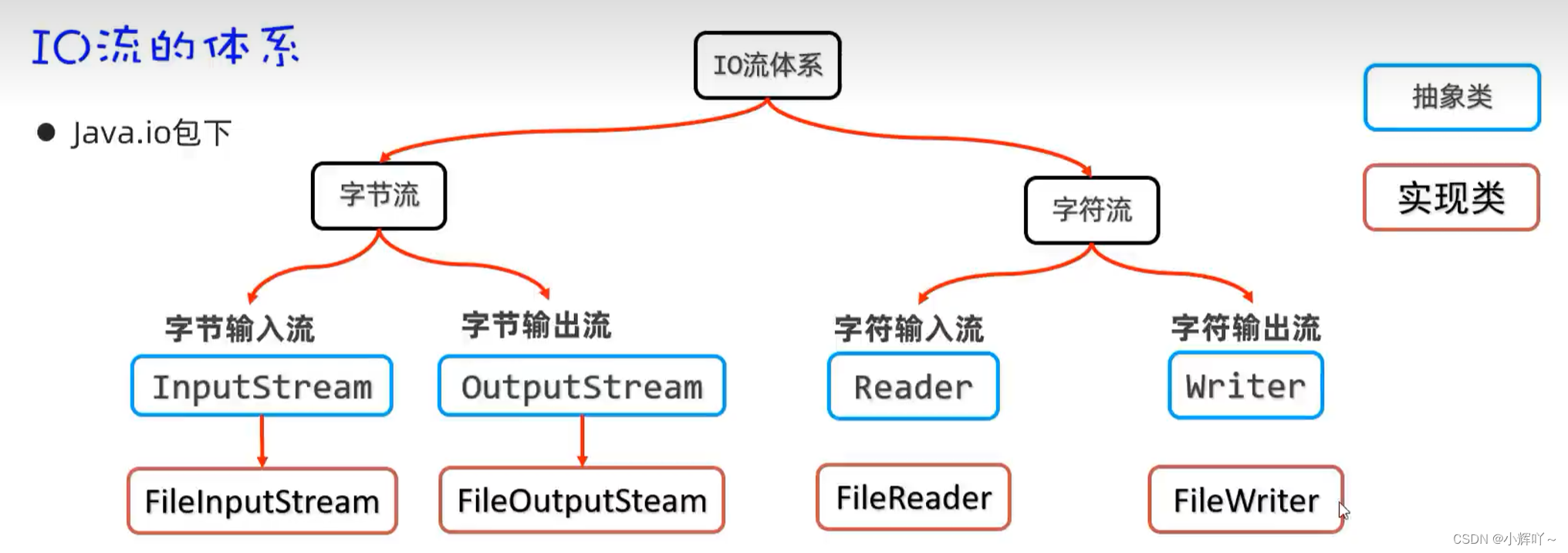
Java File与IO流学习笔记
内存中存放的都是临时数据,但是在断电或者程序终止时都会丢失 而硬盘则可以长久存储数据,即使断电,程序终止,也不会丢失 File File是java.io.包下的类,File类的对象,用于代表当前操作系统的文件(可以是文…...
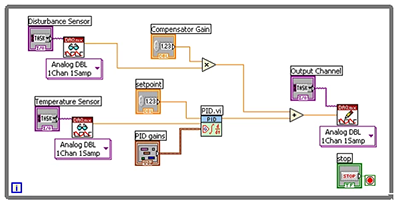
LabVIEW中PID控制的的高级功能
LabVIEW中PID控制的的高级功能 比例-积分-微分(PID)控制占当今控制和自动化应用的90%以上,主要是因为它是一种有效且简单的解决方案。虽然PID算法最初用于线性、时不变系统,但现在已经发展到控制具有复杂动力学的系统。在现实世界…...
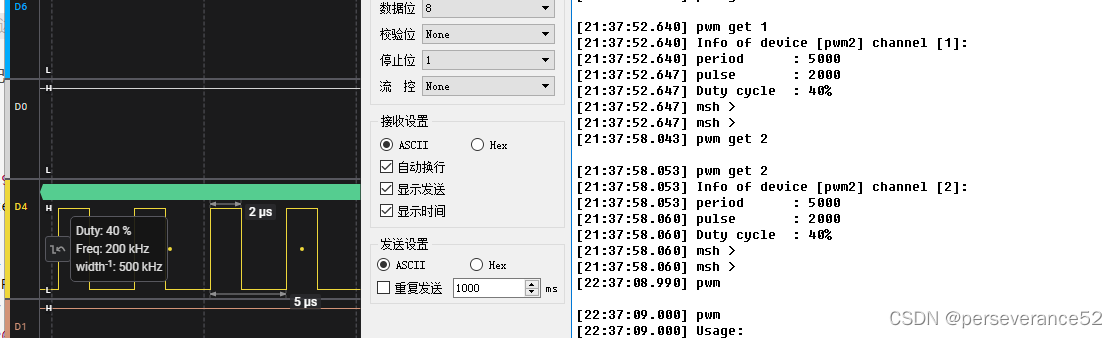
STM32基于HAL库RT-Thread Demo测试
STM32基于HAL库RT-Thread Demo测试 🎈源码地址:https://github.com/RT-Thread/rt-thread/tree/master📌基于STM32CUBEMX中间件安装《基于 CubeMX 移植 RT-Thread Nano》📍环境搭建《使用 Env 创建 RT-Thread 项目工程》ǵ…...
找素数)
萌新小白必做题(2)找素数
一.思路分析 先来看看素数的性质: 素数又称质数,是指除了1和本身外没有其它因数的自然数。素数有许多有趣的性质和应用,例如可以用于加密算法和数学证明等。比如2、3、5、7等都是素数,而4、6、8、9等则不是素数。素数的研究是数…...

2025网盘直链下载神器:八大平台高速下载完整指南
2025网盘直链下载神器:八大平台高速下载完整指南 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云盘 …...

高斯分布与拉普拉斯分布:从数学原理到Python实战
1. 高斯分布与拉普拉斯分布的核心数学原理 我第一次接触高斯分布是在大学物理实验课上,教授用它来描述测量误差。当时觉得这个"钟形曲线"特别神奇,后来才发现它无处不在——从考试成绩分布到股票价格波动。而拉普拉斯分布则是在研究金融数据时…...

多权限批量处理技巧:react-native-permissions性能优化终极指南
多权限批量处理技巧:react-native-permissions性能优化终极指南 【免费下载链接】react-native-permissions An unified permissions API for React Native on iOS, Android and Windows. 项目地址: https://gitcode.com/gh_mirrors/re/react-native-permissions …...
TransformationLayout配置详解:从基础属性到高级参数的完整教程
TransformationLayout配置详解:从基础属性到高级参数的完整教程 【免费下载链接】TransformationLayout 🌠 Transform between two Views, Activities, and Fragments, or a View to a Fragment with container transform animations for Android. 项目…...
)
Milvus vs ElasticSearch实战对比:从零搭建到性能测试全记录(附避坑指南)
Milvus vs ElasticSearch实战对比:从零搭建到性能测试全记录(附避坑指南) 在AI应用开发领域,向量数据库的选择往往决定了整个系统的性能上限。当开发者面临Milvus和ElasticSearch这两个主流选项时,如何根据实际业务需…...

用HDLbits练手计数器?我总结了这5种经典模式帮你搞定FPGA面试题
5种计数器设计模式:从HDLbits到FPGA面试的实战指南 在数字电路设计中,计数器就像面包和黄油一样基础而重要。无论是简单的时序控制还是复杂的时钟管理,计数器都扮演着关键角色。对于准备FPGA相关岗位面试的工程师来说,掌握各种计数…...

大模型学习-python基础Day6
一.文件操作文件是存储在磁盘上的数据集合。文件可以包含各种类型的数据,如文本、图像、音频等等。文件系统通过文件名和文件路径来定位和管理文件。文件名通常包含文件的名称和和扩展名。文件路径可以是绝对路径也可以是相对路径。1.文件的分类纯文本文件ÿ…...

暗黑破坏神II角色编辑器:解放你的游戏创造力
暗黑破坏神II角色编辑器:解放你的游戏创造力 【免费下载链接】diablo_edit Diablo II Character editor. 项目地址: https://gitcode.com/gh_mirrors/di/diablo_edit 你是否曾经在暗黑破坏神II中花费数小时刷装备,只为获得一件特定属性的传奇物品…...

如何用Zotero Better Notes打造终极文献笔记管理系统?
如何用Zotero Better Notes打造终极文献笔记管理系统? 【免费下载链接】zotero-better-notes Everything about note management. All in Zotero. 项目地址: https://gitcode.com/gh_mirrors/zo/zotero-better-notes 在学术研究和知识管理领域,文…...

Linux CFS 的 switched_from/switched_to:调度类切换的处理
一、简介在Linux内核的调度子系统中,任务在不同调度类之间切换是一个复杂且关键的操作。当应用程序调用sched_setscheduler()将任务从普通调度策略(SCHED_NORMAL)切换为实时策略(SCHED_FIFO/SCHED_RR),或者…...