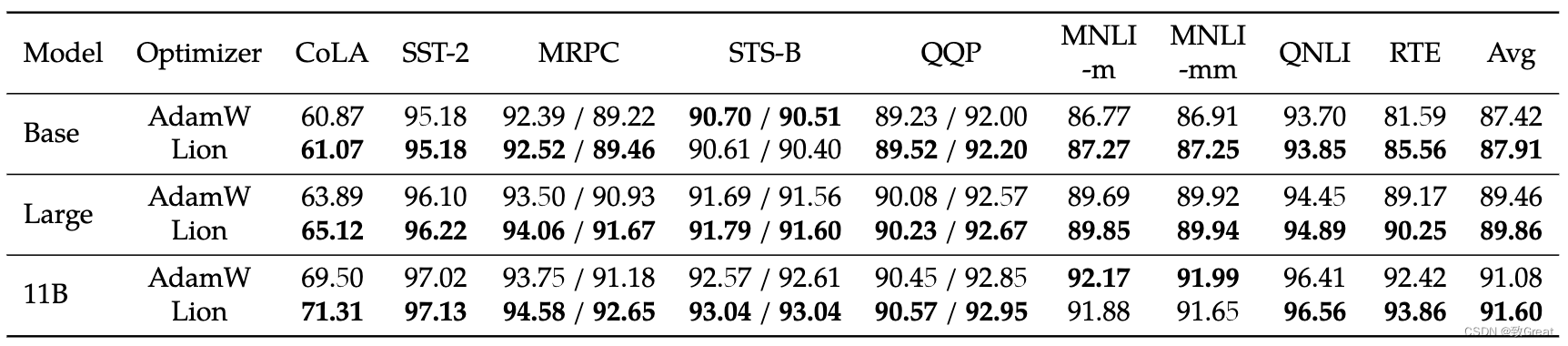
Google Brain新提出的优化器“Lion”,效果要比Adam(W)更好
Google Brain新提出的优化器“Lion”,效果要比Adam(W)更好
- 论文地址:https://arxiv.org/abs/2302.06675
- 代码地址:https://github.com/google/automl/blob/master/lion/lion_pytorch.py
1 简单、内存高效、运行速度更快
与 AdamW 和各种自适应优化器需要同时保存一阶和二阶矩相比,Lion 只需要动量,将额外的内存占用减半。 这在训练大型模型和大Batch size时很有用。 例如,AdamW 需要至少 16 个 TPU V4 芯片来训练图像大小为 224、批量大小为 4,096 的 ViT-B/16,而 Lion 只需要8个。
另一个显而易见的好处是,由于 Lion 的简单性,Lion 在我们的实验中具有更快的运行时间(step/s),通常比 AdamW 和 Adafactor 提速 2-15%,具体取决于任务、代码库和硬件。

2 在各种模型、任务和领域上的优越性能
2.1 图像分类
- Lion 在 ImageNet 上从头开始训练或在 ImageNet-21K 上预训练的各种网络模型上优于 AdamW。
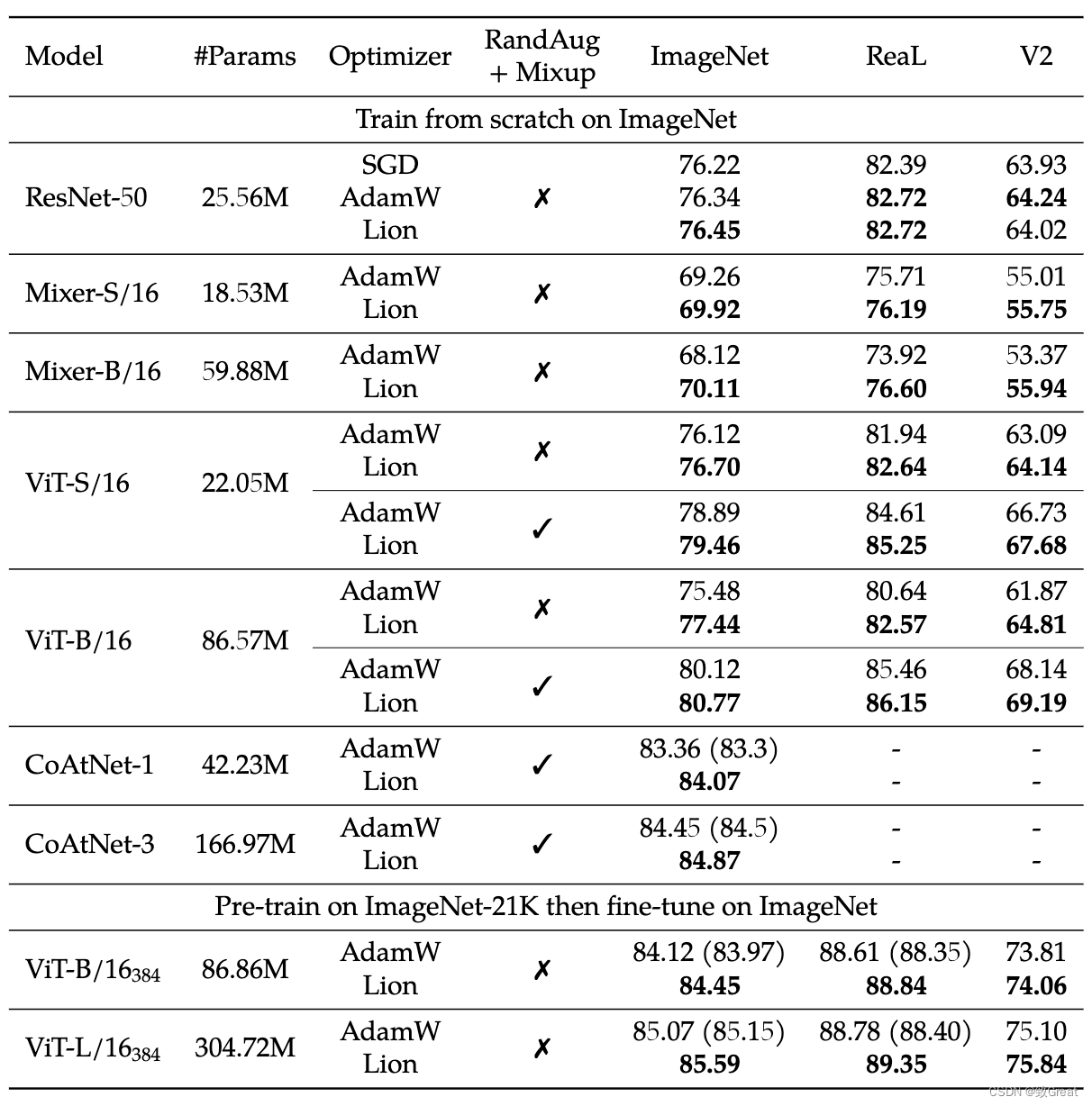
- Lion 在 JFT-300M 上节省了高达 5 倍的预训练成本。
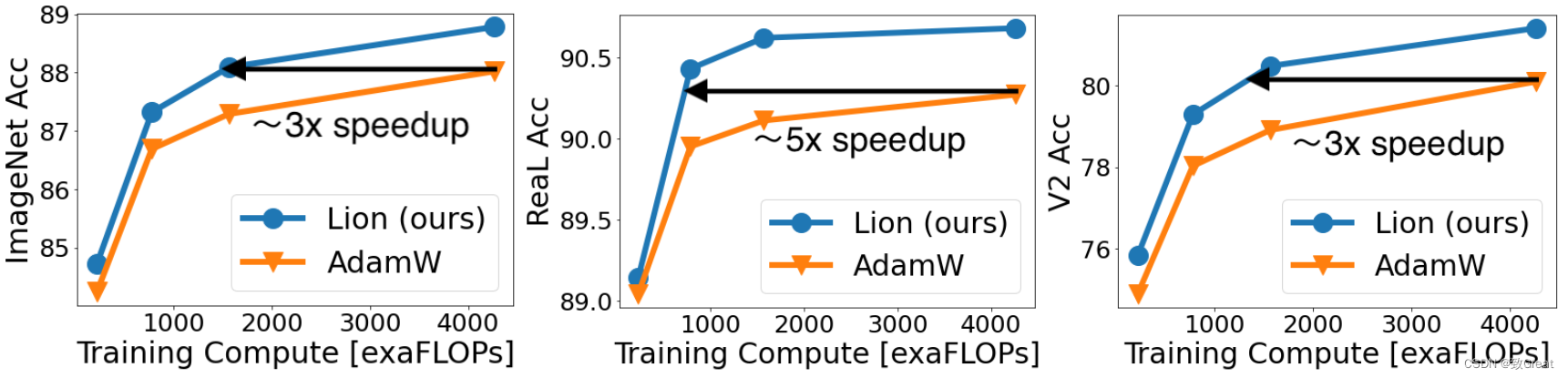
- 使用更高分辨率和 Polyak 平均进行微调后的结果。
Lion获得的 ViT-L/16 与之前由 AdamW 训练的 ViT-H/14 结果相匹配,同时缩小了 2 倍,同时对于 ViT-G/14 在 ImageNet 上进一步达到了 90.71% 的准确率。
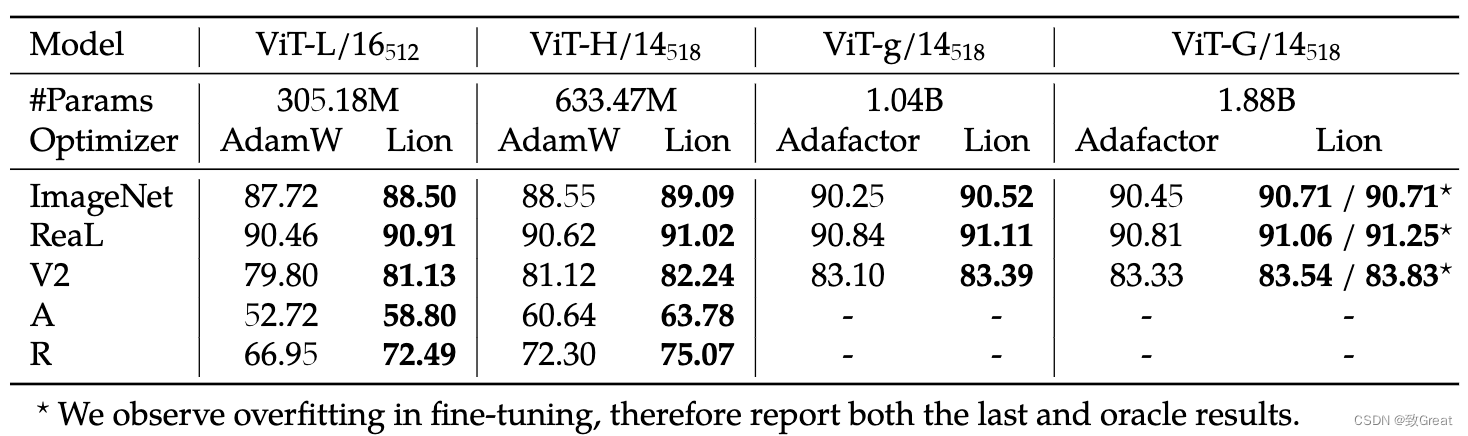
2.2 视觉-语言对比训练
- 在 LiT 上,Lion 在零样本图像分类和图像文本检索方面击败了 AdamW。
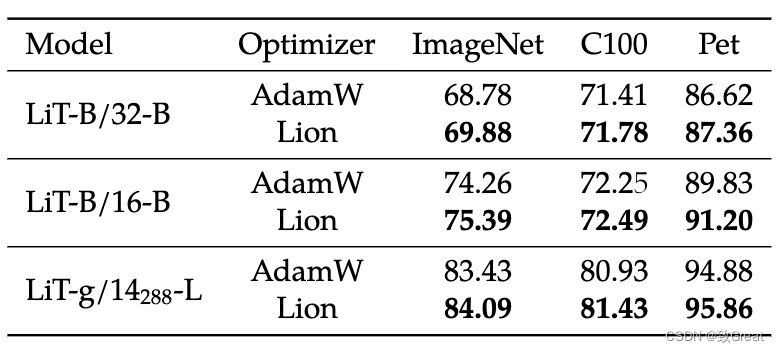
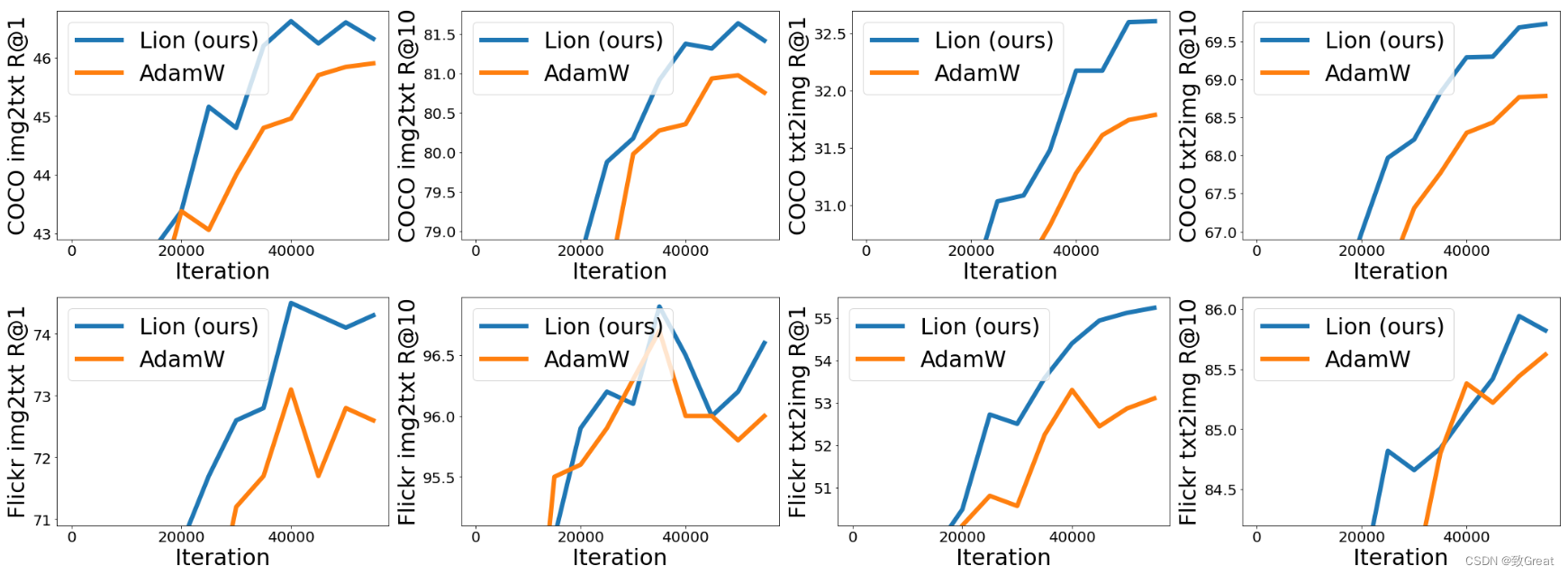
- 在 BASIC-L 上,Lion 实现了 88.3% 的零样本和 91.1% 的微调 ImageNet 准确率,分别超过之前的最佳结果 2% 和 0.1%。

2.3 扩散模型
- 在扩散模型上,Lion 在 FID 分数方面超过了 AdamW,节省了高达 2.3 倍的训练计算。 从左到右:在 ImageNet 上训练的 64x64、128x128、256x256 图像生成。
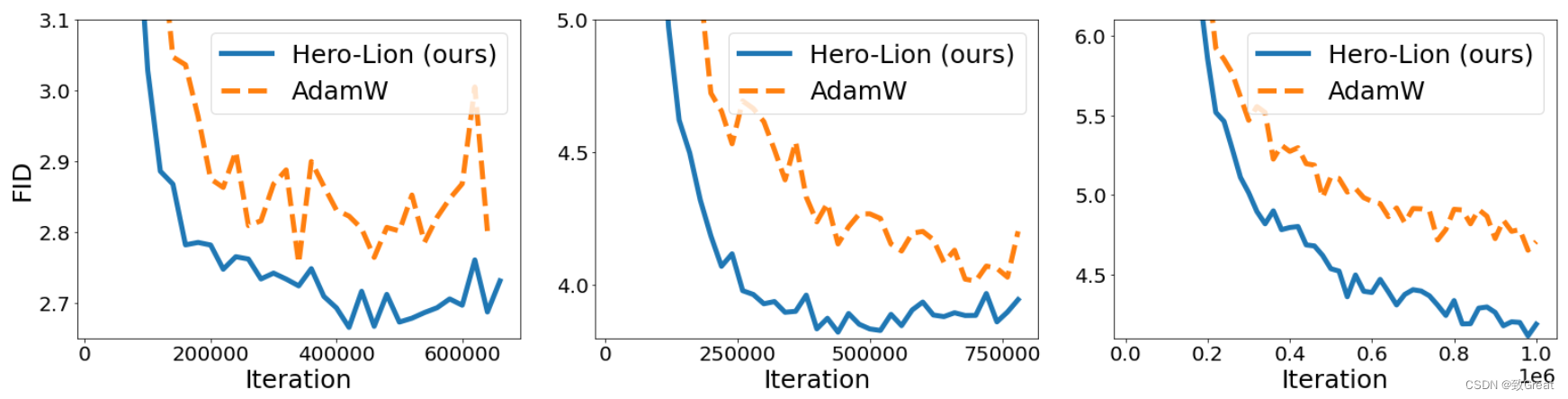
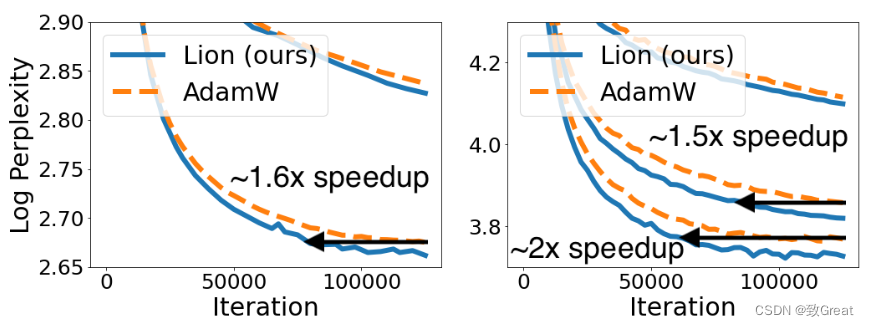
2.4 语言建模
- Lion 在执行语言建模任务时在验证困惑度(perplexity)上节省了高达 2 倍的计算量(左:在 Wiki-40B 上,右:在 PG-19 上)。 Lion 在更大的transformer上获得更大的收益。
- 与 Adafactor 相比,Lion 在训练 LLM 时获得更好的平均上下文学习能力。
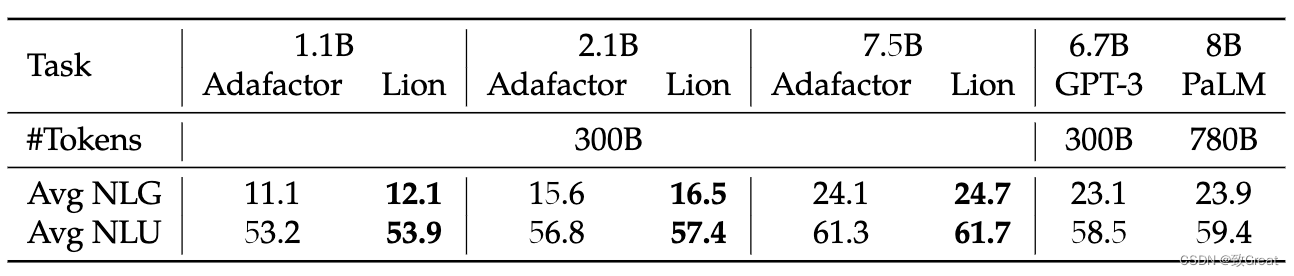
- 在 GLUE 上微调 T5 时 Lion 也更好。
3 超参数和批量大小选择
-
Lion 很简单,与 AdamW 和 Adafactor 相比,超参数更少,因为它不需要 ϵ\epsilonϵ 和因式分解相关的参数。
为了确保公平比较,我们使用对数标度为 AdamW (Adafactor) 和我们的 Lion 调整峰值学习率 lrlrlr 和解耦权重衰减 λ\lambdaλ。
AdamW 中 β1\beta_1β1 和 β2\beta_2β2 的默认值分别设置为 0.9 和 0.999,ϵ\epsilonϵ 为 1e−81e-81e−8,而在 Lion 中,β1\beta_1β1 和 β1\beta_1β1 的默认值 β2\beta_2β2 是通过程序搜索过程发现的,分别设置为 0.9 和 0.99。
作者只调整语言任务中的那些超参数,其中 β1=0.9\beta_1=0.9β1=0.9,β2=0.99\beta_2=0.99β2=0.99 在 AdamW 中,β1=0.95\beta_1=0.95β1=0.95,β2=0.98\beta_2=0.98β2=0.98 在 Lion 中。 此外,AdamW 中的 ϵ\epsilonϵ 设置为 1e−61e-61e−6 而不是默认的 1e−81e-81e−8,因为它提高了我们实验中的稳定性,类似于 RoBERTa 中的观察结果。 -
Lion 生成的更新是元素二进制 ±1\pm 1±1,作为符号操作的结果,因此它具有比其他优化器生成的更大的范数。
根据作者的经验,Lion 的合适学习率通常比 AdamW 小 10 倍,尽管有时小 3 倍的学习率可能表现稍好。
由于有效权重衰减为 lr∗λlr * \lambdalr∗λ,因此用于 Lion 的 λ\lambdaλ 值比 AdamW 大 10 倍,以保持相似的强度。
例如,- lr=1e−4lr=1e-4lr=1e−4, λ=10.0\lambda=10.0λ=10.0 在 Lion 和 lr=1e−3lr=1e-3lr=1e−3, λ=1.0\lambda=1.0λ=1.0 在 ImageNet 上训练 ViT-B/16 时使用强增强。
- Lion 中的 lr=3e−5lr=3e-5lr=3e−5, λ=0.1\lambda=0.1λ=0.1 和 AdamW 中的 lr=3e−4lr=3e-4lr=3e−4, λ=0.01\lambda=0.01λ=0.01 用于扩散模型。
- Lion 中的 lr=1e−4lr=1e-4lr=1e−4、λ=0.01\lambda=0.01λ=0.01 和 Adafactor 中的 lr=1e−3lr=1e-3lr=1e−3、λ=0.001\lambda=0.001λ=0.001 用于 7.5B 语言建模。
-
除了峰值性能外,对超参数的敏感性和调整它们的难度对于在实践中采用优化器也很关键。 在下图中,我们在 ImageNet 上从头开始训练 ViT-B/16 时同时更改 lrlrlr 和 λ\lambdaλ。 热图表明,与 AdamW 相比,Lion 对于不同的超参数选择更加稳健。
-
有些人可能会质疑 Lion 是否需要大批量大小才能准确确定方向,因为标志操作会增加噪音。 为了解决这个问题,我们使用各种批量大小在 ImageNet 上训练 ViT-B/16 模型,同时将总训练时期保持为 300,并结合 RandAug 和 Mixup 技术。
如下图所示,AdamW 的最佳批量大小为 256,而 Lion 为 4,096。
这表明 Lion 确实更喜欢更大的批处理大小,但即使使用 64 的小批处理大小,其性能仍然保持稳健。
此外,当批量大小扩大到 32K 时,只需要 11K 训练步骤,
Lion 的准确率比 AdamW 高出 2.5%(77.9% 对 75.4%),证明了它在大批量训练环境中的有效性。
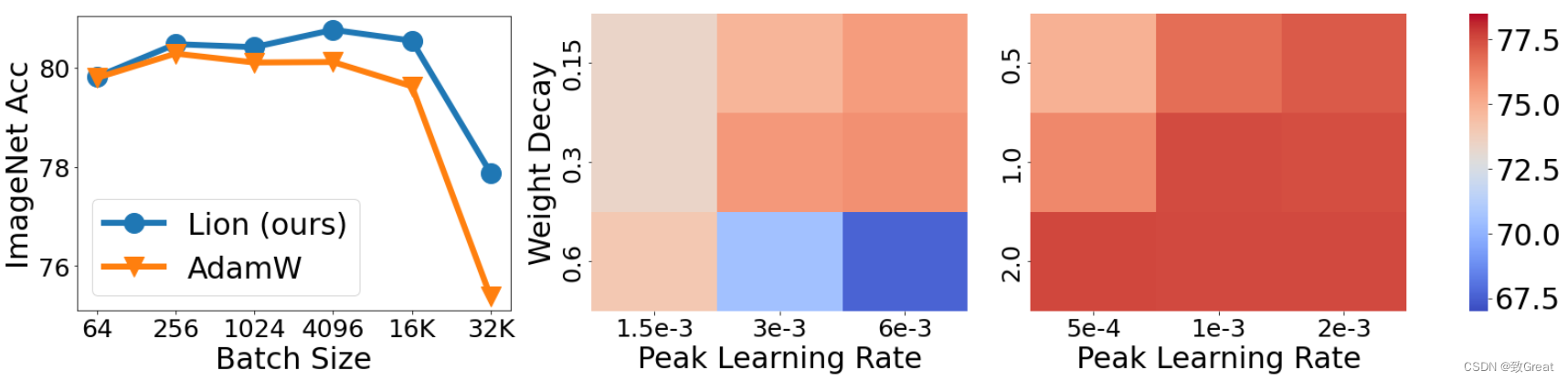
左:批量大小影响的消融实验。 Lion 比 AdamW 更喜欢更大的批次。
当我们为 AdamW(中间)和 Lion(右)改变 lrlrlr 和 λ\lambdaλ 时,从头开始训练的 ViT-B/16 的 ImageNet 精度。 Lion 对于不同的超参数选择更加稳健。
4 代码实现
"""PyTorch implementation of the Lion optimizer."""
import torch
from torch.optim.optimizer import Optimizerclass Lion(Optimizer):r"""Implements Lion algorithm."""def __init__(self, params, lr=1e-4, betas=(0.9, 0.99), weight_decay=0.0):"""Initialize the hyperparameters.Args:params (iterable): iterable of parameters to optimize or dicts definingparameter groupslr (float, optional): learning rate (default: 1e-4)betas (Tuple[float, float], optional): coefficients used for computingrunning averages of gradient and its square (default: (0.9, 0.99))weight_decay (float, optional): weight decay coefficient (default: 0)"""if not 0.0 <= lr:raise ValueError('Invalid learning rate: {}'.format(lr))if not 0.0 <= betas[0] < 1.0:raise ValueError('Invalid beta parameter at index 0: {}'.format(betas[0]))if not 0.0 <= betas[1] < 1.0:raise ValueError('Invalid beta parameter at index 1: {}'.format(betas[1]))defaults = dict(lr=lr, betas=betas, weight_decay=weight_decay)super().__init__(params, defaults)@torch.no_grad()def step(self, closure=None):"""Performs a single optimization step.Args:closure (callable, optional): A closure that reevaluates the modeland returns the loss.Returns:the loss."""loss = Noneif closure is not None:with torch.enable_grad():loss = closure()for group in self.param_groups:for p in group['params']:if p.grad is None:continue# Perform stepweight decayp.data.mul_(1 - group['lr'] * group['weight_decay'])grad = p.gradstate = self.state[p]# State initializationif len(state) == 0:# Exponential moving average of gradient valuesstate['exp_avg'] = torch.zeros_like(p)exp_avg = state['exp_avg']beta1, beta2 = group['betas']# Weight updateupdate = exp_avg * beta1 + grad * (1 - beta1)p.add_(torch.sign(update), alpha=-group['lr'])# Decay the momentum running average coefficientexp_avg.mul_(beta2).add_(grad, alpha=1 - beta2)return loss
5 参考资料
- https://github.com/google/automl/blob/master/lion/README.md
相关文章:
Google Brain新提出的优化器“Lion”,效果要比Adam(W)更好
Google Brain新提出的优化器“Lion”,效果要比Adam(W)更好 论文地址:https://arxiv.org/abs/2302.06675代码地址:https://github.com/google/automl/blob/master/lion/lion_pytorch.py 1 简单、内存高效、运行速度更快 与 AdamW 和各种自适…...

慢雾:Discord 私信钓鱼手法分析
事件背景 5 月 16 日凌晨,当我在寻找家人的时候,从项目官网的邀请链接加入了官方的 Discord 服务器。在我加入服务器后立刻就有一个"机器人"(Captcha.bot)发来私信要我进行人机验证。这一切看起来相当的合理。我也点击了这个验证链接进行查看…...

2023-2-25 刷题情况
交换字符使得字符串相同 题目描述 有两个长度相同的字符串 s1 和 s2,且它们其中 只含有 字符 “x” 和 “y”,你需要通过「交换字符」的方式使这两个字符串相同。 每次「交换字符」的时候,你都可以在两个字符串中各选一个字符进行交换。 …...

【数据结构】双向链表的接口实现(附图解和源码)
双向链表的接口实现(附图解和源码) 文章目录双向链表的接口实现(附图解和源码)前言一、定义结构体二、接口实现(附图解源码)1.初始化双向链表2.开辟新空间3.尾插数据4.尾删数据5.打印双向链表中数据6.头插数…...
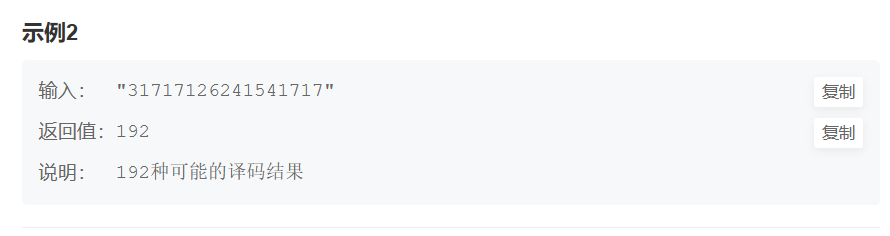
数据结构与算法之[把数字翻译成字符串]动态规划
前言:最近在刷动态规划的算法题目,感觉这一类题目还是有一点难度的,但是不放弃也还是能学好的,今天给大家分享的是牛客网中的编程题目[把数字翻译成字符串],这是一道经典的面试题目,快手,字节跳…...
java 面向对象三大特性之多态 万字详解(超详细)
目录 前言 : 一、为什么需要多态 : 1.白璧微瑕 : 2.举栗(请甘雨,刻晴,钟离吃饭): 3.代码 : 4.问题 : 二、什么是多态 : 1.定义 : 2.多态的实现步骤(重要) : 三、多态的使用 : 1.多态中成员方法的使用(重要…...

git push origin master 情况
📢📢📢📣📣📣哈喽!大家好,我是「奇点」,江湖人称 singularity。刚工作几年,想和大家一同进步🤝🤝一位上进心十足的【Java ToB端大厂领…...

ElasticSearch查询优化routing
如果一个索引分片多达一百,再加上每个分片数据量大的情况下ES查询速度会慢,这种情况可以根据业务情况考虑使用_routing优化。 _routing 路由 当索引一个文档的时候,文档会被存储在一个主分片上。在存储时一般都会有多个主分片。Elasticsearch 如何知道一个文档应该放置在哪…...

【HashMap 1.7和1.8】
Java中的HashMap是一种常用的数据结构,用于存储键值对。在Java 1.7和1.8中,HashMap的实现有一些不同。 Java 1.7中的HashMap实现是基于“拉链法”的哈希表。每个哈希桶(bucket)是一个链表,存储了散列值相同的键值对。当键值对数量过多时&…...

【Zabbix实战之故障处理篇】Zabbix监控中文乱码问题解决方法
【Zabbix实战之故障处理篇】Zabbix监控中文乱码问题解决方法 一、问题展现1.查看Zabbix仪表盘2.问题分析二、检查Zabbix环境1.检查Zabbix监控主机2.检查Zabbix各组件状态三、在宿主机安装中文字体库1.安装中文字体2.查看字体文件四、安装中文字库1.查看Zabbix所有组件容器2.拷贝…...
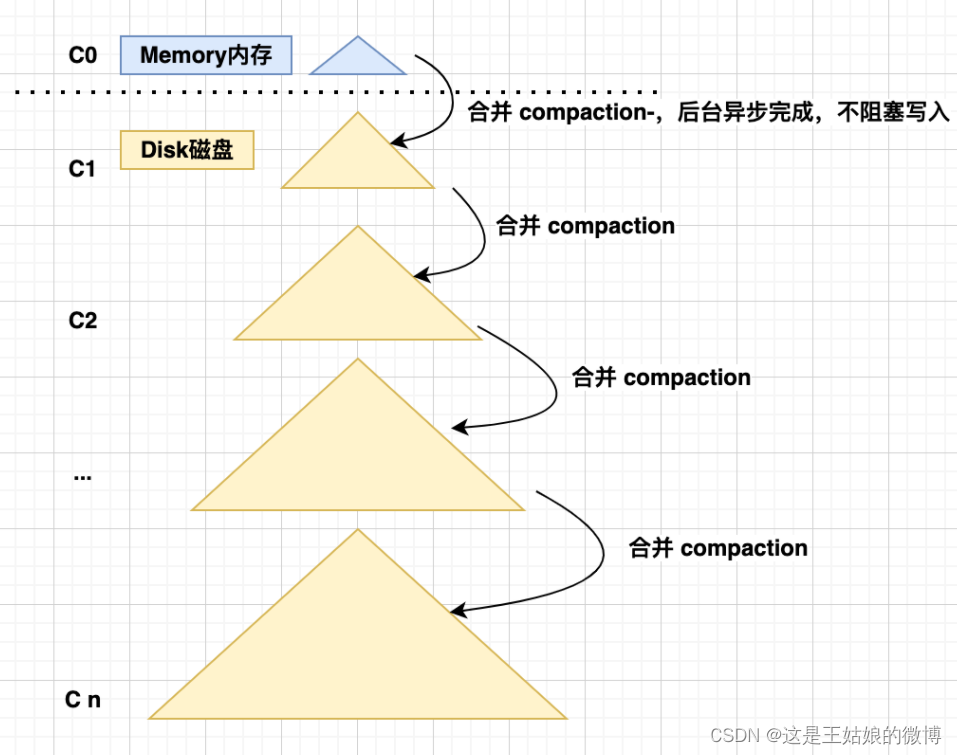
学习(mianshi)必备-ClickHouse高性能查询/写入和常见注意事项(五)
目录 一、ClickHouse高性能查询原因-稀疏索引 二、ClickHouse高性能写入-LSM-Tree存储结构 什么是LSM-Tree 三、ClickHouse的常见注意事项和异常问题排查 一、ClickHouse高性能查询原因-稀疏索引 密集索引: 在密集索引中,数据库中的每个键值都有一个索引记录&…...
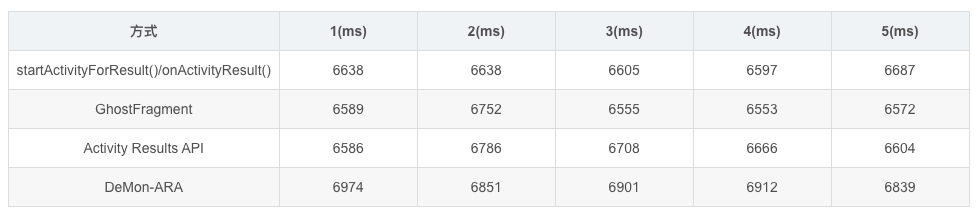
在Kotlin中探索 Activity Results API 极简的解决方案
Activity Results APIActivity Result API提供了用于注册结果、启动结果以及在系统分派结果后对其进行处理的组件。—Google官方文档https://developer.android.google.cn/training/basics/intents/result?hlzh-cn一句话解释:官方Jetpack组件用于代替startActivity…...

样式冲突太多,记一次前端CSS升级
目前平台前端使用的是原生CSSBEM命名,在多人协作的模式下,容易出现样式冲突。为了减少这一类的问题,提升研效,我调研了业界上主流的7种CSS解决方案,并将最终升级方案落地到了工程中。 样式冲突的原因 目前遇到的样式…...

如何解决报考PMP的那些问题?
关于PMP的报考条件,报考PMP都需要什么条件呢?【学历条件】:需要满足23周岁/高中毕业5年以上/大专以上学历,三个满足一个即可;【PDU条件】:报考PMP需要PDU证明(学习项目管理课程的学时证明&#…...
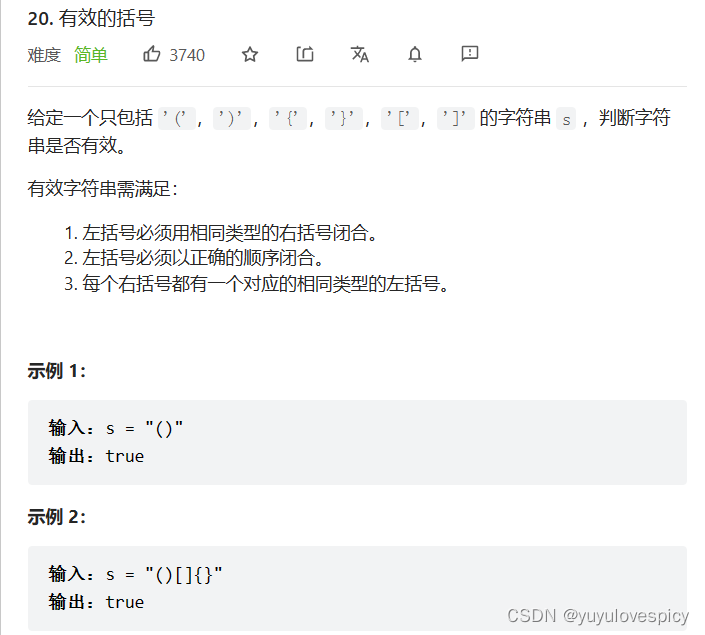
数据结构栈的经典OJ题【leetcode最小栈问题大剖析】【leetcode有效的括号问题大剖析】
目录 0.前言 1.最小栈 1.1 原题展示 1.2 思路分析 1.2.1 场景引入 1.2.2 思路 1.3 代码实现 1.3.1 最小栈的删除 1.3.2 最小栈的插入 1.3.3 获取栈顶元素 1.3.4 获取当前栈的最小值 2. 有效的括号 0.前言 本篇博客已经把两个关于栈的OJ题分块,可以根据目…...
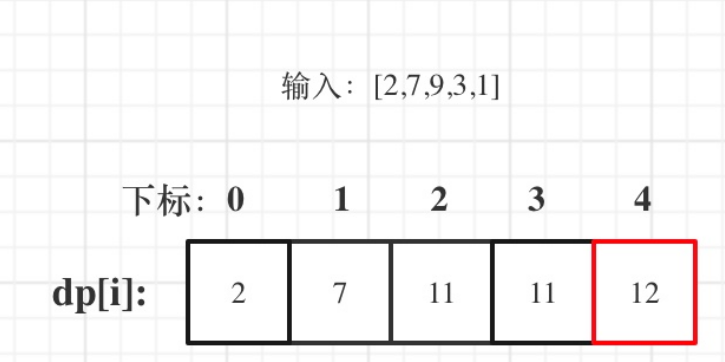
数据结构与算法之打家劫舍(一)动态规划思想
动态规划里面一部题目打家劫舍是一类经典的算法题目之一,他有各种各样的变式,这一篇文章和大家分享一下打家劫舍最基础的一道题目,掌握这一道题目,为下一道题目打下基础。我们直接进入正题。一.题目大家如果刚接触这样的题目&…...

无人驾驶路径规划论文简要
A Review of Motion Planning Techniques for Automated Vehicles综述和分类0Motion Planning for Autonomous Driving with a Conformal Spatiotemporal Lattice从unstructured环境向structured环境的拓展,同时还从state lattice拓展到了spatiotemporal lattice从而…...
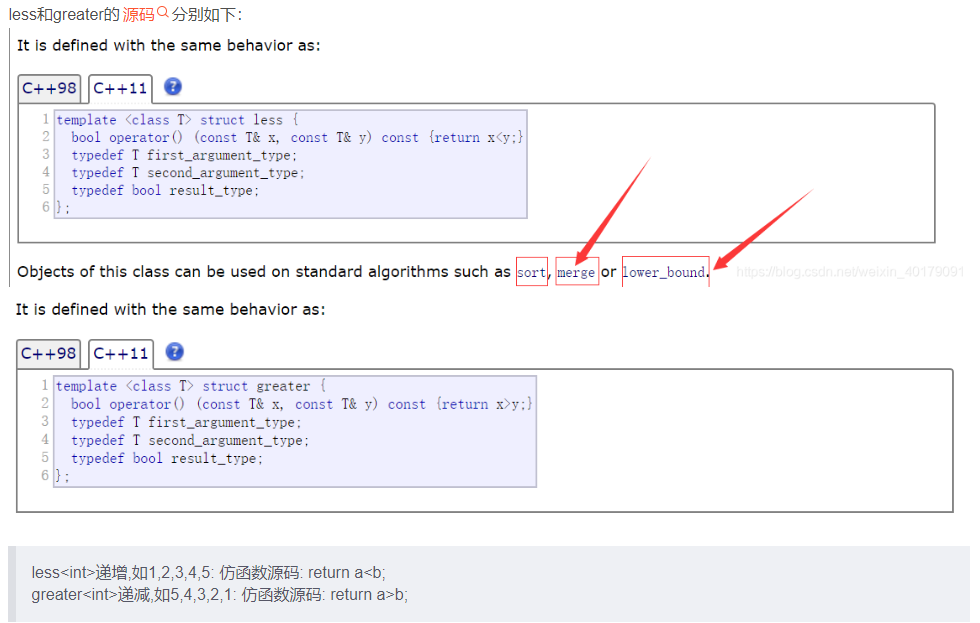
C++ sort()函数和priority_queue容器中比较函数的区别
普通的queue是一种先进先出的数据结构,元素在队列尾追加,而从队列头删除。priority_queue中元素被赋予优先级。在创建的时候根据优先级进行了按照从大到小或者从小到大进行了自动排列(大顶堆or小顶堆)。可以以O(log n) 的效率查找…...
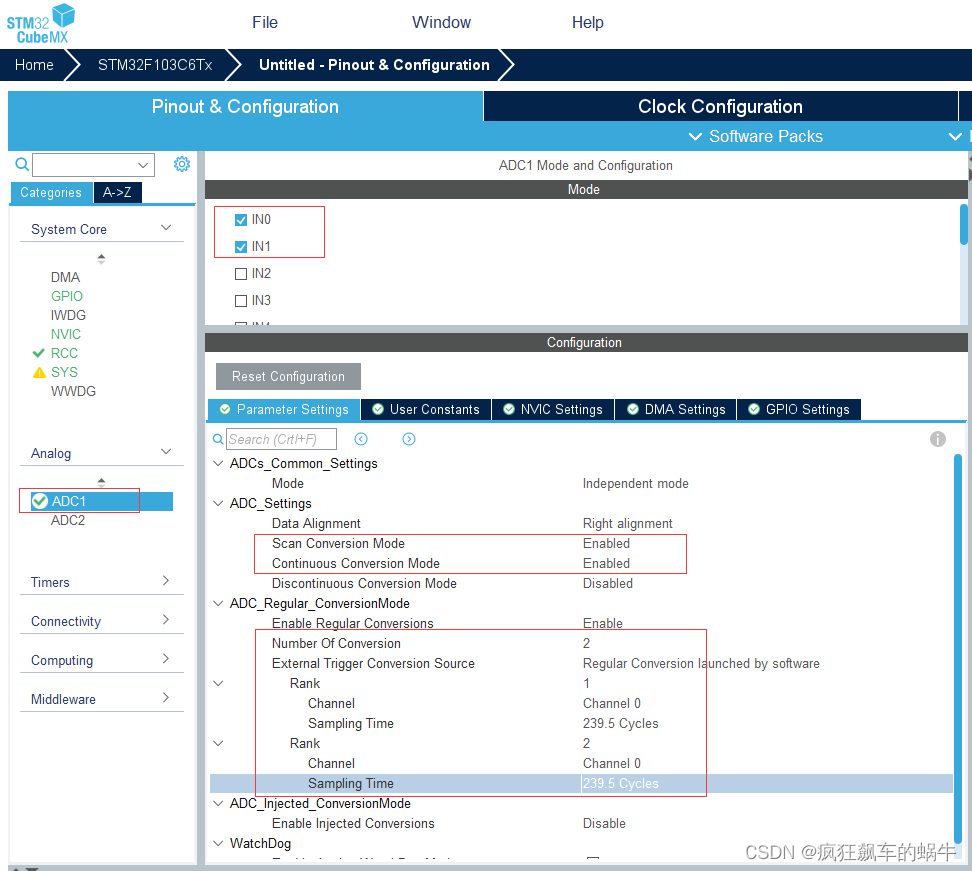
STM32开发(14)----CubeMX配置ADC
CubeMX配置ADC前言一、什么是ADC?二、实验过程1.单通道ADC采集STM32CubeMX配置代码实现2.多通道ADC采样(非DMA)STM32CubeMX配置代码实现3.多通道ADC采样(DMA)STM32CubeMX配置代码实现总结前言 本章介绍使用STM32CubeMX对ADC进行配置的方法&a…...
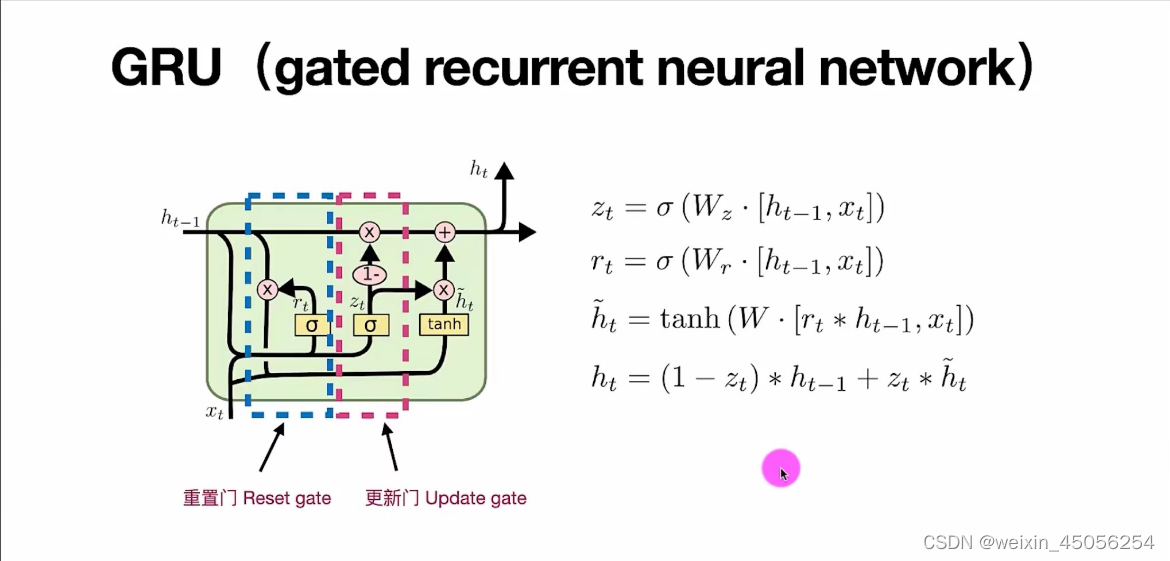
Simple RNN、LSTM、GRU序列模型原理
一。循环神经网络RNN 用于处理序列数据的神经网络就叫循环神经网络。序列数据说直白点就是随时间变化的数据,循环神经网络它能够根据这种数据推出下文结果。RNN是通过嵌含前一时刻的状态信息实行训练的。 RNN神经网络有3个变种,分别为Simple RNN、LSTM、…...

OpenCode效果实测:基于Qwen3-4B的代码生成质量与速度展示
OpenCode效果实测:基于Qwen3-4B的代码生成质量与速度展示 1. 项目概览与技术背景 OpenCode是2024年开源的AI编程助手框架,采用Go语言开发,主打"终端优先、多模型、隐私安全"的设计理念。该项目将大语言模型(LLM)包装成可插拔的Ag…...

从游戏机到影音中心:用wiliwili解锁Switch的隐藏娱乐潜能
从游戏机到影音中心:用wiliwili解锁Switch的隐藏娱乐潜能 【免费下载链接】wiliwili 专为手柄控制设计的第三方跨平台B站客户端,目前可以运行在PC全平台、PSVita、PS4 和 Nintendo Switch上 项目地址: https://gitcode.com/GitHub_Trending/wi/wiliwil…...
!)
AI Agent工程师进阶指南:掌握核心技能,冲击高薪(P7-P8必备)!
本文详细介绍了AI Agent工程师的能力分层,从API调用工程师到系统设计工程师再到基础设施架构师,明确了不同层级的能力要求和市场现状。文章深入剖析了核心技术栈,包括向量数据库、RAG系统、Agent架构、Memory系统以及生产化工程等关键领域&am…...

TradingAgents-CN 多智能体金融分析系统:企业级容器化部署实战指南
TradingAgents-CN 多智能体金融分析系统:企业级容器化部署实战指南 【免费下载链接】TradingAgents-CN 基于多智能体LLM的中文金融交易框架 - TradingAgents中文增强版 项目地址: https://gitcode.com/GitHub_Trending/tr/TradingAgents-CN TradingAgents-CN…...

嘉立创PCB打样被加价到170元?手把手教你用STM32H743飞控板案例解决‘拆单嫌疑’
STM32H743飞控板PCB打样避坑指南:如何巧妙应对嘉立创拆单判定 最近不少硬件开发者在使用嘉立创进行STM32H743飞控板PCB打样时,遇到了一个令人头疼的问题——原本33元的4层板打样价格突然飙升到170多元。这种情况往往是由于平台算法误判设计文件存在"…...

Cursor Pro破解工具:如何通过开源技术方案实现AI编程助手无限制使用?
Cursor Pro破解工具:如何通过开源技术方案实现AI编程助手无限制使用? 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能…...

Mermaid Live Editor:代码驱动图表的革新者,重新定义技术可视化流程
Mermaid Live Editor:代码驱动图表的革新者,重新定义技术可视化流程 【免费下载链接】mermaid-live-editor Edit, preview and share mermaid charts/diagrams. New implementation of the live editor. 项目地址: https://gitcode.com/GitHub_Trendin…...

利用快马平台快速构建arm7流水灯原型,十分钟验证硬件控制逻辑
最近在带学生入门嵌入式开发时,发现ARM7这类经典架构虽然功能强大,但初学者往往会被复杂的环境搭建劝退。为了让大家能快速上手硬件控制逻辑,我尝试用InsCode(快马)平台构建了一个LED流水灯原型,整个过程比想象中顺畅很多。 项目设…...
)
保姆级教程:手把手教你用PHPStudy本地搭建GaussDB开发环境(附JDBC连接避坑指南)
从零搭建GaussDB开发环境:PHPStudy集成与JDBC连接实战 在数据库技术快速迭代的今天,国产数据库正逐渐成为企业级应用的新选择。GaussDB作为一款高性能分布式数据库,其学习门槛却让不少开发者望而却步。本文将带你绕过那些官方文档中语焉不详的…...

重装系统后的环境快速恢复:包含BERT模型部署的自动化脚本
重装系统后的环境快速恢复:包含BERT模型部署的自动化脚本 重装系统,对开发者来说,就像一场“数字大扫除”。清爽是清爽了,但看着空空如也的终端和待部署的一长串服务列表,那种从头再来的疲惫感瞬间涌上心头。尤其是当…...