Java基础面试题知识点总结(上篇)
大家好,我是栗筝i,从 2022 年 10 月份开始,我持续梳理出了全面的 Java 技术栈内容,一方面是对自己学习内容进行整合梳理,另一方面是希望对大家有所帮助,使我们一同进步。得到了很多读者的正面反馈。
而在 2023 年 10 月份开始,我将推出 Java 面试题/知识点系列内容,期望对大家有所助益,让我们一起提升。
本篇是对 Java 基础系列的面试题 / 知识点的总结的上篇
系列相关链接:
文章目录
- 1、Java基础面试题问题
- 2、Java基础面试题解答
- 2.1、JavaObject类相关
- 2.2、Java深拷贝浅拷贝相关
- 2.3、Java序列化反序列化相关
- 2.4、Java数据类型相关
- 2.5、Java字符串相关
1、Java基础面试题问题
Java基础面试题问题(上篇)
- 问题 1. Object 类在 Java 中是什么样的存在?为何在 Java 中,所有的类都会继承自 Object 类?
- 问题 2. Object 类有哪些主要的方法?每个方法的作用是什么?
- 问题 3. Object 类 native 方法和非 native 方法区别是什么?
- 问题 4. Java 中 == 和 equals 的有什么区别?
- 问题 5. Java 中为什么重写 equals() 方法后,还必须重写 hashCode()?
- 问题 6. 什么是深拷贝和浅拷贝?
- 问题 7. Java 中的 clone() 方法默认是深拷贝还是浅拷贝?
- 问题 8. 在实现深拷贝时,如果遇到循环引用该如何处理?
- 问题 9. 在实现深拷贝时,对于数组和集合类应该如何处理?
- 问题 10. Cloneable 接口在 Java 中的作用是什么?
- 问题 11. 为什么说 Cloneable 是一个标记接口?
- 问题 12. 什么是 Java 的序列化和反序列化?
- 问题 13.Java 中的 Serializable 接口有什么作用?
- 问题 14. 在 Java 中,如果一个对象的某个字段不想被序列化,应该如何处理?
- 问题 15. 如何自定义序列化与反序列化过程?
- 问题 16. 静态字段是否可以被序列化?为什么?
- 问题 17. 在 Java 中,默认的序列化机制是怎样的?
- 问题 18. Java 中的基本数据类型有哪些?
- 问题 19. Java 中的自动装箱和拆箱是什么?
- 问题 20. 在 Java 中什么是强制类型转换、隐式类型转换、显式类型转换?
- 问题 21. 为什么 Java 中的字符串不可变?它有什么优势?
- 问题 22. 什么是 Java 中的字符串池?
- 问题 23. 简述
String str = "aaa"与String str = new String("i")一样吗 ? - 问题 24. Java 中有哪些创建字符串的方式?
- 问题 25. 介绍一下 String、StringBuffer、StringBuilder 和他们之间的区别?
2、Java基础面试题解答
2.1、JavaObject类相关
- 问题 1. Object 类在 Java 中是什么样的存在?为何在 Java 中,所有的类都会继承自 Object 类?
解答:Object 类在 Java 中被视为所有类的基础和起点。这是因为在 Java 中,所有的类都默认继承自 Object 类,无论是 Java 内置的类,还是用户自定义的类。这种设计使得所有的 Java 对象都能够调用一些基本的方法,例如 equals(), hashCode(), toString() 等,这些方法都在 Object 类中被定义。
- 问题 2. Object 类有哪些主要的方法?每个方法的作用是什么?
解答:Object 类中的方法可以分为两类:native 方法和非 native 方法。
非 native 方法是:
equals():判断与其他对象是否相等。clone():创建并返回此对象的一个副本。toString():返回该对象的字符串表示。finalize():当垃圾回收器确定不存在对该对象的更多引用时,由对象的垃圾回收器调用此方法。
native 方法是:
getClass():返回此 Object 的运行时类。hashCode():返回该对象的哈希码值。notify():唤醒在此对象监视器上等待的单个线程。notifyAll():唤醒在此对象监视器上等待的所有线程。wait(long timeout):在其他线程调用此对象的 notify() 方法或 notifyAll() 方法前,导致当前线程等待。
- 问题 3. Object 类 native 方法和非 native 方法区别是什么?
解答:native 方法和非 native 方法的主要区别在于它们的实现方式和运行环境。
- native 方法:这些方法在 Java 代码中声明,但是它们的实现是用其他语言(通常是 C 或 C++)编写的,并且在 Java 之外的环境中运行。native 方法可以访问系统特有的资源,如硬件设备接口、系统调用等。在 Java 代码中,native 方法通常用关键字 “native” 声明。
- 非 native 方法:这些方法完全在 Java 中声明和实现。它们在 Java 虚拟机(JVM)内部运行,并且只能访问由 JVM 提供的资源。非 native 方法不能直接访问系统资源或执行系统调用。
- 问题 4. Java 中 == 和 equals 的有什么区别?
在 Java 中,== 和 equals() 方法用于比较两个对象,但它们的比较方式和使用场景有所不同。
-
==:对于基本数据类型,==比较的是值是否相等;对于引用类型,==比较的是两个引用是否指向同一个对象,即它们的地址是否相同。 -
equals():这是一个方法,不是操作符。它的行为可能会根据它在哪个类中被调用而变化。在 Object 类中,equals()方法的行为和==相同,比较的是引用是否指向同一个对象。但是在一些类(如 String、Integer 等)中,equals()方法被重写,用于比较两个对象的内容是否相等。因此,如果你想比较两个对象的内容是否相等,应该使用equals()方法。
- 问题 5. Java 中为什么重写 equals() 方法后,还必须重写 hashCode()?
解答:在 Java 中,equals() 和 hashCode() 两个方法是密切相关的。如果你重写了 equals() 方法,那么你也必须重写 hashCode() 方法,以保证两个相等的对象必须有相同的哈希码。这是因为在 Java 集合框架中,特别是哈希表相关的数据结构(如 HashMap、HashSet 等)在存储和检索元素时,会使用到对象的 hashCode() 方法。
以下是 Java 中 equals() 和 hashCode() 方法的一般约定:
-
如果两个对象相等(即,
equals(Object)方法返回true),那么调用这两个对象中任一对象的hashCode()方法都必须产生相同的整数结果。 -
如果两个对象不等(即,
equals(Object)方法返回false),那么调用这两个对象中任一对象的hashCode()方法,不要求必须产生不同的整数结果。但是,程序员应该意识到,为不相等的对象生成不同的整数结果可能提高哈希表的性能。
因此,如果你重写了 equals() 方法但没有重写 hashCode() 方法,可能会导致违反上述的第一条约定,从而影响到哈希表相关数据结构的正确性和性能。
2.2、Java深拷贝浅拷贝相关
- 问题 6. 什么是深拷贝和浅拷贝?
解答:深拷贝和浅拷贝是编程中常见的两种复制对象的方式,主要区别在于是否复制对象内部的引用对象。
-
浅拷贝(Shallow Copy):当进行浅拷贝时,如果对象中的字段是基本类型,会直接复制其值;如果对象中的字段是引用类型,那么只复制其引用,而不复制引用指向的对象。因此,原对象和拷贝对象会共享同一个引用对象。这就意味着,如果其中一个对象改变了这个引用对象的内容,那么另一个对象的这个引用对象的内容也会随之改变。
-
深拷贝(Deep Copy):当进行深拷贝时,无论对象中的字段是基本类型还是引用类型,都会创建一个新的副本。对于引用类型,会复制引用指向的对象,而不仅仅是复制引用。因此,原对象和拷贝对象不会共享任何一个引用对象。这就意味着,无论哪一个对象改变了引用对象的内容,都不会影响到另一个对象。
需要注意的是,实现深拷贝可能会比较复杂,特别是当对象的引用结构很复杂时,例如存在循环引用。此外,深拷贝可能会消耗更多的计算和存储资源。
- 问题 7. Java 中的 clone() 方法默认是深拷贝还是浅拷贝?
解答:在 Java 中,clone() 方法默认进行的是浅拷贝。
这意味着,如果你的对象中包含了对其他对象的引用,那么 clone() 方法只会复制这个引用,而不会复制引用指向的对象。因此,原对象和克隆对象会共享这个引用指向的对象,这就是所谓的浅拷贝。
如果你想实现深拷贝,即完全复制一个新的对象,包括其引用的所有对象,那么你需要重写 clone() 方法,手动复制这些对象。
- 问题 8. 在实现深拷贝时,如果遇到循环引用该如何处理?
解答:在实现深拷贝时,如果遇到循环引用,需要特别小心,否则可能会导致无限递归,最终导致栈溢出。
处理循环引用的一种常见方法是使用一个哈希表来跟踪已经复制过的对象。具体来说,每当你复制一个对象时,都将原对象和复制的新对象放入哈希表中。然后,在复制一个对象之前,先检查这个对象是否已经在哈希表中。如果已经在哈希表中,那么就直接返回哈希表中的复制对象,而不再进行复制。
以下是一个简单的示例:
public class Node {public Node next;// ...
}public class DeepCopy {private HashMap<Node, Node> visited = new HashMap<>();public Node clone(Node node) {if (node == null) {return null;}if (visited.containsKey(node)) {return visited.get(node);}Node cloneNode = new Node();visited.put(node, cloneNode);cloneNode.next = clone(node.next);return cloneNode;}
}
在这个示例中,DeepCopy 类使用了一个 visited 哈希表来跟踪已经复制过的 Node 对象。在 clone() 方法中,每次复制一个 Node 对象之前,都会先检查这个对象是否已经在 visited 哈希表中。这样就可以避免因为循环引用而导致的无限递归。
- 问题 9. 在实现深拷贝时,对于数组和集合类应该如何处理?
解答:在实现深拷贝时,对于数组和集合类的处理需要特别注意,因为它们都可能包含引用类型的元素。
数组:如果数组的元素是基本类型,那么可以直接使用 clone() 方法或 System.arraycopy() 方法来复制数组。如果数组的元素是引用类型,那么需要遍历数组,对每个元素进行深拷贝。
MyClass[] copy = new MyClass[array.length];
for (int i = 0; i < array.length; i++) {copy[i] = array[i].clone();
}
集合类:对于集合类,如 ArrayList、HashSet 等,需要创建一个新的集合,然后遍历原集合,对每个元素进行深拷贝,并添加到新集合中。
ArrayList<MyClass> copy = new ArrayList<>();
for (MyClass item : list) {copy.add(item.clone());
}
需要注意的是,实现深拷贝可能会比较复杂,特别是当对象的引用结构很复杂时,例如存在循环引用。此外,深拷贝可能会消耗更多的计算和存储资源。
- 问题 10. Cloneable 接口在 Java 中的作用是什么?
解答:Cloneable 接口在 Java 中被称为标记接口(Marker Interface),它本身并没有定义任何方法,但是它对于 Java 的对象克隆机制来说非常重要。
当一个类实现了 Cloneable 接口后,它就表明它的对象是可以被克隆的,即它的 clone() 方法可以被合法地调用。如果一个类没有实现 Cloneable 接口,但是调用了它的 clone() 方法,那么将会在运行时抛出 CloneNotSupportedException 异常。
实现 Cloneable 接口的目的是为了让 Object 的 clone() 方法知道它可以对这个类的对象进行字段对字段的复制。
需要注意的是,虽然 Cloneable 接口本身并没有定义任何方法,但是实现 Cloneable 接口的类通常需要重写 Object 类的 clone() 方法,以提供公开的克隆方法并实现类特定的克隆行为,例如深拷贝。
- 问题 11. 为什么说 Cloneable 是一个标记接口?
Cloneable 接口被称为标记接口,是因为它本身并没有定义任何方法,它的作用主要是为了标记一个类的对象可以被克隆。
在 Java 中,Cloneable 接口的主要作用是告诉 Object 的 clone() 方法,它可以对实现了 Cloneable 接口的类的对象进行字段对字段的复制。
如果一个类没有实现 Cloneable 接口,但是调用了它的 clone() 方法,那么将会在运行时抛出 CloneNotSupportedException 异常。
因此,Cloneable 接口虽然没有定义任何方法,但是它对于 Java 的对象克隆机制来说非常重要,它是一种标记,表明一个类的对象可以被克隆。
2.3、Java序列化反序列化相关
- 问题 12. 什么是 Java 的序列化和反序列化?
解答:Java 的序列化(Serialization)和反序列化(Deserialization)是 Java 对象持久化的一种机制。
-
序列化:序列化是将对象的状态信息转换为可以存储或传输的形式的过程。在序列化过程中,对象将其当前状态写入到一个输出流中。
-
反序列化:反序列化是从一个输入流中读取对象的状态信息,并根据这些信息创建对象的过程。
序列化和反序列化在很多场景中都非常有用,例如:
- 在网络通信中,序列化可以用于在网络上发送对象。
- 在持久化数据时,序列化可以用于将对象保存到磁盘,然后在需要时通过反序列化重新创建。
- 在 Java RMI(远程方法调用)技术中,序列化和反序列化被用于在 JVM 之间传递对象。
在 Java 中,如果一个类的对象需要支持序列化和反序列化,那么这个类需要实现 java.io.Serializable 接口。这个接口是一个标记接口,没有定义任何方法,只是用来表明一个类的对象可以被序列化和反序列化。
- 问题 13.Java 中的 Serializable 接口有什么作用?
解答:在 Java 中,Serializable 接口是一个标记接口,用于表明一个类的对象可以被序列化和反序列化。
序列化是将对象的状态信息转换为可以存储或传输的形式的过程。反序列化则是从一个输入流中读取对象的状态信息,并根据这些信息创建对象的过程。
如果一个类实现了 Serializable 接口,那么它的对象可以被序列化,即可以将对象的状态信息写入到一个输出流中。然后,这个输出流可以被存储到磁盘,或通过网络发送到另一个运行 JVM 的机器。在需要时,可以从这个输出流中读取对象的状态信息,并通过反序列化重新创建对象。
需要注意的是,Serializable 接口本身并没有定义任何方法,它只是一个标记接口。实际的序列化和反序列化过程是由 JVM 通过一些特殊的机制来完成的。
- 问题 14. 在 Java 中,如果一个对象的某个字段不想被序列化,应该如何处理?
在 Java 中,如果你不希望对象的某个字段被序列化,你可以使用 transient 关键字来修饰这个字段。
transient 是 Java 的一个关键字,用来表示一个字段不应该被序列化。在对象序列化的过程中,被 transient 修饰的字段会被忽略,不会被写入到输出流中。因此,这个字段的状态信息不会被持久化。
例如:
public class MyClass implements Serializable {private int field1;private transient int field2;// ...
}
在这个例子中,field1 字段会被序列化,而 field2 字段则不会被序列化。
需要注意的是,如果一个字段被标记为 transient,那么在反序列化的过程中,这个字段的值会被初始化为其类型的默认值,例如 null、0 或 false。
- 问题 15. 如何自定义序列化与反序列化过程?
解答:在 Java 中,虽然默认的序列化机制已经足够强大,但在某些情况下,你可能需要自定义序列化过程。例如,你可能需要对某些敏感信息进行加密,或者需要以特定的格式写入对象的状态信息。
要自定义序列化过程,你可以在类中添加一个名为 writeObject() 的方法。这个方法必须接受一个 ObjectOutputStream 类型的参数,并且返回 void:
private void writeObject(ObjectOutputStream out) throws IOException {// 自定义序列化过程
}
在这个方法中,你可以自定义序列化过程。例如,你可以选择只序列化部分字段,或者对某些字段进行特殊处理。
需要注意的是,writeObject() 方法必须是 private 的,这是因为序列化机制会忽略 public 和 protected 的 writeObject() 方法。
同样,如果你需要自定义反序列化过程,你可以添加一个名为 readObject() 的方法:
private void readObject(ObjectInputStream in) throws IOException, ClassNotFoundException {// 自定义反序列化过程
}
在这个方法中,你可以自定义反序列化过程。例如,你可以选择只反序列化部分字段,或者对某些字段进行特殊处理。
同样,readObject() 方法必须是 private 的。
- 问题 16. 静态字段是否可以被序列化?为什么?
解答:静态字段不能被序列化。这是因为静态字段不属于对象,而是属于类。
在 Java 中,静态字段是类级别的,所有的对象实例共享同一个静态字段。因此,静态字段的状态不应该被看作是对象的一部分,所以在序列化对象时,静态字段会被忽略。
序列化的主要目的是为了保存对象的状态,以便在需要时可以恢复这个状态。但是,静态字段的状态是与特定的对象无关的,所以无需在序列化过程中保存和恢复。
如果你需要保存和恢复静态字段的状态,你需要通过其他方式来实现,例如,你可以在序列化和反序列化过程中手动处理静态字段。
- 问题 17. 在 Java 中,默认的序列化机制是怎样的?
解答:在 Java 中,对象的默认序列化机制是通过实现 java.io.Serializable 接口来完成的。Serializable 是一个标记接口,它本身并没有定义任何方法,但是它告诉 Java 虚拟机(JVM)这个对象是可以被序列化的。
当一个对象被序列化时,JVM 会将该对象的类信息、类的签名以及非静态和非瞬态字段的值写入到一个输出流中。这个过程是自动的,不需要程序员进行任何特殊处理。
具体来说,序列化过程如下:
-
如果对象的类定义了
writeObject方法,那么 JVM 会调用这个方法进行序列化。否则,JVM 会默认地进行序列化。 -
JVM 会检查每个需要序列化的字段。如果字段是基本类型,那么 JVM 会直接写入其值。如果字段是引用类型,那么 JVM 会递归地对这个字段指向的对象进行序列化。
-
如果对象的类实现了
Externalizable接口,那么 JVM 会调用writeExternal方法进行序列化。
反序列化过程与序列化过程相反。当一个对象被反序列化时,JVM 会从输入流中读取类信息和字段的值,然后根据这些信息创建新的对象。
需要注意的是,静态字段和用 transient 关键字修饰的字段不会被序列化。静态字段属于类,而不是对象。transient 关键字告诉 JVM 该字段不应该被序列化。
2.4、Java数据类型相关
- 问题 18. Java 中的基本数据类型有哪些?
解答:Java 中的数据类型可以分为 4 类 8 种,4 类分别为:整型、浮点型、字符型和布尔型。
- 整型:包括 byte、short、int 和 long 四种类型,主要用于表示没有小数部分的数值,区别在于它们的取值范围和存储大小不同。
byte:占用 1 字节,取值范围为 -128 到 127
short:占用 2 字节,取值范围为 -32768 到 32767
int:占用 4 字节,取值范围为 -2147483648 到 2147483647
long:占用 8 字节,取值范围为 -9223372036854775808 到 9223372036854775807
- 浮点型:包括 float 和 double 两种类型,主要用于表示有小数部分的数值。
float:单精度浮点型,占用 4 字节,取值范围为 1.4E-45 到 3.4028235E38
double:双精度浮点型,占用 8 字节,取值范围为 4.9E-324 到 1.7976931348623157E308
- 字符型:只有 char 一种类型,主要用于表示单个字符。
char:占用 2 字节,取值范围为 0 到 65535,可以表示 Unicode 编码中的任何字符。
- 布尔型:只有 boolean 一种类型,主要用于表示真或假的逻辑值。
boolean:只有两个取值,即 true 和 false。
- 问题 19. Java 中的自动装箱和拆箱是什么?
解答:自动装箱和拆箱是 Java 5.0 版本引入的新特性,主要用于基本数据类型和对应的包装类之间的自动转换。
自动装箱和拆箱是 Java 编译器的特性,它在编译阶段会自动为我们插入必要的代码来实现基本数据类型和包装类之间的转换。
- 自动装箱(Autoboxing):是指基本数据类型自动转换为对应的包装类。例如,将 int 类型自动转换为 Integer 类型。
int i = 10;
Integer integer = i; // 自动装箱 编译器会将这行代码转换为:Integer integer = Integer.valueOf(i);
- 自动拆箱(Unboxing):是指包装类自动转换为对应的基本数据类型。例如,将 Integer 类型自动转换为 int 类型。
Integer integer = new Integer(10);
int i = integer; // 自动拆箱 编译器会将这行代码转换为:int i = integer.intValue();
这两个特性使得基本数据类型和包装类在很多情况下可以互相替代,大大提高了编程的便利性。
- 问题 20. 在 Java 中什么是强制类型转换、隐式类型转换、显式类型转换?
解答:
- 强制类型转换:也称为显式类型转换,是指程序员明确要求进行的类型转换。在 Java 中,可以通过在表达式前加上类型名的方式来进行强制类型转换。例如:
double d = 10.5;
int i = (int) d; // 将 double 类型转换为 int 类型
- 隐式类型转换:也称为自动类型转换,是指编译器在编译过程中自动进行的类型转换。在 Java 中,当我们把一个表示范围小的类型赋值给一个表示范围大的类型时,编译器会自动进行类型转换。例如:
int i = 10;
double d = i; // 将 int 类型自动转换为 double 类型
- 显式类型转换:和强制类型转换是同一个概念,都是指程序员明确要求进行的类型转换。
2.5、Java字符串相关
- 问题 21. 为什么 Java 中的字符串不可变?它有什么优势?
解答:Java 中的字符串被设计为不可变的,这意味着一旦创建字符串对象,其内容无法更改。这个设计决策具有一些重要的优势:
-
线程安全性: 不可变字符串是线程安全的,因为多个线程可以同时访问一个字符串对象而无需担心并发修改导致的问题。这对于多线程应用程序来说是非常重要的。
-
安全性: 不可变字符串可以用作参数传递给方法,而不必担心方法在不经意间更改了字符串的内容。
-
性能优化: 因为字符串不可变,可以在运行时对其进行缓存,以减少内存占用和提高性能。例如,多个字符串变量可以共享相同的字符串字面值,从而节省内存。
-
哈希码缓存: 字符串的哈希码可以在创建时计算并缓存,这样在后续哈希比较(如在哈希表中查找字符串)时会更加高效。
-
字符串池: 不可变字符串使得字符串池的实现更容易,从而可以共享字符串字面值,减少内存占用。
-
安全性: 不可变字符串对于安全性是有帮助的。例如,当字符串用于密码或其他敏感数据时,不可变性可以确保这些数据不会在内存中不经意地被修改。
-
简化字符串操作: 不可变性简化了字符串操作。例如,当你连接两个字符串时,实际上是创建了一个新的字符串,而不是修改原始字符串。
尽管不可变字符串有很多优势,但它们也有一些劣势,例如在频繁修改字符串内容时可能会导致性能下降,因为每次修改都会创建新的字符串对象。为了解决这个问题,Java 提供了 StringBuilder 和 StringBuffer 等可变字符串类,以便更高效地进行字符串拼接和修改。然而,在大多数情况下,不可变字符串的优点远远超过了其劣势,因此它们在 Java中得到广泛应用。
- 问题 22. 什么是 Java 中的字符串池?
解答:Java 中的字符串池(String Pool)是 Java 堆内存中的一个特殊区域,用于存储所有由字面量创建的字符串对象。
当我们创建一个字符串字面量(例如,String str = "Hello";),JVM 首先会检查字符串池中是否已经存在 “Hello” 这个字符串。如果存在,那么 str 就会指向这个已存在的 “Hello” 字符串;如果不存在,JVM 就会在字符串池中创建一个新的 “Hello” 字符串,然后 str 会指向这个新创建的字符串。
通过这种方式,字符串池可以帮助我们节省内存,因为它允许相同的字符串字面量共享同一个存储空间。
- 问题 23. 简述
String str = "aaa"与String str = new String("i")一样吗 ?
解答:String str = "aaa"; 和 String str = new String("aaa"); 在 Java 中并不完全相同。
-
String str = "aaa";:这种方式创建的字符串会被放入字符串池中。如果字符串池中已经存在 “aaa” 这个字符串,那么str就会指向这个已存在的字符串;如果不存在,JVM 就会在字符串池中创建一个新的 “aaa” 字符串,然后str会指向这个新创建的字符串。 -
String str = new String("aaa");:这种方式会在堆内存中创建一个新的字符串对象,然后str会指向这个新创建的对象。这时,无论字符串池中是否存在 “aaa” 这个字符串,都不会影响str的创建。
所以,虽然这两种方式创建的字符串内容相同,但是他们在内存中的存储位置可能不同。如果你使用 == 操作符比较这两个字符串,可能会得到 false,因为 == 操作符比较的是对象的引用,而不是内容。如果你使用 equals() 方法比较这两个字符串,会得到 true,因为 equals() 方法比较的是字符串的内容
- 问题 24. Java 中有哪些创建字符串的方式?
解答:在 Java 中,主要有以下几种创建字符串的方式:
-
字符串字面量:这是最常见的创建字符串的方式,例如
String str = "Hello";。这种方式创建的字符串会被放入字符串池中。 -
使用
new关键字:例如String str = new String("Hello");。这种方式会在堆内存中创建一个新的字符串对象。 -
通过字符数组:例如
char[] array = {'H', 'e', 'l', 'l', 'o'}; String str = new String(array);。这种方式会创建一个新的字符串,内容是字符数组的内容。 -
通过
StringBuilder或StringBuffer:例如StringBuilder sb = new StringBuilder("Hello"); String str = sb.toString();。这种方式可以创建一个可变的字符串,然后再转换为不可变的String。 -
通过
String.format()方法:例如String str = String.format("Hello %s", "World");。这种方式可以创建一个格式化的字符串。
以上就是在 Java 中创建字符串的主要方式。
- 问题 25. 介绍一下 String、StringBuffer、StringBuilder 和他们之间的区别?
解答:
-
String:在 Java 中,String是不可变的,也就是说一旦一个String对象被创建,我们就不能改变它的内容。每次对String类型进行修改,都会生成一个新的String对象。这在需要大量修改字符串时,会导致内存的大量占用和效率的降低。 -
StringBuffer:StringBuffer是线程安全的可变字符序列。每个方法都是同步的,可以被多个线程安全地调用。但是,这种线程安全带来的缺点是效率相对较低。 -
StringBuilder:StringBuilder是一个可变字符序列,它提供了append、insert、delete、reverse、setCharAt等方法来修改字符串。与StringBuffer相比,StringBuilder不是线程安全的,因此在单线程环境下,StringBuilder的效率更高。
总结一下,他们之间的区别主要在于:
String是不可变的,而StringBuffer和StringBuilder是可变的。StringBuffer是线程安全的,而StringBuilder是非线程安全的。- 在单线程环境下,如果需要对字符串进行大量修改,应优先考虑使用
StringBuilder。在多线程环境下,应使用StringBuffer来确保线程安全。如果字符串不需要修改,那么使用String是最好的选择。
相关文章:
)
Java基础面试题知识点总结(上篇)
大家好,我是栗筝i,从 2022 年 10 月份开始,我持续梳理出了全面的 Java 技术栈内容,一方面是对自己学习内容进行整合梳理,另一方面是希望对大家有所帮助,使我们一同进步。得到了很多读者的正面反馈。 而在 2…...
STM32进行LVGL裸机移植
本文的移植参考的是正点原子的课程《手把手教你学LVGL图形界面编程》 基于该课程和《LVGL开发指南_V1.3》“第二章 LVGL 无操作系统移植”,然后结合自身的实际情况进行整理。 先根据自己的习惯,创建基础的单片机工程,然后在APP业务层和DRIVE…...

python解析robot framework的output.xml并生成html
一、用pyh模块解析stat结点数据(output.py) #codingutf-8import xml.dom.minidom import xml.etree.ElementTree#打开xml文档 dom xml.dom.minidom.parse(./ui/output.xml);root2 xml.etree.ElementTree.parse(./ui/output.xml) #得到文档元素对象 ro…...

【RuoYi移动端】uni-app中的单击和双击事件
1、单击事件: click"enterpriseSelect" 2、双击事件: touchend"userinfo"...

使用 conda 在 Ubuntu 16.04 上安装 Python 3.9 的步骤:和 VSCode配置
一、使用conda在 Ubuntu 16.04 上安装 Python 3.9 的步骤: 当然可以,conda 是一个非常强大的包管理器,它可以方便地管理不同版本的 Python 和各种库包。以下是使用 conda 在 Ubuntu 16.04 上安装 Python 3.9 的步骤: 1. 安装 Miniconda Miniconda 是 Anaconda 的轻量级版…...
spring6-国际化:i18n | 数据校验:Validation
文章目录 1、国际化:i18n1.1、i18n概述1.2、Java国际化1.3、Spring6国际化1.3.1、MessageSource接口1.3.2、使用Spring6国际化 2、数据校验:Validation2.1、Spring Validation概述2.2、实验一:通过Validator接口实现2.3、实验二:B…...
【MicroSoft Edge】格式化的显示JSON格式的数据
当我们没有进行任何操作的时候,默认浏览器给我们展示的JSON的数据是这样的: 看着十分不便。 解决方案: 首先点击 MicroSoft Edge 浏览器右上角的三点,如何选择扩展 点击 获取Microsoft Edge 扩展 搜索 JSONView,第一…...

【c++】跟webrtc学std array 2:TaskExecutorMap单例用法
D:\XTRANS\m98_rtc\ndrtc-webrtc\src\base\task\task_executor.ccstd array实现的map:TaskExecutorMap // Maps TaskTraits extension IDs to registered TaskExecutors. Index |n| // corresponds to id |n - 1|. using TaskExecutorMap =std::array<TaskExecutor*, Task…...

力扣每日一题59:螺旋矩阵||
题目描述: 给你一个正整数 n ,生成一个包含 1 到 n2 所有元素,且元素按顺时针顺序螺旋排列的 n x n 正方形矩阵 matrix 。 示例 1: 输入:n 3 输出:[[1,2,3],[8,9,4],[7,6,5]]示例 2: 输入&am…...
codeforces (C++ In Love )
题目: 翻译: 思路: 1、在一个集合中有多组线段,如果有不相交的两组线段,则输出YES,否则输出NO。 2、每次操纵可以选择增加一组线段或者删除一组线段后,输出YES或者NO。 3、用flag标记该线段是否…...

【python】py文件全自动打包成spec文件
说明: 自动获取当前根目录下所有py文件生成spec文件,直接运行pyinstaller进行打包即可。直接打包成单执行文件。 直接上代码 import ospathex []def recursion(path, main):if path[:1] ! /:path /listpath os.listdir(path)for item in listpath:if…...
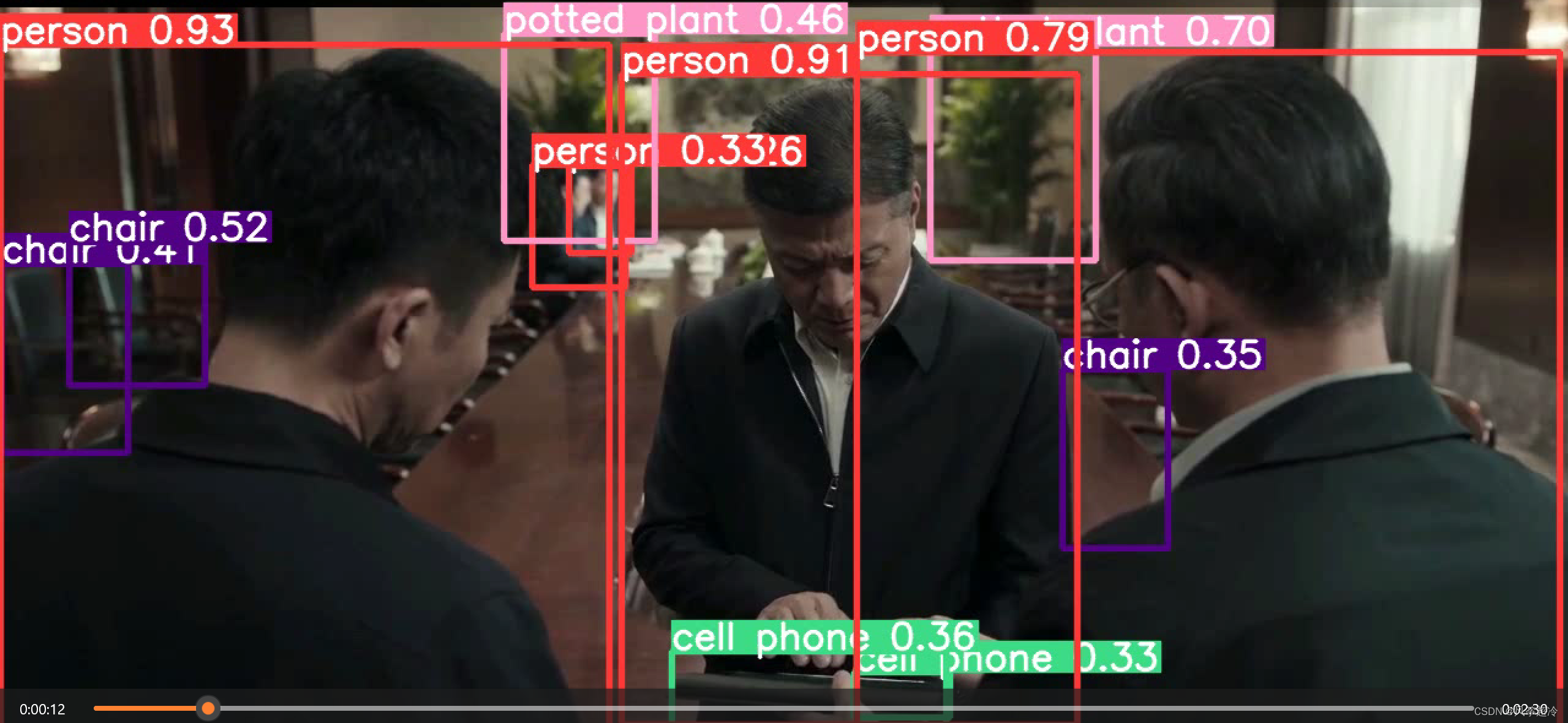
YOLOv5-调用官方权重进行检验(目标检测)
🍨 本文为[🔗365天深度学习训练营学习记录博客 🍦 参考文章:365天深度学习训练营-第7周:咖啡豆识别(训练营内部成员可读) 🍖 原作者:[K同学啊 | 接辅导、项目定制](https…...

springMVC中统一异常处理@ControllerAdvice
1.在DispatcherServlet中初始化HandlerExceptionResolver 2.controller执行完成后执行processDispatchResult(processedRequest,response,mappedHandler,mv,dispatchException),有异常则处理异常 3.ExcepitonHandlerExceptionResolver中执行方法doResolveHandlerMethodExceptio…...

【Java】<泛型>,在编译阶段约束操作的数据结构,并进行检查。
个人简介:Java领域新星创作者;阿里云技术博主、星级博主、专家博主;正在Java学习的路上摸爬滚打,记录学习的过程~ 个人主页:.29.的博客 学习社区:进去逛一逛~ JAVA泛型 泛型介绍: ①泛型&#…...

解决谷歌学术bib信息不全的问题
在我们撰写学术论文时,经常需要引用参考文献。如果用latex撰写论文,势必会用到文献的bib信息,大部分的教程都会告诉我们去google scholar上去搜索。 一、问题描述 搜索一篇文章,然后选择cite,再选择bib。 很明显&…...

初始Redis 分布式结构的发展演变
目录 Redis的特点和使用场景 分布式系统的引入 单机系统 分布式系统 应用服务器的增多(处理更多的请求) 数据库读写分离(数据服务器的增多) 引入缓存 应对更大的数据量 业务拆分:微服务 Redis的特点和使用场景 我们先来…...

关于动态内存管理中的常见练习题
文章目录 前言练习1:练习2:练习3:练习4: 前言 学习完C语言中的动态内存管理,大家开始利用动态内存管理来去开辟空间,经过一顿狂敲代码后,发现了问题,程序要么崩掉,要么运…...

冒泡排序、插入排序、选择排序和快速排序的原理
下面是对冒泡排序、插入排序、选择排序和快速排序的原理的简要解释: 冒泡排序(Bubble Sort):冒泡排序是一种简单的排序算法。它通过多次迭代比较相邻的元素,并交换它们的位置,使得较大(或较小&…...

VB.NET之SqlCommand详解
目录 一.前言 二.SqlCommand的背景方法 1.构造函数 2.属性 3.方法 三.SqlCommand的使用实例 1.创建SqlCommand对象 2.执行SQL查询语句 3.执行存储过程 四.总结 一.前言 VB.NET的SqlCommand是ADO.NET的一部分,主要用于执行SQL语句并返回受影响的行数、查询…...

.NET主流的ORM框架 2023年
1. Entity Framework Entity Framework是Microsoft开发的一款强大的ORM框架。适用于.NET开发,支持多种数据库,并提供了广泛的文档和教程。Entity Framework基于面向对象的数据模型,使用LINQ进行查询。它的强大功能和易用性使得它成为.NET开发…...

终极游戏资源编辑指南:如何用ExtractorSharp轻松制作DNF补丁
终极游戏资源编辑指南:如何用ExtractorSharp轻松制作DNF补丁 【免费下载链接】ExtractorSharp Game Resources Editor 项目地址: https://gitcode.com/gh_mirrors/ex/ExtractorSharp 你是否曾经想要自定义游戏中的角色外观、武器特效或界面元素?E…...

Qwen3-14B Python科学计算环境搭建:Anaconda集成部署指南
Qwen3-14B Python科学计算环境搭建:Anaconda集成部署指南 1. 为什么选择Anaconda部署Qwen3-14B 在数据科学和机器学习领域,Anaconda已经成为事实上的标准环境管理工具。对于Qwen3-14B这样的开源大模型,使用Anaconda可以带来几个明显优势&am…...

OnmyojiAutoScript:阴阳师全自动托管脚本,每天为你节省2小时游戏时间!
OnmyojiAutoScript:阴阳师全自动托管脚本,每天为你节省2小时游戏时间! 【免费下载链接】OnmyojiAutoScript Onmyoji Auto Script | 阴阳师脚本 项目地址: https://gitcode.com/gh_mirrors/on/OnmyojiAutoScript 还在为阴阳师繁重的日常…...

给虚拟主播做动作选什么工具?2026年4款主流工具实测对比
虚拟主播产业的快速发展,推动动作创作工具向高效化、轻量化、专业化升级。随着虚拟主播行业的规范化发展,动作创作的效率与质量成为核心竞争力,传统手动绑定、专业设备驱动的模式已无法满足批量产出需求。本文基于实测数据,结合虚…...

Windows11轻松设置:极简设计理念,小白也能轻松驾驭
在软件设计领域,真正的功力往往体现在如何让复杂的功能变得简单易用。 Windows11轻松设置软件正是这样一款产品,它将复杂的系统配置操作简化为直观的点击。 无论是初次接触的电脑小白还是经验丰富的专业用户,都能快速上手并从中受益。 软件…...

Qwen3-0.6B-FP8惊艳效果:复杂数学题分步推导+答案验证全过程
Qwen3-0.6B-FP8惊艳效果:复杂数学题分步推导答案验证全过程 你见过一个只有6亿参数的小模型,能像学霸一样,把一道复杂的数学题一步步拆解、推导,最后还自己验算一遍吗?今天,我们就来亲眼看看Qwen3-0.6B-FP…...

【Pwn | CTF】BUUCTF nc工具实战入门:从零到flag
1. 初识nc工具:你的CTF网络瑞士军刀 第一次接触CTF比赛时,看到题目要求用nc连接服务器,我盯着黑乎乎的终端窗口发呆了十分钟。后来才发现,原来这个看似简单的工具,竟是Pwn题目的敲门砖。nc(netcatÿ…...

5分钟搞定OneNote到Markdown迁移:免费工具让你的笔记重获自由
5分钟搞定OneNote到Markdown迁移:免费工具让你的笔记重获自由 【免费下载链接】onenote-md-exporter ConsoleApp to export OneNote notebooks to Markdown formats 项目地址: https://gitcode.com/gh_mirrors/on/onenote-md-exporter 还在为OneNote笔记被锁…...
Translumo:打破语言障碍的终极屏幕实时翻译工具完整指南
Translumo:打破语言障碍的终极屏幕实时翻译工具完整指南 【免费下载链接】Translumo Advanced real-time screen translator for games, hardcoded subtitles in videos, static text and etc. 项目地址: https://gitcode.com/gh_mirrors/tr/Translumo 你是否…...

SiameseAOE模型在微信小程序评论分析中的应用实战
SiameseAOE模型在微信小程序评论分析中的应用实战 最近和几个做小程序的朋友聊天,他们都在头疼同一个问题:用户评论越来越多,根本看不过来。好评差评混在一起,想提炼点有价值的信息,比如用户到底喜欢商品的哪个点&…...