CUDA学习笔记(十四) Constant Memory
转载至https://www.cnblogs.com/1024incn/tag/CUDA/
CONSTANT MEMORY
constant Memory对于device来说只读但是对于host是可读可写。constant Memory和global Memory一样都位于DRAM,并且有一个独立的on-chip cache,比直接从constant Memory读取要快得多。每个SM上constant Memory cache大小限制为64KB。
constant Memory的获取方式不同于其它的GPU内存,对于constant Memory来说,最佳获取方式是warp中的32个thread获取constant Memory中的同一个地址。如果获取的地址不同的话,只能串行的服务这些获取请求了。
constant Memory使用__constant__限定符修饰变量。
constantMemory的生命周期伴随整个应用程序,并且可以被同一个grid中的thread和host中调用的API获取。因为constant Memory对device来说是可读的,所以只能在host初始化,使用下面的API:
cudaError_t cudaMemcpyToSymbol(const void *symbol, const void * src, size_t count, size_t offset, cudaMemcpyKind kind)
Implementing a 1D Stencil with Constant Memory
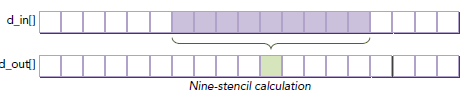
实现一个1维Stencil(数值分析领域的东,卷积神经网络处理图像的时候那个stencil),简单说就是计算一个多项式,系数放到constant Memory中,即y=f(x)这种东西,输入是九个点,如下:
{x − 4h, x − 3h, x − 2h, x − h, x, x + h, x + 2h, x + 3h, x + 4h}
在内存中的过程如下:
公式如下:
![]()
那么要放到constant Memory中的便是其中的c0、c1、c2 ……
因为每个thread使用九个点来计算一个点,所以可以使用shared memory来降低延迟。
__shared__ float smem[BDIM + 2 * RADIUS];
RADIUS定义了x两边点的个数,对于本例,RADIUS就是4。如下图所示,每个block需要RADIUS=4个halo(晕)左右边界:

#pragma unroll用来告诉编译器,自动展开循环。
![]()
View Code
Comparing with the Read-only Cache
Kepler系列的GPU允许使用texture pipeline作为一个global Memory只读缓存。因为这是一个独立的使用单独带宽的只读缓存,所以对带宽限制的kernel性能有很大的提升。
Kepler的每个SM有48KB大小的只读缓存,一般来说,在读地址比较分散的情况下,这个只读缓存比L1表现要好,但是在读同一个地址的时候,一般不适用这个只读缓存,只读缓存的读取粒度为32比特。
有两种方式来使用只读缓存:
- 使用__ldg限定
- 指定特定global Memory称为只读缓存
下面代码片段对于第一种情况:
__global__ void kernel(float* output, float* input) {...output[idx] += __ldg(&input[idx]);...
}
下面代码对应第二种情况,使用__restrict__来指定该数据的要从只读缓存中获取:
void kernel(float* output, const float* __restrict__ input) {...output[idx] += input[idx];
}
一般使用__ldg是更好的选择。通过constant缓存存储的数据必须相对较小而且必须获取同一个地址以便获取最佳性能,相反,只读缓存则可以存放较大的数据,且不必地址一致。
下面的代码是之前stencil的翻版,使用过了只读缓存来存储系数,二者唯一的不同就是函数的声明:
![]()
View Code
由于系数原本是存放在global Memory中的,然后读进缓存,所以在调用kernel之前,我们必须分配和初始化global Memory来存储系数,代码如下:
const float h_coef[] = {a0, a1, a2, a3, a4};
cudaMalloc((float**)&d_coef, (RADIUS + 1) * sizeof(float));
cudaMemcpy(d_coef, h_coef, (RADIUS + 1) * sizeof(float), cudaMemcpyHostToDevice);
下面是运行在TeslaK40上的结果,从中可知,使用只读缓存性能较差。
Tesla K40c array size: 16777216 (grid, block) 524288,32 3.4517ms stencil_1d(float*, float*) 3.6816ms stencil_1d_read_only(float*, float*, float const *)
总的来说,constant缓存和只读缓存对于device来说,都是只读的。二者都有大小限制,前者每个SM只能有64KB,后者则是48KB。对于读同一个地址,constant缓存表现好,只读缓存则对地址较分散的情况表现好。
The Warp Shuffle Instruction
之前我们有介绍shared Memory对于提高性能的好处,在CC3.0以上,支持了shuffle指令,允许thread直接读其他thread的寄存器值,只要两个thread在 同一个warp中,这种比通过shared Memory进行thread间的通讯效果更好,latency更低,同时也不消耗额外的内存资源来执行数据交换。
这里介绍warp中的一个概念lane,一个lane就是一个warp中的一个thread,每个lane在同一个warp中由lane索引唯一确定,因此其范围为[0,31]。在一个一维的block中,可以通过下面两个公式计算索引:
laneID = threadIdx.x % 32
warpID = threadIdx.x / 32
例如,在同一个block中的thread1和33拥有相同的lane索引1。
Variants of the Warp Shuffle Instruction
有两种设置shuffle的指令:一种针对整型变量,另一种针对浮点型变量。每种设置都包含四种shuffle指令变量。为了交换整型变量,使用过如下函数:
int __shfl(int var, int srcLane, int width=warpSize);
该函数的作用是将var的值返回给同一个warp中lane索引为srcLane的thread。可选参数width可以设置为2的n次幂,n属于[1,5]。
eg:如果shuffle指令如下:
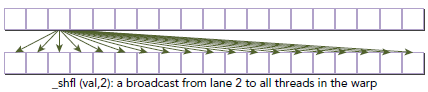
int y = shfl(x, 3, 16);
则,thread0到thread15会获取thread3的数据x,thread16到thread31会从thread19获取数据x。
当传送到shfl的lane索引相同时,该指令会执行一次广播操作,如下所示:
另一种使用shuffle的形式如下:
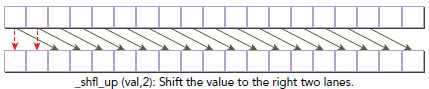
int __shfl_up(int var, unsigned int delta, int width=warpSize)
该函数通过使用调用方的thread的lane索引减去delta来计算源thread的lane索引。这样源thread的相应数据就会返回给调用方,这样,warp中最开始delta个的thread不会改变,如下所示:
第三种shuffle指令形式如下:
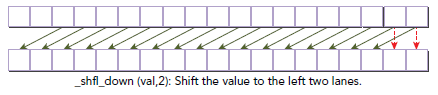
int __shfl_down(int var, unsigned int delta, int width=warpSize)
该格式是相对__shfl_down来说的,具体形式如下图所示:
最后一种shuffle指令格式如下:
int __shfl_xor(int var, int laneMask, int width=warpSize)
这次不是加减操作,而是同laneMask做抑或操作,具体形式如下图所示:
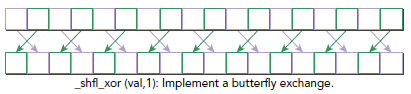
所有这些提及的shuffle函数也都支持单精度浮点值,只需要将int换成float就行,除此外,和整型的使用方法完全一样。
相关文章:
CUDA学习笔记(十四) Constant Memory
转载至https://www.cnblogs.com/1024incn/tag/CUDA/ CONSTANT MEMORY constant Memory对于device来说只读但是对于host是可读可写。constant Memory和global Memory一样都位于DRAM,并且有一个独立的on-chip cache,比直接从constant Memory读取要快得多…...
使用MFC创建一个SaleSystem
目录 1、项目的创建: 2、项目的配置: 3、设置窗口属性: (1)、设置图标 1)、添加导入资源 2)、代码初始化图标 (2)、设置标题 (3)、设置窗口…...
grafana v10.1版本设置告警
1. 相关概念概述 如图所示,点击切换菜单标志,可以看到警报相关子选项。 警报规则:通过PromQL语句定义告警规则,即达到怎样的状态触发告警。 联络点: 设置当警报规则实例触发时,如何通知联系人,…...

Python+Requests+PyTest+Excel+Allure 接口自动化测试实战
本文主要介绍了PythonRequestsPyTestExcelAllure 接口自动化测试实战,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧 Unittest是Python标准库中自带的单元测试框架…...
日志分析系统——ELK
目录 一、ELK概述 ELK的组成 1、ElasticSearch 2、Logstash 3、Kiabana 完整日志采集系统基本特征 ELK的工作原理 二、ELK的部署 1、环境准备 2、部署ElasticSearch软件 3、安装Elasticsearch-head插件 4、Logstash部署 5、Kibana部署 三、FilebeatELK部署 1、安…...
Ubuntu小知识总结
Ubuntu相关的小知识总结 一、Ubuntu系统下修改用户开机密码二、Vmware虚拟机和主机之间复制、粘贴内容、拖拽文件的详细方法问题描述Vmware tools灰色不能安装解决方法小知识点:MarkDown的空格 三、Ubuntu虚拟机网络无法连接的几种解决方法1.重启网络编辑器2. 重启虚…...

2023年全球市场新能源汽车车载充电器总体规模、主要生产商、主要地区、产品和应用细分研究报告
按收入计,2022年全球新能源汽车车载充电器收入大约 百万美元,预计2029年达到 百万美元,2023至2029期间,年复合增长率CAGR为 %。同时2022年全球新能源汽车车载充电器销量大约 ,预计2029年将达到 。2022年中国市场规模大…...

基于stm32控制的ESP8266在设备模式下通讯
一、文章中要用的指令 指令作用ATUART115200,8,1,0,0之前的51通讯是9600,这里的321用的是115200,需要改一下波特率ATCWMODEXX是1代表station(设备)模式 ,X是2代表AP(路由)模式 ,X是…...

用PHP组合数组,生成笛卡尔积。写几个例子
#创作灵感# [红色,白色,黄色,蓝色] [128G,256G,512G] [国行,港版,美版,韩版] 用PHP组合数组,生成笛卡尔积。写几个例子 你可以使用嵌套的循环来生成这些数组的笛卡尔积。以下是一些示例代码: // 示例…...

软设上午题错题知识点7
软设上午题错题知识点7 1、数据流图摆脱系统的物理内容,在逻辑上描述系统的功能、输入、输出和数据存储等,是系统逻辑模型的重要组成部分。 2、HTTPS(Secure Hypertext Transfer Protocol)安全超文本传输协议。 它是一个安全通信…...
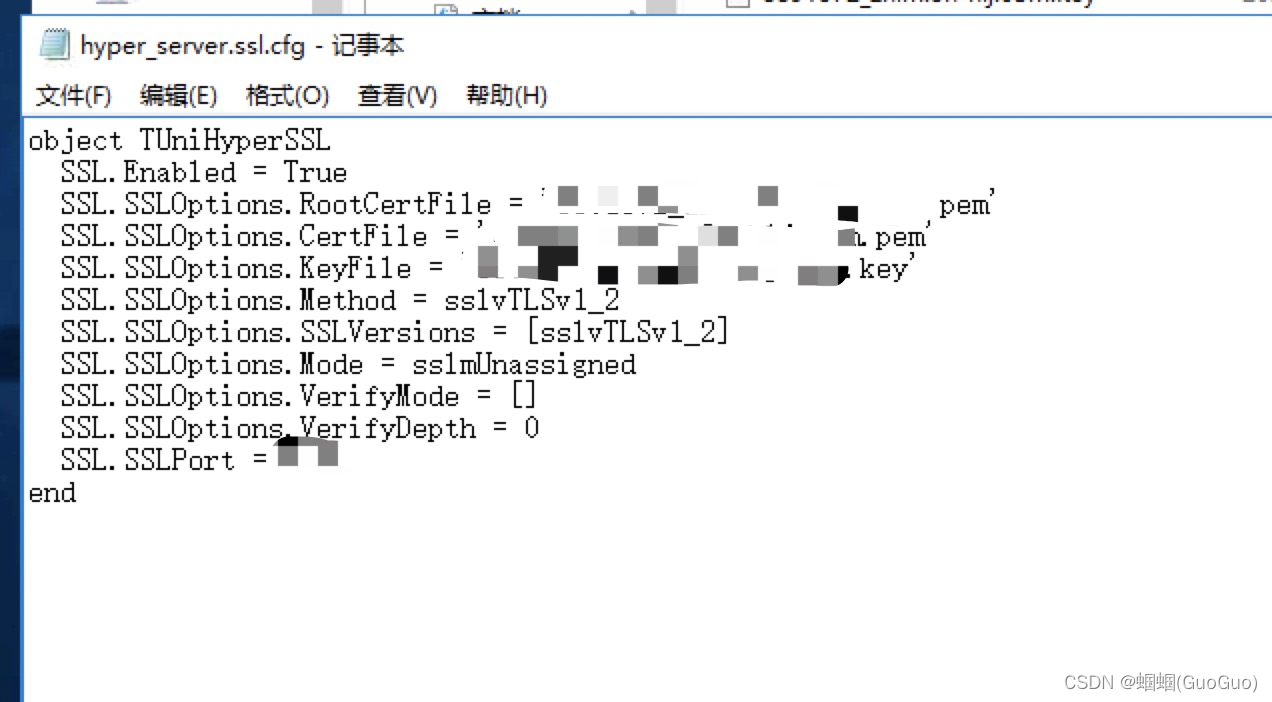
让uniGUI支持https
今天在专家的帮助下,成功的让uniGUI支持https了。 首先,去申请个**的证书。我同事去阿里申请的,申请回是一个zip文件,里面有两个文件,一个扩展是per,一个key 然后,把这两个证书文件放到uniGUI…...
iPhone怎么导出微信聊天记录?3个值得收藏的方法
随着时间的推移,微信占用的内存空间会“膨胀”得越来越大。当手机内存不足时,清理微信中的聊天记录是一个可行的方法。但是很多小伙伴觉得有些重要的聊天记录还有用,可能以后需要进行查看。 因此,他们想将一些聊天记录进行导出或…...
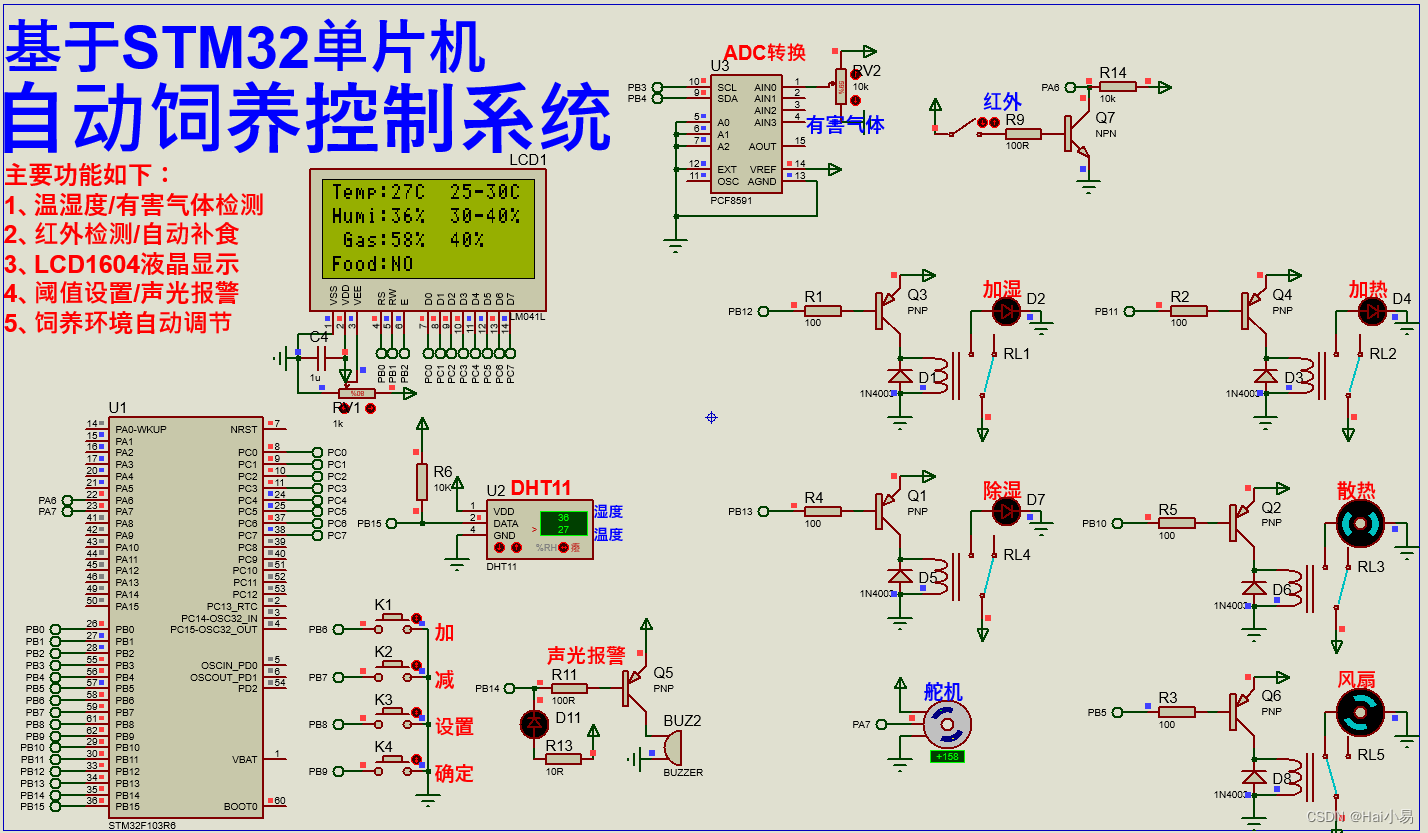
【Proteus仿真】【STM32单片机】自动饲养控制系统
文章目录 一、功能简介二、软件设计三、实验现象联系作者 一、功能简介 本项目使用Proteus8仿真STM32单片机控制器,使用LCD1604显示模块、红外传感器、有害气体检测模块、PCF8591 ADC模块,蜂鸣器、DHT11温湿度、SG90舵机、风扇加热加湿等。 主要功能&a…...

【设计模式】模板方法模式
模板方法模式 1. 什么是模板方法 模板方法模式:定义一个操作中的算法骨架(父类),而将一些步骤延迟到子类中。 模板方法使得子类可以不改变一个算法的结构来重定义该算法的 2. 什么时候使用模板方法 实现一些操作时,…...

c语言进制的转换二进制转换10进制
c语言进制的转换之二进制转换10进制 c语言的进制的转换 c语言进制的转换之二进制转换10进制一、二进制转换10进制的方法二、10进制程序打印 一、二进制转换10进制的方法 二进制: 二进制逢二进一,所有的数组是0、1组成 十进制转二进制: 除二反…...

C++ 纠错题总结2
1、for循环中的判断语句: 要注意初始赋值、< 还是 < for(int i 0; i < n; i) 2、cin.getline(char[], int, char) 注意:第二个参数为不是char[]的有效元素个数,因为最后一个元素位置要用来存储 \0 3、函数形参有默认值的,有默认…...

Jmeter性能 —— 事务控制器
统计性能测试结果一定会关注TPS,TPS表示:每秒处理事务数,JMeter默认每个事务对应一个请求。我们可以用逻辑控制器中的事务控制器将多个请求统计为一个事务。 1、添加事务控制器 2、事务控制器参数说明 Generate parent sample:如…...

Android C/C++ native编程NDK开发中logcat的使用
Android C/C native编程NDK开发中logcat的使用 前言具体用法 前言 在NDK开发过程中,C/C层,需要对代码进行一些调试,日志打印是我们解决异常或崩溃的重要手段,这里我就简单介绍下日志打印三步走。 首先我们先看下官方文档关于日志…...

什么是美颜SDK?深入了解直播实时美颜SDK
美颜已经成为了现代社交媒体和直播应用中的重要元素,它使用户能够在拍摄自拍照片或进行直播时改善其外貌特征。美颜技术的普及离不开美颜SDK(软件开发工具包),特别是在直播应用中,直播实时美颜SDK正变得越来越流行。在…...

TensorFlow2从磁盘读取图片数据集的示例(tf.data.Dataset.list_files)
import os import warnings warnings.filterwarnings("ignore") import tensorflow as tf from tensorflow.keras.optimizers import Adam from tensorflow.keras.applications.resnet import ResNet50 from pathlib import Path import numpy as np#数据所在文件夹 …...

AI编程时代,人类程序员还剩下什么?堂
故障表现 发现请求集群 demo 入口时卡住,并且对应 Pod 没有新的日志输出 rootce-demo-1:~# kubectl get pods -n deepflow-otel-spring-demo -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NO…...

终极指南:如何使用UI-Router实现AngularJS路由安全与角色访问控制
终极指南:如何使用UI-Router实现AngularJS路由安全与角色访问控制 【免费下载链接】ui-router The de-facto solution to flexible routing with nested views in AngularJS 项目地址: https://gitcode.com/gh_mirrors/ui/ui-router 在现代Web应用开发中&…...
配置与任务调度:那个让我加班到凌晨三点的调度死锁)
# 016、AutoSAR CP操作系统(OS)配置与任务调度:那个让我加班到凌晨三点的调度死锁
上周在联调ECU唤醒流程时,遇到一个诡异现象:系统唤醒后运行几分钟就卡死,仿真器显示所有任务都停在WaitEvent状态。抓了三天Trace才发现,是OS任务优先级配反了——高优先级任务等低优先级任务释放资源,低优先级任务又被中等优先级任务抢占,经典的优先级反转没处理好。今天…...

HL1606 LED灯带PWM驱动库:9/12/15位可配置灰度实现
1. HL1606 LED Strip PWM 库深度技术解析HL1606 是一款经典的串行级联LED驱动芯片,广泛应用于早期RGB LED灯带(如Adafruit早期的“NeoPixel前身”方案)。与WS2812B等单线协议芯片不同,HL1606采用标准SPI接口配合独立锁存信号&…...

保险丝选型
注意:1、保险丝有AC保险丝和DC保险丝,按保险丝工作在交流还是直流选择。 介绍:保险丝是电路过流、短路保护的核心安全元件,核心原理是电流超过额定值时,熔体发热熔断切断电路,防止故障扩大。按熔断速度分为 5 类,分别见下表。在选型 类型 型号后缀 核心特性 典型熔断参…...

【向量检索实战】FAISS + BGE-M3:构建高效RAG系统的核心引擎
1. 为什么需要FAISSBGE-M3组合? 在构建RAG系统时,最头疼的问题就是如何快速从海量文档中找到最相关的信息。想象一下,你正在整理一个超大的衣柜,里面有成千上万件衣服。当你想找"适合夏天穿的蓝色衬衫"时,如…...

从建模到优化:CST Studio Suite中波导弯头高效仿真全流程解析
1. 波导弯头仿真基础与CST环境准备 波导弯头是微波系统中不可或缺的组件,用于改变电磁波传输方向。在4-5GHz频段,传统设计方法依赖经验公式和手工计算,不仅耗时且难以评估实际性能。CST Studio Suite作为专业电磁仿真工具,能直观呈…...
俚)
哥本哈士奇(aspnetx)俚
简介 langchain中提供的chain链组件,能够帮助我门快速的实现各个组件的流水线式的调用,和模型的问答 Chain链的组成 根据查阅的资料,langchain的chain链结构如下: $$Input \rightarrow Prompt \rightarrow Model \rightarrow Outp…...

XXMI启动器技术架构解析与跨平台插件管理系统
XXMI启动器技术架构解析与跨平台插件管理系统 【免费下载链接】XXMI-Launcher Modding platform for GI, HSR, WW and ZZZ 项目地址: https://gitcode.com/gh_mirrors/xx/XXMI-Launcher XXMI启动器是一款基于Python构建的跨平台插件管理系统,为现代应用提供统…...
)
中小企业必看:Gemma 4 企业级私有化部署全流程(避坑指南)
中小企业必看:Gemma 4 企业级私有化部署全流程(避坑指南) 前言 对中小企业来说,AI大模型不用追求“参数越高越好”,核心是“低成本、易部署、能商用、保隐私”——而谷歌最新开源的Gemma 4,刚好踩中所有痛…...