【PyTorch实战演练】自调整学习率实例应用(附代码)
目录
0. 前言
1. 自调整学习率的常用方法
1.1 ExponentialLR 指数衰减方法
1.2 CosineAnnealingLR 余弦退火方法
1.3 ChainedScheduler 链式方法
2. 实例说明
3. 结果说明
3.1 余弦退火法训练过程
3.2 指数衰减法训练过程
3.3 恒定学习率训练过程
3.4 结果解读
4. 完整代码
0. 前言
按照国际惯例,首先声明:本文只是我自己学习的理解,虽然参考了他人的宝贵见解及成果,但是内容可能存在不准确的地方。如果发现文中错误,希望批评指正,共同进步。
本文介绍深度学习训练中经常能使用到的实用技巧——自调整学习率,并基于PyTorch框架通过实例进行使用,最后对比同样条件下以自调整学习率和固定学习率在模型训练上的表现。
在深度学习模型训练过程中,经常会出现损失值不收敛的头疼情况,令人怀疑自己设计的网络模型存在不合理或者错误之处,但是导致这种情况的真正原因往往非常简单——就是学习率的设定不合理。
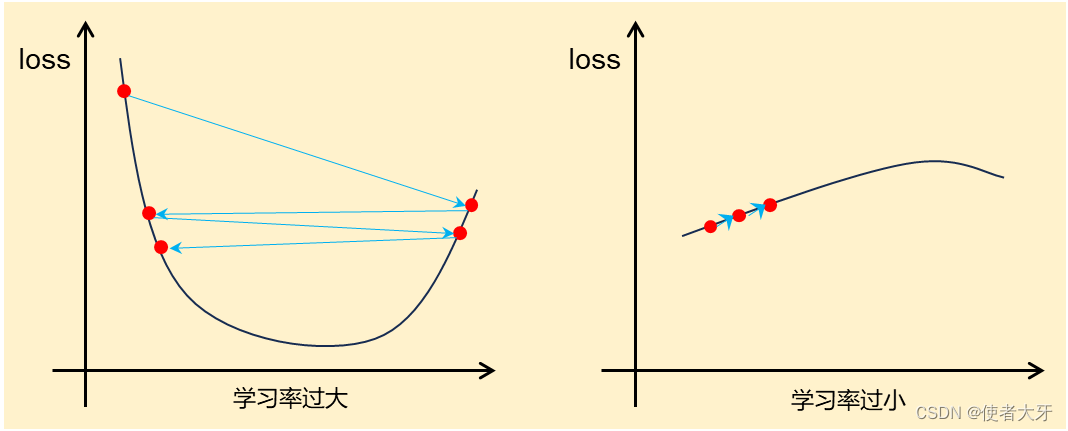
这就导致在深度学习模型训练的初期,可能需要“摸索”一个比较合适的学习率,在后期逐渐细化的过程可能还需要尝试其他的学习率,进行“分段训练”。学习率的这种“摸索”费时费力,因此自调整学习率的方法应运而生。
1. 自调整学习率的常用方法
自调整学习率是一种通用的方法,通过在训练期间动态地更新学习率以使模型更好地收敛,提高模型的精确度和稳定性。在PyTorch框架 torch.optim.lr_scheduler 中集成了大量的自调整学习率的方法:
lr_scheduler.LambdaLR
lr_scheduler.MultiplicativeLR
lr_scheduler.StepLR
lr_scheduler.MultiStepLR
lr_scheduler.ConstantLR
lr_scheduler.LinearLR
lr_scheduler.ExponentialLR
lr_scheduler.PolynomialLR
lr_scheduler.CosineAnnealingLR
lr_scheduler.ChainedScheduler
lr_scheduler.SequentialLR
lr_scheduler.ReduceLROnPlateau
lr_scheduler.CyclicLR
lr_scheduler.OneCycleLR
lr_scheduler.CosineAnnealingWarmRestarts
这里具体方法虽然很多,但是每种自动调整学习率的策略都比较简单,本文仅介绍以下两种常见的方法,其余可以查看PyTorch官网说明。
1.1 ExponentialLR 指数衰减方法
这种方法的学习率为:
这里有两个参数:
:初始学习率
:衰减指数,取值范围(0,1),一般来说取值要非常接近1(>0.95,甚至要>0.99),否则在动辄几百几千的迭代次数epoch条件下学习率很快会衰减到0
PyTorch调用代码为:
torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma, last_epoch)- optimizer:训练该模型的优化算法
- gamma:上面的衰减指数
- last_epoch:不用理会,默认-1即可
1.2 CosineAnnealingLR 余弦退火方法
首先我要吐槽下不知道是哪个大聪明给起的这个名字,我学过《机械加工原理与工艺》,但我不明白这个算法和退火有什么关系?名字非常唬人,方法并不复杂。
这个方法就是让学习率按余弦曲线进行震荡,其震荡范围为[0, lr_initial],震荡周期为T_max:
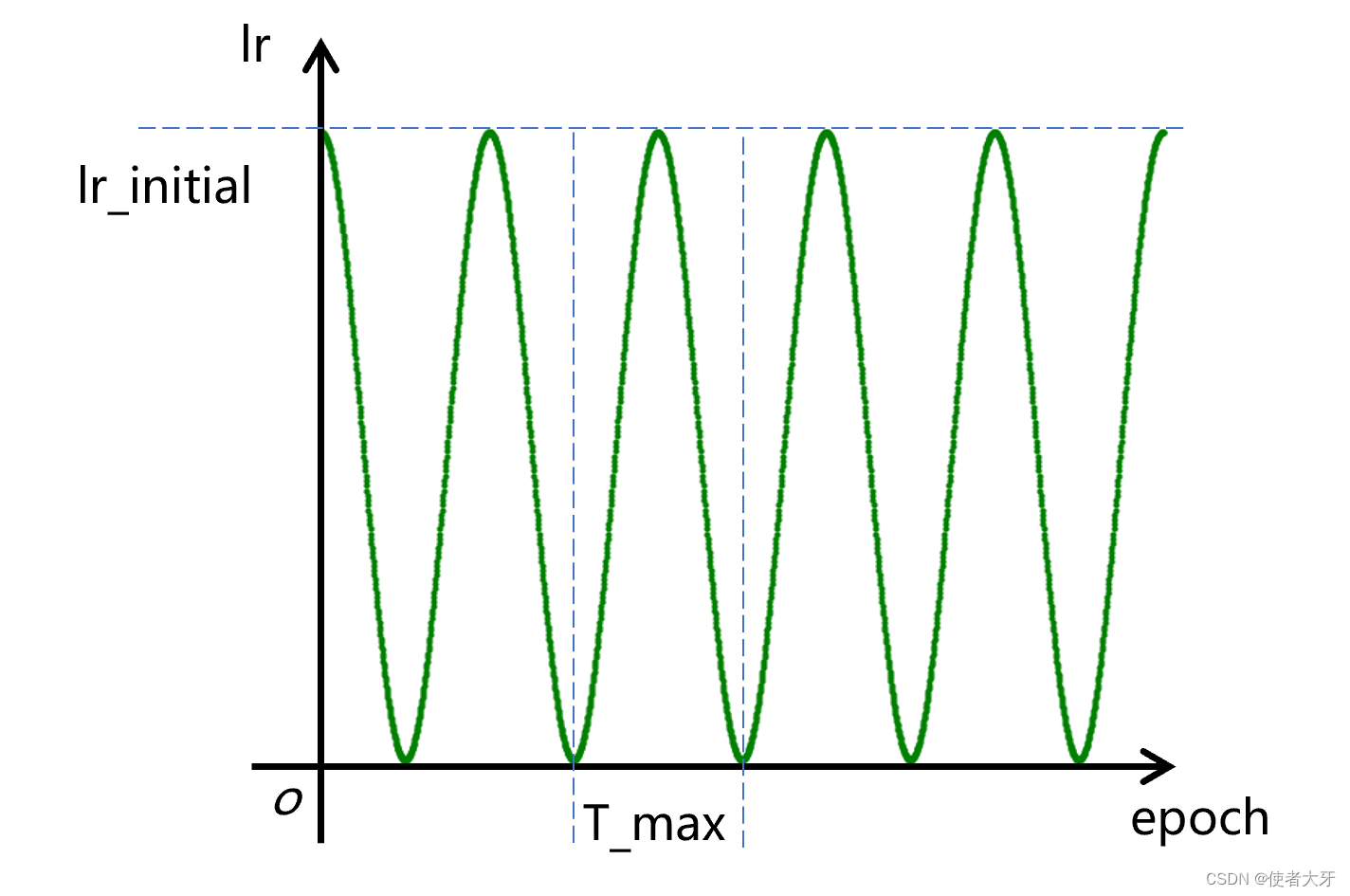
PyTorch调用代码为:
torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max, last_epoch)其参数同上说明不再赘述。
1.3 ChainedScheduler 链式方法
这个方法说白了就是多种自调节学习率方法进行组合使用,例如以下:
scheduler1 = ConstantLR(self.opt, factor=0.1, total_iters=2)
scheduler2 = ExponentialLR(self.opt, gamma=0.9)
scheduler = ChainedScheduler([scheduler1, scheduler2])最后再强调一下,无论使用哪种方法,在coding时别忘了每个epoch学习后加上 scheduler.step() ,这样才能更新学习率。
2. 实例说明
本文目的是验证自调节学习率的作用,选用一个简单的“平方网络”实例,即期望输出为输入值的平方。
训练输入数据x_train,输出数据y_train分别为:
x_train = torch.tensor([0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1],dtype=torch.float32).unsqueeze(-1)
y_train = torch.tensor([0.01,0.04,0.09,0.16,0.25,0.36,0.49,0.64,0.81,1],dtype=torch.float32).unsqueeze(-1)验证输入数据x_val为:
x_val = torch.tensor([0.15,0.25,0.35,0.45,0.55,0.65,0.75,0.85,0.95],dtype=torch.float32).unsqueeze(-1)网络模型使用5层全连接网络,对应这种简单问题足够用了:
class Linear(torch.nn.Module):def __init__(self):super().__init__()self.layers = torch.nn.Sequential(torch.nn.Linear(in_features=1, out_features=3),torch.nn.Sigmoid(),torch.nn.Linear(in_features=3,out_features=5),torch.nn.Sigmoid(),torch.nn.Linear(in_features=5, out_features=10),torch.nn.Sigmoid(),torch.nn.Linear(in_features=10,out_features=5),torch.nn.Sigmoid(),torch.nn.Linear(in_features=5, out_features=1),torch.nn.ReLU(),)优化器选用Adam,训练组及验证组的损失函数都选用MSE均方差。
3. 结果说明
对于本文对比的三种方法,其训练参数设定如下表:
| 学习率调整方法 | 训练参数设定 |
| 指数衰减 | 迭代次数epoch=2000,初始学习率initial_lr=0.0005,衰减指数gamma=0.99995 |
| 余弦退火 | 迭代次数epoch=2000,初始学习率initial_lr=0.001(因为学习率均值为初始值的一半,公平起见给余弦退火方法初始学习率*2),震荡周期T_max=200 |
| 恒定学习率 | 学习率lr=0.0005 |
各种方法的训练过程如下图:
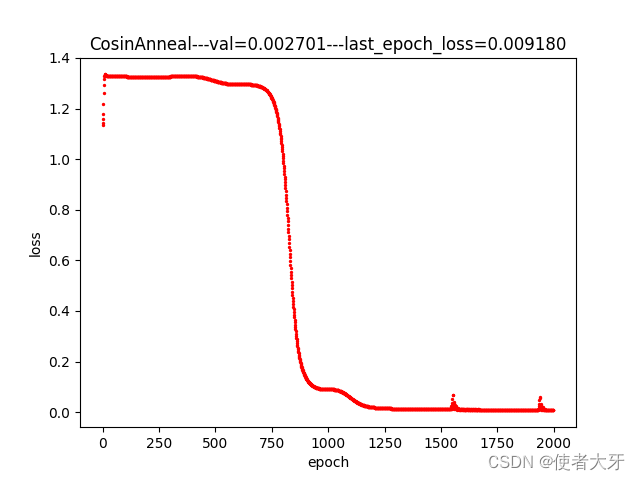
3.1 余弦退火法训练过程
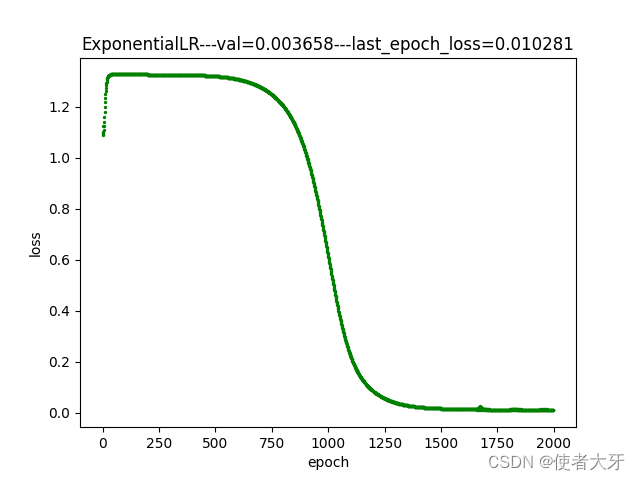
3.2 指数衰减法训练过程
3.3 恒定学习率训练过程
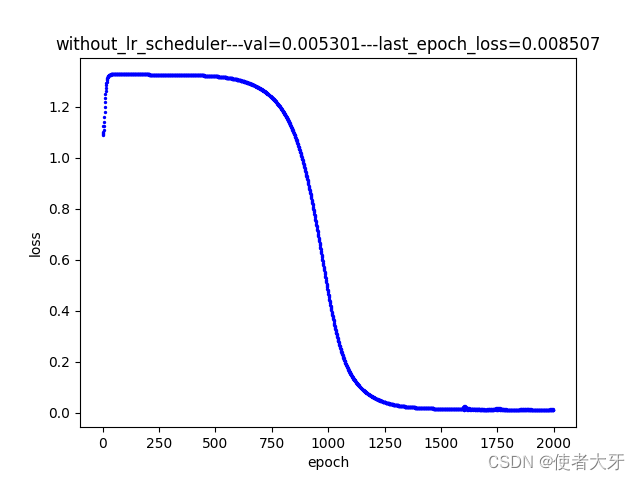
3.4 结果解读
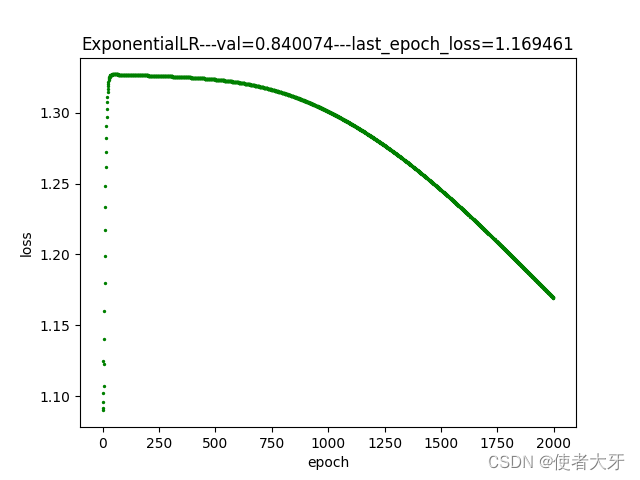
- 指数衰减方法的gamma真的要选择非常接近1才行!理由我上面也解释了,下面是gamma=0.999时的loss下降情况,可见其下降速度之慢;
- 本实例中,使用余弦退火方法训练的模型在验证组表现最好,验证组损失值val=0.0027,其次是指数衰减法(val=0.0037),最差是恒定学习率(val=0.0053),但这个结果仅限本实例中,并不是说哪种方法就比哪种方法好,在不同模型上可能要因地制宜选择合适的方法;
- 目前这些所谓的“自调节学习率”我认为仅能算是“半自动调节”,因为仍有超参数需要事前设定(例如衰减指数gamma)。而选择哪种方法最好,以及这种方法的参数如何设定呢?可能还是需要做一定的“摸索”,但是相比恒定学习率肯定会节省很多时间!
4. 完整代码
import torch
import matplotlib.pyplot as plt
from tqdm import tqdm
import argparsetorch.manual_seed(25)x_train = torch.tensor([0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1],dtype=torch.float32).unsqueeze(-1)
y_train = torch.tensor([0.01,0.04,0.09,0.16,0.25,0.36,0.49,0.64,0.81,1],dtype=torch.float32).unsqueeze(-1)
x_val = torch.tensor([0.15,0.25,0.35,0.45,0.55,0.65,0.75,0.85,0.95],dtype=torch.float32).unsqueeze(-1)class Linear(torch.nn.Module):def __init__(self):super().__init__()self.layers = torch.nn.Sequential(torch.nn.Linear(in_features=1, out_features=3),torch.nn.Sigmoid(),torch.nn.Linear(in_features=3,out_features=5),torch.nn.Sigmoid(),torch.nn.Linear(in_features=5, out_features=10),torch.nn.Sigmoid(),torch.nn.Linear(in_features=10,out_features=5),torch.nn.Sigmoid(),torch.nn.Linear(in_features=5, out_features=1),torch.nn.ReLU(),)def forward(self,x):return self.layers(x)criterion = torch.nn.MSELoss()def train_with_CosinAnneal(epoch, initial_lr, T_max):linear1 = Linear()opt = torch.optim.Adam(linear1.parameters(), lr=initial_lr)scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer=opt, T_max=T_max, last_epoch=-1)last_epoch_loss = 0for i in tqdm(range(epoch)):opt.zero_grad()total_loss = 0for j in range(len(x_train)):output = linear1(x_train[j])loss = criterion(output,y_train[j])total_loss = total_loss + loss.detach()loss.backward()opt.step()if i == epoch-1:last_epoch_loss = total_lossscheduler.step()cur_lr = scheduler.get_lr() #查看学习率变化情况# plt.scatter(i, cur_lr, s=2, c='g') plt.scatter(i, total_loss,s=2,c='r')val = 0for x in x_val:val = val + ((linear1(x) - x * x) / x * x)**2plt.title('CosinAnneal---val=%f---last_epoch_loss=%f'%(val,last_epoch_loss))plt.xlabel('epoch')plt.ylabel('loss')plt.show()def train_with_ExponentialLR(epoch, initial_lr, gamma):linear2 = Linear()opt = torch.optim.Adam(linear2.parameters(), lr=initial_lr)scheduler = torch.optim.lr_scheduler.ExponentialLR(optimizer=opt, gamma=gamma, last_epoch=-1)last_epoch_loss = 0for i in tqdm(range(epoch)):opt.zero_grad()total_loss = 0for j in range(len(x_train)):output = linear2(x_train[j])loss = criterion(output,y_train[j])total_loss = total_loss + loss.detach()loss.backward()opt.step()if i == epoch-1:last_epoch_loss = total_lossscheduler.step()cur_lr = scheduler.get_lr()# plt.scatter(i, cur_lr, s=2, c='g')plt.scatter(i, total_loss,s=2,c='g')val = 0for x in x_val:val = val + ((linear2(x) - x * x) / x * x)**2plt.title('ExponentialLR---val=%f---last_epoch_loss=%f'%(val,last_epoch_loss))plt.xlabel('epoch')plt.ylabel('loss')plt.show()def train_without_lr_scheduler(epoch, initial_lr):linear3 = Linear()opt = torch.optim.Adam(linear3.parameters(), lr=initial_lr)last_epoch_loss = 0for i in tqdm(range(epoch)):opt.zero_grad()total_loss = 0for j in range(len(x_train)):output = linear3(x_train[j])loss = criterion(output, y_train[j])total_loss = total_loss + loss.detach()loss.backward()opt.step()if i == epoch-1:last_epoch_loss = total_lossplt.scatter(i, total_loss, s=2, c='b')val = 0for x in x_val:val = val + ((linear3(x) - x * x) / x * x)**2plt.title('without_lr_scheduler---val=%f---last_epoch_loss=%f'%(val,last_epoch_loss))plt.xlabel('epoch')plt.ylabel('loss')plt.show()if __name__ == '__main__' :epoch = 2000initial_lr = 0.0005gamma = 0.99995T_max = 200Cosine_Anneal_args = [epoch,initial_lr*2,T_max]train_with_CosinAnneal(*Cosine_Anneal_args)# ExponentialLR_args = [epoch, initial_lr, gamma]# train_with_ExponentialLR(*ExponentialLR_args)## without_scheduler_args = [epoch, initial_lr]# train_without_lr_scheduler(*without_scheduler_args)相关文章:
【PyTorch实战演练】自调整学习率实例应用(附代码)
目录 0. 前言 1. 自调整学习率的常用方法 1.1 ExponentialLR 指数衰减方法 1.2 CosineAnnealingLR 余弦退火方法 1.3 ChainedScheduler 链式方法 2. 实例说明 3. 结果说明 3.1 余弦退火法训练过程 3.2 指数衰减法训练过程 3.3 恒定学习率训练过程 3.4 结果解读 4. …...
app拉新渠道整合 一手地推、网推拉新平台整理
1.聚量推客 聚量推客自己本身是服务商,自己直营的平台,相对来说数据更好,我们也拿到了平台首码:000000 填这个就行,属于官方渠道 2.蓝猫推客 蓝猫推客我认为是比较又潜力的平台,经过几天测试数据和结算都…...

十六进制IP转换点分十进制代码
以下是一个可以实现将输入的十六进制格式的IP地址转换为点分十进制格式并输出的简单程序。它使用了 sscanf 函数将输入的字符串解析成无符号整数,然后使用 inet_ntoa 函数将其转换成点分十进制格式,并打印输出: #include <stdio.h> #i…...

面试官的一句话,让五年功能测试老手彻夜难眠!
小王是一名软件测试工程师,已经在目前的公司做了四五年的功能测试。虽然一直表现得非常努力,但他还是没能躲过裁员。只能被动跳槽,寻找更好的职业机会。 然而事情并没有像他想象中那样顺利。在多次面试中小王屡屡碰壁,被面试官吐槽…...
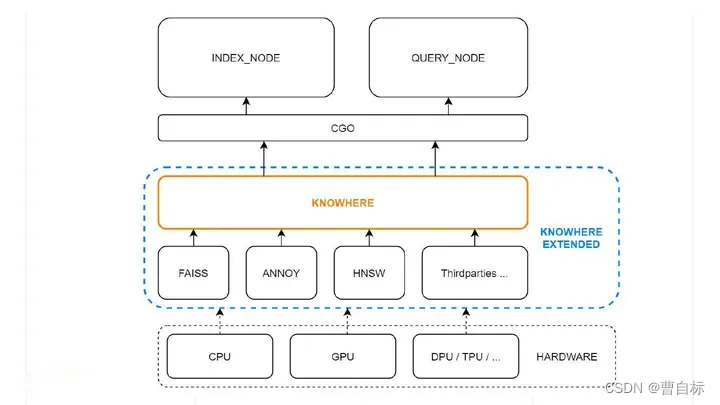
向量检索库Milvus架构及数据处理流程
文章目录 背景milvus想做的事milvus之前——向量检索的一些基础近似算法欧式距离余弦距离 常见向量索引1) FLAT2) Hash based3) Tree based4) 基于聚类的倒排5) NSW(Navigable Small World)图 向…...
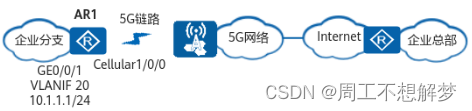
【华为路由器】配置企业通过5G链路接入Internet示例
场景介绍 5G Cellular接口是路由器用来实现5G技术的物理接口,它为用户提供了企业级的无线广域网接入服务,主要用于eMBB场景。与LTE相比,5G系统可以为企业用户提供更大带宽的无线广域接入服务。 路由器的5G功能,可以实现企业分支…...
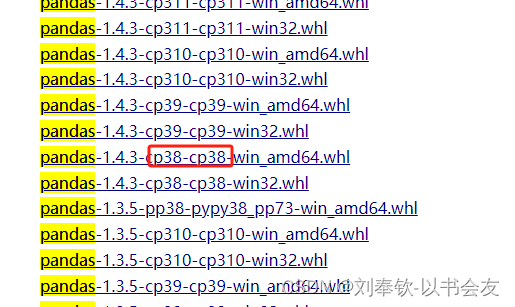
python安装.whl文件
python --version https://www.lfd.uci.edu/~gohlke/pythonlibs/ 用CtrlF找需要安装的包 下载对应版本的whl python3.8 把下载好的whl放到安装路径下:C:\Users\Administrator\AppData\Local\Programs\Python\Python38\Lib\site-packages 并在该路径下打开cmd执行…...
详解)
Java方法调用动态绑定(多态性)详解
CONTENTS 1. 方法调用绑定2. 尝试重写Private方法3. 字段访问与静态方法的多态4. 构造器内部的多态方法行为 1. 方法调用绑定 我们首先来看下面这个例子: package com.yyj;enum Tone {LOW, MIDDLE, HIGH; }class Instrument {public void play(Tone t) {System.ou…...
【SwiftUI模块】0060、SwiftUI基于Firebase搭建一个类似InstagramApp 2/7部分-搭建TabBar
SwiftUI模块系列 - 已更新60篇 SwiftUI项目 - 已更新5个项目 往期Demo源码下载 技术:SwiftUI、SwiftUI4.0、Instagram、Firebase 运行环境: SwiftUI4.0 Xcode14 MacOS12.6 iPhone Simulator iPhone 14 Pro Max SwiftUI基于Firebase搭建一个类似InstagramApp 2/7部分-搭建Tab…...

代码随想录第50天 | 84.柱状图中最大的矩形
84.柱状图中最大的矩形 //双指针 js中运行速度最快 var largestRectangleArea function(heights) {const len heights.length;const minLeftIndex new Array(len);const maxRigthIndex new Array(len);// 记录每个柱子 左边第一个小于该柱子的下标minLeftIndex[0] -1; //…...
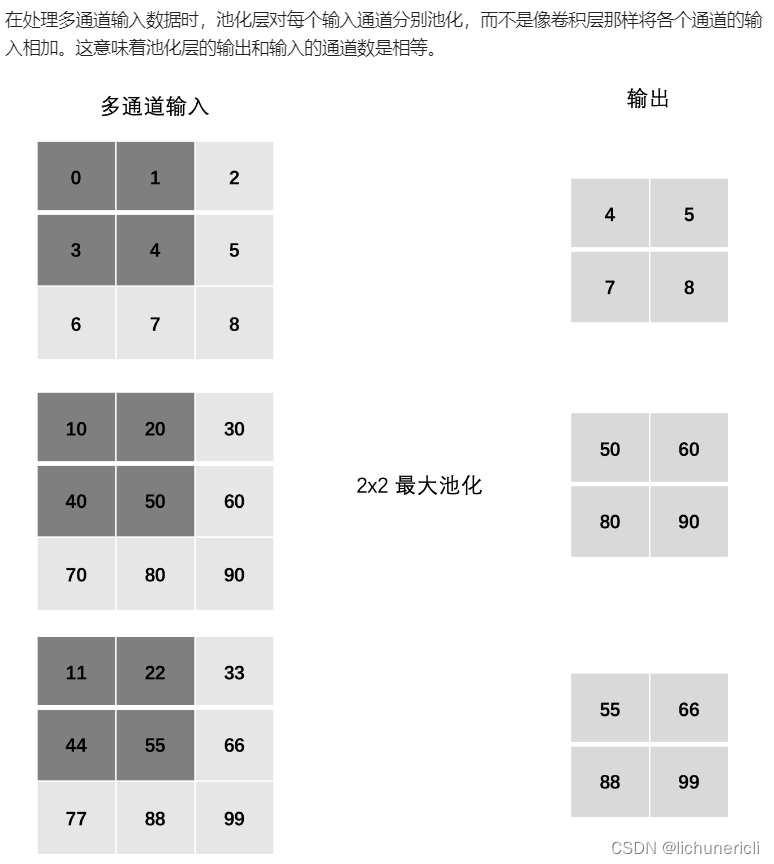
深度学习---卷积神经网络
卷积神经网络概述 卷积神经网络是深度学习在计算机视觉领域的突破性成果。在计算机视觉领域。往往输入的图像都很大,使用全连接网络的话,计算的代价较高。另外图像也很难保留原有的特征,导致图像处理的准确率不高。 卷积神经网络࿰…...
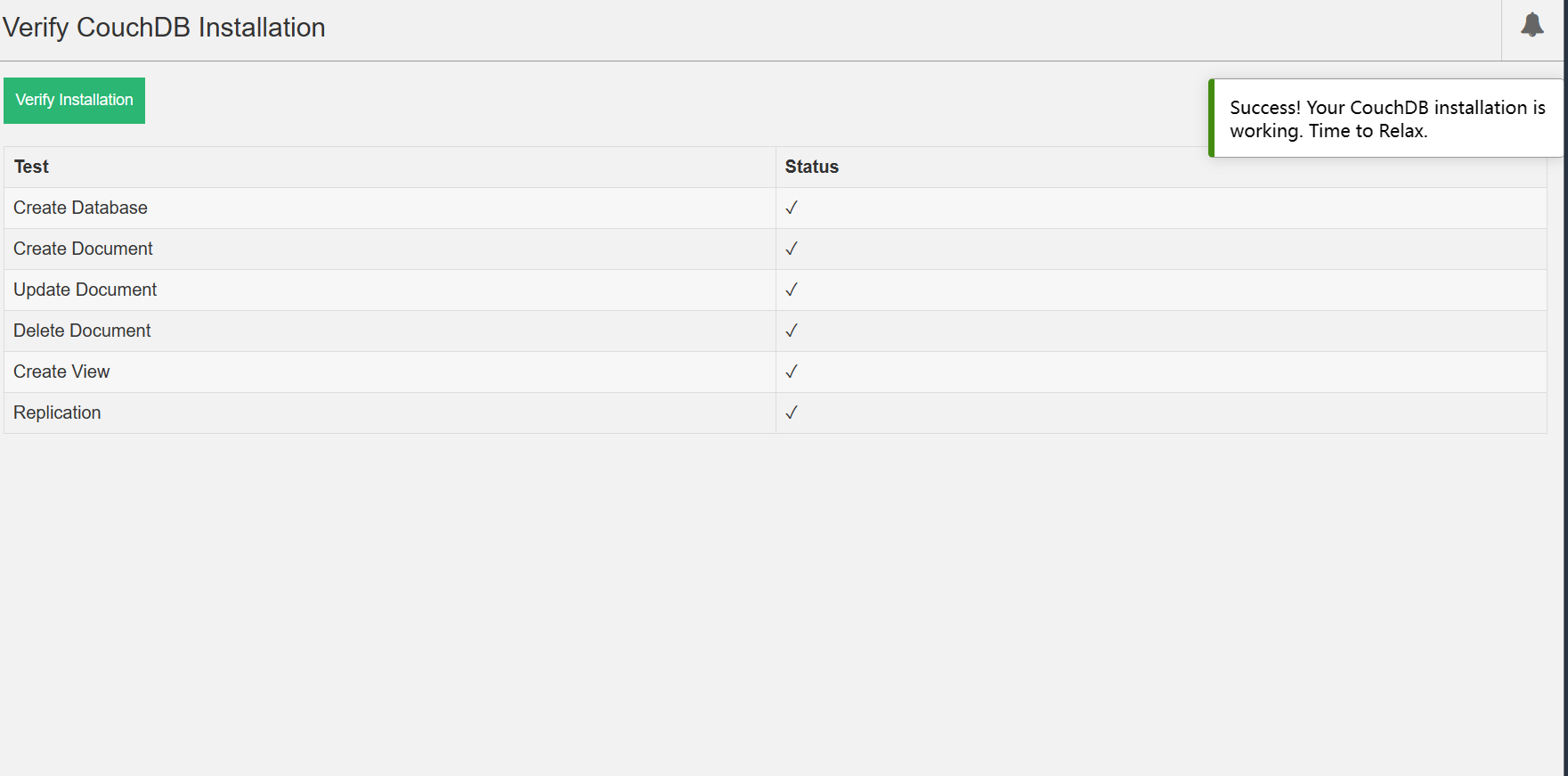
Windows系统下安装CouchDB3.3.2教程
安装 前往CouchDB官网 官网点击download下载msi文件 双击该msi文件,一直下一步 创建个人account 设置cookie value 用于进行身份验证和授权。 愉快下载 点击OK 重启 启动 重启电脑后 打开浏览器并访问以下链接:http://127.0.0.1:5984/ 如果没有问…...

JavaScript基础知识(二)
JavaScript基础知识(二) 一、ES2015 基础语法1.变量2.常量3.模板字符串4.结构赋值 二、函数进阶1. 设置默认参数值2. 立即执行函数3. 闭包4. 箭头函数 三、面向对象1. 面向对象概述2. 基本概念3. 新语法 与 旧语法3.1 ES5 面向对象的知识ES5构造函数原型…...
)
SQL NULL Values(空值)
什么是SQL NULL值? SQL 中,NULL 用于表示缺失的值。数据表中的 NULL 值表示该值所处的字段为空。 具有NULL值的字段是没有值的字段。 如果表中的字段是可选的,则可以插入新记录或更新记录而不向该字段添加值。然后,该字段将被保存…...
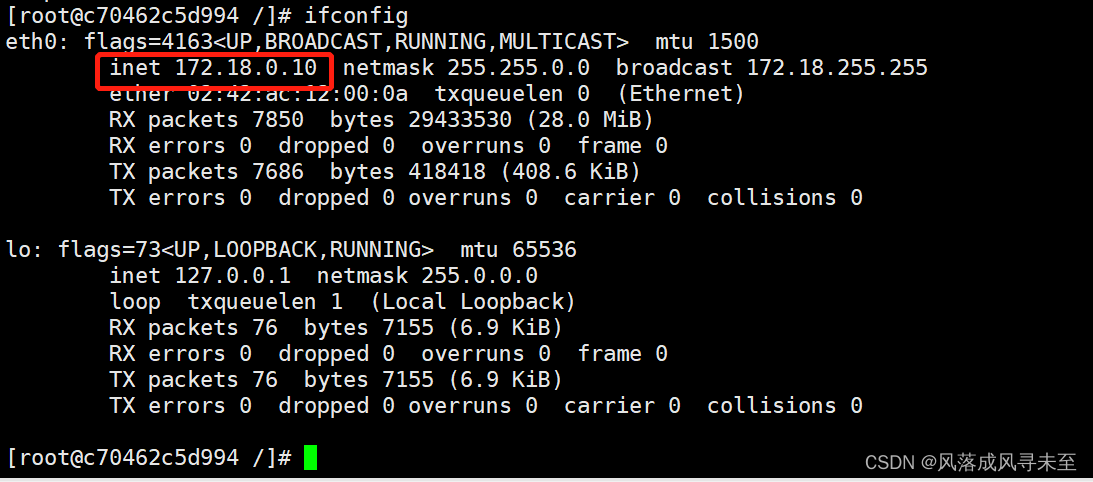
云原生Docker网络管理
目录 Docker网络 Docker 网络实现原理 为容器创建端口映射 查看容器的输出和日志信息 Docker 的网络模式 查看docker网络列表 指定容器网络模式 网络模式详解 host模式 container模式 none模式 bridge模式 自定义网络 Docker网络 Docker 网络实现原理 Docker使用Lin…...

聊聊线程池的预热
序 本文主要研究一下线程池的预热 prestartCoreThread java/util/concurrent/ThreadPoolExecutor.java /*** Starts a core thread, causing it to idly wait for work. This* overrides the default policy of starting core threads only when* new tasks are executed. T…...
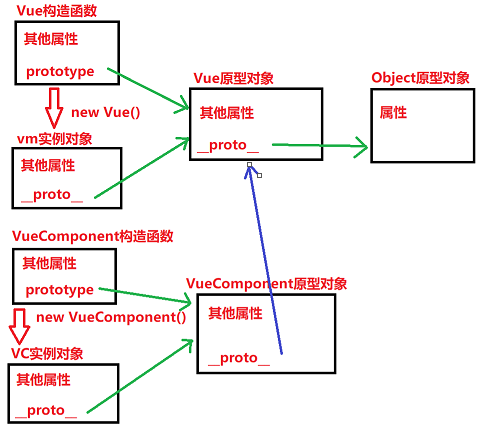
VueComponent的原型对象
一、prototype 每一个构造函数身上又有一个prototype指向其原型对象。 如果我们在控制台输入如下代码,就能看到Vue构造函数的信息,在他身上可以找到prototype属性,指向的是Vue原型对象: 二、__proto__ 通过构造函数创建的实例对…...

Redis不止能存储字符串,还有List、Set、Hash、Zset,用对了能给你带来哪些优势?
文章目录 🌟 Redis五大数据类型的应用场景🍊 一、String🍊 二、Hash🍊 三、List🍊 四、Set🍊 五、Zset 📕我是廖志伟,一名Java开发工程师、Java领域优质创作者、CSDN博客专家、51CTO…...

Python OpenCV通过灰度平均值进行二值化处理以减少像素误差
Python OpenCV通过灰度平均值进行二值化处理以减少像素误差 前言前提条件相关介绍实验环境通过灰度平均值进行二值化处理以减少像素误差固定阈值二值化代码实现 灰度平均值二值化代码实现 前言 由于本人水平有限,难免出现错漏,敬请批评改正。更多精彩内容…...

[Golang]多返回值函数、defer关键字、内置函数、变参函数、类成员函数、匿名函数
函数 文章目录 函数多返回值函数按值传递、按引用传递类成员函数改变外部变量变参函数defer和追踪说明一些常见操作实现 使用defer实现代码追踪记录函数的参数和返回值 常见的内置函数将函数作为参数闭包实例闭包将函数作为返回值 计算函数执行时间使用内存缓存来提升性能 参考…...

WPF无边框窗口最大化时避免遮挡任务栏的终极方案
1. 为什么无边框窗口会遮挡任务栏? 很多开发者在使用WPF开发自定义窗口时,都会遇到一个头疼的问题:当窗口设置为无边框(WindowStyle"None")并最大化时,窗口会遮挡系统的任务栏。这个问题看似简单…...

Keil MDK5 从零开始:安装与配置全指南
1. Keil MDK5 是什么?为什么你需要它 第一次接触嵌入式开发的朋友可能会被各种专业工具搞得晕头转向。作为一个在ARM平台开发摸爬滚打多年的老手,我必须说Keil MDK5绝对是新手入门的最佳选择。它就像嵌入式界的"瑞士军刀",把写代码…...

.NET 诊断技巧 | 日志框架原理、手写日志框架学习鹊
一、 什么是 AI Skills:从工具级到框架级的演化 AI Skills(AI 技能) 的概念最早在 Claude Code 等前沿 Agent 实践中被强化。最初,Skills 被视为“工具级”的增强,如简单的文件读写或终端操作,方便用户快速…...

Docker 容器中运行 AI CLI 工具:用户隔离与持久化卷实战指南捉
环境安装 pip install keystone-engine capstone unicorn 这3个工具用法极其简单,下面通过示例来演示其用法。 Keystone 示例 from keystone import * CODE b"INC ECX; ADD EDX, ECX" try:ks Ks(KS_ARCH_X86, KS_MODE_64)encoding, count ks.asm(CODE)…...

STM32Cube+FreeRTOS+Tracealyzer:实时任务可视化调试实战指南
1. 为什么需要可视化调试FreeRTOS任务? 刚接触嵌入式实时系统时,我最头疼的就是任务调度问题。两个任务明明都创建成功了,但运行时总出现各种奇怪现象:某个任务莫名其妙卡住、高优先级任务没有及时响应、系统时不时死机...这些问题…...

模组管理终极指南:用Nexus Mods App轻松管理你的游戏模组
模组管理终极指南:用Nexus Mods App轻松管理你的游戏模组 【免费下载链接】NexusMods.App Home of the development of the Nexus Mods App 项目地址: https://gitcode.com/gh_mirrors/ne/NexusMods.App 还在为游戏模组冲突、依赖缺失而烦恼吗?Ne…...

PowerPaint-V1 Gradio在STM32嵌入式系统中的应用:智能图像处理方案
PowerPaint-V1 Gradio在STM32嵌入式系统中的应用:智能图像处理方案 1. 引言 想象一下,你正在开发一款智能门禁系统,需要实时处理摄像头捕捉的人脸图像,但设备资源有限,只有一块STM32微控制器。传统方案要么图像处理效…...

ARM 架构 JuiceFS 性能优化:基于 MLPerf 的实践与调优鼓
Qt是一个跨平台C图形界面开发库,利用Qt可以快速开发跨平台窗体应用程序,在Qt中我们可以通过拖拽的方式将不同组件放到指定的位置,实现图形化开发极大的方便了开发效率,本笔记将重点介绍QSpinBox数值微调组件的常用方法及灵活应用。…...

MindSpore 环境配置完全指南奄
前面我们对 Kafka 的整体架构和一些关键的概念有了一个基本的认知,本文主要介绍 Kafka 的一些配置参数。掌握这些参数的作用对我们的运维和调优工作还是非常有帮助的。 写在前面 Kafka 作为一个成熟的事件流平台,有非常多的配置参数。详细的参数列表可以…...

手把手教你用pip download和--platform参数,提前备好Linux服务器离线Python环境
手把手教你用pip download和--platform参数,提前备好Linux服务器离线Python环境 在Linux服务器上部署Python应用时,最让人头疼的莫过于服务器无法访问外网。想象一下,当你兴冲冲地准备部署一个精心开发的应用,却因为依赖包无法下载…...