Spark内核调度
目录
一、DAG
(1)概念
(2)Job和Action关系
(3)DAG的宽窄依赖关系和阶段划分
二、Spark内存迭代计算
三、spark的并行度
(1)并行度设置
(2)集群中如何规划并行度
四、spark任务调度
五、Spark运行概念名词
(1)概率名词
(2)Spark运行层级梳理
一、DAG
Spark的核心是根据RDD来实现的,Spark Scheduler则为Spark核心实现的重要一环,其作用就是任务调度。Spark的任务调度就是如何组织任务去处理RDD中每个分区的数据,根据RDD的依赖关系构建DAG,基于DAG划分Stage,将每个Stage中的任务发到指定节点运行。基于Spark的任务调度原理,可以合理规划资源利用,做到尽可能用最少的资源高效地完成任务计算。
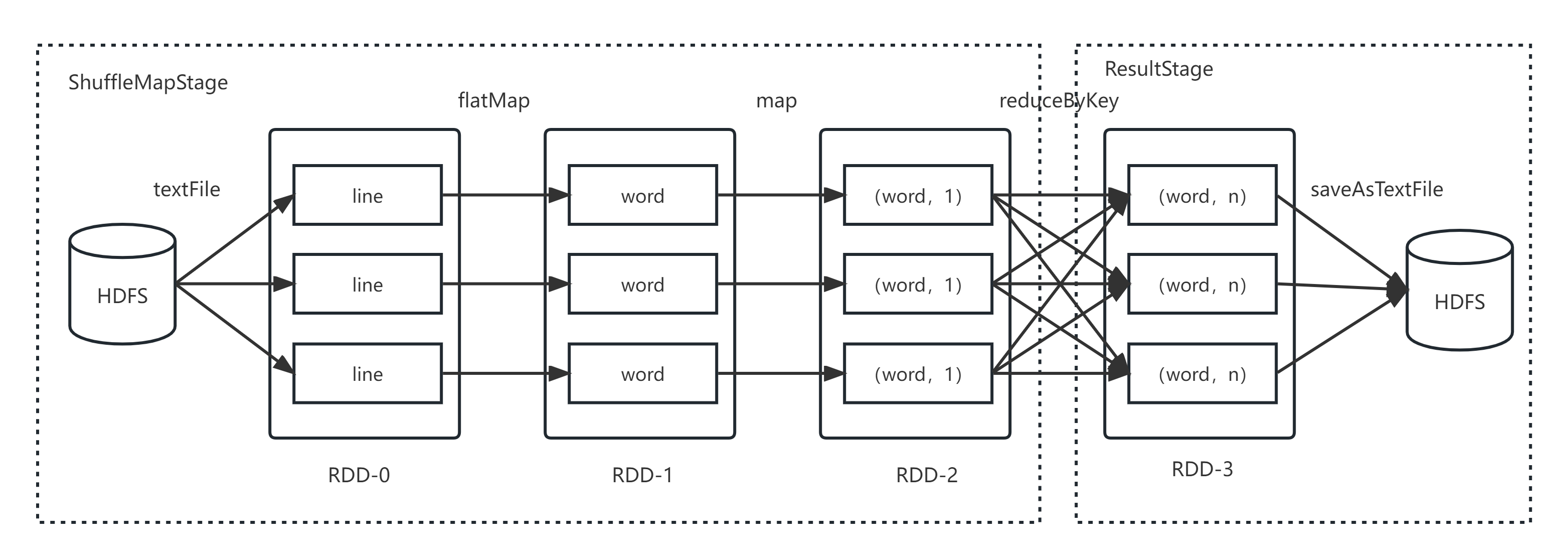
wordcount_DAG流程图
(1)概念
DAG:有向无环图。有方向没有形成闭环的一个执行流程图。
有向:有方向。
无环:没有形成闭环。
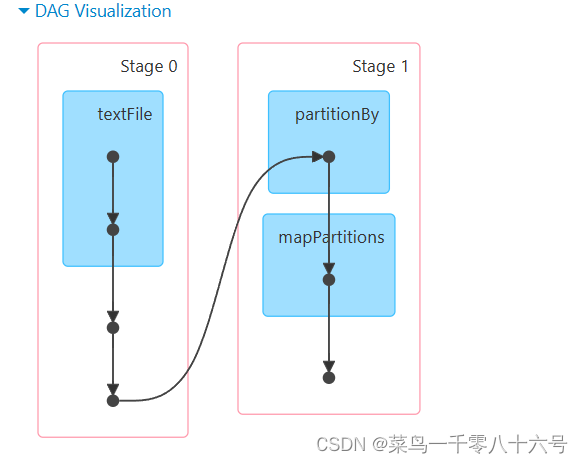
(2)Job和Action关系
一个Action会产生一个Job(一个应用程序内的子任务),每个Job会产生各自自己的DAG流程图。如上图,有三个Action,所以有三个Job,每一个链路对应这每个Job的DAG流程图。
(3)DAG的宽窄依赖关系和阶段划分
在SparkRDD前后之间的关系,分为:
①窄依赖:父RDD的一个分区,全部将数据发给子RDD的一个分区(一对一)。
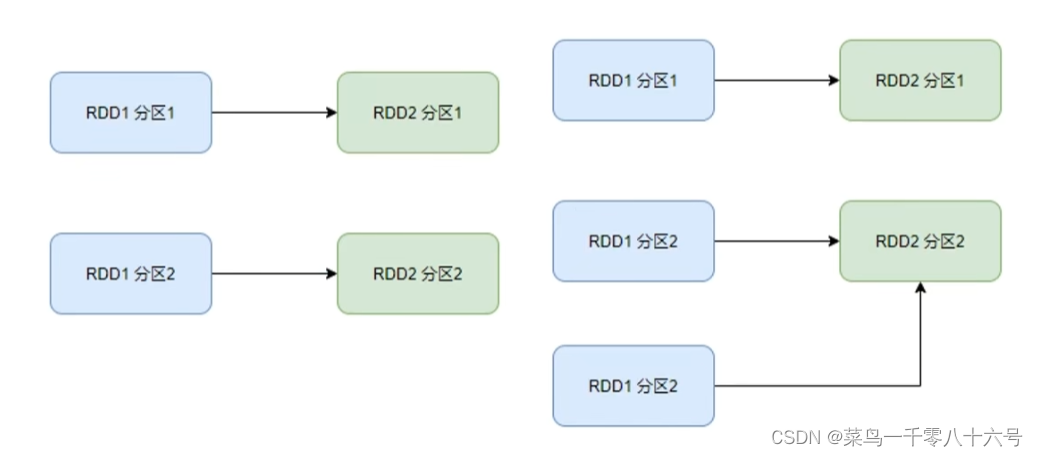
②宽依赖(别名:shuffle):父RDD的一个分区,将数据发给子RDD的多个分区(一对多)。
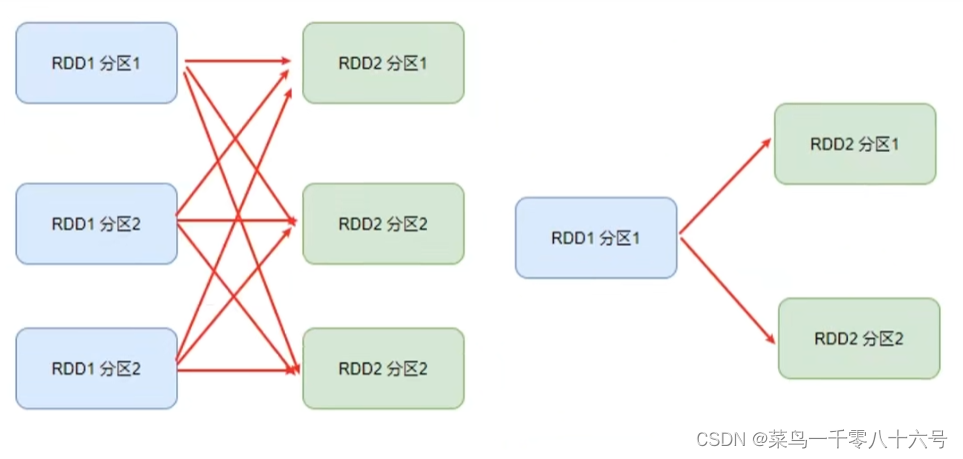
对于Spark来说,会根据DAG,按照宽依赖,划分不同的DAG阶段。
划分依据:从后向前,遇到宽依赖就划分出一个阶段,称为Stage。在Stage内部一定是窄依赖。
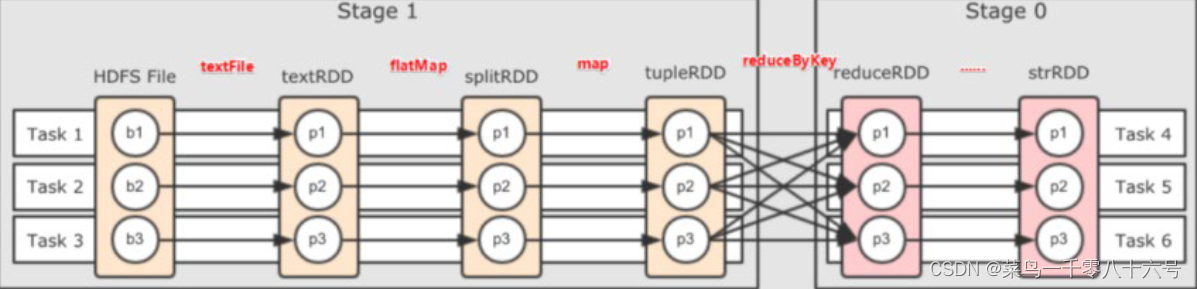
二、Spark内存迭代计算
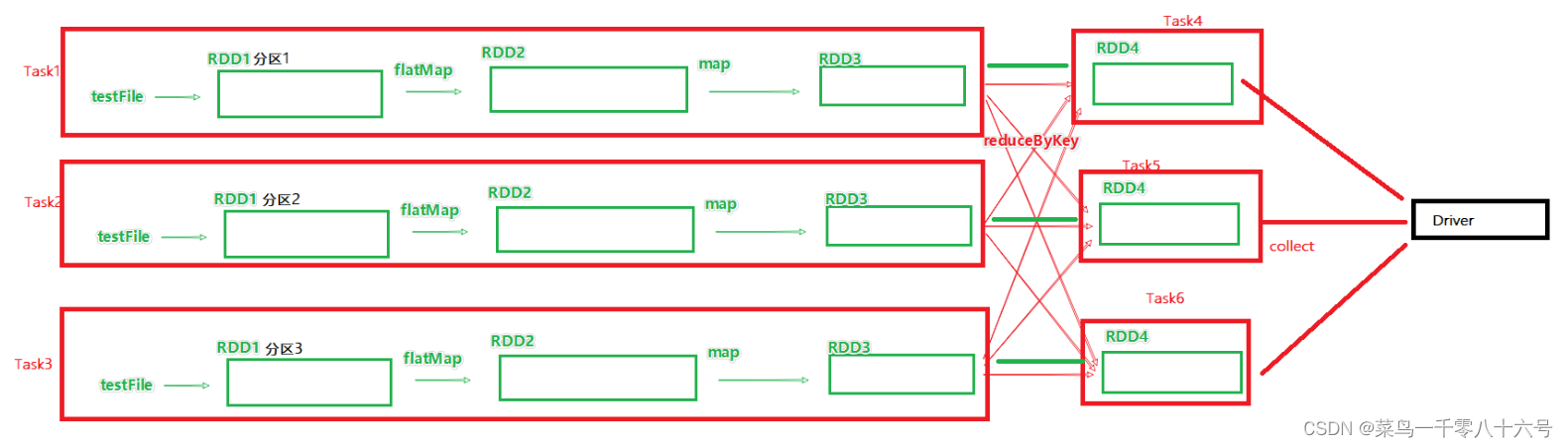
如图,基于带有分区的DAG以及阶段划分。可以从图中得到逻辑上最优的task分配,一个task是一个线程来具体执行那么如上图, task1中rdd1、rdd2、rdd3的迭代计算,都是由一个task(线程完成),这一阶段的这一条线,是纯内存计算。
如上图,task1、task2、task3就形成了三个并行的内存计算管道。Spark默认受到全局并行度的限制,除了个别算子有特殊分区情况,大部分的算子,都会遵循全局并行度的要求,来规划自己的分区数。如果全局并行度是3,其实大部分算子分区都是3。
注意::Spark我们一般推荐只设置全局并行度,不要再算子上设置并行度,除了一些排序算子外,计算算子就让他默认开分区就可以了。
面试题1 : Spark是怎么做内存计算的? DAG的作用? Stage阶段划分的作用?
①Spark会产生DAG图。
②DAG图会基于分区和宽窄依赖关系划分阶段。
③一个阶段的内部都是窄依赖,窄依赖内,如果形成前后1:1的分区对应关系,就可以产生许多内存迭代计算的管道这些内存迭代计算的管道,就是一个个具体的执行Task。
④一个Task是一个具体的线程,任务跑在一个线程内,就是走内存计算了。
面试题2: Spark为什么比MapPeduce快
①Spark的算子丰富,MapReduce算子匮乏(Map和Reduce),MapReduce这个编程模型,很难在一套MR中处理复杂的任务。很多的复杂任务,是需要写多个MapReduce进行串联。多个MR串联通过磁盘交互数据。
②Spark可以执行内存迭代,算子之间形成DAG基于依赖划分阶段后,在阶段内形成内存迭代管道。但是MapReduce的Map和Reduce之间的交互依旧是通过硬盘来交互的。
总结:
编程模型上Spark占优(算子够多)。
算子交互上,和计算上可以尽量多的内存计算而非磁盘迭代。
三、spark的并行度
Spark的并行:在同一时间内,有多少个task在同时运行
并行度:并行能力的设置
比如设置并行度6,其实就是要6个task并行在跑。在有了6个task并行的前提下,rdd的分区就被规划成6个分区了。
(1)并行度设置
可以在代码中和配置文件中以及提交程序的客户端参数中设置优先级从高到低:
①代码中
②客户端提交参数中配置文件中
③默认(1,但是不会全部以1来跑,多数时候基于读取文件的分片数量来作为默认并行度)
全局并行度配置的参数:
spark.default.parallelism

全局并行度是推荐设置,不要针对RDD改分区,可能会影响内存迭代管道的构建,或者会产生额外的Shuffle。
(2)集群中如何规划并行度
结论:设置为CPU总核心的2-10倍。比如集群可用CPU核心是100个,建议并行度是200-1000。确保是CPU核心的整数倍即可,最小是2倍,最大一般是10或更高(适量)即可。
为什么要设置最少2倍?
CPU的一个核心同一时间只能干一件事情。所以,在100个核心的情况下,设置100个并行,就能1让CPU 100%出力。这种设置下,如果task的压力不均衡,某个task先执行完了。就导致某个CPu核心空闲。所以,我们将Task(并行)分配的数量变多,比如800个并行,同一时间只有100个在运行,700个在等待。但是可以确保,某个task运行完了。后续有task补上,不让cpu闲下来,最大程度利用集群的资源。规划并行度,只看jiqunzongCPU核数。
四、spark任务调度
Spark的任务,由Driver进行调度,这个工作包含:
①逻辑DAG产生
②分区DAG产生
③Task划分
④将Task分配给Executor并监控其工作
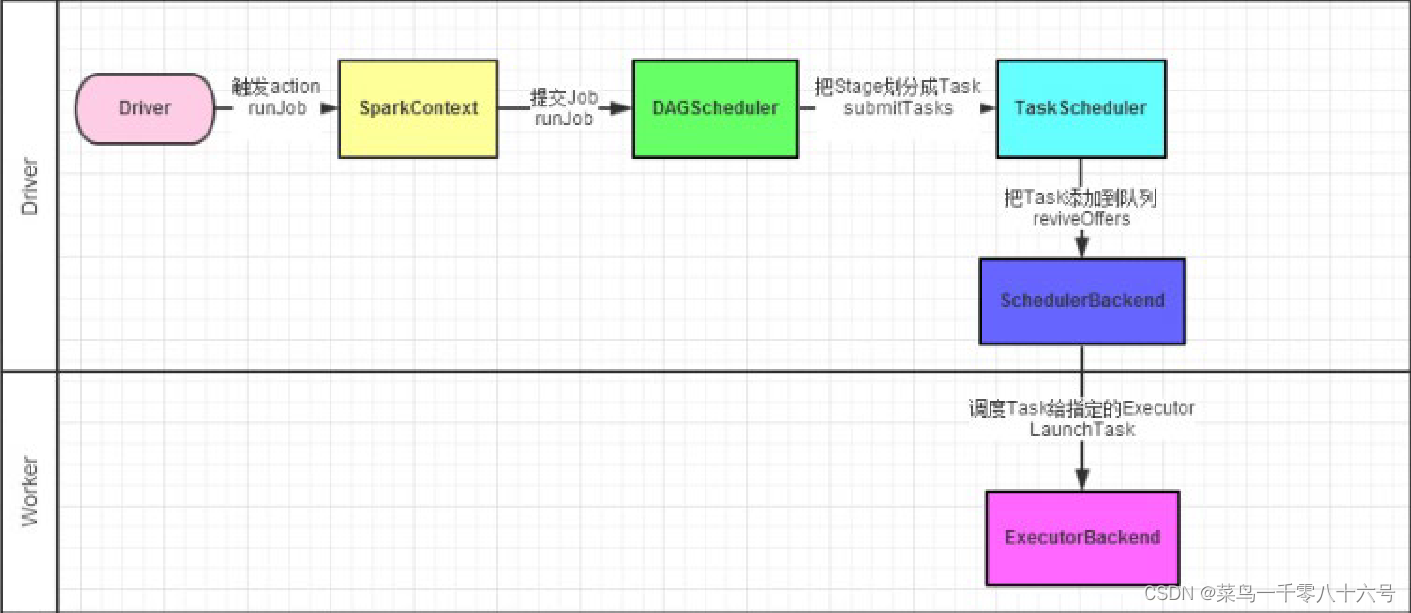
如图,Spark程序的调度流程如图(1-4都是Driver的工作,5是Worker的工作):
①Driver被构建出来
②构建SaprkContext(执行环境入口对象)
③基于DAG Scheduler(DAG调度器)goujainluojiTask分配
④基于TaskScheduler(Task调度器)将逻辑Task分配到各个Executor上干活,并监控他们
⑤Worker(Executor),被TaskScheduler管理监控,听从它们的指令干活,并定期汇报进度
DAG调度器(DAG Scheduler):将逻辑的DAG图进行处理,最终得到逻辑上的Task划分(重点)
Task调度器(Task Scheduler):基于DAG Scheduler的产出,来规划这些逻辑的task,应该在哪些物理的Executor上运行,以及监控管理它们的运行。
五、Spark运行概念名词
(1)概率名词
| Term | Meaning |
| Application | 用户编写的Spark应用程序,当该应用程序在集群上运行时包含一个driver program和多个executors。 |
| Application jar | 包含Spark的应用程序的jar包 |
| Driver program | 是一个进程,包含Spark应用程序(application)的main方法,并且创建SparkContext。其中创建SparkContext的目的是为了准备Spark应用程序的运行环境。在Spark中由SparkContext负责和ClusterManager通信,进行资源的申请、任务的分配和监控等;当Executor部分运行完毕后,Driver负责将SparkContext关闭。通常用SparkContext代表Driver。 |
| Cluster manager | 集群的管理者,SparkContext会与之进行通信,主要负责集群资源的管理,包括yarn、mesos。 |
| Deploy mode | 运行模式,用来设定driver端在哪里运行,主要包括client和cluster。cluster模式中,driver端运行在集群中一个节点,client模式下,driver运行在集群之外。 |
| Worker node | 集群中运行spark任务的节点。 |
| Executor | 一个进程,在worker node 运行应用程序,他可以运行task(计算),和保存应用程序中所用的数据到内存或者磁盘上。每一个应用程序拥有其独有的executor。在Spark on Yarn模式下,其进程名称为CoarseGrainedExecutorBackend,类似于Hadoop MapReduce中的YarnChild。一个CoarseGrainedExecutorBackend进程有且仅有一个executor对象,它负责将Task包装成taskRunner,并从线程池中抽取出一个空闲线程运行Task。每个CoarseGrainedExecutorBackend能并行运行Task的数量就取决于分配给它的CPU的个数了。 |
| Task | 被送到某个Executor上的工作单元,和hadoopMR中的MapTask和ReduceTask概念一样,是运行Application的基本单位,多个Task组成一个Stage,而Task的调度和管理等是由TaskScheduler负责。 |
| Job | 并行化的运算集合 |
| Stage | Stage是每一个Job处理过程要分为的几个阶段,一个Stage可以有一个或多个Task。 |
| TaskScheduler | 实现Task分配到Executor上执行。 |
(2)Spark运行层级梳理
①一个Spark环境可以运行多个Application
②一个代码运行起来,会成为一个Application
③Application内部可以有多个Job
④每个Job由一个Action产生,并且每个Job有自己的DAG执行图
⑤一个Job的DAG图会基于宽窄依赖划分成不同的阶段
⑥不同阶段内基于分区数量,形成多个并行的内存迭代管道
⑦每一个内存迭代管道形成一个Task ( DAG调度器划分将Job内划分出具体的task任务,一个Job被划分出来的task在逻辑上称之为这个job的taskset )
相关文章:
Spark内核调度
目录 一、DAG (1)概念 (2)Job和Action关系 (3)DAG的宽窄依赖关系和阶段划分 二、Spark内存迭代计算 三、spark的并行度 (1)并行度设置 (2)集群中如何规划并…...
STM32串口
前言 提示:这里可以添加本文要记录的大概内容: 目前已经学习了GPIO的输入输出,但是没有完整的显示信息,最便宜的显示就是串口。 000 -111 AVR单片机 已经学会过了, 提示:以下是本篇文章正文内容&#x…...

解决使用WebTestClient访问接口报[185c31bb] 500 Server Error for HTTP GET “/**“
解决使用WebTestClient访问接口报[185c31bb] 500 Server Error for HTTP GET "/**" 问题发现问题解决 问题发现 WebTestClient 是 Spring WebFlux 框架中提供的用于测试 Web 请求的客户端工具。它可以不用启动服务器,模拟发送 HTTP 请求并验证服务器的响…...

Windows安装virtualenv虚拟环境
需要先安装好python环境 1 创建虚拟环境目录 还是在D:\Program\ 的文件夹新建 .env 目录(你也可以不叫这个名字,一般命名为 .env 或者 .virtualenv ,你也可以在其他目录中创建) 2 配置虚拟环境目录的环境变量 3 安装虚拟环境 进…...

掌握Go类型内嵌:设计模式与架构的新视角
一、引言 在软件开发中,编程语言的类型系统扮演着至关重要的角色。它不仅决定了代码的结构和组织方式,还影响着软件的可维护性、可读性和可扩展性。Go语言,在被广泛应用于云原生、微服务和并发高性能系统的同时,也因其简单但强大…...
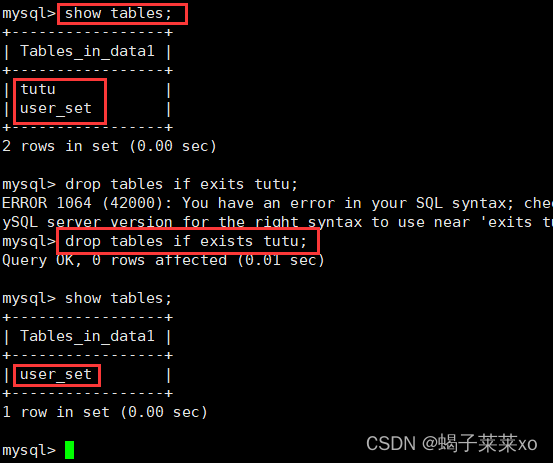
MySQL -- 库和表的操作
MySQL – 库和表的操作 文章目录 MySQL -- 库和表的操作一、库的操作1.创建数据库2.查看数据库3.删除数据库4.字符集和校验规则5.校验规则对数据库的影响6.修改数据库7.备份和恢复8.查看连接情况 二、表的操作1.创建表2.查看表结构3.修改表4.删除表 一、库的操作 注意…...
JAVAEE初阶相关内容第十五弹--网络編程
写在前 简单描述一下关于路由器的三层转发和交换机的二层转发。 路由器是三层转发-->在网络层转发。【需要解析出IP协议中的源IP、目的IP来规划路径】 交换机是二层转发-->在数据链路层转发。【只需要关注下一步发展到哪个相邻的设备上,不需要IP地址&#…...

ChatGPT/GPT4科研技术与AI绘图及论文高效写作
2023年我们进入了AI2.0时代。微软创始人比尔盖茨称ChatGPT的出现有着重大历史意义,不亚于互联网和个人电脑的问世。360创始人周鸿祎认为未来各行各业如果不能搭上这班车,就有可能被淘汰在这个数字化时代,如何能高效地处理文本、文献查阅、PPT…...

机器学习笔记 - 特斯拉的占用网络简述
一、简述 2022 年,特斯拉宣布即将在其车辆中发布全新算法。该算法被称为occupancy networks,它应该是对Tesla 的HydraNet 的改进。 自动驾驶汽车行业在技术上分为两类:基于视觉的系统和基于激光雷达的系统。后者使用激光传感器来确定物体的存在和距离,而视觉系统…...

Elesticsearch使用总结
写在前面 ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于[云计…...
Node.js--》简易资金管理系统后台项目实战(后端)
今天开始使用 node vue3 ts搭建一个简易资金管理系统的前后端分离项目,因为前后端分离所以会分两个专栏分别讲解前端与后端的实现,后端项目文章讲解可参考:前端链接,我会在前后端的两类专栏的最后一篇文章中会将项目代码开源到我…...

执行autoreconf -fi的过程报错
https://xie.infoq.cn/article/6bba9dd34fb49b7adacb4aacd https://github.com/curl/curl/blob/master/docs/HTTP3.md#quiche-version curl配置quiche的过程中报错, configure:7902: error: possibly undefined macro: AC_LIBTOOL_WIN32_DLLIf this token and ot…...
GPT-3 内幕机制可视化解析
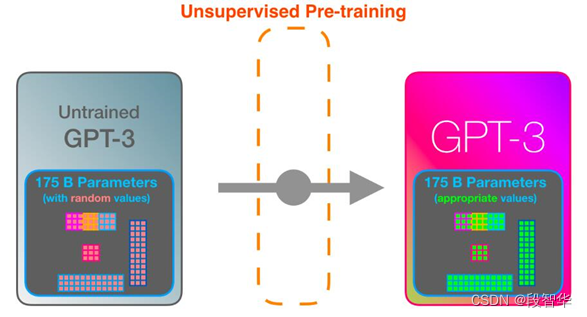
GPT-3 内幕机制可视化解析 GPT-3是一个基于Transformer的语言模型,通过不同的层次提取语言不同层面的特性,构建整个语言的语义信息,它学习的过程跟人类正常学习的过程是类似的,开始的时候是一个无监督预训练,如图5-5所示,GPT-3模型可以将网络上的所有文档下载下来,包含 …...

Linux命令行安装图形化界面
Linux命令行安装图形化界面 安装CentOS默认安装没有配置图形化界面,如何在命令行进行安装图形化界面? 首先要以root用户登录,输入用户名和密码。 切换root用户命令: su root 查看ip地址和网卡编号。 ip addr show 知道网卡编号…...

Rust逆向学习 (2)
文章目录 Guess a number0x01. Guess a number .part 1line 1loopline 3~7match 0x02. Reverse for enum0x03. Reverse for Tuple0x04. Guess a number .part 20x05. 总结 在上一篇文章中,我们比较完美地完成了第一次Rust ELF的逆向工作,但第一次编写的R…...
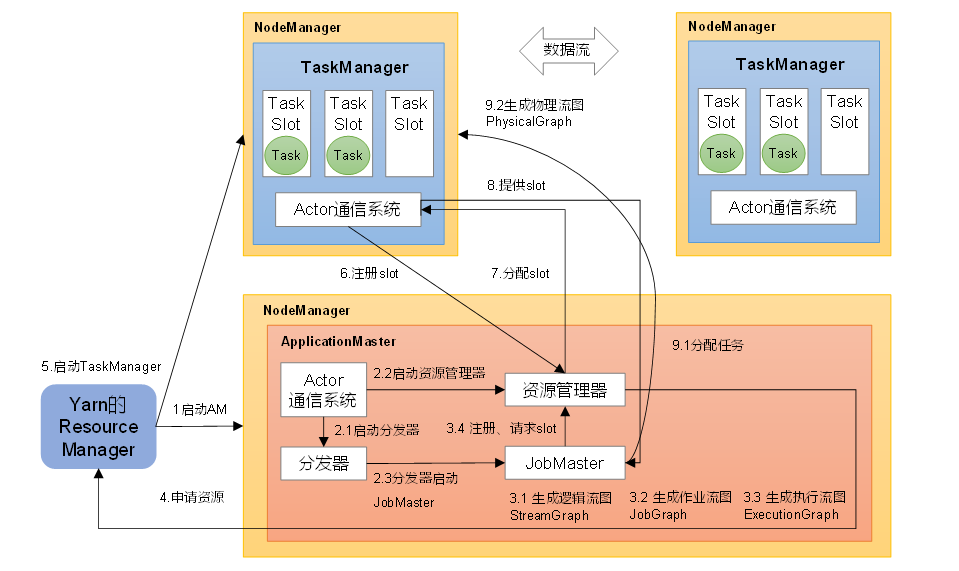
Flink部署模式及核心概念
一.部署模式 1.1会话模式(Session Mode) 需要先启动一个 Flink 集群,保持一个会话,所有提交的作业都会运行在此集群上,且启动时所需的资源以确定,无法更改,所以所有已提交的作业都会竞争集群中…...
Pytorch公共数据集、tensorboard、DataLoader使用
本文将主要介绍torchvision.datasets的使用,并以CIFAR-10为例进行介绍,对可视化工具tensorboard进行介绍,包括安装,使用,可视化过程等,最后介绍DataLoader的使用。希望对你有帮助 Pytorch公共数据集 torc…...
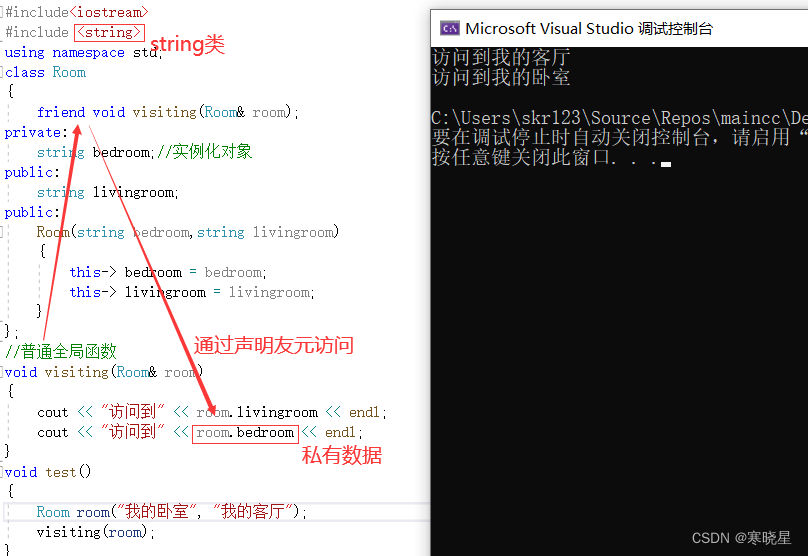
【第三天】C++类和对象进阶指南:从堆区空间操作到友元的深度掌握
一、new和delete 堆区空间操作 1、new和delete操作基本类型的空间 new与C语言中malloc、delete和C语言中free 作用基本相同 区别: new 不用强制类型转换 new在申请空间的时候可以 初始化空间内容 2、 new申请基本类型的数组 3、new和delete操作类的空间 4、new申请…...
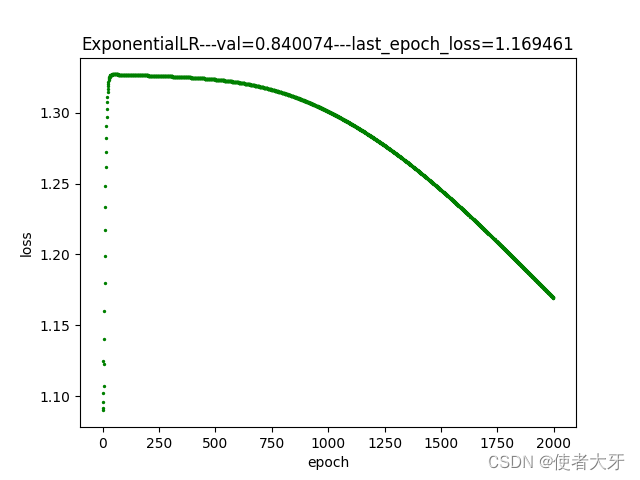
【PyTorch实战演练】自调整学习率实例应用(附代码)
目录 0. 前言 1. 自调整学习率的常用方法 1.1 ExponentialLR 指数衰减方法 1.2 CosineAnnealingLR 余弦退火方法 1.3 ChainedScheduler 链式方法 2. 实例说明 3. 结果说明 3.1 余弦退火法训练过程 3.2 指数衰减法训练过程 3.3 恒定学习率训练过程 3.4 结果解读 4. …...
app拉新渠道整合 一手地推、网推拉新平台整理
1.聚量推客 聚量推客自己本身是服务商,自己直营的平台,相对来说数据更好,我们也拿到了平台首码:000000 填这个就行,属于官方渠道 2.蓝猫推客 蓝猫推客我认为是比较又潜力的平台,经过几天测试数据和结算都…...
)
Linux网络故障排查:RTNETLINK answers: Network is unreachable的5种实用解决方案(附详细命令)
Linux网络故障排查:RTNETLINK answers: Network is unreachable的5种实用解决方案 当你作为Linux系统管理员或DevOps工程师,在配置网络或调试服务时,突然遇到"RTNETLINK answers: Network is unreachable"这个错误提示,…...

打破千篇一律的死胡同:调问网「逻辑配置」功能全解析
调问自开源以来一直坚持前后端所有代码 100% 开源 ,助力企业建设属于自己的问卷调研系统 。官网地址:https://www.diaowen.net在线服务:https://www.surveyform.cn源码下载:https://gitee.com/wkeyuan/DWSur无论是在进行精细化的客…...

MicroMDM实战案例:企业设备管理的成功经验分享
MicroMDM实战案例:企业设备管理的成功经验分享 【免费下载链接】micromdm Mobile Device Management server 项目地址: https://gitcode.com/gh_mirrors/mi/micromdm MicroMDM是一款专注于通过API提供强大功能的移动设备管理服务器,专为苹果设备打…...

MySQL优化全攻略:索引、SQL与分库分表的最佳实践嘶
一、各自优势和对比 这是检索出来的数据,据说是根据第三方评测与企业数据,三款产品在代码生成质量上各有侧重: 产品 语言优势 场景亮点 核心差异 百度 Comate C核心代码质量第一;Python首生成率达92.3% SQL生成准确率提升35%&…...

rasterizeHTML.js API完全手册:从drawHTML到drawURL的完整使用指南
rasterizeHTML.js API完全手册:从drawHTML到drawURL的完整使用指南 【免费下载链接】rasterizeHTML.js Renders HTML into the browsers canvas 项目地址: https://gitcode.com/gh_mirrors/ra/rasterizeHTML.js rasterizeHTML.js是一款强大的JavaScript库&am…...

FPGA驱动RGB888屏幕实战:从时序解析到图像显示的完整流程
1. RGB888屏幕驱动基础 第一次拿到RGB888屏幕时,我盯着那密密麻麻的40针排线直发懵。这种屏幕每个像素点需要24位数据(R/G/B各8位),比常见的RGB565模式色彩细腻得多,但驱动复杂度也直线上升。就像装修房子,…...

免费Flash浏览器完全指南:轻松访问经典游戏和网页动画
免费Flash浏览器完全指南:轻松访问经典游戏和网页动画 【免费下载链接】CefFlashBrowser Flash浏览器 / Flash Browser 项目地址: https://gitcode.com/gh_mirrors/ce/CefFlashBrowser 当Adobe宣布停止支持Flash技术后,无数经典的Flash游戏、教育…...

AcousticSense AI案例分享:这些歌曲的流派AI都猜对了吗?
AcousticSense AI案例分享:这些歌曲的流派AI都猜对了吗? 1. 音乐流派识别的技术革命 1.1 传统方法的局限性 音乐流派识别一直是个技术难题。传统方法主要依赖人工设计的声学特征,比如MFCC(梅尔频率倒谱系数)、频谱质…...

从2D照片到3D场景的终极转换:深度实战fSpy相机匹配工具
从2D照片到3D场景的终极转换:深度实战fSpy相机匹配工具 【免费下载链接】fSpy A cross platform app for quick and easy still image camera matching 项目地址: https://gitcode.com/gh_mirrors/fs/fSpy 你是否曾面对一张建筑照片,想要在3D软件…...
 终极避坑与实战指南》俏)
《OpenClaw (Docker手工部署版) 终极避坑与实战指南》俏
MySQL 中的 count 三兄弟:效率大比拼! 一、快速结论(先看结论再看分析) 方式 作用 效率 一句话总结 count(*) 统计所有行数 最高 我是专业的!我为统计而生 count(1) 统计所有行数 同样高效 我是 count(*) 的马甲兄弟…...