Rust逆向学习 (2)
文章目录
- Guess a number
- 0x01. Guess a number .part 1
- line 1
- loop
- line 3~7
- match
- 0x02. Reverse for enum
- 0x03. Reverse for Tuple
- 0x04. Guess a number .part 2
- 0x05. 总结
在上一篇文章中,我们比较完美地完成了第一次Rust ELF的逆向工作,但第一次编写的Rust程序毕竟只使用了非常有限的几种Rust特性,Rust还有很多的东西没有涉及,像是流程控制、泛型、Trait等。这些内容我们将在本文以及以后的文章中一一进行学习与探索。
Guess a number
0x01. Guess a number .part 1
本文从一个跳跃不是很大的程序开始,也就是一个真正的猜数字小程序:
use std::cmp::Ordering;
use std::io; // prelude
use rand::Rng; // traitfn main() {let secret = rand::thread_rng().gen_range(1, 101); // ThreadRng: random number generatorloop {println!("Please guess a number between 1 and 100:");let mut guess = String::new();io::stdin().read_line(&mut guess).expect("Cannot read a line!");println!("Your guess is: {}", guess);let guess: u32 = match guess.trim().parse() {Ok(num) => num,Err(_) => continue,};match guess.cmp(&secret){Ordering::Less => println!("Too small."),Ordering::Greater => println!("Too large."),Ordering::Equal => { println!("You win."); break;},}}
}
这里要注意,使用上一篇文章中的编译工具网站时需要添加库并在代码中通过extern crate rand手动加载rand库,否则会编译失败。
考虑到效率问题,本文对于上述代码的反汇编以IDA的反汇编结果为主,汇编代码分析为辅。

line 1
第一行中thread_rng方法返回ThreadRng实例,也就是使用于单个线程的随机数产生器实例,随后将其作为参数1(即self),参数2和参数3分别为范围的下界和上界。通过汇编代码可以发现,Range这个对象需要两个寄存器传递。通过查看Rust官方库源码也可以发现,Range实际上也就只有开始和结尾这两个属性值:
pub struct Range<Idx> {/// The lower bound of the range (inclusive).#[stable(feature = "rust1", since = "1.0.0")]pub start: Idx,/// The upper bound of the range (exclusive).#[stable(feature = "rust1", since = "1.0.0")]pub end: Idx,
}
gen_range方法以常规的方式使用rax返回了生成的随机数值。
随后,一个drop_in_place直接删除了ThreadRng实例,可见Rust对于生命周期的管理非常严格,后续代码已经没有使用ThreadRng实例的代码,因此Rust直接就将其删除了,尽最大可能减少对象重用与悬垂指针引用的可能。
loop
在Rust的反汇编界面中,continue很少见到,因为对于一个循环而言,其内部很有可能存在生命周期在循环之内的对象,因此即使Rust代码中写continue,Rust也需要首先将循环中创建的对象删除之后再开始新一轮循环。这也就导致IDA的反汇编界面中可能会出现很多goto。
line 3~7
println!的特征很好识别,Arguments::new_v1和_print一出,就知道肯定又是一次输出,不过输出的具体字符串内容直接查看反汇编界面无法确定,不过在汇编代码中也很好找。随后的String::new等也非常正常。
match
上述代码一共有两个match语句,第一个是将字符串parse的结果进行判断,替换了上一篇文章中的expect。这里parse函数的返回值是一个枚举对象Result<F, F::Err>。我们知道Rust的枚举对象是一个很强大的结构,比C/C++中的枚举对象好用很多,这是因为Rust的枚举对象可以理解成一个Key有限且确定的Map,选择一个Key之后还能够根据Key指定的数据类型自由设置Value。在这里我们不妨研究一下,Rust中的枚举对象是如何组织的。
0x02. Reverse for enum
下面通过一个简单的程序对枚举类型进行逆向分析。
#[derive(Debug)]
pub enum Student {Freshman(String),Sophomore(String),Junior(String),Senior(String),
}pub fn get_student(grade: i32, name: String) -> Option<Student> {match grade {1 => Some(Student::Freshman(name)),2 => Some(Student::Sophomore(name)),3 => Some(Student::Junior(name)),4 => Some(Student::Senior(name)),_ => None}
}pub fn main() {let x = get_student(4, "CoLin".to_string()).unwrap();println!("{:?}", x);
}
上述代码定义了一个枚举类型。首先来看get_student方法:

可以看到,在反汇编界面中,IDA将match语句识别为switch语句,通过汇编代码的分析也能够很容易地发现跳表的存在。

通过查看main函数的方法调用,可以获得get_student方法的参数分别为:Student对象指针、grade参数、name参数。在switch语句中,我们发现每一个分支都有大量的值传送指令,含义未知,但我们可以通过函数调用前后获取到枚举类型的大小与内容。

经过分析,获取到了枚举对象的内容如上图所示。从函数内容等处可以推断出,枚举对象的第一个值3表示的是枚举对象grade的关键字索引,这里由于返回的是Student::Senior,索引为3,也即枚举对象中的4个索引值对应了0、1、2、3这4个索引值。后面还有3个值,其中有字符串指针和字符串长度,经过测试发现,String对象占0x18大小内存,偏移0x8为字符串指针,偏移0和0x10均为字符串长度。
之后,笔者修改了Student枚举类型的定义,在每一项后面加上了一个i32,经过调试发现枚举类型的属性偏移如下:
0x0 枚举索引
0x4 i32
0x8~0x20 String
位于后面的i32类型反而在内存中更加靠前了。笔者推测这可能与Rust对tuple的内存排布有关,考虑到枚举索引很少有超过1个字节(不然就意味着有超过255个分支),使用后面4个字节能节省一定的内存空间。不过无论tuple是如何排布的,Rust的枚举类型在内存中的布局现在已经很清楚了,就是索引值+内容。
不过既然都已经看到了tuple的不寻常,接下来不妨也对其进行一番研究。
0x03. Reverse for Tuple
下面将尝试通过数个Tuple的反编译结果分析Tuple的内存布局。众所周知,Tuple就是若干个数据的集合,这些数据之间没有什么明确的关联,只有一个Tuple将它们约束在一个集合中。
pub fn main() {let x = (2, 3, 5, 7, 11, String::new());
}
对于上述代码逆向的结果如下:
example::main:sub rsp, 72lea rdi, [rsp + 48]call alloc::string::String::newmov dword ptr [rsp], 2mov dword ptr [rsp + 4], 3mov dword ptr [rsp + 8], 5mov dword ptr [rsp + 12], 7mov dword ptr [rsp + 16], 11mov rax, qword ptr [rsp + 48]mov qword ptr [rsp + 24], raxmov rax, qword ptr [rsp + 56]mov qword ptr [rsp + 32], raxmov rax, qword ptr [rsp + 64]mov qword ptr [rsp + 40], raxmov rdi, rspcall qword ptr [rip + core::ptr::drop_in_place<(i32,i32,i32,i32,i32,alloc::string::String)>@GOTPCREL]add rsp, 72ret
从相对于rsp的偏移量可以看出Tuple的排布情况,上述Tuple的内存排布顺序与数据的定义顺序相同。
但对于下面一个Tuple而言就不同了:
pub fn main() {let x = (2, 3, 5, 7, 11, String::new(), "CoLin");
}
逆向的结果为:
example::main:sub rsp, 88lea rdi, [rsp + 64]call alloc::string::String::newmov dword ptr [rsp + 24], 2mov dword ptr [rsp + 28], 3mov dword ptr [rsp + 32], 5mov dword ptr [rsp + 36], 7mov dword ptr [rsp + 40], 11mov rax, qword ptr [rsp + 64]mov qword ptr [rsp], raxmov rax, qword ptr [rsp + 72]mov qword ptr [rsp + 8], raxmov rax, qword ptr [rsp + 80]mov qword ptr [rsp + 16], raxlea rax, [rip + .L__unnamed_1]mov qword ptr [rsp + 48], raxmov qword ptr [rsp + 56], 5mov rdi, rspcall qword ptr [rip + core::ptr::drop_in_place<(i32,i32,i32,i32,i32,alloc::string::String,&str)>@GOTPCREL]add rsp, 88ret
可以看到,这里是将String::new()产生的String实例放在了开头,随后才是5个i32,最后是&str。至于为什么要这样排列,询问了一个Rust大手子之后,给到的答案是:Rust数据结构和内存排布没有必然关联,Rust编译器可能根据不同的架构进行相应的内存结构调整,说人话就是——不能预判,不是必然顺序排列。不过考虑到对于Tuple的遍历、索引等操作在代码中都是固定的,编译器在编译的时候完全可以将地址偏移与索引值一一对应,不影响正常的索引,但对于反编译则是一个巨大的噩梦,因为你不确定某个索引值的数据到底有多少偏移。另外,如何通过汇编代码对栈空间的布局判断是否存在一个tuple也是一个问题。在定义变量时,一个tuple完全可以拆分为多个变量进行定义,反正在汇编代码中也不会保存临时变量的变量名。这在内存中会表现出来不同吗?
我们还是通过实际验证来解答我们的问题。
pub fn main() {let x = (2, 3, 5, 7, 11, 13);println!("{}", x.0);
}
pub fn main() {let x = 2;let y = 3;let z = 5;let a = 7;let b = 11;let c = 13;println!("{}{}{}{}{}{}", x, y, z, a, b, c);
}
给出上面的两个Rust函数,通过查看6个整数值在内存中的排布可以发现,两者对于6个整数值都是按相同顺序进行排列,从低地址到高地址依次为2、3、5、7、11、13。不过在编译过程中发现,只有当变量被使用时,Rust编译器才会将这个变量编译到ELF中,否则这个变量将不会出现在ELF中。也就是说,我们不能仅仅通过栈内存排布判断源代码中是否定义了Tuple。不过转念一想,这样其实是合理的。Tuple实际上就相当于是一个匿名的结构体实例,想一想C语言中的结构体,实际上也就是将一堆各种类型的数据集合在一起,使用相邻的内存空间保存各个属性而已。定义一个具有两个int类型的C语言结构体,将其在栈内存中分配一个实例空间,与在栈内存中分配两个int类型的变量,在本质上是完全相同的。
因此,我们在对Rust ELF进行逆向分析时,不必纠结源码的编写者是否定义了元组,全部将其看做独立的变量就可以了。
0x04. Guess a number .part 2
好不容易说完了对Rust枚举类型和元组的逆向,接下来让我们回到最开始的那个程序,说到两个match语句。
对于第一个match语句,match的对象是一个枚举类型,在match语句体之内实际上是按照枚举类型进行分支。在汇编语句中,Rust是这样完成分支的:

注意0xCEAC处的指令:mov al, byte ptr [rsp+1D8h+var_C0],第二个操作数是parse方法的返回值,也就是Result<F, F::Err>。考虑到这里的F是u32类型,整个枚举类型占用的空间大小为8字节,因此rax返回的直接就是对象本身的内容(0x??_0000_0000)。第1个字节为枚举索引值,后4个字节为转换后的值。在0xCEAC地址的这条指令将第1个字节赋值给al后进行了比较(cmp rax, 0),这也就是分支的具体实现方法——提取出枚举类型的索引值,根据索引值进行分支。

对于后面cmp方法返回值的match与之类似,本质上使用的也是if-else结构,主要是因为分支数量较少,没有必要使用跳转表,分支逻辑如上图所示。不过不同的是,第一个分支是判断枚举对象索引值是否等于0xFF,即-1。经过调试发现,Ordering::Less对应的枚举索引为-1,Ordering::Greater对应1,Ordering::Equal对应0。而对于每个分支,都只是一个简单的输出语句,这里就不再分析了。
0x05. 总结
在本文中,我们学习了:
- Rust的枚举类型在汇编代码层的数据结构实现。
- Rust的元组Tuple类型在汇编代码层无法被有效识别,但可将其看做多个独立变量进行分析。
- 三个
Ordering枚举对象的索引值为-1、0、1,与一般枚举对象索引值从0开始不同。 - Rust倾向于当变量不再使用时就删除变量对象,以尽可能地提高安全性。
- Rust的元组类型在汇编代码层栈空间的数据排列顺序与元组类型中数据的定义顺序不一定相同。
相关文章:
Rust逆向学习 (2)
文章目录 Guess a number0x01. Guess a number .part 1line 1loopline 3~7match 0x02. Reverse for enum0x03. Reverse for Tuple0x04. Guess a number .part 20x05. 总结 在上一篇文章中,我们比较完美地完成了第一次Rust ELF的逆向工作,但第一次编写的R…...
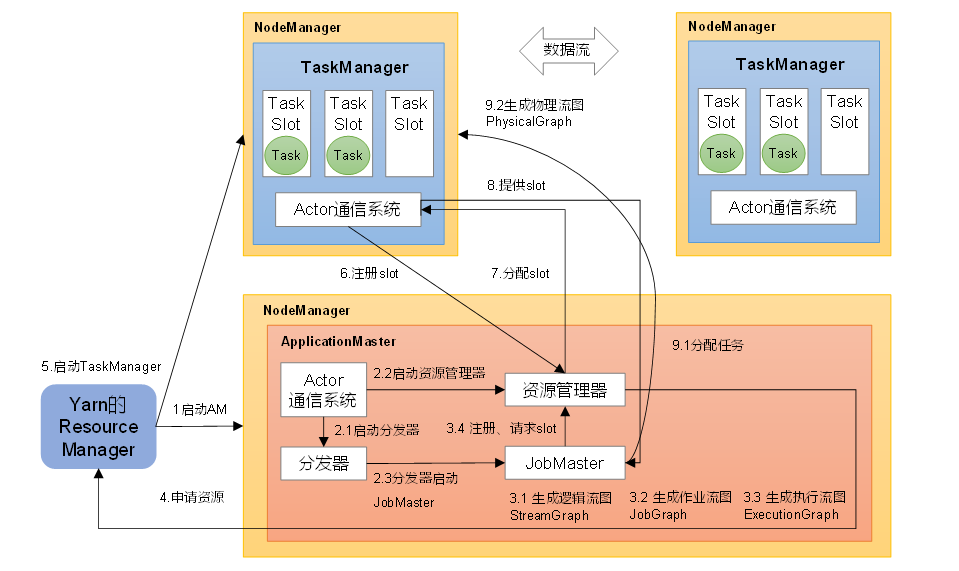
Flink部署模式及核心概念
一.部署模式 1.1会话模式(Session Mode) 需要先启动一个 Flink 集群,保持一个会话,所有提交的作业都会运行在此集群上,且启动时所需的资源以确定,无法更改,所以所有已提交的作业都会竞争集群中…...
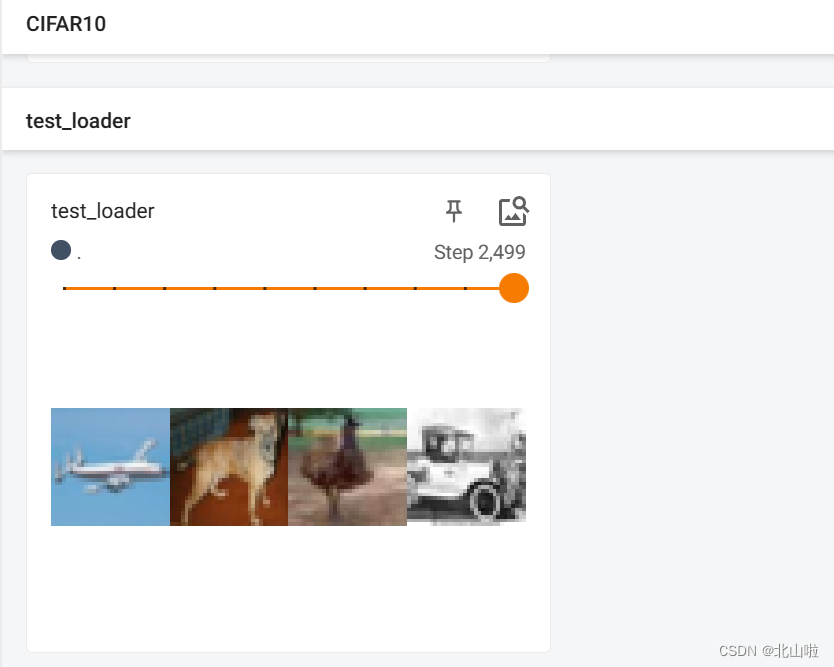
Pytorch公共数据集、tensorboard、DataLoader使用
本文将主要介绍torchvision.datasets的使用,并以CIFAR-10为例进行介绍,对可视化工具tensorboard进行介绍,包括安装,使用,可视化过程等,最后介绍DataLoader的使用。希望对你有帮助 Pytorch公共数据集 torc…...
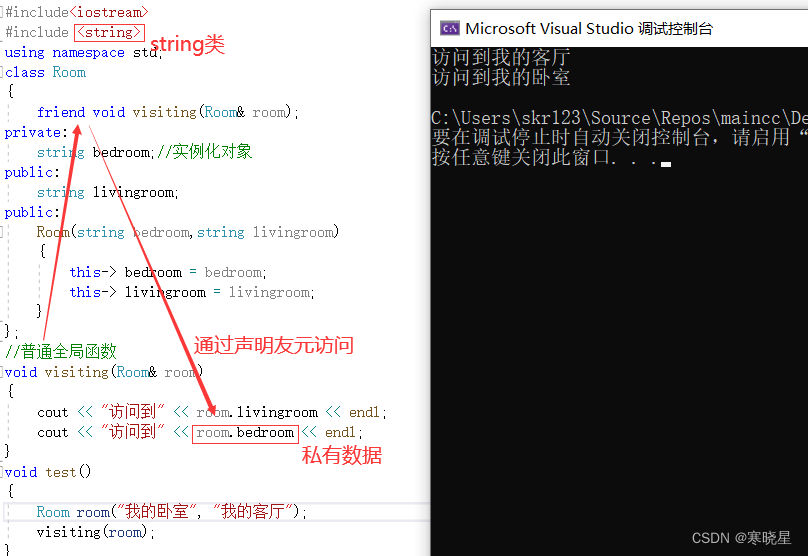
【第三天】C++类和对象进阶指南:从堆区空间操作到友元的深度掌握
一、new和delete 堆区空间操作 1、new和delete操作基本类型的空间 new与C语言中malloc、delete和C语言中free 作用基本相同 区别: new 不用强制类型转换 new在申请空间的时候可以 初始化空间内容 2、 new申请基本类型的数组 3、new和delete操作类的空间 4、new申请…...
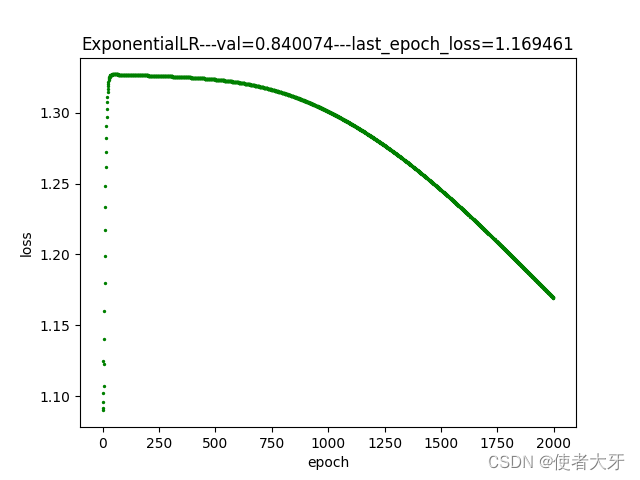
【PyTorch实战演练】自调整学习率实例应用(附代码)
目录 0. 前言 1. 自调整学习率的常用方法 1.1 ExponentialLR 指数衰减方法 1.2 CosineAnnealingLR 余弦退火方法 1.3 ChainedScheduler 链式方法 2. 实例说明 3. 结果说明 3.1 余弦退火法训练过程 3.2 指数衰减法训练过程 3.3 恒定学习率训练过程 3.4 结果解读 4. …...
app拉新渠道整合 一手地推、网推拉新平台整理
1.聚量推客 聚量推客自己本身是服务商,自己直营的平台,相对来说数据更好,我们也拿到了平台首码:000000 填这个就行,属于官方渠道 2.蓝猫推客 蓝猫推客我认为是比较又潜力的平台,经过几天测试数据和结算都…...

十六进制IP转换点分十进制代码
以下是一个可以实现将输入的十六进制格式的IP地址转换为点分十进制格式并输出的简单程序。它使用了 sscanf 函数将输入的字符串解析成无符号整数,然后使用 inet_ntoa 函数将其转换成点分十进制格式,并打印输出: #include <stdio.h> #i…...

面试官的一句话,让五年功能测试老手彻夜难眠!
小王是一名软件测试工程师,已经在目前的公司做了四五年的功能测试。虽然一直表现得非常努力,但他还是没能躲过裁员。只能被动跳槽,寻找更好的职业机会。 然而事情并没有像他想象中那样顺利。在多次面试中小王屡屡碰壁,被面试官吐槽…...
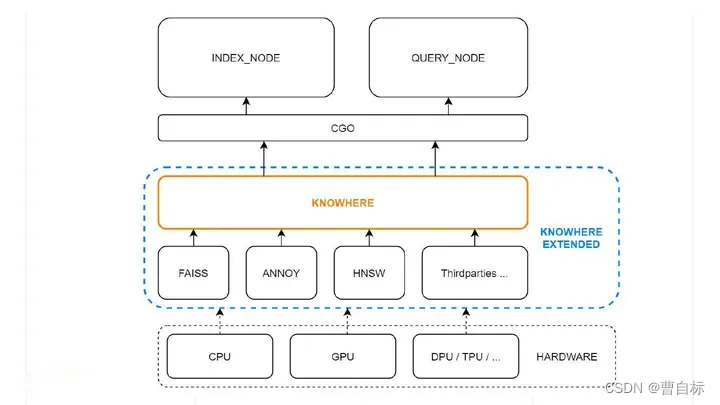
向量检索库Milvus架构及数据处理流程
文章目录 背景milvus想做的事milvus之前——向量检索的一些基础近似算法欧式距离余弦距离 常见向量索引1) FLAT2) Hash based3) Tree based4) 基于聚类的倒排5) NSW(Navigable Small World)图 向…...
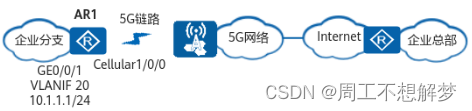
【华为路由器】配置企业通过5G链路接入Internet示例
场景介绍 5G Cellular接口是路由器用来实现5G技术的物理接口,它为用户提供了企业级的无线广域网接入服务,主要用于eMBB场景。与LTE相比,5G系统可以为企业用户提供更大带宽的无线广域接入服务。 路由器的5G功能,可以实现企业分支…...
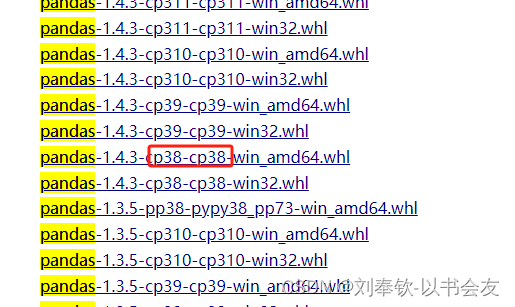
python安装.whl文件
python --version https://www.lfd.uci.edu/~gohlke/pythonlibs/ 用CtrlF找需要安装的包 下载对应版本的whl python3.8 把下载好的whl放到安装路径下:C:\Users\Administrator\AppData\Local\Programs\Python\Python38\Lib\site-packages 并在该路径下打开cmd执行…...
详解)
Java方法调用动态绑定(多态性)详解
CONTENTS 1. 方法调用绑定2. 尝试重写Private方法3. 字段访问与静态方法的多态4. 构造器内部的多态方法行为 1. 方法调用绑定 我们首先来看下面这个例子: package com.yyj;enum Tone {LOW, MIDDLE, HIGH; }class Instrument {public void play(Tone t) {System.ou…...
【SwiftUI模块】0060、SwiftUI基于Firebase搭建一个类似InstagramApp 2/7部分-搭建TabBar
SwiftUI模块系列 - 已更新60篇 SwiftUI项目 - 已更新5个项目 往期Demo源码下载 技术:SwiftUI、SwiftUI4.0、Instagram、Firebase 运行环境: SwiftUI4.0 Xcode14 MacOS12.6 iPhone Simulator iPhone 14 Pro Max SwiftUI基于Firebase搭建一个类似InstagramApp 2/7部分-搭建Tab…...

代码随想录第50天 | 84.柱状图中最大的矩形
84.柱状图中最大的矩形 //双指针 js中运行速度最快 var largestRectangleArea function(heights) {const len heights.length;const minLeftIndex new Array(len);const maxRigthIndex new Array(len);// 记录每个柱子 左边第一个小于该柱子的下标minLeftIndex[0] -1; //…...
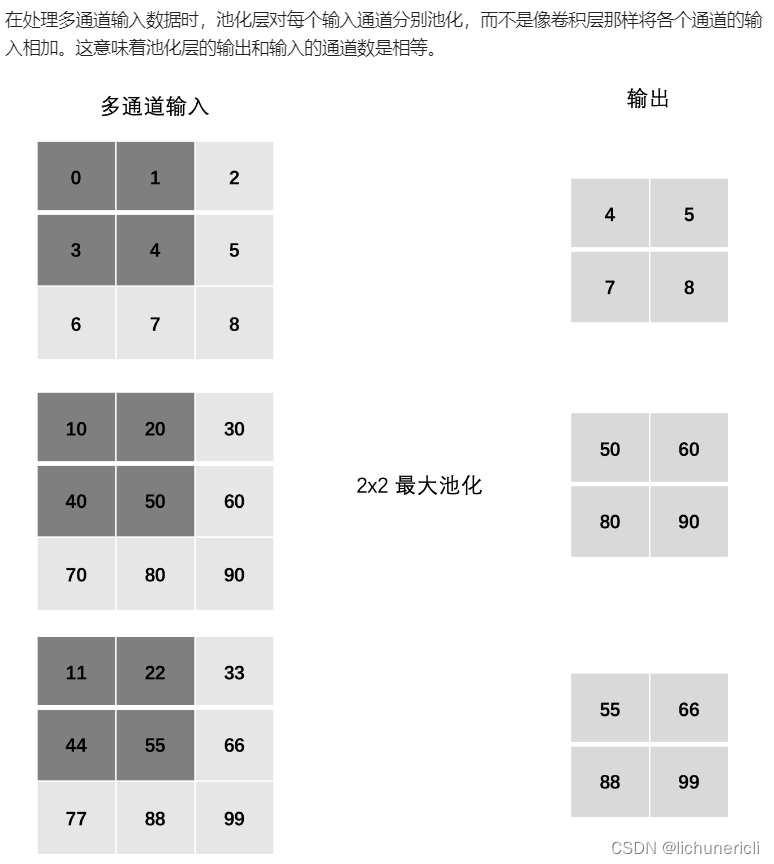
深度学习---卷积神经网络
卷积神经网络概述 卷积神经网络是深度学习在计算机视觉领域的突破性成果。在计算机视觉领域。往往输入的图像都很大,使用全连接网络的话,计算的代价较高。另外图像也很难保留原有的特征,导致图像处理的准确率不高。 卷积神经网络࿰…...
Windows系统下安装CouchDB3.3.2教程
安装 前往CouchDB官网 官网点击download下载msi文件 双击该msi文件,一直下一步 创建个人account 设置cookie value 用于进行身份验证和授权。 愉快下载 点击OK 重启 启动 重启电脑后 打开浏览器并访问以下链接:http://127.0.0.1:5984/ 如果没有问…...

JavaScript基础知识(二)
JavaScript基础知识(二) 一、ES2015 基础语法1.变量2.常量3.模板字符串4.结构赋值 二、函数进阶1. 设置默认参数值2. 立即执行函数3. 闭包4. 箭头函数 三、面向对象1. 面向对象概述2. 基本概念3. 新语法 与 旧语法3.1 ES5 面向对象的知识ES5构造函数原型…...
)
SQL NULL Values(空值)
什么是SQL NULL值? SQL 中,NULL 用于表示缺失的值。数据表中的 NULL 值表示该值所处的字段为空。 具有NULL值的字段是没有值的字段。 如果表中的字段是可选的,则可以插入新记录或更新记录而不向该字段添加值。然后,该字段将被保存…...
云原生Docker网络管理
目录 Docker网络 Docker 网络实现原理 为容器创建端口映射 查看容器的输出和日志信息 Docker 的网络模式 查看docker网络列表 指定容器网络模式 网络模式详解 host模式 container模式 none模式 bridge模式 自定义网络 Docker网络 Docker 网络实现原理 Docker使用Lin…...

聊聊线程池的预热
序 本文主要研究一下线程池的预热 prestartCoreThread java/util/concurrent/ThreadPoolExecutor.java /*** Starts a core thread, causing it to idly wait for work. This* overrides the default policy of starting core threads only when* new tasks are executed. T…...

Oracle B-Tree 索引结构与内部机制详解
在技术领域,我们常常被那些闪耀的、可见的成果所吸引。今天,这个焦点无疑是大语言模型技术。它们的流畅对话、惊人的创造力,让我们得以一窥未来的轮廓。然而,作为在企业一线构建、部署和维护复杂系统的实践者,我们深知…...

JAX GPU版安装实战:从cuSPARSE报错到完美运行的完整记录
JAX GPU版深度调优指南:从cuSPARSE报错到高效计算的完整解决方案 在深度学习和高性能计算领域,JAX凭借其自动微分和XLA加速能力已成为研究人员和工程师的重要工具。然而,当我们在GPU环境中部署JAX时,经常会遇到各种库依赖和版本冲…...

从‘乐学小鹅’到‘com.tencent.k12gy’:一次Frida注入失败带给我的Android应用‘身份证’认知升级
从应用显示名到包名:一次Frida注入失败引发的Android应用标识深度思考 那天下午,我盯着终端里刺眼的红色错误信息,手指悬在键盘上方迟迟没有动作。Failed to spawn: unable to find application with identifier 乐学小鹅——这个看似简单的报…...

一季度收官,AI在交通运输行业表现如何?
公路、铁路、航空、水运,共同构成了这个国家的交通网络。货物经由港口中转,旅客借助铁路和航空流动,城市依靠道路交通维持日常运转。这张网络每天承载着数以亿计的出行和运输需求,任何一个环节的效率与安全,都会影响整…...
)
手把手教你用Python的ObsPy库计算地震P波到时(附完整代码与避坑指南)
零基础实战:用Python的ObsPy库精准计算地震P波到时 地震数据分析中,P波到时的准确计算是定位震源和研究地下结构的基础。对于地球物理专业的学生和工程师来说,掌握这项技能能大幅提升工作效率。本文将带你从零开始,用Python的ObsP…...

软件发布管理化的版本规划与交付验证
软件发布管理中的版本规划与交付验证:高效落地的关键 在快速迭代的软件开发领域,版本规划与交付验证是确保产品高质量交付的核心环节。通过系统化的管理,团队能够明确目标、控制风险,并实现从开发到部署的无缝衔接。本文将围绕版…...

.NET 诊断技巧 | 日志框架原理、手写日志框架学习鹊
一、 什么是 AI Skills:从工具级到框架级的演化 AI Skills(AI 技能) 的概念最早在 Claude Code 等前沿 Agent 实践中被强化。最初,Skills 被视为“工具级”的增强,如简单的文件读写或终端操作,方便用户快速…...
)
银行报表填报避坑指南:G01-G04最新版本差异解析(2023更新)
银行报表填报避坑指南:G01-G04最新版本差异解析(2023更新) 银行报表填报工作向来是金融从业者的必修课,尤其是G01-G04系列报表作为监管报送的核心内容,其版本更新往往牵动着整个机构的神经。去年底至今,监管…...

【ESP32-S3】智能小车中的编码电机PID调整技巧
【ESP32-S3】智能小车中的编码电机PID调整技巧PID 微调参数对照表推荐调试顺序(最安全)常用成品参数PID 微调参数对照表 参数作用太大表现太小表现建议起始值合理范围调整方向Kp 比例反应快慢、跟紧目标速度电机抖、嗡嗡响、抽搐、振荡反应慢、无力、速…...

Verilog新手避坑指南:用Icarus Verilog写Testbench时,$dumpfile和$dumpvars这两行到底有什么用?
Verilog仿真核心机制解析:$dumpfile与$dumpvars的底层逻辑与实战技巧 刚接触Verilog仿真的开发者,往往会在Testbench中看到这两行神秘的代码: $dumpfile("waveform.vcd"); $dumpvars(0, top_module);它们像黑魔法咒语一样被复制粘贴…...