sql高级教程-索引
文章目录
- 架构简介
- 1.连接层
- 2.服务层
- 3.引擎层
- 4.存储层
- 索引优化
- 背景
- 目的
- 劣势
- 分类
- 基本语法
- 索引结构和适用场景
- 性能分析
- MySq| Query Optimizer
- explain
- 索引优化
- 单表优化
- 两表优化
- 三表优化
- 索引失效
- 原因
架构简介

1.连接层
最上层是一些客户端和连接服务,包含本地sock通信和大多数基于客户端/服务端工具实现的类似于tcp/ip的通信。主要完成一些类似于连接处理、授权认证、及相关的安全方案。在该层上引入了线程池的概念,为通过认证安全接入的客户端提供线程。同样在该层上可以实现基于SSL的安全链接。服务器也会为安全接入的每个客户端验证它所具有的操作权限。
2.服务层
第二层架构主要完成大多少的核心服务功能,如SQL接口,并完成缓存的查询,SQL的分析和优化及部分内置函数的执行。所有跨存储引擎的功能也在这一层实现,如过程、函数等。在该层,服务器会解析查询并创建相应的内部解析树,并对其完成相应的优化如确定查询表的顺序,是否利用索引等,最后生成相应的执行操作。如果是select语句,服务器还会查询内部的缓存。如果缓存空间足够大,这样在解决大量读操作的环境中能够很好的提升系统的性能。
3.引擎层
存储引擎层,存储引擎真正的负责了MySQL中数据的存储和提取,服务器通过API与存储引擎进行通信。不同的存储引擎具有的功能不同,这样我们可以根据自己的实际需要进行选取。后面介绍MyISAM和InnoDB。
插件式的存储引擎架构将查询处理和其它的系统任务以及数据的存储提取相分离。这种架构可以根据业务的需求和实际需要选择合适的存储引擎。
4.存储层
数据存储层,主要是将数据存储在运行子裸设备的文件系统之上,并完成与存储引擎的交互。
索引优化
背景
性能下降SQL语句运行慢,导致执行时间和等待时间长,可能原因是如下四方面:查询语句写的烂,索引失效(单值,复合),关联查询太多join(设计缺陷或不得已的需求),服务器调优及各个参数设置(缓冲、线程数等)。
SQL机器读取顺序:

目的
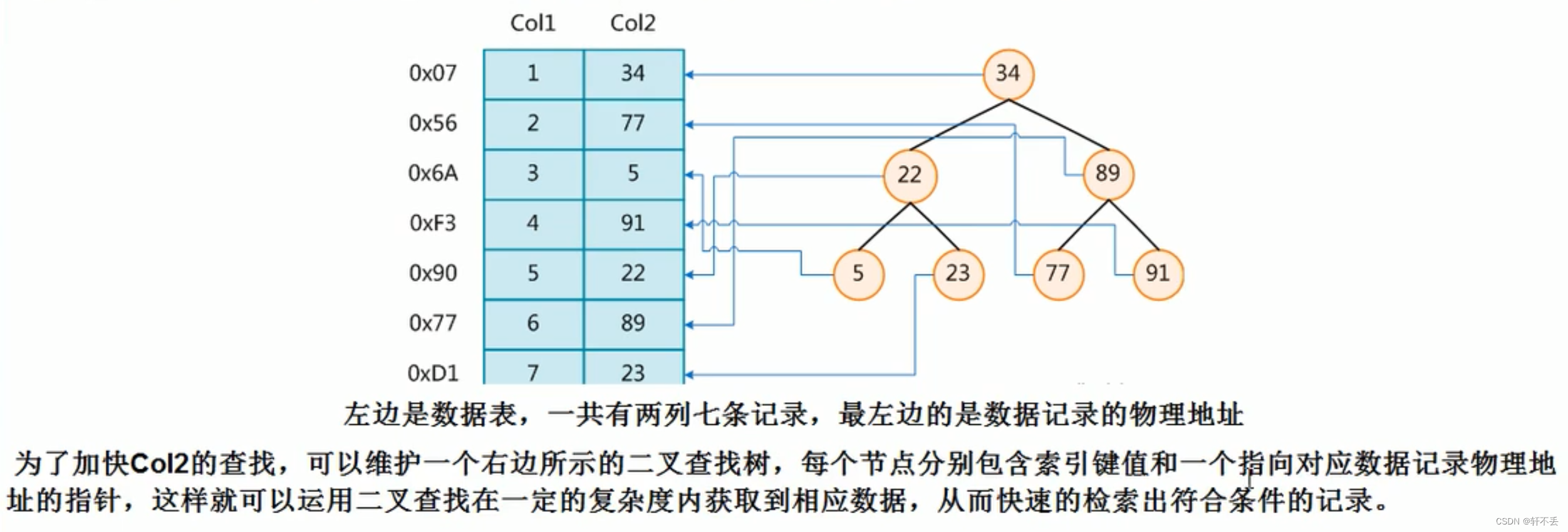
索引是一种数据结构,用于提高数据库查询操作的效率。MySQL使用B树或哈希索引来实现索引功能。(本质上就是某种数据结构)
索引的作用是通过创建一个快速访问的路径,使得数据库可以更快地找到满足特定条件的记录。当我们在数据库表的某个列上创建索引时,数据库系统会按照这个索引的顺序存储数据并建立索引关系。这样,在查询时,数据库就可以直接跳过不符合条件的记录,快速定位到需要的数据。
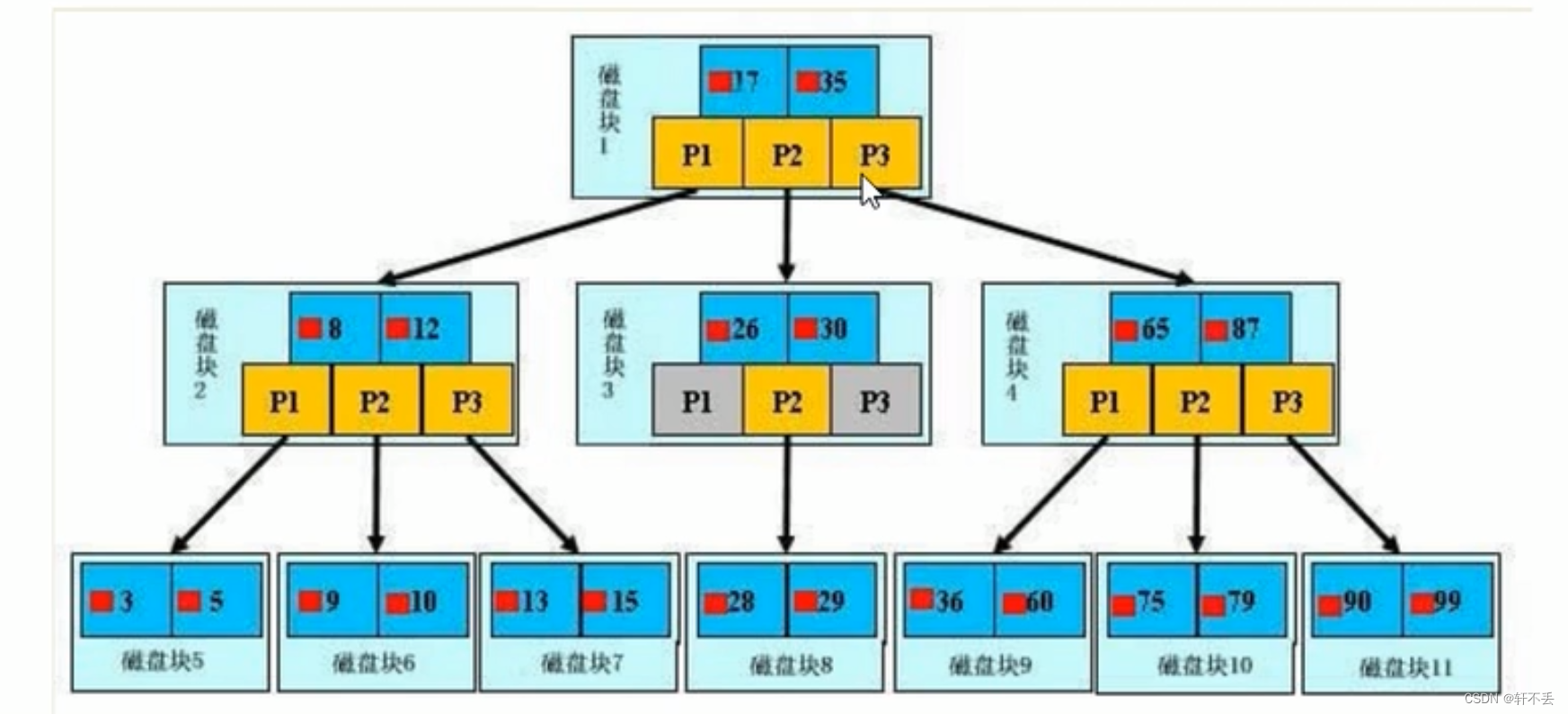
真实的情况是,3层的b+树可以表示上百万的数据,如果上百万的数据查找只需要三次I0,性能提高将是巨大的,如果没有索引,每个数据项都要发生一次I0,那么总共需要百万次的I0, 显然成本非常非常高。
索引的创建可以根据需求选择单列索引或多列索引。单列索引是基于单个列的值创建的,而多列索引是基于多个列的组合值创建的。在选择创建索引时,需要权衡查询效率和写入性能之间的关系。
需要注意的是,虽然索引可以提高查询性能,但也会增加插入、删除和更新操作的时间。因此,在创建索引时需要考虑到数据库的读写比例,并且避免过度索引导致性能下降。
总而言之,索引是用于加快数据库查询操作的重要工具,可以提高数据库的性能。但在使用索引时需要谨慎权衡索引的创建和使用,以获得最佳的查询性能。
一般来说索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储的磁盘上
示例:小顶堆
劣势
实际上索引也是- -张表,该表保存了主键与索引字段,并指向实体表的记录,所以索引列也是要占用空间的
虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT. UPDATE和DELETE。因为更新表时,MySQL不仅 要保存数据,还要保存下索引文件每次更新添加了索引列的字段,都会调整因为更新所带来的键值变化后的索引信息。
索引只是提高效率的一个因素,如果你的MySQL有大数据量的表,就需要花时间研究建立最优秀的索引。
分类
单值索引:即一个索引只包含单个列,-一个表可以有多个单列索引。
单值索引只能保证索引项的唯一性,而不是列中的值的唯一性。在列中可以有重复的值,但每个值只能对应一个索引项。(一般不超过5个)
唯一索引:索引列的值必须唯一,但允许有空值.
复合索引:一个索引有多列。
其他概念:覆盖索引
理解方式一:就是select的数据列只用从索引中就能够取得,不必读取数据行,MySQL可以利用索引返回select列表中的字段,而不必根据索引再次读取数据文件换句话说查询列要被所建的索引覆盖。
理解方式二:索引是高效找到行的-一个方法,但是- -般数据库也能使用索引找到一个列的数据,因此它不必读取整个行。毕竟索引叶子节点存储了它们索引的数据;当能通过读取索引就可以得到想要的数据,那就不需要读取行了。一个索引包含了(或覆盖了)满足查询结果的数据就叫做覆盖索引。
基本语法
1、创建CREATE [UNIQUE ][Cluster] INDEX indexName ON mytable(columnname(length));ALTER Table 表名 ADD [UNIQUE ] INDEX [indexName] ON (columnname(length))PS1:CLUSTER关键字用于指定一个表的物理存储顺序,也称为聚集(cluster)。通过聚集,可以将具有相似数据的行存储在物理上紧密相邻的位置,以提高查询性能。在大多数关系型数据库管理系统(RDBMS)中,一个表通常只能建立一个聚集索引(Clustered Index)。聚集索引对表中的行进行物理存储上的排序,并决定了数据在磁盘上的存储顺序。聚集索引决定了数据在磁盘上的物理排序方式,因此一个表只能根据一个列或列组合进行排序。PS2:在索引时还可以排序:Create Unique Index Scno ON SC(Sno ASC,Cno DESC)
2、删除:DROP INDEX [indexName] ON mytable;
3、查看:SHOW INDEX FROM table_ name\G#案例:ALTER TABLE tb_ name ADD PRIMARY KEY (column_ list): 该语句添加一个主键,这意味着索引值必须是唯一的,且不能为NULL.(主键这个约束就是索引)ALTER TABLE tb_ name ADD UNIQUE index_ name (column_ list): 这条语句创建索引的值必须是唯一的 (除了NULL外,NULL可能会出现多次)。(唯一键这个约束也是索引)ALTER TABLE tb_ name ADD INDEX index_ name (column_ list): 添加普通索引,索引值可出现多次。ALTER TABLE tbl _name ADD FULLEXT index_ name (column_ lst):该语 句指定了索引为FLLTEXT,用于全文索引。
索引结构和适用场景
结构:BTree索引,Hash索引,full-text全文索引|,R-Tree索引
场景:
1、主键自动建立唯-一索引
2、频繁作为查询条件的字段应该创建索引
3、查询中与其它表关联的字段,外键关系建立索引
4、表记录过少or频繁更新的字段不适合创建索引,因为每次更新不单单是更新了记录还会更新索引
5、注意,如果某个数据列包含许多重复的内容,为它建立索引就没有太大的实际效果。(查找结果太多)
5、Where条件里用不到的字段不创建索引
6、单键/组合索引的选择问题, (在高并发下倾向创建组合索引)
7、查询中排序的字段,排序字段若通过索引去访问将大提高排序速度
8、查询中统计或者分组字段
性能分析
MySq| Query Optimizer
MysqI专门负责优化SELECT语句的优化器模块,主要功能:通过计算分析系统中收集到的统计信息,为客户端请求的Query提供他认为最优的执行计划(他认为最优的数据检索方式,但不见得是DBA认为是最优的,这部分最耗费时间)
explain
使用EXPLAIN关键字可以模拟优化器执行SQL查询语句,从而知道MySQL是如何处理你的SQL语句的。分析你的查询语句或表结构的性能瓶颈。

语法:explain+SQL语句。得到信息如上表。末尾加\G可将横板改为竖版。id:id相同,执行顺序按tabler由上至下id不同,如果是子查询,id序号会递增,id值越大优先级越高,越先被执行id相同不同情况同时存在,优先级大的先走,平级顺序执行。id为null表示最后读取select_type:SIMPLE:简单的select查询,查询中不包含子查询或者UNIONPRIMARY:查询中若包含任何复杂的子部分,最外层查询则被标记为SUBQUERY:在SELECT或WHERE列表中包含了子查询DERIUED:在FROM列表中包含的子查询被标记为DERIVED(衍生),MySQL会递归执行这些子查询,把结果放在临时表里。UNION:若第二个SELECT出现在UNION之后,则被标记为UNION;
若UNION包含在FROM子句的子查询中,外层SELECT将被标记为: DERIVEDUNI0N RESULT:从UNION表获取结果的SELECTtable:显示这一行数据是关于哪张表的type:all:全表扫描,性能最差index:Full Index Scan, index与ALL区别为index类型只遍历索引树。这通常比ALL快,因为索引文件通常比数据文件小。(也就是说虽然all和Ihdex都是读全表,但index是从索引中读取的,而all是从硬盘中读的)range:只检索给定范围的行,使用一个索引来选择行。key列显示使用了哪个索引
一般就是在你的where语句中出现了between、<、>、in等的查询。这种范围扫描索引扫描比全表扫描要好,跟为它只需要开始于索引的某一点, 而结束语另一点,不用扫描全部索引。ref:非唯一性索引扫描,返回匹配某个单独值的所有行.本质上也是一种索引访问,它返回所有匹配某个单独值的行,然而,它可能会找到多个符合条件的行,所以他应该属于查找和扫描的混合体eq_ref:唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配。常见于主键或唯一索引扫描const:表示通过索引- .次就找到了,const用于比较primary key或者unique索引。因为只匹配一行数据,所以很快如将主键置于where列表中,MySQL 就能将该查询转换为一一个赏量system:表只有一行记录(等于系统表),这是const类型的特列,平时不会出现,这个也可以忽略不计,几乎不可能优化到这个程度。NULL从最好到最差依次是:system> const>eq ref> ref> range> index> ALLpossible_key:显示可能应用在这张表中的索引,一个或多个。查询涉及到的字段上若存在索引,则该索引将被列出,但不一定被查询实际使用。Key:实际使用的索引。如果为NULL,则没有使用索引。查询中若使用了覆盖索引,则该索引仅出现在key列表中。(即possible_key没有key有)key_len:表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度。在不损失精确性的情况下,长度越短越好。key_ len显示的值为索引字段的最大可能长度,并非实际使用长度,即key_ len是 根据表定义计算而得,不是通过表内检索出的。ref:显示索引的哪一列被使用了,如果可能的话,是一个常数。哪些列或常量被用于查找索引列上的值。row:根据表统计信息及索引选用情况,大致估算出找到所需的记录所需要读取的行数。extra:包含不适合在其他列中显示但十分重要的额外信息Using filesort:说明mysql会对数据使用一个外部的索引排序,而不是按照表内的索引顺序进行读取。MySQL中无法利用索引完成的排序操作称为“文件排序”。(出现这个很危险,性能很差,尽快优化)。Using temporary:使了用临时表保存中间结果,MySQL在对查询结果排序时使用临时表。常见于排序order by和分组查询grqup by。(出现这个更危险,性能很差,尽快优化)。Using index:表示相应的select操作中使用了覆盖索引(Covering Index), 避免访问了表的数据行,效率不错!如果同时出现usingwhere,表明索引被用来执行索引键值的查找;如果没有同时出现usingwhere,表明索引用来读取数据而非执行查找动作。Using where:表示使用了where过滤Using join buffer:表示使用了连接缓存impossible where:where子句的值总是false,不能用来获取任何元组select tables optimized away:在没有GROUPBY子句的情况下,基于索引优化MIN/MAX操作或者对于MyISAM存储引擎优化COUNT(*)操作,不必等到执行阶段再进行计算,查询执行计划生成的阶段即完成优化。distinct:优化distinct操作,在找到第--匹配的元组后即停止找同样值的动作>
总结:优化过程就是不断添加适合的索引,将type变成ref以上,extra不出现Using filesort和Using temporary
索引优化
单表优化
SELECT id,author. id FROM article WHERE category_ id = 1 AND comments > 1 ORDER BY views DESC LIMIT 1;
若是将category_ id,comments和views三者结合作为索引,根据Btree索引工作原理,comments>1作为范围无法利用这个索引进行搜索,因此有范围的不能作为索引,此时只能将category_ id,comments两者结合作为索引。
create index idx_ article _CCV on article(category. id ,views);
两表优化
SELECT * FROM class LEFT JOIN book ON class.card王book.card;
左连接LEFT JOIN条件用于确定如何从右表搜索行,左边一定都有,所以右边是我们的关键点,一定需要根据右表属性建立索引。
ALTER TABLE 'book ADD INDEX Y ( card");
同理右连接需要根据左表建立索引
三表优化
SELECT* FROM class LEFT JOIN book ON class.card=book.card LEFT JOIN phone ON book.card = phone.card;
被连接的两个属性建立索引。
ALTER TABLE 'phone' ADD INDEX z( 'card');
ALTER TABLE 'book' ADD INDEX Y ('card' );
尽可能减少Join语句中的NestedL oop的循环总次数;“ 永远用小结果集驱动大的结果集”。
优先优化NestedLoop的内层循环;
保证Join语句中被驱动表上Join条件字段已经被索引;
当无法保证被驱动表的Join条件字段被索引且内存资源充足的前提下,不要太吝惜JoinBuffer的设置;
索引失效
原因
1、全值匹配
建立索引的属性按顺序都用到了。不会发生失效
2、最佳左前缀法则
如果索引了多列,要遵守最左前缀法则。指的是查询从索引的最左前列开始关且不跳过索引中的列。
eg.若是name,age,pos三个属性建立索引,则select必须包括name属性才能用到此索引。
若只用到name和age,则只有name属性会用到索引,往后都是直接查找。
若是and连接mysql底层会自动转换,可以不按顺序
3、不在索引列上做任何操作(计算、函数、(自动or手动)类型转换),会导致索引失效而转向全表扫描。
4、存储引擎不能使用索引中范围条件右边的列
还是上面的例子,若是age使用判断条件age>25,则后面的pos则不能用到索引。
5、尽量使用覆盖索引(只访问索引的查询(索引列和查询列一致)),减少select *
6、mysql在使用不等于(!=或者<>)的时候无法使用索引会导致全表扫描
7、is null ,is not null也无法使用索引
8、like以通配符开头( %ab…')mysq|索引失效会变成全表扫描的操作
因此%尽量不要放开头。实在要放必须用覆盖索引解决问题,需要查什么字段建立什么索引
9、字符串不加单引号索引失效口
要符合规定的写
10、少用or,用它来连接时会索引失效
相关文章:
sql高级教程-索引
文章目录 架构简介1.连接层2.服务层3.引擎层4.存储层 索引优化背景目的劣势分类基本语法索引结构和适用场景 性能分析MySq| Query Optimizerexplain 索引优化单表优化两表优化三表优化 索引失效原因 架构简介 1.连接层 最上层是一些客户端和连接服务,包含本地sock通…...
拼团小程序制作技巧大揭秘:零基础也能轻松掌握
随着拼团模式的日益流行,越来越多的商家和消费者开始关注拼团小程序的制作。对于没有技术背景的普通人来说,制作一个拼团小程序似乎是一项艰巨的任务。但实际上,选择一个简单易用的第三方平台或工具,可以轻松完成拼团小程序的制作…...

报错:The supplied javaHome seems to be invalid. I cannot find the java executable
AS 升级遇到的问题 问题 升级 Android Studio,碰到无法检测到 java The supplied javaHome seems to be invalid. I cannot find the java executable. Tried location: D:\Program Files\Android\Android Studio\jre\bin\java.exe 然后去网上找解决思路。 终于…...
关于 硬盘
关于 硬盘 1. 机械硬盘1.1 基本概念1.2 工作原理1.3 寻址方式1.4 磁盘磁记录方式 2. 固态硬盘2.1 基本概念2.2 工作原理 1. 机械硬盘 1.1 基本概念 机械硬盘即是传统普通硬盘,硬盘的物理结构一般由磁头与盘片、电动机、主控芯片与排线等部件组成。 所有的数据都是…...
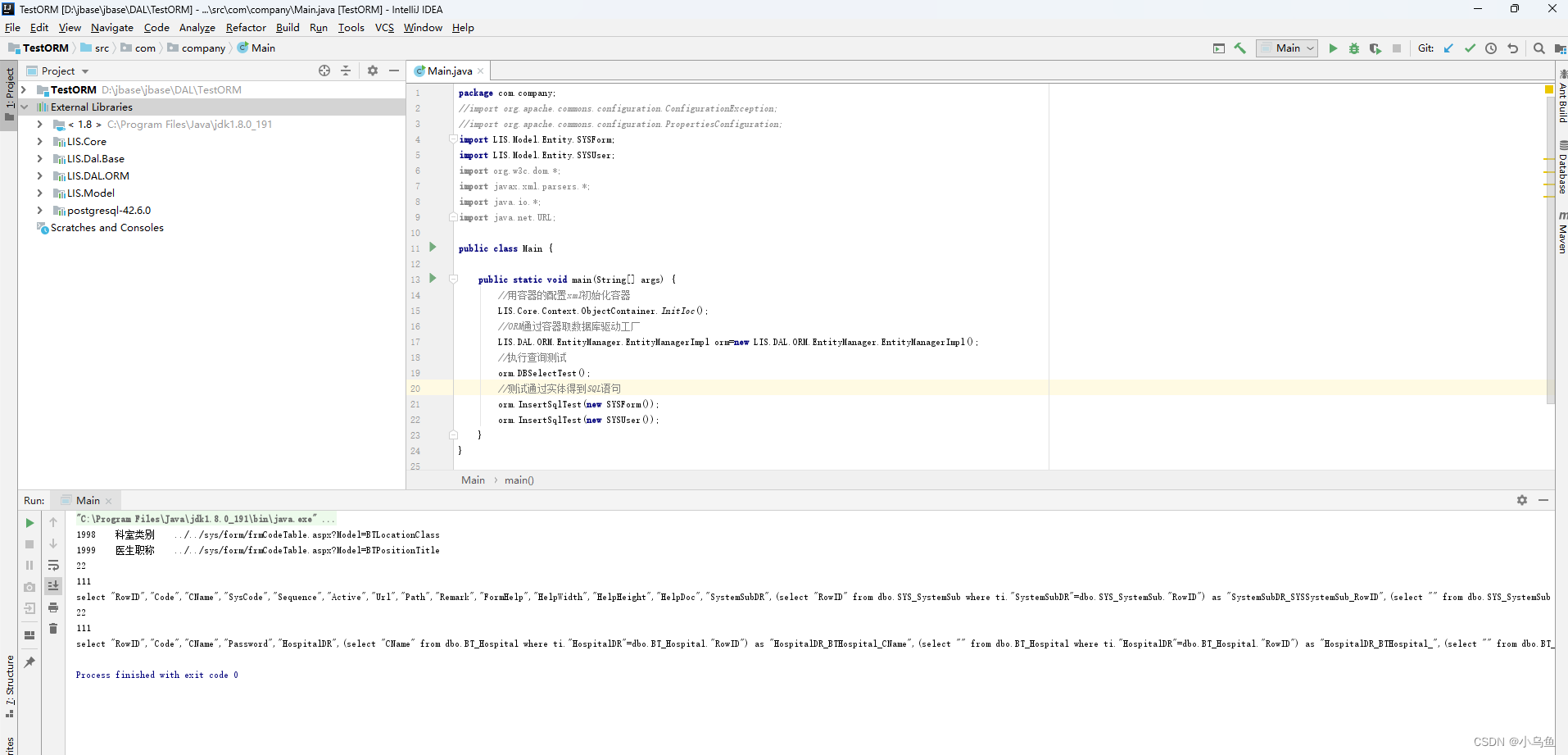
Java反射实体组装SQL
之前在LIS.Core定义了实体特性,在LIS.Model给实体类加了表特性,属性特性,外键特性等。ORM要实现增删改查和查带外键的父表信息就需要解析Model的特性和实体信息组装SQL来供数据库驱动实现增删改查功能。 实现实体得到SQL的工具类,…...

tensorrt安装使用教程
一般的深度学习项目,训练时为了加快速度,会使用多GPU分布式训练。但在部署推理时,为了降低成本,往往使用单个GPU机器甚至嵌入式平台(比如 NVIDIA Jetson)进行部署,部署端也要有与训练时相同的深…...
-- idea(2022版)将 已push 的 远程仓库 的 多条commit记录 进行撤销)
Java后端开发(十)-- idea(2022版)将 已push 的 远程仓库 的 多条commit记录 进行撤销
目录 1.多次 修改Test01类后,提交到本地仓库 。 2.多次重复 1 的步骤,多次commit成功后,在Git =》Log中会显示,commit记录...
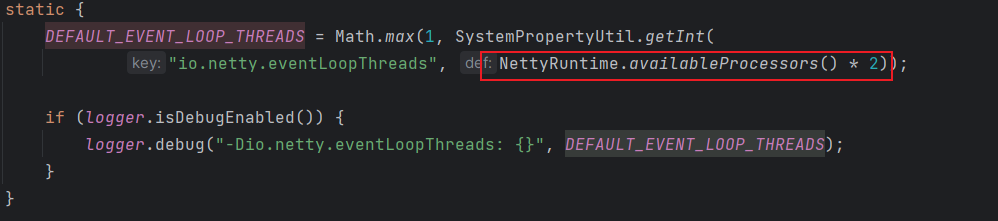
常见面试题-Netty专栏(一)
typora-copy-images-to: imgs Netty 是什么呢?Netty 用于做什么呢? 答: Netty 是一个 NIO 客户服务端框架,可以快速开发网络应用程序,如协议服务端和客户端,极大简化了网络编程,如 TCP 和 UDP …...

【iOS】JSONModel的基本使用
文章目录 前言一、导入JSONModel二、JSONModel的基本使用1.基本用法2.模型集合3.模型导出为NSDictionary或JSON4.设置所有属性可选(所有属性值可以为空)5.下划线(蛇式)转驼峰命名法 前言 JSONModel 是一个用于 Objective-C 的开源库,它用于简…...
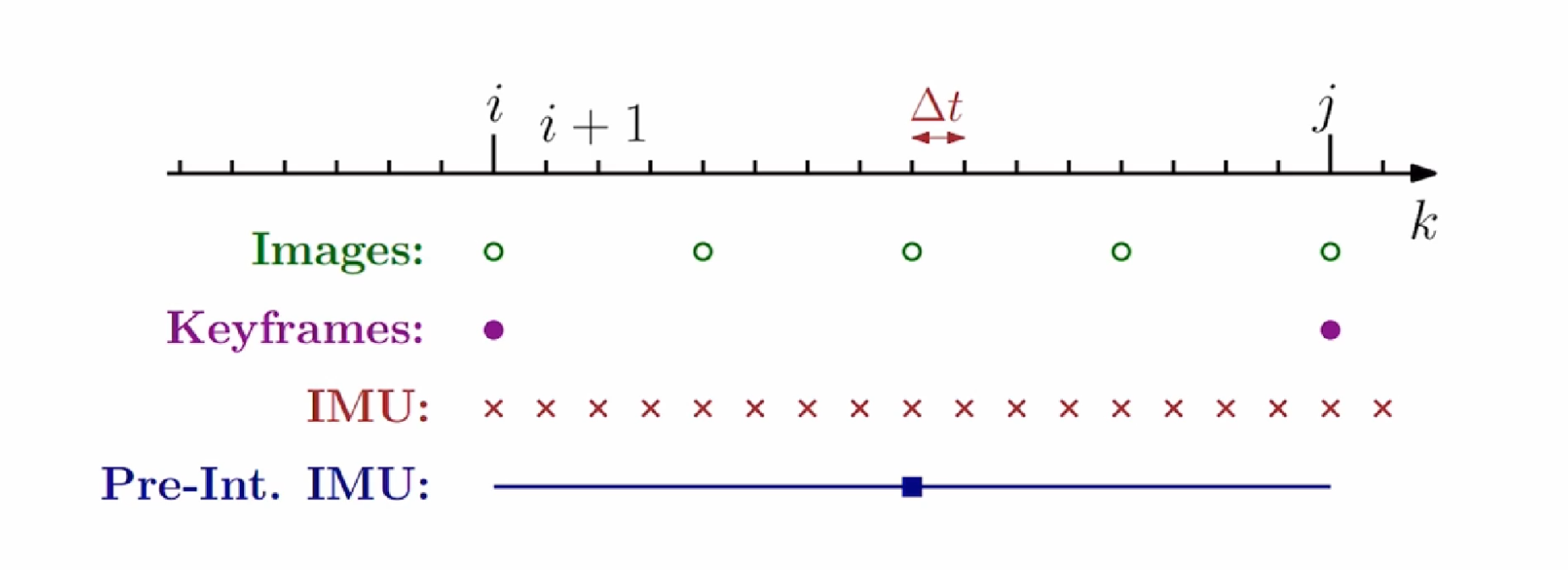
imu预积分学习(更新中)
imu预积分学习(更新中) IMU预积分可以做什么? 以上面那个经典图片为例子,IMU可以通过六轴数据,拿到第i帧和第j帧之间的相对位姿,这样不就可以去用来添加约束了吗 但是有一个比较大的问题是: I…...
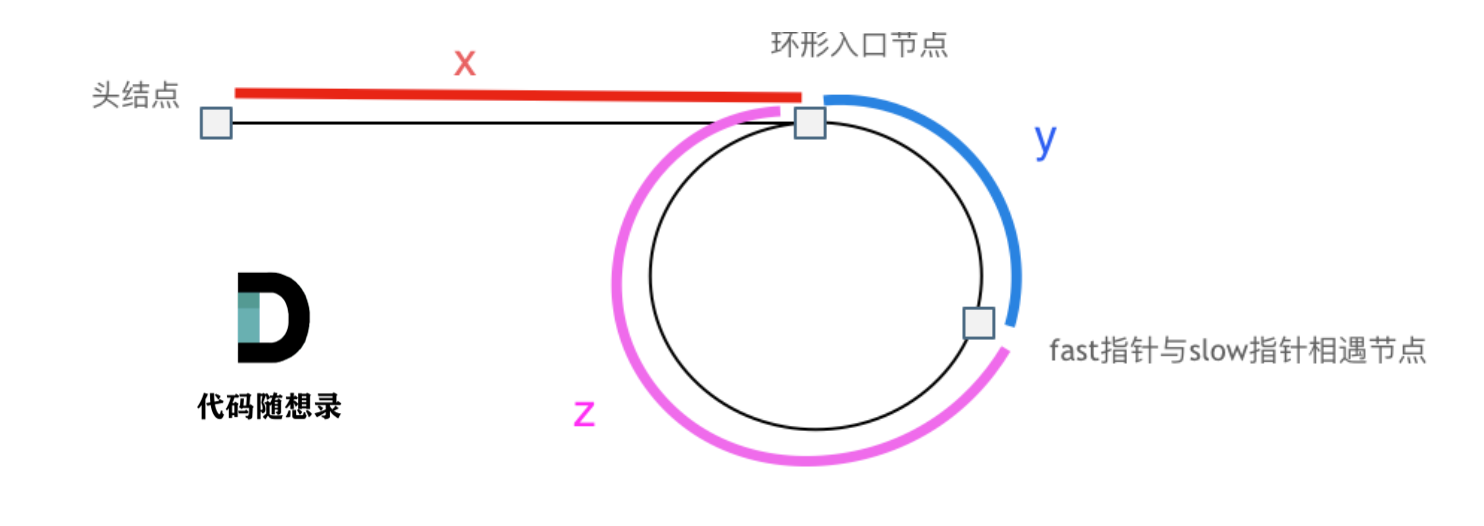
算法刷题-链表
算法刷题-链表 203. 移除链表元素 给你一个链表的头节点 head 和一个整数 val ,请你删除链表中所有满足 Node.val val 的节点,并返回 新的头节点 。 示例 1: 输入:head [1,2,6,3,4,5,6], val 6 输出:[1,2,3,4,5]…...
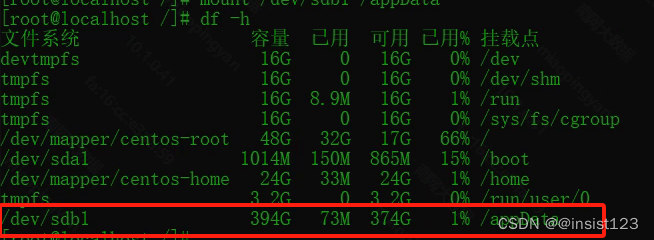
Linux 挂载磁盘到指定目录
问题:公司分配了数据磁盘,但是分区也没有挂载到目录 首先 df -h 查看一下挂载点的情况 查看服务器上未挂载的磁盘 fdisk -l 注:图中sda、sdb (a、b指的是硬盘的序号) 分区操作 我们可以看到b硬盘有536G未分区&…...

ZYNQ linux调试LCD7789
一,硬件管脚 1,参数解释和实物 LVGL是一个开源的图形库,主要用于MCU上屏幕UI的部署,功能完善,封装合理,可裁切性强,也可以实现Linux上fbx的部署。LVGL官网LVGL - Light and Versatile Embedded Graphics Library 每根线的作用...
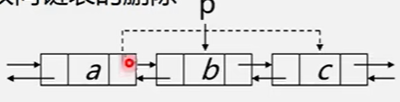
【双向链表的插入和删除】
文章目录 双向链表双向链表的插入双向链表的删除操作 双向链表 双向链表的结构定义如下: //双向链表的结构定义 typedef struct DuLNode {ElemType data;struct DuLNode* prior, * next; }DuLNode,*DuLinkList;双向链表的结点有两个指针域:prior&#…...
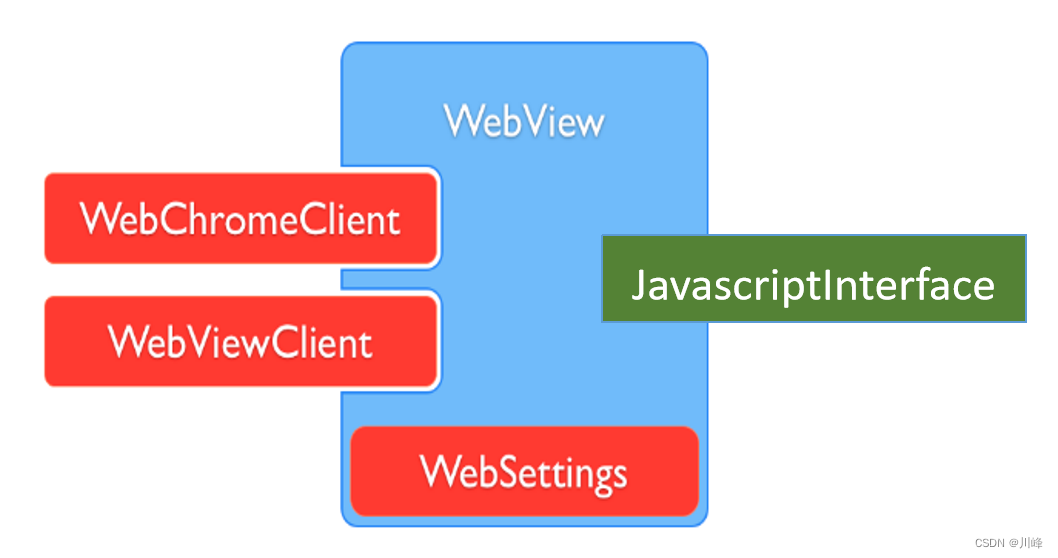
【Android知识笔记】Webview专题
WebView 核心组件 类名作用常用方法WebView创建对象加载URL生命周期管理状态管理loadUrl():加载网页 goBack():后退WebSettings配置&管理 WebView缓存:setCacheMode() 与JS交互:setJavaScriptEnabled()WebViewClient处理各种通知&请求事件should...

Leetcode第 368 场周赛
元素和最小的山形三元组 II 预处理前缀和后缀最小值,记为pre[i]和sa[i] 对于当前编号i,如果前面的最小值和后面的最大值都小于nums[i],则记录ans[i] nums[i]pre[i-1]sa[i1] 结果输出最小的ans[i]即可。 合法分组的最少组数 统计每一个数字出现的次数。将每一个数…...
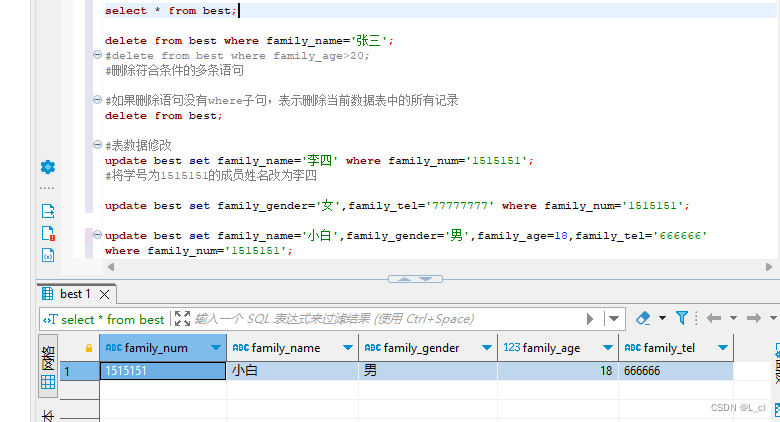
Mysql数据库 3.SQL语言 DML数据操纵语言 增删改
DML语句:用于完成对数据表中数据的插入、删除、修改操作 一.表数据插入 插入数据语法: 步骤例: 1.声明数据库:use 数据库名; 2.删除操作:drop table if exists 表名; 3.创建数据库中的表:create table 表…...

Java中,如何去掉字符串中前面所有的0
大家好,我是三叔,这期主要给大家分享下在开发中使用的字符串的一些常见方法。 例如:00000000110,现在需要去掉前面所有补的0,得到110,相信大家在开发中肯定有遇到过类似的开发需求,如何做&…...

数组能开空间大小
奈何辰星无可奈_leetcode,中等难度,算法-CSDN博客 这个博客介绍的很好,可以参考下...

Python 数据类 - dataclass 的作用与不足
https://docs.python.org/zh-cn/3/library/dataclasses.html https://peps.python.org/pep-0526/ https://peps.python.org/pep-0557/ dataclass 简单示例 from dataclasses import dataclassdataclass class User:name: strage: intif __name__ __main__:response_json {na…...

G-Helper深度探索:如何用开源工具重塑华硕笔记本的性能控制体验
G-Helper深度探索:如何用开源工具重塑华硕笔记本的性能控制体验 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, Flow, TUF, …...
之CLAHE在医学影像处理中的应用)
【Emgu CV教程】7.7、图像锐化(增强)之CLAHE在医学影像处理中的应用
1. CLAHE算法在医学影像处理中的核心价值 医学影像有个很头疼的问题——对比度不足。比如X光片里骨骼和软组织的灰度差异小,或者MRI图像中病灶区域与正常组织界限模糊。这时候传统的直方图均衡化就像用大锤砸核桃,虽然整体亮度提升了,但会把噪…...

SAP财务数据一致性检查:手把手教你用ABAP程序自动修复ACDOCA表异常
SAP财务数据一致性检查:手把手教你用ABAP程序自动修复ACDOCA表异常 在SAP财务模块的日常运维中,ACDOCA表作为新总账(New GL)的核心表,承载着所有财务凭证的明细数据。然而在实际操作中,我们经常会遇到ACDOCA表与BSEG表数据不一致的…...

黑苹果触摸板手势终极方案:从卡顿到流畅的完整配置指南
黑苹果触摸板手势终极方案:从卡顿到流畅的完整配置指南 【免费下载链接】Hackintosh Hackintosh long-term maintenance model EFI and installation tutorial 项目地址: https://gitcode.com/gh_mirrors/ha/Hackintosh 还在为黑苹果触摸板的生硬操作而烦恼吗…...

GCC源码深度分析:从设计哲学到工程实践
一、设计原理与哲学1.1 三段式架构的哲学基础GCC(GNU Compiler Collection)的设计核心是三段式架构,这一设计哲学源于编译器理论中的经典分离原则。GCC将编译过程清晰地划分为前端、中端和后端三个逻辑部分,每个部分专注于特定的任…...

Z-Image-GGUF人像生成专项测试:不同种族、年龄与表情的刻画能力
Z-Image-GGUF人像生成专项测试:不同种族、年龄与表情的刻画能力 最近在尝试各种图像生成模型,发现一个挺有意思的现象:很多模型生成风景、静物效果不错,但一到人像,尤其是需要体现特定种族、年龄和表情的时候…...

别再只盯着理论了!用LTspice仿真施密特触发器,5分钟搞定传输特性分析
别再只盯着理论了!用LTspice仿真施密特触发器,5分钟搞定传输特性分析 在电子电路设计中,施密特触发器因其独特的迟滞特性而广受欢迎,它能有效消除噪声干扰,提高信号稳定性。然而,传统的理论分析往往让初学者…...
)
别再死磕A*了!用MATLAB从零实现RRT*路径规划(附完整代码与避坑指南)
从A到RRT:MATLAB实战高维空间路径规划全解析 当传统栅格搜索算法在机器人关节空间或复杂三维环境中捉襟见肘时,概率采样方法正成为新一代路径规划的核心利器。本文将带您深入理解RRT算法相对于A的突破性优势,并通过MATLAB完整实现过程&#…...

C语言文件操作实战:读写YOLOv12模型权重与配置
C语言文件操作实战:读写YOLOv12模型权重与配置 如果你正在用C或C捣鼓YOLOv12模型,尤其是在那些没有现成Python库的嵌入式或高性能计算环境里,那么你很可能需要自己动手,从最底层的文件读写开始,把模型权重和配置“喂”…...

macOS 强制运行拦截程序
当你从 Chrome、Safari 或其它网络渠道下载文件时,macOS 会自动给这个文件贴上一张“隐形贴纸”,名字就叫 com.apple.quarantine。系统的逻辑: 当你双击运行一个文件时,系统的 Gatekeeper会先检查有没有这张贴纸。拦截逻辑&#x…...