搜索问答技术学习:基于知识图谱+基于搜索和机器阅读理解(MRC)
目录
一、问答系统应用分析
二、搜索问答技术与系统
(一)需求和信息分析
问答需求类型
多样的数据源
文本组织形态
(二)主要问答技术介绍
发展和成熟度分析
重点问答技术基础:KBQA和DeepQA
KBQA(基于知识图谱的问答)
DeepQA(深度问答)
机器阅读理解(Machine Reading Comprehension,MRC)
(三)系统整体架构
三、KBQA:基于知识图谱的问答系统
(一)图谱数据与检索
数据更新方向
直接三元组索引查询
通过图数据库存储检索
(二)语义解析
(三)深度学习
扩展:汉语诗词类、单实体类、多实体关系类
四、DeepQA:基于搜索+机器阅读理解的问答系统
(一)基本背景分析
(二)短答案MRC
基本功能
面临挑战:搜索结果噪声过多
面临挑战:答案出现常识性错误
面临挑战:鲁棒性问题
面临挑战:答案归一化和多span问题
(三)长答案MRC
基本功能
长答案MRC-组合式问答
长答案MRC-判断类观点问答
主要学习资料
背景:重点学习来源于QQ浏览器搜索中的智能问答技术
一、问答系统应用分析
问答的核心是通过理解语言和运用知识来进行提问和回答。从应用角度看,由于人类有获取信息的需求和旺盛的好奇心,问答的场景无处不在;从研究角度看,问答是认知智能的前沿之一。问答系统在搜索中有广泛的应用,它们可以提高信息检索的效率和质量。以下是问答在搜索中的应用:
-
自然语言搜索: 传统搜索引擎主要依赖于关键词匹配,但自然语言搜索允许用户提出问题,而不仅仅是关键词。问答系统可以理解用户的问题,并返回相关的答案,这提供了更直观、准确的搜索体验。
-
信息检索: 问答系统可以根据用户的问题提供相关的文档、文章或网页。它们可以分析问题并从大量文本数据中筛选出最相关的信息,帮助用户更快速地找到他们需要的内容。
-
智能助手: 问答系统被用作虚拟助手,比如Siri、Google Assistant和Alexa。用户可以通过语音提问,系统会理解问题并提供相应的答案或执行任务,如设置提醒、发送消息等。
-
知识图谱: 问答系统被用于构建知识图谱,这是一个结构化的知识数据库,其中包含实体、属性和关系。用户可以通过问答来探索和查询知识图谱,以获取相关信息。
-
专业领域搜索: 在专业领域,问答系统可以用于检索专门领域的知识,如医学、法律、科学等。这些系统可以帮助专业人士快速获得专业领域的答案和信息。
-
智能客服: 问答系统被用于网站和应用的在线客服功能。它们可以回答常见问题,提供支持和解决问题,以减轻人工客服的负担。
-
教育和培训: 问答系统可以用于在线教育平台,帮助学生提出问题并获取关于课程内容的答案。它们还可以用于培训材料的检索和解释。
-
社交媒体: 一些社交媒体平台使用问答系统来推荐内容、回答用户的问题,并提供个性化建议。
-
智能搜索引擎: 问答系统可以提高搜索引擎的智能程度,使其更好地理解用户的意图,提供更精确的搜索结果。
总之,问答系统在搜索中的应用为用户提供了更智能、更个性化的信息检索体验,有助于满足用户的知识需求。这些系统利用自然语言处理和人工智能技术,不断改进和扩展其功能,以适应不同领域和用户需求。
二、搜索问答技术与系统
为满足搜索中问答的需求,现代搜索引擎和问答系统需要结合自然语言处理、信息检索和数据整合技术。它们必须能够理解用户问题、从各种数据源中检索信息,分析和排名答案,并以用户友好的方式呈现结果。这个领域的不断发展和创新,旨在提供更准确、全面和个性化的搜索体验。
(一)需求和信息分析
问答需求类型
25%的明确需求占比表明了用户在搜索过程中经常需要具体的答案,而不仅仅是相关的文本或链接。这种需求可以涵盖各种领域和问题类型,包括事实类问题(如"今天的天气如何?")和非事实类问题(如"如何减肥?")。

多样的数据源
问答系统需要访问和整合多种数据源,包括网页、UGC(用户生成内容)和PGC(专业生成内容)。这意味着系统必须能够检索、理解和分析不同来源的信息以满足用户需求。

文本组织形态
数据的组织形态可以分为结构化、半结构化和无结构化。
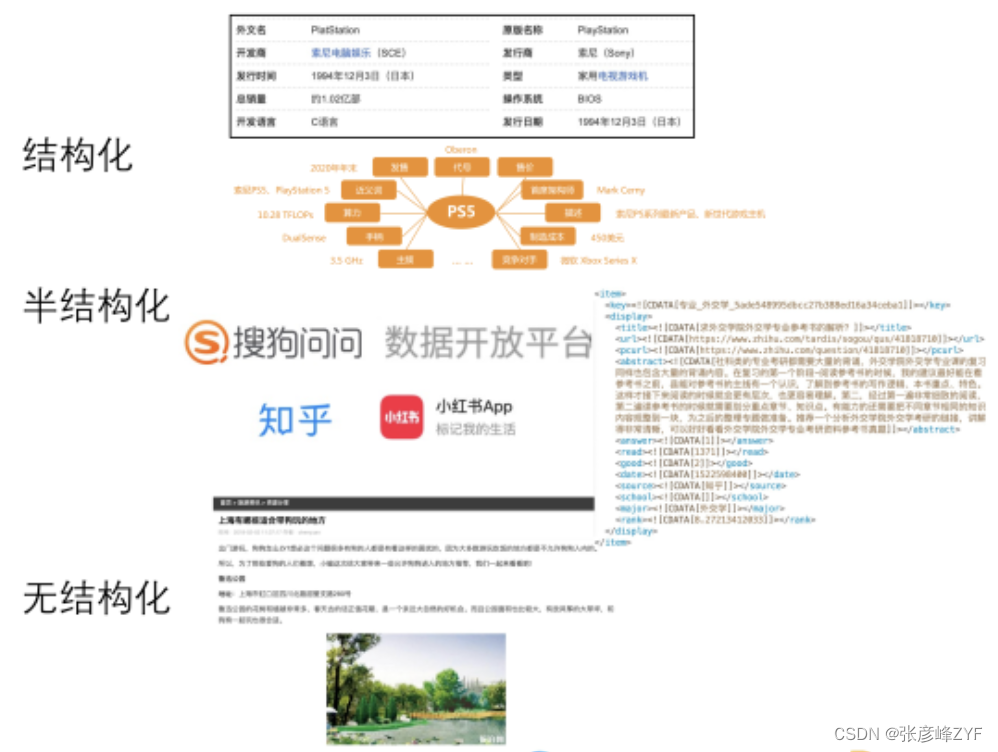
不同类型的数据需要不同的处理方法。结构化数据,如知识图谱,通常更容易处理,因为信息有明确的格式和关系。半结构化数据,如社区问答对,通常有一定的格式和模式,但可能不如结构化数据那么严格。无结构化数据,如普通网页文本,最具挑战性,因为信息通常以自由文本形式存在,需要自然语言处理技术来理解和提取信息。
(二)主要问答技术介绍
发展和成熟度分析
搜索中的问答技术一直处于不断发展和成熟的阶段,这是一个涵盖多个领域的综合性领域,包括自然语言处理、信息检索、知识图谱和机器学习。以下是搜索中问答技术的发展和成熟度的整体介绍:

总体而言,搜索中的问答技术在不断演化,以满足用户对信息检索的更高期望。它们结合了多个领域的知识和技术,包括自然语言处理、机器学习、知识图谱等。未来,随着技术的不断发展,搜索中的问答技术将变得更加精确、全面和个性化,以满足用户的知识需求。
重点问答技术基础:KBQA和DeepQA
KBQA和DeepQA是两种不同类型的问答技术,它们分别用于处理不同种类的数据和问题需求。
KBQA(基于知识图谱的问答)
- 数据类型: KBQA主要针对结构化数据,其基础是离线构建的知识图谱,其中包含实体、属性和关系的信息。
- 工作流程: KBQA系统通过问题解析,将用户提出的问题映射到知识图谱上的实体、关系和属性,然后执行图谱查询和推理,以获取答案。
- 应用范围: KBQA系统适用于事实类问题,因为知识图谱主要包含关于实体之间的事实性信息,如"谁是美国第一位总统?"。
DeepQA(深度问答)
- 数据类型: DeepQA技术可以处理更广泛的非结构化数据(半结构化和无结构化),包括各种文本来源,如网页、文档和用户生成内容。
- 工作流程: DeepQA系统依赖离线构建的问答内容,使用机器学习和自然语言处理技术,通过搜索引擎获取候选文档,然后使用机器阅读理解技术来抽取答案。
- 应用范围: DeepQA技术更灵活,可以解决更多不同类型的问题需求,包括事实类问题和非事实类问题,因为它可以处理多样性的文本数据。
在实际应用中,可以根据具体需求构建不同类型的DeepQA系统:
-
独立检索系统: 这种系统依赖于高质量的问答数据源,以提供准确的答案。它可以用于特定领域或垂直市场,以提供深度问题回答。
-
通用问答系统: 这种系统结合了在线搜索和机器阅读理解技术,能够处理广泛的问题,通过搜索引擎获得相关文档,并从中提取答案。
-
端到端问答系统: 这种系统更为综合,可以处理多模态输入(如文本、图片、语音),并提供更综合的问题解答服务。
总之,KBQA和DeepQA都是重要的问答技术,它们分别适用于不同类型的数据和问题场景,以满足用户多样化的信息需求。在实际应用中,可以根据需求选择合适的技术和系统。
机器阅读理解(Machine Reading Comprehension,MRC)
当涉及到深度问答(DeepQA)时,机器阅读理解(Machine Reading Comprehension,MRC)是其中一个核心组成部分,因为它为系统提供了能力来理解文本并从中提取答案。以下是有关MRC的一些关键方面:
-
MRC的工作原理: MRC系统旨在使计算机能够像人类一样阅读文本并回答问题。它们使用自然语言处理技术,将问题和文本进行匹配,然后定位并抽取文本中的答案。这通常涉及到命名实体识别、实体关系抽取、句法分析等技术。
-
训练数据: MRC系统通常需要大量的标记数据,包括问题和对应的答案,以便进行机器学习。这些数据可以来自各种来源,包括人工标注的数据集和已有的文本文档。
-
多样性: MRC系统需要处理多样性的文本,包括新闻文章、百科全书、科技文档、小说等各种领域和风格的文本。
-
应用领域: MRC技术可应用于多个领域,包括搜索引擎、虚拟助手、教育、医疗保健、法律等。它们可以用于回答关于这些领域的问题,提供更好的信息检索和交互体验。
-
评估: MRC系统的性能通常使用标准的评估指标,如准确性、召回率、F1分数等来衡量。这些系统经常参与自然语言处理和机器学习竞赛,如SQuAD(Stanford Question Answering Dataset)。
总的来说,MRC是深度问答系统中的一个关键组件,使系统能够理解文本并提取答案,从而为用户提供精确的问题回答。它是问答技术中的一个重要发展方向,将自然语言处理和信息检索融合在一起,以改进搜索和问题解答的能力。
(三)系统整体架构

离线部分是问答内容的构建和理解,比如对专业生产内容做质量和权威性分析、从全网数据中进行问答对的挖掘和选取等;
数据源包括网页库、优质问答库和知识图谱;
在线部分包括搜索问答结果的召回和排序、段落匹配和答案抽取、知识图谱检索和推理计算等,以及问答融合决策从多源结果中决定最终展现给用户的答案。
三、KBQA:基于知识图谱的问答系统
(一)图谱数据与检索
图谱问答系统的数据依据不同实体更新的要求分为三路,数据通过直接的三元组索引查询或者图数据库存储检索系统应用。
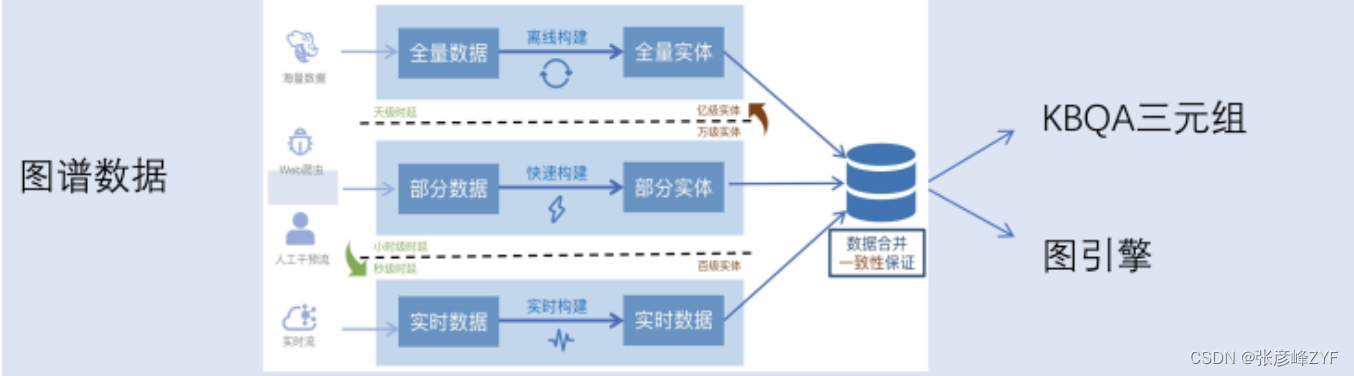
数据更新方向
对于图谱问答系统,数据更新通常可以分为以下三个主要方向:
-
自动更新: 这是一种基于自动化流程的数据更新方式,其中系统可以定期或实时地从各种数据源获取信息,并将其整合到知识图谱中。这可以包括爬虫程序从互联网上抓取新的信息,或从结构化数据源(例如数据库)中自动更新知识图谱。自动更新确保了知识图谱的及时性和准确性。
-
半自动更新: 在这种方式下,数据更新涉及人工干预,但仍采用自动化工具来辅助。人类操作者可能需要审核、编辑或标注从外部源获得的数据,以确保数据的质量和一致性。半自动更新方法通常用于需要高度精准性和可控性的知识图谱。
-
手动更新: 手动更新是最传统的数据更新方式,其中数据管理人员或领域专家负责手动添加、编辑和删除知识图谱中的实体和关系。手动更新通常用于小规模的知识图谱或需要高度人工干预的情况,例如专业领域的图谱。
这三种更新方式可以根据知识图谱的规模、复杂性和数据源的特点选择和组合。对于大规模知识图谱,通常采用自动或半自动更新来确保及时性和数据完整性,而手动更新可能更适合小规模、专业领域或需要高度精准性的场景。
直接三元组索引查询
直接使用三元组索引查询知识图谱的方式是知识图谱问答系统中常见的数据检索方式。在这种方法中,知识图谱中的数据以三元组的形式存储,每个三元组包含实体、属性和值,例如 (巴黎, 是首都, 法国)。用户提出问题时,系统会直接查询这些三元组,以找到与问题相关的信息。这种方式的主要特点包括:
- 直接查询: 查询是基于三元组的实际数据,因此系统可以直接与知识图谱中的实体和关系交互。
- 高度结构化: 由于数据以结构化形式存储,这种方法适合于处理事实类问题,如 "法国的首都是什么?"。
- 高效性: 三元组索引通常可以实现高效的查询,尤其是在知识图谱数据的规模较小的情况下。
这种方法适用于需要高度结构化和精确答案的问题。然而,它可能不够灵活,难以处理非结构化文本的问题,如用户以自然语言形式提出的开放性问题。为了满足更广泛的问题需求,某些系统可能结合其他技术,如自然语言处理和机器阅读理解,以在更复杂的情境中提供答案。
通过图数据库存储检索
数据存储在图数据库中,并通过图数据库来进行检索的方法,同时还应用了图数据库技术。这种方法在知识图谱的构建和问答系统中相当常见。以下是一些相关特点:
-
图数据库存储: 在这种方法中,知识图谱的数据以图形结构的方式存储在专门的图数据库中。图数据库可以有效地表示实体、关系和属性,以及它们之间的连接。
-
图数据库查询: 当用户提出问题时,系统可以使用图数据库的查询语言来检索相关的实体、关系和属性。这通常涉及到图的遍历和查询操作,以查找与问题相关的数据。
-
关系和推理: 图数据库允许进行复杂的关系分析和推理。系统可以通过图数据库来查找实体之间的路径、计算关系的权重,甚至执行一些基本的推理操作。
-
适用性: 这种方法更适合需要处理复杂关系和多步问题的问答系统。它适用于专业领域、复杂推理和知识图谱中的非平凡问题。
-
性能: 图数据库的性能通常较好,特别是当需要执行复杂的查询和关系分析时。这使得它适用于大规模知识图谱的情况。
通过将图数据库与知识图谱问答系统相结合,系统能够更有效地处理知识图谱中的关系和实体,提供更复杂的问题解答服务。这种方法使得知识图谱问答系统能够进行高级的关系分析和推理,从而更全面地回答用户的问题。
(二)语义解析
在线图谱问答的流水线之一是语义解析的方法,系统先对查询进行领域分类以装配不同类型的处理流程(例如汉语诗词类、单实体类、多实体关系类),然后对查询进行语法树分析和形式逻辑规约,在三元组中递归查询和拼装得到最终答案。该方法的优点是支持一些复杂的查询推理,且在规则适用的范畴内准确率较高。

在线图谱问答流水线涉及了多个关键步骤,包括领域分类、语法树分析、形式逻辑规约和三元组查询。这些步骤有助于系统理解用户查询并从知识图谱中检索相关信息以生成答案。以下是这些步骤的详细解释:
-
领域分类: 首先,系统对用户的查询进行领域分类。这是为了确定用户查询的主题或领域,以便装配适当的处理流程。不同领域可能需要不同的处理方法,因此领域分类有助于系统选择正确的处理策略。
-
语法树分析: 一旦系统确定了查询的领域,它会对用户的查询进行语法树分析。这个步骤涉及将自然语言查询分解成一个结构化的语法树,其中包括词汇、短语和语法关系。语法树分析有助于系统理解查询的结构和含义。
-
形式逻辑规约: 接下来,系统进行形式逻辑规约,将自然语言查询转化为逻辑表示。这有助于系统将用户查询与知识图谱中的数据进行匹配。规约过程可以包括识别实体、属性和关系,并将它们映射到知识图谱中的对应项。
-
三元组查询和拼装: 一旦查询被规约为逻辑表示,系统可以进行三元组查询。这意味着系统会递归地查询知识图谱中的三元组,以找到与查询匹配的数据。系统会检索包含所需信息的三元组,然后逐步拼装这些信息以生成最终答案。这可能涉及到多次查询和关系的拼接。
整个流水线的目标是将用户自然语言查询转化为结构化查询,然后使用查询引擎从知识图谱中检索相关信息,最终生成准确的答案。这种方法允许系统处理各种类型的查询,包括事实类问题、关系查询和复杂的问题需求。它结合了自然语言处理和知识图谱检索技术,以提供高效的问答服务。
(三)深度学习
另一种流水线是基于深度学习的方法,系统首先识别出具有问答意图的查询,然后通过深度模型识别查询问题中的实体,对实体属性和查询表达进行深度语义匹配映射,计算出候选结果并进行清洗和排序得到答案。该方法的优点是对查询语义理解较好,泛化性强,召回率较高。

这种基于深度学习的流水线方法是现代问答系统中的常见方式,它结合了自然语言处理和机器学习技术,以理解用户的查询并生成答案。以下是关于这一方法的详细解释:
-
识别问答意图: 流水线的第一步是识别用户查询的意图,以确定用户是否正在寻找特定的答案或信息。这可以通过自然语言处理技术和深度学习模型来实现,例如递归神经网络(RNN)或卷积神经网络(CNN)。
-
实体识别: 一旦系统确定了用户的意图,它会使用深度学习模型来识别查询中的实体。这可以包括命名实体识别(NER),其中系统尝试标识出查询中的特定名词、地点、日期等。
-
深度语义匹配: 接下来,系统会进行深度语义匹配,以理解查询中的实体、属性和关系。这可能涉及到使用深度学习模型来将用户查询与知识图谱中的数据进行语义匹配,以找到最相关的信息。
-
候选结果计算: 系统会计算候选结果,这些结果可能包括多个可能的答案。深度学习模型通常用于计算答案的置信度和相关性。
-
清洗和排序: 最后,系统会对候选答案进行清洗和排序,以确定最终的答案。这可以包括排除不相关的结果、处理模棱两可的查询和根据答案的可信度进行排序。
这种深度学习流水线方法允许系统自动从大规模的文本和知识库中提取信息,以满足用户的需求。这种方法具有适应性,能够处理各种查询类型,包括事实类问题和非事实类问题,因为它强调了语义理解和深度匹配。深度学习模型通常需要大量的训练数据和计算资源,以便在多样化的查询中表现良好。
扩展:汉语诗词类、单实体类、多实体关系类
"汉语诗词类"、"单实体类" 和 "多实体关系类" 是不同类型的查询或问答类别,这些类别在问答系统中需要不同的处理方式:

-
汉语诗词类: 这是一种问答类别,涉及回答与汉语诗歌和文学相关的问题。这些问题可能包括要求识别、解释或引用古代或现代汉语诗歌的内容、作者和背景。对于汉语诗词类问题,系统需要具有文学知识和文化理解能力,以回答与汉诗相关的问题。
-
单实体类: 单实体类问题是那些与单个实体(通常是一个名词或专有名词)相关的问题。这类问题可能包括实体的定义、属性、特征或与实体相关的其他信息。例如,"巴黎是哪个国家的首都?" 是一个单实体类问题,其中实体是 "巴黎"。
-
多实体关系类: 多实体关系类问题涉及多个实体之间的关系或交互。这些问题可能需要系统理解和分析多个实体之间的关系,以提供答案。例如,"谁是巴黎的市长?" 是一个多实体关系类问题,其中涉及 "巴黎"(城市)和 "市长"(职位)之间的关系。
每种类别的问题都需要不同的处理策略和语义解析方法。对于汉语诗词类问题,需要文学知识和语言处理技巧;对于单实体类问题,需要实体识别和属性提取;对于多实体关系类问题,需要理解实体之间的关系和进行复杂的语义匹配。因此,问答系统需要能够分类和处理这些不同类型的问题,以提供准确的答案。
四、DeepQA:基于搜索+机器阅读理解的问答系统
(一)基本背景分析
早期的DeepQA系统具有非常复杂的流水线,例如IBM的Waston,以及2017年第一版“立知“问答。系统包括多个数据挖掘和机器学习模块,在问题分析、答案候选的特征抽取、评分排序等诸多环节都可能有错误的传播和积累,可扩展性不强。

2017年以后,斯坦福的陈丹琦等人提出了一个面向规模文档集的开放域问答系统——DrQA,系统定义了一种新的开放域问答实现方式,即通过检索和深度机器阅读理解(MRC)产生答案。在SQuAD等公开数据集和评测的推动下,深度机器阅读理解发展迅速,在查询和文档语义建模、上下文信息交互建模、答案抽取和预测方式建模上都不断涌现新的方法,2019年机器阅读理解系统甚至在事实类问答上超过了人类水平。

然而在真实的搜索场景中,DeepQA仍然面临着很多挑战。首先是用户的需求纷繁复杂,表达方式也千差万别,而互联网数据规模巨大,需求检索匹配的难度很大。其次是网页数据多种多样,页面类型和格式繁多、质量参差、答案的形式不一,机器阅读理解面临较大的挑战。
(二)短答案MRC
基本功能
短答案机器阅读理解(MRC)任务的定义是从搜索结果的多个文档中抽取唯一的答案片段,同时提供支持答案的文本来源。这一任务旨在让机器理解自然语言问题,并从大规模文本语料库中定位并提取与问题相关的答案片段,从而为用户提供准确的答案,并展示答案来自哪些文本资源或文档。短答案MRC任务通常用于评估机器理解自然语言的能力和信息检索技术的效果。
面临挑战:搜索结果噪声过多
噪声包括不相关结果、不一致答案等。短答案抽取模型是一个多文档段落抽取的模型,将搜索排名topN(常用N=10)的文档段落输入到BERT中进行表示建模,然后预测段落中答案的起始位置。
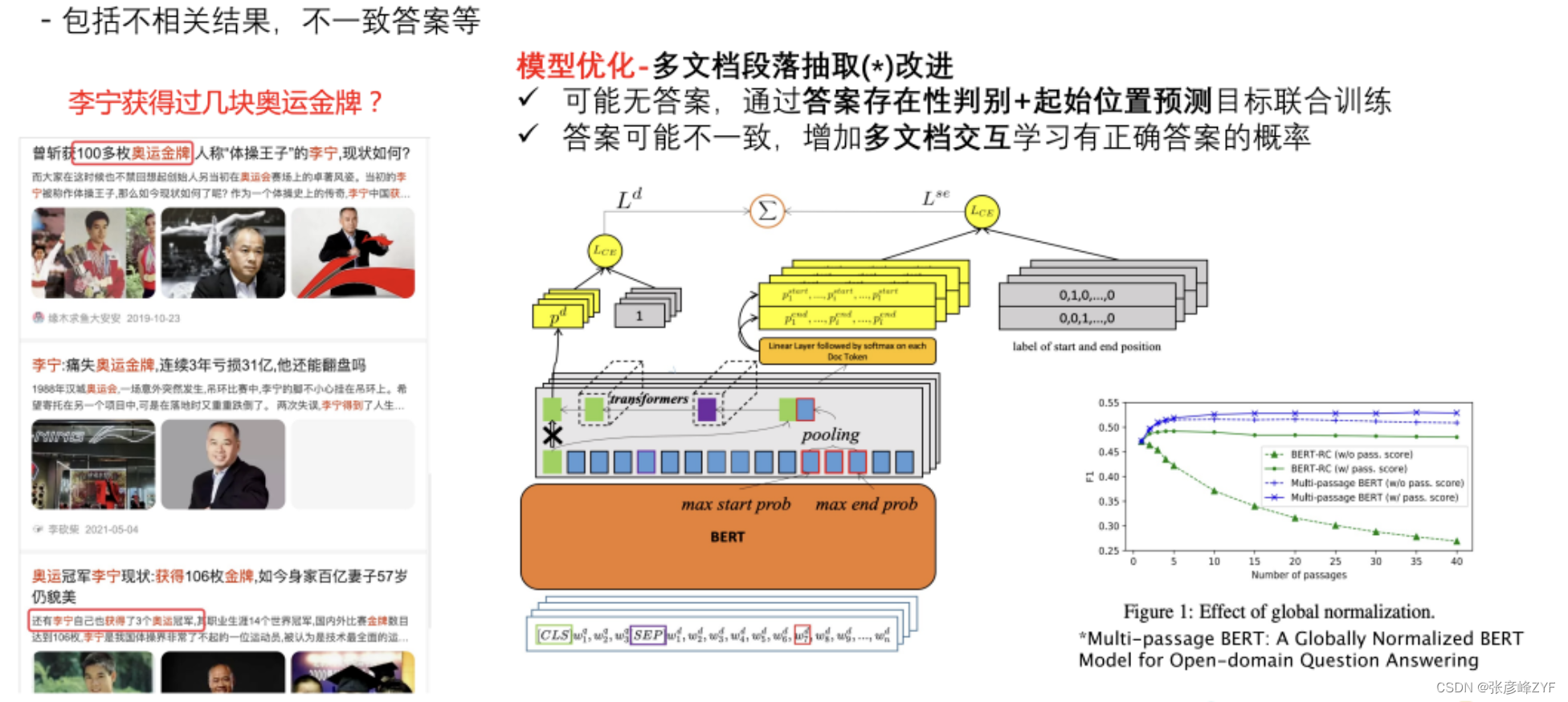
为了解决输入文档不相关的问题,将“答案存在性判别”和“答案起止位置预测”两个目标进行联合训练;为了应对各文档的答案不一致问题们加入了多文档交互,将多个文档中包含答案概率最大的片段拼接起来进行建模,信息融合之后再预测文档包含答案的概率。
面临挑战:答案出现常识性错误
常识性错误即模型输出无意义答案,例如边界错误、答案类型错误。

优化做法是引入一些外部知识,例如百科、知识图谱等,给候选文档中符合答案类型的实体打上特殊的标记,在建模过程中加强对它们的关注。
面临挑战:鲁棒性问题
鲁棒性问题指的是由于过拟合导致模型输出不稳定。Dropout是一种有效的减少过拟合的方式,但它的缺点是不能保持输出的一致性。

优化应用了R-Drop,通过将Dropout作用于输出层,降低了训练和测试的不一致性,同时引入对称KL散度作为正则项,增强了输出的稳定性。在实验过程中发现对输出层使用两次dropout效果较好。此外还对训练数据进行了同语义问题的数据增强,加入相同语义query下的段落输出部分的KL-Loss,增强了模型的稳定性。
面临挑战:答案归一化和多span问题
在抽取式阅读理解中,由于多文档表述的不一致,往往会遇到答案归一化的问题,比如“安全带使用期限是几年”的问题答案可能有“3到5年”、“3年至5年等”;而且还有答案并不是连续判断,比如“沉鱼落雁指的是谁”这个问题中,答案可能对应文档中两个片段(span)。为了解决上述问题,我们尝试用生成式阅读理解方法,以Fusion-in-Decoder(FiD)为例,将检索得到的多文档分别进行编码表示,拼接起来输入到decoder生成统一的答案。

实践中利用大规模点击日志文档生成查询进行预训练,利用短答案日志构建大量弱监督数据进行自训练,有效提升了生成式阅读理解的效果。由于生成模型输出的答案得分其实是语言模型的困惑度,不能很好地刻画答案本身的置信度,我们训练了一个生成答案的置信度预测模型,对答案输出进行决策。
(三)长答案MRC
基本功能
长答案机器阅读理解(MRC)任务类似于短答案MRC,但在答案的形式上有所不同。在长答案MRC任务中,系统需要从大规模文本语料库中寻找较长的文本段落,而不仅仅是短答案片段。
具体来说,长答案MRC任务的定义如下:
长答案MRC任务是从一组文档中,针对给定的自然语言问题,寻找并提取包含详细信息、较长文本段落作为答案。这些文本段落通常包括更广泛的背景信息,以回应问题,而不仅仅是简短的答案片段。系统需要确定哪些段落包含与问题相关的信息,并将它们提供给用户作为答案。
长答案MRC任务更侧重于理解问题的上下文和信息背景,并从大规模文本语料库中检索和提取包含详细信息的文本段落。这种任务在需要更详细解释和推理的问题情境中非常有用,例如提供关于某一主题的全面解释或包含多个方面的答案。长答案MRC任务通常要求系统在更广泛的文本背景中查找答案,这对于信息检索和自然语言理解领域的进展具有重要意义。
长答案MRC-组合式问答
针对长答案包含信息量大、不连续的特点,提出了一种“组合式问答”的任务形式:从搜索结果的单个文档中抽取出一组片段来合成精选摘要答案。任务输入为给定问题和文档的完整片段组合,输出为答案片段组合。评价方式为片段预测的F1和人工评价相结合。

组合式问答模型的整体框架基于BERT,输入是问题和进行了启发式分句的文档句子序列,输出是每个句子是否是答案的概率。引入了两个非常有用的设计,具体见参考文章即可:
- 第一个是引入页面的结构信息。由于网页的HTML能够一定程度上反映页面结构、文本关联以及展示内容的重要度等特征,我们选择了部分网页标签作为符号输入到模型中。
- 第二个是引入针对性的预训练任务。—般预训练都是建模句子级别的关系,没有有效挖掘文档结构的信息;我们引入了两类相关的预训练任务,一类是问题选择(QS),即随机替换一个问题并预测;另一类是节点选择(NS),可以对句子和符号进行随机替换或打乱顺序。这样的预训练任务可以让模型更深刻地理解问题和长文本的内容。
长答案MRC-判断类观点问答
对于判断类观点问答任务,考虑到用户不会仅仅满足于论断,而会更关心论据,设计了一个模型,首先抽取能够回答问题的长答案,即论据,然后根据该论据做论断的分类,产生一个短答案。
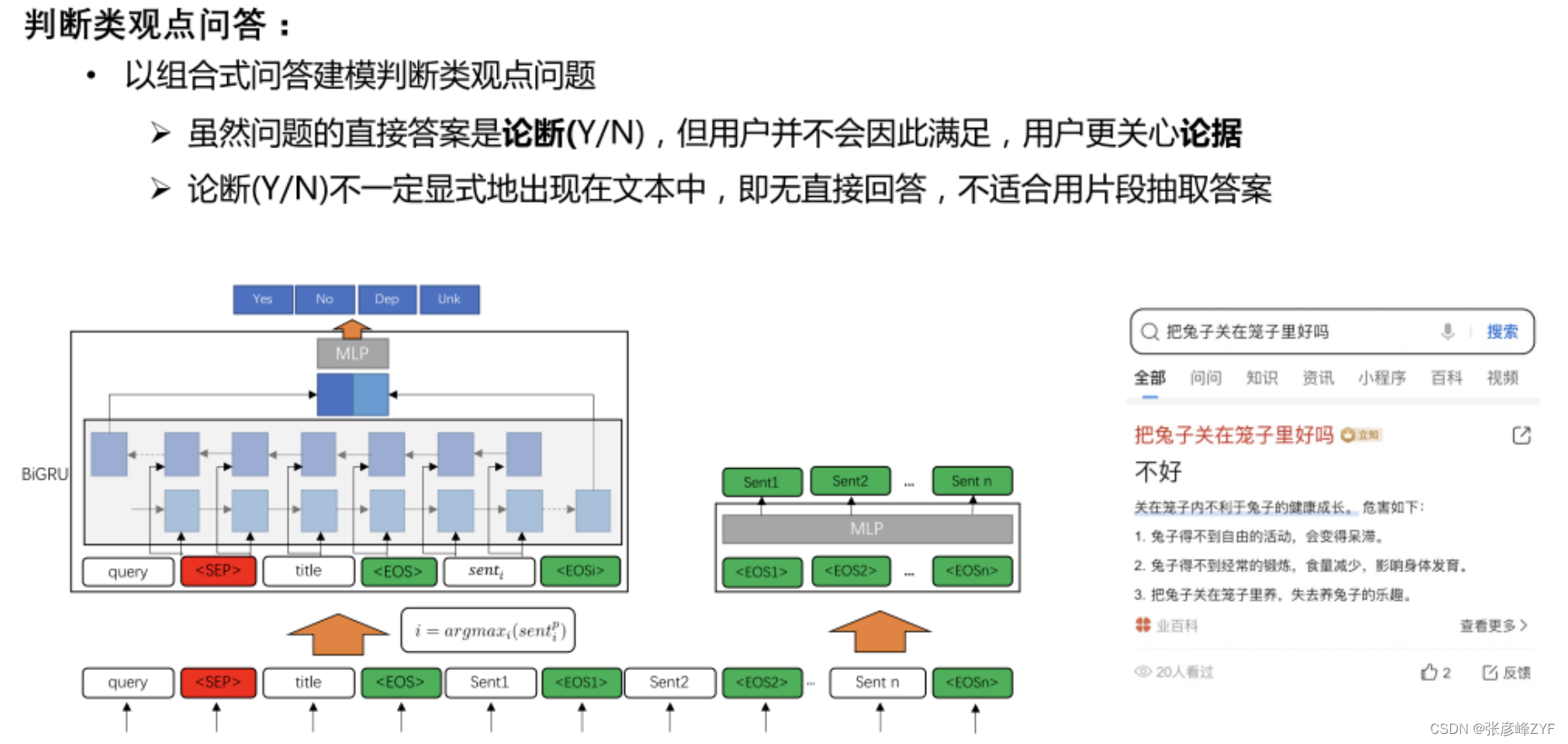
模型的整体结构是基于长答案模型结构的改进,在抽取长答案的同时,将query、title和长答案抽取过程中最高概率答案句拼接起来输入判断模块。通过论据抽取和论点分类两个目标的联合学习,模型可以解决短答案抽取无法解决的问题。比如在下图的例子中,对于“把兔子关在笼子里好吗”这个问题,短答案抽取并不能直接抽取出“好”或者“不好”的答案片段,而通过分类可以知道它是一个否定的回答。
主要学习资料
全面解读!QQ浏览器搜索中的智能问答技术-腾讯云开发者社区-腾讯云 (主要学习来源)
访问ACM Digital Library(ACM数字图书馆)以查找计算机科学和信息检索领域的相关文章
相关文章:
搜索问答技术学习:基于知识图谱+基于搜索和机器阅读理解(MRC)
目录 一、问答系统应用分析 二、搜索问答技术与系统 (一)需求和信息分析 问答需求类型 多样的数据源 文本组织形态 (二)主要问答技术介绍 发展和成熟度分析 重点问答技术基础:KBQA和DeepQA KBQA(…...
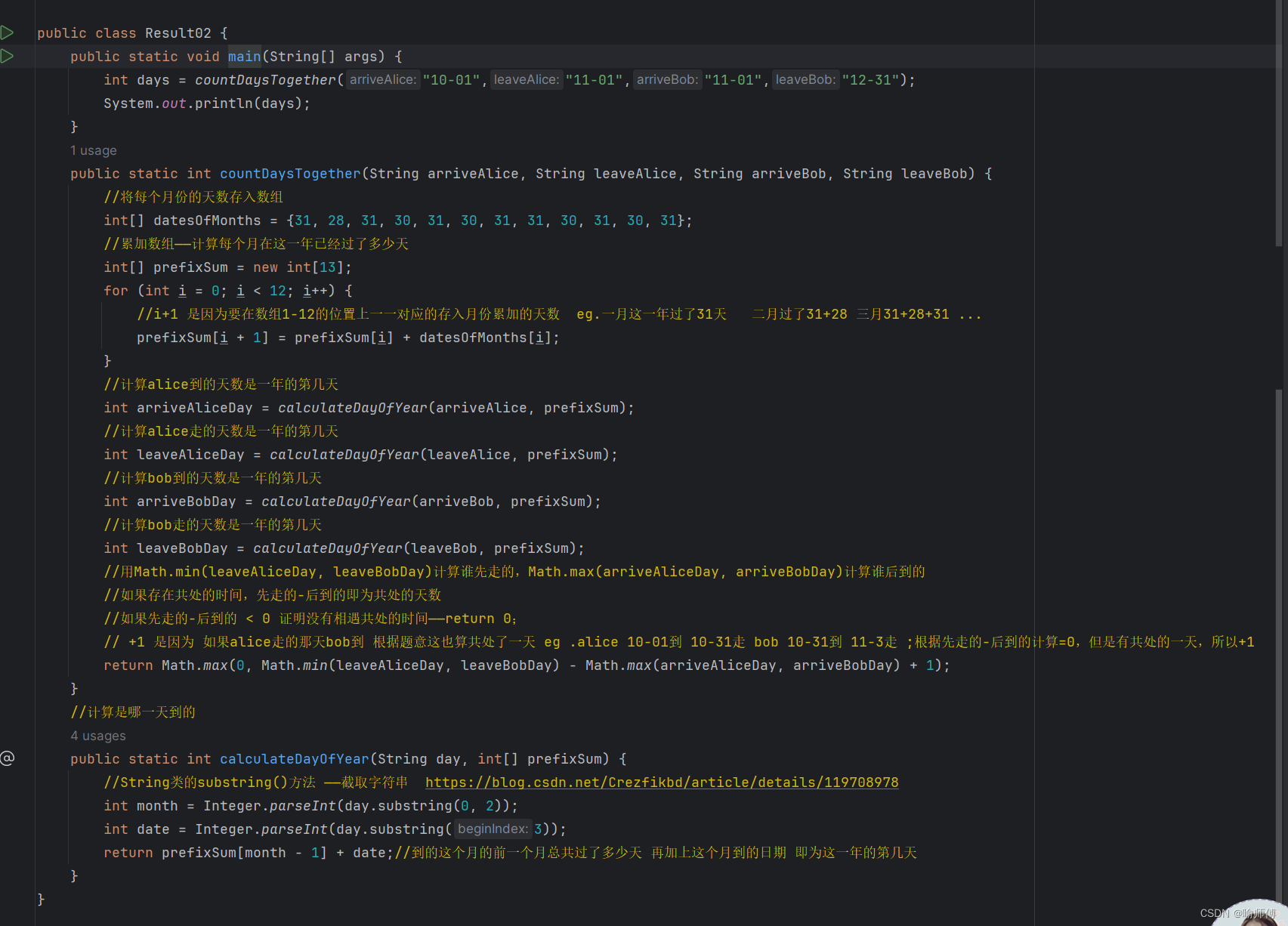
LeetCode2409——统计共同度过的日子数
博主的解法过于冗长,是一直对着不同的案例debug修改出来的,不建议学习。虽然提交成功了,但是自己最后都不知道写的是啥了哈哈哈。 package keepcoding.leetcode.leetcode2409; /*Alice 和 Bob 计划分别去罗马开会。给你四个字符串 arriveA…...

【MyBatisPlus】快速入门、常用注解、常用配置
🐌个人主页: 🐌 叶落闲庭 💨我的专栏:💨 c语言 数据结构 javaEE 操作系统 Redis 石可破也,而不可夺坚;丹可磨也,而不可夺赤。 MyBatisPlus 一、快速入门1.1 引入MyBatisP…...

【USRP】通信之:光通信
光通信: 光通信是使用光信号(通常是红外或可见光信号)在光纤或空气中传输信息的技术。由于光信号的特性,光通信具有非常高的数据传输率和长距离传输能力。以下是光通信的一些关键组件和概念: 光纤: 是由非常纯净的玻璃…...

bpf对内核的观测
目录 1 bpftrace常用命令1.1 列出bpftrace 相关命令的list1. 2bpftrace -e 是执行1.3 查看参数 -lv 2 bpftrace 可以用到的变量3 高级3.1 内置函数3.2 文件系统3.3 内核内存 栈3.4 Malloc 调用 统计3.5 系统调用 brk 的 统计3.6 脚本调用 4 应用5 怎么串联起来呢 bpftrace 总的…...

Tiktok shop api 调试
记录一下调试Tiktok shop api 踩坑记录。 主要是在按官网api上规则和加密生成sign时候一直通不过的问题: 官网地址:https://partner.tiktokshop.com/doc/page/63fd743e715d622a338c4eab 直接贴代码了 import lombok.extern.slf4j.Slf4j;import javax.cr…...

QFSFileEngine::open: No file name specified解决方案
问题 使用QFile类进行文件操作时,报错QFSFileEngine::open: No file name specified。 原因 QFile::open: No file name specified是Qt中的一个错误消息,提示没有指定文件名导致文件无法打开。这个错误通常出现在使用QFile::open()函数时没有提供有效…...

Flappy bird项目
一、功能分析 1、小鸟自动向右滑行 2、按下空格小鸟上升,不按下落 3、显示小鸟需要穿过的管道 4、管道自动左移和创建 5、小鸟和管道碰撞,游戏结束 6、技术 7、 项目框图 8、Ncurses 1)创建窗口界面,移动光标,产…...

高校教务系统登录页面JS分析——西安科技大学
高校教务系统密码加密逻辑及JS逆向 本文将介绍高校教务系统的密码加密逻辑以及使用JavaScript进行逆向分析的过程。通过本文,你将了解到密码加密的基本概念、常用加密算法以及如何通过逆向分析来破解密码。 本文仅供交流学习,勿用于非法用途。 一、密码加…...

Mysql 事务的实现原理
Mysql 里面的事务,满足 ACID 特性,所以Mysql 的事务实现原理,就是InnoDB 是如何保证 ACID 特性的。 ACID A 表示 Atomic 原子性,也就是需要保证多个 DML 操作是原子的,要么都成功,要么都失败。那么…...
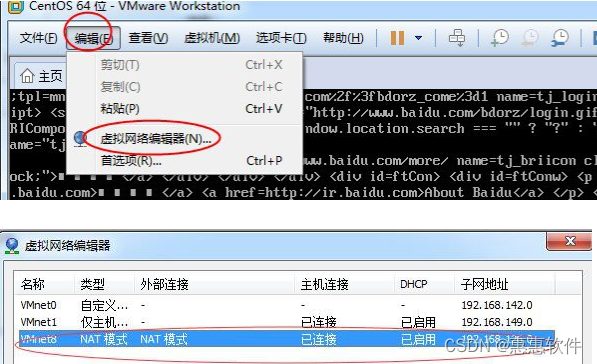
使用vscode搭建虚拟机
首先vscode插件安装 名称: Remote - SSH ID: ms-vscode-remote.remote-ssh 说明: Open any folder on a remote machine using SSH and take advantage of VS Codes full feature set. 版本: 0.51.0 VS Marketplace 链接: https://marketplace.visualstudio.com/items?it…...

C# 使用 LibUsbDotNet 实现 USB 设备检测
国庆节回来后的工作内容,基本都在围绕着各种各样的硬件展开,这无疑让本就漫长的 “七天班” ,更加平添了三分枯燥,我甚至在不知不觉中学会了,如何给打印机装上不同尺寸的纸张。华为的 Mate 60 发布以后,人群…...

系统安全分析与设计
系统安全分析与设计(2分) 内容提要 对称加密与非对称加密 加密技术与认证技术 加密技术(只能防止第三方窃听) 讲解地址:对称加密与非对称加密_哔哩哔哩_bilibili 认证技术 骚戴理解:数字签名是用私钥签名…...
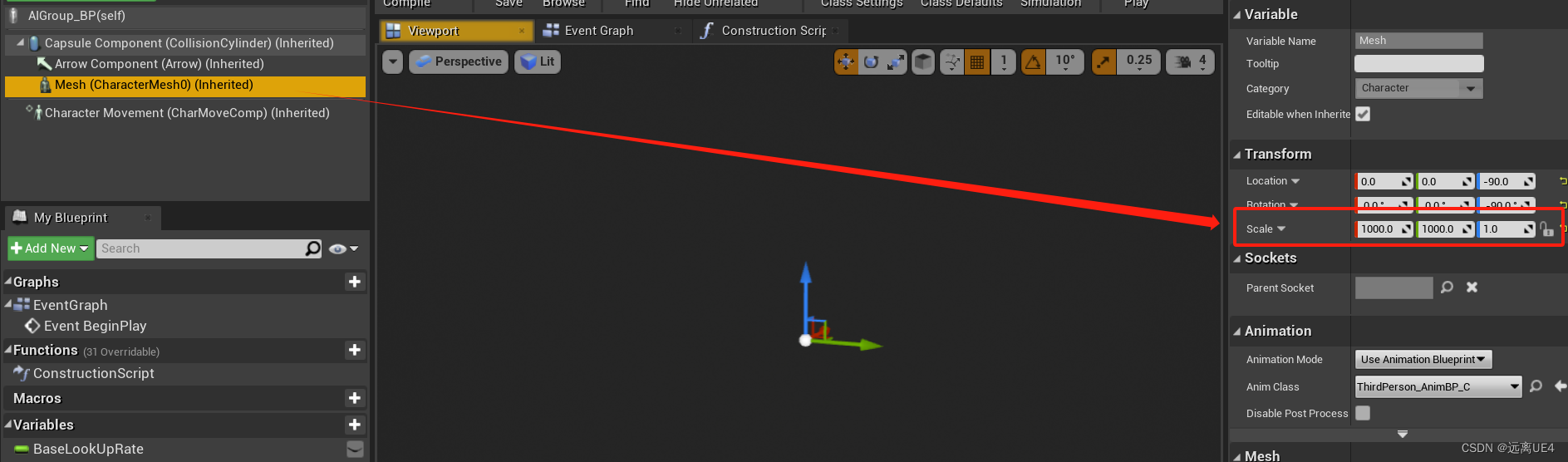
UE4 AI群集实现
逻辑就不用说了,就是计算对应图形位置让每个Pawn移动到该位置 因为有时候AI与AI会卡住 所以加上这个Bool为true,以及设置两个AI之间至少隔的距离,设置在一个合理的参数即可 有时候AI群集,AI与AI会比较紧密,可以将Caps…...
机器学习---CNN(创建和训练一个卷积神经网络并评估其性能)下
import numpy as np import matplotlib.pyplot as plt from cnn_operations import cnn_operations as cnn_opr convolutional_neural_network模块: 1. 卷积神经网络类 def __init__(self):# 网络的层数self.n_layers 0# list,网络中的各层self.layers…...
2021-arxiv-Prefix-Tuning- Optimizing Continuous Prompts for Generation
2021-arxiv-Prefix-Tuning- Optimizing Continuous Prompts for Generation Paper:https://arxiv.org/pdf/2101.00190.pdf Code:https://github.com/XiangLi1999/PrefixTuning 前缀调优:优化生成的连续提示 prefix-tunning 的基本思想也是想…...

使用CMakeLists.txt简化项目构建过程
在软件开发过程中,项目的构建是一个不可避免的环节。而随着项目规模的增大,手动管理编译过程变得越来越繁琐。为了简化构建流程并实现跨平台支持,CMake作为一种流行的构建系统被广泛采用。本文将介绍CMakeLists.txt文件的结构,以及…...

构建并训练简单的CNN
1. 构建并训练深度神经网络模型 1.1 准备数据集 本次使用自己生成的一些数据,如下生成代码: # 准备数据集 # 此处自己生成一些原始的数据点 dataset_X=np.linspace(-10,10,100) dataset_y=2*np.square(dataset_X)+7...

Axi_Lite接口的IP核与地址与缓冲与AxiGP0
AXI Interconnect互连内核将一个或多个 AXI 内存映射主设备连接到一个或多个内存映射从设备。 AXI_GP 接口 AXI_GP 接口是直接连接主机互联和从机互联的端口的。 AXI_HP 接口具有一个 1kB 的数据 FIFO 来做缓冲 [4],但是 AXI_GP 接口与它不同,没…...

maven以及配置
oss oss配置 <!--oss--> <dependency><groupId>com.aliyun.oss</groupId><artifactId>aliyun-sdk-oss</artifactId><version>3.6.0</version></dependency> lombok <!--lombok--><dependency><gro…...

深入解析嵌入式通信协议:UART、SPI、IIC、CAN的实战对比
1. 嵌入式通信协议基础概念 当你拆开一个智能家居设备或者汽车电子模块时,总会发现几根细如发丝的导线连接着不同芯片。这些看似简单的导线背后,隐藏着电子设备之间交流的秘密语言——通信协议。作为嵌入式开发者,理解UART、SPI、IIC、CAN这四…...

构建企业级工业可视化监控系统:FUXA在生产环境的高效部署方案
构建企业级工业可视化监控系统:FUXA在生产环境的高效部署方案 【免费下载链接】FUXA Web-based Process Visualization (SCADA/HMI/Dashboard) software 项目地址: https://gitcode.com/gh_mirrors/fu/FUXA 在数字化转型浪潮中,工业企业面临设备数…...

3步让老Mac焕发新生:OpenCore Legacy Patcher终极升级指南
3步让老Mac焕发新生:OpenCore Legacy Patcher终极升级指南 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 你是否还在为老Mac无法升级到最新macOS…...

第X篇:COZE实战指南 【基于COZE工作流打造智能视频素材提取引擎】全流程解析
1. 为什么需要智能视频素材提取引擎 最近两年短视频内容爆发式增长,我身边很多做自媒体的朋友每天都要花大量时间处理视频素材。有个做科普视频的团队告诉我,他们剪辑一个5分钟的视频,光是找素材、截取片段就要耗费大半天。这种重复性工作不仅…...

破解重庆企业数据治理困局:基于本地化定制的大数据平台如何构建统一主数据标准
引言 在数字化转型浪潮席卷全国的背景下,重庆作为西部重要的制造业与商贸枢纽,正加速推进“智造重镇”和“智慧名城”建设。然而,众多中大型企业在迈向数据驱动的过程中,普遍面临数据孤岛林立、标准不一、质量低下、合规风险高等核…...

批量音频音量调整工具使用说明:固定增减分贝与目标响度两种模式怎么选
音频素材一多,“音量不一致”会非常影响体验:同一套课程、同一期播客、同一批口播,听起来忽大忽小,不是观感问题,是会把人听烦。【批量音频音量调整工具】的核心思路很直白:选一个主文件夹,把里…...

R 4.5深度学习框架集成——最后的机会:R Consortium将于Q3终止对keras 2.x的维护,迁移路线图限时公开
第一章:R 4.5深度学习框架集成——最后的机会:R Consortium将于Q3终止对keras 2.x的维护,迁移路线图限时公开R 4.5正式版已全面支持TensorFlow 2.16与Keras 3.0原生后端,标志着R生态正式告别基于Python绑定的keras 2.x时代。R Con…...
)
如何在TI-28388 DSP的CM核上快速搭建freeRTOS环境(附LED控制实战)
在TI-28388 DSP的CM核上构建freeRTOS开发环境的完整指南 1. 环境准备与硬件配置 在开始freeRTOS移植之前,我们需要确保开发环境配置正确。TI-28388 DSP是一款多核处理器,包含两个C28x核和一个ARM Cortex-M4核(CM核)。我们将专注于…...
)
SITS2026平台深度拆解:如何用1套配置实现92%业务场景零代码交付?(附Gartner验证的ROI测算模型)
第一章:SITS2026平台深度拆解:如何用1套配置实现92%业务场景零代码交付?(附Gartner验证的ROI测算模型) 2026奇点智能技术大会(https://ml-summit.org) SITS2026并非传统低代码平台的简单迭代,而是基于语义…...

Qwen3.5-9B问题解决:部署常见错误排查与日志查看指南
Qwen3.5-9B问题解决:部署常见错误排查与日志查看指南 1. 部署前环境检查 1.1 硬件要求确认 在部署Qwen3.5-9B模型前,请确保您的硬件环境满足以下最低要求: GPU:NVIDIA显卡,显存≥24GB(推荐RTX 3090/409…...