【分布式缓存】关于 Memcached 的几个常见问题
关于 Memcached 的几个常见问题
- 1.Memcached 是怎么工作的?
- 2.Memcached 最大的优势是什么?
- 3.Memcached 和 MySQL 的 querycache 相比,有什么优缺点?
- 4.Memcached 和服务器的 local cache(比如 PHP 的 APC、mmap 文件等)相比,有什么优缺点?
- 5.Memcached 如何实现冗余机制?
- 6.Memcached 如何处理容错的?
- 7.如何将 Memcached 中 item 批量导入导出?
- 8.Memcached 是如何做身份验证的?
- 9.Memcached 的多线程是什么?如何使用它们?
- 10.Memcached 能接受的 key 的最大长度是多少?
- 11.Memcached 对 item 的过期时间有什么限制?
- 12.Memcached 最大能存储多大的单个 item?
- 13.Memcached 能够更有效地使用内存吗?
- 14.什么是二进制协议?
- 15.Memcached 的内存分配器是如何工作的?为什么不适用 malloc/free?为何要使用 slabs?
- 16.Memcached 是原子的吗?
- 17.如何实现集群中的 Session 共享存储?
- 18.Memcached与 Redis 的区别?
- 19.Memcached 服务分布式集群如何实现?
1.Memcached 是怎么工作的?
Memcached 的神奇来自两阶段哈希(two-stage hash)。Memcached 就像一个巨大的、存储了很多 <key,value> 对的哈希表。通过 key,可以存储或查询任意的数据。
客户端可以把数据存储在多台 Memcached 上。当查询数据时,客户端首先参考节点列表计算出 key 的哈希值(阶段一哈希),进而选中一个节点;客户端将请求发送给选中的节点,然后 Memcached 节点通过一个内部的哈希算法(阶段二哈希),查找真正的数据(item)。
2.Memcached 最大的优势是什么?
Memcached 最大的好处就是它带来了 极佳的水平可扩展性,特别是在一个巨大的系统中。由于客户端自己做了一次哈希,那么我们很容易增加大量 Memcached 到集群中。Memcached 之间没有相互通信,因此不会增加 Memcached 的负载;没有多播协议,不会网络通信量爆炸(implode)。
Memcached 的集群很好用。内存不够了?增加几台 Memcached 吧;CPU 不够用了?再增加几台吧;有多余的内存?再增加几台吧,不要浪费了。
基于 Memcached 的基本原则,可以相当轻松地构建出不同类型的缓存架构。
3.Memcached 和 MySQL 的 querycache 相比,有什么优缺点?
把 Memcached 引入应用中,还是需要不少工作量的。MySQL 有个使用方便的 query cache,可以自动地缓存 SQL 查询的结果,被缓存的 SQL 查询可以被反复地快速执行。Memcached 与之相比,怎么样呢?
MySQL 的 query cache 是集中式的,连接到该 query cache 的 MySQL 服务器都会受益。当您修改表时,MySQL 的 query cache 会立刻被刷新(flush)。存储一个 Memcached Item 只需要很少的时间,但是当写操作很频繁时,MySQL 的 query cache 会经常让所有缓存数据都失效。
在多核 CPU 上,MySQL 的 query cache 会遇到扩展问题(scalability issues)。在多核 CPU 上,query cache 会增加一个全局锁(global lock), 由于需要刷新更多的缓存数据,速度会变得更慢。
在 MySQL 的 query cache 中,我们是不能存储任意的数据的(只能是 SQL 查询结果)。而利用 Memcached,我们可以搭建出各种高效的缓存。比如,可以执行多个独立的查询,构建出一个用户对象(user object),然后将用户对象缓存到 Memcached 中。而 query cache 是 SQL 语句级别的,不可能做到这一点。在小的网站中,query cache 会有所帮助,但随着网站规模的增加,query cache 的弊将大于利。
query cache 能够利用的内存容量受到 MySQL 服务器空闲内存空间的限制。给数据库服务器增加更多的内存来缓存数据,固然是很好的。但是,有了 memcached,只要您有空闲的内存,都可以用来增加 memcached 集群的规模,然后您就可以缓存更多的数据。
4.Memcached 和服务器的 local cache(比如 PHP 的 APC、mmap 文件等)相比,有什么优缺点?
首先,local cache 有许多与上面 query cache 相同的问题。local cache 能够利用的内存容量受到(单台)服务器空闲内存空间的限制。不过,local cache 有一点比 Memcached 和 query cache 都要好,那就是它不但可以存储任意的数据,而且没有网络存取的延迟。
local cache 的数据查询更快。考虑把 highly common 的数据放在 local cache 中吧。如果每个页面都需要加载一些数量较少的数据,考虑把它们放在 local cached 吧。
local cache 缺少集体失效(group invalidation)的特性。在 Memcached 集群中,删除或更新一个key会让所有的观察者觉察到。但是在 local cache 中, 我们只能通知所有的服务器刷新 cache(很慢,不具扩展性),或者仅仅依赖缓存超时失效机制。
local cache 面临着严重的内存限制,这一点上面已经提到。
5.Memcached 如何实现冗余机制?
不实现!我们对这个问题感到很惊讶。Memcached 应该是应用的缓存层。它的设计本身就不带有任何冗余机制。如果一个 Memcached 节点失去了所有数据,您应该可以从数据源(比如数据库)再次获取到数据。
您应该特别注意,您的应用应该可以容忍节点的失效。不要写一些糟糕的查询代码,寄希望于 Memcached 来保证一切!如果您担心节点失效会大大加重数据库的负担,那么您可以采取一些办法。比如您可以增加更多的节点(来减少丢失一个节点的影响),热备节点(在其他节点 down 了的时候接管 IP),等等。
6.Memcached 如何处理容错的?
不处理!在 memcached 节点失效的情况下,集群没有必要做任何容错处理。如果发生了节点失效,应对的措施完全取决于用户。节点失效时,下面列出几种方案供您选择:
- 忽略它! 在失效节点被恢复或替换之前,还有很多其他节点可以应对节点失效带来的影响。
- 把失效的节点从节点列表中移除。做这个操作千万要小心!在默认情况下(余数式哈希算法),客户端添加或移除节点,会导致所有的缓存数据不可用!因为哈希参照的节点列表变化了,大部分 key 会因为哈希值的改变而被映射到(与原来)不同的节点上。
- 启动热备节点,接管失效节点所占用的 IP。这样可以防止哈希紊乱(Hashing Chaos)。
- 如果希望添加和移除节点,而不影响原先的哈希结果,可以使用一致性哈希算法(Consistent
Hashing)。您可以百度一下一致性哈希算法。支持一致性哈希的客户端已经很成熟,而且被广泛
使用。去尝试一下吧! - 两次哈希(reshing)。当客户端存取数据时,如果发现一个节点 down 了,就再做一次哈希(哈希算法与前一次不同),重新选择另一个节点(需要注意的时,客户端并没有把 down 的节点从节点列表中移除,下次还是有可能先哈希到它)。如果某个节点时好时坏,两次哈希的方法就有风险了,好的节点和坏的节点上都可能存在脏数据(stale data)。
7.如何将 Memcached 中 item 批量导入导出?
您不应该这样做!Memcached 是一个非阻塞的服务器。任何可能导致 memcached 暂停或瞬时拒绝服务的操作都应该值得深思熟虑。向 memcached 中批量导入数据往往不是您真正想要的!想象看,如果缓存数据在导出导入之间发生了变化,您就需要处理脏数据了;如果缓存数据在导出导入之间过期了,您又怎么处理这些数据呢?
因此,批量导出导入数据并不像您想象中的那么有用。不过在一个场景倒是很有用。如果您有大量的从不变化的数据,并且希望缓存很快热(warm)起来,批量导入缓存数据是很有帮助的。虽然这个场景并不典型,但却经常发生,因此我们会考虑在将来实现批量导出导入的功能。
如果一个 memcached 节点 down 了让您很痛苦,那么您还会陷入其他很多麻烦。您的系统太脆弱了。您需要做一些优化工作。比如处理 惊群 问题(比如 memcached 节点都失效了,反复的查询让您的数据库不堪重负……这个问题在FAQ的其他提到过),或者优化不好的查询。记住,Memcached 并不是您逃避优化查询的借口。
8.Memcached 是如何做身份验证的?
没有身份认证机制!memcached 是运行在应用下层的软件(身份验证应该是应用上层的职责)。memcached 的客户端和服务器端之所以是轻量级的,部分原因就是完全没有实现身份验证机制。这样,memcached 可以很快地创建新连接,服务器端也无需任何配置。
如果您希望限制访问,您可以使用防火墙,或者让 memcached 监听 unix domain socket。
9.Memcached 的多线程是什么?如何使用它们?
在 Steven Grimm 和 Facebook 的努力下,memcached 1.2 及更高版本拥有了多线程模式。多线程模式允许 memcached 能够充分利用多个 CPU,并在 CPU 之间共享所有的缓存数据。memcached 使用一种简单的锁机制来保证数据更新操作的互斥。相比在同一个物理机器上运行多个 memcached 实例,这种方式能够更有效地处理 multi gets。
如果您的系统负载并不重,也许您不需要启用多线程工作模式。如果您在运行一个拥有大规模硬件的、庞大的网站,您将会看到多线程的好处。
简单地总结一下:命令解析(memcached 在这里花了大部分时间)可以运行在多线程模式下。memcached 内部对数据的操作是基于很多全局锁的(因此这部分工作不是多线程的)。未来对多线程模式的改进,将移除大量的全局锁,提高 memcached 在负载极高的场景下的性能。
10.Memcached 能接受的 key 的最大长度是多少?
key 的最大长度是 250 个字符。需要注意的是,250 是 memcached 服务器端内部的限制,如果您使用的客户端支持 key 的前缀 或类似特性,那么 key(前缀+原始 key)的最大长度是可以超过 250 个字符的。
我们推荐使用使用较短的 key,因为可以节省内存和带宽。
11.Memcached 对 item 的过期时间有什么限制?
过期时间最大可以达到 30 天。memcached 把传入的过期时间(时间段)解释成时间点后,一旦到了这个时间点,memcached 就把 item 置为失效状态。这是一个简单但 obscure 的机制。
12.Memcached 最大能存储多大的单个 item?
1MB。如果你的数据大于 1MB,可以考虑在客户端压缩或拆分到多个 key 中。
为什么单个 item 的大小被限制在 1M byte 之内?这是一个大家经常问的问题!
- 简单的回答:因为内存分配器的算法就是这样的。
- 详细的回答:Memcached 的内存存储引擎(引擎将来可插拔…),使用 slabs 来管理内存。内存被分成大小不等的 slabs chunks(先分成大小相等的 slabs,然后每个 slab 被分成大小相等 chunks,不同 slab 的 chunk 大小是不相等的)。chunk 的大小依次从一个最小数开始,按某个因子增长,直到达到最大的可能值。
13.Memcached 能够更有效地使用内存吗?
Memcache 客户端仅根据哈希算法来决定将某个 key 存储在哪个节点上,而不考虑节点的内存大小。
因此,您可以在不同的节点上使用大小不等的缓存。但是一般都是这样做的:拥有较多内存的节点上可以运行多个 memcached 实例,每个实例使用的内存跟其他节点上的实例相同。
14.什么是二进制协议?
关于二进制最好的信息当然是二进制协议规范:二进制协议尝试为端提供一个更有效的、可靠的协议,减少客户端 / 服务器端因处理协议而产生的 CPU 时间。
根据 Facebook 的测试,解析 ASCII 协议是 memcached 中消耗 CPU 时间最多的环节。所以,我们为什么不改进 ASCII 协议呢?
15.Memcached 的内存分配器是如何工作的?为什么不适用 malloc/free?为何要使用 slabs?
实际上,这是一个编译时选项。默认会使用内部的 slab 分配器。您确实应该使用内建的 slab 分配器。最早的时候,memcached 只使用 malloc / free 来管理内存。然而,这种方式不能与 OS 的内存管理很好地工作。反复地 malloc / free 造成了内存碎片,OS 最终花费大量的时间去查找连续的内存块来满足 malloc 的请求,而不是运行 memcached 进程。
slab 分配器就是为了解决这个问题而生的。内存被分配并划分成 chunks,一直被重复使用。因为内存被划分成大小不等的 slabs,如果 item 的大小与被选择存放它的 slab 不是很合适的话,就会浪费一些内存。Steven Grimm 正在这方面已经做出了有效的改进。
16.Memcached 是原子的吗?
所有的被发送到 memcached 的单个命令是完全原子的。如果您针对同一份数据同时发送了一个 set 命令和一个 get 命令,它们不会影响对方。它们将被串行化、先后执行。即使在多线程模式,所有的命令都是原子的,除非程序有 bug。
命令序列不是原子的。如果您通过 get 命令获取了一个 item,修改了它,然后想把它 set 回memcached,我们不保证这个 item 没有被其他进程(process,未必是操作系统中的进程)操作过。在并发的情况下,您也可能覆写了一个被其他进程 set 的 item。
memcached 1.2.5 以及更高版本,提供了 gets 和 cas 命令,它们可以解决上面的问题。如果您使用 gets 命令查询某个 key 的 item,memcached 会给您返回该 item 当前值的唯一标识。如果您覆写了这个 item 并想把它写回到 memcached 中,您可以通过 cas 命令把那个唯一标识一起发送给memcached。如果该 item 存放在 memcached 中的唯一标识与您提供的一致,您的写操作将会成功。如果另一个进程在这期间也修改了这个 item,那么该 item 存放在 memcached 中的唯一标识将会改变,您的写操作就会失败。
17.如何实现集群中的 Session 共享存储?
Session 是运行在一台服务器上的,所有的访问都会到达我们的唯一服务器上,这样我们可以根据客户端传来的 SessionID,来获取 Session,或在对应 Session 不存在的情况下(Session 生命周期到了,或者用户第一次登录),创建一个新的 Session;但是,如果我们在集群环境下,假设我们有两台服务器 A,B,用户的请求会由 Nginx 服务器进行转发(别的方案也是同理),用户登录时,Nginx 将请求转发至服务器 A 上,A 创建了新的 Session,并将 SessionID 返回给客户端,用户在浏览其他页面时,客户端验证登录状态,Nginx 将请求转发至服务器 B,由于 B 上并没有对应客户端发来 SessionID 的 Session,所以会重新创建一个新的 Session,并且再将这个新的 SessionID 返回给客户端,这样,我们可以想象一下,用户每一次操作都有 1 / 2 1/2 1/2 的概率进行再次的登录,这样不仅对用户体验特别差,还会让服务器上的 Session 激增,加大服务器的运行压力。
为了解决集群环境下的 Seesion 共享问题,共有 4 种解决方案:
- 粘性 Session。粘性 Session 是指 Ngnix 每次都将同一用户的所有请求转发至同一台服务器上,即将用户与服务器绑定。
- 服务器 Session 复制。即每次 Session 发生变化时,创建或者修改,就广播给所有集群中的服务器,使所有的服务器上的 Session 相同。
- Session 共享。缓存 Session,使用 Redis,Memcached。
- Session 持久化。将 Session 存储至数据库中,像操作数据一样操作 Session。
18.Memcached与 Redis 的区别?
- Redis 不仅仅支持简单的 K / V 类型的数据,同时还提供 List,Set,Zset,Hash 等数据结构的存储。而 Memcached 只支持简单数据类型,需要客户端自己处理复杂对象。
- Redis 支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用。持久化在 RDB(Redis DataBase)、AOF(Append Only File)。
- 由于 Memcached 没有持久化机制,因此宕机所有缓存数据失效。Redis 配置为持久化,宕机重启后,将自动加载宕机时刻的数据到缓存系统中。具有更好的灾备机制。
- Memcached 可以使用 Magent 在客户端进行一致性 hash 做分布式。Redis 支持在服务器端做分布式,如 Twemproxy、Codis、Redis-cluster 等多种分布式实现方式。
- Memcached 的简单限制就是 Key 和 Value 的限制。最大键长为 250 250 250 个字符,可以接受的储存数据不能超过 1 M B 1MB 1MB(可修改配置文件变大),因为这是典型 Slab 的最大值,不适合虚拟机使用。而 Redis 的 Key 长度支持到 512K。
- Redis 使用的是单线程模型,保证了数据按顺序提交。Memcached 需要使用 CAS 保证数据一致性。CAS(Check and Set)是一个确保并发一致性的机制,属于 “乐观锁” 范畴。原理很简单:拿版本号,操作,对比版本号,如果一致就操作,不一致就放弃任何操作
- CPU 利用。由于 Redis 只使用单核,而 Memcached 可以使用多核,所以平均每一个核上 Redis 在存储小数据时比 Memcached 性能更高;而在 100K 以上的数据中,Memcached 性能要高于Redis 。
- Memcache 内存管理:使用 Slab Allocation。原理相当简单,预先分配一系列大小固定的组,然后根据数据大小选择最合适的块存储。避免了内存碎片。(缺点:不能变长,浪费了一定空间)Memcached 默认情况下下一个 Slab 的最大值为前一个的 1.25 1.25 1.25 倍。
- Redis 内存管理: Redis 通过定义一个数组来记录所有的内存分配情况, Redis 采用的是包装的 malloc / free,相较于 Memcached 的内存管理方法来说,要简单很多。由于 malloc 首先以链表的方式搜索已管理的内存中可用的空间分配,导致内存碎片比较多。
19.Memcached 服务分布式集群如何实现?
特殊说明:Memcached 集群和 Web 服务集群是不一样的,所有 Memcached 的数据总和才是数据库的数据。每台 Memcached 都是部分数据。(一台 Memcached 的数据,就是一部分 MySQL 数据库的数据。)
- 程序端实现。程序加载所有 MC 的 ip 列表,通过对 key 做 hash (一致性哈希算法)。例如:web1 (key) => 对应 A , B , C , D , E , F , G … A,B,C,D,E,F,G… A,B,C,D,E,F,G… 若干台服务器。(通过哈希算法实现)
- 负载均衡器。通过对 key 做 hash(一致性哈希算法)。一致哈希算法的目的是不但保证每个对象只请求一个对应的服务器,而且当节点宕机,缓存服务器的更新重新分配比例降到最低。
相关文章:

【分布式缓存】关于 Memcached 的几个常见问题
关于 Memcached 的几个常见问题 1.Memcached 是怎么工作的?2.Memcached 最大的优势是什么?3.Memcached 和 MySQL 的 querycache 相比,有什么优缺点?4.Memcached 和服务器的 local cache(比如 PHP 的 APC、mmap 文件等&…...
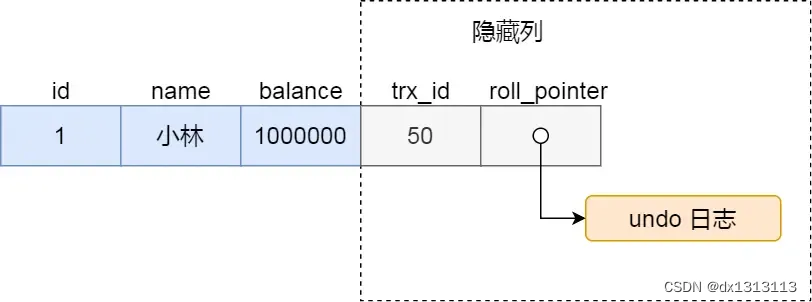
MySQL 三大日志(bin log、redo log、undo log)
redo log redo log (重做日志) 是 InnoDB 存储引擎独有的,它让 MySQL有了崩溃恢复的能力,是事务中实现 持久化的重要操作 比如 MySQL 实例宕机了,重启时,InnoDB 存储引擎会使用 redo log 恢复数据,保证数据的持久性与…...
asp.net社区医疗辅助诊断网站系统VS开发sqlserver数据库web结构c#编程
一、源码特点 asp.net社区医疗辅助诊断网站系统 是一套完善的web设计管理系统,系统采用mvc模式(BLLDALENTITY)系统具有完整的源代码和数据库,系统主要采用B/S模式开发。开发环境为vs2010,数据库为sqlserver200…...
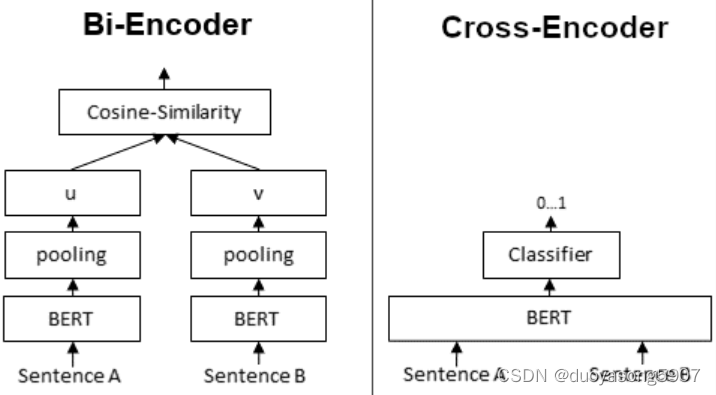
NLP Bi-Encoder和Re-ranker
Retrieve & Re-Rank https://www.sbert.net/examples/applications/retrieve_rerank/README.html Bi-Encoder vs. Cross-Encoder https://www.sbert.net/examples/applications/cross-encoder/README.html Bi-Encoder会用BERT对输入文本编码,再根据cosine相似度…...

SpringBoot+Mybatis 配置多数据源及事务管理
目录 1.多数据源 2.事务配置 项目搭建参考: 从零开始搭建SpringBoot项目_从0搭建springboot项目-CSDN博客 SpringBoot学习笔记(二) 整合redismybatisDubbo-CSDN博客 1.多数据源 添加依赖 <dependencies><dependency><groupId>org.springframework.boot&…...
【java】A卷+B卷)
华为OD 猴子吃桃(100分)【java】A卷+B卷
华为OD统一考试A卷+B卷 新题库说明 你收到的链接上面会标注A卷还是B卷。目前大部分收到的都是B卷。 B卷对应20022部分考题以及新出的题目,A卷对应的是新出的题目。 我将持续更新最新题目 获取更多免费题目可前往夸克网盘下载,请点击以下链接进入: 我用夸克网盘分享了「华为O…...
切片不够技术来凑
概述 随着数据经度的提升,18级的切片有些场景已经不够用了,但是大部分在线的栅格切片最大级别还是18级,如果地图继续放大,有的框架(leaflet会,openlayers和mapboxGL不会)会存在没有底图的情况。…...
特约|数码转型思考:Web3.0与银行
日前,欧科云链研究院发布重磅报告,引发银行界及金融监管机构广泛关注。通过拆解全球70余家银行的加密布局,报告认为,随着全球采用率的提升与相关技术的成熟,加密资产已成为银行业不容忽视也不能错过的创新领域。 作为…...

MySQL知识详细汇总
存储引擎 MyISAM 不支持事务,不支持外键,支持全文索引,查询、插入效率高InnoDB 支持事务(事务的特性) 原子性:一个事务中所有的操作,要么全部完成,要么全部不完成,不会在…...

【驱动开发】LED灯的亮灭——通过字符设备驱动的分步实现编写LED驱动,实现设备文件和设备的绑定
头文件: #ifndef __HEAD_H__ #define __HEAD_H__typedef struct {unsigned int MODER;unsigned int OTYPER;unsigned int OSPEEDR;unsigned int PUPDR;unsigned int IDR;unsigned int ODR; }gpio_t;//LED灯的寄存器地址 #define LED1_ADDR 0X50006000 #define L…...
【java】A卷+B卷)
华为OD 最小数字(100分)【java】A卷+B卷
华为OD统一考试A卷+B卷 新题库说明 你收到的链接上面会标注A卷还是B卷。目前大部分收到的都是B卷。 B卷对应20022部分考题以及新出的题目,A卷对应的是新出的题目。 我将持续更新最新题目 获取更多免费题目可前往夸克网盘下载,请点击以下链接进入: 我用夸克网盘分享了「华为O…...
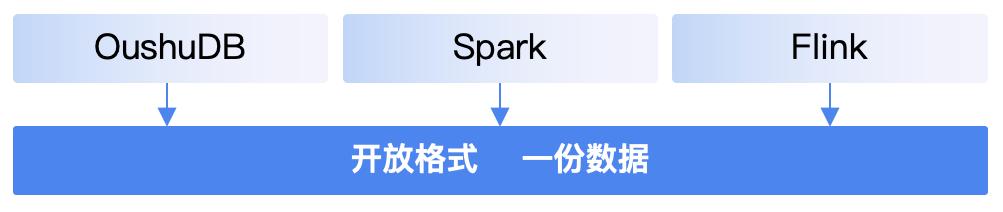
大模型、实时需求推动湖仓平台走向开放
大模型、实时需求高涨 AGI 时代,以 ChatGPT、Midjourney 等为代表的大模型迅速应用加速了 AI 普及,越来越多的企业选择搭建自己的 AI 基础设施,训练行业大模型。 另一方面,企业为了在瞬息万变的市场环境中更快的做出商业决策&…...
Linux搭建文件服务器
搭建简单文件服务器 基于centos7.9搭建http文件服务器基于centos7.9搭建nginx文件服务器基于ubuntu2204搭建http文件服务器 IP环境192.168.200.100VMware17 基于centos7.9搭建http文件服务器 安装httpd [rootlocalhost ~]# yum install -y httpd关闭防火墙以及selinux [roo…...
跨境商城源码可以支持多种支付方式吗?
跨境商城源码是一种用于建立跨国界电商平台的程序代码。随着全球电商的繁荣发展,越来越多的商家开始寻找一种既安全可靠,又能满足用户需求的支付方式。那么,跨境商城源码是否能够支持多种支付方式呢?让我们深入探讨一下。 1. 支付宝支付 支付…...
机器学习中的核方法
一、说明 线性模型很棒,因为它们易于理解且易于优化。他们受苦是因为他们只能学习非常简单的决策边界。神经网络可以学习更复杂的决策边界,但失去了线性模型良好的凸性特性。 使线性模型表现出非线性的一种方法是转换输入。例如,通过添加特征…...
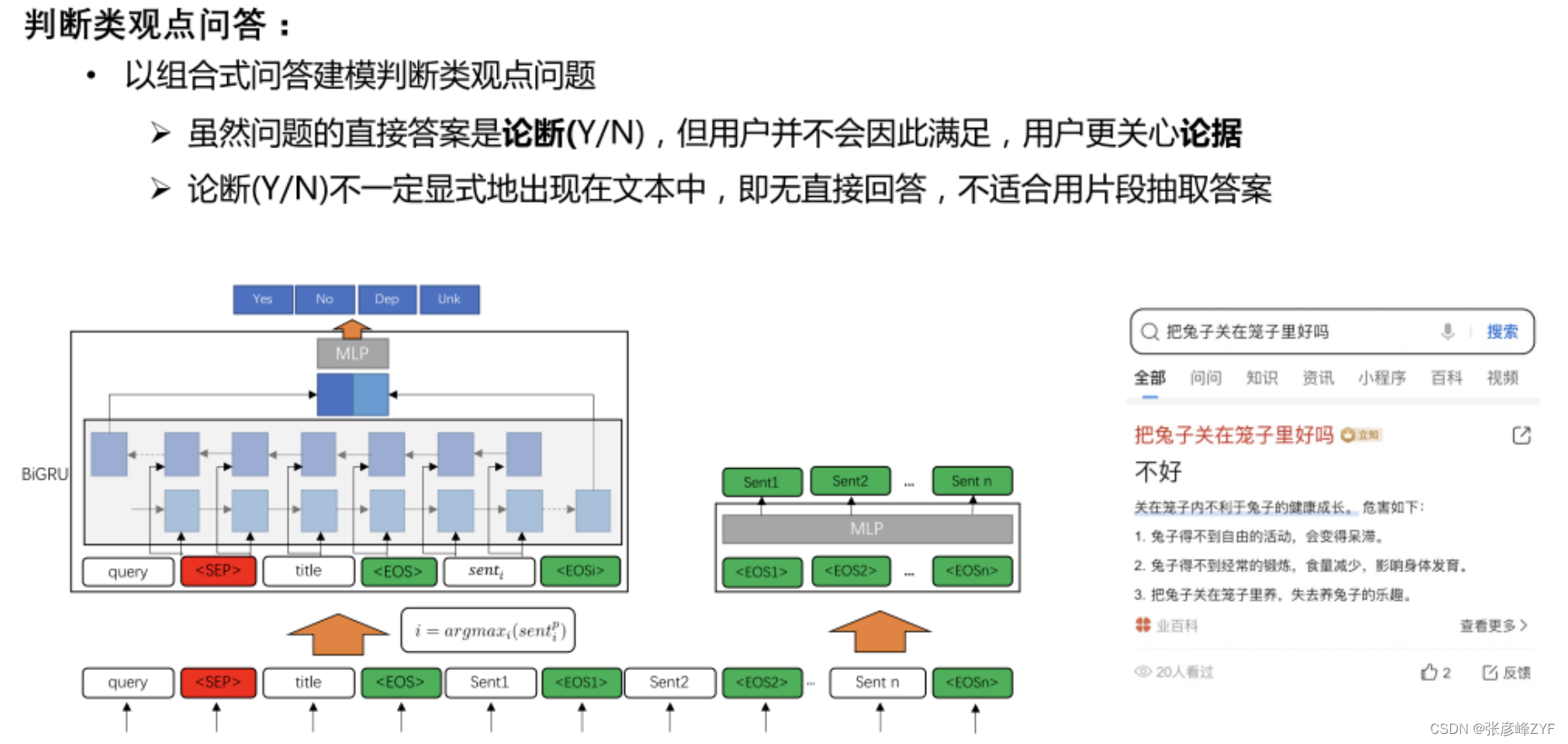
搜索问答技术学习:基于知识图谱+基于搜索和机器阅读理解(MRC)
目录 一、问答系统应用分析 二、搜索问答技术与系统 (一)需求和信息分析 问答需求类型 多样的数据源 文本组织形态 (二)主要问答技术介绍 发展和成熟度分析 重点问答技术基础:KBQA和DeepQA KBQA(…...
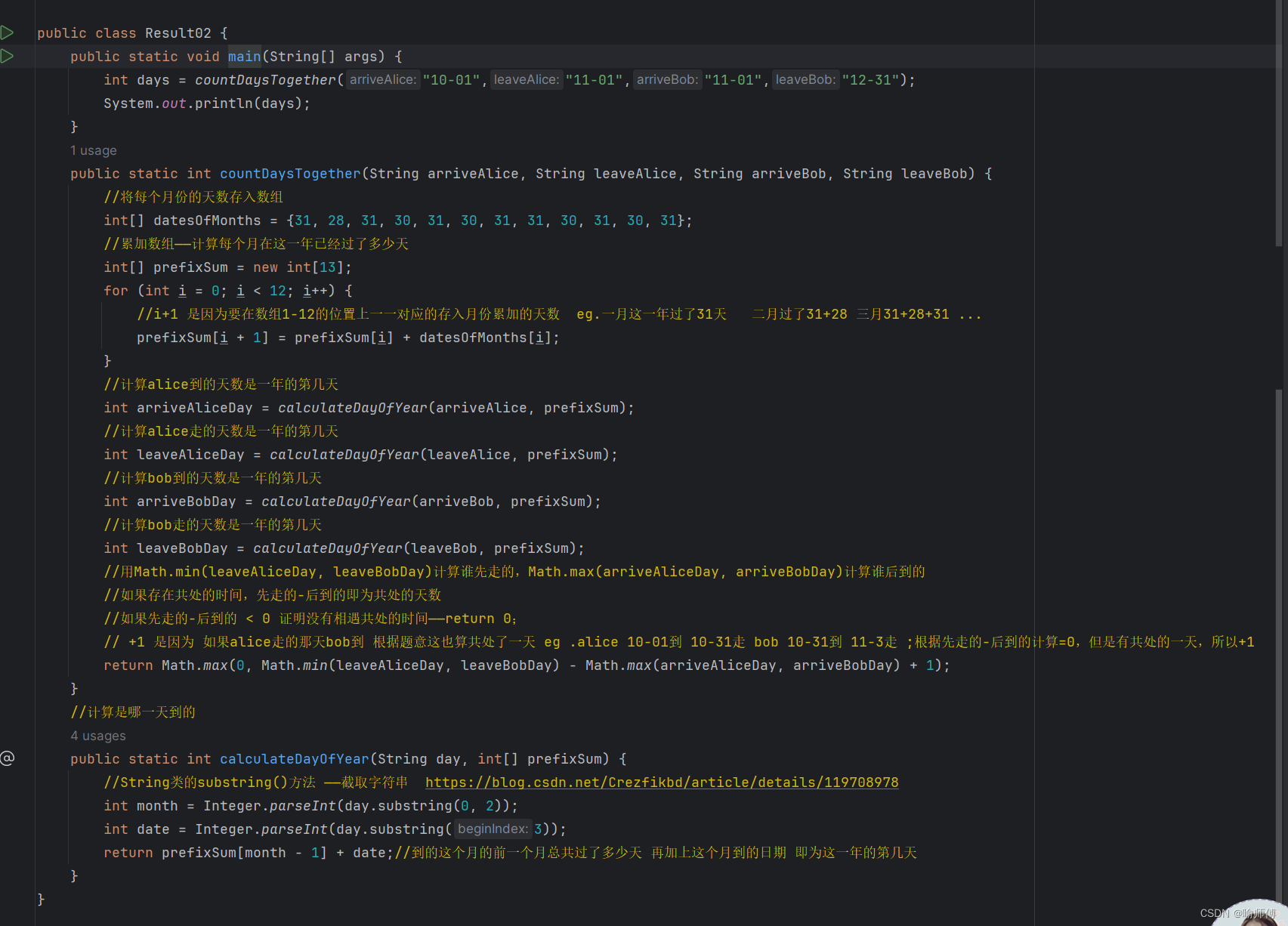
LeetCode2409——统计共同度过的日子数
博主的解法过于冗长,是一直对着不同的案例debug修改出来的,不建议学习。虽然提交成功了,但是自己最后都不知道写的是啥了哈哈哈。 package keepcoding.leetcode.leetcode2409; /*Alice 和 Bob 计划分别去罗马开会。给你四个字符串 arriveA…...

【MyBatisPlus】快速入门、常用注解、常用配置
🐌个人主页: 🐌 叶落闲庭 💨我的专栏:💨 c语言 数据结构 javaEE 操作系统 Redis 石可破也,而不可夺坚;丹可磨也,而不可夺赤。 MyBatisPlus 一、快速入门1.1 引入MyBatisP…...

【USRP】通信之:光通信
光通信: 光通信是使用光信号(通常是红外或可见光信号)在光纤或空气中传输信息的技术。由于光信号的特性,光通信具有非常高的数据传输率和长距离传输能力。以下是光通信的一些关键组件和概念: 光纤: 是由非常纯净的玻璃…...

bpf对内核的观测
目录 1 bpftrace常用命令1.1 列出bpftrace 相关命令的list1. 2bpftrace -e 是执行1.3 查看参数 -lv 2 bpftrace 可以用到的变量3 高级3.1 内置函数3.2 文件系统3.3 内核内存 栈3.4 Malloc 调用 统计3.5 系统调用 brk 的 统计3.6 脚本调用 4 应用5 怎么串联起来呢 bpftrace 总的…...

Buildroot外部工具链路径解析:从权限问题到正确配置
1. Buildroot外部工具链路径问题解析 第一次用Buildroot配置外部工具链时,我遇到了一个典型的路径解析问题。当时选择的工具链路径是/opt/cross-toolchain/bin/arm-linux-gnueabihf-gcc,编译过程中却报错提示找不到libgcc_s.so。这种问题看似简单&#x…...
完全解析)
【传统图像分割算法】- 图像分割之自适应阈值(Adaptive Thresholding)完全解析
一、自适应阈值核心定义与应用价值 在二值化图像处理中,我们常常会遇到一个问题:全局阈值法(如固定阈值、Otsu 大津法无法适配光照不均匀的图像。当图像存在明暗差异、局部阴影、反光等情况时,全局阈值会导致亮区过分割、暗区欠分…...

避坑指南:RK3588部署YOLOv8时,模型转换与板端环境那些容易忽略的细节
RK3588部署YOLOv8避坑实战:模型转换与板端环境的七个关键陷阱 当你在RK3588上部署YOLOv8时,是否遇到过这样的场景:按照官方文档一步步操作,却在模型转换或板端推理时莫名失败?这很可能是因为忽略了某些"隐藏规则…...

阿里开源大模型Qwen2.5-7B实测:离线推理+结构化输出,提升数据处理效率
阿里开源大模型Qwen2.5-7B实测:离线推理结构化输出,提升数据处理效率 1. 引言:为什么选择Qwen2.5-7B进行离线推理 在当今数据驱动的业务环境中,企业面临着海量数据处理的需求。传统的大模型在线推理方式虽然灵活,但在…...
)
JS——动态判断节假日(支持自定义节假日与调休规则)
1. 为什么需要动态判断节假日? 在日常开发中,我们经常会遇到需要判断某一天是否是节假日的场景。比如电商平台的促销活动页面需要显示"节假日不发货"的提示,或者企业考勤系统需要自动计算员工的休假天数。传统的做法是硬编码节假日…...

STIX Two字体:解决学术文档跨平台符号显示问题的专业方案
STIX Two字体:解决学术文档跨平台符号显示问题的专业方案 【免费下载链接】stixfonts OpenType Unicode fonts for Scientific, Technical, and Mathematical texts 项目地址: https://gitcode.com/gh_mirrors/st/stixfonts 你是否曾遇到过这样的困扰&#x…...

Windows驱动清理完全指南:使用DriverStore Explorer轻松管理驱动存储
Windows驱动清理完全指南:使用DriverStore Explorer轻松管理驱动存储 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer 你是否曾因C盘空间不足而烦恼?是否遇到过因…...

【爬虫实战对比】Requests vs Scrapy 笔趣阁小说爬虫,从单线程到高效并发的全方位升级
【爬虫实战对比】Requests vs Scrapy 笔趣阁小说爬虫,从单线程到高效并发的全方位升级 近期完成了笔趣阁小说爬虫的重构,从最初的Requests单线程版本,升级为Scrapy框架版本,过程中深刻体会到两者在开发效率、运行性能、代码可维护…...
)
Java Loom + R2DBC + VirtualThread三重奏:构建零阻塞数据库访问层(含GraalVM原生镜像适配方案)
第一章:Java Loom响应式编程转型的背景与核心价值长期以来,Java 的并发模型依赖线程(Thread)作为基本执行单元,但传统线程是重量级操作系统资源,受限于内核调度开销与内存占用(每个线程栈默认 1…...

显微图像拼接的三大困境与MIST的突破性解决方案
显微图像拼接的三大困境与MIST的突破性解决方案 【免费下载链接】MIST Microscopy Image Stitching Tool 项目地址: https://gitcode.com/gh_mirrors/mist3/MIST 你是否曾经面对数百张高分辨率显微图像,却苦于找不到一个既快速又精准的拼接工具?当…...