MySQL知识详细汇总
存储引擎
- MyISAM 不支持事务,不支持外键,支持全文索引,查询、插入效率高
- InnoDB 支持事务(事务的特性)
- 原子性:一个事务中所有的操作,要么全部完成,要么全部不完成,不会在中间停止,执行时发生错误,会回滚(Rollback)到事务开始的状态。
- 一致性:事务开始之前结束之后,数据库的完整性没有破坏。
- 隔离性:数据库允许多个并发事务同时对数据进行读写和修改,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。
- 持久性:事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
范式
-
候选码:能唯一的标示一个元组,若元组中有很多候选码,选一个为主码(候选码的属性称为主属性)
-
1NF强调列的原子性,表中的列不能再分,不能表中有表。
-
2NF基于1NF之上,表中必须又一个主属性,每个非主属性完全依赖于主属性,而不能只依赖一其中部分。
学号 系名 宿舍楼 课程 分数 主键 (学号 课程)1 通院 16# python 90 系名部分依赖于(学号 课程) <知道学号 或者 课程就能确定系名>宿舍楼部分依赖于(学号 课程) 不完全依赖于候选码 不属于2NF -
3NF基于2NF之上,非主属性必须直接依赖于主属性,不能出现传递依赖,
A 主键 B 非主键 C非主键
C依赖于B,B依赖于A
不符合3NF:
学号 姓名 年龄 学院 学院电话 学院长(学院长 学院电话)-----> 学院 -------> 学号符合:
学号 姓名 年龄 学院学院 学院长 学院电话 -
BC范式 表里除了主键,其他的列不能存在唯一信息 (下面不符合,除了学号,邮箱也能唯一标示一行)
学号 姓名 邮箱1 张三 zhang@123.com2 李四 li@123.com5 张三 zhang1@123.com -
4NF 表里不能有多值依赖,
学号 姓名 语言
1 张三 英语、汉语、韩语符合 学号 姓名 语言 1 张三 英语学号 姓名 语言 1 张三 汉语学号 姓名 语言 1 张三 汉语 -
总结
-
1NF不能表中有表
-
2NF非主键不能依赖主键中的一部分
-
3NF非主键不能依赖非主键
-
BCNF每一行只能有一个唯一标识属性
-
4NF一列中不能有多值
SQL基本操作
-
创建表
CREATE TABLE `userprofile` (`id` int(11) NOT NULL AUTO_INCREMENT,`name` varchar(10) DEFAULT NULL,`age` int(11) DEFAULT NULL,`department_id` int(11) DEFAULT NULL,PRIMARY KEY (`id`),constraint `fk` foreign key (`department_id`) references `department`(`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8;- AUTO_INCREMENT 自增,表里只能有一个(每插入数会自动增加),可以修改 alter table userprofile AUTO_INCREMENT=5
- PRIMARY KEY 主键约束,不能重复,不能为空,加速查找
- CHARSET=utf8 字符集支持中文
-
清空表
truncate table userprofile; 可以删除自增id和数据,整体删除不写logdelete from userprofile; 逐条删,写log,速度慢 -
删除表
drop table userprofile; -
查看表结构
desc userprofile; -
查看创建语句,\G 竖行表示
show create table userprofile \G; -
查看函数创建语句
show create function function_name; -
查看存储过程创建语句
show create procedure proce_name; -
创建root用户远程
create user 'root'@'%' indentified by '123456';grant all privileges on *.* to 'root'@'%';flush privileges;
约束
主键约束:primary key 唯一 非空
外键约束:foreign key 另一个表的主键,值只能在里面选
唯一约束:unique key 唯一
非空约束:not null 不为空
查询
-
限值
limit 10 取十条
limit 10, 20 从11条开始 取20条 -
偏移
limit 10 offset 20 从21条开始,取10条 -
排序
order by asc 顺序
desc 逆序 -
分组
group by
聚合函数
最大值 max
最小值 min
求和 sum
求平均 avg
求数量 countselect count(id), max(id) as max_id, department_id from userprofile group by department_id order by max_id desc; -
连表
-
left join 左连接
select * from user left join department on user.department_id=department.id;显示user左边的数据 右边的表没数据为NULL
select * from department left join user on user.department_id=department.id;显示department左边数据
-
right join 右连接
显示右边的数据 左边的表没数据为NULL
inner join 内连接
将null的行隐藏
-
视图
从一个或多个基本表导出的表。它本身不存储在数据库中,
只存放视图的定义,不存放视图对应的数据,视图是一个虚拟临时表,不能修改,开发人员不建议使用CREATE VIEW `view_userprofile` AS(SELECT * FROM userprofile WHERE id>2)
为什么使用视图1、重复SQL语句2、将复杂得SQL操作,转换成虚拟表3、保护数据,可以将表得特定部分授权,而不是整个表
视图得特点1、不能索引,不能有关联的触发器和默认值2、可以和表一起使用3、不能修改
触发器
触发器是一种特殊的存储过程,但是不会主动执行,满足条件时执行触发器中定义的sql语句,视图不支持# 插入前CREATE TRIGGER `trigger_name` BEFORE INSERT ON `table_name` FOR EACH ROWBEGINEND# 插入后CREATE TRIGGER `trigger_name` AFTER INSERT ON `table_name` FOR EACH ROWBEGIN...END# 删除前CREATE TRIGGER `trigger_name` BEFORE DELETE ON `table_name` FOR EACH ROWBEGIN...END# 删除后CREATE TRIGGER `trigger_name` AFTER DELETE ON `table_name` FOR EACH ROWBEGIN...END# 更新前CREATE TRIGGER `trigger_name` BEFORE UPDATE ON `table_name` FOR EACH ROWBEGIN...END# 更新后CREATE TRIGGER `trigger_name` AFTER UPDATE ON `table_name` FOR EACH ROWBEGIN...END其中 NEW表示即将插入的数据行,插入、更新OLD表示即将删除的数据行,更新、删除
-
创建触发器
DELIMITER // # 修改结束符 -
在 userprofile表中插入数据之前触发
CREATE TRIGGER `update_record` BEFORE INSERT ON `userprofile` FOR EACH ROW begininsert into update_log(record_name, update_time) values(NEW.name, NOW());end//DELIMITER ; # 还原结束符 -
删除触发器
DROP TRIGGER update_record;
存储过程
-
为什么要用存储过程
- 简化复杂的操作和事务
- 保证数据完整性和一致性,(不需要重复建立执行逻辑,测试和开发使用相同的过程)
- 简化变动,逻辑发生变化时,只需修改存储过程,对使用者是透明的
- 提高性能,存储过程是编译过的,执行速度较快
-
SQL语句的集合:
- 速度快,创建的时候编译一次
- 只需连接一次,降低SQL语句在网络中的传输延时
- 隐藏逻辑
-
缺点:
- 编写较复杂,需要更高的技能和经验
- 调试麻烦
- 移植性差,每种数据库语法不同
-
创建
delimiter //create procedure p1()BEGINSELECT * FROM userprofile;insert into userprofile(name, age, department_id) values ('hadoop', 12, 2);END //delimiter; -
执行
call p1() -
传参
in 仅用于传入参数out 传出参数,用于返回值inout 即可传入又可传出 -
与函数区别
-
函数有返回值
-
函数不能有 insert update delete create 语句
-
存储过程可以调用函数,函数不能调用存储过程
delimiter \\create procedure p1(in i1 int,in i2 int,inout i3 int,out r1 int)BEGIN-- 声明局部变量DECLARE temp1 int;DECLARE temp2 int default 0;set temp1 = 1;set r1 = i1 + i2 + temp1 + temp2;set i3 = i3 + 100;end\\delimiter ;-- 执行存储过程-- 设置变量,以@开头set @t1 =4;set @t2 = 0;-- 查看结果集1CALL p1 (1, 2 ,@t1, @t2);-- 查看结果集2SELECT @t1,@t2;CREATE DEFINER=`root`@`%` PROCEDURE `getAppendixModulus`(IN `id` int, IN `ge` VARCHAR(255))BEGIN-- 声明变量 modu 字符串类型 默认值是 ''DECLARE modu VARCHAR(255) default '';IF n > 100 THEN-- case 逻辑CASE geWHEN '99%' THENSET modu = 2.3265/SQRT(n);WHEN '95%' THENSET modu = 1.6449/SQRT(n);WHEN '90%' THENSET modu = 1.2815/SQRT(n);END CASE;ELSEIF n >= 2 AND n <= 100 THENSELECT modulu into modu from appendix_modulus WHERE appendix_modulus.n=n and appendix_modulus.guarantee_rate = ge;END IF;-- 保留三位小数SELECT ROUND(modu, 3);END
-
函数
字符串截取
SUBSTRING_INDEX(SUBSTRING_INDEX('1,2,3,4,5', ',', 2), ',', -1)
根据 , 分割,先取前两位 再取结果中的最后一位 也就是整体的第二位
索引
-
userprofile 中有10万条数据,如果没有索引,查询的时候MySQL会从第一行开始遍历,直到找到符合条件的。
-
如果将数据通过一定的方法进行存储,查询的时候,不需要再从第一行开始,这就是索引。
-
MySQL中有两种
-
B-TREE
MyISAM和InnoDB默认,不能修改,多路搜索树,查询速度默认是log(n), 左节点小于根节点,右节点大于根节点,左右子树都是搜索树,红黑树 平衡树,高度比B树高,树的查找性能取决于树的高度,高度越高,性能越低,在内存种,红黑树比B树性能好,在文件系统种,B树比红黑树好 -
HASH
单值查询比较快,范围查询比较慢,HASH是无序的,用作order by group by ,比较慢精确查询单值比较快,范围慢(hash表是无序的),不能用于排序和分组,查询速度是O(1)
-
-
创建索引(会额外创建文件保存这种数据结构)
create index id_index on userprofile(id); -
注意 如果是BLOB TEXT 类型,要指定他的长度
create index ix_extra on in1(extra(32)) -
删除
drop id_index on userprofile; -
查看
show index from userprofile;Non_unique 如果索引不能包括重复词,则为0。如果可以,则为1Key_name 索引的名称Seq_in_index 索引中的列序列号,从1开始Column_name 列名称Collation 列以什么方式存储在索引中。在MySQL中,有值A(升序)或NULL(无分类)Cardinality 索引中唯一值的数目的估计值Sub_part 如果列只是被部分地编入索引,则为被编入索引的字符的数目。如果整列被编入索引,则为NULLPacked 指示关键字如何被压缩。如果没有被压缩,则为NULL。Null 如果列含有NULL,则含有YES。如果没有,则该列含有NO。Index_type 用过的索引方法(BTREE, FULLTEXT, HASH, RTREE)B-TREE B树FULLTEXT 全文索引HASH HASH索引 -
分类
-
普通索引:加速查找
-
唯一索引: 加速,唯一约束(可以为NULL)
create unique index id_index on userprofile(id); -
主键索引:加速, 唯一约束(不可为NULL,因为主键不能为NULL)
-
组合索引:将多个列设置为索引(同时用多条件查询,在该条件下,比单个索引效率高,遵循最左前缀)
create index id_email_index on userprofile(id, email)-
最左前缀,匹配
select * from userprofile where id=9999;select * from userprofile where id=9999 and email='apache333@tomcat'; -
不匹配
select * from userprofile where email='apache333@tomcat';
-
-
覆盖索引:查询的索引那列,可以直接从索引文件中获取,索引文件被读到内存中
create index id_index on userprofile(id);select id from userprofile where id=999; -
索引合并:多个单列索引,合并使用
select * from userprofile where id=999 and email='apache333@tomcat.com';
-
-
不命中
-
like ‘%xx’
select * from userprofile where name link '%spart'; -
使用函数
select * from userprofile where reverse(email)='apache'; -
or
select * from userprofile where id=999 or name='spart';-- 以下会走索引select * from userprofile where id=99999 or email='apache333@tomcat'select * from userprofile where id=9999 or name='spart' and email='apache3300@tomcat' -
类型不一致
注意字符串和字符串数字 email=999 和 email=‘999’ -
!= 如果是主键会走索引
-
> 如果是主键或索引是整数,会走索引
-
order by 如果是索引列,或主键,会走索引
-
-
执行计划
explain 预估执行时间all < index < range < index_merge < ref_or_null < ref < eq_ref < system/constexplain select * from userprofile; type: ALL (全表扫描)explain select * from userprofile where id=9999; type:const (索引) -
优化方案
- 避免全表扫描,首先应该考虑在where及orderby涉及的列上建立索引
- 避免在where子句中对字段null值判断,导致引擎放弃使用索引,进行全表扫描,可以将null值设置为0来规避
- 避免在where子句中使用!= 或>操作符,导致全表扫描
- 避免使用or来连接条件,使用select emp_no from salaries where emp_no=10009 union all select emp_no from salaries where emp_no=10008;
- 慎用in 和 not 可以用exists代替in
- 慎用like 可以用全文检索
- 避免在where中对列使用计算表达式
- 避免在where中对列进行函数操作
- 复合索引,尽可能让字段顺序与索引顺序一致,并且满足最左前缀原则
- 避免在大量重复的列上建索引,比如性别列,只有男或女,或者年龄列
- 索引不是越多越好,可以提高select效率,同时降低insert 和update的效率,因为会重建索引
- 不要使用select * from table,用具体字段代替*
- 避免频繁创建删除临时表,以减少系统资源消耗
- 建立临时表时,如果一次插入数据量大,那么可以使用select into 代替create table造成大量log,如果数据不大,先create table 然后insert
- 尽量避免向客户端返回大数据量,数据量大,应该考虑相应需求是否合理
- 分表分库,垂直分表:将一些列分到另一张表
水平分表:将历史信息分到另一张表中,很久之前的记录少有查询 - 读写分离
- 利用缓存存储经常查询的数据,redis memcache
数据关系
一对一:一个学生只有一个档案,一个学号
一对多:一个学生属于一个班,一个班有多个学生,学生表里有班级表的外键
多对多:一个学生可以选择多门课,一门课有多个学生选,多出一个关系表
事务
-
隔离级别
- READ UNCOMMITTED 读取未提交内容,A启动一个事务,执行UPDATE暂未提交,此时B也启动一个事务,读取A更新但未提交的数据,如果A由于某种原因回滚,导致B出现脏读;
- READ COMMITTED 读取提交内容,A启动一个事务,执行UPDATE暂未提交,此时B读取的数据是未更新的数据,等A提交后,B才能读到更新后的数据,此时出现的问题就是不可重复读,重读的数据有可能不相同;
- REPEATABLE-READ 可重读,MySQL默认级别,A B同时启动一个事务,A执行UPDATE并提交,此时B事务看不见更新,只有B也提交后再查询能看见变化,此时出现幻读问题;
- SERIALIZABLE 可串行化,A启动一个事务,B也启动一个事务,在A没有提交之前,B不能更改数据。
-
操作
-
事务默认提交
show variables like 'autocommit'; -- 查看是否默认提交set autocommit=0; -- 关闭自动提交 -
查看事务隔离级别
SELECT @@global.tx_isolation; -- 查看全局SELECT @@session.tx_isolation; -- 查看会话 SELECT @@tx_isolation; -- 查看当前会话 -
读未提交
A:-- 修改当前会话级别 set session TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;start TRANSACTION; --开始事务select * from `user`;-- 等B更新了,未提交再查,读到已修改未提交的内容 ---> 如果B回滚,A就会产生脏读select * from `user`;B:set session TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;start TRANSACTION;update `user` set `name`='sparknb' where id=6; -
读已提交
A:-- 修改当前会话级别 set session TRANSACTION ISOLATION LEVEL READ COMMITTED;start TRANSACTION; --开始事务-- 等B更新了,未提交再查,读到未修改未提交的内容,当B提交后,A读到修改后的内容 ---> 重复读的时候数据可能不一致, 不可重复读select * from `user`; B:set session TRANSACTION ISOLATION LEVEL READ COMMITTED;start TRANSACTION;update `user` set `name`='sparknb' where id=6;COMMIT; -- 提交 -
可重复读
A:set session TRANSACTION ISOLATION LEVEL REPEATABLE READ;start TRANSACTION;select * from `user`; 6 sparknp 1-- 等B更新了,提交后,读取的还是原来内容,select * from `user`;-- 当A做更新的时候,会发现结果是已经修改过的,------> 此时出现幻读update `user` set `name`=CONCAT(name, '456') where id=6;select * from `user`;6 spark123456 1B:set session TRANSACTION ISOLATION LEVEL REPEATABLE READ;start TRANSACTION;update `user` set `name`='spark123' where id=6;COMMENT; -
串行
A:set session TRANSACTION ISOLATION LEVEL SERIALIZABLE;start TRANSACTION;select * from `user`;-- 未提交之前 A会锁住数据库,不让其他事务执行COMMIT;B:set session TRANSACTION ISOLATION LEVEL SERIALIZABLE;start TRANSACTION;-- A开启一个事务执行查询操作,未提交,此时B开启一个事务执行插入,会阻塞,等待A提交后,B才会继续执行插入操作INSERT INTO `bbs`.`user` (`id`, `name`, `department_id`) VALUES ('11', 'kafka', '1'); -
MYSQL默认是可重复读级别
MYSQL 主从复制的时候,使用binlog来恢复数据,就是在master上执行的顺序为先删后插!而此时binlog为STATEMENT格式,它记录的顺序为先插后删!所以采用可重复读
-
日志
- 错误日志 记录出错的、警告信息
- 查询日志 记录所有对数据请求的信息
- 满查询日志 设置一个阈值,将运行时间超过该值的SQL记录下来
- 二进制日志 记录对数据库执行更改的所有操作
封锁
-
排它锁 称为写锁,若事务T对对象A加上X锁,则只允许T读取和修改A,其他任何事物都不能再对A 加任何锁,直到T释放A上的锁。
-
共享锁 称为读锁,若事务T对数据对象A加上S锁,则事务T可以读A,但不能修改A,其他事务只能再对A加S锁,而不能加X锁,直到T释放A上的S锁。
-
活锁 事务T1封锁了R,T2又请求封锁R,于是T2等待,T3也请求封锁R,当T1释放了R 上的锁,系统首先批准了T3的请求,T2继续等待,这就是活锁。
-
死锁 事务T1封锁了R1,T2封锁了R2,T1又请求封锁R2,因为T2已经封锁了R2,于是T1等待T2释放R2上的锁,接着T2又申请封锁R1,因为T1已经封锁了R1,T2只能等待T1释放R1上的锁,这就是死锁。
-
解决死锁的方法:一次封锁法 每个事务必须将所有要使用的数据全部加锁,否则就不能执行,弊端 加大封锁范围,降低了并发速度。
问题
*一张表里,id是自增主键,当insert 17条记录,删除了第15,16,17条记录,再重启mysql,再insert一条记录,此时ID是多少?如果表引擎类型是MyISAM,是18,会把自增主键最大记录到文件里,重启不会丢失如果是InnoDB,是15,会把自增主键记录到内存里,重启或对表进行OPTIMIZE操作,都会丢失。
1、查找最晚入职员工的所有信息
select * from employees order by hire_date desc limit 1可能有多条数据select * from employees where hire_date in (select max(hire_date) from employees)
2、查找入职员工时间排名倒数第三的员工
select * from employees where hire_date = (select hire_date from employees order by hire_date desc limit 2,1);
3、查找当前薪水详情以及部门编号dept_no
select s.*, d.dept_no from salaries s, dept_manager d where s.emp_no=d.emp_no and d.to_date='9999-01-01' and s.to_date='9999-01-01';select salaries.*, dept_manager.dept_no from salaries join dept_manager on dept_manager.emp_no=salaries.emp_no and dept_manager.to_date='9999-01-01' and salaries.to_date='9999-01-01';
4、查找所有已经分配部门的员工的last_name和first_name
select employees.last_name, first_name, dept_emp.dept_no from employees inner join dept_emp on employees.emp_no=dept_emp.emp_no
5、查找所有员工的last_name和first_name以及对应部门编号dept_no,也包括展示没有分配具体部门的员工
select employees.last_name, first_name, dept_emp.dept_no from employees left join dept_emp on employees.emp_no=dept_emp.emp_no
6、查找薪水涨幅超过15次的员工号emp_no以及其对应的涨幅次数t(由于COUNT()函数不可用于WHERE语句中,故使用HAVING语句来限定t>15的条件)
select emp_no,count(emp_no) as t from salaries group by emp_no having t > 15;
7、找出所有员工当前(to_date=‘9999-01-01’)具体的薪水salary情况,对于相同的薪水只显示一次,并按照逆序显示
select distinct salary from salaries where to_date='9999-01-01' order by salary desc;
相关文章:

MySQL知识详细汇总
存储引擎 MyISAM 不支持事务,不支持外键,支持全文索引,查询、插入效率高InnoDB 支持事务(事务的特性) 原子性:一个事务中所有的操作,要么全部完成,要么全部不完成,不会在…...

【驱动开发】LED灯的亮灭——通过字符设备驱动的分步实现编写LED驱动,实现设备文件和设备的绑定
头文件: #ifndef __HEAD_H__ #define __HEAD_H__typedef struct {unsigned int MODER;unsigned int OTYPER;unsigned int OSPEEDR;unsigned int PUPDR;unsigned int IDR;unsigned int ODR; }gpio_t;//LED灯的寄存器地址 #define LED1_ADDR 0X50006000 #define L…...
【java】A卷+B卷)
华为OD 最小数字(100分)【java】A卷+B卷
华为OD统一考试A卷+B卷 新题库说明 你收到的链接上面会标注A卷还是B卷。目前大部分收到的都是B卷。 B卷对应20022部分考题以及新出的题目,A卷对应的是新出的题目。 我将持续更新最新题目 获取更多免费题目可前往夸克网盘下载,请点击以下链接进入: 我用夸克网盘分享了「华为O…...
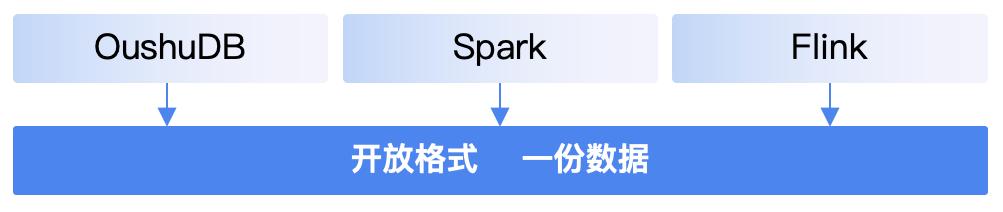
大模型、实时需求推动湖仓平台走向开放
大模型、实时需求高涨 AGI 时代,以 ChatGPT、Midjourney 等为代表的大模型迅速应用加速了 AI 普及,越来越多的企业选择搭建自己的 AI 基础设施,训练行业大模型。 另一方面,企业为了在瞬息万变的市场环境中更快的做出商业决策&…...
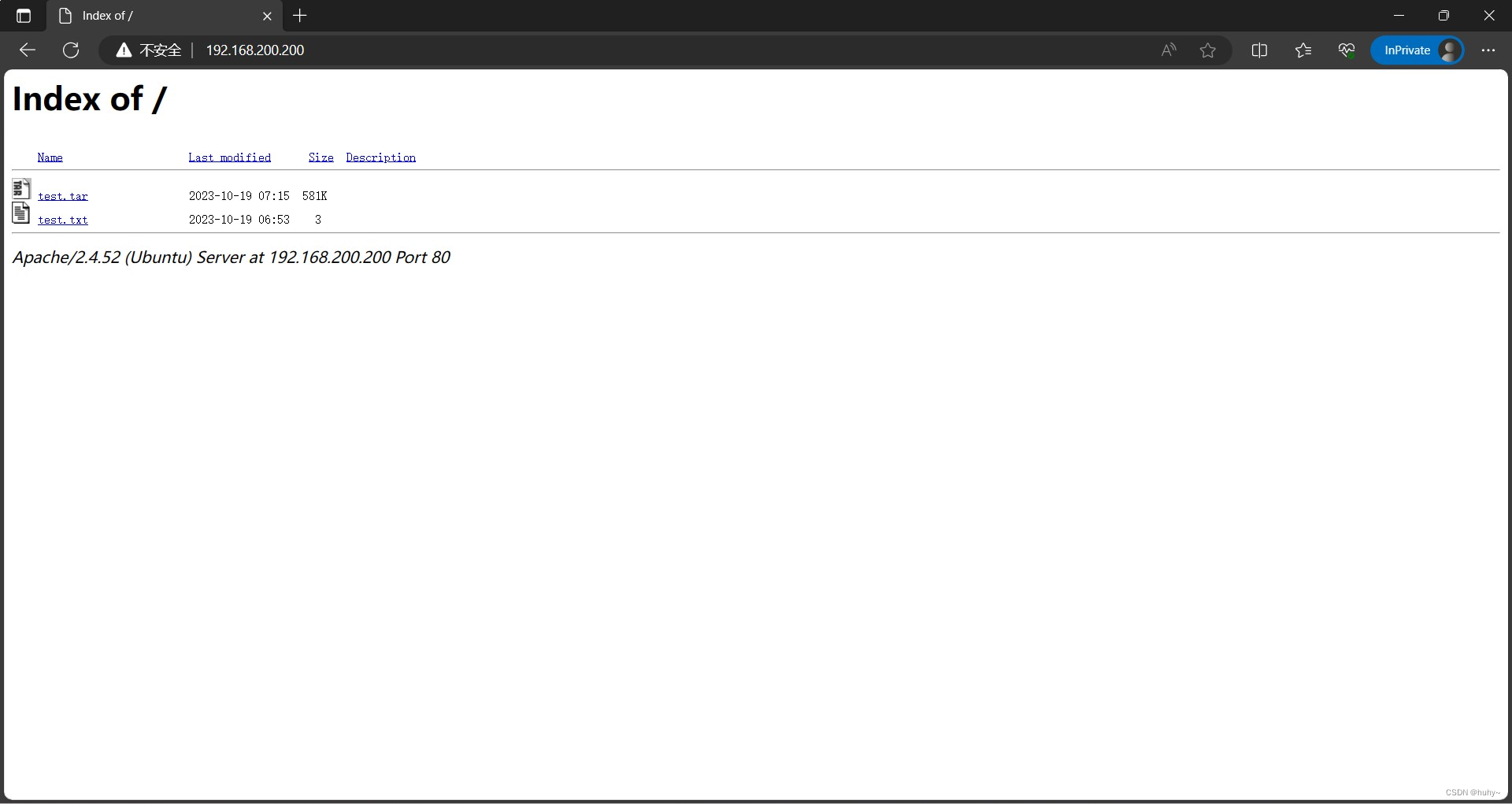
Linux搭建文件服务器
搭建简单文件服务器 基于centos7.9搭建http文件服务器基于centos7.9搭建nginx文件服务器基于ubuntu2204搭建http文件服务器 IP环境192.168.200.100VMware17 基于centos7.9搭建http文件服务器 安装httpd [rootlocalhost ~]# yum install -y httpd关闭防火墙以及selinux [roo…...
跨境商城源码可以支持多种支付方式吗?
跨境商城源码是一种用于建立跨国界电商平台的程序代码。随着全球电商的繁荣发展,越来越多的商家开始寻找一种既安全可靠,又能满足用户需求的支付方式。那么,跨境商城源码是否能够支持多种支付方式呢?让我们深入探讨一下。 1. 支付宝支付 支付…...
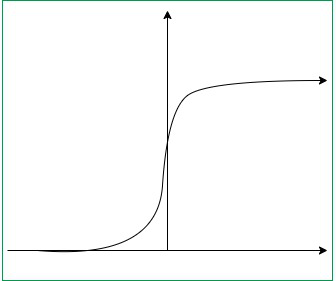
机器学习中的核方法
一、说明 线性模型很棒,因为它们易于理解且易于优化。他们受苦是因为他们只能学习非常简单的决策边界。神经网络可以学习更复杂的决策边界,但失去了线性模型良好的凸性特性。 使线性模型表现出非线性的一种方法是转换输入。例如,通过添加特征…...
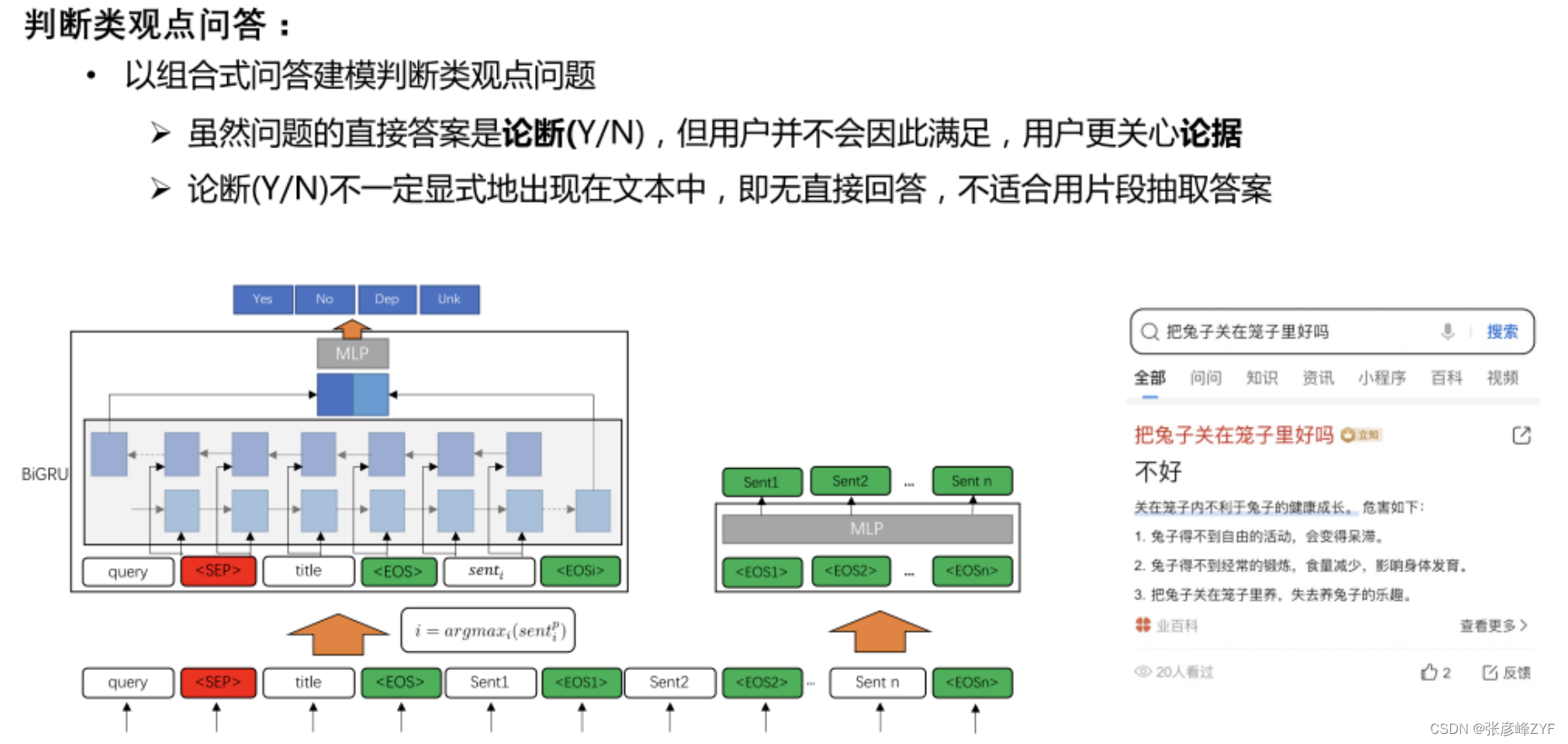
搜索问答技术学习:基于知识图谱+基于搜索和机器阅读理解(MRC)
目录 一、问答系统应用分析 二、搜索问答技术与系统 (一)需求和信息分析 问答需求类型 多样的数据源 文本组织形态 (二)主要问答技术介绍 发展和成熟度分析 重点问答技术基础:KBQA和DeepQA KBQA(…...
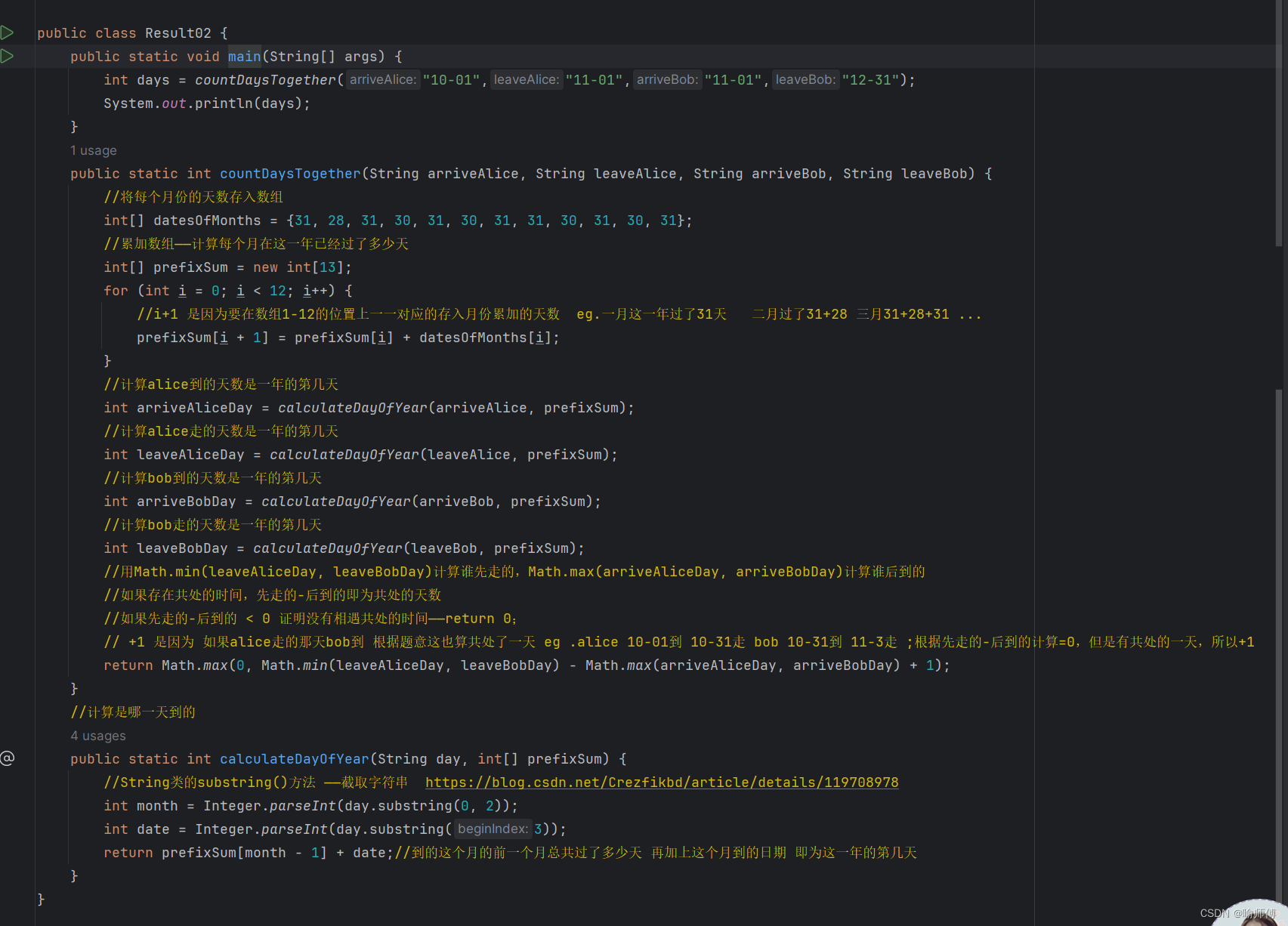
LeetCode2409——统计共同度过的日子数
博主的解法过于冗长,是一直对着不同的案例debug修改出来的,不建议学习。虽然提交成功了,但是自己最后都不知道写的是啥了哈哈哈。 package keepcoding.leetcode.leetcode2409; /*Alice 和 Bob 计划分别去罗马开会。给你四个字符串 arriveA…...

【MyBatisPlus】快速入门、常用注解、常用配置
🐌个人主页: 🐌 叶落闲庭 💨我的专栏:💨 c语言 数据结构 javaEE 操作系统 Redis 石可破也,而不可夺坚;丹可磨也,而不可夺赤。 MyBatisPlus 一、快速入门1.1 引入MyBatisP…...

【USRP】通信之:光通信
光通信: 光通信是使用光信号(通常是红外或可见光信号)在光纤或空气中传输信息的技术。由于光信号的特性,光通信具有非常高的数据传输率和长距离传输能力。以下是光通信的一些关键组件和概念: 光纤: 是由非常纯净的玻璃…...

bpf对内核的观测
目录 1 bpftrace常用命令1.1 列出bpftrace 相关命令的list1. 2bpftrace -e 是执行1.3 查看参数 -lv 2 bpftrace 可以用到的变量3 高级3.1 内置函数3.2 文件系统3.3 内核内存 栈3.4 Malloc 调用 统计3.5 系统调用 brk 的 统计3.6 脚本调用 4 应用5 怎么串联起来呢 bpftrace 总的…...

Tiktok shop api 调试
记录一下调试Tiktok shop api 踩坑记录。 主要是在按官网api上规则和加密生成sign时候一直通不过的问题: 官网地址:https://partner.tiktokshop.com/doc/page/63fd743e715d622a338c4eab 直接贴代码了 import lombok.extern.slf4j.Slf4j;import javax.cr…...

QFSFileEngine::open: No file name specified解决方案
问题 使用QFile类进行文件操作时,报错QFSFileEngine::open: No file name specified。 原因 QFile::open: No file name specified是Qt中的一个错误消息,提示没有指定文件名导致文件无法打开。这个错误通常出现在使用QFile::open()函数时没有提供有效…...

Flappy bird项目
一、功能分析 1、小鸟自动向右滑行 2、按下空格小鸟上升,不按下落 3、显示小鸟需要穿过的管道 4、管道自动左移和创建 5、小鸟和管道碰撞,游戏结束 6、技术 7、 项目框图 8、Ncurses 1)创建窗口界面,移动光标,产…...

高校教务系统登录页面JS分析——西安科技大学
高校教务系统密码加密逻辑及JS逆向 本文将介绍高校教务系统的密码加密逻辑以及使用JavaScript进行逆向分析的过程。通过本文,你将了解到密码加密的基本概念、常用加密算法以及如何通过逆向分析来破解密码。 本文仅供交流学习,勿用于非法用途。 一、密码加…...

Mysql 事务的实现原理
Mysql 里面的事务,满足 ACID 特性,所以Mysql 的事务实现原理,就是InnoDB 是如何保证 ACID 特性的。 ACID A 表示 Atomic 原子性,也就是需要保证多个 DML 操作是原子的,要么都成功,要么都失败。那么…...
使用vscode搭建虚拟机
首先vscode插件安装 名称: Remote - SSH ID: ms-vscode-remote.remote-ssh 说明: Open any folder on a remote machine using SSH and take advantage of VS Codes full feature set. 版本: 0.51.0 VS Marketplace 链接: https://marketplace.visualstudio.com/items?it…...

C# 使用 LibUsbDotNet 实现 USB 设备检测
国庆节回来后的工作内容,基本都在围绕着各种各样的硬件展开,这无疑让本就漫长的 “七天班” ,更加平添了三分枯燥,我甚至在不知不觉中学会了,如何给打印机装上不同尺寸的纸张。华为的 Mate 60 发布以后,人群…...

系统安全分析与设计
系统安全分析与设计(2分) 内容提要 对称加密与非对称加密 加密技术与认证技术 加密技术(只能防止第三方窃听) 讲解地址:对称加密与非对称加密_哔哩哔哩_bilibili 认证技术 骚戴理解:数字签名是用私钥签名…...

4步实战精通微信聊天记录解密技术
4步实战精通微信聊天记录解密技术 【免费下载链接】WechatDecrypt 微信消息解密工具 项目地址: https://gitcode.com/gh_mirrors/we/WechatDecrypt 微信作为中国最主流的即时通讯工具,每天承载着数十亿条重要对话,但当你需要迁移设备、恢复误删记…...
)
从零开始:在CentOS 7上使用Docker快速搭建OpenVAS漏洞扫描环境(附详细配置步骤)
从零构建企业级漏洞扫描平台:CentOS 7DockerOpenVAS全实战指南 在网络安全日益重要的今天,漏洞扫描已成为企业IT基础设施的标配防护手段。OpenVAS作为开源的漏洞评估系统,凭借其全面的漏洞检测能力和持续更新的漏洞数据库,成为众多…...

【架构实战】API接口防刷与限流策略
一、接口防刷概述 接口防刷是保护系统安全的重要手段: 常见攻击: 暴力破解密码恶意爬虫刷接口(抽奖、秒杀)CC攻击 二、限流算法 1. 计数器算法 Component public class CounterRateLimiter {public boolean tryAcquire(String key…...

浙江金华车间酷热难挡?蒸发冷省电空调能否解决降温难题?
浙江金华的夏季,车间内酷热难挡是许多企业面临的难题。高温不仅让员工工作体验变差,还可能影响生产效率。这时,蒸发冷省电空调成为备受关注的解决方案。蒸发冷省电空调的制冷原理有其独特之处。它需要压缩机、制冷剂进行内循环制冷。压缩机作…...

QGroundControl 4.0地面站新手入门:从零开始规划你的第一次无人机任务
QGroundControl 4.0地面站新手入门:从零开始规划你的第一次无人机任务 第一次接触无人机地面站软件时,那种既兴奋又忐忑的心情我至今记忆犹新。QGroundControl作为开源无人机生态中最受欢迎的地面控制站之一,其4.0版本在用户体验和功能完整性…...

Python定时任务实战:让脚本自己跑起来
为什么需要定时任务? 手动执行脚本很麻烦?定时任务来帮你! 常见场景: 每天2点自动备份数据库 每小时抓取一次股票价格 每周一发送工作周报 每月1号生成月度报表 本文教你多种方式实现Python定时任务,让脚本自动化运行! 方案一:使用schedule库(推荐新手) 简介 sch…...
---HITL(Human In The Loop)贡)
【GUI-Agent】阶跃星辰 GUI-MCP 解读---()---HITL(Human In The Loop)贡
插件化架构 v3 版本最大的变化是引入了模块化插件系统。此前版本中集成在核心包里的原生功能,现在被拆分成独立的插件。 每个插件都是一个独立的 Composer 包,包含 Swift 和 Kotlin 代码、权限清单以及原生依赖。开发者只需安装实际用到的插件࿰…...

信号完整性入门避坑:为什么你的PCB板总在‘振铃’?从阻抗不连续说起
信号完整性实战指南:从振铃现象到阻抗匹配的工程思维 实验室里,示波器屏幕上那道本该平滑的方波信号边缘,此刻却像被风吹皱的水面般上下起伏——这种被称为"振铃"的现象,是每位硬件工程师成长路上的必修课。当你的PCB设…...

智赋学术・真实赋能|虎贲等考 AI:全流程论文写作辅助平台,以真文献・真数据・真工具重构学术创作
虎贲等考 AI 智能写作(https://www.aihbdk.com/)是一款基于人工智能深度模型研发的论文写作辅助工具,专注服务于本专科、硕士、博士等各阶段学生与科研人员,以全流程覆盖、真实学术资源、硬核实证工具、高度合规安全为核心定位&am…...

想转AI大模型开发?小白必看收藏:入门学习清单与实战技巧全解析!
本文为想进入AI大模型开发领域的小白或程序员提供实用建议,包括:避免裸辞,先试水学习;将数开经验转化为竞争优势;接受新手期,积累经验;不被高深名词PUA,先落地再优化。文章还提供了A…...