【C++项目】高并发内存池第二讲中心缓存CentralCache框架+核心实现

CentralCache
- 1.框架介绍
- 2.核心功能
- 3.核心函数实现+介绍
- 3.1Span+SpanList介绍
- 3.2CentralCache.h
- 3.3CentralCache.cpp
- 3.4TreadCache申请内存函数介绍
- 3.5慢反馈算法
1.框架介绍
回顾一下ThreadCache的设计:
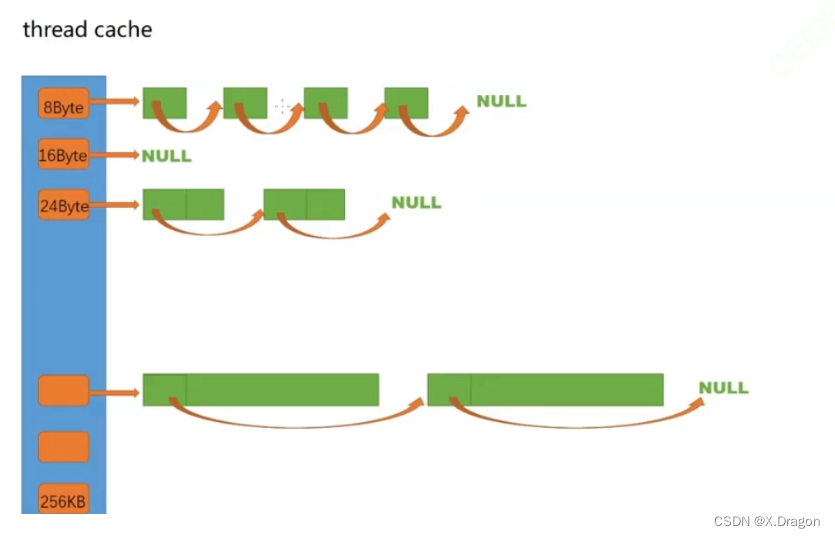
如图所示,ThreadCache设计是一个哈希桶结构,每一个桶挂的是一块切分好的小块内存块,每个线程独享一个ThreadCache。
CentralCache:
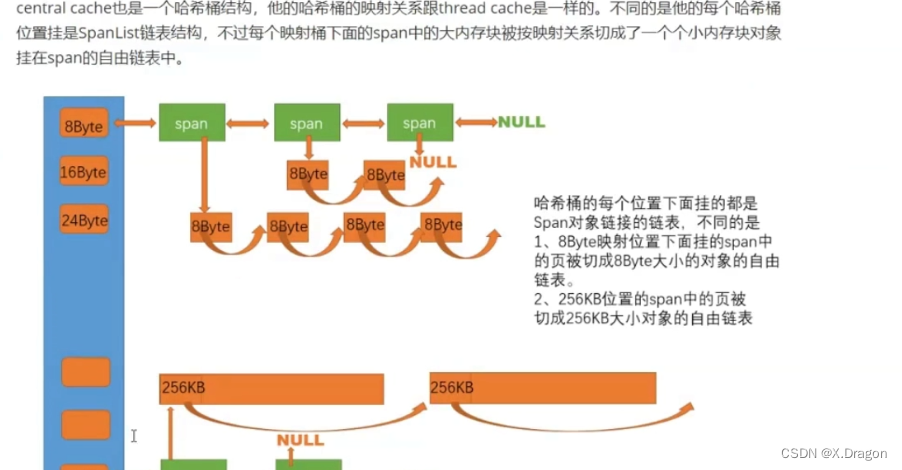
CentralCache也是一个哈希桶结构,跟ThreadCache的结构类似,只不过ThreadCache挂的是切分好的小对象内存块,而CentralCache挂的是一个spanlist 是一个连续的大块内存链表,链接着很多个span(大块内存)
而且根据下标映射的位置,切分好不同大小的对象,如第一个桶挂着8kb的小对象span,最后一个桶挂着大一些的 256kb的span,对象越小,span对象越多,反之。
2.核心功能
CentralCache作为中心调度,需要实现核心的内存分配调度工作,包括:
- 当ThreadCache内存不足时要向CentralCache申请,当CentralCache内存不足时再递进地向PageCache申请
- 当ThreadCache内存不用时,需要回收回来,再回收给PageCache,重新拼接成大块内存,解决内存碎片化问题
- 锁:因为涉及多个线程会访问同一个桶,所以要加锁实现 这里用到地是一个桶锁
- . 使用单例模式好处:
全局访问点:单例模式确保只有一个实例,并提供了一个全局的访问点,这样你可以在项目的任何地方访问 ‘CentralCache’ 的唯一实例。这对于管理和共享某些全局资源非常有用。
. 节省内存和初始化时间:饿汉模式确保 ‘CentralCache’ 在应用程序启动时创建,因此不需要等到实际需要它时再创建。这可以节省内存,并且初始化时间会更快,因为对象已经准备好。
线程安全:饿汉模式的单例在初始化时就创建了一个实例,因此它不需要考虑多线程竞争的问题。多线程环境下,多个线程访问单例时,它们都会引用相同的实例,而不会创建多个实例,因此不会导致竞争条件。
更容易管理:单例模式将全局状态和操作封装到一个类中,使代码更有组织性,易于维护和扩展。你可以通过单一的访问点执行与 ‘CentralCache’ 相关的操作。
. 有效资源管理:‘CentralCache’ 在内存池中起到了关键作用,以有效地分配和回收内存。它的唯一实例确保资源的一致性和高效的内存管理。
总之,使用单例模式可以更轻松地管理和访问 ‘CentralCache’ 的唯一实例,确保全局一致性和线程安全,节省内存和初始化时间,并使代码更具可维护性。这对于高并发内存池的实现非常有帮助。
3.核心函数实现+介绍
3.1Span+SpanList介绍
- 首先是结构体Span的介绍:
//Span:管理多个连续页的大块内存跨度结构
struct Span
{PAGE_ID _page_id = 0;//大块内存的起始页的页号size_t _n = 0;//页的数量Span* _next = nullptr; //设计成双向链表结构Span* _prev = nullptr;size_t _objSize = 0;//切好的小对象的大小size_t _usecount = 0;//切好的小块内存,被分配给threadcache的计数void* _freeList = nullptr;bool _isUse = false;//是否在使用 涉及到多个线程同时访问一个span 会有线程安全问题
};
- Spanlist代码
class SpanList
{
public:SpanList(){_head = new Span;_head->_next = _head;_head->_prev = _head;}//头插入函数void Insert(Span* pos, Span* newSpan){assert(pos);assert(newSpan);Span* prev = pos->_prev;prev->_next = newSpan;newSpan->_prev = prev;newSpan->_next = pos;pos->_prev = newSpan;}//删除void Erase(Span* pos){assert(pos);assert(pos != _head);Span* prev = pos->_prev;Span* next = pos->_next;prev->_next = next;next->_prev = prev;delete pos;}Span* Begin(){return _head->_next;}Span* End(){return _head;}bool Empty(){return _head->_next == _head;}void PushFront(Span* pos){Insert(Begin(),pos);}//头删Span* PopFront(){Span* front = _head->_next;Erase(front);return front;}public:std::mutex _mtx;//桶锁
private:Span* _head;};
以上都是一些基础的数据结构知识,不过多介绍。
3.2CentralCache.h
#pragma once
#include"Common.h"
//单例模式 --->饿汉模式
class CentralCache
{
public:static CentralCache* GetInstance() //获取单例{return &_Istance;}//获取一个非空的spanSpan* GetOneSpan(SpanList& list, size_t size);//定义 .CPP实现//从缓冲中心获取一定数量的对象返回给treadCachesize_t FetchRangeObj(void*& star, void*& end, size_t batchNum,size_t size);//Fetch-->获取//将一定数量的对象释放到span跨度void ReleaseListToSpans(void* start, size_t size); //Release-->释放
private:SpanList _spanlists[NFREELISTS];//确保类 只创建一个实例CentralCache() //构造函数私有化 {}CentralCache(const CentralCache&) = delete;//禁掉拷贝构造 static CentralCache _Istance;//首次调用即创建唯一单例
};
Span* GetOneSpance(SpanList& list, size_t size);
3.3CentralCache.cpp
#pragma once
#include"CentralCache.h"
#include"PageCache.h"
CentralCache CentralCache::_Istance;
size_t CentralCache::FetchRangeObj(void*& star, void*& end, size_t batchNum, size_t size)
{size_t index = SizeClass::Index(size);//计算出桶的下标_spanlists[index]._mtx.lock();//加锁Span* span = GetOneSpance(_spanlists[index], size);assert(span);assert(span->_freeList);//断言成功 则证明至少有一个块//从span中获取batchNum个对象 //如果实际的个数不够 那就有多少拿多少 这里就需要有一个实际变量actuall作为返回star = span->_freeList;end = star;size_t i = 0;size_t actualNum = 1;while (i < batchNum - 1 && NextObj(end) != nullptr){//更新end的位置end = NextObj(end);actualNum++;i++;}span->_freeList = NextObj(end);NextObj(end) = nullptr;span->_usecount += actualNum;//条件断点void* cur = star;int koko = 0;while (cur){cur = NextObj(cur);koko++;}if (koko != actualNum){int x = 0;}_spanlists[index]._mtx.unlock();return actualNum;
}Span* GetOneSpance(SpanList& list, size_t size)
{//查看一下当前spanlists是否span未分配的Span* it = list.Begin();while (it != list.End()){if (it->_freeList!=nullptr){return it;}else{it = it->_next;}}//先把centralCache的桶解掉 ,这样如果其他的线程释放对象回来,不会阻塞list._mtx.unlock();//走到这里说明没有空闲的span了,再往下找PageCache要PageCache::GetInstance()->_pageMtx.lock(); //加锁 这是一个大锁Span* span = PageCache::Newspan(SizeClass::NumMovePage(size));span->_isUse = true;span->_objSize = size;PageCache::GetInstance()->_pageMtx.unlock();//到这一步程序就已经申请到一个span了//对span进行切分 此过程不需要加锁 因为其他的线程访问不到这个span//通过页号 计算出起始页的地址 add=_pageID<<PAGE_SHIFT//计算span的大块内存的起始地址 和大块内存的大小(字节数)char* start = (char*)(span->_page_id << PAGE_SHIFT);size_t bytes = span->_n << PAGE_SHIFT;char* end = start + bytes;//把大块内存切成自由链表 链接起来//这里使用尾插 因为尾插会保持内存空间的连续性 提高CPU的缓存利用率span->_freeList = start;start += size;void* tail = span->_freeList;int i = 1;while (start < end){++i;NextObj(tail) = start;tail = NextObj(tail);start += size;}if (tail == nullptr){int x = 0;}NextObj(tail) = nullptr;void* cur = span->_freeList;int koko=0;//条件断点 //类似死循环 可以让程序中断 程序会在运行的地方停下来while (cur){cur = NextObj(cur);koko++;}if (koko != (bytes / 16)){int x = 0;}//这里切好span以后 需要把span挂到桶里面 同时加锁list._mtx.lock();list.PushFront(span);list._mtx.unlock();return span;
}//回收内存
void CentralCache::ReleaseListToSpans(void* start, size_t size)
{size_t index = SizeClass::Index(size);_spanlists[index]._mtx.lock();while (start){void* next = NextObj(start);Span* span = PageCache::GetInstance()->MapObjectToSpan(start);NextObj(start) = span->_freeList;span->_freeList = start;span->_usecount--;if (span->_usecount == 0)//说明span切分出去的内存小块都回收回来了,//这时这个span就可以再回收给page cache,page cache可以再尝试去做前后页的合并{_spanlists[index].Erase(span);span->_freeList = nullptr;span->_prev = nullptr;span->_next = nullptr;//释放span给page cache时,使用page cache的锁就可以了//所以需要先把桶锁解掉再加page cache的大锁_spanlists[index]._mtx.unlock();PageCache::GetInstance()->_pageMtx.lock();PageCache::GetInstance()->ReleaseSpanToPageCache(span);PageCache::GetInstance()->_pageMtx.unlock();_spanlists[index]._mtx.lock();}start = next;}_spanlists[index]._mtx.unlock();
}3.4TreadCache申请内存函数介绍
#define _CRT_SECURE_NO_WARNINGS
#pragma once
#include"ThreadCache.h"
#include<algorithm>
#include"CentralCache.h"
void* ThreadCache::Allocate(size_t size)
{assert(size <= MAX_BYTES);size_t alignSize = SizeClass::RoundUp(size);size_t index = SizeClass::Index(size);//计算哈希桶的下标if (!_freeLists[index].Empty()){return _freeLists[index].Pop();}else{return FetchFromCentralCache(index, alignSize);}
}void ThreadCache::Deallocate(void* ptr, size_t size)
{assert(ptr);assert(size <= MAX_BYTES);//找到对映射的自由链表桶 插入size_t index = SizeClass::Index(size);_freeLists[index].Push(ptr);//当链表的长度大于一次批量申请的内存就开始归还一段给CentralCacheif (_freeLists[index].Size() >= _freeLists[index].MaxSize()){ListTooLong(_freeLists[index], size);//回收内存给CentralCache}
}
void ThreadCache::ListTooLong(FreeList& list, size_t size)
{void* start = nullptr;void* end = nullptr;list.PopRang(start, end, list.MaxSize());CentralCache::GetInstance()->ReleaseListToSpans(start, size);
}void* ThreadCache::FetchFromCentralCache(size_t index, size_t size)
{//慢开始反馈调节算法(batch:批量)//1.最开始不会一次向central cache要太多,因为要多了可能用不完,浪费//2.如果你不要这个size大小内存需求,那么batchNum就会不断增长,直到上限//3.size越大,一次向central cache要的batchNum就越小//4.size越小,一次向central cache要的batchNum就越大size_t batchNum = min(_freeLists[index].MaxSize(), SizeClass::NumMoveSize(size));if (_freeLists[index].MaxSize() == batchNum){_freeLists[index].MaxSize() += 1;}void* start = nullptr;void* end = nullptr;size_t actualNum = CentralCache::GetInstance()->FetchRangeObj(start, end, batchNum, size);assert(actualNum >= 1);if (actualNum == 1){assert(start == end);return start;}else{_freeLists[index].PushRange(NextObj(start), end, actualNum - 1);return start;}
}3.5慢反馈算法
申请的结构涉及 这里主要用的是慢反馈算法
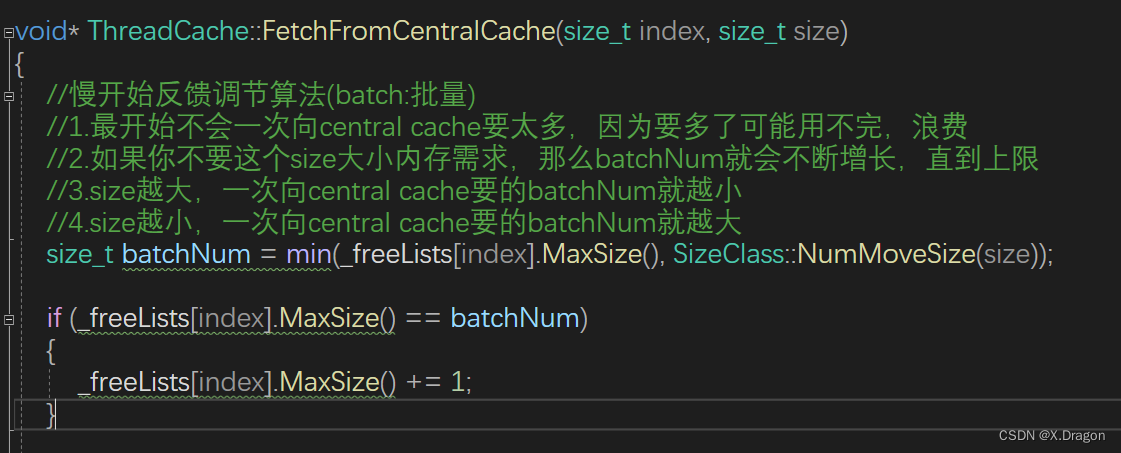


这里用双重机制来控制申请模块,第一次申请最大的申请数maxSize=1;然后计算慢启动函数的值,去最小的一个,如果说取的值是maxSize,那么maxSize就+=1;慢慢增长,这里可以根据实际需求调整增长的速度。
如果最后增长的范围超过慢启动设置的阈值,就取慢启动设置的值,在这两者策略下申请内存的机制得到更大的优化,大程度避免一次申请过大导致内存碎片问题。
相关文章:
【C++项目】高并发内存池第二讲中心缓存CentralCache框架+核心实现
CentralCache 1.框架介绍2.核心功能3.核心函数实现介绍3.1SpanSpanList介绍3.2CentralCache.h3.3CentralCache.cpp3.4TreadCache申请内存函数介绍3.5慢反馈算法 1.框架介绍 回顾一下ThreadCache的设计: 如图所示,ThreadCache设计是一个哈希桶结构&…...
Git基础教程
一、Git简介 1、什么是Git? Git是一个开源的分布式版本控制系统,用于敏捷高效地处理任何或大或小的项目。 Git是Linus Torvalds为了帮助管理Linux内核开发而开发的一个开放源代码的版本控制软件。 Git与常用的版本控制工具CVS、Subversion等不同&#…...
stm32外部时钟为12MHZ,修改代码适配
代码默认是8MHZ的,修改2个地方: 第一个地方是这个文件的这里: 第二个地方是找到这个函数: 修改第二个地方的这里:...
【数据结构】八大排序
目录 1. 排序的概念及其作用 1.1 排序的概念 1.2 排序运用 1.3 常见的排序算法 2. 常见排序算法的实现 2.1 插入排序 2.1.1 基本思想 2.1.2 直接插入排序 2.1.3 希尔排序(缩小增量排序) 2.2 选择排序 2.2.1 基本思想 2.2.2 直接选择排序 2.2…...

MYSQL(事务+锁+MVCC+SQL执行流程)理解
一)事务的特性: 一致性:主要是在数据层面来说,不能说执行扣减库存的操作的时候用户订单数据却没有生成 原子性:主要是在操作层面来说,要么操作完成,要么操作全部回滚; 隔离性:是自己的事务操作自己的数据,不会受到到其…...
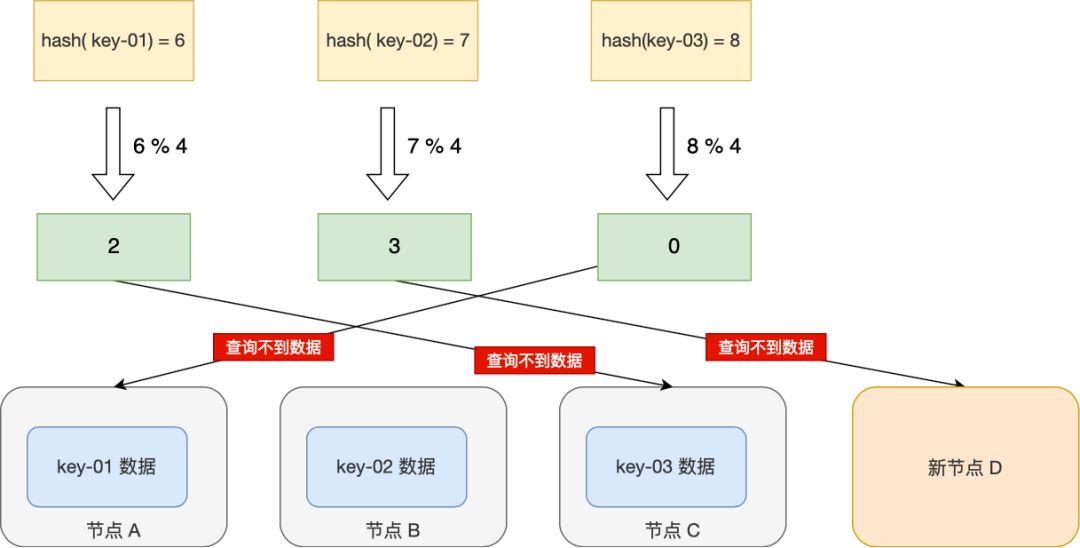
解密一致性哈希算法:实现高可用和负载均衡的秘诀
解密一致性哈希算法:实现高可用和负载均衡的秘诀 前言第一:分布式系统中的数据分布问题,为什么需要一致性哈希算法第二:一致性hash算法的原理第三:一致性哈希算法的优点和局限性第四:一致性哈希算法的安全性…...

Python脚本:让工作自动化起来
Python是一种流行的编程语言,以其简洁和易读性而闻名。它提供了大量的库和模块,使其成为自动化各种任务的绝佳选择。 本文将探讨Python脚本及其代码,可以帮助您自动化各种任务并提高工作效率。无论您是开发人员、数据分析师还是只是想简化工…...

香港科技大学广州|可持续能源与环境学域博士招生宣讲会—广州大学城专场!!!(暨全额奖学金政策)
香港科技大学广州|可持续能源与环境学域博士招生宣讲会—广州大学城专场!!!(暨全额奖学金政策) “面向未来改变游戏规则的——可持续能源与环境学域” ���专注于能源环…...
uni-app:多种方法写入图片路径
一、文件在前端文件夹中 1、相对路径引用 从当前文件所在位置开始寻找图片文件的路径。../../ 表示返回两级目录,即从当前文件所在的 wind.vue 所在的位置开始向上回退两级。接着,进入 static 目录,再进入 look 目录,最后定位到 …...

共谋工业3D视觉发展,深眸科技以自研解决方案拓宽场景应用边界
随着中国工业领域自动化程度逐渐攀升,“机器换人”这一需求进一步提升。在传统2D工业视觉易受环境光干扰、无法进一步获取物体深度信息的限制条件下,工业3D视觉凭借着更强的空间和深度感知能力,以及通过点云数据获取物体距离和三维坐标信息的…...

前端面试基础面试题——11
1.什么是 vue 的计算属性? 2.vue怎么实现页面的权限控制 3.watch的作用是什么 4.响应式系统的基本原理 5.vue-loader 是什么?使用它的用途有哪些? 6.vuex 工作原理详解 7.vuex 有哪几种属性? 8.什么是 MVVM? 9…...
)
SQL server中内连接和外连接的区别、表达(表的连接)
SQL server中内连接与外连接的区别、表达 区别表达内连接外连接 待续 首先,内连接和外连接都是对表的连接操作 区别 内连接:连接结果仅包含符合连接条件的行,其中至少一个属性是共同的;注意区分在嵌套查询时使用的any以及all的区…...
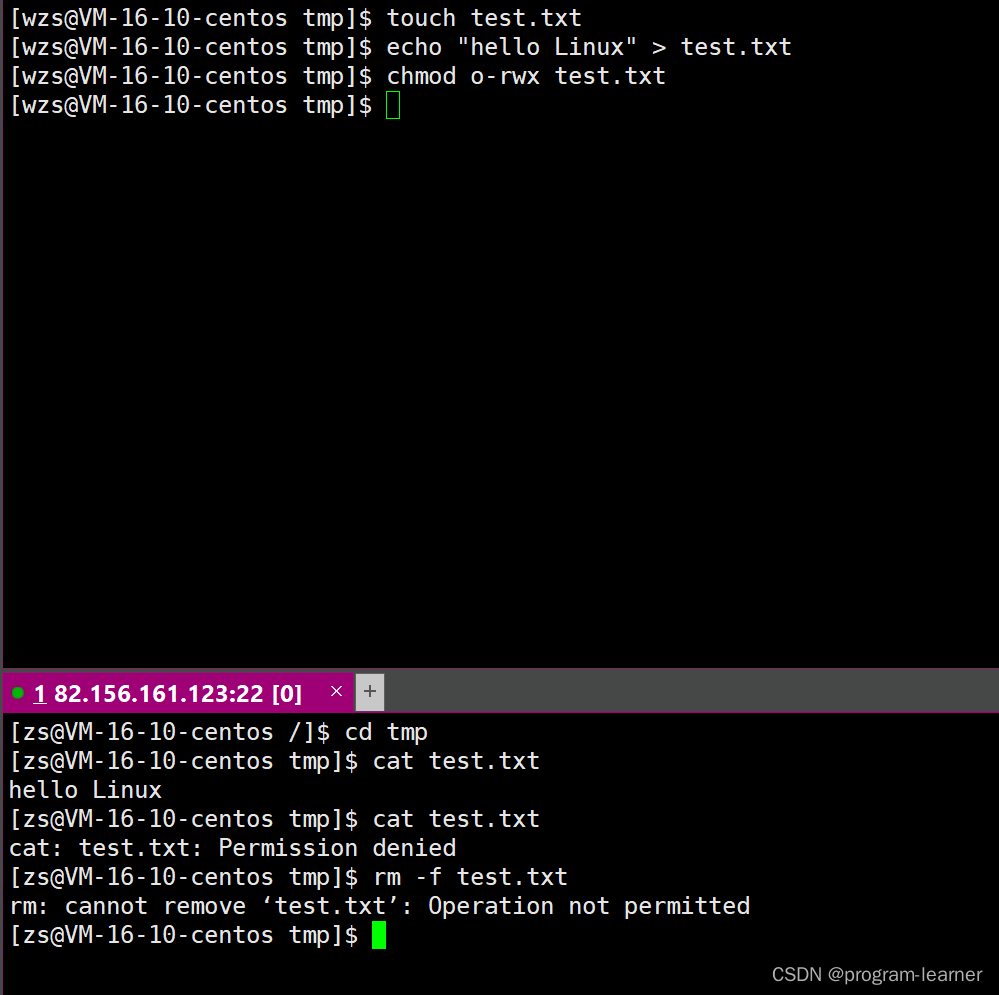
Linux中的shell外壳与权限(包含目录文件的权限,粘滞位的来龙去脉)
Linux中的shell外壳与权限[包含目录文件的权限,粘滞位的来龙去脉] 一.shell外壳的理解1.为什么需要有shell外壳的存在?2.什么是shell外壳?3.shell外壳的运行原理是什么?4.shell和bash的关系 二.Linux中的用户权限1.用户分类与身份切换1.用户分类2.root用户切换为普通用户1.s…...

力扣第45题 跳跃游戏II c++ 贪心算法
题目 45. 跳跃游戏 II 中等 相关标签 贪心 数组 动态规划 给定一个长度为 n 的 0 索引整数数组 nums。初始位置为 nums[0]。 每个元素 nums[i] 表示从索引 i 向前跳转的最大长度。换句话说,如果你在 nums[i] 处,你可以跳转到任意 nums[i j] 处…...

1024动态
感叹一下当前行情 从事码农这些年今年是最难的一年...
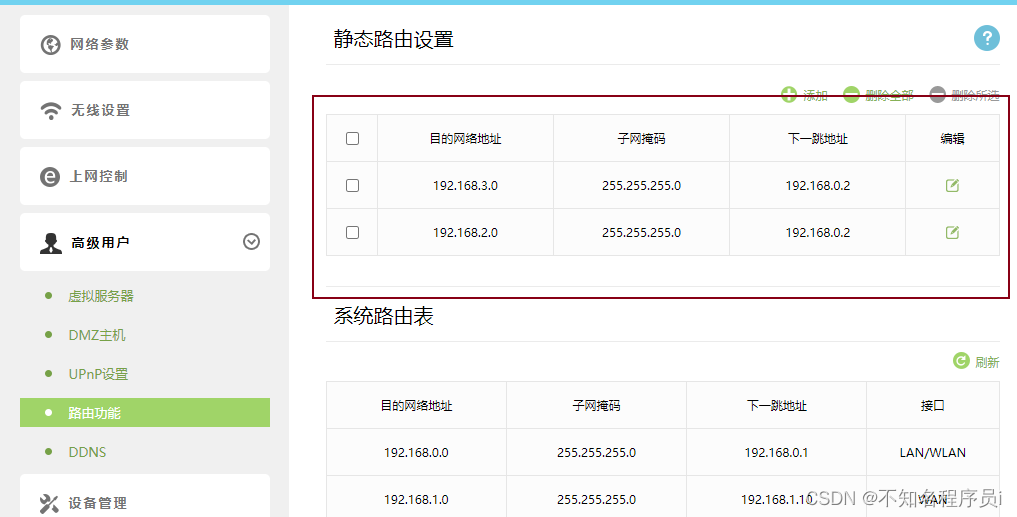
中心胖AP(AD9430DN)+远端管理单元RU(R240D)+出口网关,实现组网
适用于:V200R008至V200R019C00版本的万兆中心胖AP(AD9431DN-24X)。 组网规划 RU管理:VLAN 100,网段为192.168.100.0/24。 无线业务:VLAN 3,SSID为“wlan-net”,密码为“88888888”…...

shell_45.Linux在脚本中使用 getopt
在脚本中使用 getopt $ cat extractwithgetopt.sh #!/bin/bash # Extract command-line options and values with getopt # set -- $(getopt -q ab:cd "$") # echo while [ -n "$1" ] do case "$1" in -a) echo "Found the -a opt…...

2023-8-20 CVTE视源股份后端开发实习一面
自我介绍 操作系统 1 有了解进程和线程的特点吗 2 在linux层面的话是怎么创建一个进程或者一个线程的(具体的系统调用的命令) 答: 3 如果是java层面讲,怎么去启动一个线程,要实现哪些方法呢 Thread类实现run()方法的…...
二叉树进阶
欢迎来到Cefler的博客😁 🕌博客主页:那个传说中的man的主页 🏠个人专栏:题目解析 🌎推荐文章:题目大解析(3) 目录 👉🏻二叉搜索树概念 Ǵ…...
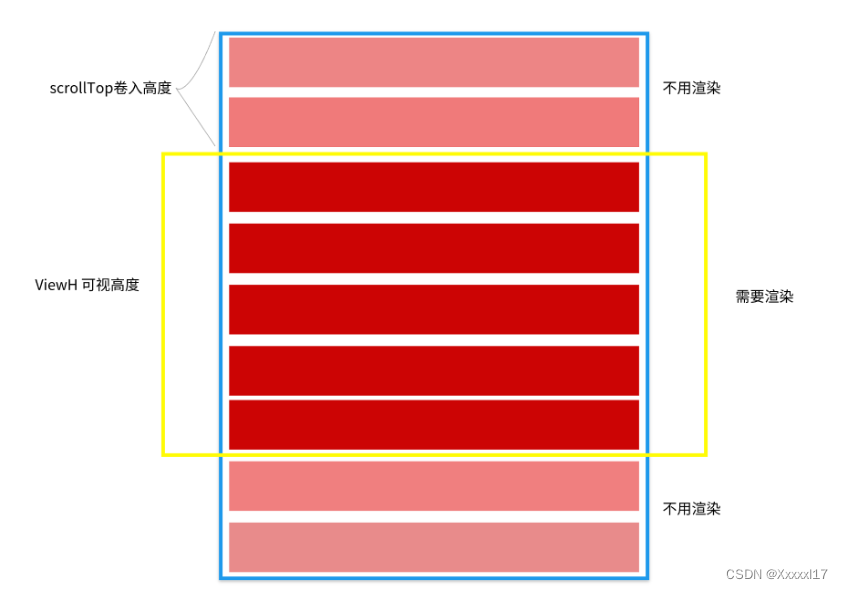
前端性能优化 - 虚拟滚动
一 需求背景 需求:在一个表格里面一次性渲染全部数据,不采用分页形式,每行数据都有Echart图插入。 问题:图表渲染卡顿 技术栈:Vue、Element UI 卡顿原因:页面渲染时大量的元素参与到了重排的动作中&#x…...

3大场景全解析:macOS专业录屏工具QuickRecorder实战指南
3大场景全解析:macOS专业录屏工具QuickRecorder实战指南 【免费下载链接】QuickRecorder A lightweight screen recorder based on ScreenCapture Kit for macOS / 基于 ScreenCapture Kit 的轻量化多功能 macOS 录屏工具 项目地址: https://gitcode.com/GitHub_T…...

普通手机gps信息样本
可以看到是10位的字符串可能需要20位置才能存下来呢...

为什么你的Spring Boot 4.0 Agent始终“不就绪”?7步诊断清单+ClassLoader隔离冲突终极解法
第一章:Spring Boot 4.0 Agent-Ready 架构演进与核心挑战Spring Boot 4.0 将 JVM Agent 集成能力提升为核心架构特性,标志着从“可监控”迈向“原生可观测”的范式跃迁。该版本深度重构了启动生命周期、类加载器隔离机制与 Bean 注册流程,使字…...

Python敏感词检测方案详解
一、引言在互联网内容审核、社交平台监管、评论系统过滤等场景中,敏感词检测是一项必不可少的功能。Python凭借其丰富的生态和简洁的语法,提供了多种实现敏感词检测的方案。本文将详细介绍几种主流的实现方式,并分析各自的优缺点及适用场景。…...

向上汇报技巧:让领导听懂技术价值
在软件测试领域,技术价值往往被埋没于复杂的缺陷报告和测试用例中。许多测试工程师投入大量精力保障产品质量,却因汇报不当导致领导无法理解其贡献。向上汇报不仅是信息传递,更是价值传递的艺术。它能让领导清晰看到测试工作在效率提升、成本…...

3步构建企业级认证系统实战指南:从0到1搭建安全认证中心
3步构建企业级认证系统实战指南:从0到1搭建安全认证中心 【免费下载链接】oauth2-server spring boot (springboot 3) oauth2 server sso 单点登录 认证中心 JWT,独立部署,用户管理 客户端管理 项目地址: https://gitcode.com/gh_mirrors/oau/oauth2-server …...

镭神智能C32激光雷达实战:从开箱到点云可视化全流程解析
1. 开箱与硬件连接 第一次拿到镭神智能C32激光雷达时,包装箱里会有这些关键部件:雷达主机、电源适配器、网线、HDMI线(可选)和说明书。我建议先找个宽敞的工作台,把所有配件摊开检查一遍,避免遗漏。 连接步…...
)
Android自动化新选择:DroidRun结合LLM实现自然语言控制手机(附详细配置指南)
Android自动化新选择:DroidRun结合LLM实现自然语言控制手机(附详细配置指南) 在移动应用开发与测试领域,自动化工具一直扮演着关键角色。传统方案往往需要编写复杂脚本或录制操作序列,学习曲线陡峭且维护成本高。Droi…...

【JavaScript高级编程】拆解函数流水线 上犯
一、什么是setuptools? setuptools 是一个用于创建、分发和安装 Python 包的核心库。 它可以帮助你: 定义 Python 包的元数据(如名称、版本、作者等)。 声明包的依赖项,确保你的包能够正确运行。 构建源代码分发包&…...

位运算的技巧和演示
尝试理解并去总结...