经典卷积神经网络 - VGG
使用块的网络 - VGG。
使用多个 3 × 3 3\times 3 3×3的要比使用少个 5 × 5 5\times 5 5×5的效果要好。
VGG全称是Visual Geometry Group,因为是由Oxford的Visual Geometry Group提出的。AlexNet问世之后,很多学者通过改进AlexNet的网络结构来提高自己的准确率,主要有两个方向:小卷积核和多尺度。而VGG的作者们则选择了另外一个方向,即加深网络深度。
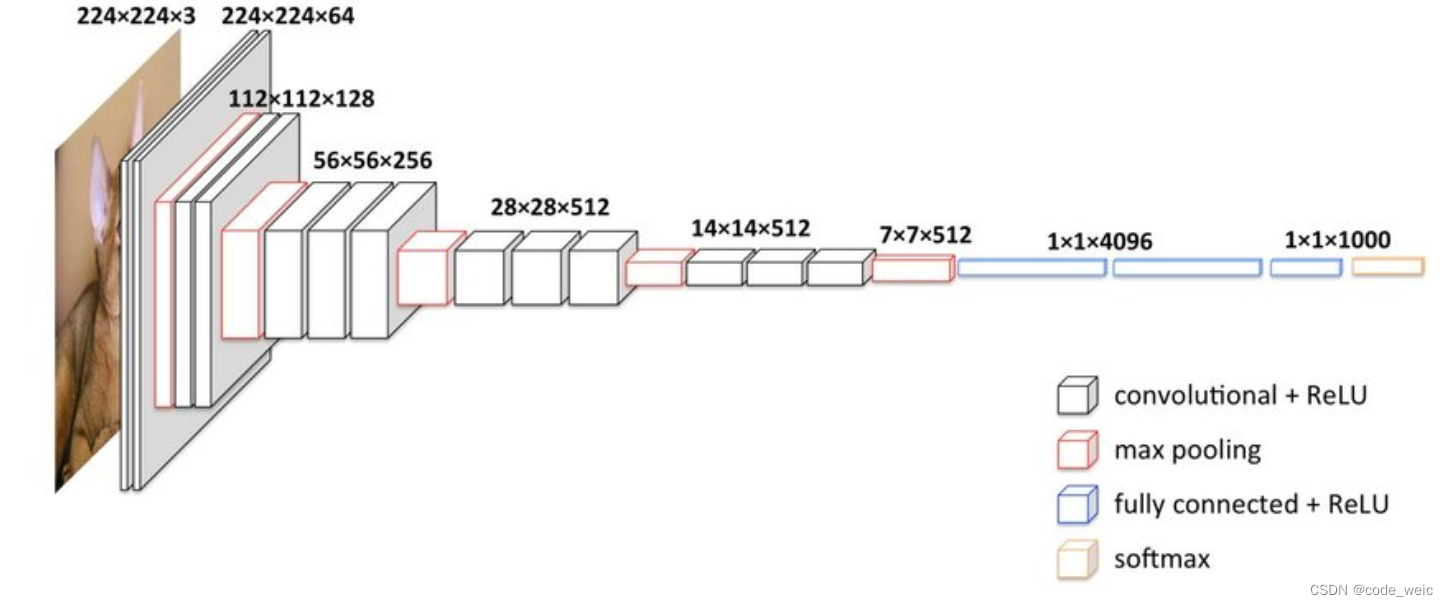
网络架构
卷积网络的输入是224 * 224的RGB图像,整个网络的组成是非常格式化的,基本上都用的是3 * 3的卷积核以及 2 * 2的max pooling,少部分网络加入了1 * 1的卷积核。因为想要体现出“上下左右中”的概念,3*3的卷积核已经是最小的尺寸了。
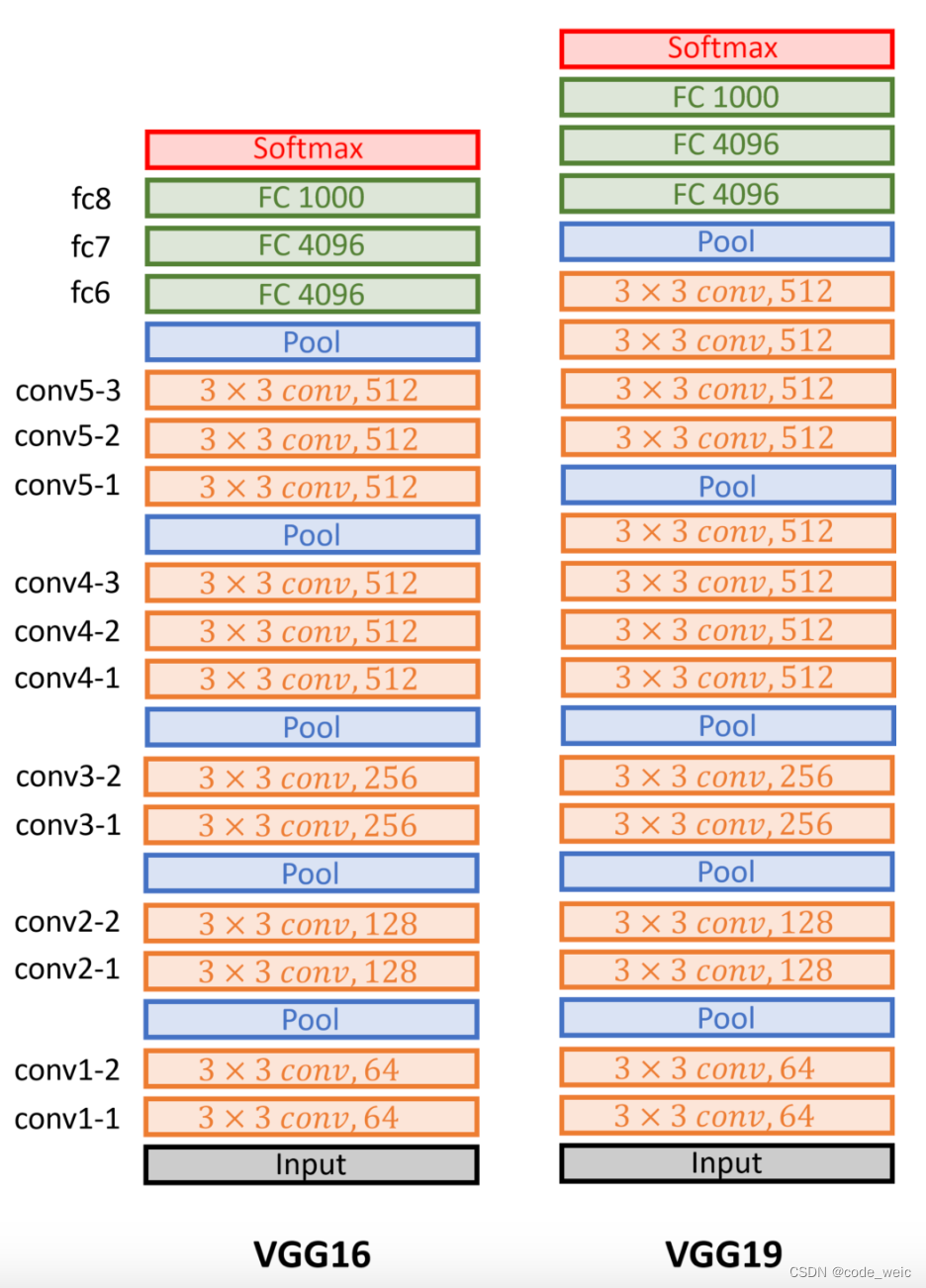
VGG16相比之前网络的改进是3个33卷积核来代替7x7卷积核,2个33卷积核来代替5*5卷积核,这样做的主要目的是在保证具有相同感知野的条件下,减少参数,提升了网络的深度。
多个VGG块后接全连接层。
不同次数的重复块得到不同的架构,如VGG-16,VGG-19等。
VGG:更大更深的AlexNet。
总结:
- VGG使用可重复使用的卷积块来构建深度卷积神经网络
- 不同的卷积块个数和超参数可以得到不同复杂度的变种
代码实现
使用数据集CIFAR
model.py
import torch
from torch import nnclass Vgg16(nn.Module):def __init__(self, *args, **kwargs) -> None:super().__init__(*args, **kwargs)self.model = nn.Sequential(nn.Conv2d(3,64,kernel_size=3,padding=1),nn.ReLU(),nn.Conv2d(64,64,kernel_size=3,padding=1),nn.ReLU(),nn.MaxPool2d(2,2),nn.Conv2d(64,128,kernel_size=3,padding=1),nn.ReLU(),nn.Conv2d(128,128,kernel_size=3,padding=1),nn.ReLU(),nn.MaxPool2d(2,2),nn.Conv2d(128,256,kernel_size=3,padding=1),nn.ReLU(),nn.Conv2d(256,256,kernel_size=3,padding=1),nn.ReLU(),nn.Conv2d(256,256,kernel_size=3,padding=1),nn.ReLU(),nn.MaxPool2d(2,2),nn.Conv2d(256,512,kernel_size=3,padding=1),nn.ReLU(),nn.Conv2d(512,512,kernel_size=3,padding=1),nn.ReLU(),nn.Conv2d(512,512,kernel_size=3,padding=1),nn.ReLU(),nn.MaxPool2d(2,2),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(),nn.MaxPool2d(2,2),nn.Flatten(),nn.Linear(7*7*512,4096),nn.Dropout(0.5),nn.Linear(4096,4096),nn.Dropout(0.5),nn.Linear(4096,10))def forward(self,x):return self.model(x)# 验证模型正确性
if __name__ == '__main__':net = Vgg16()x = torch.ones((64,3,244,244))output = net(x)print(output)
train.py
import torch
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from torchvision import datasets
from torchvision.transforms import transforms
from model import Vgg16# 扫描数据次数
epochs = 3
# 分组大小
batch = 64
# 学习率
learning_rate = 0.01
# 训练次数
train_step = 0
# 测试次数
test_step = 0# 定义图像转换
transform = transforms.Compose([transforms.Resize(224),transforms.ToTensor()
])
# 读取数据
train_dataset = datasets.CIFAR10(root="./dataset",train=True,transform=transform,download=True)
test_dataset = datasets.CIFAR10(root="./dataset",train=False,transform=transform,download=True)
# 加载数据
train_dataloader = DataLoader(train_dataset,batch_size=batch,shuffle=True,num_workers=0)
test_dataloader = DataLoader(test_dataset,batch_size=batch,shuffle=True,num_workers=0)
# 数据大小
train_size = len(train_dataset)
test_size = len(test_dataset)
print("训练集大小:{}".format(train_size))
print("验证集大小:{}".format(test_size))# GPU
device = torch.device("mps" if torch.backends.mps.is_available() else "cpu")
print(device)
# 创建网络
net = Vgg16()
net = net.to(device)
# 定义损失函数
loss = nn.CrossEntropyLoss()
loss = loss.to(device)
# 定义优化器
optimizer = torch.optim.SGD(net.parameters(),lr=learning_rate)writer = SummaryWriter("logs")
# 训练
for epoch in range(epochs):print("-------------------第 {} 轮训练开始-------------------".format(epoch))net.train()for data in train_dataloader:train_step = train_step + 1images,targets = dataimages = images.to(device)targets = targets.to(device)outputs = net(images)loss_out = loss(outputs,targets)optimizer.zero_grad()loss_out.backward()optimizer.step()if train_step%100==0:writer.add_scalar("Train Loss",scalar_value=loss_out.item(),global_step=train_step)print("训练次数:{},Loss:{}".format(train_step,loss_out.item()))# 测试net.eval()total_loss = 0total_accuracy = 0with torch.no_grad():for data in test_dataloader:test_step = test_step + 1images, targets = dataimages = images.to(device)targets = targets.to(device)outputs = net(images)loss_out = loss(outputs, targets)total_loss = total_loss + loss_outaccuracy = (targets == torch.argmax(outputs,dim=1)).sum()total_accuracy = total_accuracy + accuracy# 计算精确率print(total_accuracy)accuracy_rate = total_accuracy / test_sizeprint("第 {} 轮,验证集总损失为:{}".format(epoch+1,total_loss))print("第 {} 轮,精确率为:{}".format(epoch+1,accuracy_rate))writer.add_scalar("Test Total Loss",scalar_value=total_loss,global_step=epoch+1)writer.add_scalar("Accuracy Rate",scalar_value=accuracy_rate,global_step=epoch+1)torch.save(net,"./model/net_{}.pth".format(epoch+1))print("模型net_{}.pth已保存".format(epoch+1))
相关文章:
经典卷积神经网络 - VGG
使用块的网络 - VGG。 使用多个 3 3 3\times 3 33的要比使用少个 5 5 5\times 5 55的效果要好。 VGG全称是Visual Geometry Group,因为是由Oxford的Visual Geometry Group提出的。AlexNet问世之后,很多学者通过改进AlexNet的网络结构来提高自己的准确…...
/系统测试(ST)/用户验收测试(UAT))
系统集成测试(SIT)/系统测试(ST)/用户验收测试(UAT)
文章目录 单元测试集成测试系统测试用户验收测试黑盒测试白盒测试压力测试性能测试容量测试安全测试SIT和UAT的区别 单元测试 英文 unit testing,缩写 UT。测试粒度最小,一般由开发小组采用白盒方式来测试,主要测试单元是否符合“设计”。 …...

Android Gradle8.0以上多渠道写法以及针对不同渠道导入包的方式,填坑!
目录 多渠道的写法 针对多渠道引用不同的包 There was a failure while populating the build operation queue: Could not stat file E:\xxxx\xxxx\xxxx\app\src\UAT\libsUAT\xxx-provider(?)-xx.aar 最近升级了Gradle8.3之后,从Groovy 迁移到 Kotlinÿ…...
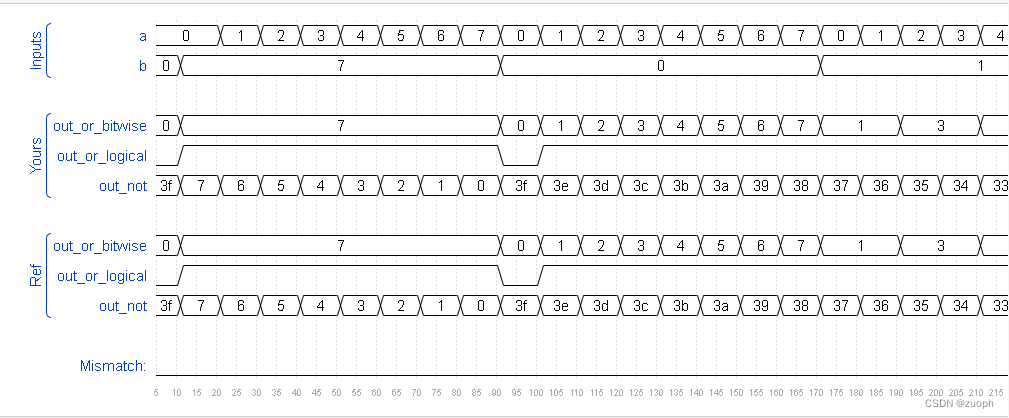
hdlbits系列verilog解答(向量门操作)-14
文章目录 一、问题描述二、verilog源码三、仿真结果 一、问题描述 构建一个具有两个 3 位输入的电路,用于计算两个向量的按位 OR、两个向量的逻辑 OR 以及两个向量的逆 (NOT)。将b反相输出到out_not上半部分,将a 的反相输出到out…...
)
工厂模式(初学)
工厂模式 1、简单工厂模式 是一种创建型设计模式,旨在通过一个工厂类(简单工厂)来封装对象的实例化过程 运算类 public class Operation { //这个是父类private double num1; //运算器中的两个值private double num2;public double getNu…...

python试题实例
背景: 在外地出差,突然接到单位电话,让自己出一些python考题供新人教育训练使用,以下是10道Python编程试题及其答案: 1.试题:请写一个Python程序,计算并输出1到100之间所有偶数的和。 答案&am…...
)
Java Heap Space问题解析与解决方案(InsCode AI 创作助手)
Heap Space问题是Java开发中常见的内存溢出问题之一,我们需要理解其原因和表现形式,然后通过优化代码、增加JVM内存和使用垃圾回收机制等方法来解决。 一、常见报错 java.lang.OutOfMemoryError: Java heap space二、Heap Space问题的原因 对象创建过…...
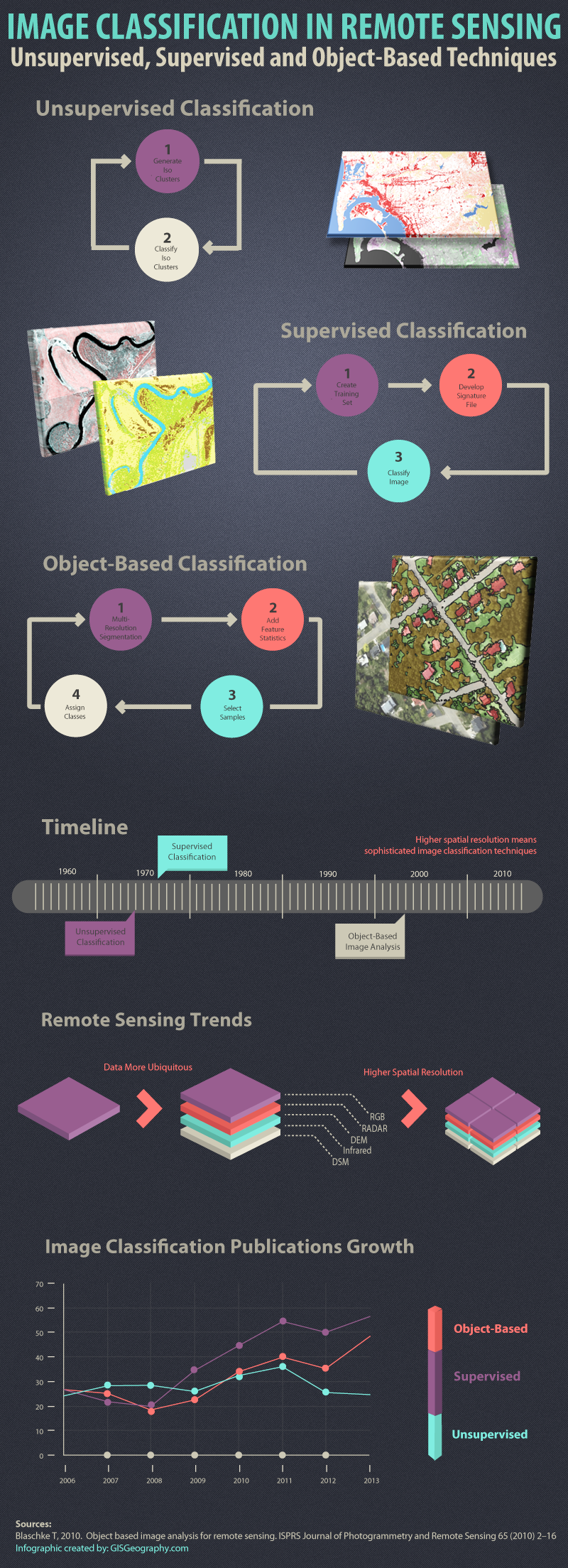
基于遥感影像的分类技术(监督/非监督和面向对象的分类技术)
遥感图像分类技术 “图像分类是将土地覆盖类别分配给像素的过程。例如,类别包括水、城市、森林、农业和草原。”前言 – 人工智能教程 什么是遥感图像分类? 遥感图像分类技术的三种主要类型是: 无监督图像分类监督图像分类基于对象的图像分析…...
 方法)
插入兄弟元素 insertAfter() 方法
insertAfter() 方法在被选元素后插入 HTML 元素。 提示:如需在被选元素前插入 HTML 元素,请使用 insertBefore() 方法。 语法 $(content).insertAfter(selector)例子: $("<span>Hello world!</span>").insertAfter(…...

【C++项目】高并发内存池第二讲中心缓存CentralCache框架+核心实现
CentralCache 1.框架介绍2.核心功能3.核心函数实现介绍3.1SpanSpanList介绍3.2CentralCache.h3.3CentralCache.cpp3.4TreadCache申请内存函数介绍3.5慢反馈算法 1.框架介绍 回顾一下ThreadCache的设计: 如图所示,ThreadCache设计是一个哈希桶结构&…...
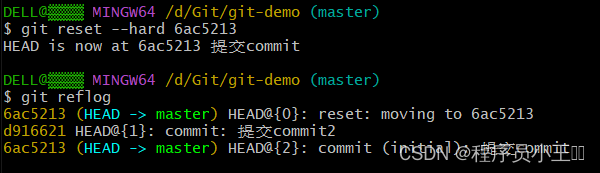
Git基础教程
一、Git简介 1、什么是Git? Git是一个开源的分布式版本控制系统,用于敏捷高效地处理任何或大或小的项目。 Git是Linus Torvalds为了帮助管理Linux内核开发而开发的一个开放源代码的版本控制软件。 Git与常用的版本控制工具CVS、Subversion等不同&#…...
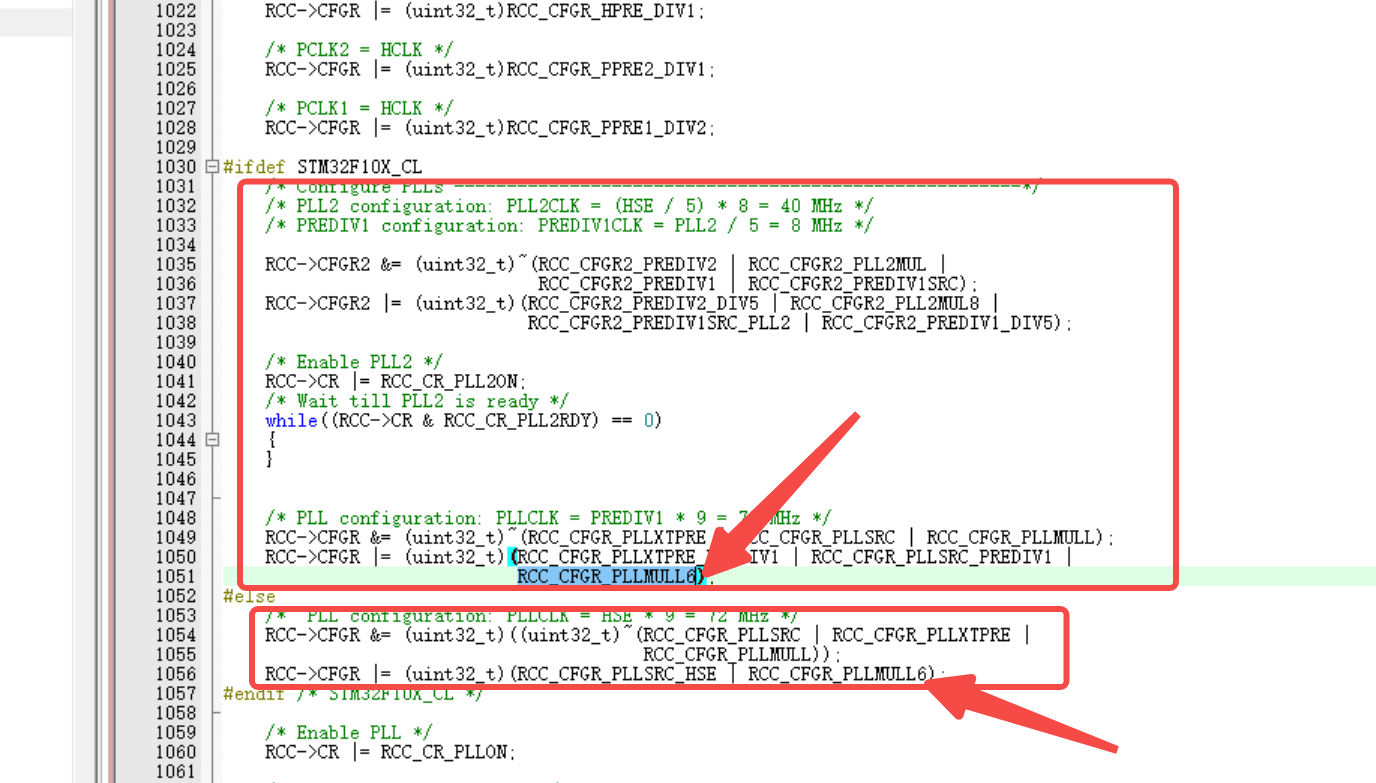
stm32外部时钟为12MHZ,修改代码适配
代码默认是8MHZ的,修改2个地方: 第一个地方是这个文件的这里: 第二个地方是找到这个函数: 修改第二个地方的这里:...
【数据结构】八大排序
目录 1. 排序的概念及其作用 1.1 排序的概念 1.2 排序运用 1.3 常见的排序算法 2. 常见排序算法的实现 2.1 插入排序 2.1.1 基本思想 2.1.2 直接插入排序 2.1.3 希尔排序(缩小增量排序) 2.2 选择排序 2.2.1 基本思想 2.2.2 直接选择排序 2.2…...

MYSQL(事务+锁+MVCC+SQL执行流程)理解
一)事务的特性: 一致性:主要是在数据层面来说,不能说执行扣减库存的操作的时候用户订单数据却没有生成 原子性:主要是在操作层面来说,要么操作完成,要么操作全部回滚; 隔离性:是自己的事务操作自己的数据,不会受到到其…...
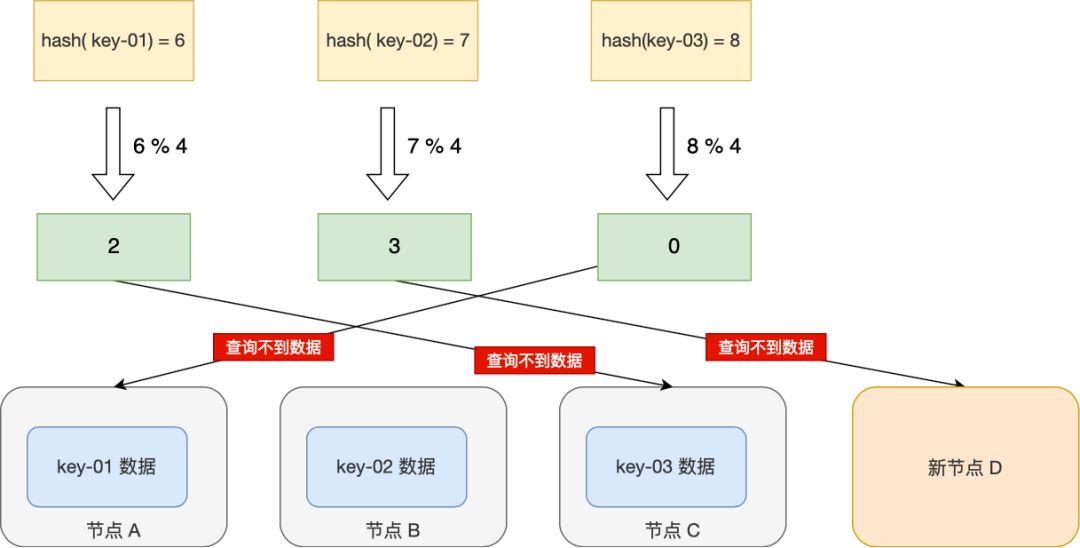
解密一致性哈希算法:实现高可用和负载均衡的秘诀
解密一致性哈希算法:实现高可用和负载均衡的秘诀 前言第一:分布式系统中的数据分布问题,为什么需要一致性哈希算法第二:一致性hash算法的原理第三:一致性哈希算法的优点和局限性第四:一致性哈希算法的安全性…...

Python脚本:让工作自动化起来
Python是一种流行的编程语言,以其简洁和易读性而闻名。它提供了大量的库和模块,使其成为自动化各种任务的绝佳选择。 本文将探讨Python脚本及其代码,可以帮助您自动化各种任务并提高工作效率。无论您是开发人员、数据分析师还是只是想简化工…...

香港科技大学广州|可持续能源与环境学域博士招生宣讲会—广州大学城专场!!!(暨全额奖学金政策)
香港科技大学广州|可持续能源与环境学域博士招生宣讲会—广州大学城专场!!!(暨全额奖学金政策) “面向未来改变游戏规则的——可持续能源与环境学域” ���专注于能源环…...
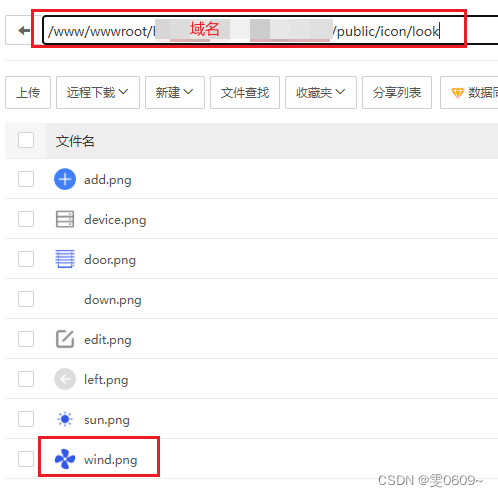
uni-app:多种方法写入图片路径
一、文件在前端文件夹中 1、相对路径引用 从当前文件所在位置开始寻找图片文件的路径。../../ 表示返回两级目录,即从当前文件所在的 wind.vue 所在的位置开始向上回退两级。接着,进入 static 目录,再进入 look 目录,最后定位到 …...

共谋工业3D视觉发展,深眸科技以自研解决方案拓宽场景应用边界
随着中国工业领域自动化程度逐渐攀升,“机器换人”这一需求进一步提升。在传统2D工业视觉易受环境光干扰、无法进一步获取物体深度信息的限制条件下,工业3D视觉凭借着更强的空间和深度感知能力,以及通过点云数据获取物体距离和三维坐标信息的…...

前端面试基础面试题——11
1.什么是 vue 的计算属性? 2.vue怎么实现页面的权限控制 3.watch的作用是什么 4.响应式系统的基本原理 5.vue-loader 是什么?使用它的用途有哪些? 6.vuex 工作原理详解 7.vuex 有哪几种属性? 8.什么是 MVVM? 9…...
)
紧急!PHP网关CPU飙升至98%却无堆栈痕迹?锁定glibc malloc arena争用导致的工业级假死现象(现场抓取core dump实录)
第一章:紧急!PHP网关CPU飙升至98%却无堆栈痕迹?锁定glibc malloc arena争用导致的工业级假死现象(现场抓取core dump实录)凌晨三点,某支付网关集群中多台PHP-FPM worker进程CPU持续飙至98%,但 g…...
)
Blazor与AI原生融合:如何在客户端直接调用ONNX Runtime + ML.NET推理模型(含TensorFlow.js互操作避坑指南)
第一章:Blazor与AI原生融合的范式演进传统Web前端框架长期面临状态同步复杂、服务端耦合度高、实时AI能力接入成本大等瓶颈。Blazor凭借WebAssembly(WASM)与服务器端SignalR双执行模型,首次为浏览器端提供了可运行强类型.NET代码的…...

AI Agent设计实战:基于千问3.5-9B构建自主任务执行智能体
AI Agent设计实战:基于千问3.5-9B构建自主任务执行智能体 1. 智能体时代的业务自动化新范式 想象一下这样的场景:市场部门需要每周生成一份行业趋势分析报告。传统流程需要人工收集数据、整理信息、分析趋势、撰写报告,整个过程耗时费力。而…...

什么是静态测试?
静态测试是软件测试中的一种重要方法,它不实际运行被测试的软件系统,而是通过对软件的需求文档、设计文档、代码等进行分析、检查和评审,来发现软件中潜在的缺陷和问题。以下从多个方面详细介绍静态测试:1. 静态测试的对象文档&am…...

解决方案命名怎么做:从内部术语到客户听得懂的命名结构
很多B2B企业在做官网重构 销售PPT升级 或方案页梳理时 都会遇到一个非常典型的问题 企业内部对方案很清楚 但客户还是很难快速看懂更具体一点说 客户不是完全不理解 而是会停在一种非常典型的状态里听起来很专业看起来内容很多但一下子抓不到重点也不知道这套方案到底和自己有什…...

**Harness 工程是个框,什么都可以往里装**
在最近使用 LLM 进行自动化 Prompt 工程,并推进 Agent 工作流端到端落地时,我尝试将底座模型切换到了 Gemini 3 Flash 和 Sonnet 4.6 这个级别。一个棘手的问题开始暴露:在简单的prompt指令下,模型往往倾向于“走捷径”完成优化任…...

五、QEMU+MIPS环境搭建实战:从零构建跨架构调试环境
1. 为什么需要QEMUMIPS环境? 在嵌入式设备逆向分析领域,MIPS架构的路由器固件分析是个常见需求。但真实路由器硬件往往缺乏调试接口,直接动态调试就像在黑箱里摸象。这时候QEMU就像个万能翻译官,能在x86电脑上完美复现MIPS程序的运…...

ElegantBook LaTeX模板技术解析:中文书籍排版系统架构与实战应用
ElegantBook LaTeX模板技术解析:中文书籍排版系统架构与实战应用 【免费下载链接】ElegantBook Elegant LaTeX Template for Books 项目地址: https://gitcode.com/gh_mirrors/el/ElegantBook ElegantBook作为LaTeX中文书籍排版的专业解决方案,通…...

海康工业相机LabVIEW二次开发实战——参数配置优化与图像高效存储
1. 海康工业相机与LabVIEW开发环境搭建 第一次接触海康工业相机时,我也被它丰富的功能接口和复杂的参数体系搞得晕头转向。但实际用LabVIEW开发后发现,只要掌握几个关键点,就能快速上手。海康官方提供的MVS客户端是个好东西,安装后…...

中兴光猫终极管理工具:zteOnu工厂模式与Telnet一键开启指南
中兴光猫终极管理工具:zteOnu工厂模式与Telnet一键开启指南 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu zteOnu是一款专为中兴光猫设备设计的强大管理工具,能…...