优化单元测试效率:Spring 工程启动耗时统计
相关文章:
- Java Agent 的简单使用
本文相关代码地址:https://gitee.com/dongguabai/blog
单元测试在软件项目的可持续发展中扮演着不可或缺的角色,这一点毫无疑问。不久前,公司大佬在内部分享时也提到过:单元测试是每个研发工程师的基本技能。
然而,在实际的开发过程中,我们发现很多研发人员并不愿意编写单元测试。其中一个普遍的原因是很多单元测试需要启动 Spring 容器(而许多 Mock 工具本身并不好用),导致启动过程非常耗时。
以我们的核心项目为例,一次单元测试的运行时间接近 5 分钟。考虑到一般需求开发涉及多个接口,再加上中间调试的时间,可能测试几个接口就会耗费一整天的时间。这严重影响了研发工作的效率。
[2023-10-23 12:34:07] [xxx_release] [Dongguabai.local] [INFO] [dfe7d0de51f548dd90e31411312acbd1] 705c1661f4044444b10b53009a32e8e1 main org.springframework.boot.StartupInfoLogger.logStarted(StartupInfoLogger.java:57) - Started SrvCustomerMapperProxyTest in 277.059 seconds (JVM running for 279.544) [12:34:07.659]
也有同学吐槽过:
本文就是希望可以解决这一痛点问题。
切入点
现在的问题是我们的项目启动 Spring 容器慢,那么我们就需要知道启动到底慢在哪里,结合 Spring 的生命周期,就需要去统计每个 Bean 实例化的时间,有几种很常见的切入点:
-
基于
BeanPostProcessorBeanPostProcessor提供了两个函数可以帮助我们在 Bean 实例化之后,属性赋值前做一些事情,这也是网上很多博客介绍的一种方案,但是这个方案有个细节要注意,一个 Bean 可能被多个BeanPostProcessor去处理,所以要注意计算耗时的BeanPostProcessor的postProcessBeforeInitialization是第一个调用,且postProcessAfterInitialization是最后一个调用。这里就涉及到多个BeanPostProcessor处理的顺序问题。在 Spring 容器中,多个
BeanPostProcessor,它们的执行顺序是:postProcessBeforeInitialization方法:按照BeanPostProcessor在 Spring 容器中的注册顺序依次执行。InitializingBean.afterPropertiesSet方法:这是Bean初始化后调用的方法。- Bean 配置中的
init-method:如果有配置,则执行该方法。 postProcessAfterInitialization方法:按照BeanPostProcessor在 Spring 容器中的注册顺序依次执行。
很明显,与我们期望的计算耗时的 BeanPostProcessor 的 postProcessBeforeInitialization 和 postProcessAfterInitialization 的执行顺序是有冲突的,所以需要特殊处理。当然如果实际场景影响不大,直接基于 BeanPostProcessor 来做问题也不大。
-
基于
InstantiationStrategy它负责基于默认构造器,实例化 Bean。需要在
instantiate函数执行前后进行统计,但整体实现相对比较复杂 -
基于
org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory#doCreateBean统计的时间范围太宽了,属性赋值的情况也会计入其中,不太准确
-
其实以上三点皆有缺陷,在业务系统中,每个 Bean 的耗时点可能各不一样,有的在实例化阶段,有的在初始化阶段(初始化又分多种情况,如
@PostConstruct、afterPropertiesSet,init-method)。所以这几块要单独统计,便于真正知道 Bean 初始化的耗时
耗时统计实现思路
其实耗时统计说白了就是在方法前后记录一下时间,然后求出差值即可。很常见的方案就是基于代理模式去做,但无论是基于 BeanPostProcessor 还是 InstantiationStrategy 其实都需要考虑 Spring 很多基础组件的顺序问题,相对比较麻烦。本文是基于 Java Agent 实现(关于 Java Agent 可以参看:Java Agent 的简单使用),对 Bean 的实例化和初始化两个阶段分别统计耗时。
耗时记录拦截器:
package blog.dongguabai.spring.bean.timestatistics;import net.bytebuddy.implementation.bind.annotation.AllArguments;
import net.bytebuddy.implementation.bind.annotation.Argument;
import net.bytebuddy.implementation.bind.annotation.Origin;
import net.bytebuddy.implementation.bind.annotation.RuntimeType;
import net.bytebuddy.implementation.bind.annotation.SuperCall;
import net.bytebuddy.implementation.bind.annotation.This;import java.lang.reflect.Method;
import java.util.Objects;
import java.util.concurrent.Callable;/*** @author dongguabai* @date 2023-10-22 14:18*/
public class BeanLifeInterceptor {@RuntimeTypepublic static Object intercept(@Origin Method method, @SuperCall Callable<?> callable, @Argument(1) String beaName, @AllArguments Object[] args, @This Object obj) throws Exception {long start = System.currentTimeMillis();try {return callable.call();} finally {long end = System.currentTimeMillis();if (Objects.equals(method.getName(), "instantiate")) {instantiateLog(beaName, end - start);}if (Objects.equals(method.getName(), "postProcessBeforeInitialization")) {beforeInitializationLog(beaName, start);}if (Objects.equals(method.getName(), "postProcessAfterInitialization")) {afterInitializationLog(beaName, end);}}}private synchronized static void instantiateLog(String beaName, long time) {Log log = LogInterceptor.logs.get(beaName);if (log == null) {log = new Log(beaName);}TimeDate timeDate = log.getTimeDate();timeDate.setBeanName(beaName);timeDate.setInstantiateTime(time);LogInterceptor.logs.put(beaName, log);}private synchronized static void beforeInitializationLog(String beaName, long time) {Log log = LogInterceptor.logs.get(beaName);if (log == null) {log = new Log(beaName);}log.setStartInitializationTime(Math.min(log.getStartInitializationTime() == 0L ? Long.MAX_VALUE : log.getStartInitializationTime(), time));LogInterceptor.logs.put(beaName, log);}private synchronized static void afterInitializationLog(String beaName, long time) {Log log = LogInterceptor.logs.get(beaName);if (log == null) {log = new Log(beaName);}log.setEndInitializationTime(Math.max(time, log.getEndInitializationTime()));LogInterceptor.logs.put(beaName, log);}
}
装载耗时记录拦截器:
package blog.dongguabai.spring.bean.timestatistics;import net.bytebuddy.agent.builder.AgentBuilder;
import net.bytebuddy.implementation.MethodDelegation;
import net.bytebuddy.matcher.ElementMatchers;import java.lang.instrument.Instrumentation;/*** @author dongguabai* @date 2023-10-22 14:19*/
public class PreMainAgent {public static void premain(String agentArgs, Instrumentation inst) {new AgentBuilder.Default().type(ElementMatchers.hasSuperType(ElementMatchers.named("org.springframework.beans.factory.support.InstantiationStrategy"))).transform((builder, typeDescription, classLoader, javaModule) -> builder.method(ElementMatchers.named("instantiate")).intercept(MethodDelegation.to(BeanLifeInterceptor.class))).type(ElementMatchers.hasSuperType(ElementMatchers.named("org.springframework.beans.factory.config.InstantiationAwareBeanPostProcessorAdapter"))).transform((builder, typeDescription, classLoader, javaModule) -> builder.method(ElementMatchers.named("postProcessBeforeInitialization").or(ElementMatchers.named("postProcessAfterInitialization"))).intercept(MethodDelegation.to(BeanLifeInterceptor.class))).installOn(inst);new AgentBuilder.Default().type(ElementMatchers.named(agentArgs.split("#")[0])).transform((builder, typeDescription, classLoader, javaModule) -> builder.method(ElementMatchers.named(agentArgs.split("#")[1])).intercept(MethodDelegation.to(LogInterceptor.class))).installOn(inst);}
}
将 Agent 工程进行打包:
➜ spring-bean-timestatistics mvn package
[INFO] Scanning for projects...
...
[WARNING] Replacing pre-existing project main-artifact file: /Users/dongguabai/IdeaProjects/github/spring-bean-timestatistics/target/dongguabai-spring-bean-timestatistics-1.0-SNAPSHOT.jar
with assembly file: /Users/dongguabai/IdeaProjects/github/spring-bean-timestatistics/target/dongguabai-spring-bean-timestatistics-1.0-SNAPSHOT.jar
...
查看耗时
在启动单元测试时,增加 VM options:
-javaagent:/Users/dongguabai/IdeaProjects/github/spring-bean-timestatistics/target/dongguabai-spring-bean-timestatistics-1.0-SNAPSHOT.jar=com.xxx.SrvCustomerMapperProxyTest#testInsert
这里 com.xxx.SrvCustomerMapperProxyTest 是指要代理的类,testInsert 是指要代理的函数。
接下来启动单元测试看看效果(可以看到这次启动居然只用了 200s,也说明每次启动的时间都不稳定):
...
[2023-10-24 18:04:45] [maf_release] [Dongguabai.local] [INFO] [b4f3a146566b46a49214e48ffabfb615] 06df0988e4364d499d90aa4f7b702b2f main org.springframework.boot.StartupInfoLogger.logStarted(StartupInfoLogger.java:57) - Started SrvCustomerMapperProxyTest in 199.152 seconds (JVM running for 204.326) [18:04:45.346]
...
BEANS TIME STATISTICS:
【shardingDatasourceRoutingDataSource-> totalTime=50526, instantiateTime=76, initializeTime=50450】
【basicDataDubboService-> totalTime=5876, instantiateTime=0, initializeTime=5876】
【com.alibaba.boot.dubbo.DubboProviderAutoConfiguration-> totalTime=4641, instantiateTime=0, initializeTime=4641】
【orgBaseManager-> totalTime=4481, instantiateTime=0, initializeTime=4481】
【srvCommonDubboServiceImpl-> totalTime=2845, instantiateTime=17, initializeTime=2828】
【storageProxyService-> totalTime=2708, instantiateTime=0, initializeTime=2708】...
可以看到各个 Bean 实例化和初始化的耗时,接下来要做的就是逐个分析降低它们的耗时,这就比较简单了。
耗时分析
这里分析几个 Top 耗时。
shardingDatasourceRoutingDataSource
可以看到耗时在 initializeTime,而这个 Bean 实现了 AbstractRoutingDataSource,重写了 afterPropertiesSet 方法:
private void initDataSource(DruidDataSource druidDataSource) {try {druidDataSource.init();} catch (SQLException e) {throw new RuntimeException(e);}}
而耗时主要就在连接池初始化,这个其实有两种方案:
-
异步初始化
设置一下即可,但是这个要注意,可能我们跑单测的时候涉及到数据库访问,如果此时连接池没有初始化完成的话会出现异常
druidDataSource.setAsyncInit(true); -
初始化连接数为 0
就是不需要一开始就设置数据库连接:
ds.setInitialSize(NumberUtils.toInt(env.getProperty("ds.initialSize"), 10));
我这边使用第二种方案。
basicDataDubboService
这是一个普通被 @Service 标注的 Bean,可以看到也是耗时在 initializeTime,这是因为这个项目使用的是自己封装的 Dubbo 接口,依赖注入 Dubbo Reference 是依赖于 BeanPostProcessor 实现。
在 basicDataDubboService 中引入 Dubbo 接口方式是使用的自定义注解 @DubboConsumer:
@Service
@Slf4j
public class BasicDataDubboService {@DubboConsumer(check = false) private FaultService faultService;
}
而 @DubboConsumer 会被 BeanPostProcessor 处理:
@Beanpublic BeanPostProcessor beanPostProcessor() {return new BeanPostProcessor() {@Overridepublic Object postProcessBeforeInitialization(Object bean, String beanName)throws BeansException {Class<?> objClz = bean.getClass();if (org.springframework.aop.support.AopUtils.isAopProxy(bean)) {objClz = org.springframework.aop.support.AopUtils.getTargetClass(bean);}try {for (Field field : objClz.getDeclaredFields()) {DubboConsumer dubboConsumer = field.getAnnotation(DubboConsumer.class);
...
分析后可以设置 @DubboConsumer 属性 lazy 为 true,相当于 ReferenceBean 的 lazy 属性,这样可以懒加载创建 Reference 代理。
同时也发现有很多无用的注入,这里可以直接清除:

com.alibaba.boot.dubbo.DubboProviderAutoConfiguration
这个也是团队内部封装的 Dubbo 配置类,它依赖 @PostConstruct 对外暴露 Dubbo 服务:
@PostConstructpublic void init() throws Exception {Map<String, Object> beans = this.applicationContext.getBeansWithAnnotation(Service.class);for (Map.Entry<String, Object> entry : beans.entrySet()) {this.initProviderBean(entry.getKey(), entry.getValue());if(this.properties.getProviderDefaultGroup()){this.initProviderBeanWithGroup(entry.getKey(), entry.getValue());}}}
private void initProviderBeanWithGroup(String beanName, Object bean) throws Exception {...serviceConfig.export();}
可以看到整个实现也是相对比较粗糙(比如根本没必要获取全部的 @Service 标注的 Bean,可以自定义一个实现注解,降低查找范围),先不纠结于细节,至少本地启动单元测试是没必要暴露 Dubbo 服务的,所以是否暴露 Dubbo 服务可以基于 profile 做一个限制。
结果查看
上面三耗时分析,除了 com.alibaba.boot.dubbo.DubboProviderAutoConfiguration 由于涉及到代码改造,暂时没有处理,其余的两个已经处理,重新启动,看看效果:
...
[2023-10-24 18:52:03] [maf_release] [Dongguabai.local] [INFO] [d53b3ebcc40240f19b12ca0bdf434436] 375000afa08a48b49f9121a5c4760386 main org.springframework.boot.StartupInfoLogger.logStarted(StartupInfoLogger.java:57) - Started SrvCustomerMapperProxyTest in 142.282 seconds (JVM running for 148.136) [18:52:03.086]
...
【basicDataDubboService-> totalTime=5567, instantiateTime=0, initializeTime=5567】
【shardingDatasourceRoutingDataSource-> totalTime=272, instantiateTime=70, initializeTime=202】
...
可以看到整个启动速度大大提升,主要还是 shardingDatasourceRoutingDataSource 的初始化速度从 50450ms 降低至 202ms。至于 basicDataDubboService,效果相对一般,但也从中找到了内部封装的 Dubbo 组件优化点。
总结
基于 TOP3 耗时 Bean 的分析来看,耗时有这么几种原因:
- 数据库连接可以延迟初始化
- 移除无用的依赖注入
- 内部封装的 Dubbo 组件存在很多优化点,如:
- Dubbo Provider 在本地没必要对外暴露服务
- 懒加载创建 Reference 代理
尽管不同项目的耗时原因各有差异,但只要能够确定具体的耗时点,问题就不会太棘手。本文介绍了一个简单的工具,用于获取 Spring Bean 初始化的时间,借此能够准确定位具体的 Bean,从而有针对性地进行优化。通过优化这些耗时操作,就能够有效提升整个项目的启动速度,显著增强研发工作的效率。
References
- https://github.com/microsphere-projects/microsphere-spring
- https://github.com/raphw/byte-buddy/issues/748
欢迎关注公众号:

相关文章:
优化单元测试效率:Spring 工程启动耗时统计
相关文章: Java Agent 的简单使用 本文相关代码地址:https://gitee.com/dongguabai/blog 单元测试在软件项目的可持续发展中扮演着不可或缺的角色,这一点毫无疑问。不久前,公司大佬在内部分享时也提到过:单元测试是…...

华纳云:连接mysql出现2059错误怎么解决
MySQL连接错误2059通常表示MySQL服务器拒绝了连接。这种错误可能由多种原因引起,以下是一些可能的解决方法: 检查MySQL服务器是否正在运行: 确保MySQL服务器正在正常运行。您可以使用以下命令检查MySQL服务器的状态: systemctl st…...

零基础Linux_22(多线程)线程控制和和C++的多线程和笔试选择题
目录 1. 线程控制 1.1 线程创建(pthread_create) 1.2 线程结束(pthread_exit) 1.3 线程等待(pthread_join) 1.4 线程取消(pthread_cancel结束) 1.5 线程tid(pthread_self()) 1.6 线程局部存储(__thread) 1.7 线程分离(pthread_detach) 2. C的多线程 3. 笔试选择题 答…...
docker版本的Jenkins安装与更新技巧
因为jenkins/jenkins镜像默认带的jenkins版本比较低,导致安装完以后,很多插件因为版本问题无法安装。以下是最权威,最方便的安装教程。 1. 创建本地挂载目录 mkdir -p /mnt/dockerdata/jenkins/home/2. 修改挂载目录权限 chown -R 1000:10…...
[C++]3.类和对象下(this指针补充)+ 类和对象中构造函数和析构函数。
类和对象下(this指针补充) 类和对象中构造函数和析构函数 一.this补充:1.概念总结:2.两个问题: 二.构造函数和析构函数:一.类的默认构造:1.初始化和清理:2.拷贝复制:3.取…...

OpenLDAP LDIF详解
手把手一步步搭建LDAP服务器并加域 有必要理解的概念LDAPWindows Active Directory 服务器配置安装 OpenLDAP自定义安装修改对象(用户和分组等)修改olcSuffix 和 olcRootDN 属性增加olcRootPW 属性修改olcAccess属性验证新属性值 添加对象(用…...

Leetcode.33 搜索旋转排序数组
题目链接 Leetcode.33 搜索旋转排序数组 mid 题目描述 整数数组 n u m s nums nums 按升序排列,数组中的值 互不相同 。 在传递给函数之前, n u m s nums nums 在预先未知的某个下标 k ( 0 ≤ k < n u m s . l e n g t h )…...

ES 8.x 向量检索性能测试 把向量检索性能提升100倍!
向量检索不仅在的跨模态检索场景中应用广泛,随着chat gpt的或者,利用es的向量检索,在Ai领域发挥着越来越大的作用。 本文,主要测试es的向量检索性能。我从8.x就开始关注ES的向量检索了。当前ES已经发布到 8.10 版本。以下是官方文…...
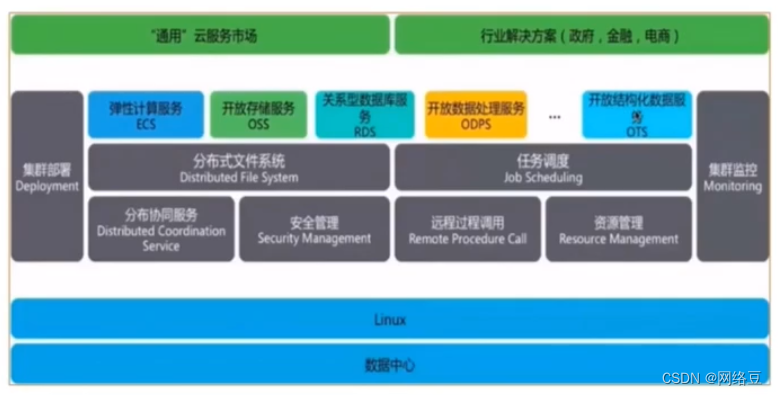
云计算——ACA学习 云计算架构
作者简介:一名云计算网络运维人员、每天分享网络与运维的技术与干货。 公众号:网络豆云计算学堂 座右铭:低头赶路,敬事如仪 个人主页: 网络豆的主页 目录 写在前面 前期回顾 本期介绍 一.云计算架…...
基于深度学习实现一张单图,一个视频,一键换脸,Colab脚本使用方法,在线版本,普通人也可以上传一张图片体验机器学习一键换脸
基于深度学习实现一张单图,一个视频,一键换脸,Colab脚本使用方法,在线版本,普通人也可以上传一张图片体验机器学习一键换脸。 AI领域人才辈出,突然就跳出一个大佬“s0md3v”,开源了一个单图就可以进行视频换脸的项目。 项目主页给了一张换脸动图非常有说服力,真是一图…...

leetcode 21
递归的方式 class Solution { public:ListNode* mergeTwoLists(ListNode* l1, ListNode* l2) {if(l1 nullptr){return l2;}else if(l2 nullptr){return l1;}else if(l1->val < l2->val){l1->next mergeTwoLists(l1->next, l2);return l1;}else if(l1->va…...
)
【Spring Cloud】openfeign负载均衡方案(和lb发展历史)
文章目录 版本1:原始loadBalancerClient方案版本2:ribbon-loadbalancer方案版本3:openfeign方案(即**方案2openfeign版本**) 本文描述了Spring Cloud微服务中,各个服务间调用的负载均衡方案的升级历史&…...

R语言:主成分分析PCA
文章目录 主成分分析处理步骤数据集code主成分分析 主成分分析(或称主分量分析,principal component analysis)由皮尔逊(Pearson,1901)首先引入,后来被霍特林(Hotelling,1933)发展。 主成分分析是一种通过降维技术把多个变量化为少数几个主成分(即综合变量)的统计分…...

Linux下磁盘备份、文件备份和定时备份命令指南
文章目录 磁盘备份和定时备份命令指南1. 引言2. 磁盘备份命令dda. 简介和基本用法b. dd命令的参数和选项说明c. 使用dd命令进行磁盘镜像备份的步骤d. 恢复备份数据的方法和注意事项e. 示例:使用dd命令备份和还原磁盘镜像 3. 磁盘备份命令tara. 简介和基本用法b. tar…...
电脑软件:推荐一款非常强大的pdf阅读编辑软件
目录 一、软件简介 二、功能介绍 1、界面美观,打开速度快 2、可直接编辑pdf 3、非常强大好用的注释功能 4、很好用的页面组织和提取功能 5、PDF转word效果非常棒 6、强大的OCR功能 三、软件特色 四、软件下载 pdf是日常办公非常常见的文档格式,…...

Android 13.0 系统开机屏幕设置默认横屏显示
1.概述 在13.0的系统产品开发中,对于产品需求来说,由于是宽屏设备所以产品需要开机默认横屏显示,开机横屏显示这就需要从 两部分来实现,一部分是系统开机动画横屏显示,另一部分是系统屏幕显示横屏显示,从这两方面就可以做到开机默认横屏显示了 2.系统开机设置默认横屏显…...

Redis -- 基础知识1
1.介绍 1.初识Redis Redis:The open source, in-memory data store used by millions of developers as a database, cache, streaming engine, and message broker. in-memory data:在内存中存储,Redis是在分布式系统中存储起作用的 解释&am…...

ubuntu 20.04 passwd 指令不能使用
Linux 更改用户密码报Changing password for user 用户名. passwd: Module is unknown或更改新增用户密码passwd:未知的用户名 报错信息如下: 解决方法: 可以排查 /etc/pam.d/passwd配置文件 注释掉包含pam_passwdqc.so模块的行,…...
单片机郭天祥(02)
1:解决keil5软件的乱码问题,修改编码为UTF-8 2:打开keil5使用debug对编写好的程序进行调试 给程序打上断点 使用仿真芯片 更改设备管理器相关设置 接通电源后点击debug连接到51单片机 使用stc-isp获取延时函数 将延时函数添加进入创建好的…...

Hadoop3教程(三十五):(生产调优篇)HDFS小文件优化与MR集群简单压测
文章目录 (168)HDFS小文件优化方法(169)MapReduce集群压测参考文献 (168)HDFS小文件优化方法 小文件的弊端,之前也讲过,一是大量占用NameNode的空间,二是会使得寻址速度…...

企业SEO网站推广的优势和劣势有哪些
企业SEO网站推广的优势分析 在当今互联网时代,企业SEO网站推广已经成为一种必不可少的数字营销手段。无论是中小企业还是大型企业,都在竞争激烈的市场中寻找最佳的方式来提升品牌知名度和销售额。企业SEO网站推广究竟有哪些优势呢?以下将从几…...

IntelliJ IDEA 2019安装教程及下载
软件介绍: IntelliJ IDEA 是捷克 JetBrains 公司研发的集成开发环境(IDE),主打 Java 和 Kotlin 开发,被誉为 “最佳 Java IDE”,适配不同层级开发者需求;它具备智能代码补全、静态分析、一键重…...

比迪丽模型在Python入门教学可视化中的应用
比迪丽模型在Python入门教学可视化中的应用 让编程初学者通过可视化方式快速理解Python核心概念 1. 教学痛点与解决方案 很多Python初学者在学习过程中会遇到这样的困境:看着密密麻麻的代码,却不知道程序到底是怎么运行的;遇到错误时&#x…...

告别复杂配置!Qwen-Image-2512图片生成服务保姆级部署教程
告别复杂配置!Qwen-Image-2512图片生成服务保姆级部署教程 1. 为什么选择这个镜像? 在AI图片生成领域,Qwen-Image-2512模型以其出色的中文理解和图像质量著称。但传统部署方式往往需要面对以下挑战: 复杂的Python环境配置数十G…...

Hogan.js数据绑定终极指南:5个简单步骤实现动态内容渲染
Hogan.js数据绑定终极指南:5个简单步骤实现动态内容渲染 【免费下载链接】hogan.js A compiler for the Mustache templating language 项目地址: https://gitcode.com/gh_mirrors/ho/hogan.js Hogan.js是一个专为Mustache模板语言设计的编译器,由…...

.py域名注册对SEO有什么影响吗_.py域名注册在哪里可以办理
.py域名注册对SEO有什么影响吗 在现代互联网时代,域名选择对网站的SEO(搜索引擎优化)表现有着重要的影响。而最近,一种新型的域名扩展名——.py域名,开始受到越来越多的关注。.py域名注册对SEO有什么影响呢࿱…...

Chord在科研视频处理中的应用:实验过程帧级语义标注与行为时序建模
Chord在科研视频处理中的应用:实验过程帧级语义标注与行为时序建模 1. 引言:科研视频分析的挑战与机遇 在科学研究领域,特别是生物学、心理学、医学和工程学等学科中,实验过程视频记录已成为不可或缺的研究手段。研究人员通过视…...

零基础新手如何借助快马ai编程迈出代码第一步
作为一个零编程基础的新手,第一次接触代码时难免会感到迷茫。最近尝试用InsCode(快马)平台搭建个人博客网站,发现整个过程比想象中简单很多。下面分享我的实践过程,希望能帮助同样想入门的朋友。 理解基础概念 刚开始连"框架"是什么…...

实战应用:基于快马平台开发企业级极域电子教室校园分发与管理系统
实战应用:基于快马平台开发企业级极域电子教室校园分发与管理系统 最近接手了一个校园信息化项目,需要为某中学开发一套极域电子教室的分发管理系统。学校希望实现软件版本的分班级分时段管理,同时避免下载高峰期的网络拥堵。经过调研&#…...

GLM-4.1V-9B-Base效果展示:中文表格图像结构识别与语义摘要生成
GLM-4.1V-9B-Base效果展示:中文表格图像结构识别与语义摘要生成 1. 模型能力概览 GLM-4.1V-9B-Base是智谱开源的视觉多模态理解模型,在中文视觉理解任务上表现出色。这个开箱即用的Web界面模型已经完成预加载,特别适合需要快速分析图片内容…...