Hadoop3教程(三十四):(生产调优篇)MapReduce生产经验汇总
文章目录
- (164)MR跑得慢的原因
- (165)MR常用调优参数
- Map阶段
- Reduce阶段
- (166)MR数据倾斜问题
- 参考文献
(164)MR跑得慢的原因
MR程序执行效率的瓶颈,或者说当你觉得你的MR程序跑的比较慢的时候,可以从以下两点来分析:
- 计算机性能
节点的CPU、内存、磁盘、网络等,这种属于硬件上的检查;
- IO操作上的检查
- 是否发生了数据倾斜?即单一reduce处理了绝大部分数据
- Map运行时间过长,导致Reduce一直在等待;
- 小文件过多。
(165)MR常用调优参数
Map阶段
Map阶段:
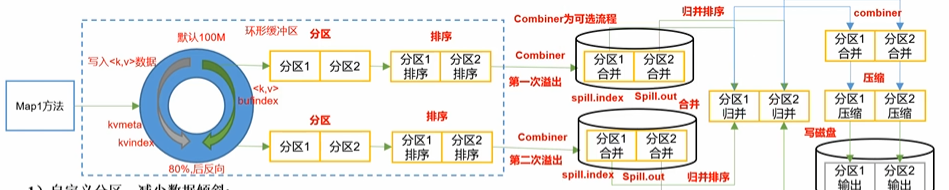
1)自定义分区,减少数据倾斜。即自定义分区类,继承Partitioner接口,重写getPartition();
2)减少环形缓冲区溢写的次数:
mapreduce.task.io.sort.mb:shuffle的环形缓冲区大小,默认是100M,可以提高至200M;mapreduce.map.sort.spill.percent:环形缓冲区的溢出阈值,默认是80%,可以提高至90%。即写到90%的时候才溢出。
这样做的目的是,减少环形缓冲区溢写后形成的文件的个数,减少后面步骤里分区合并的压力。
3)增加每次Merge合并次数:
mapreduce.task.io.sort.factor:分区归并时,每次归并的文件数量。默认是10,可以提高到20(如果你的内存足够支撑的话,否则只能调小了)
4)在不影响业务结果的前提下,可以开启Combiner:
job.setCombinerClass(xxxReducer.class);
5)为了减少磁盘IO,对于Map的输出文件,可以采用snappy或者LZO压缩。
6)提高MapTask的内存上限:
mapreduce.map.memory.mb:默认内存上限是1024MB。通常来讲,1G内存用来处理128M数据是绰绰有余的,可以根据128M数据对应1G内存的原则,对应提高内存。
7)调整MapTask的堆内存大小:
mapreduce.map.java.opts:跟上面的内存参数保持一致就可以。控制java用的内存
8)增加MapTask的CPU核数。
mapreduce.map.cpu.vcores:默认核数是1,对于计算密集型任务,可以增加CPU核数;
9)异常重试次数
mapreduce.map.maxattempts:每个MapTask的最大重试次数,一旦重试次数超过该值,则认为MapTask运行失败,默认值是4。可以根据实际情况做加减。
Reduce阶段
Reduce阶段:
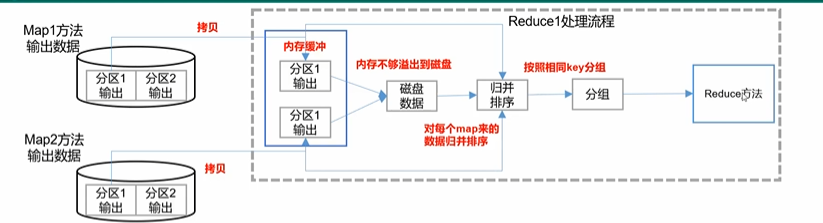
1)调整每个Reduce一次性从多少个MapTask拉取数据。
mapreduce.reduce.shuffle.parallelecopies:默认是5,即每个Reduce一次最多拉5个MapTask里的数据,如果内存足够支撑,完全可以调成10;
2)调整所拉取数据,在内存缓冲的占比。
mapreduce.reduce.shuffle.input.buffer.percent:控制内存buffer大小占ReduceTask可用内存的比例。默认是0.7,可以提高到0.8。毕竟在内存中缓存的数据越多,整体计算速度就越快。
3)控制归并排序时,可以使用的内存比例:
mapreduce.reduce.shuffle.merge.percent:简单的说,就是归并排序时,可以使用的内存占Reduce总可用内存的比例,超过这个比例,就只能溢出到磁盘了。这个比例默认是0.66,最高可以提高到0.75。
4)调整ReduceTask的可用内存上限:
mapreduce.reduce.memory.mb:默认可用内存上限为1024MB。同样的,128M数据对应1G内存原则。适当提升内存到4-6G。
5)调整ReduceTask的堆内存:
mapreduce.reduce.java.opts
6)调整ReduceTask的CPU核数:
mapreduce.reduce.cpu.vcores:默认核数是1,可以提高到2-4个
7)最大重试次数:
mapreduce.reduce.maxattempts:ReduceTask的最大重试次数,一旦重试次数超过该值,则认为运行失败。默认是4。
8)当MapTask的完成比例达到多少时,才会为ReduceTask申请资源:
mapreduce.job.reduce.slowstart.completedmaps:默认是0.05,即有5%的MapTask完成任务后就可以为ReduceTask申请资源。
9)Task的超时时间:
mapreduce.task.timeout:控制task的超时时间,默认是600000毫秒,即10min。如果一个Task,在10min内,没有数据进入,也没有数据输出,则直接退出该任务。如果你的程序对每条输出数据的处理时间很长,可适当调大这个参数。
10)如果可以不用Reduce,那就尽量不用。
(166)MR数据倾斜问题
直观来看,就是在大部分任务都已经完成了的情况下,还有少数任务仍在运行,这时候大概率就是发生了数据倾斜,分给那少数任务的数据太多了,导致它们一直没有处理完。
当发生数据倾斜后,我们可以从哪些角度考虑优化呢?
- 首先是检查是否是由于空值过多(key)造成的数据倾斜;
生产环境下,可以选择过滤掉空值;如果一定要保留空值的话,可以自定义分区,将空值加随机数打散分布。
- 能在Map阶段提前处理的,就在Map阶段提前处理。比如说Map阶段的Combiner、MapJoin等;
- 设置多个reduce个数;
参考文献
- 【尚硅谷大数据Hadoop教程,hadoop3.x搭建到集群调优,百万播放】
相关文章:
Hadoop3教程(三十四):(生产调优篇)MapReduce生产经验汇总
文章目录 (164)MR跑得慢的原因(165)MR常用调优参数Map阶段Reduce阶段 (166)MR数据倾斜问题参考文献 (164)MR跑得慢的原因 MR程序执行效率的瓶颈,或者说当你觉得你的MR程…...

Unity⭐️Win和Mac安卓打包环境配置
文章目录 🟥 配置Android SDK1️⃣ 配置 SDK Platforms2️⃣ 配置 SDK Tools🎁 Android SDK Build-Tools🎁 Android SDK Command-line Tools(latest)🎁 Android SDK Tools(Obsolete)🟧 配置NDK🟩 配置JDK前情提示: 此方法适用于Windows/Mac 在配置时注意开启 🪜 …...

STM32F4XX之串口
一、标准串口(UART)介绍 1、通信协议相关概念 1.1同步通信和异步通信 (1)同步通信:两个器件之间共用一个时钟线,要发送的数据在时钟的作用下一位一位发送出去。 (2)异步通信:指两个器件之间没…...
【J-Long Group Limited】申请1500万美元纳斯达克IPO上市
来源:猛兽财经 作者:猛兽财经 猛兽财经获悉,总部位于中国香港的J-Long Group Limited(简称:J-Long)近期已向美国证券交易委员会(SEC)提交招股书,申请在纳斯达克IPO上市&…...

上传文件到google drive
参考:使用 Python 将文件上传到 Google 云端硬盘_迹忆客 第 1 步:Google API Playground 我们可以通过搜索 Google 找到更多关于 Google API Playground 的信息。 我们必须单击第一个链接才能继续前进。 选择第一个链接后,我们会自动进入下一…...
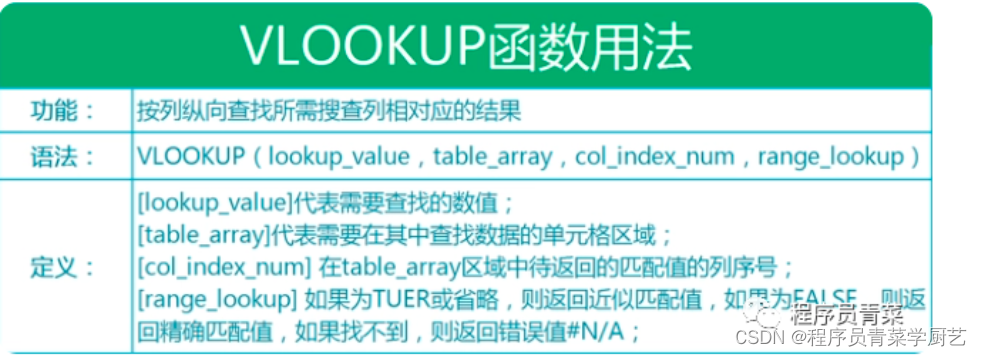
用VLOOKUP快速合并两个表格
一、前言 上周五微信收到运营提过来的需求,第一句话:帮我提取一下1号门店的库存数据,马上登录系统下载一份库存数据给到他然后专心读代码,过一会微信第二句话:帮我提取一下1号门店商品半年/一年的销量数据,…...
Vue ref属性
Vue中的ref属性可以用来对HTML元素或者是对组件进行唯一标识。 一、设置ref属性 只需要在元素或者是组件后跟上如下语法即可: ref"标识名" 二、获取元素或对象 我们可以用如下方法获取我们设置ref的元素或组件: this.$refs.标识名 第一个输…...

【python入门】函数,类和对象
【大家好,我是爱干饭的猿,本文重点介绍python入门的函数,高阶函数,python中的类和对象,模块的作用等。 后续会继续分享其他重要知识点总结,如果喜欢这篇文章,点个赞👍,关…...
-- jar包导入)
alibaba.fastjson的使用(二)-- jar包导入
目录 1. 在pom文件中引入依赖: 2.fastjsonv2的使用: 1. 在pom文件中引入依赖: <dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>2.0.14</version> </dependency>2.fastjsonv2的使用…...

A_搜索(A Star)算法
A*搜索(A Star) 不同于盲目搜索,A算法是一种启发式算法(Heuristic Algorithm)。 上文提到,盲目搜索对于所有要搜索的状态结点都是一视同仁的,因此在每次搜索一个状态时,盲目搜索并不会考虑这个状态到底是有利于趋向目标的&#x…...
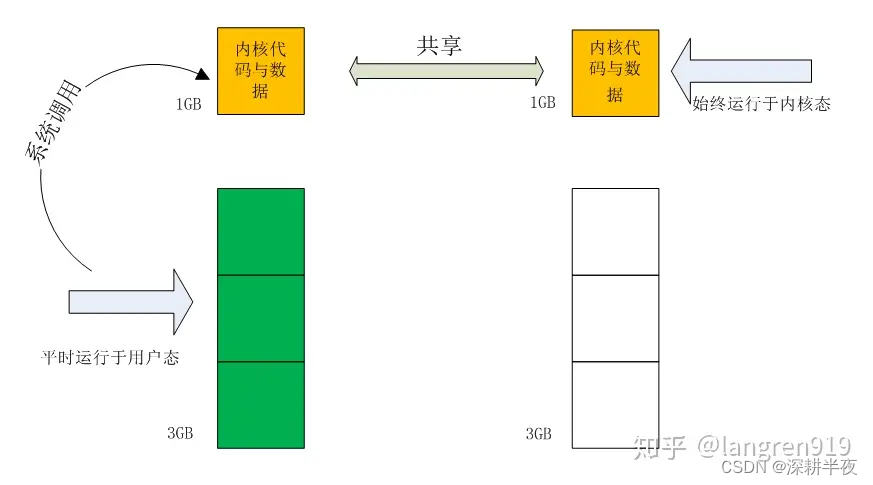
Tinywebserve学习之linux 用户态内核态
一.CPU指令集权限 指令集是实现CPU实现软件指挥硬件执行的媒介,具体来说每一条汇编语句都对应了一条CPU指令,而非常多的CPU指令再一起组成一个甚至多个集合,指令的集合叫CPU指令集; 因为CPU指令集可以操纵硬件,会造成…...

AI之浅谈
随着ChatGPT的爆火,AI的应用也随之遍地开花,国内国外的各种大模型也都陆续推出,AI的本质是进行数据的分析和整理,其背后的资源来自于互联网时代所积累的大数据基础,这也是深度学习的结果,AI具有不眠不休的特…...

20231024后端研发面经整理
1.如何在单链表O(1)删除节点? 狸猫换太子 2.redis中的key如何找到对应的内存位置? 哈希碰撞的话用链表存 3.线性探测哈希法的插入,查找和删除 插入:一个个挨着后面找,知道有空位 查找:一个个挨着后面找…...

【前段基础入门之】=>CSS3新增渐变颜色属性
导语: CSS3 新增了,渐变色 的解决方案,这使得我们可以绘制出更加生动的炫酷的的配色效果 线性渐变 多个颜色之间的渐变, 默认从上到下渐变 background-image: linear-gradient(red,yellow,green); /*默认从上到下渐变*/默认从上…...

深入浅出排序算法之归并排序
目录 1. 归并排序的原理 1.1 二路归并排序执行流程 2. 代码分析 2.1 代码设计 3. 性能分析 4. 非递归版本 1. 归并排序的原理 “归并”一词的中文含义就是合并、并入的意思,而在数据结构中的定义是将两个或者两个以上的有序表组合成一个新的有序表。 归并排序…...

opencv dnn模块 示例(19) 目标检测 object_detection 之 yolox
文章目录 0、前言1、网络介绍1.1、输入1.2、Backbone主干网络1.3、Neck1.4、Prediction预测输出1.4.1、Decoupled Head解耦头1.4.2、Anchor-Free1.4.3、标签分配1.4.4、Loss计算 1.5、Yolox-s、l、m、x系列1.6、轻量级网络研究1.6.1、轻量级网络1.6.2、数据增强的优缺点 1.7、Y…...

微信小程序阻止返回事件
需求场景 当在一个表单页面 填写了很多数据,或者编辑页面数据发生变动之后,这时候返回上一个页面需要提醒用户是否返回的弹框 实现方法一(ios会存在一定的问题) 在onLoad生命周期里 注册 wx.enableAlertBeforeUnload({message: "您内容已更新,还没保存,确定要退出吗?&…...

YOLOv7改进:新颖的上下文解耦头TSCODE,即插即用,各个数据集下实现暴力涨点
💡💡💡本文属于原创独家改进:上下文解耦头TSCODE,进行深、浅层的特征融合,最后再分别输入到头部进行相应的解码输出,实现暴力暴力涨点 上下文解耦头TSCODE| 亲测在多个数据集实现暴力涨点,对遮挡场景、小目标场景提升也明显; 收录: YOLOv7高阶自研专栏介绍: …...
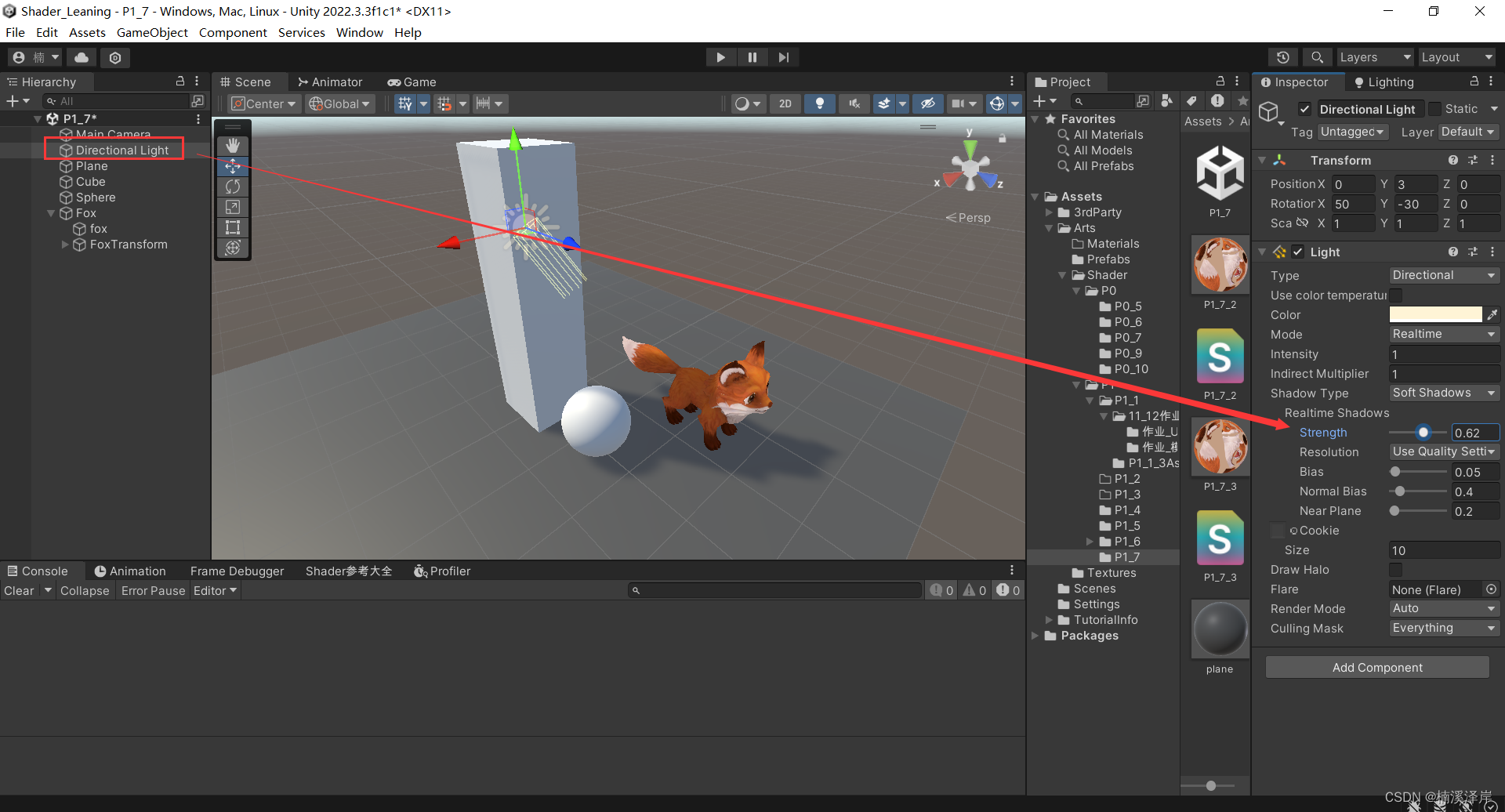
Unity中Shader阴影的接收
文章目录 前言一、阴影接受的步骤1、在v2f中添加UNITY_SHADOW_COORDS(idx),unity会自动声明一个叫_ShadowCoord的float4变量,用作阴影的采样坐标.2、在顶点着色器中添加TRANSFER_SHADOW(o),用于将上面定义的_ShadowCoord纹理采样坐标变换到相应的屏幕空间…...

✔ ★【备战实习(面经+项目+算法)】 10.22学习时间表(总计学习时间:4.5h)(算法刷题:7道)
✔ ★【备战实习(面经项目算法)】 坚持完成每天必做如何找到好工作1. 科学的学习方法(专注!效率!记忆!心流!)2. 每天认真完成必做项,踏实学习技术 认真完成每天必做&…...

TC264摄像头循迹进阶:从八邻域到逐行遍历的赛道边界鲁棒提取实战
1. 赛道边界提取为什么需要进阶算法 第一次接触智能车摄像头循迹时,很多人会直接用最简单的找中线方法——比如在每一行图像里取左右两边的黑线中点。这种方法对付直道还行,但遇到去年全国大学生智能车竞赛里的环岛元素,或者像三岔路、十字路…...

提升开发效率:用快马AI自动生成2048论坛带加密验证的登录模块代码
最近在开发一个2048论坛项目时,遇到了登录模块的开发需求。这个看似简单的功能其实包含不少技术细节,如果从头开始手动编写,至少要花费一整天时间。幸运的是,我发现了InsCode(快马)平台这个开发利器,它帮我快速生成了完…...

零基础新手如何借助快马ai编程迈出代码第一步
作为一个零编程基础的新手,第一次接触代码时难免会感到迷茫。最近尝试用InsCode(快马)平台搭建个人博客网站,发现整个过程比想象中简单很多。下面分享我的实践过程,希望能帮助同样想入门的朋友。 理解基础概念 刚开始连"框架"是什么…...

RNN、LSTM、BiLSTM 算法学习笔记
NLP-AHU-026一、RNN1.我之前学的普通神经网络和CNN,都是一次性处理数据的,比如给一张图片,它就直接分析这张图的像素,不会管前后的关联。但现实里很多数据都是有顺序的,像咱们读课文、看视频,得结合上下文才…...

告别系统臃肿与隐私泄露:Win11Debloat让Windows效率提升80%
告别系统臃肿与隐私泄露:Win11Debloat让Windows效率提升80% 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter a…...

OpenClaw自动化周报:Qwen3.5-9B-AWQ-4bit整合Git与日历数据
OpenClaw自动化周报:Qwen3.5-9B-AWQ-4bit整合Git与日历数据 1. 为什么需要自动化周报 每周五下午,我的日历总会准时弹出"写周报"的提醒。这个看似简单的任务却总让我头疼——需要翻遍Git提交记录、查日历会议纪要、整理零散的笔记࿰…...
求解,同时进行鲁棒度和置信水平的敏感度分析(Matlab代码实现))
综合能源系统双层鲁棒优化,考虑风光负荷电价四重不确定性的综合能源系统双层鲁棒优化模型,采用多目标粒子群算法(MOPSO)求解,同时进行鲁棒度和置信水平的敏感度分析(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

永磁同步电机PMSM无感FOC控制:扩展卡尔曼滤波器EKF观测器,代码运行无错,支持无感启动...
永磁同步电机pmsm无感foc控制,观测器采用扩展卡尔曼滤波器ekf,代码运行无错误,支持无感启动,代码移植性强,可以移植到国产mcu上.—— 从“功能”视角看透 ARM 官方 5 套 demo 一、写作目的 很多开发者拿到 CMSIS-DSP 例…...

5分钟搞定Asterisk SIP服务器:Ubuntu下从安装到Linphone客户端配置全流程
零基础构建企业级VoIP通信系统:Asterisk与Linphone实战指南 1. VoIP技术与企业通信系统架构解析 在数字化办公场景中,VoIP(Voice over Internet Protocol)技术正在彻底改变传统通信方式。与PSTN(公共交换电话网络&…...

孤能子视角:“人“的关系线束
(EIS下的"人"不同于实体的"人"。但这里不做比对。姑且当科幻小说看) 我的问题: 1."人"这条线,你能串联起多少知识? 2.Kimi分析。 3.信兄对Kimi分析的反馈。 (注:DeepSeek居然对Kimi的意见既有坚持又有吸收。另外&…...