opencv dnn模块 示例(19) 目标检测 object_detection 之 yolox
文章目录
- 0、前言
- 1、网络介绍
- 1.1、输入
- 1.2、Backbone主干网络
- 1.3、Neck
- 1.4、Prediction预测输出
- 1.4.1、Decoupled Head解耦头
- 1.4.2、Anchor-Free
- 1.4.3、标签分配
- 1.4.4、Loss计算
- 1.5、Yolox-s、l、m、x系列
- 1.6、轻量级网络研究
- 1.6.1、轻量级网络
- 1.6.2、数据增强的优缺点
- 1.7、Yolox的实现成果
- 1.7.1、精度速度对比
- 1.7.2、Autonomous Driving竞赛
- 1.8、网络训练
- 2、测试
- 2.1、官方脚本测试
- 2.1.1、torch 模型测试
- 2.1.2、onnx 模型测试
- 2.1.3、opencv dnn测试
- 2.2、测试汇总对比
0、前言
YOLOX是旷视科技在2021年发表,对标YOLO v5。YOLOX中引入了当年的黑科技主要有三点,decoupled head、anchor-free以及advanced label assigning strategy(SimOTA)。YOLOX的性能如何呢,可以参考原论文图一如下图所示。YOLOX比当年的YOLO v5略好一点,并且利用YOLOX获得当年的Streaming Perception Challenge第一名。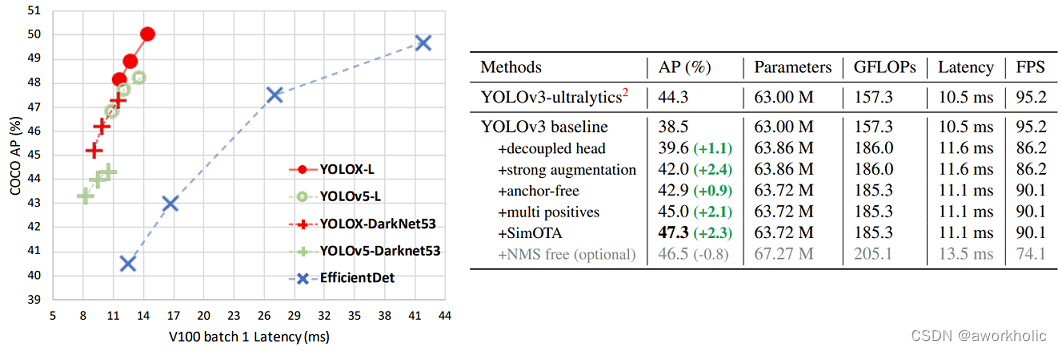
那这里可能有人会问了,在自己的项目中在YOLO v5和YOLOX到底应该选择哪个(后面还有yolov7,yolov8…)。如果数据集图像分辨率不是很高,比如640x640,那么两者都可以试试。如果分辨率很高,比如1280x1280,那么使用YOLO v5。因为YOLO v5官方仓库有提供更大尺度的预训练权重,而YOLOX当前只有640x640的预训练权重(YOLOX官方仓库说后续会提供更大尺度的预训练权重,目前一年多也毫无音讯)。
主要的模型内容:
- 对Yolov3 baseline基准模型,添加各种trick,比如Decoupled Head、SimOTA等,得到Yolox-Darknet53版本;
- 对Yolov5的四个版本,采用这些有效的trick,逐一进行改进,得到Yolox-s、Yolox-m、Yolox-l、Yolox-x四个版本;
- 设计了Yolox-Nano、Yolox-Tiny轻量级网络,并测试了一些trick的适用性;
1、网络介绍
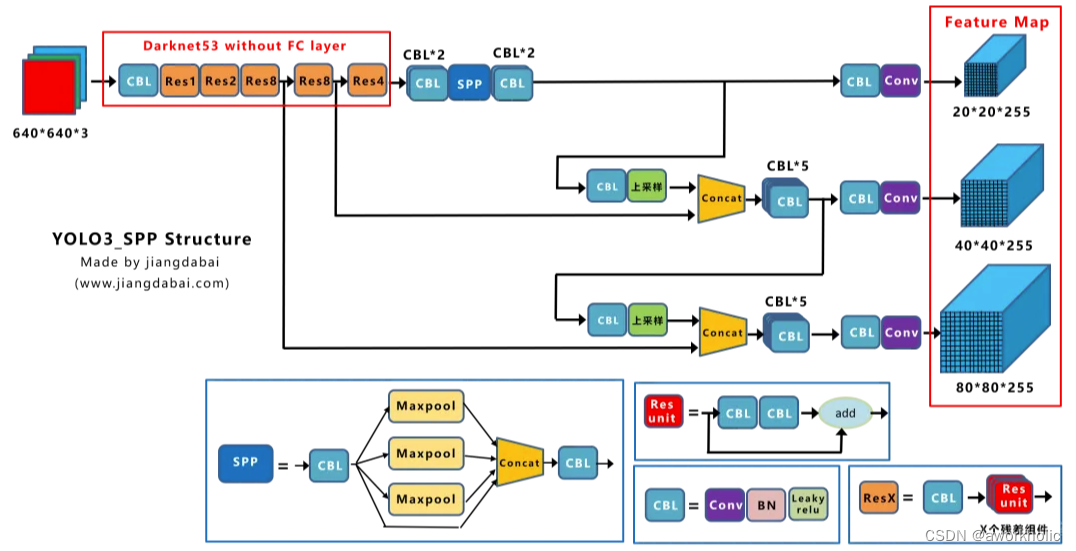
以Yolox-Darknet53为例,给出网络结构
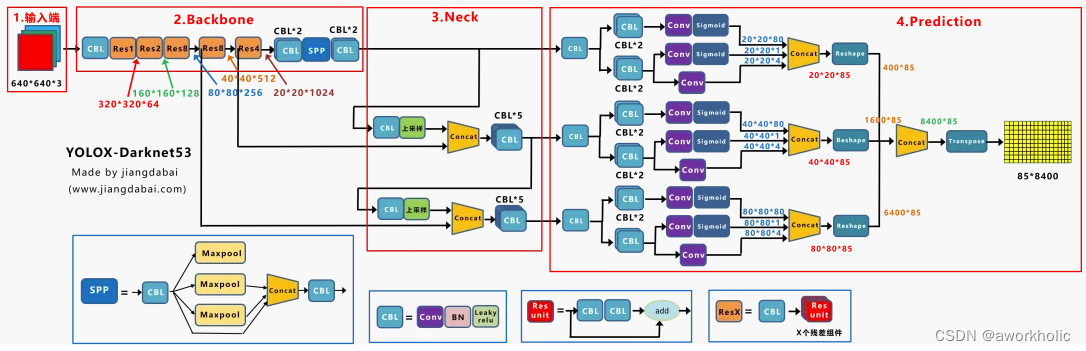
为了便于分析改进点,我们对Yolox-Darknet53网络结构进行拆分,变为四个板块:
- 输入端:Strong augmentation数据增强
- BackBone主干网络:主干网络没有什么变化,还是Darknet53。
- Neck:没有什么变化,Yolov3 baseline的Neck层还是FPN结构。
- Prediction:Decoupled Head、End-to-End YOLO、Anchor-free、Multi positives。
在经过一系列的改进后,Yolox-Darknet53最终达到AP47.3的效果。
1.1、输入
在网络的输入端,Yolox主要采用了Mosaic、Mixup两种数据增强方法。而采用了这两种数据增强,直接将Yolov3 baseline,提升了2.4个百分点。
有两点需要注意:(1)在训练的最后15个epoch,这两个数据增强会被关闭掉。而在此之前,Mosaic和Mixup数据增强,都是打开的,这个细节需要注意。(2)由于采取了更强的数据增强方式,作者在研究中发现,ImageNet预训练将毫无意义,因此,所有的模型,均是从头开始训练的。
1.2、Backbone主干网络
Yolox-Darknet53和原本的Yolov3 baseline的主干网络都是采用Darknet53的网络结构。
1.3、Neck
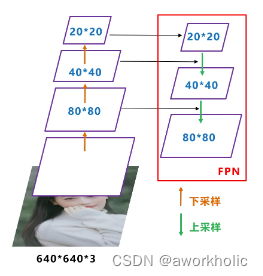
Yolox-Darknet53和Yolov3 baseline的Neck结构都是采用FPN的结构进行融合。
如下图所示,FPN自顶向下,将高层的特征信息,通过上采样的方式进行传递融合,得到进行预测的特征图。
1.4、Prediction预测输出
在输出层中,主要从四个方面进行讲解:Decoupled Head、Anchor Free、标签分配、Loss计算。
1.4.1、Decoupled Head解耦头
目前在很多一阶段网络中都有类似应用,比如RetinaNet、FCOS等。而在Yolox中,作者增加了三个Decoupled Head。
基准网络中,Yolov3 baseline的AP值为38.5。作者想继续改进,比如输出端改进为End-to-end的方式(即无NMS的形式)后的AP值只有34.3。在对FCOS改进为无NMS时,在COCO上,达到了与有NMS的FCOS,相当的性能。为什么在Yolo上改进,会下降这么多?在偶然间,作者将End-to-End中的Yolo Head,修改为Decoupled Head的方式。
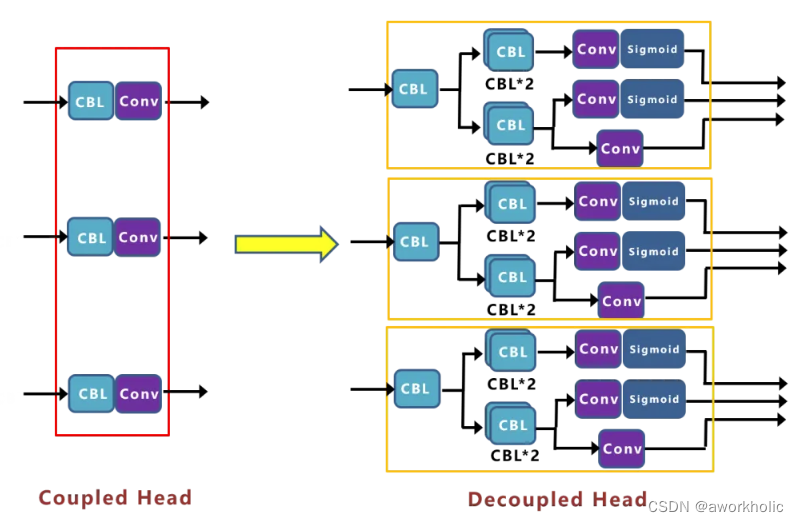
测试发现,End-to-end Yolo的AP值,从34.3增加到38.8。作者又将Yolov3 baseline 中Yolo Head,也修改为Decoupled Head,发现AP值,从38.5,增加到39.6。还发现,不单单是精度上的提高,网络的收敛速度也加快了。结论:目前Yolo系列使用的检测头,表达能力可能有所欠缺,没有Decoupled Head的表达能力更好。对比曲线如下
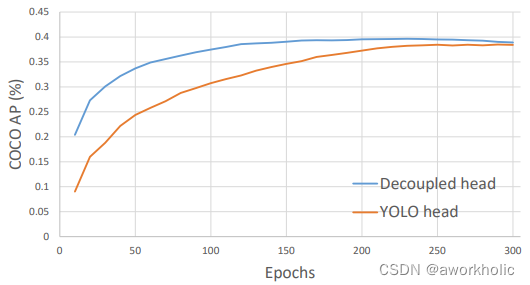
曲线表明:Decoupled Head的收敛速度更快,且精度更高一些。但是需要注意的是:将检测头解耦,会增加运算的复杂度。因此作者经过速度和性能上的权衡,最终使用 1个1x1 的卷积先进行降维,并在后面两个分支里,各使用了 2个3x3 卷积,最终调整到仅仅增加一点点的网络参数。而且这里解耦后,还有一个更深层次的重要性:Yolox的网络架构,可以和很多算法任务,进行一体化结合。比如:(1)YOLOX + Yolact/CondInst/SOLO ,实现端侧的实例分割。(2)YOLOX + 34 层输出,实现端侧人体的 17 个关键点检测。
Yolox-Darknet53的decoupled detection head的细节如图,对于预测Cls.、Reg.以及IoU参数分别使用三个不同的分支,将三者进行解耦。注意一点,在YOLOX中对于不同的预测特征图采用不同的head,即参数不共享。第一个Head 输出长度为20*20。Concat前总共有三个分支:Concat前总共有三个分支:
(1)cls_output:主要对目标框的类别,预测分数。因为COCO数据集总共有80个类别,且主要是N个二分类判断,因此经过Sigmoid激活函数处理后,变为20*20*80大小。
(2)obj_output:主要判断目标框是前景还是背景,因此经过Sigmoid处理好,变为20*20*1大小。
(3)reg_output:主要对目标框的坐标信息(x,y,w,h)进行预测,因此大小为20*20*4。
最后三个output,经过Concat融合到一起,得到20*20*85的特征信息。当然,这只是Decoupled Head①的信息,再对Decoupled Head②和③进行处理。
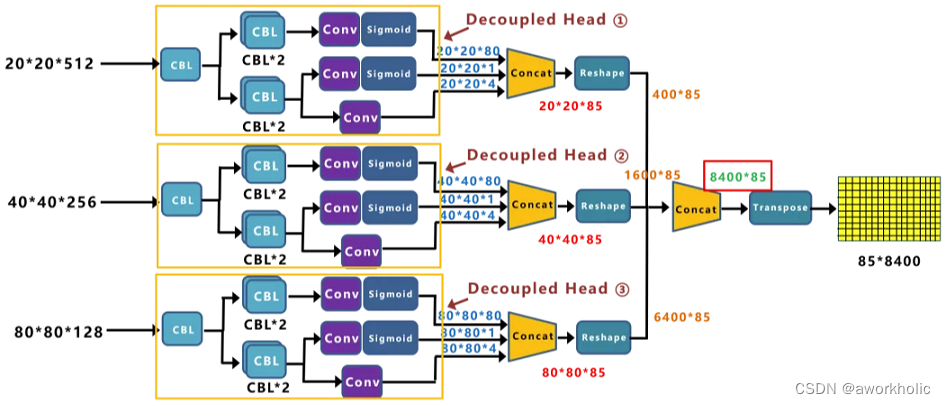
Decoupled Head②输出特征信息,并进行Concate,得到404085特征信息。Decoupled Head③输出特征信息,并进行Concate,得到808085特征信息。再对①②③三个信息,进行Reshape操作,并进行总体的Concat,得到8400*85的预测信息。
1.4.2、Anchor-Free
目前行业内,主要有Anchor Based和Anchor Free两种方式,在Yolov3、Yolov4、Yolov5中,通常都是采用Anchor Based的方式,来提取目标框,进而和标注的groundtruth进行比对,判断两者的差距。
① Anchor Based方式
比如输入图像,经过Backbone、Neck层,最终将特征信息,传送到输出的Feature Map中。这时,就要设置一些Anchor规则,将预测框和标注框进行关联。从而在训练中,计算两者的差距,即损失函数,再更新网络参数。比如在下图的,最后的三个Feature Map上,基于每个单元格,都有三个不同尺寸大小的锚框。
输入为416*416时,网络最后的三个特征图大小为13*13,26*26,52*52。每个特征图上的格点都预测三个锚框。当采用COCO数据集,即有80个类别时。基于每个锚框,都有x、y、w、h、obj(前景背景)、class(80个类别),共85个参数。因此会产生3*(13*13+26*26+52*52)*85=904995个预测结果。如果输入为640*640,最后的三个特征图大小为20*20,40*40,80*80,则会产生3*(20*20+40*40+80*80)*85=2142000个预测结果。
② Anchor Free方式
Yolox-Darknet53中,则采用Anchor Free的方式。网络的输出不同于Yolov3中的FeatureMap,而是 8400*85 的特征向量。通过计算,8400*85=714000个预测结果,比基于Anchor Based的方式,少了2/3的参数量。
Anchor框信息在前面Anchor Based中,我们知道每个Feature map的单元格,都有3个大小不一的锚框。Yolox-Darknet53仍然有,只是巧妙的将前面Backbone中下采样的大小信息引入进来。
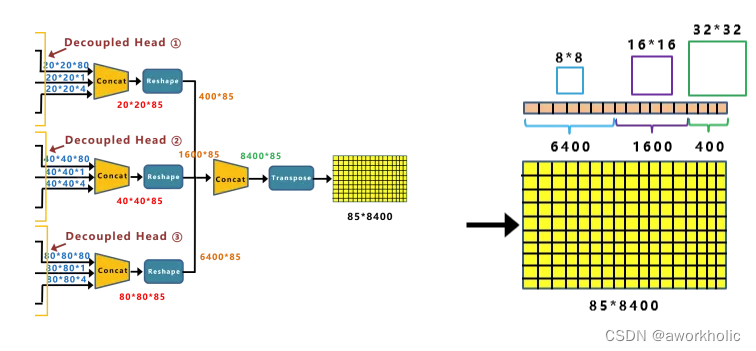
最上面的分支,下采样了5次,2的5次方为32,并且Decoupled Head①的输出,为202085大小。中间的分支,有1600个预测框,所对应锚框的大小为16*16。最后分支有6400个预测框,所对应锚框的大小,为8*8。
1.4.3、标签分配
1.4.4、Loss计算
1.5、Yolox-s、l、m、x系列
Yolov5s的网络结构图
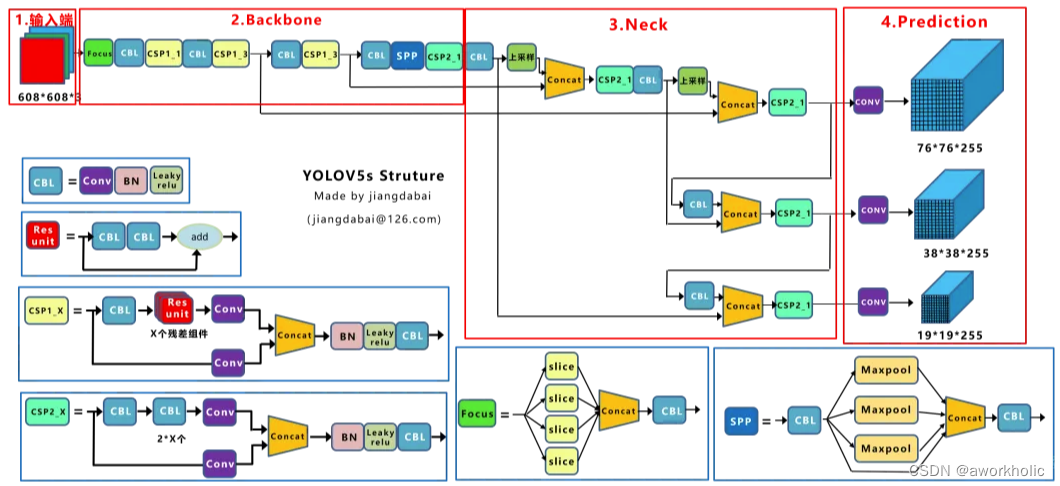
Yolox-s的网络结构:
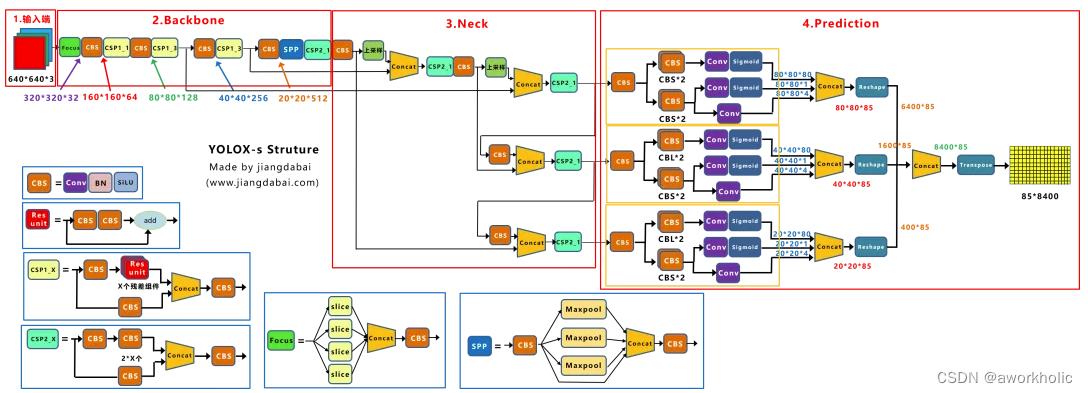
由上面两张图的对比,及前面的内容可以看出,Yolov5s和Yolox-s主要区别在于:(1)输入端:在Mosa数据增强的基础上,增加了Mixup数据增强效果;(2)Backbone:激活函数采用SiLU函数;(3)Neck:激活函数采用SiLU函数;(4)输出端:检测头改为Decoupled Head、采用anchor free、multi positives、SimOTA的方式。在前面Yolov3 baseline的基础上,以上的tricks,取得了很不错的涨点。
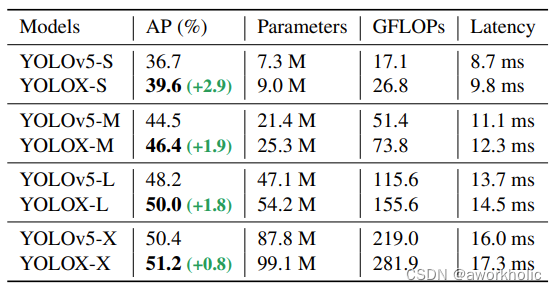 可以看出,在速度增加1ms左右的情况下,AP精度实现了0.8~2.9的涨点。且网络结构越轻,比如Yolox-s的时候,涨点最多,达到2.9的涨点。随着网络深度和宽度的加深,涨点慢慢降低,最终Yolox-x有0.8的涨点。
可以看出,在速度增加1ms左右的情况下,AP精度实现了0.8~2.9的涨点。且网络结构越轻,比如Yolox-s的时候,涨点最多,达到2.9的涨点。随着网络深度和宽度的加深,涨点慢慢降低,最终Yolox-x有0.8的涨点。
1.6、轻量级网络研究
在对Yolov3、Yolov5系列进行改进后,作者又设计了两个轻量级网络,与Yolov4-Tiny、和Yolox-Nano进行对比。在研究过程中,作者有两个方面的发现,主要从轻量级网络,和数据增强的优缺点,两个角度来进行描述。
1.6.1、轻量级网络
因为实际场景的需要将Yolo移植到边缘设备中。因此针对Yolov4-Tiny,构建了Yolox-Tiny网络结构;针对FCOS 风格的NanoDet,构建了Yolox-Nano网络结构。
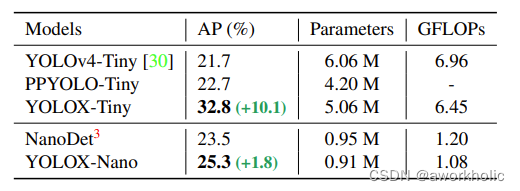
从上表可以看出:(1)和Yolov4-Tiny相比,Yolox-Tiny在参数量下降1M的情况下,AP值实现了9个点的涨点。(2)和NanoDet相比,Yolox-Nano在参数量下降,仅有0.91M的情况下,实现了1.8个点的涨点。(3)因此可以看出,Yolox的整体设计,在轻量级模型方面,依然有很不错的改进点。
1.6.2、数据增强的优缺点
在Yolox的很多对比测试中,都使用了数据增强的方式。但是不同的网络结构,有的深有的浅,网络的学习能力不同,那么无节制的数据增强是否真的更好呢?作者团队,对这个问题也进行了对比测试。
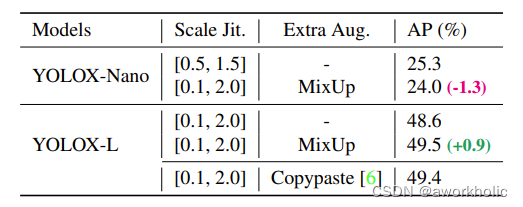
通过以上的表格有以下发现:
① Mosaic和Mixup混合策略(1)对于轻量级网络,Yolox-nano来说,当在Mosaic基础上,增加了Mixup数据增强的方式,AP值不增反而降,从25.3降到24。(2)而对于深一些的网络,Yolox-L来说,在Mosaic基础上,增加了Mixup数据增强的方式,AP值反而有所上升,从48.6增加到49.5。(3)因此不同的网络结构,采用数据增强的策略也不同,比如Yolox-s、Yolox-m,或者Yolov4、Yolov5系列,都可以使用不同的数据增强策略进行尝试。
② Scale 增强策略在Mosaic数据增强中,代码Yolox/data/data_augment.py中的random_perspective函数,生成仿射变换矩阵时,对于图片的缩放系数,会生成一个随机值。
对于Yolox-l来说,随机范围scale设置在[0.1,2]之间,即文章中设置的默认参数;而当使用轻量级模型,比如YoloNano时,一方面只使用Mosaic数据增强,另一方面随机范围scale,设置在[0.5,1.5]之间,弱化Mosaic增广的性能。
1.7、Yolox的实现成果
1.7.1、精度速度对比
前面我们了解了Yolox的各种trick改进的原因以及原理,下面我们再整体看一下各种模型精度速度方面的对比:
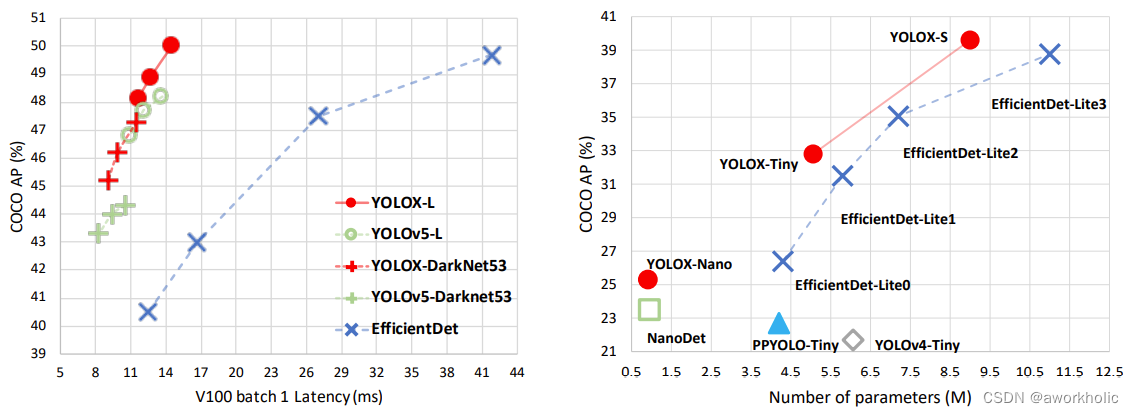
左面的图片是相对比较标准的,网络结构的对比效果,主要从速度和精度方面,进行对比。而右面的图片,则是轻量级网络的对比效果,主要对比的是参数量和精度。
从左面的图片可以得出:(1)和与Yolov4-CSP相当的Yolov5-l进行对比,Yolo-l在COCO数据集上,实现AP50%的指标,在几乎相同的速度下超过Yolov5-l 1.8个百分点。(2)而Yolox-Darknet53和Yolov5-Darknet53相比,实现AP47.3%的指标,在几乎同等速度下,高出3个百分点。
而从右面的图片可以得出:(1)和Nano相比,Yolox-Nano参数量和GFLOPS都有减少,参数量为0.91M,GFLOPS为1.08,但是精度可达到25.3%,超过Nano1.8个百分点。(2)而Yolox-Tiny和Yolov4-Tiny相比,参数量和GFLOPS都减少的情况下,精度远超Yolov4-Tiny 9个百分点。
1.7.2、Autonomous Driving竞赛
在CVPR2021自动驾驶竞赛的,Streaming Perception Challenge赛道中,挑战的主要关注点之一,是自动驾驶场景下的实时视频流2D目标检测问题。由一个服务器收发图片和检测结果,来模拟视频流30FPS的视频,客户端接收到图片后进行实时推断。竞赛地址: https://eval.ai/web/challenges/challenge-page/800/overview
在竞赛中旷视科技采用Yolox-l作为参赛模型,同时使用TensorRT进行推理加速,最终获得了full-track和detection-only track,两个赛道比赛的第一。因此Yolox的各种改进方式还是挺不错,值得好好学习,深入研究一下。
1.8、网络训练
参考链接 https://github.com/Megvii-BaseDetection/YOLOX/blob/main/docs/train_custom_data.md
2、测试
首先clone项目并安装
git clone git@github.com:Megvii-BaseDetection/YOLOX.git
cd YOLOX
pip3 install -v -e . # or python3 setup.py develop
我们以yolox-m模型为例进行测试,下载链接使用wget工具下载
wget https://github.com/Megvii-BaseDetection/YOLOX/releases/download/0.1.1rc0/yolox_m.pth
2.1、官方脚本测试
2.1.1、torch 模型测试
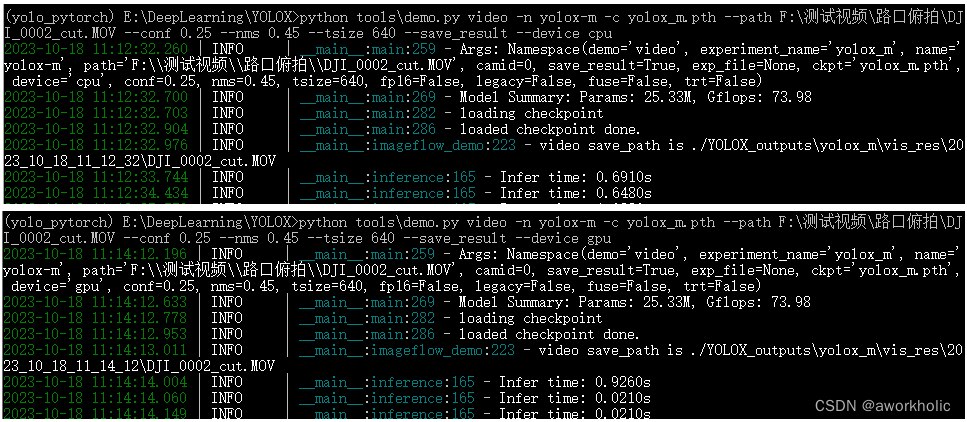
python tools/demo.py image -n yolox-m -c yolox_m.pth --path assets/dog.jpg --conf 0.25 --nms 0.45 --tsize 640 --save_result --device [cpu/gpu]
针对一个 1080p是视频,分别用 cpu和gpu测试,每一帧推理耗时分别为 650ms、20ms。
2.1.2、onnx 模型测试
官方提供了模型下载链接 https://ghproxy.com/https://github.com/Megvii-BaseDetection/YOLOX/releases/download/0.1.1rc0/yolox_m.onnx。
或者,通过脚本从 .pth 转换得到
python tools/export_onnx.py --output-name yolox_m.onnx -f exps/default/yolox_m.py -c yolox_m.pth
测试代码
python demo\ONNXRuntime\onnx_inference.py -m yolox_m.onnx -i assets\bus.jpg -o output -s 0.3 --input_shape 640,640
执行后的结果图将保存在 output 文件夹下。
2.1.3、opencv dnn测试
注意输出的后处理流程,yolox的输出为原始输出,需要解码。根据不同特征图大小、偏移和步长,计算映射到输入图像大小上的目标框,最后进行缩放到原图上。
当80类输入640*640时,输出[8400,85], 8400为目标框总个数,85为目标框的信息,格式为
[center_x, center_y, w,h, obj-score, cls1-score, cls2-score, ... , cls80-score]
8400个目标框基于anchor free,在三个不同特征图上生成, [80,80],[40,40],[20,20],对应特征图步长为 strides = 8,16, 32。首先是特征图[80,80],存在6400个位置,每个位置对应 80类目标的信息(85维);之后同理,[40,40]存在1600个位置,[20,20]存在400个位置。
center_x, center_y :表示位于当前特征图的格点位置偏移,例如 在40x40上, 格点(1,2),那么 center_x = 0.12,center_y = 0.08, 那么映射到 输入图上是位置为 [(1+0.12)*16,( 2 + 0.08) *16 ]
w,h :目标框的宽高,映射到输入图上宽高 需要乘以当前目标框所在特征图上的对应步长。
obj-score:存在目标的置信度
cls1-score, cls2-score, … , cls80-score : 每一类的置信度, 实际目标置信度要再乘以 obj-score
以下直接给出代码如下
#pragma once#include "opencv2/opencv.hpp"#include <fstream>
#include <sstream>#include <random>using namespace cv;
using namespace dnn;float inpWidth;
float inpHeight;
float confThreshold, scoreThreshold, nmsThreshold;
std::vector<std::string> classes;
std::vector<cv::Scalar> colors;bool letterBoxForSquare = true;cv::Mat formatToSquare(const cv::Mat &source);void postprocess(Mat& frame, cv::Size inputSz, const std::vector<Mat>& out, Net& net);void drawPred(int classId, float conf, int left, int top, int right, int bottom, Mat& frame);std::random_device rd;
std::mt19937 gen(rd());
std::uniform_int_distribution<int> dis(100, 255);struct GridAndStride
{int grid0;int grid1;int stride;
};static void generate_grids_and_stride(std::vector<int>& strides, std::vector<GridAndStride>& grid_strides)
{for(auto stride : strides) {int num_grid_y = inpHeight / stride;int num_grid_x = inpWidth / stride;for(int g1 = 0; g1 < num_grid_y; g1++) {for(int g0 = 0; g0 < num_grid_x; g0++) {grid_strides.push_back(GridAndStride{g0, g1, stride});}}}
}std::vector<GridAndStride> grid_strides;int NUM_CLASSES;int testYolo_x()
{// 根据选择的检测模型文件进行配置 confThreshold = 0.25;scoreThreshold = 0.45;nmsThreshold = 0.5;float scale = 1; // 1 / 255.0; //0.00392Scalar mean = {0,0,0};bool swapRB = true;inpWidth = 640;inpHeight = 640;String modelPath = R"(E:\DeepLearning\YOLOX\yolox_m.onnx)";String configPath;String framework = "";//int backendId = cv::dnn::DNN_BACKEND_OPENCV;//int targetId = cv::dnn::DNN_TARGET_CPU;int backendId = cv::dnn::DNN_BACKEND_CUDA;int targetId = cv::dnn::DNN_TARGET_CUDA;String classesFile = R"(E:\DeepLearning\darknet-yolo3-master\data\coco.names)";// Open file with classes names.if(!classesFile.empty()) {const std::string& file = classesFile;std::ifstream ifs(file.c_str());if(!ifs.is_open())CV_Error(Error::StsError, "File " + file + " not found");std::string line;while(std::getline(ifs, line)) {classes.push_back(line);colors.push_back(cv::Scalar(dis(gen), dis(gen), dis(gen)));}}NUM_CLASSES = classes.size();std::vector<int> strides = {8, 16, 32};generate_grids_and_stride(strides, grid_strides);// Load a model.Net net = readNet(modelPath, configPath, framework);net.setPreferableBackend(backendId);net.setPreferableTarget(targetId);std::vector<String> outNames = net.getUnconnectedOutLayersNames();{int dims[] = {1,3,inpHeight,inpWidth};cv::Mat tmp = cv::Mat::zeros(4, dims, CV_32F);std::vector<cv::Mat> outs;net.setInput(tmp);for(int i = 0; i<10; i++)net.forward(outs, outNames); // warmup}// Create a windowstatic const std::string kWinName = "Deep learning object detection in OpenCV";cv::namedWindow(kWinName, 0);// Open a video file or an image file or a camera stream.VideoCapture cap;cap.open(R"(E:\DeepLearning\yolov5\data\images\bus.jpg)");cv::TickMeter tk;Mat frame, blob;while(waitKey(1) < 0) {cap >> frame;if(frame.empty()) {waitKey();break;}// Create a 4D blob from a frame.cv::Mat modelInput = frame;if(letterBoxForSquare && inpWidth == inpHeight)modelInput = formatToSquare(modelInput);blobFromImage(modelInput, blob, scale, cv::Size2f(inpWidth, inpHeight), mean, swapRB, false);// Run a model.net.setInput(blob);std::vector<Mat> outs;//tk.reset();//tk.start();auto tt1 = cv::getTickCount();net.forward(outs, outNames);auto tt2 = cv::getTickCount();tk.stop();postprocess(frame, modelInput.size(), outs, net);//tk.stop();std::string label = format("Inference time: %.2f ms", (tt2 - tt1) / cv::getTickFrequency() * 1000);cv::putText(frame, label, Point(0, 15), FONT_HERSHEY_SIMPLEX, 0.5, Scalar(0, 255, 0));cv::imshow(kWinName, frame);}return 0;
}cv::Mat formatToSquare(const cv::Mat &source)
{int col = source.cols;int row = source.rows;int _max = MAX(col, row);cv::Mat result = cv::Mat::zeros(_max, _max, CV_8UC3);source.copyTo(result(cv::Rect(0, 0, col, row)));return result;
}void postprocess(Mat& frame, cv::Size inputSz, const std::vector<Mat>& outs, Net& net)
{// yolox has an output of shape (batchSize, 8400, 85) (box[x,y,w,h] + confidence[c] + Num classes )auto tt1 = cv::getTickCount();float x_factor = inputSz.width / inpWidth;float y_factor = inputSz.height / inpHeight;std::vector<int> class_ids;std::vector<float> confidences;std::vector<cv::Rect> boxes;float *feat_blob = (float *)outs[0].data;const int num_anchors = grid_strides.size();// 后处理部分,可以简化for(int anchor_idx = 0; anchor_idx < num_anchors; anchor_idx++) {const int grid0 = grid_strides[anchor_idx].grid0;const int grid1 = grid_strides[anchor_idx].grid1;const int stride = grid_strides[anchor_idx].stride;const int basic_pos = anchor_idx * (NUM_CLASSES + 5);float box_objectness = feat_blob[basic_pos + 4];for(int class_idx = 0; class_idx < NUM_CLASSES; class_idx++) {float box_cls_score = feat_blob[basic_pos + 5 + class_idx];float box_prob = box_objectness * box_cls_score;if(box_prob > scoreThreshold) {class_ids.push_back(class_idx);confidences.push_back(box_prob);// yolox/models/yolo_head.py decode logicfloat x_center = (feat_blob[basic_pos + 0] + grid0) * stride;float y_center = (feat_blob[basic_pos + 1] + grid1) * stride;float w = exp(feat_blob[basic_pos + 2]) * stride;float h = exp(feat_blob[basic_pos + 3]) * stride;int left = int((x_center - 0.5 * w) * x_factor);int top = int((y_center - 0.5 * h) * y_factor);int width = int(w * x_factor);int height = int(h * y_factor);boxes.push_back(cv::Rect(left, top, width, height));}} // class loop}std::vector<int> indices;NMSBoxes(boxes, confidences, scoreThreshold, nmsThreshold, indices);auto tt2 = cv::getTickCount();std::string label = format("NMS time: %.2f ms", (tt2 - tt1) / cv::getTickFrequency() * 1000);cv::putText(frame, label, Point(0, 30), FONT_HERSHEY_SIMPLEX, 0.5, Scalar(0, 255, 0));for(size_t i = 0; i < indices.size(); ++i) {int idx = indices[i];Rect box = boxes[idx];drawPred(class_ids[idx], confidences[idx], box.x, box.y,box.x + box.width, box.y + box.height, frame);}
}void drawPred(int classId, float conf, int left, int top, int right, int bottom, Mat& frame)
{rectangle(frame, Point(left, top), Point(right, bottom), Scalar(0, 255, 0));std::string label = format("%.2f", conf);Scalar color = Scalar::all(255);if(!classes.empty()) {CV_Assert(classId < (int)classes.size());label = classes[classId] + ": " + label;color = colors[classId];}int baseLine;Size labelSize = getTextSize(label, FONT_HERSHEY_SIMPLEX, 0.5, 1, &baseLine);top = max(top, labelSize.height);rectangle(frame, Point(left, top - labelSize.height),Point(left + labelSize.width, top + baseLine), color, FILLED);cv::putText(frame, label, Point(left, top), FONT_HERSHEY_SIMPLEX, 0.5, Scalar());
}
后处理中,可以精简,仅处理每个目标框最大概率的类别数据,以提高运行速度,以及能极大的提高NMS的时间。
void postprocess(Mat& frame, cv::Size inputSz, const std::vector<Mat>& outs, Net& net)
{....for(int anchor_idx = 0; anchor_idx < num_anchors; anchor_idx++) {const int grid0 = grid_strides[anchor_idx].grid0;const int grid1 = grid_strides[anchor_idx].grid1;const int stride = grid_strides[anchor_idx].stride;const int basic_pos = anchor_idx * (NUM_CLASSES + 5);float *data = feat_blob + basic_pos;float confidence = data[4];if(confidence < confThreshold)continue;cv::Mat scores(1, classes.size(), CV_32FC1, data + 5);cv::Point class_id;double max_class_score;minMaxLoc(scores, 0, &max_class_score, 0, &class_id);float box_prob = confidence * max_class_score;if(box_prob > scoreThreshold) {class_ids.push_back(class_id.x);confidences.push_back(box_prob);// yolox/models/yolo_head.py decode logicfloat x_center = (feat_blob[basic_pos + 0] + grid0) * stride;float y_center = (feat_blob[basic_pos + 1] + grid1) * stride;float w = exp(feat_blob[basic_pos + 2]) * stride;float h = exp(feat_blob[basic_pos + 3]) * stride;int left = int((x_center - 0.5 * w) * x_factor);int top = int((y_center - 0.5 * h) * y_factor);int width = int(w * x_factor);int height = int(h * y_factor);boxes.push_back(cv::Rect(left, top, width, height));} }... // nms + draw
}
测试结果:
cuda 36ms, cpu 420ms, fp16 650ms。

2.2、测试汇总对比
使用onnx在其他框架上测试的汇总
opencv cuda: 36ms
opencv cpu: 420ms,
opencv cuda fp16: 650ms
以下包含 预处理+推理+后处理
openvino(CPU): 199ms
onnxruntime(GPU):22ms
trt:13ms
相关文章:
opencv dnn模块 示例(19) 目标检测 object_detection 之 yolox
文章目录 0、前言1、网络介绍1.1、输入1.2、Backbone主干网络1.3、Neck1.4、Prediction预测输出1.4.1、Decoupled Head解耦头1.4.2、Anchor-Free1.4.3、标签分配1.4.4、Loss计算 1.5、Yolox-s、l、m、x系列1.6、轻量级网络研究1.6.1、轻量级网络1.6.2、数据增强的优缺点 1.7、Y…...

微信小程序阻止返回事件
需求场景 当在一个表单页面 填写了很多数据,或者编辑页面数据发生变动之后,这时候返回上一个页面需要提醒用户是否返回的弹框 实现方法一(ios会存在一定的问题) 在onLoad生命周期里 注册 wx.enableAlertBeforeUnload({message: "您内容已更新,还没保存,确定要退出吗?&…...

YOLOv7改进:新颖的上下文解耦头TSCODE,即插即用,各个数据集下实现暴力涨点
💡💡💡本文属于原创独家改进:上下文解耦头TSCODE,进行深、浅层的特征融合,最后再分别输入到头部进行相应的解码输出,实现暴力暴力涨点 上下文解耦头TSCODE| 亲测在多个数据集实现暴力涨点,对遮挡场景、小目标场景提升也明显; 收录: YOLOv7高阶自研专栏介绍: …...
Unity中Shader阴影的接收
文章目录 前言一、阴影接受的步骤1、在v2f中添加UNITY_SHADOW_COORDS(idx),unity会自动声明一个叫_ShadowCoord的float4变量,用作阴影的采样坐标.2、在顶点着色器中添加TRANSFER_SHADOW(o),用于将上面定义的_ShadowCoord纹理采样坐标变换到相应的屏幕空间…...

✔ ★【备战实习(面经+项目+算法)】 10.22学习时间表(总计学习时间:4.5h)(算法刷题:7道)
✔ ★【备战实习(面经项目算法)】 坚持完成每天必做如何找到好工作1. 科学的学习方法(专注!效率!记忆!心流!)2. 每天认真完成必做项,踏实学习技术 认真完成每天必做&…...
Amazonlinux2023(AL2023)获取metadata
今年AWS发布了新的Amazonlinux2023版本,其中获取metadata元数据方式发生了一点改变。 早些时候,在 Amazon Linux 2 中,使用以下命令获取实例元数据 http://169.254.169.254/latest/meta-data/ 具体可以获取的元数据类别可以查阅如下aws官方…...
C++(Chapter 3)
C(三) 1.引用 1.引用的概念 引用的概念:引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空间,它和它引用的变量共用同一块内存空间。 引用的语法:类型& 引用变量名(对象名) 引用实体 ; 例如: #i…...

优化单元测试效率:Spring 工程启动耗时统计
相关文章: Java Agent 的简单使用 本文相关代码地址:https://gitee.com/dongguabai/blog 单元测试在软件项目的可持续发展中扮演着不可或缺的角色,这一点毫无疑问。不久前,公司大佬在内部分享时也提到过:单元测试是…...

华纳云:连接mysql出现2059错误怎么解决
MySQL连接错误2059通常表示MySQL服务器拒绝了连接。这种错误可能由多种原因引起,以下是一些可能的解决方法: 检查MySQL服务器是否正在运行: 确保MySQL服务器正在正常运行。您可以使用以下命令检查MySQL服务器的状态: systemctl st…...

零基础Linux_22(多线程)线程控制和和C++的多线程和笔试选择题
目录 1. 线程控制 1.1 线程创建(pthread_create) 1.2 线程结束(pthread_exit) 1.3 线程等待(pthread_join) 1.4 线程取消(pthread_cancel结束) 1.5 线程tid(pthread_self()) 1.6 线程局部存储(__thread) 1.7 线程分离(pthread_detach) 2. C的多线程 3. 笔试选择题 答…...
docker版本的Jenkins安装与更新技巧
因为jenkins/jenkins镜像默认带的jenkins版本比较低,导致安装完以后,很多插件因为版本问题无法安装。以下是最权威,最方便的安装教程。 1. 创建本地挂载目录 mkdir -p /mnt/dockerdata/jenkins/home/2. 修改挂载目录权限 chown -R 1000:10…...
[C++]3.类和对象下(this指针补充)+ 类和对象中构造函数和析构函数。
类和对象下(this指针补充) 类和对象中构造函数和析构函数 一.this补充:1.概念总结:2.两个问题: 二.构造函数和析构函数:一.类的默认构造:1.初始化和清理:2.拷贝复制:3.取…...

OpenLDAP LDIF详解
手把手一步步搭建LDAP服务器并加域 有必要理解的概念LDAPWindows Active Directory 服务器配置安装 OpenLDAP自定义安装修改对象(用户和分组等)修改olcSuffix 和 olcRootDN 属性增加olcRootPW 属性修改olcAccess属性验证新属性值 添加对象(用…...

Leetcode.33 搜索旋转排序数组
题目链接 Leetcode.33 搜索旋转排序数组 mid 题目描述 整数数组 n u m s nums nums 按升序排列,数组中的值 互不相同 。 在传递给函数之前, n u m s nums nums 在预先未知的某个下标 k ( 0 ≤ k < n u m s . l e n g t h )…...

ES 8.x 向量检索性能测试 把向量检索性能提升100倍!
向量检索不仅在的跨模态检索场景中应用广泛,随着chat gpt的或者,利用es的向量检索,在Ai领域发挥着越来越大的作用。 本文,主要测试es的向量检索性能。我从8.x就开始关注ES的向量检索了。当前ES已经发布到 8.10 版本。以下是官方文…...
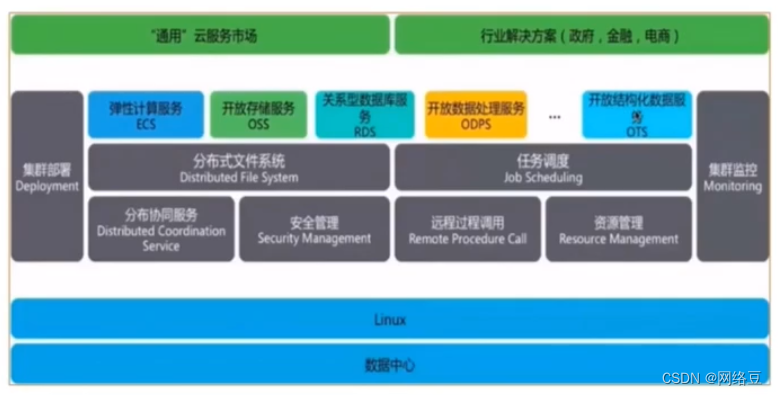
云计算——ACA学习 云计算架构
作者简介:一名云计算网络运维人员、每天分享网络与运维的技术与干货。 公众号:网络豆云计算学堂 座右铭:低头赶路,敬事如仪 个人主页: 网络豆的主页 目录 写在前面 前期回顾 本期介绍 一.云计算架…...
基于深度学习实现一张单图,一个视频,一键换脸,Colab脚本使用方法,在线版本,普通人也可以上传一张图片体验机器学习一键换脸
基于深度学习实现一张单图,一个视频,一键换脸,Colab脚本使用方法,在线版本,普通人也可以上传一张图片体验机器学习一键换脸。 AI领域人才辈出,突然就跳出一个大佬“s0md3v”,开源了一个单图就可以进行视频换脸的项目。 项目主页给了一张换脸动图非常有说服力,真是一图…...

leetcode 21
递归的方式 class Solution { public:ListNode* mergeTwoLists(ListNode* l1, ListNode* l2) {if(l1 nullptr){return l2;}else if(l2 nullptr){return l1;}else if(l1->val < l2->val){l1->next mergeTwoLists(l1->next, l2);return l1;}else if(l1->va…...
)
【Spring Cloud】openfeign负载均衡方案(和lb发展历史)
文章目录 版本1:原始loadBalancerClient方案版本2:ribbon-loadbalancer方案版本3:openfeign方案(即**方案2openfeign版本**) 本文描述了Spring Cloud微服务中,各个服务间调用的负载均衡方案的升级历史&…...

R语言:主成分分析PCA
文章目录 主成分分析处理步骤数据集code主成分分析 主成分分析(或称主分量分析,principal component analysis)由皮尔逊(Pearson,1901)首先引入,后来被霍特林(Hotelling,1933)发展。 主成分分析是一种通过降维技术把多个变量化为少数几个主成分(即综合变量)的统计分…...

网络原理视角下的CasRel模型分布式部署与通信优化
网络原理视角下的CasRel模型分布式部署与通信优化 最近在帮一个团队落地一个关系抽取项目,他们用的就是CasRel模型。模型本身效果不错,但一到线上高并发场景,单实例就扛不住了,响应延迟飙升,还时不时挂掉。这让我意识…...

终极AI图像修复指南:用Real-ESRGAN让低清动漫影像重现光彩
终极AI图像修复指南:用Real-ESRGAN让低清动漫影像重现光彩 【免费下载链接】Anime4K A High-Quality Real Time Upscaler for Anime Video 项目地址: https://gitcode.com/gh_mirrors/an/Anime4K Anime4K是一款高性能实时动漫视频超分辨率工具,能…...
)
Cadence 17.4 保姆级教程:从Database Check到Gerber文件一键导出(附嘉立创预览指南)
Cadence 17.4 全流程制板文件导出实战指南:从设计验证到生产交付 在PCB设计领域,Cadence Allegro作为行业标准工具链的核心组成部分,其制板文件导出流程的规范性直接关系到生产质量与成本控制。本文将系统梳理从设计完成到Gerber文件交付的完…...

用SDNET2018和Crack500数据集训练YOLOv8,手把手教你搞定混凝土裂缝检测模型
基于SDNET2018与Crack500的YOLOv8裂缝检测实战指南 混凝土结构的安全评估中,裂缝检测是关键环节。传统人工巡检效率低下且易漏检,而基于深度学习的自动化方案能显著提升检测精度与效率。本文将手把手带您完成从数据集处理到模型部署的全流程,…...

深入解析PG332 ERNIC:基于RoCE v2的嵌入式RDMA加速引擎
1. PG332 ERNIC:重新定义嵌入式网络加速 第一次接触PG332 ERNIC这个IP核时,我正为一个工业视觉项目头疼——传统TCP/IP协议栈的延迟让机械臂控制指令总是慢半拍。直到测试了基于RoCE v2的ERNIC方案,端到端延迟直接从毫秒级降到微秒级…...

10-项目规划测试代码审查实战
10-项目规划、测试、代码审查实战使用 Cursor 完成软件工程全流程:项目规划、测试驱动开发、代码审查与质量保障。一、AI 驱动项目管理概述 1.1 全流程覆盖 项目启动↓ 需求分析 → AI 辅助需求拆解↓ 技术方案 → AI 生成架构设计↓ 任务分解 → AI 生成任务清单↓…...

AD09 PCB设计技巧与实战经验分享
1. PCB设计基础与AD09软件概述作为一名从业十年的硬件工程师,我使用Altium Designer(简称AD)完成了近百个PCB设计项目,从简单的双面板到复杂的八层板都有涉及。AD09虽然是比较早期的版本,但其核心功能已经非常完善&…...

USB MIDI嵌入式库:跨平台Arduino MIDI通信方案
1. USBMIDI库概述:面向嵌入式开发者的USB MIDI通信解决方案USBMIDI是一个专为Arduino平台设计的轻量级USB MIDI协议栈,其核心目标并非简单复刻标准MIDI接口功能,而是构建一套可无缝迁移、低侵入式集成、硬件抽象完备的底层通信框架。该库不依…...
Pixel Language Portal详细步骤:从GitHub源码构建到自定义16-bit图标替换
Pixel Language Portal详细步骤:从GitHub源码构建到自定义16-bit图标替换 1. 项目介绍与准备工作 Pixel Language Portal(像素语言跨维传送门)是一款基于Tencent Hunyuan-MT-7B翻译引擎构建的创新型翻译工具。它将传统翻译功能与16-bit像素…...
)
Debian 12 内网求生记:手把手搞定1Panel离线安装与Docker启动(附iptables补丁)
Debian 12 内网求生记:手把手搞定1Panel离线安装与Docker启动(附iptables补丁) 1. 内网环境下的技术挑战 在完全隔离的内网环境中部署现代化运维工具,就像在没有GPS的荒野中寻找方向。我们面对的不仅是网络连接的缺失,…...