SqueezeNet 一维,二维网络复现 pytorch 小白易懂版
SqueezeNet
时隔一年我又开始复现神经网络的经典模型,这次主要复的是轻量级网络全家桶,轻量级神经网络旨在使用更小的参数量,无限的接近大模型的准确率,降低处理时间和运算量,这次要复现的是轻量级网络的非常经典的一个模型SqueezeNet,它由美国加州大学伯克利分校的研究团队开发,并于2016年发布。
文章链接: https://arxiv.org/pdf/1602.07360.pdf?source=post_page---------------------------
看懂这篇文章需要的基础知识
- 了解python语法基础
- 了解深度学习基本原理
- 知道什么是卷积层池化层激活函数层softmanx层
- 熟悉卷积层池化层需要的参数
- 需要了解pytorch模型的基本构成
我记得去年的这个时候,好像GPT还没被特别广泛的使用,还没到一键就能直接输出写好的模型的这一个步骤,那为什么还要看博客这类的文章呢,应该是因为毕竟GPT他还是靠着已有的资料进行读取,他不能图文并茂的给你写一个一定好用的大型模型,不然直接把论文甩给他让他复现就好了,所以还是打算写一下,然后简单画点图然后给之后的学弟学妹们留一点遗产。
SqueezeNet 的模型结构
下面是原论文给出的模型结构
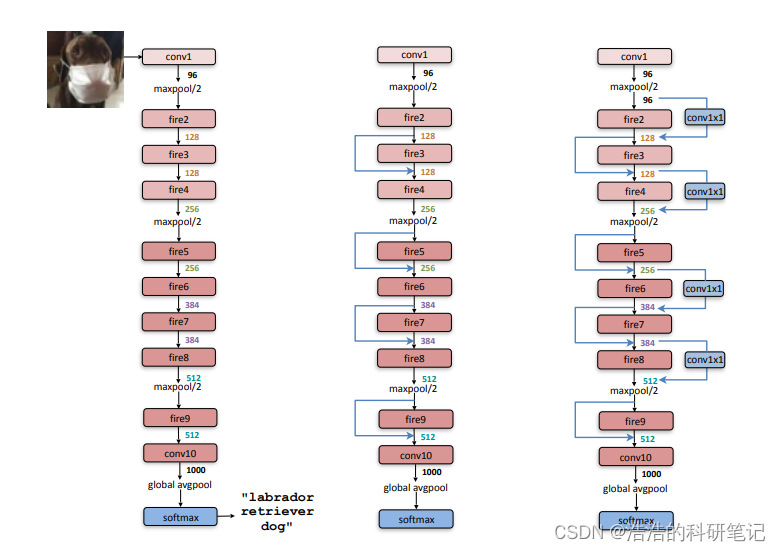
原文中给出了三种模型,分别是第一个基础模型,以及第二个和第三个带有残差分支的模型,其中卷积池化分支我们都有了解,这里新的东西就是这个Fire层,那就先从这个Fire层开始介绍
Fire层
作者说他的SqueezeNet网络为什么可以有更小的参数量,主要由于用了下面这个叫Fire层的东西,Fire层分两部分
- 一部分是Squeeze层其实就是卷积核大小为1×1的一个卷积层
- 另一部分呢是expend层他实际上是卷积核大小为1×1和卷积核大小为卷积层和3×3输出的一个拼接
下面是原论文中对Fire模型的详细描述

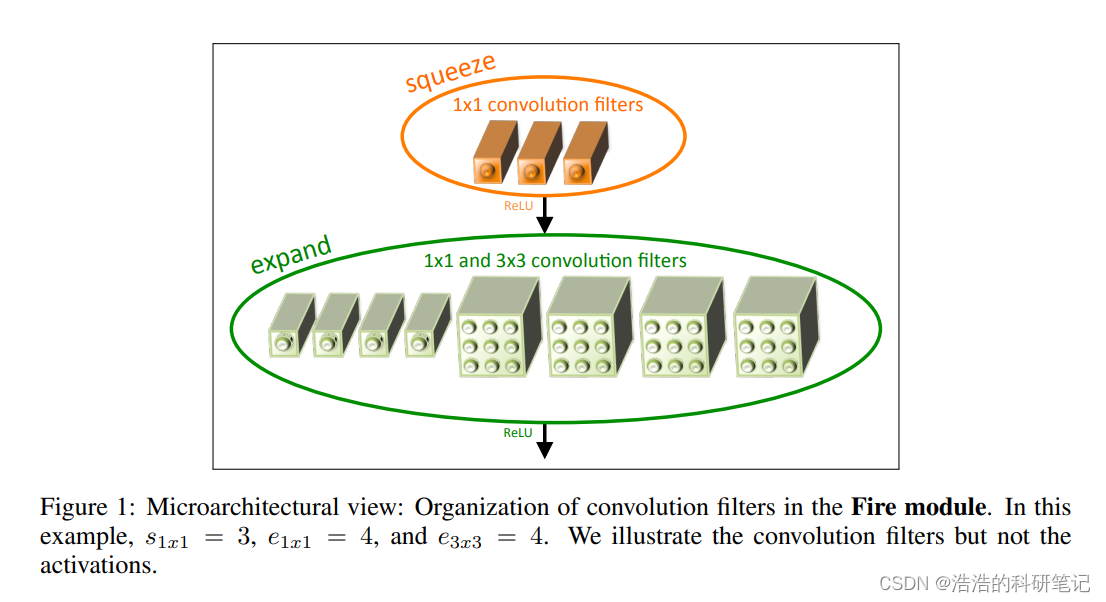
那如果要实现一维的那就把3×3的卷积核改成1×3的
加上激活函数,其实现代码应该是这样的,接下来详细介绍里面的参数。
- in_channels 指Fire模块的输入通道数,也是就每个Fire模块的squeeze卷积层的输入通道数
- squeeze_channels 指的是squeeze层的输出通道数
- expand1x1_channels 指的是expand层中卷积核大小为1×1的卷积层的输出通道数
- expand1x3_channels 指的是expand层中卷积核大小为1×2的卷积层的输出通道数
class FireModule(torch.nn.Module):def __init__(self, in_channels, squeeze_channels, expand1x1_channels, expand1x3_channels):super(FireModule, self).__init__()self.squeeze = torch.nn.Conv1d(in_channels, squeeze_channels, kernel_size=1)self.relu = torch.nn.ReLU(inplace=True)self.expand1x1 = torch.nn.Conv1d(squeeze_channels, expand1x1_channels, kernel_size=1)self.expand1x3 = torch.nn.Conv1d(squeeze_channels, expand1x3_channels, kernel_size=3, padding=1)def forward(self, x):x = self.squeeze(x)x = self.relu(x)out1x1 = self.expand1x1(x)out1x3 = self.expand1x3(x)out = torch.cat([out1x1, out1x3], dim=1)return self.relu(out)
基础知识补充: torch.cat 将向量在某一个维度上拼接
import torch
# Create two tensors
out1x1 = torch.tensor([[1, 2, 3], [1, 2, 3]])
out1x3 = torch.tensor([[4, 5, 6], [7, 8, 9]])# Concatenate the tensors along the second dimension (dim=1)
out = torch.cat([out1x1, out1x3], dim=1)
print(out)
# tensor([[1, 2, 3, 4, 5, 6],
# [1, 2, 3, 7, 8, 9]])
out = torch.cat([out1x1, out1x3], dim=0)
print(out)
# tensor([[1, 2, 3],
# [1, 2, 3],
# [4, 5, 6],
# [7, 8, 9]])
那有了Fire层模块之后就可以开始搭建我们的模型,那在搭建的过程中,各个层的参数如何设置呢,原文中给了如下表
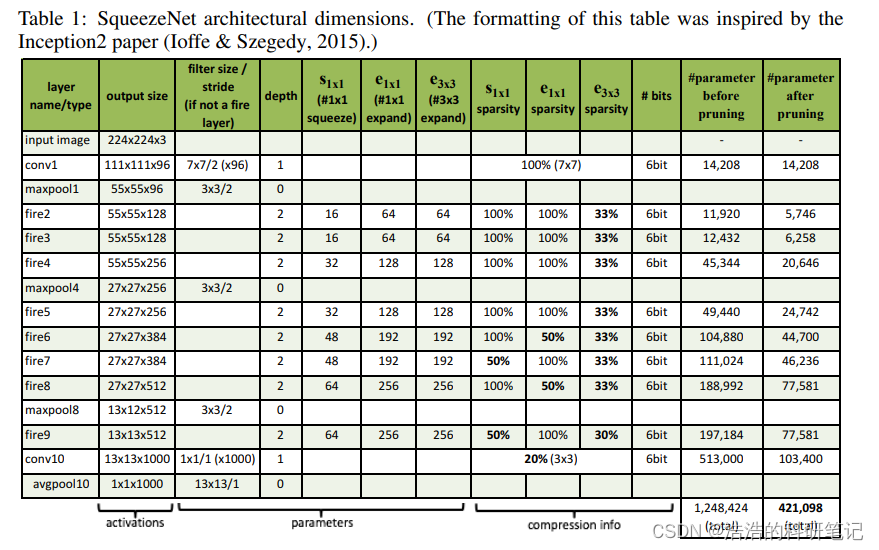
- 第一列Layer name/type 指的是层的名称和类型
- 第二列Output size 指的是输出尺寸
- 第三列是filter size/stride (if not a fire layer)滤波器(卷积核/池化核)的大小(不包含Fire层)
- 第四列depth 卷积层的深度,可以无视掉,没什么用
- 第五-第七 给的就是Fire 层的参数了
再后面的是稀疏性字节大小还有修剪前后的参数大小,这部分不用过于关注,可能要多提一下的就是这个稀疏性sparsity,他指的是卷积层里选择多少参数一直为0,但是并没有详细说具体是怎么实现的,然后我也去搜了一下,需要用一些正则化的东西才可以,这个问题我打算再详细理解一下,暂时我们都默认稀疏性是100,不再为了稀疏性降低参数量实现额外复杂的工作.
根据参数和结构实现代码
一维
import torch
from torchsummary import summary
class FireModule(torch.nn.Module):def __init__(self, in_channels, squeeze_channels, expand1x1_channels, expand1x3_channels):super(FireModule, self).__init__()self.squeeze = torch.nn.Conv1d(in_channels, squeeze_channels, kernel_size=1)self.relu = torch.nn.ReLU(inplace=True)self.expand1x1 = torch.nn.Conv1d(squeeze_channels, expand1x1_channels, kernel_size=1)self.expand1x3 = torch.nn.Conv1d(squeeze_channels, expand1x3_channels, kernel_size=3, padding=1)def forward(self, x):x = self.squeeze(x)x = self.relu(x)out1x1 = self.expand1x1(x)out1x3 = self.expand1x3(x)out = torch.cat([out1x1, out1x3], dim=1)return self.relu(out)class SqueezeNet(torch.nn.Module):def __init__(self,in_channels,classes):super(SqueezeNet, self).__init__()self.features = torch.nn.Sequential(# conv1torch.nn.Conv1d(in_channels, 96, kernel_size=7, stride=2),torch.nn.ReLU(inplace=True),# maxpool1torch.nn.MaxPool1d(kernel_size=3, stride=2),# Fire2FireModule(96, 16, 64, 64),# Fire3FireModule(128, 16, 64, 64),# Fire4FireModule(128, 32, 128, 128),# maxpool4torch.nn.MaxPool1d(kernel_size=3, stride=2),# Fire5FireModule(256, 32, 128, 128),# Fire6FireModule(256, 48, 192, 192),# Fire7FireModule(384, 48, 192, 192),# Fire8FireModule(384, 64, 256, 256),# maxpool8torch.nn.MaxPool1d(kernel_size=3, stride=2),# Fire9FireModule(512, 64, 256, 256))self.classifier = torch.nn.Sequential(# conv10torch.nn.Conv1d(512, classes, kernel_size=1),torch.nn.ReLU(inplace=True),# avgpool10torch.nn.AdaptiveAvgPool1d((1)))def forward(self, x):x = self.features(x)x = self.classifier(x)x = torch.flatten(x, 1)return xif __name__ == "__main__":# 创建一个SqueezeNet实例model = SqueezeNet(in_channels=3,classes=10)# model = FireModule(96,16,64,64)# 打印模型结构summary(model=model, input_size=(3, 224), device='cpu')
二维
import torch
from torchsummary import summary
class FireModule(torch.nn.Module):def __init__(self, in_channels, squeeze_channels, expand1x1_channels, expand3x3_channels):super(FireModule, self).__init__()self.squeeze = torch.nn.Conv2d(in_channels, squeeze_channels, kernel_size=1)self.relu = torch.nn.ReLU(inplace=True)self.expand1x1 = torch.nn.Conv2d(squeeze_channels, expand1x1_channels, kernel_size=1)self.expand3x3 = torch.nn.Conv2d(squeeze_channels, expand3x3_channels, kernel_size=3, padding=1)def forward(self, x):x = self.squeeze(x)x = self.relu(x)out1x1 = self.expand1x1(x)out3x3 = self.expand3x3(x)out = torch.cat([out1x1, out3x3], dim=1)return self.relu(out)class SqueezeNet(torch.nn.Module):def __init__(self,in_channels,classes):super(SqueezeNet, self).__init__()self.features = torch.nn.Sequential(# conv1torch.nn.Conv2d(in_channels, 96, kernel_size=7, stride=2),torch.nn.ReLU(inplace=True),# maxpool1torch.nn.MaxPool2d(kernel_size=3, stride=2),# Fire2FireModule(96, 16, 64, 64),# Fire3FireModule(128, 16, 64, 64),# Fire4FireModule(128, 32, 128, 128),# maxpool4torch.nn.MaxPool2d(kernel_size=3, stride=2),# Fire5FireModule(256, 32, 128, 128),# Fire6FireModule(256, 48, 192, 192),# Fire7FireModule(384, 48, 192, 192),# Fire8FireModule(384, 64, 256, 256),# maxpool8torch.nn.MaxPool2d(kernel_size=3, stride=2),# Fire9FireModule(512, 64, 256, 256))self.classifier = torch.nn.Sequential(# conv10torch.nn.Conv2d(512, classes, kernel_size=1),torch.nn.ReLU(inplace=True),# avgpool10torch.nn.AdaptiveAvgPool2d((1,1)))def forward(self, x):x = self.features(x)x = self.classifier(x)x = torch.flatten(x, 1)return xif __name__ == "__main__":# 创建一个SqueezeNet实例model = SqueezeNet(in_channels=3,classes=10)# model = FireModule(96,16,64,64)# 打印模型结构summary(model=model, input_size=(3, 224, 224), device='cpu')
结束
对于SqueezeNet的第二个和第三个模型,我先把其他的轻量级网络都复现完之后我再回来写一下,对于入门来说先实现个基础版本就够用了
相关文章:
SqueezeNet 一维,二维网络复现 pytorch 小白易懂版
SqueezeNet 时隔一年我又开始复现神经网络的经典模型,这次主要复的是轻量级网络全家桶,轻量级神经网络旨在使用更小的参数量,无限的接近大模型的准确率,降低处理时间和运算量,这次要复现的是轻量级网络的非常经典的一…...

Java 数据结构
枚举 Java枚举是一种特殊的类,它用于定义有限个特定的值,例如一周的星期或者性别。枚举在Java中被视为数据类型,你可以使用它们来创建枚举类型的变量,然后使用那些枚举值等。 在Java中,声明枚举类型需要使用enum关键字…...
python sqlalchemy(ORM)- 02 表关系
文章目录 表关系ORM表示 1v1ORM表示 1vm 表关系 1:1,表A 中的一条记录,仅对应表B中的一条记录;表B的一条记录,仅对应表A的一条记录。1:m,表A中的一条记录,对应表B中的多条记录,表B中的一条记录…...
Http长连接同一个socket多个请求和响应如何保证一一对应?
HTTP/2引入二进制数据帧和流的概念,其中帧对数据进行顺序标识,如下图所示,这样浏览器收到数据之后,就可以按照序列对数据进行合并,而不会出现合并后数据错乱的情况。同样是因为有了序列,服务器就可以并行的…...

Standford Compiler Course Assignment 2
第二部分的作业是语法分析,通过编写cool.y(这个assignment的任务),利用bison将其自动生成语法分析LALR(1)的代码。 语法分析,就是将词法分析阶段已经识别好的token,按照语法的规则,构建抽象语法树的过程。 比如以下的…...
基于Java的校园论坛管理系统设计与实现(源码+lw+部署文档+讲解等)
文章目录 前言具体实现截图论文参考详细视频演示为什么选择我自己的网站自己的小程序(小蔡coding) 代码参考数据库参考源码获取 前言 💗博主介绍:✌全网粉丝10W,CSDN特邀作者、博客专家、CSDN新星计划导师、全栈领域优质创作者&am…...

谈谈你对Spring的理解
谈谈你对Spring的理解 一,什么是Spring 1.介绍 Spring是一个用于开发Java应用程序的工具集合,它提供了许多方便的组件和工具,可以帮助开发者更轻松地构建企业级应用程序。 Spring Framework是Spring的核心部分,它可以帮助开发者…...

系统架构师考试易混淆知识点总结
易混淆点1:系统工程生命周期与信息系统的生命周期 1、系统工程生命周期阶段 探索性研究→概念阶段→开发阶段→生产阶段→使用阶段→保障阶段→退役阶段 2、信息系统的生命周期 产生阶段→开发阶段(单个系统开发:总体规划、系统分析、系统设计、系统实施、系统验收…...
反射的作用( 越过泛型检查 和 可以使用反射保存所有对象的具体信息 )
1、绕过 编译阶段 为集合添加数据 反射是作用在运行时的技术,此时集合的泛型将不能产生约束了,此时是可以 为集合存入其他任意类型的元素的 。泛型只是在编译阶段可以约束集合只能操作某种数据类型,在 编译成Class文件进入 运行阶段 的时候&a…...

前端开发实践:vue中用qrcode库将超链接生成二维码图片
🏆作者简介,黑夜开发者,CSDN领军人物,全栈领域优质创作者✌,阿里云社区专家博主,2023年6月csdn上海赛道top4。 🏆数年电商行业从业经验,历任核心研发工程师,项目技术负责…...
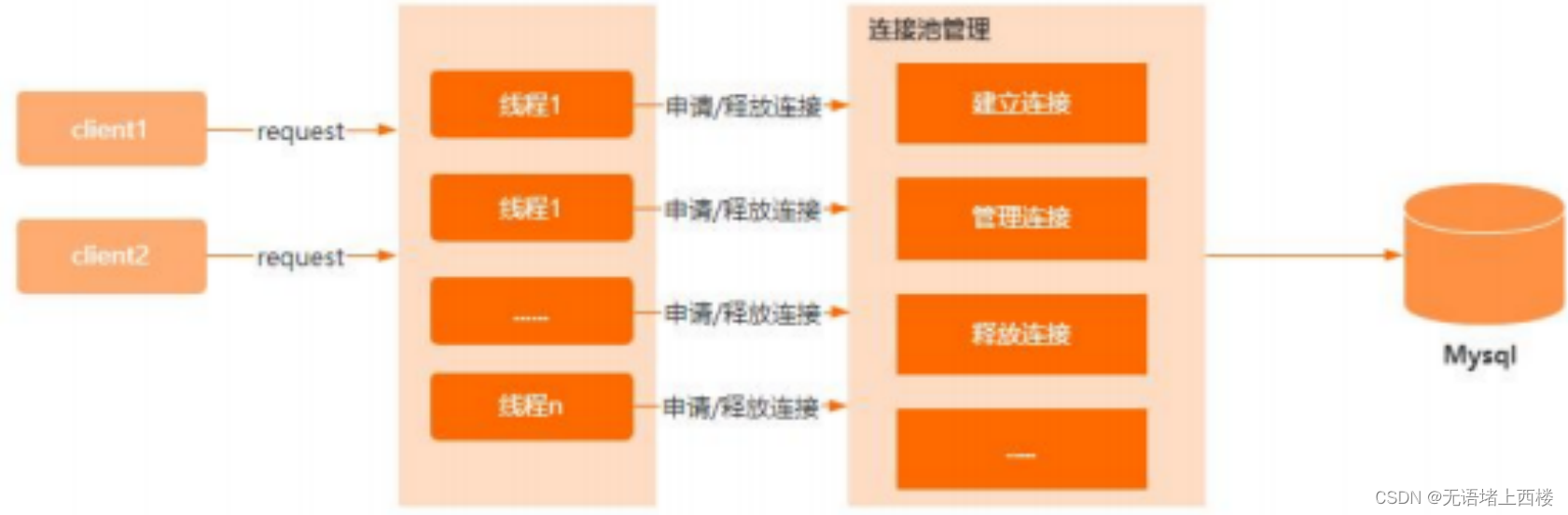
数据库连接池有什么用?它有哪些关键参数?
首先,数据库连接池是一种池化技术,池化技术的核心思想是实现资源的复用,避免资源重复创建销毁的开销。而在数据库的应用场景里面,应用程序每次向数据库发起 CRUD 操作的时候,都需要创建连接.在数据库访问量较大的情况下…...

Android Settings解析
Android Settings 系列文章: Android Settings解析SettingsIntelligenceSettingsProvider 首语 Android设置应用是Android系统中一个非常重要的系统应用,它允许用户调整和设置系统的各种参数和功能(系统设置/自定义设置/控制应用权限/开发…...
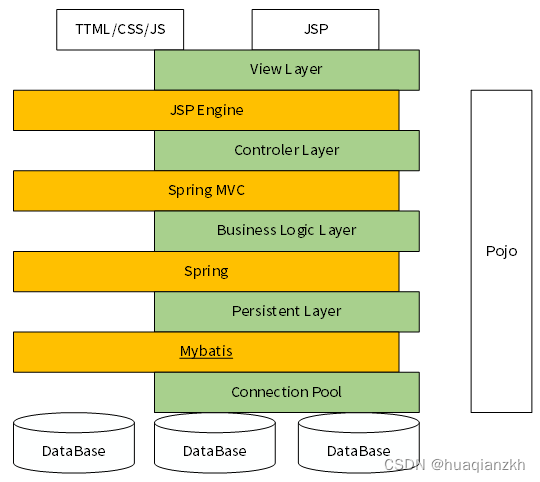
Spring+spring mvc+mybatis整合的框架
Spring是一个轻量级的企业级应用开发框架,于2004年由Rod Johnson发布了1.0版本,经过多年的更新迭代,已经逐渐成为Java开源世界的第一框架,Spring框架号称Java EE应用的一站式解决方案,与各个优秀的MVC框架如SpringMVC、…...
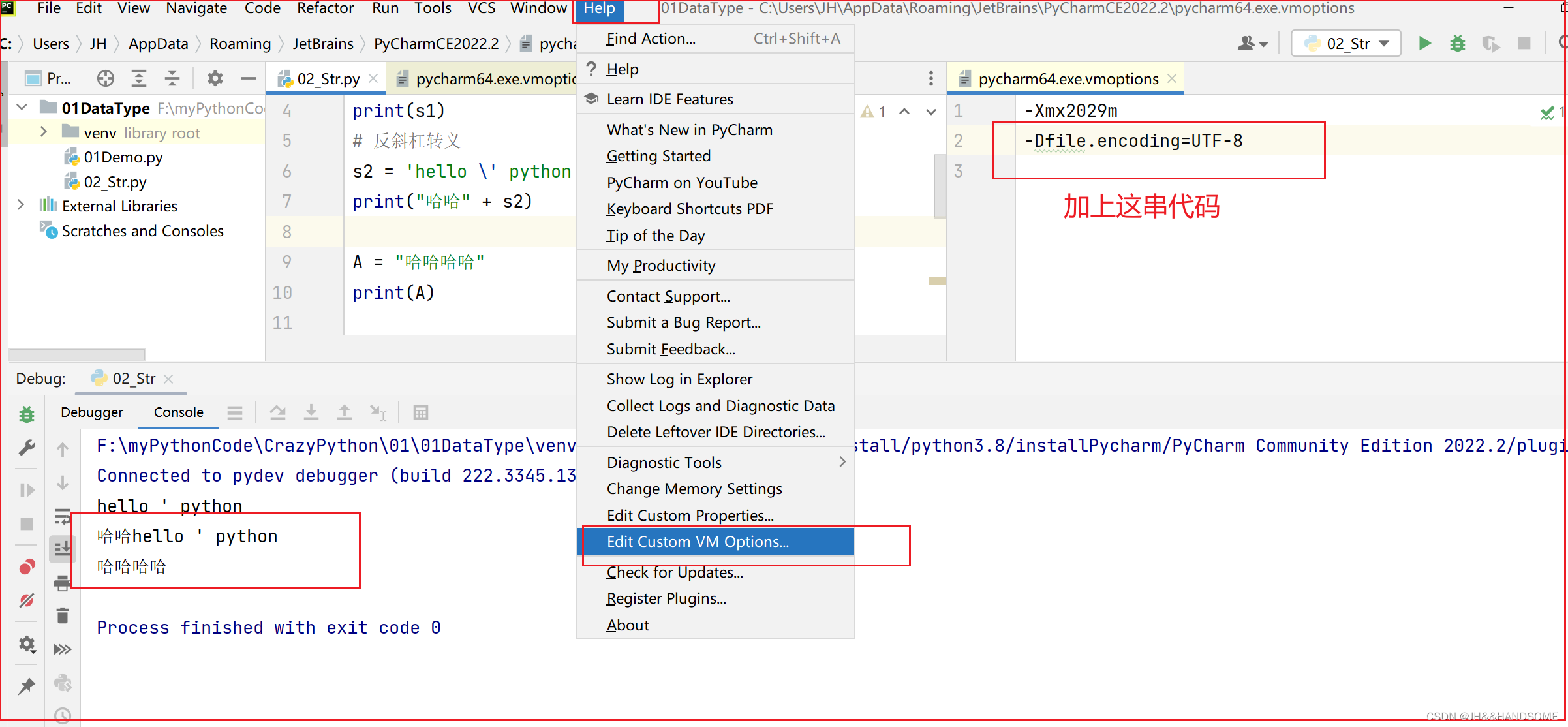
02-2、PyCharm中文乱码的三处解决方法
PyCharm中文乱码 修改处1: 修改处2:这个也没用 在Pycharm中可以创建一个模版,每次新建python文件时Pycharm会默认在前两行生成utf-8 #!/user/bin/env python3 # -- coding: utf-8 -- 还是乱码 再在这里设置以下 添加 : -Dfi…...

Axi接口的DDR3:参数,时序,握手机制
参考 AXI总线的Burst Type以及地址计算 | WRAP到底是怎么一回事?_axi wrap-CSDN博客 还有官方手册,名字太长想起来再写。 Transaction/Burst/Transfer/Beat Transaction指一次传输事务,实际上包括了address phase, data phase与response ph…...
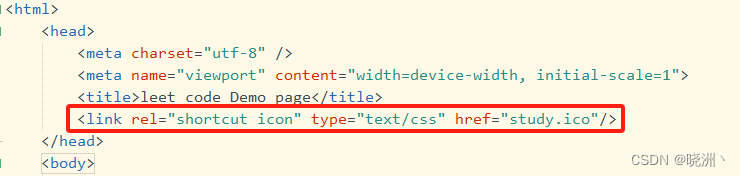
浏览器标签上添加icon图标;html引用ico文件
实例 <link rel"shortcut icon" href"./XXX.ico" type"image/x-icon">页面和图标在同一目录内 则 <link rel"shortcut icon" type"text/css" href"study.ico"/>可以阿里矢量图库关键字搜索下载自己…...
深入解析i++和++i的区别及性能影响
在我们编写代码时,经常需要对变量进行自增操作。这种情况下,我们通常会用到两种常见的操作符:i和i。最近在阅读博客时,我偶然看到了有关i和i性能的讨论。之前我一直在使用它们,但从未从性能的角度考虑过,这…...
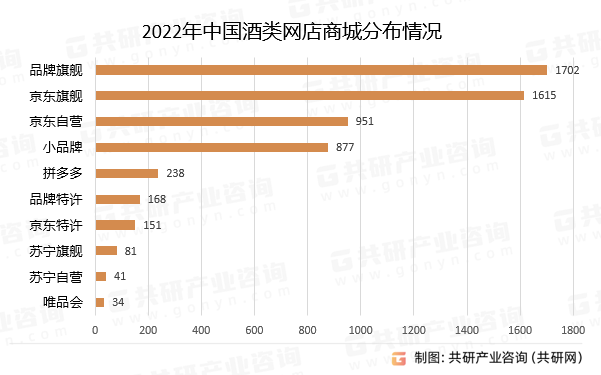
2023年中国酒类新零售行业发展概况分析:线上线下渠道趋向深度融合[图]
近年来,我国新零售业态不断发展,线上便捷性和个性化推荐的优势逐步在放大,线下渠道智慧化水平持续提升,线上线下渠道趋向深度融合。2022年,我国酒类新零售市场规模约为1516亿元,预计2025年酒类新零售市场规…...
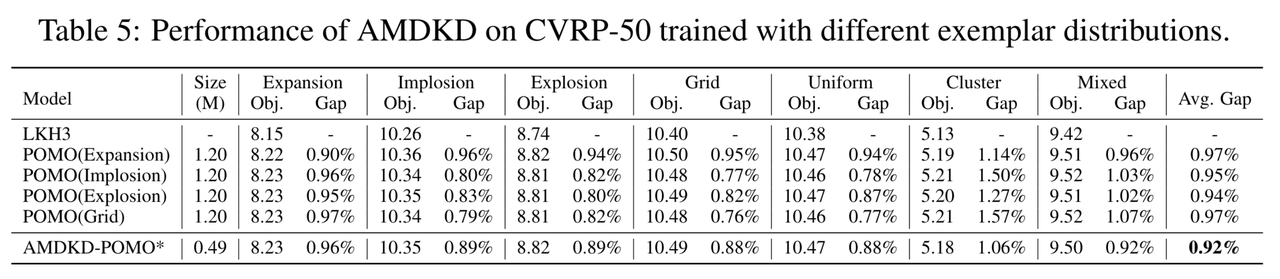
交通 | 实现可泛化性:机器学习求解VRP
推文作者:缪昌昊,张景琪,张云天 论文作者:Jieyi Bi, Yining Ma, Jiahai Wang, Zhiguang Cao, Jinbiao Chen, Yuan Sun, and Yeow Meng Chee 论文原文:Bi, Jieyi, et al. “Learning generalizable models for veh…...

php使用sqlServer
sqlServer扩展 PDO_MSSQL|sqlsrv|odbc}mssql|pdo_odbc PHP 安装php_sqlsrv php_pdo_sqlsrv https://pecl.php.net/package/sqlsrv/5.8.1/windows PECL :: Package :: pdo_sqlsrv 5.8.1 for Windows SqlServer驱动:msodbcsql...

微信聊天记录持久化:基于本地解析技术的个人数据管理方案
微信聊天记录持久化:基于本地解析技术的个人数据管理方案 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/We…...

从零搭建一个智能客服问答引擎:基于T5模型与PyTorch的完整项目实战
从零搭建智能客服问答引擎:基于T5模型与PyTorch的工业级实践 当企业客服系统每天需要处理数千条重复性问题时,人工坐席的效率瓶颈就会凸显。去年为某电商平台部署智能客服系统的经历让我深刻体会到:一个能理解"我的快递为什么三天没更新…...

OpenClaw语音控制之GoogleAPI 集成实战教程
11.1 Google Cloud 账号设置 在使用 Google Cloud 的任何服务之前,首先需要拥有一个 Google Cloud 账号。本节将详细介绍账号注册、项目创建和支付方式绑定的完整流程。 步骤 1:访问 Google Cloud 控制台 打开浏览器,访问 Google Cloud 控制台地址:https://console.clou…...

pymoo实战教程:从零开始构建你的第一个多目标优化模型
pymoo实战教程:从零开始构建你的第一个多目标优化模型 【免费下载链接】pymoo NSGA2, NSGA3, R-NSGA3, MOEAD, Genetic Algorithms (GA), Differential Evolution (DE), CMAES, PSO 项目地址: https://gitcode.com/gh_mirrors/py/pymoo pymoo是一个强大的Pyt…...

从SolidWorks到Simulink动画:手把手教你用URDF和Simscape搭建六轴机械臂仿真模型
六轴机械臂仿真全流程:从SolidWorks建模到Simulink动画生成实战指南 当我在实验室第一次看到自己设计的机械臂在Simulink中流畅地完成抓取动作时,那种成就感至今难忘。许多机器人工程师都曾面临这样的困境:在SolidWorks中精心设计的机械臂模型…...
)
SQLite Developer实战:如何高效管理Android开发中的.db文件(含数据导入导出技巧)
SQLite Developer实战:高效管理Android开发中的.db文件 在移动应用开发领域,数据存储始终是核心需求之一。对于Android开发者而言,SQLite作为轻量级的关系型数据库,因其零配置、无服务器特性而成为本地存储的首选方案。然而&…...

避开这些坑,你的芯片设计才能成功流片:CMOS制造工艺中的关键检查点详解
避开这些坑,你的芯片设计才能成功流片:CMOS制造工艺中的关键检查点详解 在芯片设计领域,流片失败往往意味着数百万美元的损失和数月的开发时间付诸东流。对于初入行的工程师而言,理解制造工艺中的潜在风险点比掌握正向设计流程更为…...

从ChatGLM到DeepSeek-V2:我用LLaMA-Factory一站式搞定5种大模型的高效微调
从ChatGLM到DeepSeek-V2:我用LLaMA-Factory一站式搞定5种大模型的高效微调 在开源大模型技术快速迭代的今天,工程师和研究者面临着一个幸福的烦恼:如何在ChatGLM、DeepSeek、Qwen、Yi、LLaMA等不同架构的模型之间高效切换和实验?传…...

B Tree
二叉树、AVL树、红黑树使得查找、插入、删除数据的效率降到了O(logN)级别,但通常是把数据全部加载到内存中进行处理的,数据量通常没有特别大。当有超大规模的数据量时,大到内存都存不下的时候,只能存储在硬盘里。由于二叉树、AVL树…...

解锁AI绘图效率工具:ComfyUI插件优化创意工作流指南
解锁AI绘图效率工具:ComfyUI插件优化创意工作流指南 【免费下载链接】ComfyUI_essentials 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI_essentials 在AI绘图领域,创作者常常面临工作流效率低下、细节控制不足等问题。ComfyUI作为强大的…...