python爬虫入门(五)XPath使用
对于网页的节点来说,它可以定义 id、class 或其他属性。而且节点之间还有层次关系,在网页中可以通过 XPath 或 CSS 选择器来定位一个或多个节点。在页面解析时,利用 XPath 或 CSS 选择器来提取某个节点,然后再调用相应方法获取它的正文内容或者属性,就可以提取我们想要的任意信息。
这种解析库已经非常多,其中比较强大的库有 lxml、Beautiful Soup、pyquery 等,通过使用解析库,可以免去编写正则表达式的麻烦,解析效率也能有所提高。
XPath的使用
XPath,全称 XML Path Language,即 XML 路径语言,它是一门在 XML 文档中查找信息的语言。它最初是用来搜寻 XML 文档的,但是它同样适用于 HTML 文档的搜索。所以在做爬虫时,我们完全可以使用 XPath 来做相应的信息抽取。XPath 的选择功能十分强大,它提供了非常简洁明了的路径选择表达式。另外,它还提供了超过 100 个内建函数,用于字符串、数值、时间的匹配以及节点、序列的处理等。几乎所有我们想要定位的节点,都可以用 XPath 来选择。
XPath 常用规则
| 表 达 式 | 描 述 |
|---|---|
| nodename | 选取所有name为nodename的结点 |
| / | 从根节点开始选取 |
| // | 从当前节点开始选取html中所有匹配选取要求的结点 |
| . | 选取当前节点 |
| … | 选取当前节点的父节点 |
| @ | 选取属性 |
| Path Expression | Result |
|---|---|
| bookstore | 选择所有名称为 “bookstore” 的节点 |
| /bookstore | 选择根元素 bookstore |
| 注意:如果路径以斜杠(/)开头,则始终表示对元素的绝对路径! | |
| bookstore/book | 选择 bookstore 的所有子元素中的 book 元素 |
| //book | 选择文档中的所有 book 元素,无论它们在哪里 |
| bookstore//book | 选择 bookstore 元素下的所有后代 book 元素,无论它们在 bookstore 元素下的哪个位置 |
| //@lang | 选择所有名为 lang 的属性 |
实例
假设html代码如下(下面为python代码),开始前请安装lxml包:
text = '''
<div><ul><li class="item-0"><a href="link1.html">first item</a></li><li class="item-1"><a href="link2.html">second item</a></li><li class="item-inactive"><a href="link3.html">third item</a></li><li class="item-1"><a href="link4.html">fourth item</a></li><li class="item-0"><a href="link5.html">fifth item</a></ul></div>
'''
对这段html进行解析:
from lxml import etree
html = etree.HTML(text)
result = etree.tostring(html)
print(result.decode('utf-8'))
这里首先导入 lxml 库的 etree 模块,然后声明了一段 HTML 文本,调用 HTML 类进行初始化,这样就成功构造了一个 XPath 解析对象。这里需要注意的是,HTML 文本中的最后一个 li 节点是没有闭合的,但是 etree 模块可以自动修正 HTML 文本。
这里我们调用 tostring 方法即可输出修正后的 HTML 代码,但是结果是 bytes 类型。这里利用 decode 方法将其转成 str 类型。
<html><body><div><ul><li class="item-0"><a href="link1.html">first item</a></li><li class="item-1"><a href="link2.html">second item</a></li><li class="item-inactive"><a href="link3.html">third item</a></li><li class="item-1"><a href="link4.html">fourth item</a></li><li class="item-0"><a href="link5.html">fifth item</a></li></ul></div>
</body></html>
经过处理之后,li 节点标签被补全,并且还自动添加了 body、html 节点。
也可以直接读取文本文件进行解析:
html = etree.parse('./test.html', etree.HTMLParser())
输出结果会多一个 DOCTYPE 的声明。
选取所有节点
一般会用 // 开头的 XPath 规则来选取所有符合要求的节点。以前面的 HTML 文本为例,如果要选取所有节点,可以这样实现:
result = html.xpath('//*')
运行结果:
[<Element html at 0x10510d9c8>, <Element body at 0x10510da08>, <Element div at 0x10510da48>, <Element ul at 0x10510da88>, <Element li at 0x10510dac8>, <Element a at 0x10510db48>, <Element li at 0x10510db88>, <Element a at 0x10510dbc8>, <Element li at 0x10510dc08>, <Element a at 0x10510db08>, <Element li at 0x10510dc48>, <Element a at 0x10510dc88>, <Element li at 0x10510dcc8>, <Element a at 0x10510dd08>]
这里使用 * 代表匹配所有节点,也就是整个 HTML 文本中的所有节点都会被获取。可以看到,返回形式是一个列表,每个元素是 Element 类型,其后跟了节点的名称,如 html、body、div、ul、li、a 等,所有节点都包含在列表中了。
如果想获取所有 li 节点:
result = html.xpath('//li')
提取结果是一个列表形式,其中每个元素都是一个 Element 对象。如果要取出其中一个对象,可以直接用中括号加索引,如 [0]。
选取子节点
通过 / 或 // 即可查找元素的子节点或子孙节点。假如现在想选择 li 节点的所有直接 a 子节点:
result = html.xpath('//li/a')
通过追加 /a 即选择了所有 li 节点的所有直接 a 子节点。因为 //li 用于选中所有 li 节点,/a 用于选中 li 节点的所有直接子节点 a,二者组合在一起即获取所有 li 节点的所有直接 a 子节点。
此处的 / 用于选取直接子节点,如果要获取所有子孙节点,就可以使用 //:
result = html.xpath('//ul//a')
本例中运行结果相同。但是如果这里用 //ul/a,就无法获取任何结果了。而//ul//a依然可以输出和前面相同的结果。
我们要注意 / 和 // 的区别,其中 / 用于获取直接子节点,// 可以获取子孙节点。如果了解linux的话,即/为当前文件夹下查找,而//能够在当前文件夹下递归查找。
选取父节点
用… 来实现查找父节点。首先选中 href 属性为 link4.html 的 a 节点,然后再获取其父节点,然后再获取其 class 属性:
result = html.xpath('//a[@href="link4.html"]/../@class')
也可以通过 parent:: 来获取父节点
result = html.xpath('//a[@href="link4.html"]/parent::*/@class')
/parent::*:选择被筛选元素的父元素(任意标签)。
属性匹配
在选取的时候,我们还可以用 @符号进行属性过滤。如果要选取 class 为 item-0 的 li 节点:
result = html.xpath('//li[@class="item-0"]')
通过加入 [@class=“item-0”],限制了节点的 class 属性为 item-0,而 HTML 文本中符合条件的 li 节点有两个,所以结果应该返回两个匹配到的元素。
文本获取
用 XPath 中的 text 方法获取节点中的文本,接下来尝试获取前面 li 节点中的文本。
result = html.xpath('//li[@class="item-0"]/text()')
运行结果:
['\n ']
奇怪的是,我们并没有获取到任何文本,只获取到了一个换行符。因为 XPath 中 text 方法前面是 /,而此处 / 的含义是选取直接子节点,很明显 li 的直接子节点都是 a 节点,文本都是在 a 节点内部的,所以这里匹配到的结果就是被修正的 li 节点内部的换行符,因为自动修正的 li 节点的尾标签换行了。
即选中的是这两个节点:
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</li>
其中一个节点因为自动修正,li 节点的尾标签添加的时候换行了,所以提取文本得到的唯一结果就是 li 节点的尾标签和 a 节点的尾标签之间的换行符。
如果想获取 li 节点内部的文本,就有两种方式,一种是先选取 a 节点再获取文本,另一种就是使用 //。
选取到 a 节点再获取文本,代码如下:
result = html.xpath('//li[@class="item-0"]/a/text()')
结果如下:
['first item', 'fifth item']
先选取了 li 节点,又利用 / 选取了其直接子节点 a,然后再选取其文本。
用另一种方式(即使用 //)选取的结果:
result = html.xpath('//li[@class="item-0"]//text()')
结果如下:
['first item', 'fifth item', '\n ']
这里是选取所有子孙节点的文本,其中前两个就是 li 的子节点 a 节点内部的文本,另外一个就是最后一个 li 节点内部的文本,即换行符。
如果要想获取子孙节点内部的所有文本,可以直接用 // 加 text 方法的方式,这样可以保证获取到最全面的文本信息,但是可能会夹杂一些换行符等特殊字符。如果想获取某些特定子孙节点下的所有文本,可以先选取到特定的子孙节点,然后再调用 text 方法方法获取其内部文本,这样可以保证获取的结果是整洁的。
属性获取
**用 @符号获取节点内部属性。**例如,我们想获取所有 li 节点下所有 a 节点的 href 属性。
result = html.xpath('//li/a/@href')
这里我们通过 @href 即可获取节点的 href 属性。注意,此处和属性匹配的方法不同,属性匹配是中括号加属性名和值来限定某个属性,如 [@href=“link1.html”],而此处的 @href 指的是获取节点的某个属性,二者需要做好区分。
属性多值匹配
某些节点的某个属性可能有多个值,例如:
text = '''
<li class="li li-first"><a href="link.html">first item</a></li>
'''
这里 HTML 文本中 li 节点的 class 属性有两个值 li 和 li-first,如果还想用之前的属性匹配获取:
result = html.xpath('//li[@class="li"]/a/text()')
运行结果为空。需要用 contains 方法了:
result = html.xpath('//li[contains(@class, "li")]/a/text()')
通过 contains 方法,第一个参数传入属性名称,第二个参数传入属性值,只要此属性包含所传入的属性值,就可以完成匹配了。
多属性匹配
根据多个属性确定一个节点,这时就需要同时匹配多个属性。此时可以使用运算符 and 来连接。
例如:
text = '''
<li class="li li-first" name="item"><a href="link.html">first item</a></li>
'''
要确定这个节点,需要同时根据 class 和 name 属性来选择,一个条件是 class 属性里面包含 li 字符串,另一个条件是 name 属性为 item 字符串,二者需要同时满足,需要用 and 操作符相连,相连之后置于中括号内进行条件筛选。
result = html.xpath('//li[contains(@class, "li") and @name="item"]/a/text()')
这里的 and 其实是 XPath 中的运算符。另外,还有很多运算符,如 or、mod 等。
| 运算符 | 描述 | 实例 | 返回值 |
|---|---|---|---|
| 计算两个节点集 | //book | ||
| + | 加法 | 6 + 4 | 10 |
| - | 减法 | 6 - 4 | 2 |
| * | 乘法 | 6 * 4 | 24 |
| div | 除法 | 8 div 4 | 2 |
| = | 等于 | price=9.80 | 如果 price 是 9.80,则返回 true。如果 price 是 9.90,则返回 false。 |
| != | 不等于 | price!=9.80 | 如果 price 是 9.90,则返回 true。如果 price 是 9.80,则返回 false。 |
| < | 小于 | price<9.80 | 如果 price 是 9.00,则返回 true。如果 price 是 9.90,则返回 false。 |
| <= | 小于或等于 | price<=9.80 | 如果 price 是 9.00,则返回 true。如果 price 是 9.90,则返回 false。 |
| > | 大于 | price>9.80 | 如果 price 是 9.90,则返回 true。如果 price 是 9.80,则返回 false。 |
| >= | 大于或等于 | price>=9.80 | 如果 price 是 9.90,则返回 true。如果 price 是 9.70,则返回 false。 |
| or | 或 | price=9.80 or price=9.70 | 如果 price 是 9.80,则返回 true。如果 price 是 9.50,则返回 false。 |
| and | 与 | price>9.00 and price<9.90 | 如果 price 是 9.80,则返回 true。如果 price 是 8.50,则返回 false。 |
| mod | 计算除法的余数 | 5 mod 2 | 1 |
按序选择
在选择的时候某些属性可能同时匹配了多个节点,但是只想要其中的某个节点,如第二个节点或者最后一个节点,可以利用中括号传入索引的方法获取特定次序的节点。
例如:
text = '''
<div><ul><li class="item-0"><a href="link1.html">first item</a></li><li class="item-1"><a href="link2.html">second item</a></li><li class="item-inactive"><a href="link3.html">third item</a></li><li class="item-1"><a href="link4.html">fourth item</a></li><li class="item-0"><a href="link5.html">fifth item</a></ul></div>
'''
html = etree.HTML(text)
result = html.xpath('//li[1]/a/text()')
print(result)
result = html.xpath('//li[last()]/a/text()')
print(result)
result = html.xpath('//li[position()<3]/a/text()')
print(result)
result = html.xpath('//li[last()-2]/a/text()')
print(result)
第一次选择时,我们选取了第一个 li 节点,中括号中传入数字 1 即可。注意,这里和代码中不同,序号是以 1 开头的,不是以 0 开头。
第二次选择时,我们选取了最后一个 li 节点,中括号中调用 last 方法即可,返回的便是最后一个 li 节点。
第三次选择时,我们选取了位置小于 3 的 li 节点,也就是位置序号为 1 和 2 的节点,得到的结果就是前两个 li 节点。
第四次选择时,我们选取了倒数第三个 li 节点,中括号中调用 last 方法再减去 2 即可。因为 last 方法代表最后一个,在此基础减 2 就是倒数第三个。
运行结果如下:
['first item']
['fifth item']
['first item', 'second item']
['third item']
这里我们使用了 last、position 等方法。在 XPath 中,提供了 100 多个方法,包括存取、数值、字符串、逻辑、节点、序列等处理功能,它们的具体作用可以参考:http://www.w3school.com.cn/xpath/xpath_functions.asp。
节点轴选择
XPath 提供了很多节点轴选择方法,包括获取子元素、兄弟元素、父元素、祖先元素等。
text = '''
<div><ul><li class="item-0"><a href="link1.html"><span>first item</span></a></li><li class="item-1"><a href="link2.html">second item</a></li><li class="item-inactive"><a href="link3.html">third item</a></li><li class="item-1"><a href="link4.html">fourth item</a></li><li class="item-0"><a href="link5.html">fifth item</a></ul></div>
'''
html = etree.HTML(text)
result = html.xpath('//li[1]/ancestor::*')
print(result)
result = html.xpath('//li[1]/ancestor::div')
print(result)
result = html.xpath('//li[1]/attribute::*')
print(result)
result = html.xpath('//li[1]/child::a[@href="link1.html"]')
print(result)
result = html.xpath('//li[1]/descendant::span')
print(result)
result = html.xpath('//li[1]/following::*[2]')
print(result)
result = html.xpath('//li[1]/following-sibling::*')
print(result)
第一次选择时,我们调用了 ancestor 轴,可以获取所有祖先节点。其后需要跟两个冒号,然后是节点的选择器,这里我们直接使用 *,表示匹配所有节点,因此返回结果是第一个 li 节点的所有祖先节点,包括 html、body、div 和 ul。
第二次选择时,我们又加了限定条件,这次在冒号后面加了 div,这样得到的结果就只有 div 这个祖先节点了。
第三次选择时,我们调用了 attribute 轴,可以获取所有属性值,其后跟的选择器还是 *,这代表获取节点的所有属性,返回值就是 li 节点的所有属性值。
第四次选择时,我们调用了 child 轴,可以获取所有直接子节点。这里我们又加了限定条件,选取 href 属性为 link1.html 的 a 节点。
第五次选择时,我们调用了 descendant 轴,可以获取所有子孙节点。这里我们又加了限定条件获取 span 节点,所以返回的结果只包含 span 节点而不包含 a 节点。
第六次选择时,我们调用了 following 轴,可以获取当前节点以及其内部的所有节点。这里我们虽然使用的是 * 匹配,但又加了索引选择,所以只获取了第二个后续节点。
第七次选择时,我们调用了 following-sibling 轴,可以获取当前节点之后的所有同级节点。这里我们使用 * 匹配,所以获取了所有后续同级节点。
以上是 XPath 轴的简单用法,更多轴的用法可以参考:http://www.w3school.com.cn/xpath/xpath_axes.asp。
相关文章:
XPath使用)
python爬虫入门(五)XPath使用
对于网页的节点来说,它可以定义 id、class 或其他属性。而且节点之间还有层次关系,在网页中可以通过 XPath 或 CSS 选择器来定位一个或多个节点。在页面解析时,利用 XPath 或 CSS 选择器来提取某个节点,然后再调用相应方法获取它的…...

【广州华锐互动】VR消防员模拟灭火:身临其境的火场救援
随着科技的不断发展,虚拟现实(VR)技术已经逐渐渗透到各个领域,为我们带来了前所未有的沉浸式体验。在这其中,VR模拟消防员灭火体验无疑是一种极具创新性和实用性的应用。通过这项技术,人们可以亲身体验到消…...
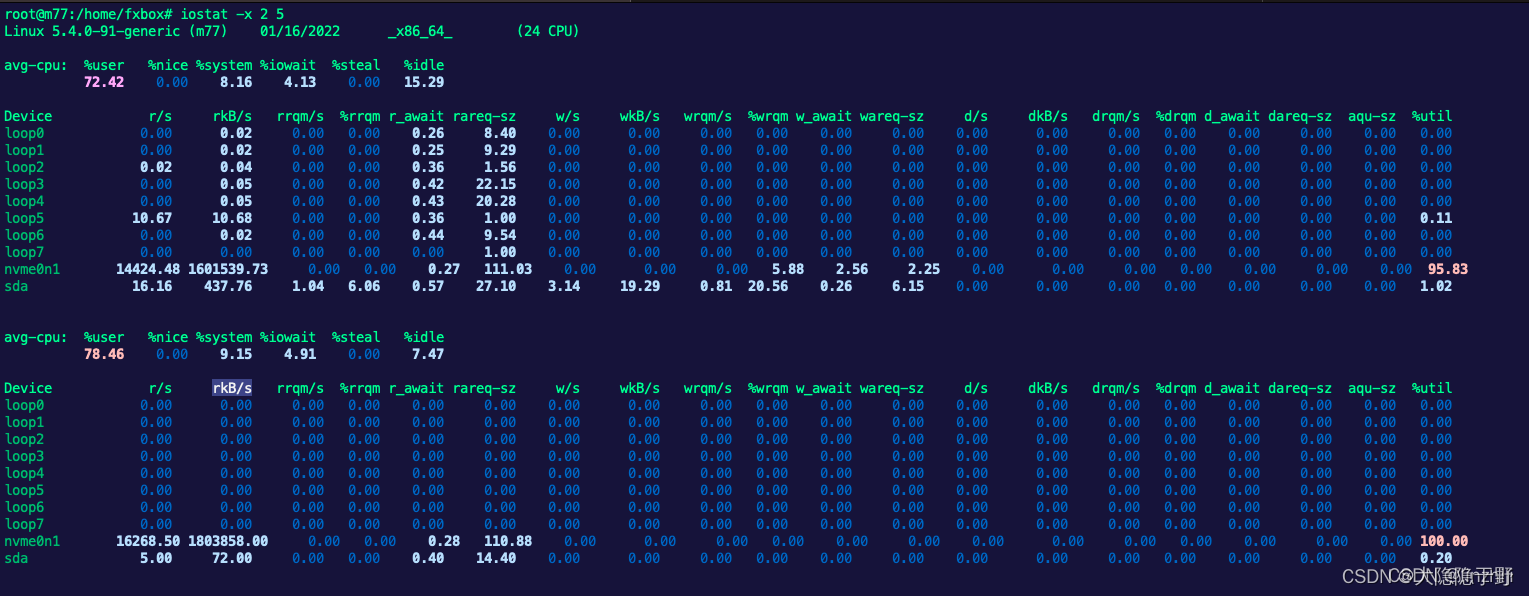
NFS性能瓶颈分析
前言 atop – run it with -d option or press d to toggle the disk stats view. iostat – try it with the -xm 2 options for extended statistics, in megabytes, and in two-second intervals. iotop – top-like I/O monitor. Try it with the -oPa options to show the…...

Java中配置RabbitMQ基本步骤
在Java中配置RabbitMQ,需要遵循以下步骤: 1.添加依赖 在项目的pom.xml文件中添加RabbitMQ的Java客户端依赖: <dependency><groupId>com.rabbitmq</groupId><artifactId>amqp-client</artifactId><versio…...

Ingress典型配置
Ingress 是 Kubernetes 中用于管理 HTTP 和 HTTPS 路由的资源。以下是一个典型的 Ingress 配置示例,用于将流量引导到两个不同的服务: apiVersion: networking.k8s.io/v1 kind: Ingress metadata:name: example-ingress spec:rules:- host: example.com…...
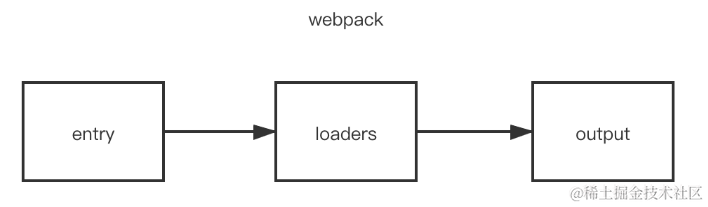
webpack中常见的Loader解决了什么问题?
一、是什么 loader 用于对模块的"源代码"进行转换,在 import 或"加载"模块时预处理文件 webpack做的事情,仅仅是分析出各种模块的依赖关系,然后形成资源列表,最终打包生成到指定的文件中。如下图所示&#…...
阿里7年经验之谈 —— 如何实现前端项目的自动化测试?
这其实就是我们常说的“UI自动化测试”,针对这个问题,我先告知答题思路如下: 1、什么是UI自动化?有什么优势? 2、UI自动化实践中会遇到什么难题? 3、如何解决难题,将UI落实到实践中?…...

动态开辟内存空间函数
文章目录 malloc函数calloc函数malloc函数和calloc函数的不同free函数realloc函数 malloc函数 参数是要开辟内存空间的大小 开辟成功则返回值为开辟空间的首地址,若开辟失败则返回一个空指针NULL calloc函数 第一个参数为开辟空间的元素个数,第二个参数…...
nodejs+vue备忘记账系统-计算机毕业设计
本文首先介绍了备忘记账系统管理技术的发展背景与发展现状,然后遵循软件常规开发流程,首先针对系统选取适用的语言和开发平台,目 录 摘 要 I ABSTRACT II 目 录 II 第1章 绪论 1 1.1背景及意义 1 1.2 国内外研究概况 1 1.3 研究的内容 1 第2章…...
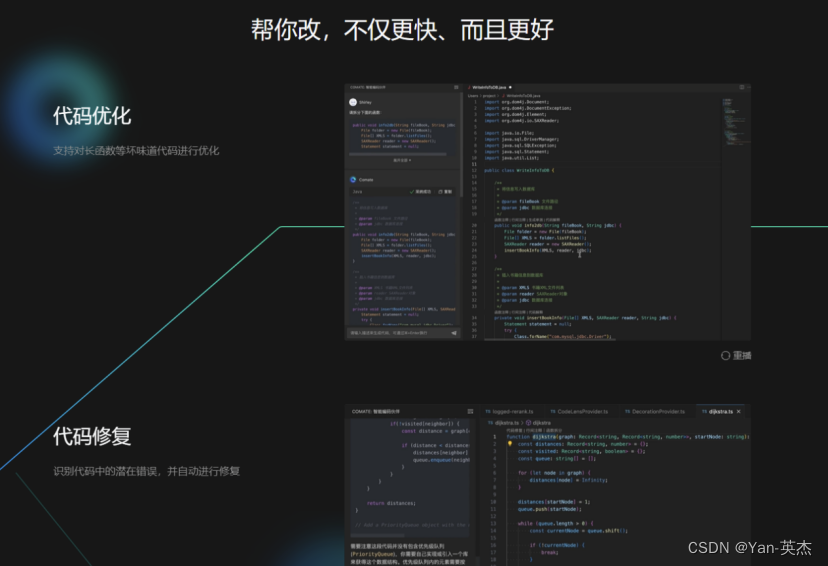
百度Comate代码助手SaaS版本:智慧编程,引领新潮
引言 在当今数字化时代,软件开发已成为企业成功的关键因素之一。为了应对市场需求的不断变化,企业需要更高效、更灵活的开发工具。百度Comate代码助手的SaaS版本的正式上线,为广大企业和开发者提供了一种全新的编码方式,帮助他们…...
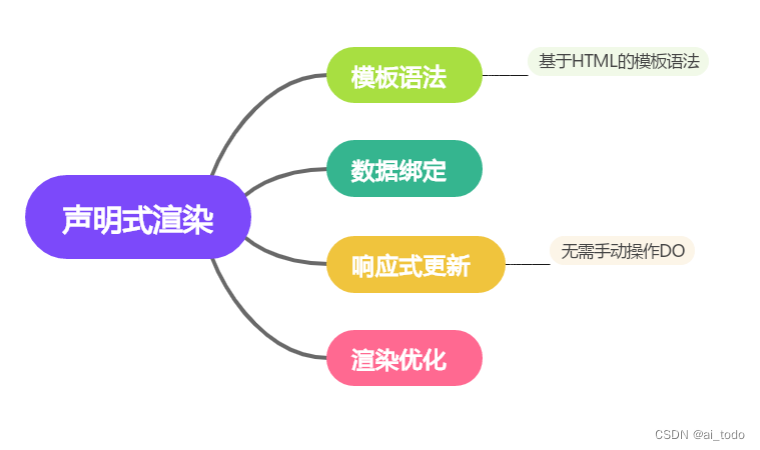
数据与视图的完美契合:Vue响应式的交织魅力
🤍 前端开发工程师(主业)、技术博主(副业)、已过CET6 🍨 阿珊和她的猫_CSDN个人主页 🕠 牛客高级专题作者、在牛客打造高质量专栏《前端面试必备》 🍚 蓝桥云课签约作者、已在蓝桥云…...

Centos8 降低gcc版本至gcc-7.3
1 首先卸载系统中的gcc sudo yum remove gcc 2 重新安装gcc-7.3 sudo dnf group install “Development Tools” 然后再次卸载gcc sudo yum remove gcc 然后发现centos-release-scl-rh已经安装了 sudo yum install centos-release-scl-rh yum -y install devtoolset-7-gcc dev…...

Qt之设置QLineEdit只能输入浮点数
Qt提供了QDoubleValidator来进行浮点数校验,但是它同样存在限定范围无效的问题,详见:Qt之彻底解决QSpinBox限定范围无效的问题 因此我们要子类化QDoubleValidator,并重写其中的validate方法,最后调用QLineEdit的setValidator方法,并将这个子类当做参数传入。 QHDoubleVa…...

Spark项目实战-卡口流量统计
一、卡口介绍 卡口摄像头正对车道安装,拍摄正面照片。 功能:抓拍正面特征 这种摄像头多安装在国道、省道、高速公路的路段上、或者城区和郊区交接的主要路口,用来抓拍超速、进出城区车辆等行为。它进行的是车辆正面抓拍,可以清晰…...

kubernetesr进阶--Secret概述
概述 Kubernetes Secret 对象可以用来储存敏感信息,例如:密码、OAuth token、ssh 密钥等。如果不使用 Secret,此类信息可能被放置在 Pod 定义中或者容器镜像中。将此类敏感信息存储到 Secret 中,可以更好地: 控制其使…...

在 Python 中使用 Pillow 进行图像处理【2/4】
第二部分 一、说明 该文是《在 Python 中使用 Pillow 进行图像处理》的第二部分,主要介绍pil库进行一般性处理:如:图像卷积、钝化、锐化、阈值分割。 二、在 Python 中使用 Pillow 进行图像处理 您已经学习了如何裁剪和旋转图像、调整图像大…...

XTU-OJ 1171-coins
题目描述 一个均质硬币抛n次,求不存在连续2次为正面的方案数。 输入 每行一个正整数n,n≤40。如果n为0,表示输入结束,不需要处理。 输出 每行输出一个结果,为一个整数。 样例输入 1 2 3 0样例输出 2 3 5 解题思路&…...
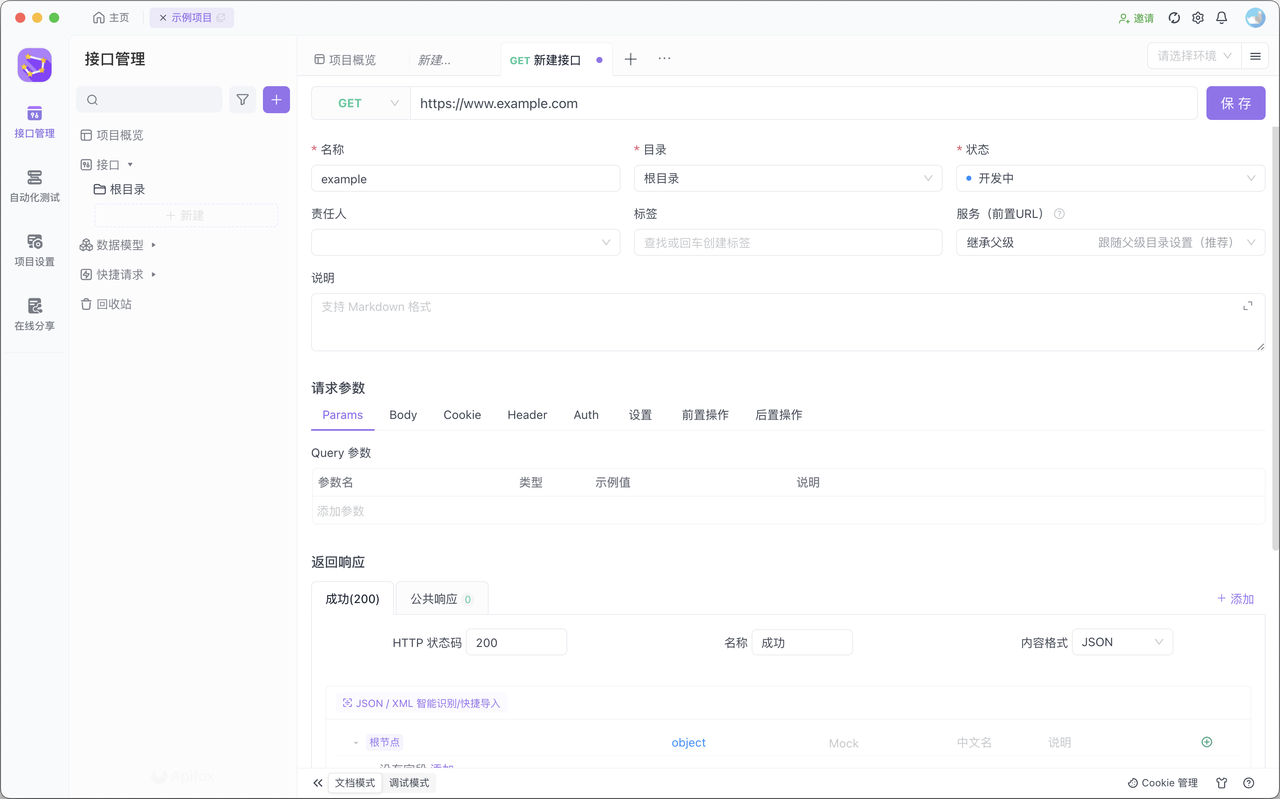
如何使用 JMeter 进行 HTTPS 请求测试?
本文将介绍如何使用 JMeter 测试 HTTPS 请求,并提供相关的技巧和注意事项。 在进行性能测试时,很多网站都采用了 HTTPS 协议。当我们测试 HTTPS 请求,如果服务端开启了双向认证,则需要客户端发送请求时带上证书。本文介绍如何在 …...

KNN-水仙花的分类
题目: 思路: 1、处理数据集,这里用的是题目已知的数据集,所以说需要提前将写好的数据放到excel表格里,再进行读取。 2、将数据集划分为训练集和测试集 3、定义K-NN模型。 4、训练模型 5、预测模型 6、计算分类精…...

Kotlin 如何确定协程是否启动
在Kotlin中,你可以确定协程是否已启动并正在运行,可以使用Job接口来管理协程,并使用一些函数来检查协程的状态。以下是一些常见的方法: 1.launch 函数返回一个 Job 对象,可以使用这个对象来确定协程的状态。例如&…...

终极指南:KOReader开源电子书阅读器如何打造完美个性化阅读体验
终极指南:KOReader开源电子书阅读器如何打造完美个性化阅读体验 【免费下载链接】koreader An ebook reader application supporting PDF, DjVu, EPUB, FB2 and many more formats, running on Cervantes, Kindle, Kobo, PocketBook and Android devices 项目地址…...

单电源运放差分放大电路实战:3.3V供电下的精确计算与仿真验证
单电源运放差分放大电路实战:3.3V供电下的精确计算与仿真验证 在嵌入式系统开发中,信号调理电路的设计往往面临低功耗与高精度的双重挑战。单电源运放差分放大电路因其结构简单、成本低廉,成为3.3V供电环境下小信号放大的首选方案。本文将深入…...

Winhance中文版:3大模块全面提升Windows使用体验
Winhance中文版:3大模块全面提升Windows使用体验 【免费下载链接】Winhance-zh_CN A Chinese version of Winhance. C# application designed to optimize and customize your Windows experience. 项目地址: https://gitcode.com/gh_mirrors/wi/Winhance-zh_CN …...

机器人学开发与编程实践:从零到一掌握Robotics Toolbox核心应用
机器人学开发与编程实践:从零到一掌握Robotics Toolbox核心应用 【免费下载链接】robotics-toolbox-python Robotics Toolbox for Python 项目地址: https://gitcode.com/gh_mirrors/ro/robotics-toolbox-python 机器人技术正在改变制造业、医疗和服务行业的…...

告别复杂配置:Phi-3-Mini-128K开箱即用,仿ChatGPT界面快速搭建对话工具
告别复杂配置:Phi-3-Mini-128K开箱即用,仿ChatGPT界面快速搭建对话工具 1. 项目简介 Phi-3-Mini-128K是一款基于微软Phi-3-mini-128k-instruct模型开发的轻量化对话工具,它彻底改变了传统大模型部署的复杂流程。这个工具最大的特点就是&quo…...

Poppins字体:全球化设计的多语言排版解决方案
Poppins字体:全球化设计的多语言排版解决方案 【免费下载链接】Poppins Poppins, a Devanagari Latin family for Google Fonts. 项目地址: https://gitcode.com/gh_mirrors/po/Poppins 在全球化设计的浪潮中,字体作为视觉传达的核心元素&#x…...

yz-bijini-cosplay实战体验:一键切换LoRA风格,轻松生成动漫/游戏/国风Cosplay角色
yz-bijini-cosplay实战体验:一键切换LoRA风格,轻松生成动漫/游戏/国风Cosplay角色 你是否曾经为了生成一张理想的Cosplay图片而反复切换模型,每次都要忍受漫长的加载等待?或者因为模型对中文提示词理解不佳,导致生成的…...

抖音无水印视频批量下载:如何免费获取高清内容并高效管理
抖音无水印视频批量下载:如何免费获取高清内容并高效管理 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback su…...

小白必读:DeepSeek-R1-Distill-Qwen-1.5B快速部署指南,轻松玩转AI
小白必读:DeepSeek-R1-Distill-Qwen-1.5B快速部署指南,轻松玩转AI 1. 认识DeepSeek-R1-Distill-Qwen-1.5B模型 DeepSeek-R1-Distill-Qwen-1.5B是一款轻量级但性能强大的语言模型,特别适合在资源有限的设备上运行。它通过知识蒸馏技术从更大…...

终极文档下载指南:kill-doc浏览器脚本快速突破文档获取限制
终极文档下载指南:kill-doc浏览器脚本快速突破文档获取限制 【免费下载链接】kill-doc 看到经常有小伙伴们需要下载一些免费文档,但是相关网站浏览体验不好各种广告,各种登录验证,需要很多步骤才能下载文档,该脚本就是…...